常用模块之re模块(十八)
在Python中需要通过正则表达式对字符串进⾏匹配的时候,可以使⽤⼀个python自带的模块,名字为re模块
我们可以在Python中使用以下的语句,导入re模块:
import re
正则表达式的大致匹配过程是:
- 依次拿出表达式和文本中的字符比较
- 如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败
- 如果表达式中有量词或边界,这个过程会稍微有一些不同
r 的作用
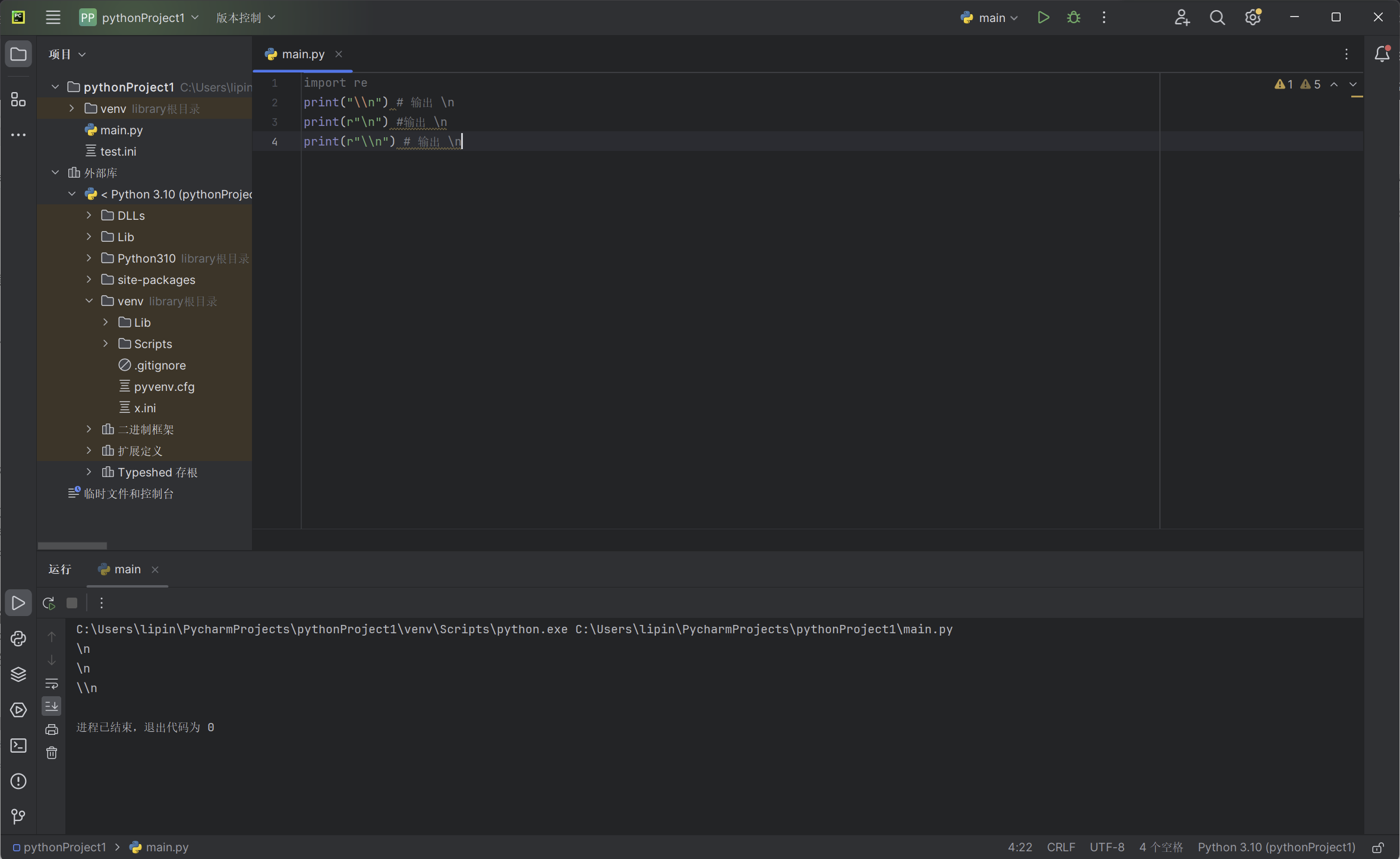
在Python 中字符串的前导 r 代表原始字符串标识符,该字符串中的特殊符号不会被转义,适用于正则表达式中繁杂的特殊符号表示。 因此 r"\n" 表示包含 ‘’ 和 ‘n’ 两个字符的字符串,而 “\n” 则表示只包含一个换行符的字符串。与大多数编程语言相同,正则表达式里使用”\”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”\”,那么使用编程语言表示的正则表达式里将需要两个反斜杠”\”。Python里的原生字符串很好地解决了这个问题,Python中字符串前⾯加上 r 表示原⽣字符串。
print("\\n") # 输出 \n
print(r"\n") #输出 \n
print(r"\\n") # 输出 \\n
以上代码的实列输出:
匹配元字符
| 符 | 功能 | 位置 |
|---|---|---|
| . | 匹配任意1个字符(除了\n) | |
| [ ] | 匹配[ ]中列举的字符 | |
| \d | 匹配数字,即0-9 | 可以写在字符集[…]中 |
| \D | 匹配⾮数字,即不是数字 | 可以写在字符集[…]中 |
| \s | 匹配空⽩,即空格,tab键 | 可以写在字符集[…]中 |
