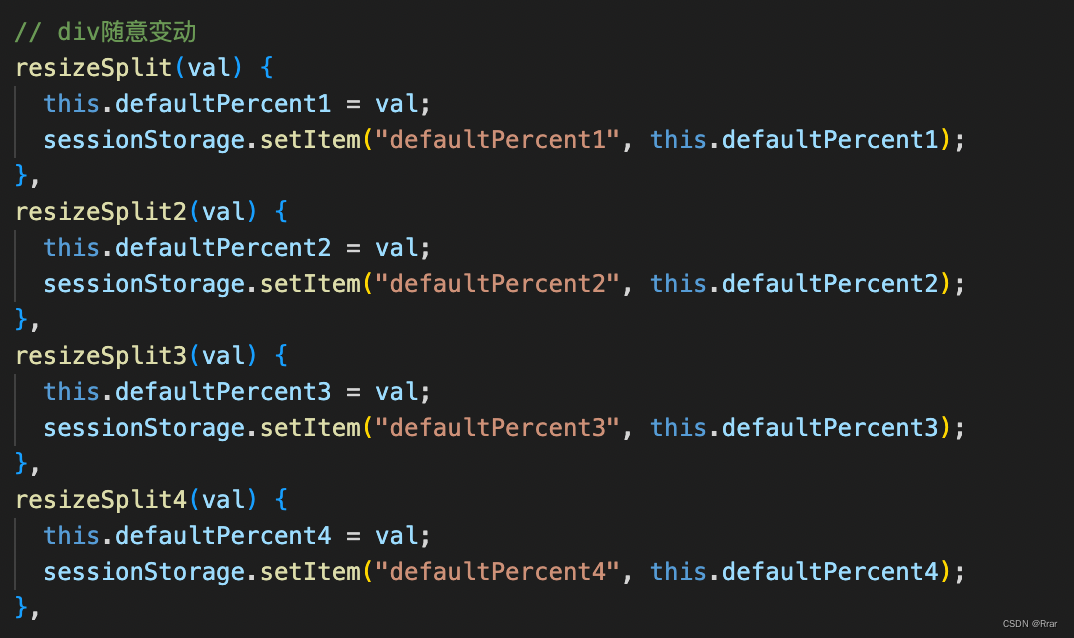
搜索功能已经深入到我们的日常生活中,我们常说“Google一下就知道了”,用户已经开始期望几乎每个应用程序和网站都提供某种类型的搜索功能。随着有效搜索变得越来越相关(双关语),寻找新的方法和体系结构来改进搜索结果对于架构师和开发人员来说至关重要。从基础开始,这篇博文将描述Redis中利用深度学习模型创建的向量Embeddings的人工智能搜索功能。
向量Embedding
什么是向量Embedding?简单地说,向量Embedding是可以表示许多类型数据的数字列表。
向量Embedding非常灵活。音频、视频、文本和图像都可以表示为矢量Embedding。这种特性使得向量Embedding成为数据科学家工具箱中的瑞士军刀。
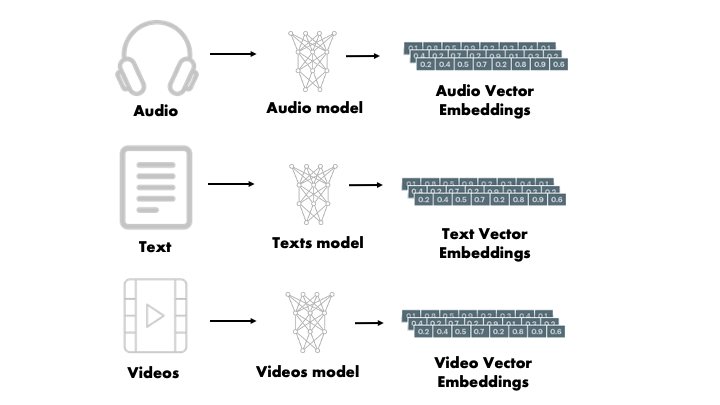
从不同类型的数据创建向量Embedding的过程:音频,文本,视频。
为了解释为什么Embedding提供了这样的实用程序,让我们看一下以前处理文本数据(如表格数据中的分类值)的方法。数据科学家有时会使用one-hot编码等方法将分类特征转换为数值。这些编码将为每种类型的类别创建一个列。值为1表示项目属于该列指定的类别。相反,值为0表示项目不属于该类别。
例如,考虑书籍类型:“小说”、“非小说”和“传记”。每一种体裁都可以编码成一个热向量,然而,这样的向量会非常稀疏,因为书籍通常只属于两个体裁。下图显示了这种编码是如何工作的。注意这里0的数量是1的两倍。对于像图书类型这样的类别,随着更多的类型被添加到数据集中,这种稀疏性将会呈指数级恶化。
稀疏性会给ML模型带来挑战。对于每一种新的类型,编码表示的大小都会增长,因此数据集的计算成本会变得很高。

One-hot(独热)编码示例
对于图书类型,或者任何具有相对较少类别的分类数据,我们可以使用简单的one-hot编码,但是,对于整个英语语言呢?对于这种规模的语料库,这种编码方法将变得不切实际。
进入向量Embedding。
向量Embedding呈现固定大小的表示,不随数据中观测值的数量而增长。由模型创建的结果向量,通常是384个浮点值,比其他编码方法(如one-hot编码)的表示密度要高得多。这意味着在更少的字节中存在更多的信息,因此在计算上的利用成本更低。正如您稍后将读到的,这些密集表示可以用于多种目的,例如反向图像搜索、聊天机器人、问答和推荐系统。
