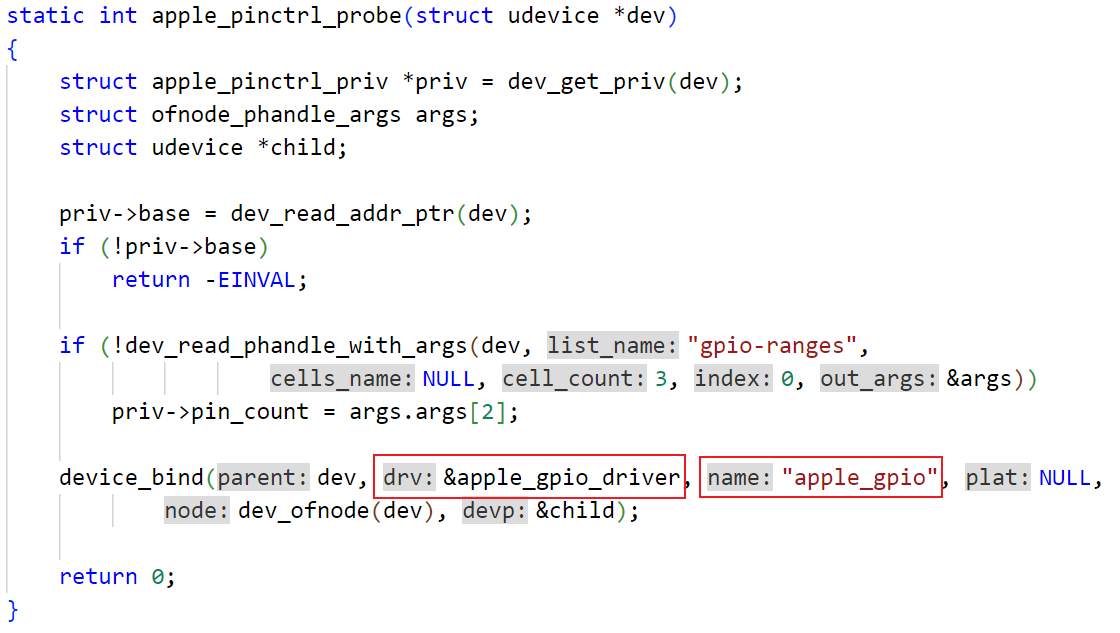
GAN:少样本学习
任何深度学习模型要获得较好结果往往需要大量的训练数据。但是,高质量的数据往往是稀缺的和昂贵的。好消息是,自从GANs问世以来,这个问题得到妥善解决,我们可以通过GAN来生成高质量的合成数据样本帮助模型训练。通过设计一个特殊的DCGAN架构,在只有一个非常小的数据集上训练分类器,仍然可以实现良好的分类效果。
模型架构:
数据集
FashionMNIST 是一个替代 MNIST 手写数字集的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。
import os
import gzip
import numpy as np
def load_mnist(path, kind='train'):
"""Load MNIST data from `path`"""
labels_path = os.path.join(path, '%s-labels-idx1-ubyte.gz'% kind)
images_path = os.path.join(path, '%s-images-idx3-ubyte.gz'% kind)
with gzip.open(labels_path, 'rb') as lbpath:
labels = np.frombuffer(lbpath.read(), dtype=np.uint8,
offset=8)
with gzip.open(images_path, 'rb') as imgpath:
images = np.frombuffer(imgpath.read(), dtype=np.uint8,
offset=16).reshape(len(labels), 784)
return images, labels
数据采样
- 从每个类别中随机采样相同数量的样本,构造小样本数据集。
def sampling_subset(feats, labels, n_samples=1280, n_classes=10):
samples_per_class = int(n_samples / n_classes)
X = []
y = []
for i in range(n_classes):
class_feats = feats[labels == i]
class_sample_idx = np.random.randint(low=0, high=len(class_feats), size=samples_per_class)
X.extend([class_feats[j] for j in class_sample_idx])
y.extend([i] * samples_per_class)
return np.array(X), np.array(y)
- 分类器训练数据批采样
def batch_sampling_for_classification(feats, labels, n_samples):
sample_idx = np.random.randint(low=0, high=feats.shape[0], size=n_samples)
X = np.array([feats[i] for i in sample_idx])
y = np.array([labels[i] for i in sample_idx])
return X, y
- 判别器训练数据批采样
def batch_sampling_for_discrimination(feats, n_samples):
sample_idx = np.random.randint(low=0,
high=feats.shape[0],
size=n_samples)
X = np.array([feats[i] for i in sample_idx])
y = np.ones((n_samples, 1))
return X, y
生成器
import os
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import BinaryCrossentropy
from tensorflow.keras.layers import Conv2D,LeakyReLU,Input,BatchNormalization,Flatten,Conv2DTranspose
from tensorflow.keras.layers import Activation, Dense,Lambda,Dropout,Softmax,Reshape
from tqdm import tqdm
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
def create_generator(latent_size):
inputs = Input(shape=(latent_size,))
x = Dense(units=128 * 7 * 7)(inputs)
x = LeakyReLU(alpha=0.2)(x)
x = Reshape((7, 7, 128))(x)
for _ in range(2):
x = Conv2DTranspose(filters=128, kernel_size=(4, 4),strides=2, padding='same')(x)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2D(filters=1, kernel_size=(7, 7), padding='same')(x)
output = Activation('tanh')(x)
return Model(inputs, output)
分类器和判别器
分类器和鉴别器共享相同的特征提取层,不同只在最终输出层,这意味着,当每次分类器训练一批标记数据时,以及当鉴别器训练真假图像时,这些共享的权值都会得到更新。
def create_classificator_discriminators(input_shape, num_classes=10):
def custom_activation(x):
log_exp_sum = K.sum(K.exp(x), axis=-1, keepdims=True)
return log_exp_sum / (log_exp_sum + 1.0)
inputs = Input(shape=input_shape)
x = inputs
for _ in range(3):
x = Conv2D(filters=128, kernel_size=(3, 3), strides=2, padding='same')(x)
