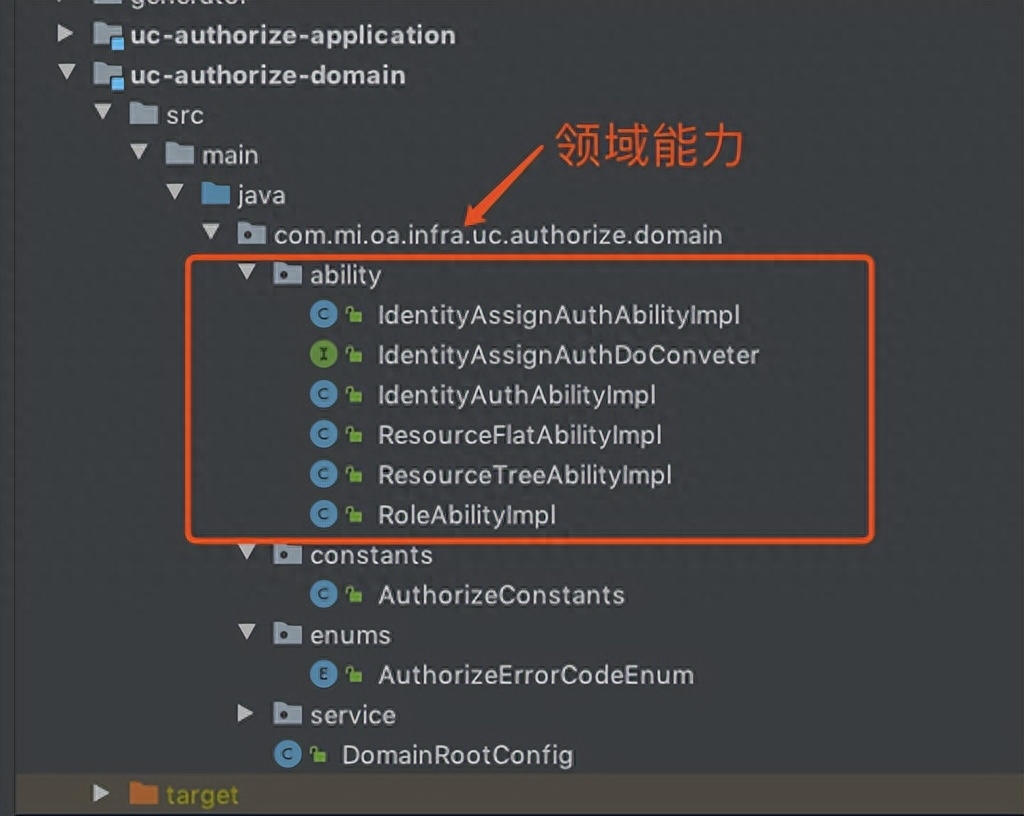
0、前言
在Elasticsearch实际应用中经常会遇到嵌套文档的情况,而且会有“对象数组彼此独立地进行索引和查询的诉求”。在ES中这种嵌套文档称为父子文档,父子文档“彼此独立地进行查询”至少有以下两种方式:
1)父子文档。在ES的5.x版本中通过parent-child父子type实现,即一个索引对应多个type;
对于6.X+版本由于不再支持一个索引多个type,所以父子索引的实现改成了Join。
2)Nested嵌套类型。
1、ES数据类型概览
1.常见类型
binary:接受二进制值作为 Base64 编码的字符串。默认情况下,该字段不存储,也不可搜索,不能包含换行符 \n
boolean:布尔类型,可以接受 true 或 false ,可以使用字符串和直接到布尔类型,空字符串为 false,包含:true,false,"true","false",""
keyword:关键字类型,不进行分词,直接索引,支持模糊、支持精确匹配,支持聚合、排序操作,用于筛选数据。最大支持的长度为——32766 个 UTF-8 类型的字符。
number:数字类型,文档链接
long
integer
short
byte
double
float
half_float
scaled_float
unsigned_longDates:日期类型
date:可以是格式化后的日期字符串,也可以是时间戳,例如 2015-01-01, 2015-01-01T12:10:30Z,1420070400001
date_nanos:支持纳秒的日期格式,在 es 内部是存的长整型
alias :别名类型2.对象和关系类型
object:对象类型,是一个 json 对象
flattened:将对象作为单个字段值存储
nested:嵌套数据类型,可以看成是一个特殊的对象类型,可以让对象数组独立检索
join:同一个文档,但具有父子关系的,类似于树
3.结构化数据类型
range:范围类型,可以用来表示数据的区间
integer_range
float_range
long_range
double_range
date_range
ip_range
2、一个例子说明nested类型的作用
(1)Nested:嵌套对象是object数据类型的专用版本,能够对 对象数组进行彼此独立地索引和查询。
(2)对象数组默认组织形式
内部对象字段数组的实际存储机制与我们想的不一样。Lucene没有内部对象的概念,因为ElasticSearch将对象层次结构扁平化为一个字段名和字段值的列表。例如下面文档。
PUT user/user_info/1
{