创建向量Embedding
为了理解向量Embedding是如何创建的,对现代深度学习模型的简要介绍是有帮助的。
机器学习模型不使用非结构化数据。为了使模型能够理解文本或图像,我们必须将它们转换为数字表示。在机器学习之前,这样的表示通常是通过Feature Engineering“手工”创建的。
随着深度学习的出现,复杂数据中的非线性特征交互是由模型学习而不是人工设计的。当一个输入遍历深度学习模型时,该输入数据的新表示将以不同的形状和大小创建。每一层通常关注输入的不同方面。深度学习的这一方面,从输入中“自动”生成特征表示,构成了如何创建向量Embedding的基础。
例如,考虑在ImageNet数据集上训练的著名的ResNet模型。ResNet是一种卷积神经网络(CNN),通常用于与图像相关的任务。在这种情况下,ResNet被训练来预测图像中的对象属于1000个类中的哪一个。
在训练过程中,ResNet将捕获图像中存在的特征信息,通过将图像传递给多个卷积层、池化层和完全连接层。这些图层将捕获边缘、线条和角等特征,并将它们分组到传递给下一个图层的“桶”中。由于CNN的空间不变特性,无论边缘或直线出现在图像的哪个位置,这些特征都将始终映射到相同的桶。这些层将通过模型的层变得越来越小,直到一个由1000个浮点值组成的完全连接的层作为输出。每个值代表1000个类中的1个。该值越高,图像中的对象属于该类的概率就越大。
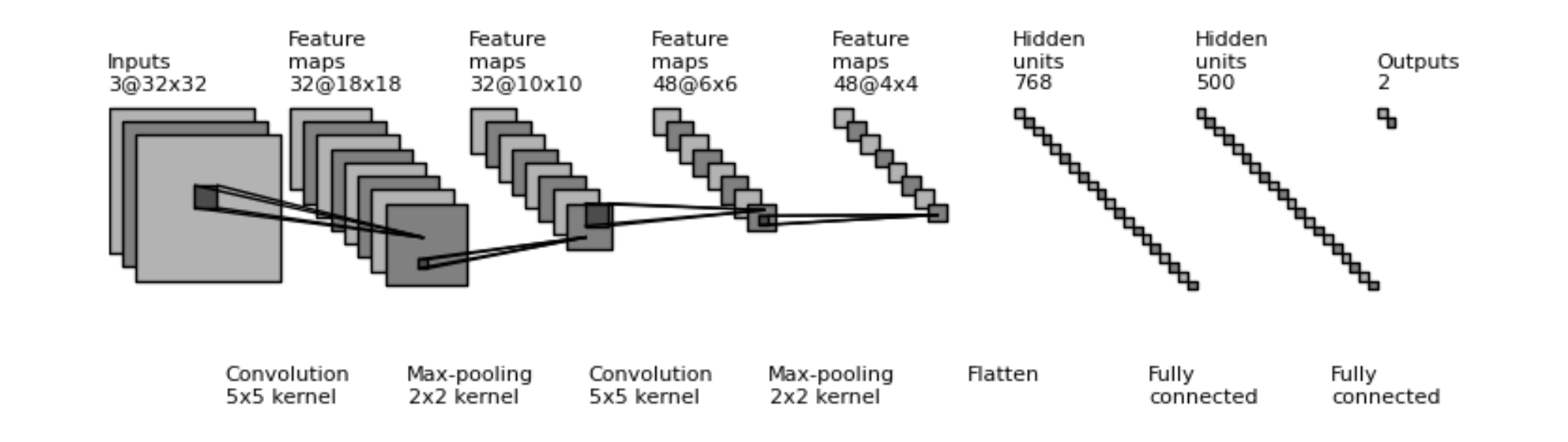
简单卷积神经网络(CNN)示意图
ResNet和其他类似的图像分类模型回答了这个问题:“这个图像中是什么类型的对象?”然而,这些分类在回答诸如“哪些图像与此图像相似?”之类的prompts时用处不大。对于这个问题,我们需要一起比较图像。尽管没有专门针对这项任务进行训练,ResNet仍然很有用,因为它可以捕获图像的密集表示。
简单地说,CNN和其他类似的模型学习有用的数据表示,以执行图像分类等任务。当输入通过模型的各个层时,可以提取这些表示。被提取的层,也称为潜在空间,通常是靠近模型输出的层。在上图中,这可能是包含768或500个隐藏单位的图层。提取的层或潜在空间提供了一个密集的表示,其中包含有关当前特征的信息,这对于视觉相似性搜索等任务在计算上是可行的。
这是向量Embedding。
