深度学习是基于人工神经网络的机器学习的一个分支。它能够学习数据中的复杂模式和关系。在深度学习中,我们不需要显式地对所有内容进行编程。近年来,由于处理能力的进步和大型数据集的可用性,它变得越来越流行。因为它基于人工神经网络(ANN),也称为深度神经网络(DNN)。这些神经网络的灵感来自于人脑生物神经元的结构和功能,它们旨在从大量数据中学习。
-
深度学习是机器学习的一个子领域,涉及使用神经网络来建模和解决复杂问题。神经网络是根据人脑的结构和功能建模的,由处理和转换数据的互连节点层组成。
-
深度学习的关键特征是使用具有多层互连节点的深度神经网络。这些网络可以通过发现数据中的分层模式和特征来学习数据的复杂表示。深度学习算法可以自动从数据中学习和改进,无需手动进行特征工程。
-
深度学习在图像识别、自然语言处理、语音识别和推荐系统等各个领域取得了巨大的成功。一些流行的深度学习架构包括卷积神经网络 (CNN)、循环神经网络 (RNN) 和深度置信网络 (DBN)。
-
训练深度神经网络通常需要大量数据和计算资源。然而,云计算的出现以及图形处理单元 (GPU) 等专用硬件的发展使得训练深度神经网络变得更加容易。
总之,深度学习是机器学习的一个子领域,涉及使用深度神经网络来建模和解决复杂问题。深度学习在各个领域都取得了巨大的成功,并且随着更多数据的出现和更强大的计算资源的出现,其使用预计将继续增长。
什么是深度学习?
深度学习是基于人工神经网络架构的机器学习的分支。人工神经网络或 ANN 使用称为神经元的互连节点层,这些节点协同工作来处理输入数据并从输入数据中学习。
在全连接的深度神经网络中,有一个输入层和一个或多个依次连接的隐藏层。每个神经元接收来自前一层神经元或输入层的输入。一个神经元的输出成为网络下一层中其他神经元的输入,这个过程一直持续到最后一层产生网络的输出。神经网络的各层通过一系列非线性变换来变换输入数据,使网络能够学习输入数据的复杂表示。
如今,深度学习由于其在计算机视觉、自然语言处理和强化学习等各种应用中的成功,已成为机器学习中最受欢迎和最引人注目的领域之一。
深度学习可用于有监督、无监督以及强化机器学习。它使用多种方式来处理这些。
-
监督机器学习: 监督机器学习是一种机器学习技术,其中神经网络学习根据标记数据集进行预测或对数据进行分类。在这里,我们输入两个输入特征以及目标变量。神经网络学习根据预测目标与实际目标之间的差异所产生的成本或误差进行预测,这个过程称为反向传播。卷积神经网络、循环神经网络等深度学习算法用于许多监督任务,如图像分类和识别、情感分析、语言翻译等。
-
无监督机器学习: 无监督机器学习是一种机器学习技术,其中神经网络学习发现模式或基于未标记的数据集对数据集进行聚类。这里没有目标变量。而机器必须自行确定数据集中隐藏的模式或关系。自动编码器和生成模型等深度学习算法用于无监督任务,如聚类、降维和异常检测。
-
强化机器学习:强化机器学习是一种机器学习技术,其中代理学习在环境中做出决策以最大化奖励信号。代理通过采取行动并观察所产生的奖励来与环境进行交互。深度学习可用于学习策略或一组行动,以随着时间的推移最大化累积奖励。Deep Q 网络和深度确定性策略梯度 (DDPG) 等深度强化学习算法用于强化机器人和游戏等任务。
人工神经网络