x = LeakyReLU(alpha=0.2)(x)
x = Flatten()(x)
x = Dropout(rate=0.4)(x)
x = Dense(units=num_classes)(x)
clf_output = Softmax()(x)
clf_model = Model(inputs, clf_output)
dis_output = Lambda(custom_activation)(x)
dis_model = Model(inputs, dis_output)
return clf_model, dis_model
训练模型
clf_model, dis_model = create_classificator_discriminators(input_shape=(28, 28, 1), num_classes=10)
clf_opt = Adam(learning_rate=2e-4, beta_1=0.5)
clf_model.compile(loss='sparse_categorical_crossentropy',optimizer=clf_opt,metrics=['accuracy'])
dis_opt = Adam(learning_rate=2e-4, beta_1=0.5)
dis_model.compile(loss='binary_crossentropy',optimizer=dis_opt)
gen_model = create_generator(latent_size=100)
dis_model.trainable = False
gan_model = Model(gen_model.input, dis_model(gen_model.output))
gan_opt = Adam(learning_rate=2e-4, beta_1=0.5)
gan_model.compile(loss='binary_crossentropy', optimizer=gan_opt)
def generate_fake_samples(model, latent_size, n_samples):
z_input = tf.random.normal((n_samples, latent_size))
images = model.predict(z_input)
y = np.zeros((n_samples, 1))
return images, y
加载数据
test_x, test_y = load_mnist('./SeData/fashion-mnist/',kind='t10k')
train_x, train_y = load_mnist('./SeData/fashion-mnist/',kind='train')
train_x = train_x.reshape((-1, 28, 28, 1))
train_x = (train_x.astype(np.float32) - 127.5)/ 127.5
test_x = test_x.reshape((-1, 28, 28, 1))
test_x = (test_x.astype(np.float32) - 127.5) / 127.5
# 小数据集
sub_x, sub_y = sampling_subset(train_x, train_y)
epochs=20
num_batches=64
batches_per_epoch = 100
num_steps = batches_per_epoch * epochs
num_samples = int(num_batches / 2)
for _ in tqdm(range(num_steps), ncols=60):
real_x, real_y = batch_sampling_for_classification(sub_x, sub_y, num_samples)
clf_model.train_on_batch(real_x, real_y)
real_x, real_y = batch_sampling_for_discrimination(sub_x, num_samples)
dis_model.train_on_batch(real_x, real_y)
fake_x, fake_y = generate_fake_samples(gen_model, latent_size=100, n_samples=num_samples)
dis_model.train_on_batch(fake_x, fake_y)
gen_x = tf.random.normal((num_batches, 100))
gen_y = np.ones((num_batches, 1))
gan_model.train_on_batch(gen_x, gen_y)
100%|███████████████████| 2000/2000 [03:10<00:00, 10.49it/s]
验证模型
- 生成器
- 分类器
import matplotlib.pyplot as plt
gen_x = tf.random.normal((25, 100))
gen_y = gen_model(gen_x, training=False)
plt.figure(figsize=(6, 6))
for i in range(gen_y.shape[0]):
plt.subplot(5, 5, i + 1)
image = gen_y[i, :, :, :] *127.5 + 127.5
image = tf.cast(image, tf.uint8)
plt.imshow(image, cmap='Greys_r')
plt.axis('off')

train_acc = clf_model.evaluate(train_x, train_y)[1]*100
print(f'Train accuracy: {train_acc:.2f}%')
test_acc = clf_model.evaluate(test_x, test_y)[1]*100
print(f'Test accuracy: {test_acc:.2f}%')
1875/1875 [==============================] - 5s 3ms/step - loss: 0.4794 - accuracy: 0.8287
Train accuracy: 82.87%
313/313 [==============================] - 1s 4ms/step - loss: 0.5083 - accuracy: 0.8191
Test accuracy: 81.91%