分布式训练:DDP单机多卡并行
- 1. 分布式训练总览
- 1.1 并行方式
- 1.2 PyTorch中数据并行方法
- 1.3 训练原理
- 1. DataParallel(DP)训练原理
- 2. DistributedDataParallel(DDP)多卡训练的原理
- 2. PyTorch分布式代码实战
- 2.1 不使用DDP和混合精度加速的代码
- 2.2 使用DDP对代码改造后
- 参考代码:
- 参考资料
分布式训练是一种模型训练范式,涉及在多个工作节点上分散训练工作量,从而显著提高训练速度和模型准确性。虽然分布式训练可以用于任何类型的ML模型训练,但将其用于大型模型和计算要求高的任务(如深度学习)是最有益的。
PyTorch中有几种方法可以执行分布式训练,每种方法在某些用例中都有其优势:
- DistributedDataParallel (DDP)
- Fully Sharded Data Parallel (FSDP)
- Remote Procedure Call (RPC) distributed training
- Custom Extensions
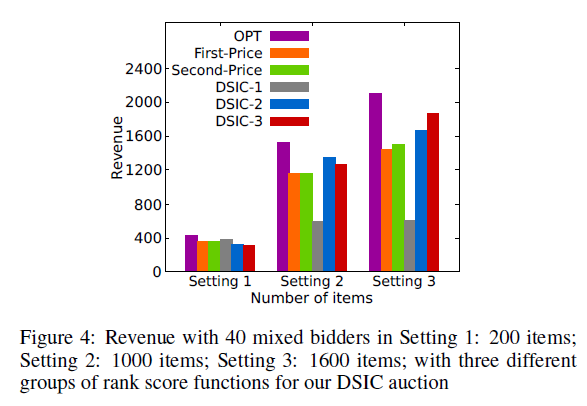
1. 分布式训练总览
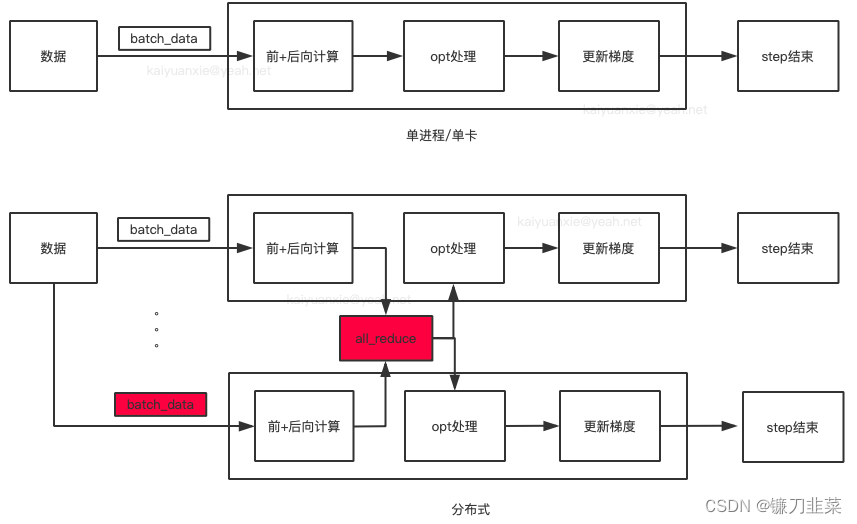
从图片的对比可知,分布式使得数据的切分(batch_data)以及前向计算后的数据传递发生了变化(all_reduce),对应到ddp里面:
1、由于分布式采用的是多进程模式,要保证不同进程拿到的是不同的数据,需要在正向传播时对数据的分配进行调整,所以dataloader里面多了一个sampler参数。
2、反向传播计算后需要对参数进行共享通信,所以多了一个allreduce的处理。
1.1 并行方式
数据并行:多张GPUs使用相同的模型副本,但采用同一batch中的不同数据进行训练。
模型并行:多张GPUs使用同一batch的数据,分别训练模型的不同部分。
简而言之,并行就是对并行对象进行拆分,以提高运算效率。
1.2 PyTorch中数据并行方法
在PyTorch中常用的数据并行分布式训练方法主要是DataParallel(DP)和DistributedDataParallel(DDP),当然还有其他方式,后面会详细介绍。
- DataParallel(DP):优点是实现简单,代码量较少,启动速度快一点。缺点是速度较慢,且存在负载不均衡的问题。单进程,多线程。主卡显存占用比其他卡会多很多。不支持 Apex 的混合精度训练。是Pytorch官方很久之前给的一种方案。受 Python GIL 的限制,DP的操作原理是将一个batch size的输入数据均分到多个GPU上分别计算(此处注意,batch size要大于GPU个数才能划分)。
- DistributedDataParallel(DDP):
All-Reduce模式,本意是用来分布式训练(多机多卡),但是也可用于单机多卡。配置稍复杂。多进程。数据分配较均衡。是新一代的多卡训练方法。
使用torch.distributed库实现并行。torch.distributed 库提供分布式支持,包括 GPU 和 CPU 的分布式训练支持,该库提供了一种类似MPI的接口,用于跨多机器网络交换张量数据。它支持几种不同的后端和初始化方法。DDP通过Ring-Reduce的数据交换方法提高了通讯效率,并通过启动多个进程的方式减轻Python GIL的限制,从而提高训练速度。
补充1: MPI 全名叫 Message Passing Interface,即信息传递接口,作用是可以通过 MPI 可以在不同进程间传递消息,从而可以并行地处理任务,即进行并行计算。需要注意的是,尽管我们偶尔会说使用 MPI 编写了某某可执行程序,但是 MPI 其实只是一个库,而不是一种语言,其可以被 Fortran、C、C++、Python 调用。
补充2:Ring All-reduce VS. Tree All-reduce
DL data parallel同步SGD训练时,需要将不同GPU卡上的模型参数梯度汇总求平均,引入了不同的卡之间通信的算法。最简单的的方式是PS模式,简单来说所有的worker卡将梯度发送给main卡进行求和取平均,但这种方式一个很大的问题就是随着机器GPU卡数的增加,main卡的通信量也是线性增长。在通信带宽确定的情况下(不考虑延迟),GPU卡数越多,通信量越大,通信时间越长, 所需要的时间会随着GPU数量增长而线性增长。
为了解决这个问题,引入了一种GPU卡之间的通信方式的优化算法,就是Ring All-Reuce, 它是高性能领域中的一个经典算法,并不是为了深度学习而生。 它的优点是通信量是恒定的,不随GPU数量的增加而增长。该算法分两个步骤进行:首先是scatter-reduce,然后是allgather。在scatter-reduce步骤中,GPU将交换数据,使每个GPU可得到最终结果的一个块。在allgather步骤中,GPU将交换这些块,以便所有GPU得到完整的最终结果。
整个通信过程中,每个GPU的通信量不再随着GPU增加而增加,通信的速度受到环中相邻GPU之间最慢的链接(最低的带宽)的限制(不考虑延迟)。因此当在分布式多节点训练中,每个机器节点可能包含多个GPU卡,机器节点内部GPU卡之间连接可能是快速的NVLINK,而机器节点之间的连接可能是相对较慢的Infiniband,所以利用简单的RingAll-reduce速度将受限于infiniband的带宽,而机器节点内的NVLINK可能并不会派上用场,因此又有了Ring All-reduce的变种,Hierarchical rings(一种是2D-Ring including inter-node and intra-node).
