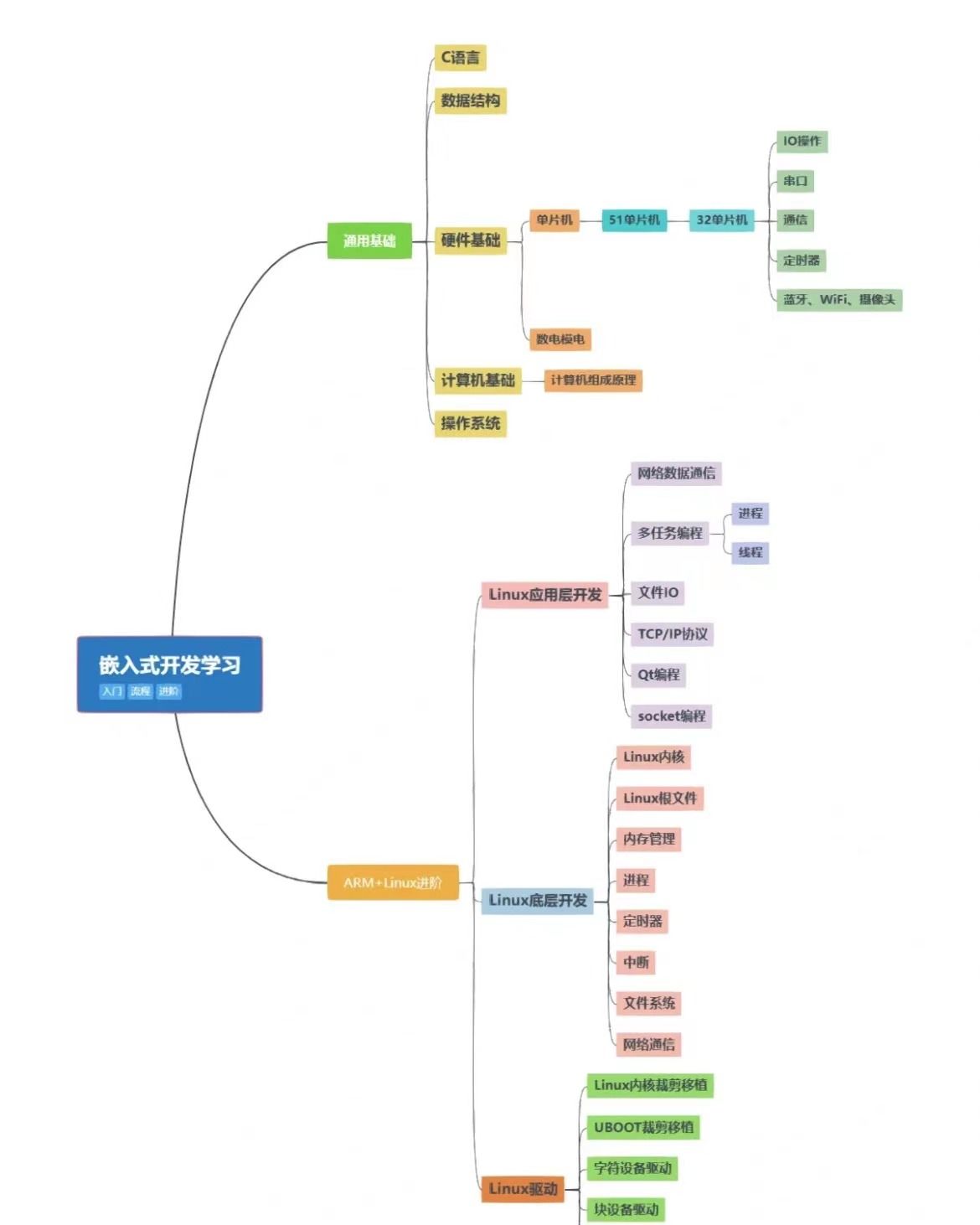
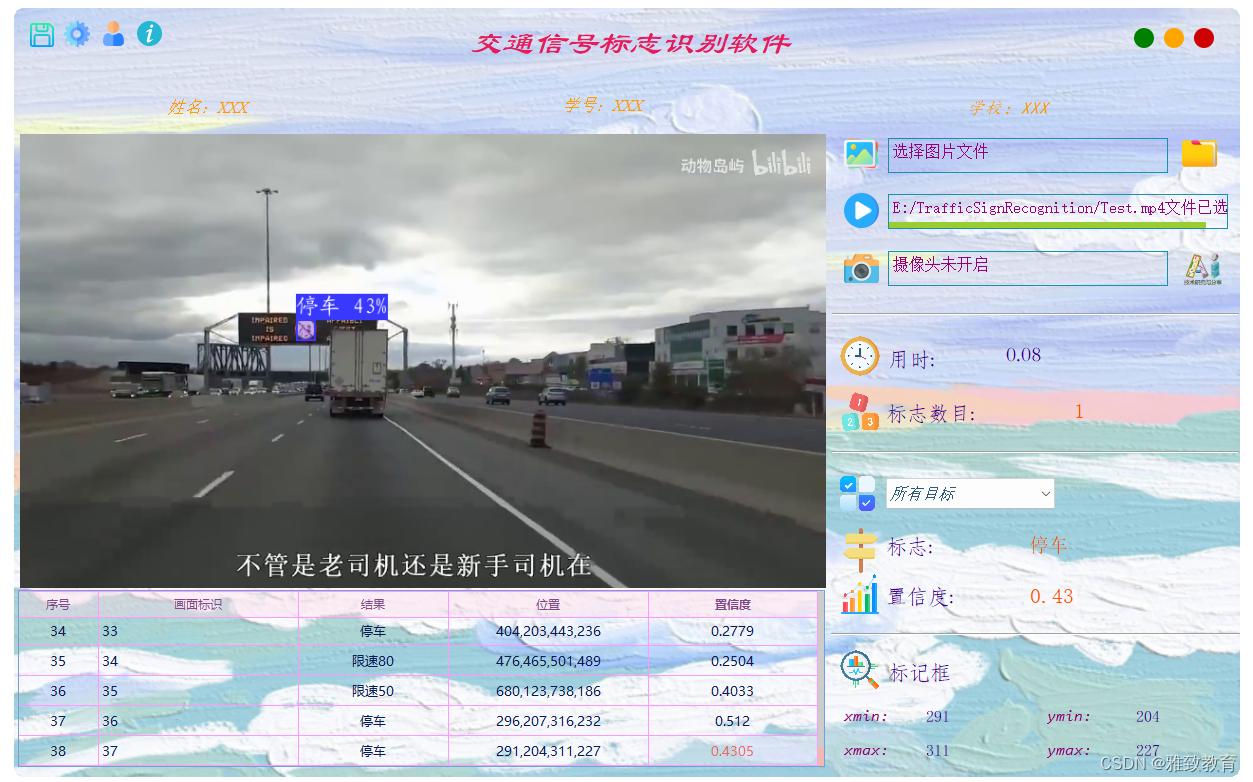
目标检测是计算机视觉的一个任务,它将指定的输入图像或视频帧转换为对象识别、定位和分类的结果。它非常类似于分类,但添加了定位的元素,它可以确定图像中的特定对象所在的位置。主要用于物体识别、跟踪和车牌识别。
Swin Transformer V2
✅标题:Swin Transformer V2: Scaling Up Capacity and Resolution
✅论文地址:https://arxiv.org/pdf/2111.09883v1.pdf(2021年)
✅代码:https://github.com/ChristophReich1996/Swin-Transformer-V2
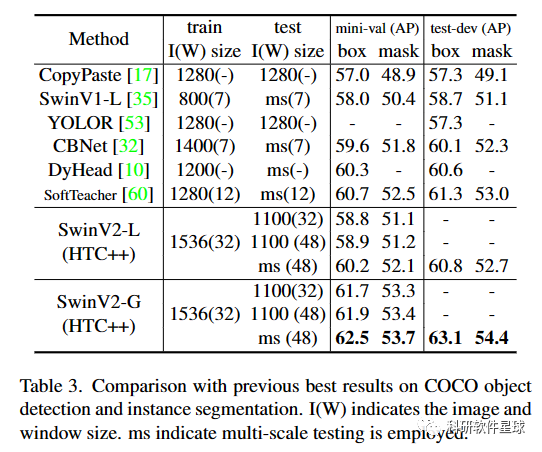
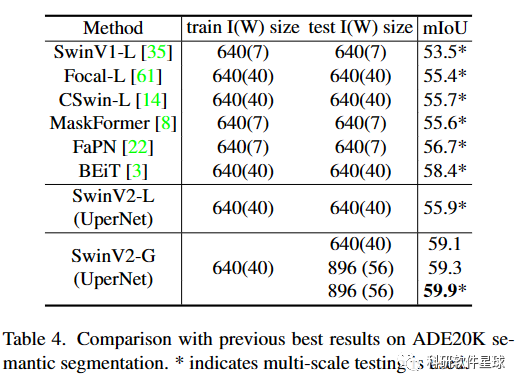
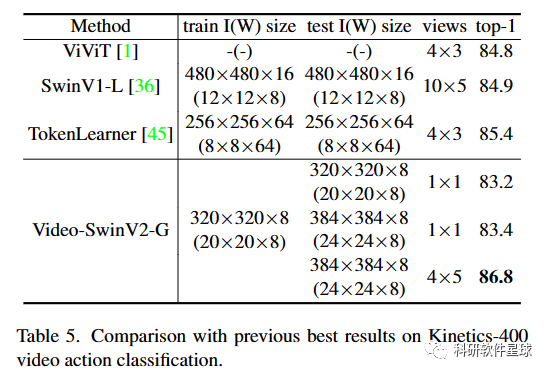
论文中展示了将 Swin Transformer 扩展到 30 亿个参数并使其能够使1536*1536输入尺寸的图像进行训练的sota探讨。