存在大量的预训练模型,可以很容易地用于创建向量Embedding。Huggingface Model Hub (https://huggingface.co/models)包含许多模型,可以为不同类型的数据创建Embedding。例如,[all-MiniLM-L6-v2模型](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2)是在线托管和运行的,不需要专业知识或安装。
像sentence_transformers这样的包,也来自HuggingFace,为语义相似度搜索、视觉搜索等任务提供了易于使用的模型。要使用这些模型创建Embeddings,只需要几行Python代码:
1 2 3 4 5 6 7 8 9 | from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
sentences = [
"That is a very happy Person",
"That is a Happy Dog",
"Today is a sunny day"
]
embeddings = model.encode(sentences)
|
语义相似度搜索的向量Embedding
语义相似搜索是将文本片段进行比较,以找出包含最相似含义的文本的过程。虽然这对普通人来说似乎很容易,但语言是相当复杂的。将非结构化文本数据提炼成机器学习模型可以理解的格式一直是许多自然语言处理研究人员的研究主题。
向量Embeddings为任何人提供了一种执行语义相似搜索的方法,而不仅仅是NLP研究人员或数据科学家。它们提供了一种有意义的、计算效率高的数字表示,可以通过预先训练的模型“开箱即用”来创建。下面是一个语义相似度的例子,它概述了用上面所示的sentence_transformers库创建的向量Embedding。
让我们看看下面的句子:
- “That is a happy dog(那是一只快乐的狗)”
- “That is a very happy person(那是一个非常幸福的人)”
- “Today is a sunny day(今天是个晴天)”
这些句子中的每一个都可以转换成向量Embedding。下面是一个简化的表示,突出显示了这些示例句子在二维向量空间中相对于彼此的位置。这对于从视觉上衡量我们的Embedding如何有效地表示文本的语义意义非常有用。下文将详细介绍。
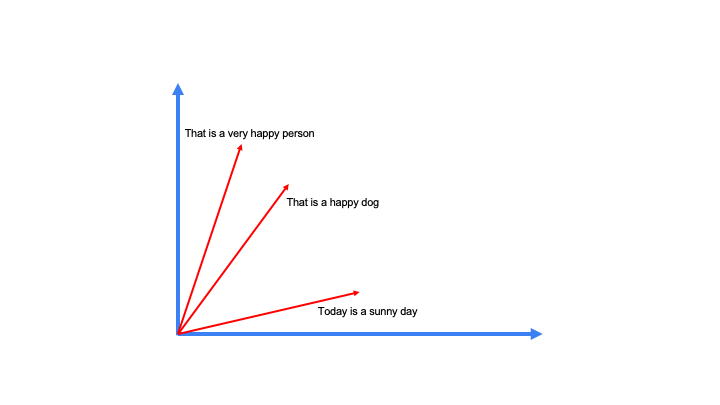