Ring-allreduce achieves full bandwidth, but the downside of rings is that latency scales linearly with the number of GPUs, preventing scaling above hundreds of GPUs.
Double binary trees, which offer full bandwidth and a logarithmic latency even lower than 2D ring latency.
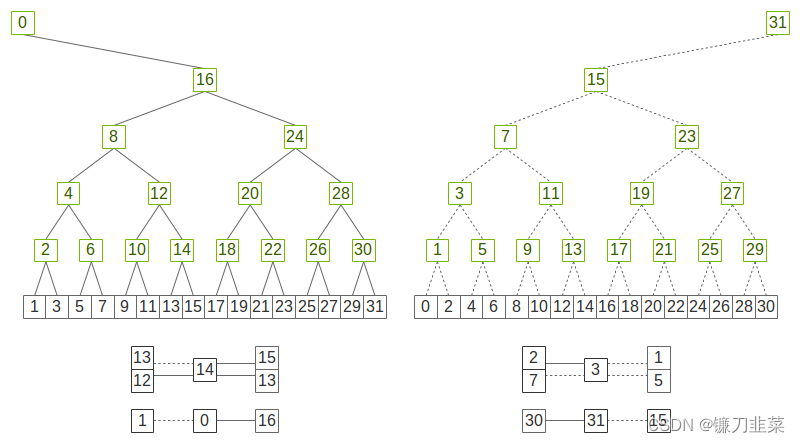
Figure. Two complementary binary trees where each rank is at most a node in one tree and a leaf in the other.
1.3 训练原理
1. DataParallel(DP)训练原理
- 首先在
前向过程中,输入数据会被划分成多个子部分(以下称为副本)送到不同的device中进行计算,而模型module是在每个device上进行复制一份,也就是说,输入的batch是会被平均分到每个device中去,但是模型module是要拷贝到每个devide中去的,每个模型module只需要处理每个副本即可,当然要保证设定的batch size大于GPU个数。 - 然后在
反向传播过程中,每个副本的梯度被累加到原始模块中。概括来说就是:DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总。
如下图所示:
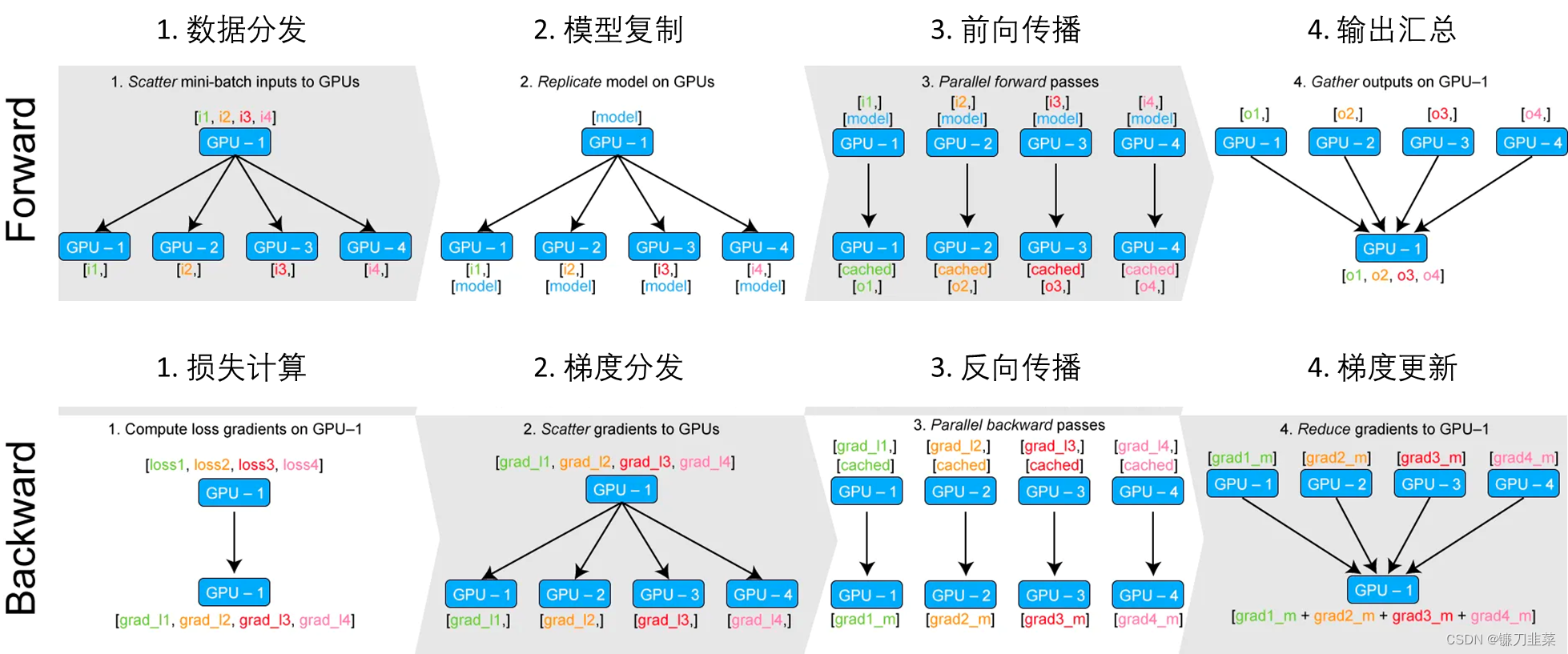
如图所示,在每个前向过程中,模型会由GPU-1复制到其他GPUs,这将引入训练延迟。其次,在每个GPU完成前向运算后,其输出logits会被收集到GPU-1。logits的收集是DataParallel中GPU显存利用不均衡的问题根源。这一现象在图像分类这种logits维度很小的任务中不明显,在图像语义分割和文本翻译等密集预测任务中,GPU-1显存占用会显著高于其他GPU,这就造成了额外的GPU资源浪费。
而且,DataParallel的并行受到Python中GIL争用的影响,仅能以单进程多线程的方式实现,同时DataParallel最多支持单机多卡的训练模式,无法适用于多级多卡的大模型训练。