"group" : "man",
"userName" : [
{
"first" : "张",
"last" : "三"
},
{
"first" : "李",
"last" : "四"
}
]
}
这里想要查询first为“张”,last为“四”的数据,按照我们的理解应该没有这种数据。按如下语句查询。
PUT user/user_info/1
{
"group" : "human",
"sex": "man",
"userName" : [
{
"first" : "张",
"last" : "三"
},
{
"first" : "李",
"last" : "四"
}
]
}查询结果如下:居然查询到了。这显然不符合我们的预期。
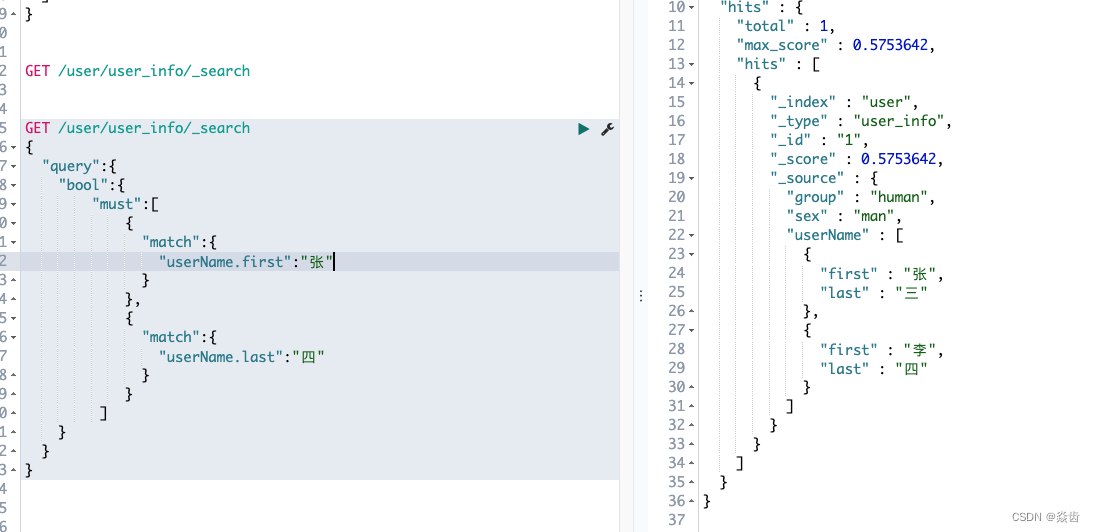
这个原因就是前面所说的lucene没有内部对象的概念,所谓的内部对象实际是被扁平化为一个简单的字段名称和值列表。文档内部存储是这个样子的:
{
"group" : "human",
"sex" : "man",
"userName.first" : [ "张", "李" ],
"userName.last" : [ "三", "四" ]
}
显然 userName.first 和 userName.last 字段平面化为多值字段,之前的关联性丢失,查询就不会得到预期的结果。
那么要如何实现自己想要的语义呢? —— 显然就是本文想要说的nested了。
3、nested类型的使用
3.1、首先插入如下一条记录
其含义为博客文章信息数据,其中每篇文章的评论以comments字段数组存储。
PUT /financeblogs/blog/docidart1
{
"title": "Invest Money",
"body": "Please start investing money as soon...",
"tags": ["money", "invest"],
"published_on": "18 Oct 2017",
"comments": [
{
"name": "William",
"age": 34,
"rating": 8,
"comment": "Nice article..",
"commented_on": "30 Nov 2017"
},
{
"name": "John",
"age": 38,
"rating": 9,
"comment": "I started investing after reading this.",
"commented_on": "25 Nov 2017"
},
{
"name": "Smith",
"age": 33,
"rating": 7,