向量Embeddings投影到二维的简化图
假设我们要将这些句子与“那是一个快乐的人”进行比较。首先,我们为查询语句创建向量Embedding。
1 2 3 4 5 | from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# create the vector embedding for the query
query_embedding = model.encode("That is a happy person")
|
接下来,我们需要比较查询向量Embedding和数据集中的向量Embedding之间的距离。
有很多方法可以计算向量之间的距离。当涉及到语义搜索时,每种方法都有自己的优点和缺点,但我们将在另一篇文章中讨论。下面显示了一些常见的距离度量。
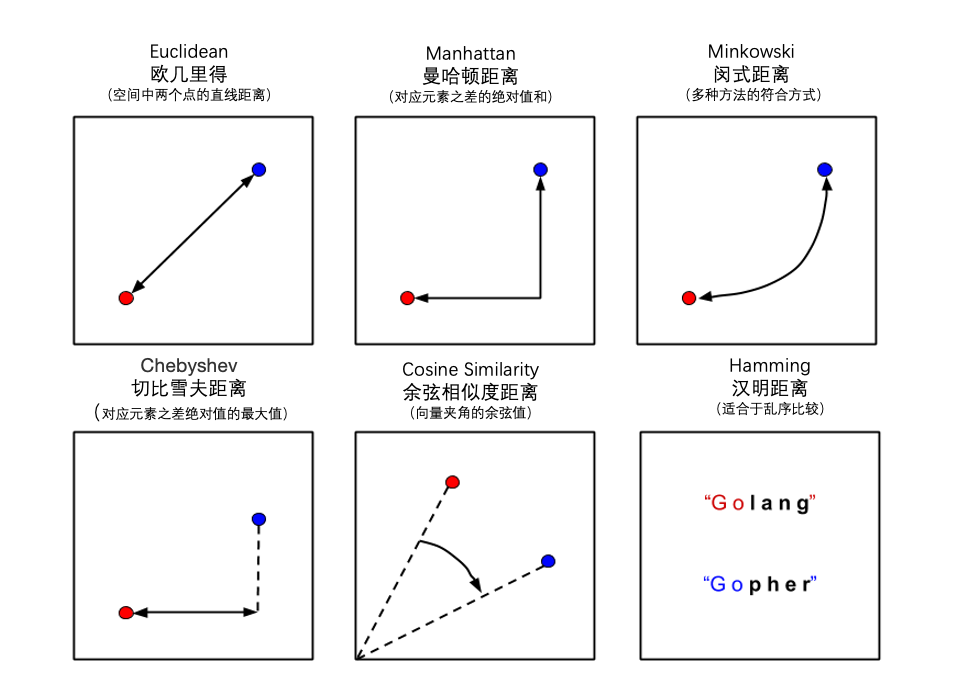
用于计算向量相似度的距离度量。
在这个例子中,我们将使用余弦相似度来度量两个向量的内积空间之间的距离。
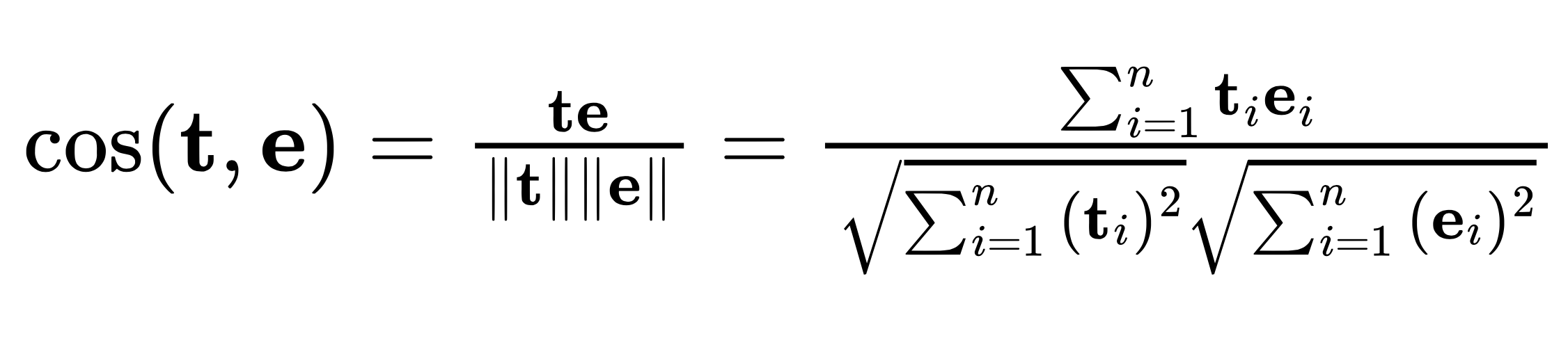
余弦相似度公式
在Python中,这看起来像
1 2 | def cosine_similarity(a, b):
return np.dot(a, b)/(norm(a)*norm(b))
|
在我们的查询向量和上图中的其他三个向量之间运行这个计算,我们可以确定句子之间的相似程度。
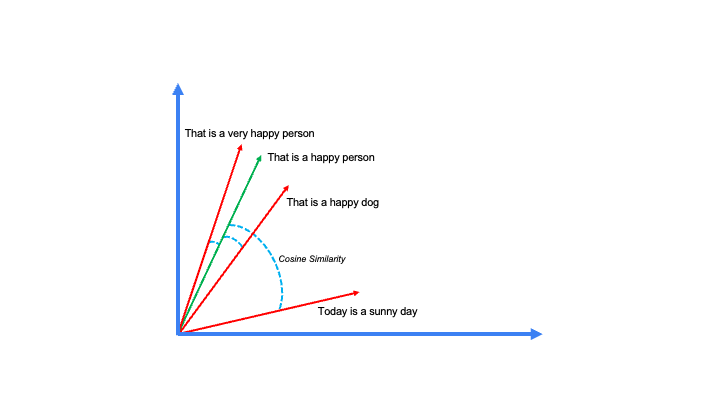
2D图显示了之前从我们的句子中创建的向量Embeddings之间的余弦相似性
你可能已经猜到,“That is a very happy person(那是一个非常幸福的人)”和“That is a happy person(那是一个幸福的人)”是最相似的句子。这个例子只捕获了向量Embeddings的许多可能用例中的一个:语义相似搜索
下面列出了运行整个示例的Python代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | import numpy as np
from numpy.linalg import norm
from sentence_transformers import SentenceTransformer
# Define the model we want to use (it'll download itself)
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
sentences = [
"That is a very happy person",
"That is a happy dog",
"Today is a sunny day"
]
# vector embeddings created from dataset
embeddings = model.encode(sentences)
# query vector embedding
query_embedding = model.encode("That is a happy person")
# define our distance metric
def cosine_similarity(a, b):
return np.dot(a, b)/(norm(a)*norm(b))
# run semantic similarity search
print("Query: That is a happy person")
for e, s in zip(embeddings, sentences):
print(s, " -> similarity score = ",
cosine_similarity(e, query_embedding))
|
在安装NumPy和sentence_transformers之后,运行这个脚本应该会得到以下计算结果
1 2 3 4 5 | >>> Query: That is a happy person >>> That is a very happy person -> similarity score = 0.94291496 >>> That is a happy dog -> similarity score = 0.69457746 >>> Today is a sunny day -> similarity score = 0.25687605 |
该脚本的结果应该与所选模型在HuggingFace inference API上看到的结果一致。

HuggingFace推理API相似度结果
向量Embedding搜索在生产环境中的使用
开发和生产是两个不同的东西,在学习了更多之后,你可能会开始问这样的问题:
- 我把这些向量存储在哪里?
- API应该是什么样子?