除此之外,在前向传播和反向传播中,都存在数据的分发以及汇总带来的延迟。
问题①:The parallelized module must have its parameters and buffers on device_ids[0] before running this DataParallel module. 意思就是:在运行此DataParallel模块之前,并行化模块必须在device_ids [0]上具有其参数和缓冲区。
问题②:如果直接使用nn.DataParallel的时候,训练采用多卡训练,会出现一个warning:UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector。原因是因为每张卡上的loss都是要汇总到第0张卡上求梯度,更新好以后把权重分发到其余卡。但是为什么会出现这个warning,这其实和nn.DataParallel中最后一个参数dim有关,其表示tensors被分散的维度,默认是0,nn.DataParallel将在dim0(批处理维度)中对数据进行分块,并将每个分块发送到相应的设备。单卡的没有这个warning,多卡的时候采用nn.DataParallel训练会出现这个warning,由于计算loss的时候是分别在多卡计算的,那么返回的也就是多个loss,使用了多少个gpu,就会返回多少个loss。
2. DistributedDataParallel(DDP)多卡训练的原理
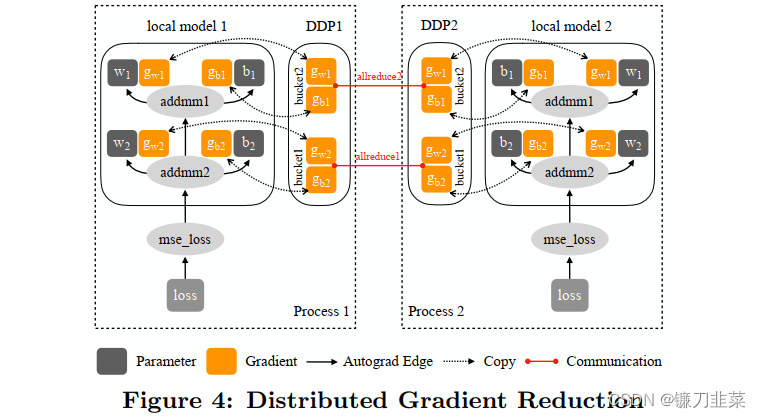
首先将模型在各个GPU上复制一份,并将总的 batch 数据等分到不同的GPU上进行计算(shuffle 顺序打乱),每个进程都从磁盘加载其自己的数据;然后在模型训练时,损失函数的前向传播和计算在每个 GPU 上独立执行,因此,不需要收集网络输出。在反向传播期间,各个进程通过一种叫 Ring-Reduce 的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的平均梯度;然后用这个值在所有 GPU 上执行梯度下降,从而每个 GPU 在反向传播结束时最终得到平均梯度的相同副本;最终各个进程用平均后的梯度更新自己的参数,因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的。
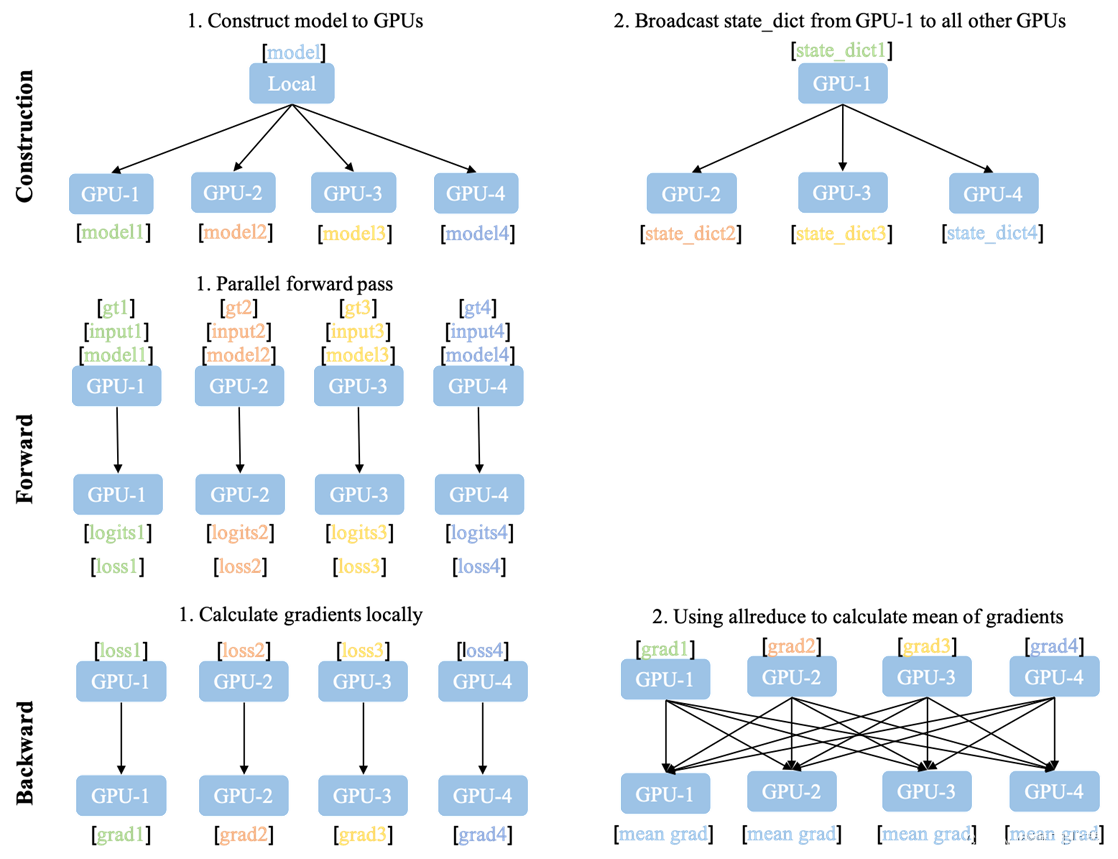