人工神经网络是建立在人类神经元的结构和操作原理之上的。它也被称为神经网络或神经网络。人工神经网络的输入层(即第一层)接收来自外部源的输入,并将其传递到隐藏层(即第二层)。隐藏层中的每个神经元从上一层神经元获取信息,计算加权总和,然后将其传输到下一层神经元。这些连接是加权的,这意味着通过为每个输入赋予不同的权重,可以或多或少地优化前一层输入的影响。然后在训练过程中调整这些权重以增强模型的性能。
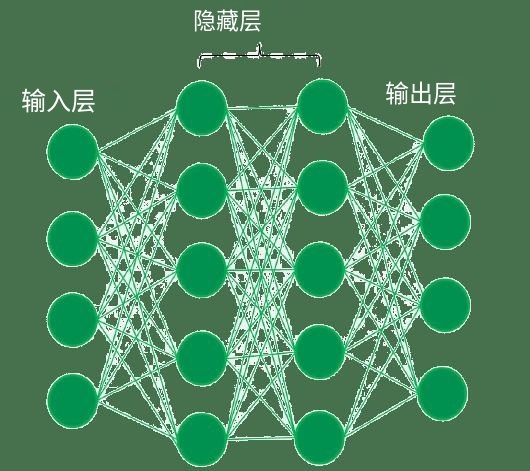
全连接人工神经网络
人工神经元,也称为单元,存在于人工神经网络中。整个人工神经网络就是由这些人工神经元组成的,这些神经元排列成一系列层。神经网络的复杂性将取决于数据集中底层模式的复杂性,无论一个层有十几个单元还是数百万个单元。通常,人工神经网络具有输入层、输出层以及隐藏层。输入层从外界接收神经网络需要分析或学习的数据。
在全连接的人工神经网络中,有一个输入层和一个或多个依次连接的隐藏层。每个神经元接收来自前一层神经元或输入层的输入。一个神经元的输出成为网络下一层中其他神经元的输入,这个过程一直持续到最后一层产生网络的输出。然后,在经过一个或多个隐藏层后,该数据被转换为输出层的有价值的数据。最后,输出层以人工神经网络对输入数据的响应的形式提供输出。
在大部分神经网络中,单元从一层到另一层相互链接。每个链接都有权重,控制一个单元对另一个单元的影响程度。当数据从一个单元移动到另一个单元时,神经网络会越来越多地了解数据,最终从输出层产生输出。
机器学习和深度学习之间的区别:
机器学习和深度学习都是人工智能的子集,但它们之间有许多相似之处和不同之处。
| 机器学习 | 深度学习 |
|---|---|
| 应用统计算法来学习数据集中隐藏的模式和关系。 | 使用人工神经网络架构来学习数据集中隐藏的模式和关系。 |
| 可以处理较小数量的数据集 | 与机器学习相比,需要更大的数据集 |
| 更适合低标签任务。 | 更适合图像处理、自然语言处理等复杂任务。 |
| 训练模型所需的时间更少。 | 需要更多时间来训练模型。 |
| 模型是通过从图像中手动提取相关特征来创建的,以检测图像中的对象。 | 从图像中自动提取相关特征。这是一个端到端的学习过程。 |
| 不太复杂且易于解释结果。 | 更复杂的是,它的工作原理就像结果的黑盒解释并不容易。 |
| 与深度学习相比,它可以在 CPU 上工作或者需要更少的计算能力。 | 它需要具有 GPU 的高性能计算机。 |
神经网络的类型
深度学习模型能够自动从数据中学习特征,这使得它们非常适合图像识别、语音识别和自然语言处理等任务。深度学习中最广泛使用的架构是前馈神经网络、卷积神经网络 (CNN) 和循环神经网络 (RNN)。
前馈神经网络 (FNN)是最简单的 ANN 类型,具有通过网络的线性信息流。FNN 已广泛应用于图像分类、语音识别和自然语言处理等任务。
卷积神经网络 (CNN)专门用于图像和视频识别任务。CNN 能够自动从图像中学习特征,这使得它们非常适合图像分类、对象检测和图像分割等任务。
循环神经网络 (RNN)是一种能够处理顺序数据(例如时间序列和自然语言)的神经网络。RNN 能够维持捕获有关先前输入的信息的内部状态,这使得它们非常适合语音识别、自然语言处理和语言翻译等任务。
深度学习的应用:
深度学习的主要应用可以分为计算机视觉、自然语言处理(NLP)和强化学习。
计算机视觉
在计算机视觉中,深度学习模型可以使机器识别和理解视觉数据。深度学习在计算机视觉中的一些主要应用包括:
-