| \S | 匹配⾮空⽩字符 | 可以写在字符集[…]中 |
| \w | 匹配所有单词字符,即a-z、A-Z、0-9、_ | 可以写在字符集[…]中 |
| \W | 匹配⾮单词字符,即空格、换行符、有特殊字符 | 可以写在字符集[…]中 |
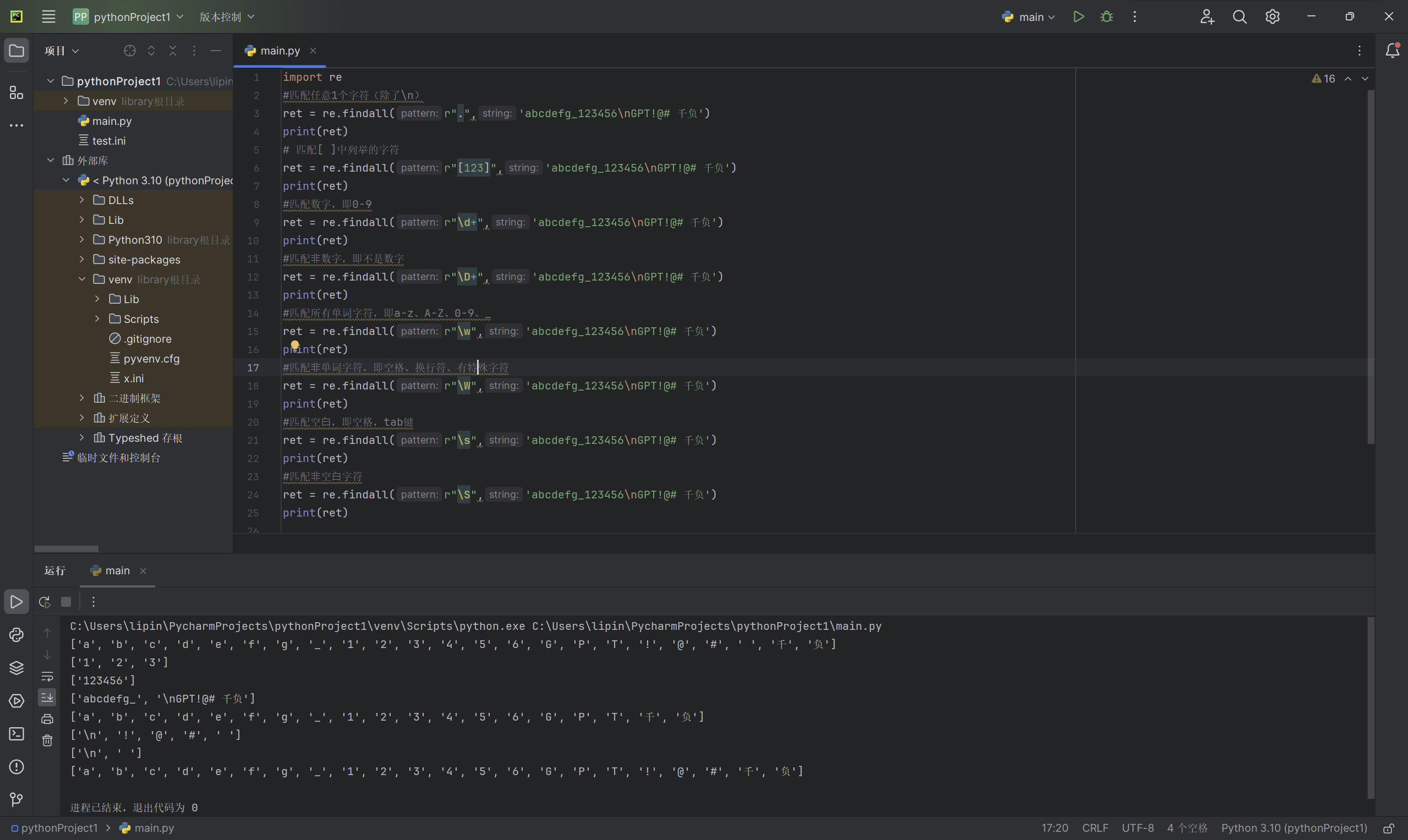
举例:
import re
#匹配任意1个字符(除了\n)
ret = re.findall(r".",'abcdefg_123456\nGPT!@# 千负')
print(ret)
# 匹配[ ]中列举的字符
ret = re.findall(r"[123]",'abcdefg_123456\nGPT!@# 千负')
print(ret)
#匹配数字,即0-9
ret = re.findall(r"\d+",'abcdefg_123456\nGPT!@# 千负')
print(ret)
#匹配⾮数字,即不是数字
ret = re.findall(r"\D+",'abcdefg_123456\nGPT!@# 千负')
print(ret)
#匹配所有单词字符,即a-z、A-Z、0-9、_
ret = re.findall(r"\w",'abcdefg_123456\nGPT!@# 千负')
print(ret)
#匹配⾮单词字符,即空格、换行符、有特殊字符
ret = re.findall(r"\W",'abcdefg_123456\nGPT!@# 千负')
print(ret)
#匹配空⽩,即空格,tab键
ret = re.findall(r"\s",'abcdefg_123456\nGPT!@# 千负')
print(ret)
#匹配⾮空⽩字符
ret = re.findall(r"\S",'abcdefg_123456\nGPT!@# 千负')
print(ret)
代码输出的实列如下:
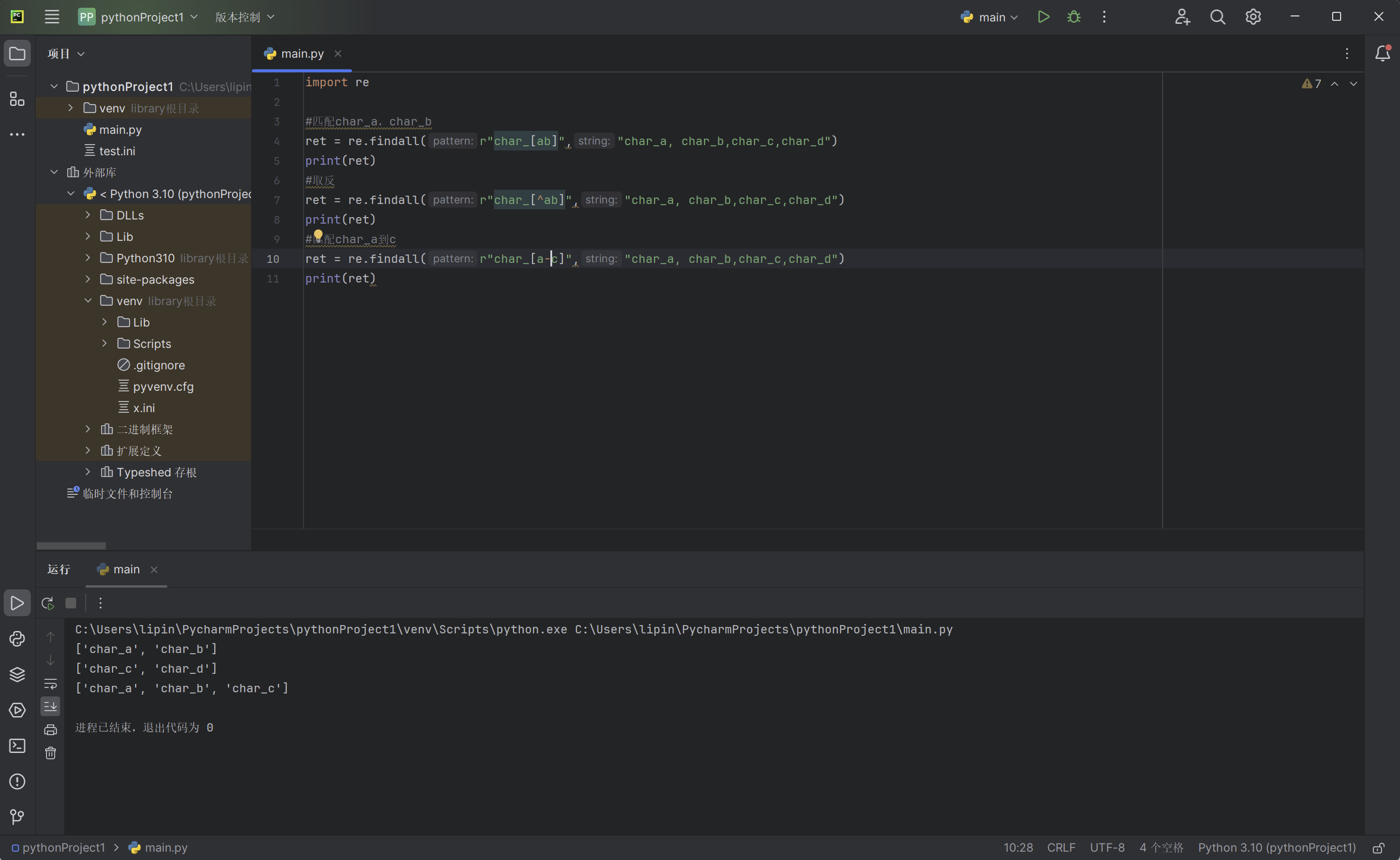
[…]字符集,对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,比如[abc]和[a-c],第一个字符如果是^表示取反。所有特殊字符(比如"]“”-“”^“)在字符集中都失去原来的含义,如要使用可把”]“”-“放在第一个字符,”^"放在非第一个字符。
import re
#匹配char_a,char_b
ret = re.findall(r"char_[ab]","char_a, char_b,char_c,char_d")
print(ret)
#取反
ret = re.findall(r"char_[^ab]","char_a, char_b,char_c,char_d")
print(ret)
#匹配char_a到c
ret = re.findall(r"char_[a-c]","char_a, char_b,char_c,char_d")
print(ret)
以上代码输出的实例:
匹配多个字符
| 字符 | 功能 | 位置 | 表达式实例 | 完整匹配的字符串 |
|---|---|---|---|---|
| * | 匹配前⼀个字符出现0次或者⽆限次,即可有可⽆ | 用在字符或(…)之后 | abc* | abccc |
| + | 匹配前⼀个字符出现1次或者⽆限次,即⾄少有1次 | 用在字符或(…)之后 | abc+ | abccc |
| ? | 匹配前⼀个字符出现1次或者0次,即要么有1次,要么没有 | 用在字符或(…)之后 | abc? | ab,abc |
| {m} | 匹配前⼀个字符出现m次 | 用在字符或(…)之后 | ab{2}c | abbc |