- 如何将其与过滤等传统搜索功能结合起来?
幸运的是,开发Redis的好人们决定为你找出这些问题,并将向量相似搜索(VSS)功能构建到现有的reresearch模块中。这基本上把Redis变成了一个低延迟的向量数据库。
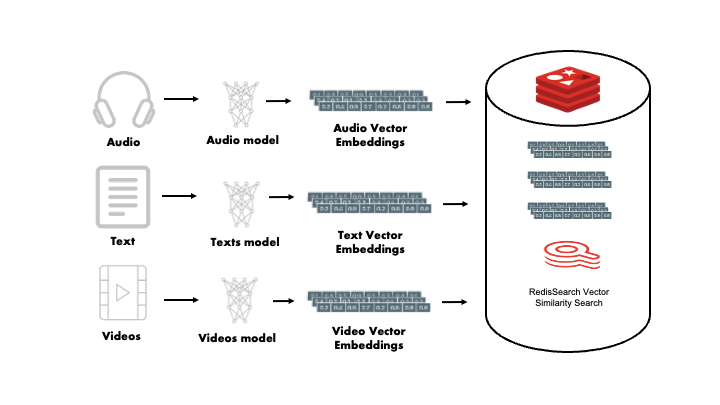
Redis是一个矢量数据库
VSS功能是作为reresearch模块的新功能而构建的。它允许开发人员像在Redis散列中存储任何其他字段一样轻松地存储向量。它提供了在大型向量空间中执行低延迟搜索所需的高级索引和搜索功能,通常分布在许多机器上的向量从数万到数亿不等。
Redis现在支持两种类型的向量索引:
- Flat
- 分级可导航小世界(HNSW)
以及3个距离度量:
LP—— 欧几里得距离IP—— 内积cos—— 余弦相似度(如上图所示)
下面是一个使用redis -py在向量被加载到Redis后创建索引的例子。
1 2 3 4 5 6 7 8 9 10 11 12 | from redis import Redis
from redis.commands.search.field import VectorField, TagField
def create_flat_index(redis_conn: Redis, number_of_vectors: int, distance_metric: str='COSINE'):
image_field = VectorField("img_vector","FLAT", {