对象检测和识别:深度学习模型可用于识别和定位图像和视频中的对象,使机器能够执行自动驾驶汽车、监控和机器人等任务。
-
图像分类:深度学习模型可用于将图像分类为动物、植物和建筑物等类别。这用于医学成像、质量控制和图像检索等应用。
-
图像分割:深度学习模型可用于将图像分割成不同的区域,从而可以识别图像中的特定特征。
自然语言处理(NLP)
:
在NLP中, 深度学习模型可以使机器理解并生成人类语言。深度学习在NLP中的一些主要应用包括:
-
自动文本生成——深度学习模型可以学习文本语料库,并且可以使用这些经过训练的模型自动生成摘要、论文等新文本。
-
语言翻译:深度学习模型可以将文本从一种语言翻译成另一种语言,使得与不同语言背景的人进行交流成为可能。
-
情感分析:深度学习模型可以分析一段文本的情感,从而可以确定文本是积极的、消极的还是中性的。这用于客户服务、社交媒体监控和政治分析等应用程序。
-
语音识别:深度学习模型可以识别和转录口语单词,从而可以执行语音到文本转换、语音搜索和语音控制设备等任务。
强化学习:
在强化学习中,深度学习作为训练代理在环境中采取行动以最大化奖励。深度学习在强化学习中的一些主要应用包括:
-
玩游戏:深度强化学习模型已经能够在围棋、国际象棋和 Atari 等游戏中击败人类专家。
-
机器人技术:深度强化学习模型可用于训练机器人执行复杂的任务,例如抓取物体、导航和操纵。
-
控制系统:深度强化学习模型可用于控制电网、交通管理和供应链优化等复杂系统。
深度学习的挑战
深度学习在各个领域取得了重大进展,但仍然存在一些挑战需要解决。以下是深度学习的一些主要挑战:
-
数据可用性:需要大量数据才能学习。对于使用深度学习来说,收集尽可能多的数据进行训练是一个大问题。
-
计算资源:训练深度学习模型的计算成本很高,因为它需要 GPU 和 TPU 等专用硬件。
-
耗时:在处理顺序数据时,取决于计算资源,甚至可能需要几天或几个月的时间。
-
可解释性:深度学习模型很复杂,它的工作原理就像一个黑匣子。解释结果非常困难。
-
过度拟合:当模型经过一次又一次的训练时,它对于训练数据变得过于专业,导致过度拟合并且在新数据上表现不佳。
深度学习的优点:
-
高准确度:深度学习算法可以在图像识别和自然语言处理等各种任务中实现最先进的性能。
-
自动化特征工程:深度学习算法可以自动从数据中发现和学习相关特征,无需手动进行特征工程。
-
可扩展性:深度学习模型可以扩展以处理大型且复杂的数据集,并且可以从大量数据中学习。
-
灵活性:深度学习模型可以应用于广泛的任务,可以处理各种类型的数据,例如图像、文本和语音。
-
持续改进:随着更多数据的可用,深度学习模型可以不断提高其性能。
深度学习的缺点:
-
高计算要求:深度学习模型需要大量数据和计算资源来训练和优化。
-
需要大量标记数据:深度学习模型通常需要大量标记数据进行训练,获取这些数据可能既昂贵又耗时。
-
可解释性:深度学习模型很难解释,因此很难理解它们如何做出决策。
过度拟合:深度学习模型有时可能会过度拟合训练数据,导致新数据和未见数据的性能不佳。 -
黑匣子性质:深度学习模型通常被视为黑匣子,因此很难理解它们如何工作以及如何得出预测。
综上所述,虽然深度学习具有许多优点,包括高精度和可扩展性,但它也有一些缺点,例如计算要求高、需要大量标记数据以及可解释性挑战。在决定是否使用深度学习来完成特定任务时,需要仔细考虑这些限制。