| {m,n} | 匹配前⼀个字符出现从m到n次,若省略m,则匹配0到n次,若省略n,则匹配m到无限次 | 用在字符或(…)之后 | ab{1,2}c | abc,abbc |
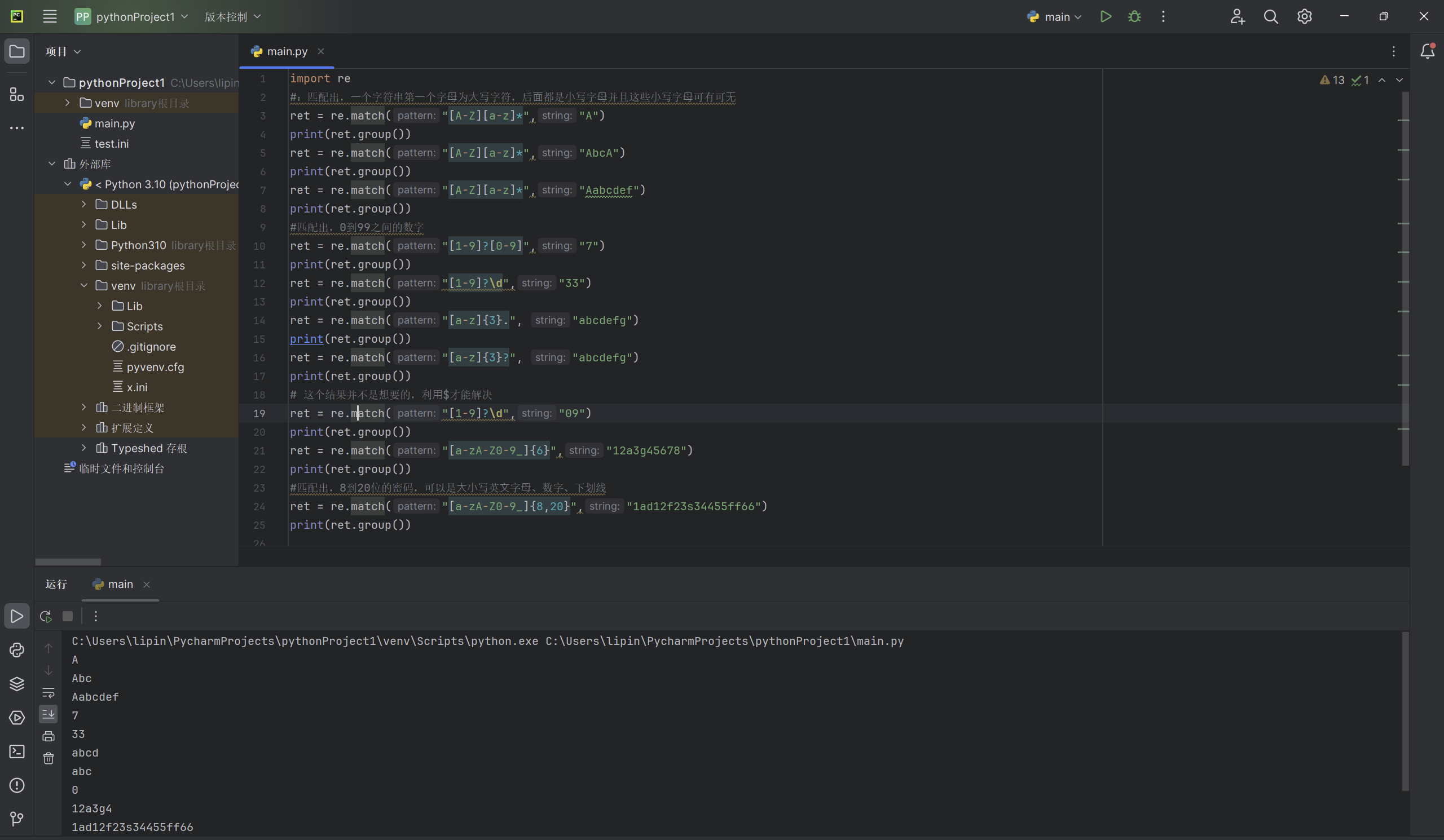
实列:
import re
#:匹配出,⼀个字符串第⼀个字⺟为⼤写字符,后⾯都是⼩写字⺟并且这些⼩写字⺟可有可⽆
ret = re.match("[A-Z][a-z]*","A")
print(ret.group())
ret = re.match("[A-Z][a-z]*","AbcA")
print(ret.group())
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
#匹配出,0到99之间的数字
ret = re.match("[1-9]?[0-9]","7")
print(ret.group())
ret = re.match("[1-9]?\d","33")
print(ret.group())
ret = re.match("[a-z]{3}.", "abcdefg")
print(ret.group())
ret = re.match("[a-z]{3}?", "abcdefg")
print(ret.group())
# 这个结果并不是想要的,利⽤$才能解决
ret = re.match("[1-9]?\d","09")
print(ret.group())
ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678")
print(ret.group())
#匹配出,8到20位的密码,可以是⼤⼩写英⽂字⺟、数字、下划线
ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")
print(ret.group())
以上代码输出的实例:
re.match()函数
