文章目录
- 前言
- 一、数据集介绍
- 二、预测房价代码
- 1.引入库
- 2.数据
- 3.梯度下降
- 总结
前言
梯度下降算法学习。
一、数据集介绍
波士顿房价数据集:波士顿房价数据集,用于线性回归预测
二、预测房价代码
1.引入库
from sklearn.linear_model import LinearRegression as LR
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston as boston
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
import numpy as np
from sklearn.metrics import mean_squared_error
2.数据
def preprocess():
# get the dataset of boston
X = boston().data
y = boston().target
name_data = boston().feature_names
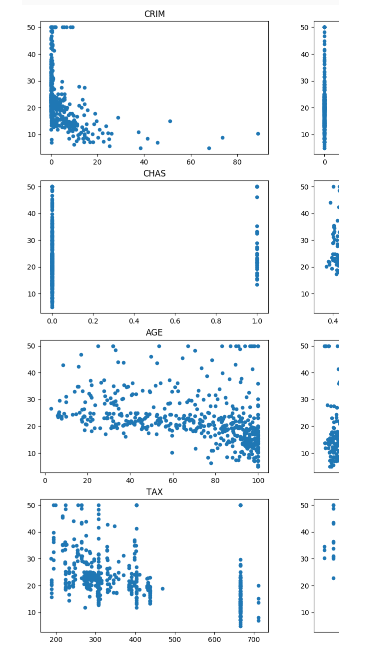
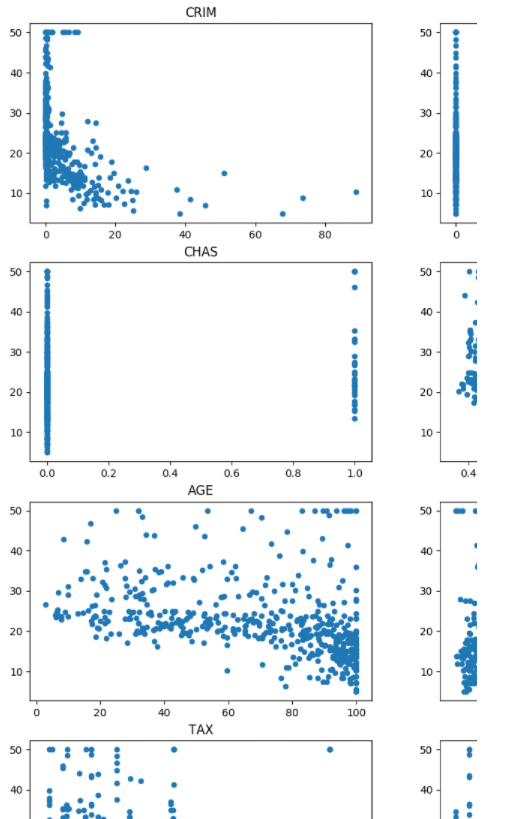
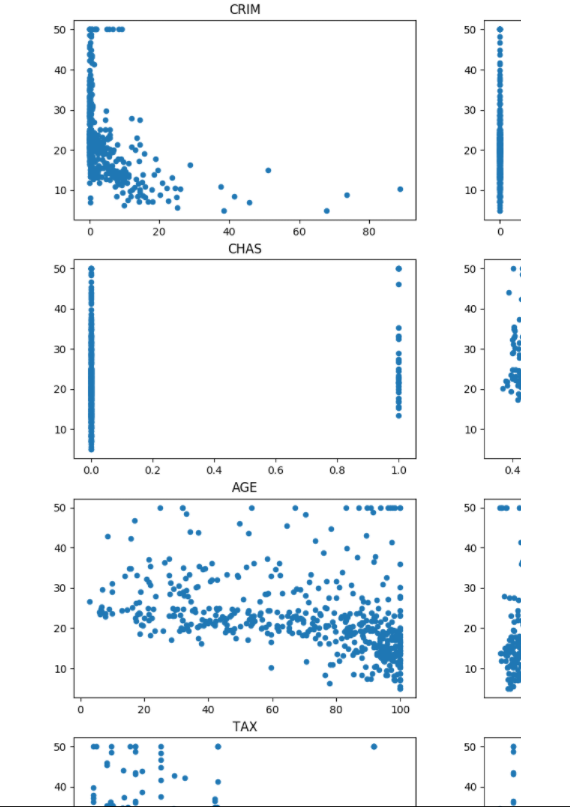
# draw the figure of relationship between feature and price
plt.figure(figsize=(20,20))
for i in range(len(X[0])):
plt.subplot(5, 3, i + 1)
plt.scatter(X[:, i], y, s=20)
plt.title(name_data[i])
plt.show()
# 删除相关性较低的特征
# X = np.delete(X, [0, 1, 3, 4, 6, 7, 8, 9, 11], axis=1)
# normalization
for i in range(len(X[0])):
X[:, i] = (X[:, i] - X[:, i].min()) / (X[:, i].max() - X[:, i].min())
# split into test and train
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, y, test_size=0.3, random_state=10)
return Xtrain, Xtest, Ytrain, Ytest, X
def lr(Xtrain, Xtest, Ytrain, Ytest, if_figure):
# use LinearRegression
reg = LR().fit(Xtrain, Ytrain)
y_pred = reg.predict(Xtest)
loss = mean_squared_error(Ytest, y_pred)
print("*************LR*****************")
print("w\t= {}".format(reg.coef_))
print("b\t= {:.4f}".format(reg.intercept_))
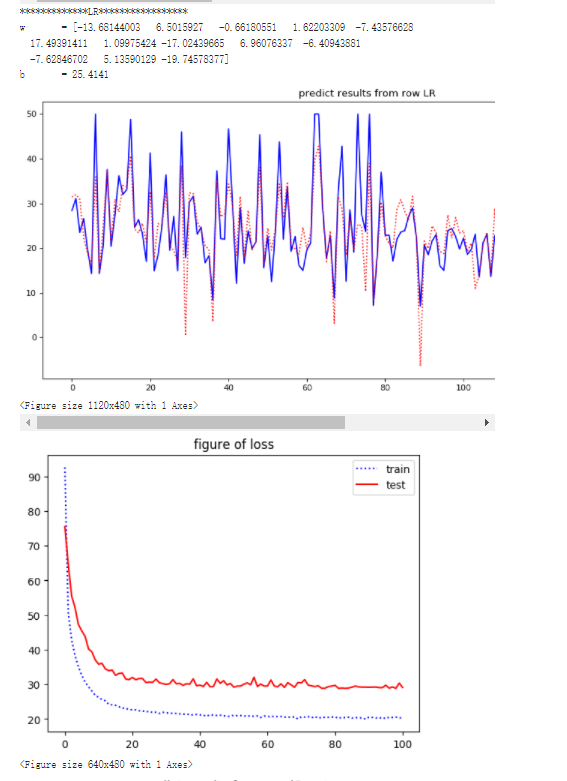
# draw the figure of predict results
if if_figure:
plt.figure(figsize = (14,6),dpi = 80)
plt.plot(range(len(Ytest)), Ytest, c="blue", label="real")