"TYPE": "FLOAT32",
"DIM": 512,
"DISTANCE_METRIC": distance_metric,
"INITIAL_CAP": number_of_vectors,
"BLOCK_SIZE": number_of_vectors})
redis_conn.ft().create_index([image_field])
|
索引只需要创建一次,当新的哈希值存储在Redis中时,索引会自动重新索引。在将向量加载到Redis中并创建索引之后,就可以为各种基于相似性的搜索任务形成和执行查询。
索引只需要创建一次,当新的哈希值存储在Redis中时,索引会自动重新索引。在将向量加载到Redis中并创建索引之后,就可以为各种基于相似性的搜索任务形成和执行查询。
更好的是,所有现有的reresearch功能,如文本、标签和基于地理的搜索,都可以与VSS功能协同工作。这被称为“混合查询”。对于混合查询,传统的搜索功能可以用作矢量搜索的预过滤器,这可以帮助限制搜索空间。
上面的索引创建函数(create_flat_index)可以很容易地通过添加新字段(如redis-py中的TagField或TextField)来支持混合查询。
Redis VSS演示
最近,我构建了一个web应用程序来探索这些功能。Fashion Product Finder利用了Redis中新的VSS功能,以及我最喜欢的Redis生态系统的其他部分,如redis-om-python。您可以访问应用程序在这里。