"comment": "Very good post",
"commented_on": "20 Nov 2017"
}
]
}现在对于这条数据评论人姓名、年龄如下。
| name | age |
|---|---|
| William | 34 |
| John | 38 |
| Smith | 33 |
3.2、非nested时内部对象无法按预期查询
我们尝试查询{name:John, age:34}评论过的博客,按照我们的理解应该没有符合条件的记录。但是由于前面说过的平铺的原因实际上如下查询语句是检索到这条数据了的。
GET /financeblogs/blog/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"comments.name":"John"
}
},
{
"match":{
"comments.age":"34"
}
}
]
}
}
}3.3、接下来换成nested的玩法
0.把这个索引删除再来一遍
DELETE financeblogs1.创建如下索引。主要是mapping中的comments字段指定了类型为 nested。
PUT /financeblogs
{
"mappings": {
"blog": {
"properties": {
"title": {
"type": "text"
},
"body": {
"type": "text"
},
"tags": {
"type": "keyword"
},
"published_on": {
"type": "keyword"
},
"comments": {
"type": "nested",
"properties": {
"name": {
"type": "text"
},
"comment": {
"type": "text"
},
"age": {
"type": "short"
},
"rating": {
"type": "short"
},
"commented_on": {
"type": "text"
}
}
}
}
}
}
}2.插入同样的目标数据
PUT /financeblogs/blog/docidart1
{
"title": "Invest Money",
"body": "Please start investing money as soon...",
"tags": ["money", "invest"],
"published_on": "18 Oct 2017",
"comments": [
{
"name": "William",
"age": 34,
"rating": 8,
"comment": "Nice article..",