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。匹配成功re.match方法返回一个匹配的对象。
语法:re.match(pattern, string, flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| lags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
如果上⼀步匹配到数据的话,可以使⽤group⽅法来提取数据。以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
group()用来提出分组截获的字符串,()用来分组,group() 同group(0)就是匹配正则表达式整体结果,group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。没有匹配成功的,re.search()返回None。
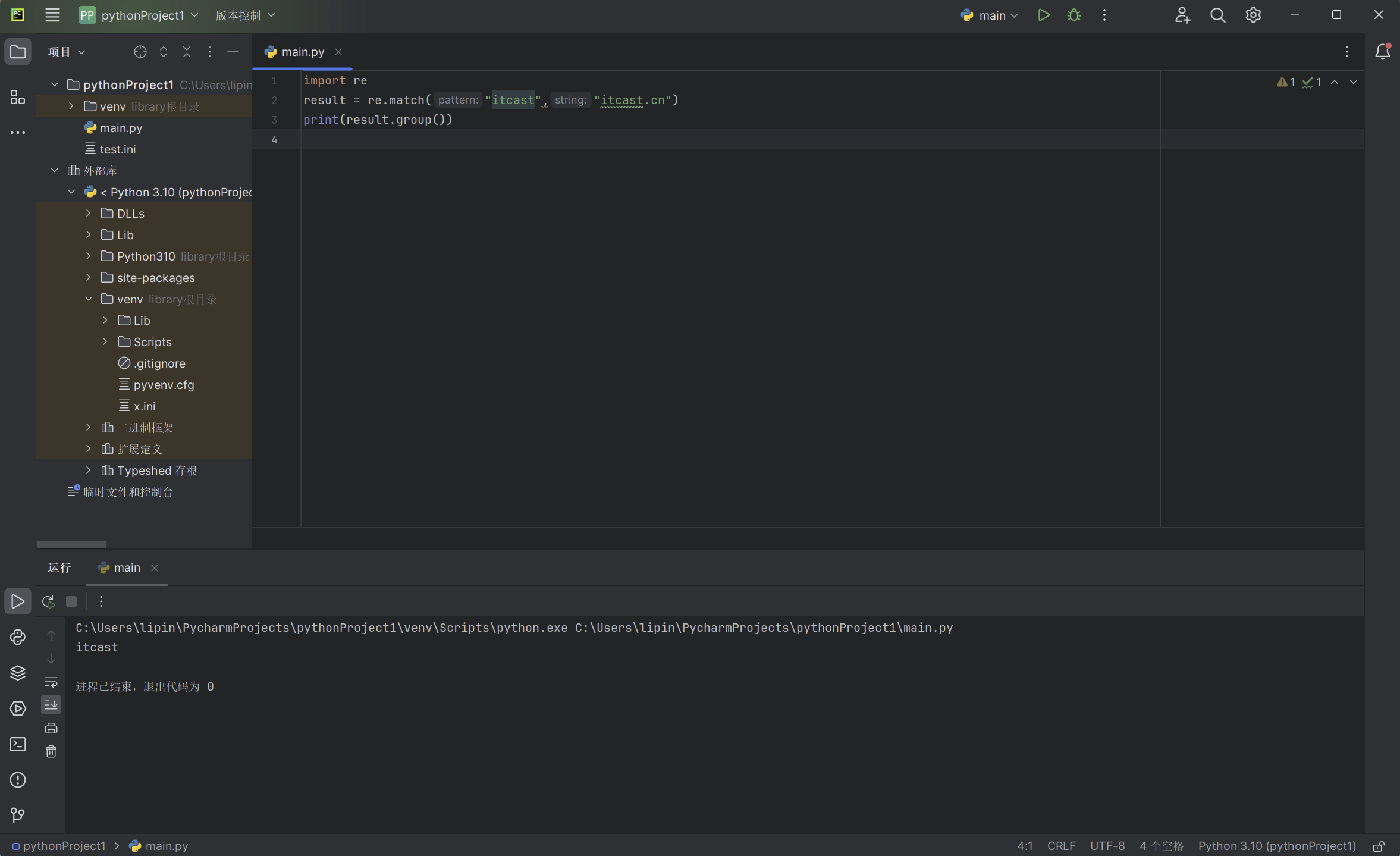
代码实列:
import re
result = re.match("itcast","itcast.cn")
print(result.group())
从string头开始匹配pattern完全可以匹配,pattern匹配结束,同时匹配终止,后面的.cn不再匹配,返回匹配成功的信息。以上代码输出的实列:
re.findall()函数
re.findall函数在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表
代码实列:
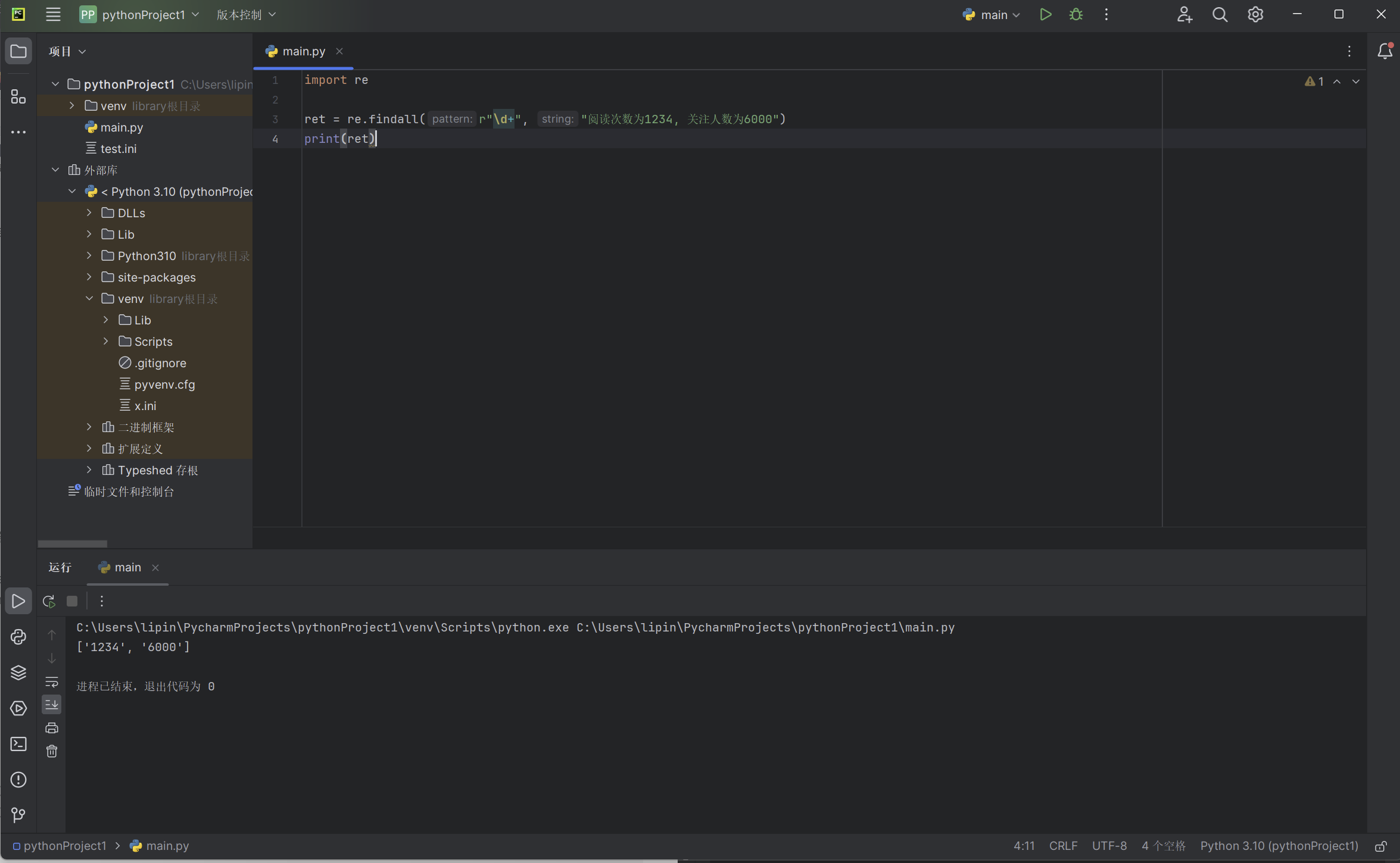
import re
ret = re.findall(r"\d+", "阅读次数为1234, 关注人数为6000")