如图所示,DDP需要额外的建立进程组阶段(Construction)。在Construction阶段需要首先明确通信协议和总进程数。通信协议是实现DDP的底层基础,总进程数就是指有多少个独立的并行进程,被称为 worldsize. 根据需求每个进程可以占用一个或多个GPU,但并不推荐多个进程共享一个GPU,这会造成潜在的性能损失。为了便于理解,在本文的所有示例中我们假定每个进程只占用1个GPU,占用多个GPU的情况只需要简单的调整GPU映射关系就好。
并行组建立之后,每个GPU上会独立的构建模型,然后GPU-1中模型的状态会被广播到其它所有进程中以保证所有模型都具有相同的初始状态。值得注意的是Construction只在训练开始前执行,在训练中只会不断迭代前向和后向过程,因此不会带来额外的延迟。
相比于DataParallel,DDP的前向后向过程更加简洁。推理、损失函数计算,梯度计算都是并行独立完成的。DDP实现并行训练的核心在于梯度同步。梯度在模型间的同步使用的是 allreduce 通信操作,每个GPU会得到完全相同的梯度。如图中后向过程的步骤2,GPU间的通信在梯度计算完成后被触发(hook函数)。
图中没有画出的是,通常每个GPU也会建立独立的优化器。由于模型具有同样的初始状态和后续相同的梯度,因此每轮迭代后不同进程间的模型是完全相同的,这保证了DDP的数理一致性。
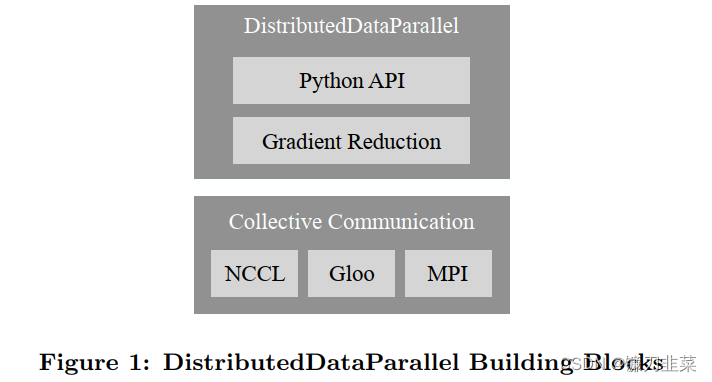
补充3:DDP在性能优化方面是怎么做的?
为优化性能,DDP中针对 allreduce 操作进行了更深入的设计。梯度的计算过程和进程间的通信过程分别需要消耗一定量的时间,等待模型所有的参数都计算完梯度再进行通信显然不是最优的。
DDP中的设计是通过将全部模型参数划分为无数个小的bucket,在bucket级别建立allreduce。当所有进程中bucket0的梯度计算完成后就立刻开始通信,此时bucket1中梯度还在计算。这样可以实现计算和通信过程的时间重叠。
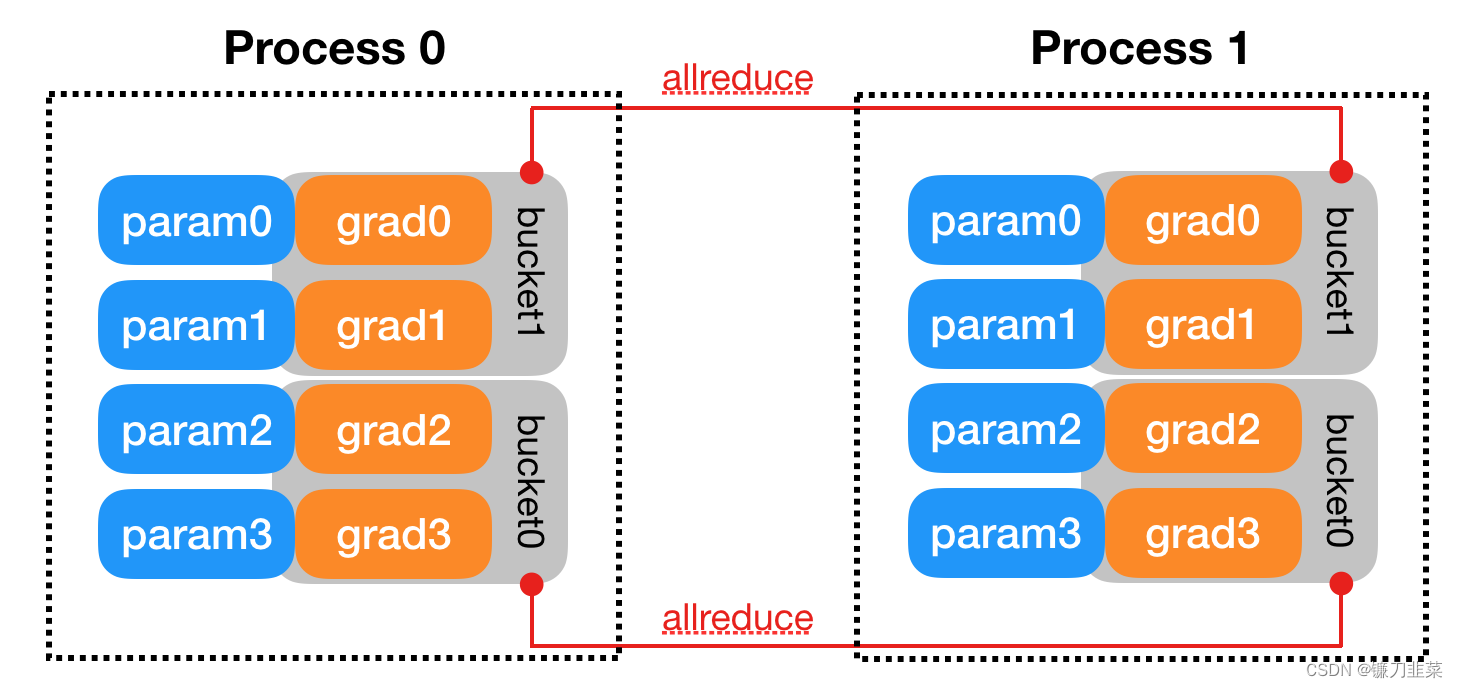
注意:DDP要求所有进程上的Reducer实例以完全相同的顺序调用allreduce,这是通过始终按bucket索引顺序而不是实际的bucket就绪顺序运行allreduced来实现的。进程之间不匹配的allreduce顺序可能导致错误的结果或DDP反向挂起。
补充4:DDP后端通信方式有哪些?