"commented_on": "30 Nov 2017"
},
{
"name": "John",
"age": 38,
"rating": 9,
"comment": "I started investing after reading this.",
"commented_on": "25 Nov 2017"
},
{
"name": "Smith",
"age": 33,
"rating": 7,
"comment": "Very good post",
"commented_on": "20 Nov 2017"
}
]
}3.使用nested查询方法
#查询name为John,age为34的记录发现是没有数据的。
GET /financeblogs/blog/_search?pretty
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "John"
}
},
{
"match": {
"comments.age": 34
}
}
]
}
}
}
}
]
}
}
}
4.查询name为John,age为38的数据就是有的
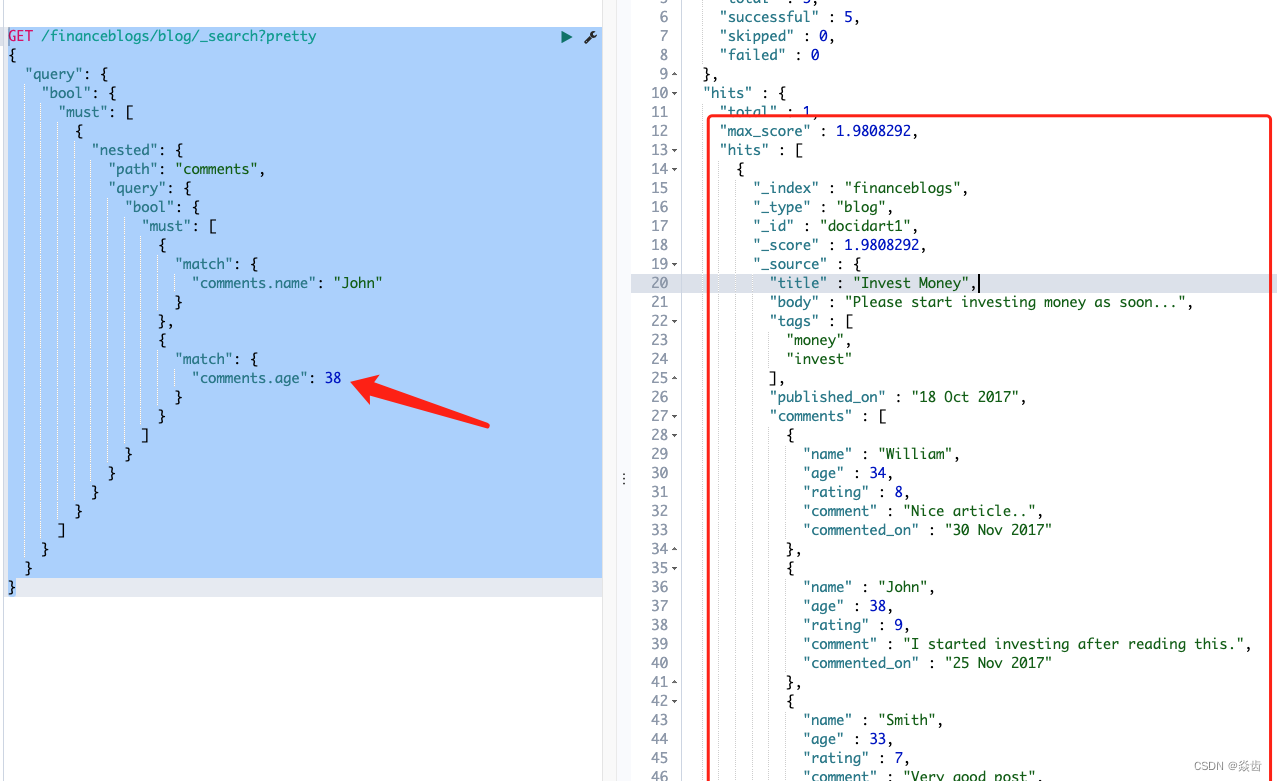
4、父子和嵌套两种方式比对
| 项 | 嵌套(nested) | 父子文档 |
| 优点 | 读取性能高 (据官方:比父子快5~10倍) | 父子文档可以独立更新 |
| 缺点 | 更新子文档时需要更新整个文档 | 读取性能差,CPU占用率高 (需额外的内存去维护关系) |
| 适应场景 | 查询为主,子文档偶尔更新的场景 | 子文档频繁更新; 子文档经常查询。 |
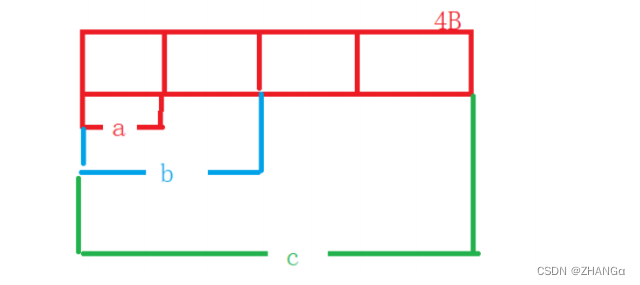
嵌套文档看似只是文档内有一个集合字段,但内部存储完全不是。以下图嵌套文档为例;留言1,留言2,留言3在内部实际存储为4个独立文档。
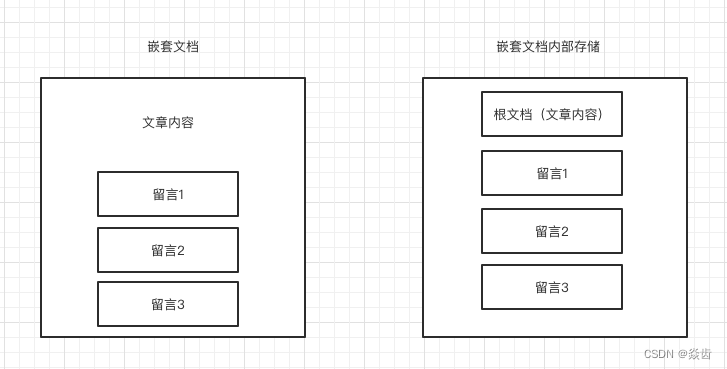
同时,嵌套文档的字段类型需要设置为nested。设置成nested后就不能被直接查询了,需要使用nested查询。
总结来说:
1.普通子对象默认实现了一对多的关系,会损失子对象的边界,子对象属性的关联性也会丧失。
2.嵌套(nested)对象可以解决普通子对象存在的问题,但是它有两个缺点:一是更新文档的时候要全部更新,另外就是不支持子文档从属多个主文档的场景。
3.父子文档能解决前面两个存在的问题,但是它适用于写多读少的场景(查询效率较慢)。
关于nested更多其他语法,参见:
干货 | Elasticsearch Nested类型深入详解_es nest类型-CSDN博客