plt.plot(range(len(y_pred)), y_pred, c="red", linestyle=':', label="predict")
plt.title("predict results from row LR")
plt.legend()
plt.show()
return loss
3.梯度下降
def gradDescnet(Xtrain, Xtest, Ytrain, Ytest, X, if_figure, rate):
# 梯度下降
def grad(y, yp, X):
grad_w = (y - yp) * (-X)
grad_b = (y - yp) * (-1)
return [grad_w, grad_b]
# 设置训练参数
epoch_train = 100
learning_rate = rate
w = np.random.normal(0.0, 1.0, (1, len(X[0])))
b = 0.0
loss_train = []
loss_test = []
for epoch in range(epoch_train + 1):
loss1 = 0
for i in range(len(Xtrain)):
yp = w.dot(Xtrain[i]) + b
# 计算损失
err = Ytrain[i] - yp
loss1 += err ** 2
# 迭代更新 w 和 b
gw = grad(Ytrain[i], yp, Xtrain[i])[0]
gb = grad(Ytrain[i], yp, Xtrain[i])[1]
w = w - learning_rate * gw
b = b - learning_rate * gb
# 记录损失
loss_train.append(loss1 / len(Xtrain))
loss11 = 0
for i in range(len(Xtest)):
yp2 = w.dot(Xtest[i]) + b
err2 = Ytest[i] - yp2
loss11 += err2 ** 2
# 记录损失
loss_test.append(loss11 / len(Xtest))
# shuffle the data
Xtrain, Ytrain = shuffle(Xtrain, Ytrain)
# draw the figure of loss
if if_figure:
plt.figure()
plt.title("figure of loss")
plt.plot(range(len(loss_train)), loss_train, c="blue", linestyle=":", label="train")
plt.plot(range(len(loss_test)), loss_test, c="red", label="test")
plt.legend()
plt.show()
# draw figure of predict results
if if_figure:
Predict_value = []
for i in range(len(Xtest)):
Predict_value.append(w.dot(Xtest[i]) + b)
plt.figure()
plt.title("predict results from gradScent")
plt.plot(range(len(Xtest)), Ytest, c="blue", label="real")
plt.plot(range(len(Xtest)), Predict_value, c="red", linestyle=':', label="predict")
plt.legend()
plt.show()
return loss_test[-1], w, b