通过扩大网络容量和分率,Swin Transformer在四个具有代表性的视觉基准上创造了新记录:ImageNet-V2图像分类的84.0%top-1准确率COCO 对象检测的 63.1/54.4 box/mask mAP,ADE20K 语义分割的 59.9 mIoU, Kinetics-400 视频动作分类的 top-1 准确率为 86.8%。
Swin Transformer V2使用的技术通常为扩大视觉模型,但它没有像 NLP语言模型那样被广泛探索,部分原因在于训练和应用方面,存在以下困难:1)视觉模型经常面临大规模不样本不均衡的问题;2)许多下游视觉任务需要高分辨率图像或滑动窗口,目前尚不清楚如何有效地将低分辨率预训练的模型转换为更高分辨率的模型;3)当图像分辨率很高时,GPU内存消耗也是一个问题。为了解决这些问题,该研究团队提出了几种技术,并通过使用Swin Transformer作为案例研究来说明:1)后归一化技术和缩放余弦注意方法来提高大型视觉模型的稳定性;2)一种对数间隔的连续位置偏差技术,可有效地将在低分辨率图像和窗口上预训练的模型转移到其更高分辨率的对应物上。此外,团队分享了关键实现细节,这些细节可以显著节省GPU 内存消耗,从而使使用常规GPU训练大型视觉模型的方案变得可行。
注:论文原文出自Swin Transformer V2: Scaling Up Capacity and Resolution本文仅用于学术分享,如有侵权,请联系后台作删文处理。
最后:
如果你想要进一步了解更多的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!