print(ret)
我们需要在字符串中,寻找数字,可以看到,最终输出如下图所示:
re.search()函数
re.search 扫描整个字符串并返回第一个成功的匹配,如果没有匹配,就返回一个 None。
re.match与re.search的区别:re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配
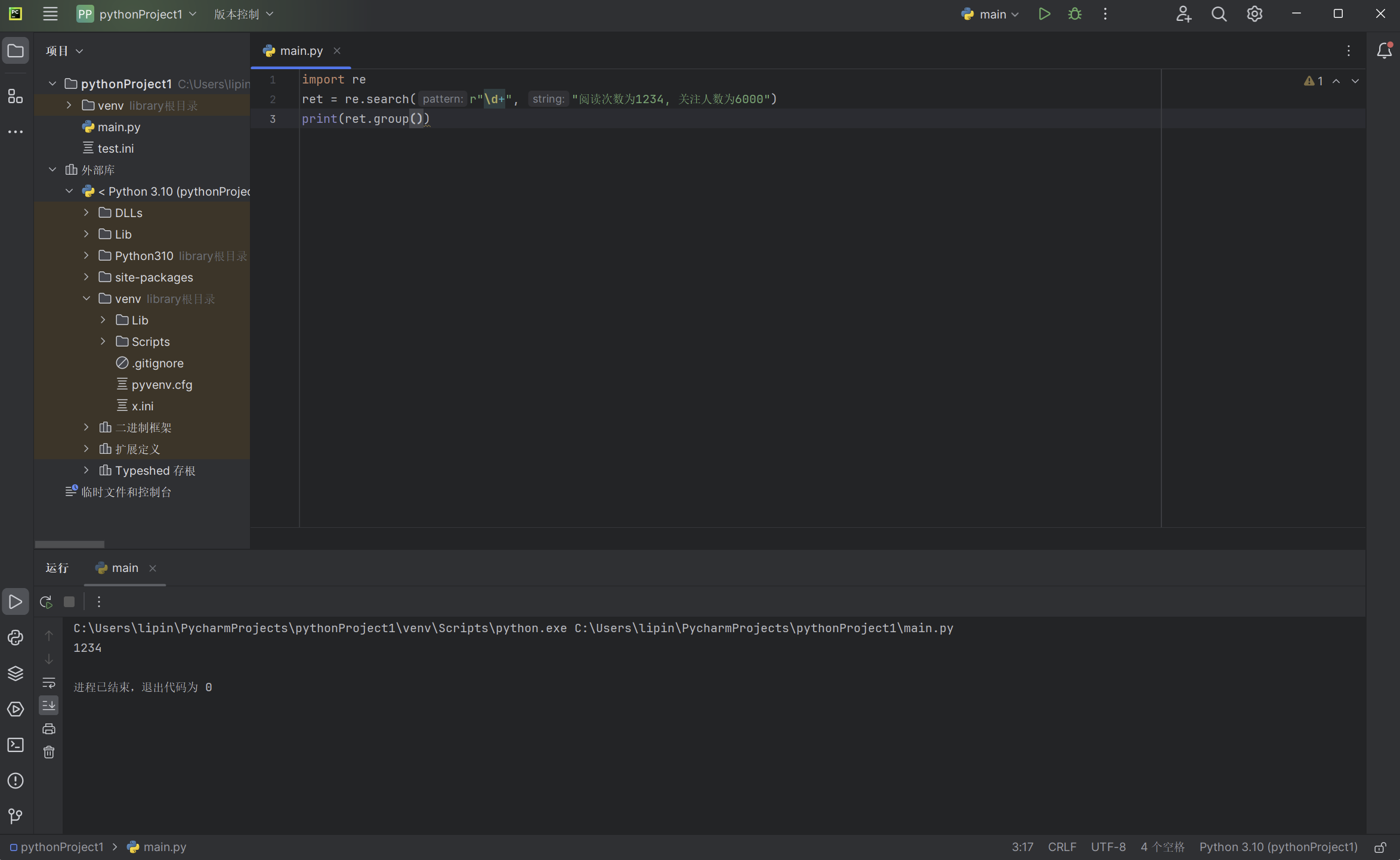
代码实列:
import re
ret = re.search(r"\d+", "阅读次数为1234, 关注人数为6000")
print(ret.group())
我们在字符串中寻找数字,search成功匹配到了数字,并且只返回第一个样本:
re.compile()函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用
prog = re.compile(pattern)
result = prog.match(string)
等价于
result = re.match(pattern, string)
代码实列:
import re
pattern = re.compile(r'\d+')
m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
print(m)
print(m.group())
print(m.start())
print(m.end())
print(m.span())
以上代码输出的实列:
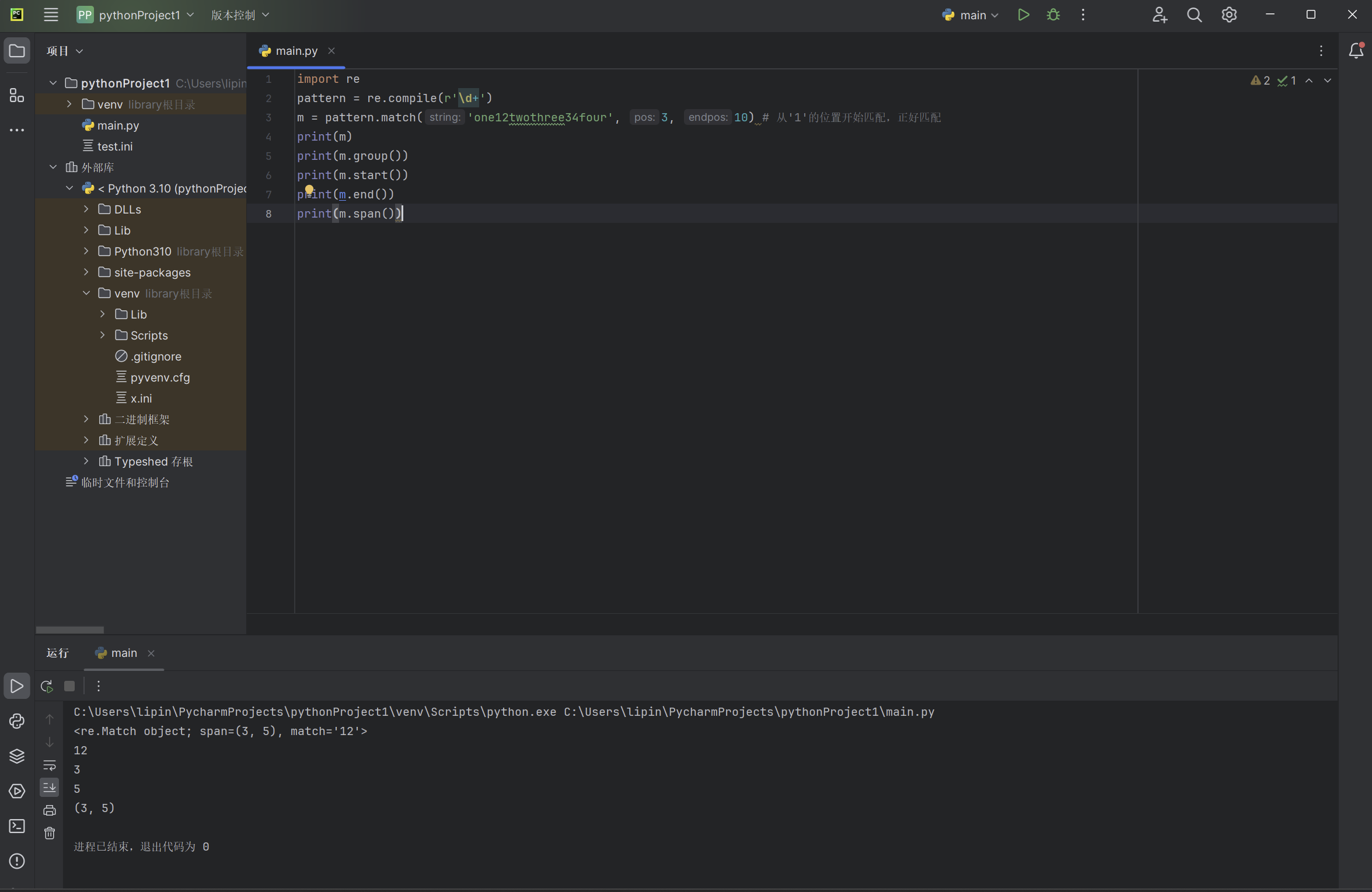
在上面,当匹配成功时返回一个 Match 对象,其中:
-
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或