def test():
if_figure = True
Xtrain, Xtest, Ytrain, Ytest, X = preprocess()
loss_lr = lr(Xtrain, Xtest, Ytrain, Ytest, if_figure)
loss_gd, w, b = gradDescnet(Xtrain, Xtest, Ytrain, Ytest, X, if_figure, 0.01)
print("*************GD*****************")
print("w\t: {}".format(w))
print("b\t: {}".format(b))
print("************loss****************")
print("lr\t: %.4f" % loss_lr)
print("gd\t: %.4f" % loss_gd)
def searchRate():
if_figure = False
Xtrain, Xtest, Ytrain, Ytest, X = preprocess()
loss_grad = []
w_grad = []
b_grad = []
rates = list(np.arange(0.001, 0.05, 0.001))
epoch = 1
for rate in rates:
loss, w, b = gradDescnet(Xtrain, Xtest, Ytrain, Ytest, X, if_figure, rate)
loss_grad.append(loss[0])
w_grad.append(w)
b_grad.append(b)
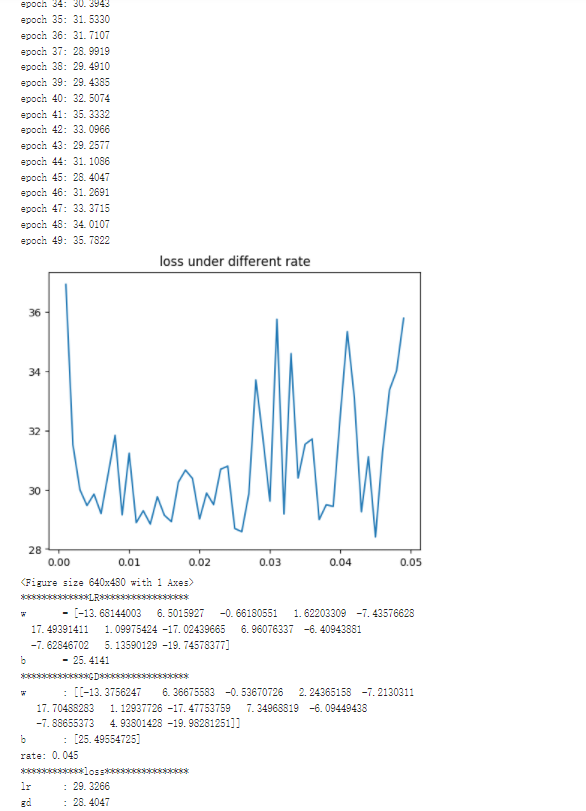
print("epoch %d: %.4f" % (epoch, loss_grad[-1]))
epoch += 1
plt.figure()
plt.plot(rates, loss_grad)
plt.title("loss under different rate")
plt.show()
loss_grad_min = min(loss_grad)
position = loss_grad.index(loss_grad_min)
w = w_grad[position]
b = b_grad[position]
rate = rates[position]
loss_lr = lr(Xtrain, Xtest, Ytrain, Ytest, if_figure)
print("*************GD*****************")
print("w\t: {}".format(w))
print("b\t: {}".format(b))
print("rate: %.3f" % rate)
print("************loss****************")
print("lr\t: %.4f" % loss_lr)
print("gd\t: %.4f" % loss_grad_min)
data = boston
Xtrain, Xtest, Ytrain, Ytest, X = preprocess()
lr(Xtrain, Xtest, Ytrain, Ytest,True)

test()
searchRate()
总结
通过此次学习,对梯度下降算法有了更深的认识。






![[动态规划] (十一) 简单多状态 LeetCode 面试题17.16.按摩师 和 198.打家劫舍](https://img-blog.csdnimg.cn/img_convert/9ff88a675db2d5d9a0f0043b1a9c35af.png)