DDP后端的通信由CPP编写的多种协议支持,通信协议的选择由两个因素决定:
- 使用的计算机集群的网络环境:
- Ethernet(以太网,大部分机器都是这个环境):优先选择性能更佳的 nccl ,gloo 作为备用。(经验:单机多卡直接 nccl;多机多卡先尝试 nccl ,如果通信有问题,使用 gloo 代替。)
- InfiniBand:只支持 nccl.
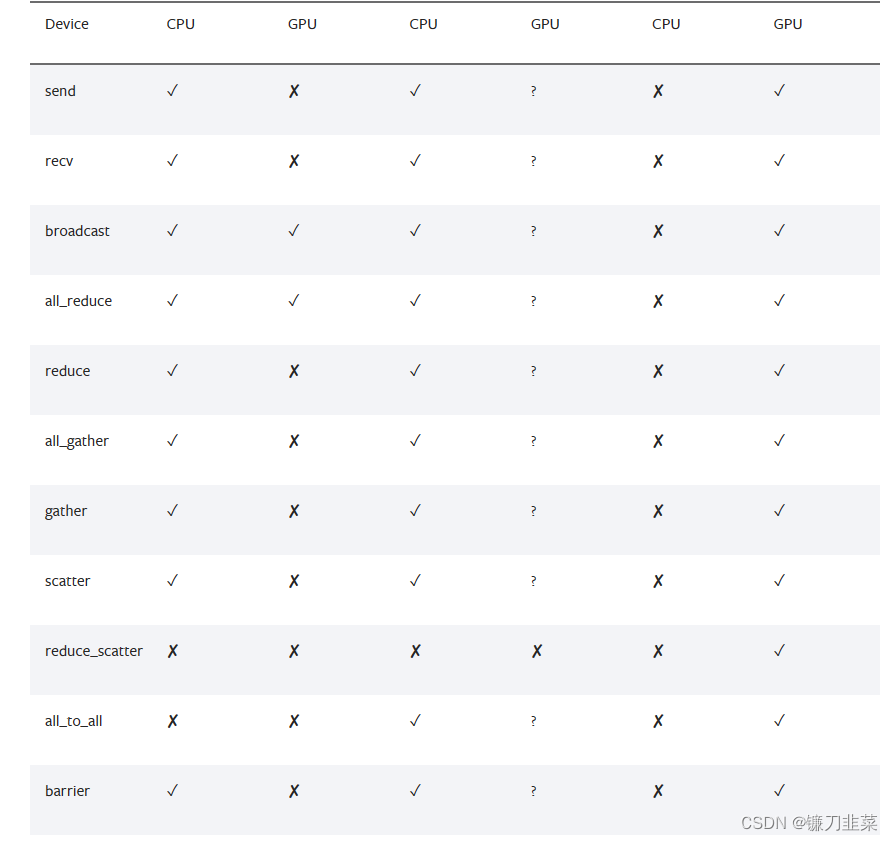
- 不同通信协议支持的算子范围不同(参考下图),例如,gloo 能够实现 GPU 中最基本的 DDP 训练, nccl 支持更加多样的算子。因此,在选择通信协议时还需要考虑相应的代码功能。
torch.distributed支持三个内置后端,每个后端都具有不同的功能。下表显示了可用于CPU/CUDA张量的功能。只有当用于构建PyTorch的实现支持CUDA时,MPI才支持CUDA。
2. PyTorch分布式代码实战
本文的代码针对单机多卡的情况,使用 nccl 后端,并通过 env 进行初始化。
2.1 不使用DDP和混合精度加速的代码
首先引入所用到的库:
import time
import argparse
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
from tqdm import tqdm
定义一个简单的卷积神经网络模型:
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2))
self.fc = nn.Linear(7 * 7 * 32, num_classes)
def forward(self, x):
with torch.cuda.amp.autocast(): # 混合精度,加速推理
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
定义参数解析函数:
def prepare():
parser = argparse.ArgumentParser()
parser.add_argument('-g', '--gpuid', default='0', type=int, help="which gpu to use")
parser.add_argument('-e', '--epochs', default=5, type=int, metavar='N', help='number of total epochs to run')
parser.add_argument('-b', '--batch_size', default=32, type=int, metavar='N', help='number of batchsize')
args = parser.parse_args()
return args
定义训练和测试函数:
def train(gpu, model, train_dloader, criterion, optimizer):
model.train()
for i, (images, labels) in enumerate(tqdm(train_dloader)):
images = images.to(gpu)
labels = labels.to(gpu)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def test(model, test_dloader):
model.eval()
size = torch.tensor(0.).cuda()
correct = torch.tensor(0.).cuda()
for images, labels in test_dloader:
images = images.cuda()
labels = labels.cuda()
with torch.no_grad():
outputs = model(images)
size += images.size(0)
correct += (outputs.argmax(1) == labels).type(torch.float).sum()
acc = correct / size
print(f'Accuracy is {acc:.2%}')
定义main函数,给出训练过程:
def main(gpu, args):
model = ConvNet().cuda(gpu)
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
train_dataset = torchvision.datasets.MNIST(root='../Datasets', train=True, transform=transforms.ToTensor(), download=True)
train_dloader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=4,
pin_memory=True,
)
test_dataset = torchvision.datasets.MNIST(root='../Datasets', train=False, transform=transforms.ToTensor(), download=True)
test_dloader = torch.utils.data.DataLoader(
dataset=test_dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=2,
pin_memory=True,
)
for epoch in range(args.epochs):
print(f'begin training of epoch {epoch + 1}/{args.epochs}')
train(gpu, model, train_dloader, criterion, optimizer)
print(f'begin testing')
test(model, test_dloader)
torch.save({'model': model.state_dict()}, './outputs/origin_checkpoint.pt')
最后确保主函数被启动:
if __name__ == '__main__':
args = prepare()
time_start = time.time()
main(args.gpuid, args)
time_elapsed = time.time() - time_start
print(f'\ntime elapsed: {time_elapsed:.2f} seconds')
执行结果:
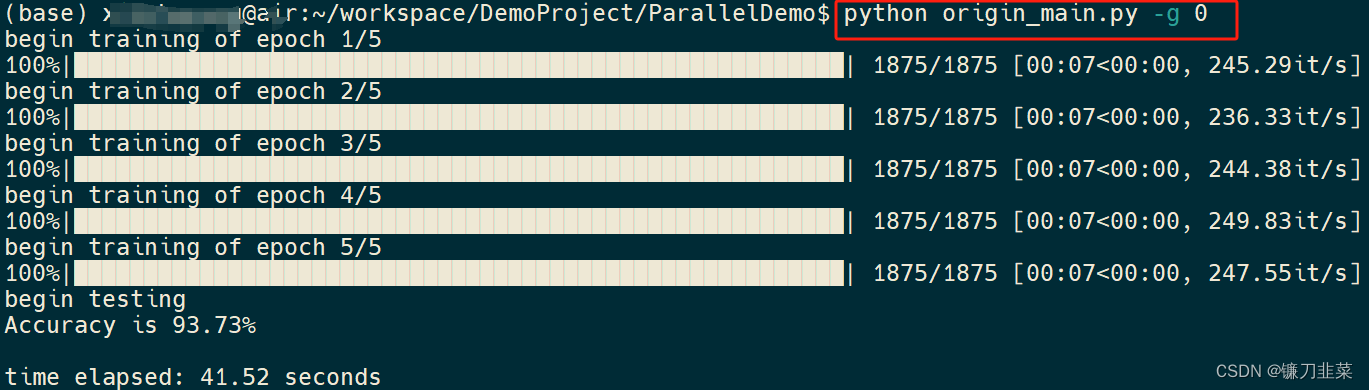
2.2 使用DDP对代码改造后
使用DDP方式完成程序并行,实现模型多卡复制和数据并行。首先导入关键包:
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.cuda.amp import GradScaler
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
在DDP的代码实现中,最重要的步骤之一就是初始化。所谓初始化对应于上文介绍的Construction阶段,每个进程中需要指明几个关键的参数:
- backend:明确后端通信方式,nccl还是gloo
- init_method: 初始化方式,tcp还是environment variable(env),可以简单理解为进程获取关键参数地址和方式
- word_size:总的进程数有多少
- rank:当前进程是总进程中的第几个
初始化方式不同会影响代码的启动部分。本文会分别给出tcp和env模式的样例。
(1)TCP模式
注意那些标记被更改的代码部分:
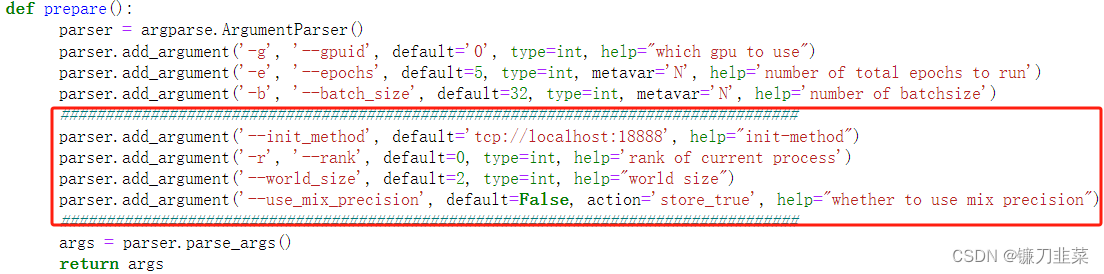
在参数解析函数中增加了以下参数:
args.init_method:url地址,用来指明的初始化方法。在tcp初始化方法中,其格式应为:tcp:[ IP ]:[ Port ] 。IP为rank=0进程所在的机器IP地址,Port为任意一个空闲的端口号。当采用的是单机多卡模式时,IP可以默认为//localhostargs.rank:当前进程在所有进程中的序号args.world_size:进程总数args.use_mix_precision:布尔变量,控制是否使用混合精度
在训练函数中增加或修改如下内容:
- 增加DDP初始化代码,需要指明backend, init_method, rank和world_size
dist.init_process_group(backend='nccl', init_method=args.init_method, rank=args.rank, world_size=args.world_size)
- 在并行环境下,对于用BN(Batch Normalization)层的模型需要转换为同步BN层;其次,用
DistributedDataParallel将模型封装为一个DDP模型,并复制到指定的GPU上。封装时不需要更改模型内部的代码;第三,设置混合精度中的scaler,通过设置enabled参数控制其生效。
# Wrap the model
model = ConvNet().cuda()
model = nn.SyncBatchNorm.convert_sync_batchnorm(model)
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank])
scaler = GradScaler(enabled=args.use_mix_precision)
- DDP要求定义distributed.DistributedSampler,通过封装train_dataset实现;然后在建立DataLoader时指定sampler。注意shuffle=False。DDP的数据打乱需要通过设置sampler。
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_dloader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=args.batch_size,
shuffle=False, # 使用数据采样器就不需要打乱数据
num_workers=2, # 工作进程个数
pin_memory=True,
sampler=train_sampler)
- 在每个epoch开始前打乱数据顺序,注意total_step已经变为
original_length//args.world_size
total_step = len(train_dloader)
for epoch in range(args.epochs):
train_dloader.sampler.set_epoch(epoch)
- 利用
torch.cuda.amp.autocast控制前向过程中是否使用半精度计算。
with torch.cuda.amp.autocast(enabled=use_mix_precision):
outputs = model(images)
loss = criterion(outputs, labels)
- 当使用混合精度时,scaler会缩放loss来避免由于精度变化导致梯度位0的情况。
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
- 为了避免log信息的重复打印,只允许rank0号进程打印
if (i + 1) % 100 == 0 and args.rank == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, args.epochs, i + 1, total_step, loss.item()))
- 清理进程
dist.destroy_process_group()
假设服务器环境为 2 台服务器(也称为2个 node),每台服务器 2块GPU。启动方式为:
# Node 0 : ip 172.16.10.169 port : 12345
# terminal-0
python ddp-tcp.py --init_method tcp://172.16.10.169:12345 -g 0 --rank 0 --world_size 4 --use_mix_precision
# terminal-1
python ddp-tcp.py --init_method tcp://172.16.10.169:12345 -g 1 --rank 1 --world_size 4 --use_mix_precision
# Node 1 :
# terminal-0
python tcp_init.py --init_method tcp://172.16.10.169:12345 -g 0 --rank 2 --world_size 4 --use_mix_precision
# terminal-1
python tcp_init.py --init_method tcp://172.16.10.169:12345 -g 1 --rank 3 --world_size 4 --use_mix_precision
显然,TCP模式启动比较麻烦,需要在bash中独立的启动每一个进程,并为每个进程分配好其rank序号。因此,更多的时候我们使用ENV模式。
(2)ENV模式
ENV模式启动会更加简洁,对于每个进程并不需要在dist.init_process_group中手动的指定其rank、world_size和url。程序会在环境变量中去寻找这些值。
定义参数解析函数:
def prepare():
parser = argparse.ArgumentParser()
parser.add_argument('-g', '--gpuid', default='0,1', help="which gpu to use")
parser.add_argument('-e', '--epochs', default=5, type=int, metavar='N', help='number of total epochs to run')
parser.add_argument('-b', '--batch_size', default=32, type=int, metavar='N', help='number of batchsize')
##################################################################################
parser.add_argument("--local_rank", type=int, help='rank in current node')
parser.add_argument('--use_mix_precision', default=False, action='store_true', help="whether to use mix precision")
##################################################################################
args = parser.parse_args()
return args
- args.local_rank指的是当前进程在当前机器中的序号,注意和在全部进程中序号的区别。在env模式中,这个参数是必须的,由启动脚本自动划分,不需要手动指定。注意要善用local_rank来分配GPU ID。
定义初始化函数,对进程进行初始化,使用 nccl 后端,并用 env 作为初始化方法。
def setup(local_rank, args):
# 定义该函数,在转换device的时候直接使用a = a.cuda()即可,否则要用a=a.cuda(local+rank)
os.environ['RANK'] = str(local_rank)