注册使用该应用程序后,您将看到如下所示的页面。
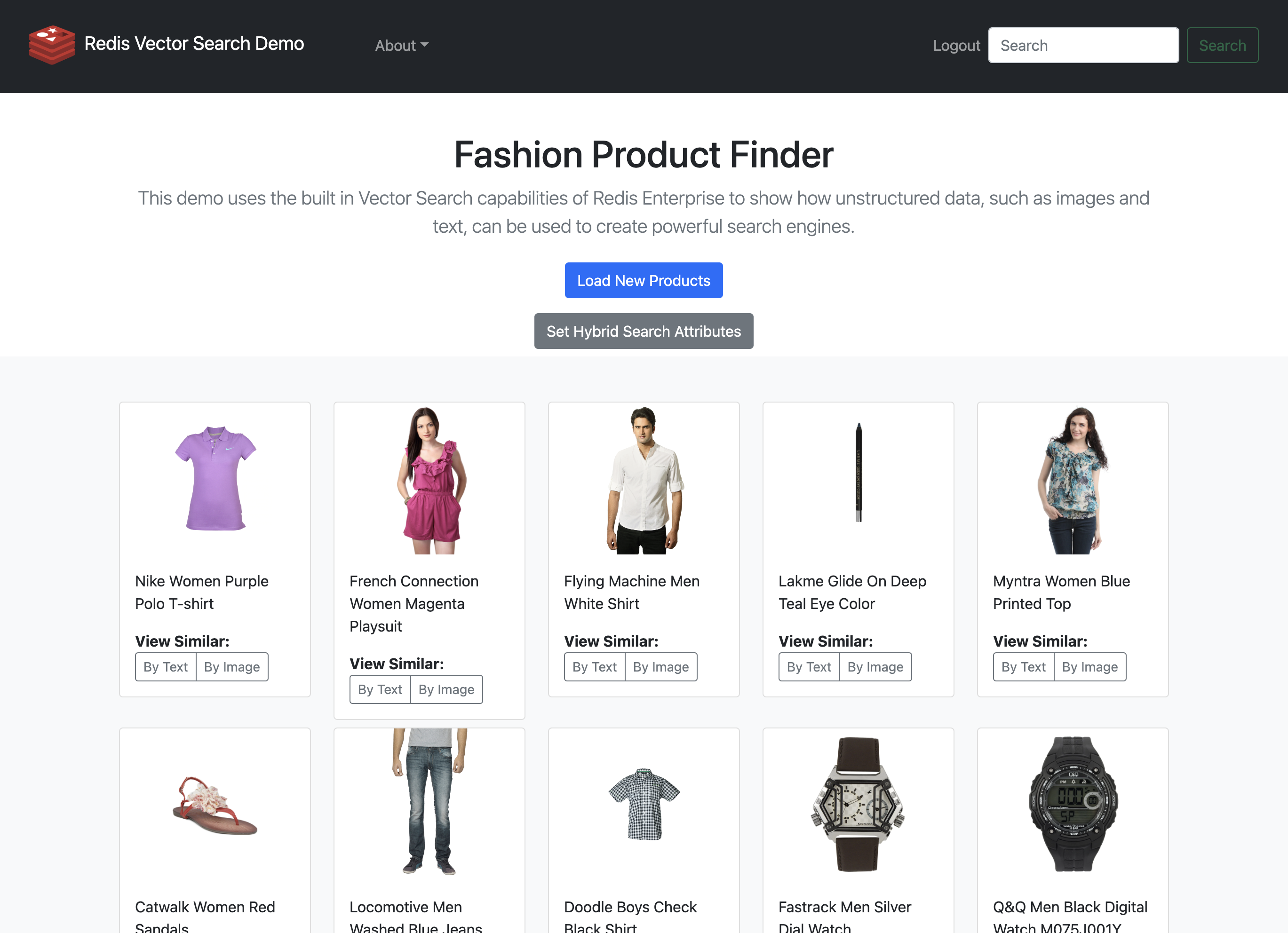
时尚产品查找应用程序,使用由Redis提供的向量相似度搜索
要通过文本表示查询类似的产品,请找到您喜欢的产品并单击by text。同样,要通过视觉向量搜索查询,请单击产品上的by Image按钮。
可以为产品的性别和类别设置混合搜索属性,以便在执行矢量搜索时,返回的项目将通过这些标记进行过滤。下面是选择右下角黑色手表时的视觉向量搜索示例。
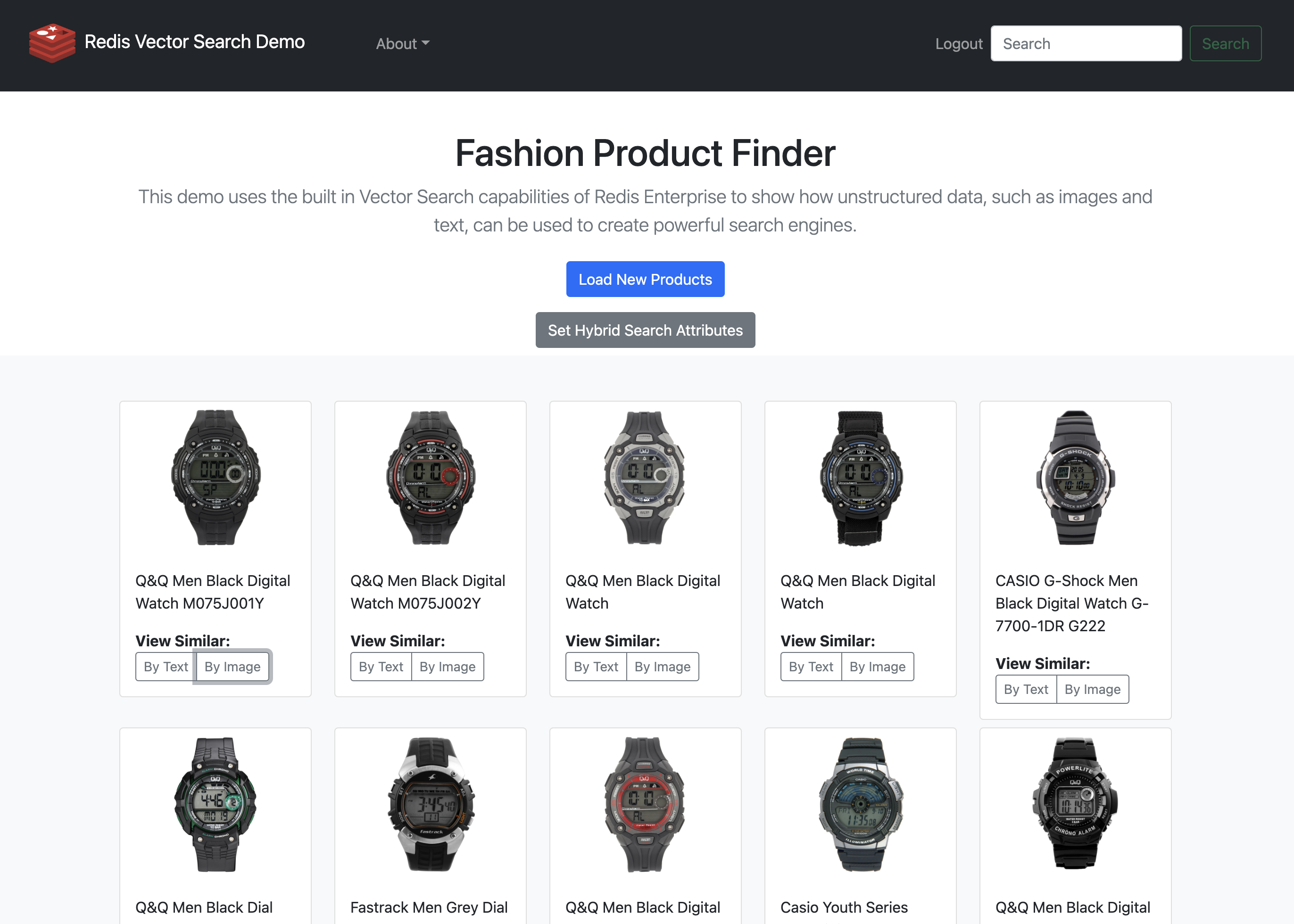
通过图片查询类似手表后的搜索结果为黑色G-Shock手表。
这个演示是一种探索Redis VSS功能的有趣方式,然而,这并不是应用程序中使用的Redis生态系统的唯一组件。事实上,Redis是这个应用程序使用的唯一数据库,用RedisJSON存储产品元数据,用RediSearch存储矢量数据。
您可以查看整个代码库在这里。如果你觉得有用,请点赞和分享!
有关Redis和reresearch模块中VSS的更多信息,您可以查看以下资源:
参考文档
- VSS Documentation
- [Redis Stack Documentation](https://partee.io/2022/08/11/vector-embeddings/Redis Stack docuemntation)