group(0); -
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
-
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
-
span([group]) 方法返回 (start(group), end(group))
re.finditer()函数
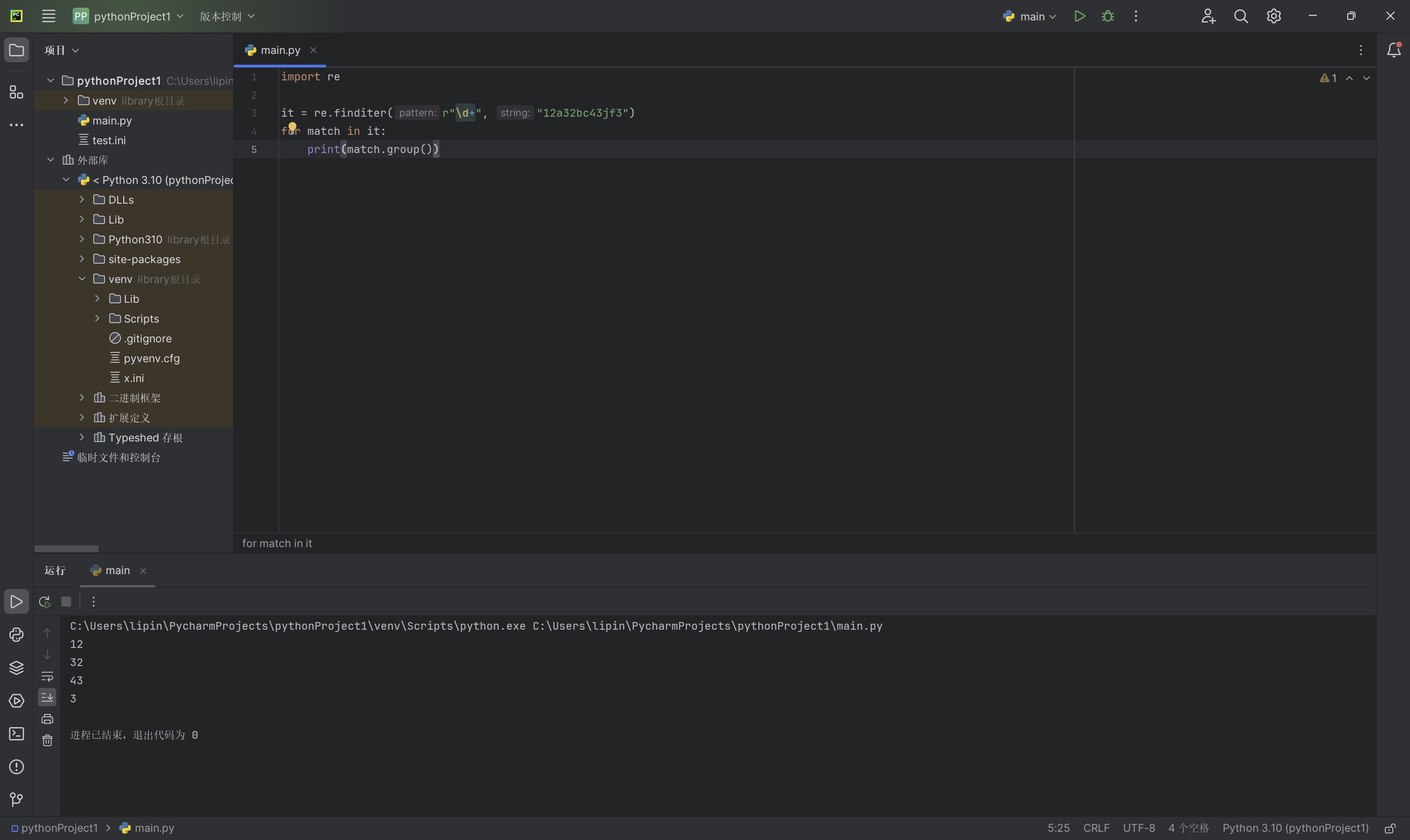
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回
import re
it = re.finditer(r"\d+", "12a32bc43jf3")
for match in it:
print(match.group())
以上代码输出的实列:
re.sub()函数
sub是substitute的所写,表示替换,将匹配到的数据进行替换。
语法:re.sub(pattern, repl, string, count=0, flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 必选,表示正则中的模式字符串 |
| repl | 必选,就是replacement,要替换的字符串,也可为一个函数 |
| string | 必选,被替换的那个string字符串 |
| count | 可选参数,count 是要替换的最大次数,必须是非负整数。如果省略这个参数或设为 0,所有的匹配都会被替换 |
| flag | 可选参数,标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
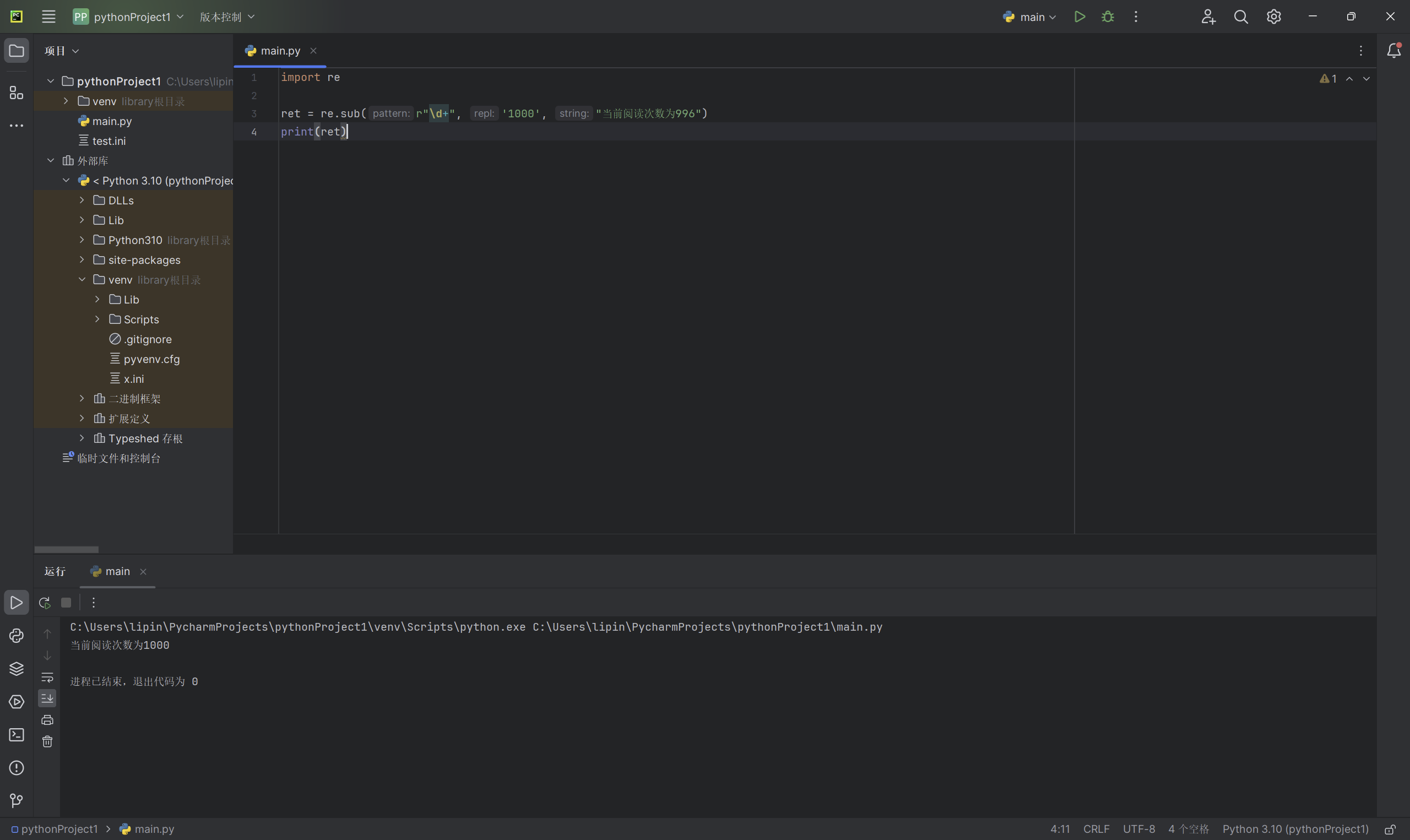