torch.cuda.set_device(local_rank)
dist.init_process_group(backend='nccl', init_method='env://')
初始化之后,可以很轻松地在需要时获得local_rank、world_size,而不需要作为额外参数从 main() 函数中一层一层往下传。
local_rank = dist.get_rank()
world_size = dist.get_world_size()
在需要 print, log, save_model时,由于多个进程拥有相同的副本,故只需要一个进程执行即可:
if local_rank == 0:
print(f'begin testing')
......
if local_rank == 0:
torch.save({'model': model.state_dict(), 'scaler': scaler.state_dict()}, './outputs/ddp_checkpoint.pt')
定义结果汇总函数,对多个进程的计算结果进行汇总,如 loss、评价指标。
def reduce_tensor(tensor: torch.Tensor):
# 对多个进程计算的多个 tensor 类型的 输出值取平均操作
rt = tensor.clone() # tensor(9.1429, device='cuda:1')
dist.all_reduce(rt, op=torch.distributed.ReduceOp.SUM)
rt /= dist.get_world_size()
return rt
定义随机数生成器,用于训练过程中,增强训练的随机性。
def get_ddp_generator(seed=2023):
# 对每个进程使用不同的随机种子,增强训练的随机性
local_rank = dist.get_rank()
g = torch.Generator()
g.manual_seed(seed + local_rank)
return g
补充:Nvidia提供了NCCL库来方便基于GPU的集合通信,这也是目前分布式GPU训练必备的工具之一。
python -c "import torch;print(torch.cuda.nccl.version())"
(2, 10, 3)
对性能有影响的参数主要包括:
NCCL_IB_DISABLE:禁用NCCL要使用的IB/RoCE传输。相反,NCCL将回退到使用IP套接字。定义并设置为1以禁止使用InfiniBand谓词进行通信(并强制使用另一种方法,例如IP套接字)。NCCL_P2P_LEVEL:NCCL_P2P_LEVEL变量允许用户精细地控制何时在GPU之间使用对等(P2P)传输。该级别定义了NCCL将使用P2P传输的GPU之间的最大距离。应该使用表示路径类型的短字符串来指定使用P2P传输的地形截止点。 数值0~5控制在何种情况下GPU卡之间可以使用P2PNCCL_P2P_DISABLE:NCCL_P2P_DISABLE变量禁用对等(P2P)传输,该传输使用NVLink或PCI在GPU之间使用CUDA直接访问。设定为1 相当于设置NCCL_P2P_LEVEL=0,并且会被NCCL_P2P_LEVEL的值所覆盖NCCL_NET_GDR_LEVEL:NCCL_NET_GDR_LEVEL变量允许用户精细控制何时在NIC和GPU之间使用GPU Direct RDMA。该级别定义NIC和GPU之间的最大距离。应使用表示路径类型的字符串来指定GpuDirect的地形截止点。数值 0~5 控制在何种情况下,跨节点的GPU卡之间可以使用GDRNCCL_NET_GDR_READ: 当发送数据时,只要GPU-NIC距离在NCCL_NET_GDR_LEVEL指定的距离内,NCCL_NET_GDR_READ变量就会启用GPU Direct RDMA。2.4.2之前,GDR读取默认禁用,即发送数据时,数据首先存储在CPU内存中,然后进入InfiniBand卡。自2.4.2起,基于NVLink的平台默认启用GDR读取。值为 0 会强制在发送数据时不使用GDR;而在为1的时候,根据NCCL_NET_GDR_LEVEL来决定发送数据时是否使用GDR。接收数据时是否使用GDR完全由距离决定,和NCCL_NET_GDR_READ无关(参见nccl源码transport/http://net.cc中netGetGdrSupport函数)。NCCL_SHM_DISABLE:NCCL_SHM_DISABLE变量禁用共享内存(SHM)传输。当对等不能发生时,在设备之间使用SHM,因此使用主机内存。禁用SHM时,NCCL将使用网络(即InfiniBand或IP套接字)在CPU套接字之间进行通信。在P2P不能生效的情况下,是否使用cpu的共享内存来传输数据。如果禁用,则使用socket通信
因为nccl里面以enum{ “PIX”, “PXB”, “PHB”, “NODE”, “SYS” }来描述设备(包括GPU卡和网卡)之间的”距离”,所以NCCL_P2P_LEVEL和NCCL_NET_GDR_LEVEL都有0~5这6种取值,来细粒度控制何种情况下可以使用P2P或者GDR。
程序入口:
在if __name__ == '__main__':中,使用 spawn() 函数启动 DDP,该函数的主要参数包括:
fn:需要并行的函数,这里是main()函数,每个线程将执行一次该函数;args:fn所需的参数,注意,传给fn的参数必须写成元组的形式,哪怕只有一个参数;nprocs:启动的进程数,默认值为1,这里将其设置为word_size即可,注意,nprocs的值与word_size不一致会导致进程等待同步而一直停滞。
if __name__ == '__main__':
args = prepare()
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12346'
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpuid
world_size = torch.cuda.device_count()
os.environ['WORLD_SIZE'] = str(world_size) # 当前服务器有4块GPU、
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:128"
time_start = time.time()
mp.spawn(main, args=(args, ), nprocs=world_size)
time_elapsed = time.time() - time_start
print(f'\ntime elapsed: {time_elapsed:.2f} seconds')
接着分析main()函数,即上面提到的 spawn() 函数中传入的第一个参数。代码关键部位修改如下:
- 参数列表更新:添加额外参数 local_rank,该参数无需在 mp.spawn() 函数中传递,系统会自动分配;
- 进程初始化:调用
setup()函数实现; - Batchnorm层同步:调用
convert_sync_batchnorm()函数用同步的方法完成BN以尽可能模拟单卡场景,尽管会降低GPU利用率,但可以提高模型在多卡场景下的表现;BN层同步的必要性依赖于单卡batch_size的大小,如果单卡batch_size太小,使用SyncBN可以提高性能。但是如果batch_size较大的时候就不需要使用SyncBN, 因为这需要多卡之间通信,会导致训练速度变慢。 - 数据并行:调用
DistributedDataParallel()函数实现; - 指定混合精度训练:调用
GradScaler()函数实现,作为参数传至 train() 函数中; - 训练采样器设置:每个 epoch 设置不同的 sampling 顺序;
- 避免副本重复执行:使用
if local_rank==0:语句进行约束; - 消除进程组:调用
destroy_process_group()函数实现。
def main(local_rank, args):
print(f"Running DDP example on {local_rank}.")
setup(local_rank, args)
# Wrap the model
model = ConvNet().cuda()
model = nn.SyncBatchNorm.convert_sync_batchnorm(model)
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
scaler = GradScaler(enabled=args.use_mix_precision)
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='../Datasets', train=True, transform=transforms.ToTensor(), download=True)
# 定义数据采样器
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_dloader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=args.batch_size,
shuffle=False, # 使用数据采样器就不需要打乱数据
num_workers=2, # 工作进程个数
pin_memory=True,
sampler=train_sampler)
test_dataset = torchvision.datasets.MNIST(root='../Datasets', train=False, transform=transforms.ToTensor(), download=True)
test_sampler = torch.utils.data.distributed.DistributedSampler(test_dataset)
test_dloader = torch.utils.data.DataLoader(
dataset=test_dataset,
batch_size=args.batch_size,
shuffle=False,
num_workers=2,
pin_memory=True,
sampler=test_sampler)
total_step = len(train_dloader)
for epoch in range(args.epochs):
if local_rank == 0:
print(f'begin training of epoch {epoch + 1}/{args.epochs}')
train_dloader.sampler.set_epoch(epoch)
train(model, train_dloader, criterion, optimizer, scaler, total_step, args.use_mix_precision, local_rank)
if local_rank == 0:
print(f'begin testing')
test(model, test_dloader)
if local_rank == 0:
torch.save({'model': model.state_dict(), 'scaler': scaler.state_dict()}, './outputs/ddp_checkpoint.pt')
dist.destroy_process_group()
train()函数 :通过 reduce_tensor() 函数对loss进行了取均值操作,并对反向传播的方式进行了修改 —— 通过scaler 对梯度进行缩放,防止由于使用混合精度导致损失下溢,并且对scaler自身的状态进行更新。多个并行进程共用同一个scaler。在模型保存过程中,如果后续需要继续训练(比如预训练-微调模式),最好将scaler 的状态一起保留,并在后续的微调过程中和模型的参数同时加载。
def train(model, train_dloader, criterion, optimizer, scaler, total_step, use_mix_precision, local_rank):
model.train()
for i, (images, labels) in enumerate(tqdm(train_dloader)):
images = images.cuda()
labels = labels.cuda()
######################## N5 ################################
with torch.cuda.amp.autocast(enabled=use_mix_precision):
outputs = model(images)
loss = criterion(outputs, labels)
reduced_loss = reduce_tensor(loss.data)
####################################################################
optimizer.zero_grad()
############## N6 ##########
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
####################################
if (i+1) % 100 == 0 and local_rank == 0:
print('Step [{}/{}], Loss: {:.4f}'.format(i + 1, total_step, loss.item()))
test()函数:
def test(model, test_dloader):
model.eval()
size = torch.tensor(0.).cuda()
correct = torch.tensor(0.).cuda()
for images, labels in test_dloader:
images = images.cuda()
labels = labels.cuda()
with torch.no_grad():
outputs = model(images)
size += images.size(0)
correct += (outputs.argmax(1) == labels).type(torch.float).sum()
acc = correct / size
print(f'Accuracy is {acc:.2%}')
程序运行:$ python ddp_main_env.py -g 0,1,2,3


参考代码:
- https://github.com/rickyang1114/DDP-practice.git
- https://github.com/KaiiZhang/DDP-Tutorial.git
参考资料
- DISTRIBUTED AND PARALLEL TRAINING TUTORIALS
- 使用 DDP 实现程序单机多卡并行指南
- 分布式训练Allreduce算法
- MPI 与并行计算入门
- ring allreduce和tree allreduce的具体区别是什么?
- Massively Scale Your Deep Learning Training with NCCL 2.4
- 「分布式训练」原理讲解+ 「DDP 代码实现」修改要点
- DISTRIBUTED DATA PARALLEL
- 分布式训练 & 多GPU训练
- DISTRIBUTED COMMUNICATION PACKAGE - TORCH.DISTRIBUTED
- 一看就懂的DDP代码实践
- 上手Distributed Data Parallel的详尽教程
- 关于DistributedDataParallel的简单详细步骤以及踩坑总结
- PyTorch分布式训练基础–DDP使用
- GPU数据传输概览
- Environment Variables