举例:将当前阅读次数修改为1000
import re
ret = re.sub(r"\d+", '1000', "当前阅读次数为996")
print(ret)
以上代码输出的实例:
re.subn()函数
行为与sub()相同,但是返回一个元组 (字符串, 替换次数)
语法:re.subn(pattern, repl, string[, count])
| 参数 | 描述 |
|---|---|
| pattern | 必选,表示正则中的模式字符串 |
| repl | 必选,就是replacement,要替换的字符串,也可为一个函数 |
| string | 必选,被替换的那个string字符串 |
| count | 可选参数,count 是要替换的最大次数,必须是非负整数。如果省略这个参数或设为 0,所有的匹配都会被替换 |
| flag | 可选参数,标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
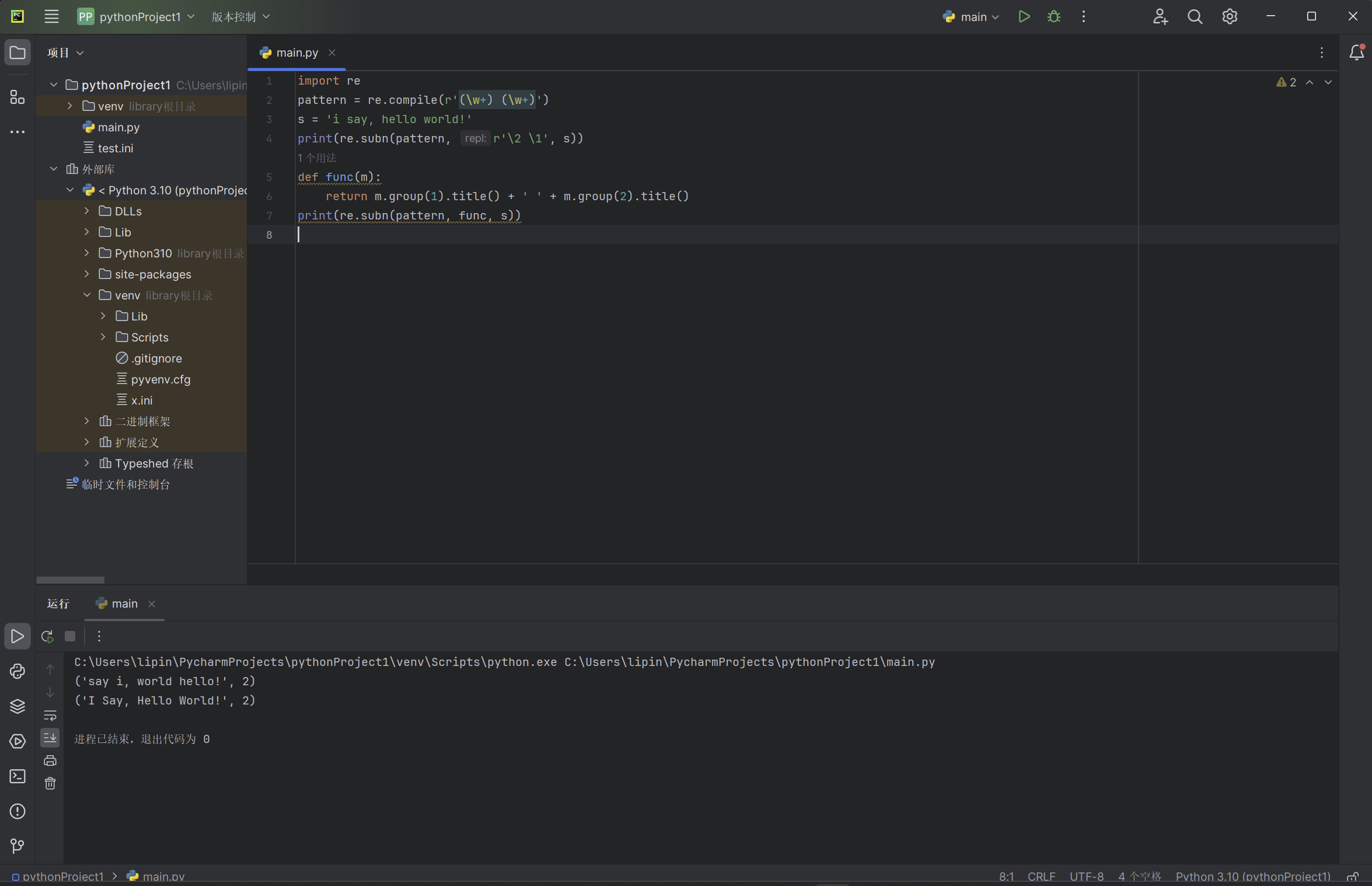
举例:
import re
pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print(re.subn(pattern, r'\2 \1', s))
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print(re.subn(pattern, func, s))
以上代码输出的实例:
re.split()函数
根据匹配进⾏切割字符串,并返回⼀个列表
语法:re.split(pattern, string, maxsplit=0, flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| maxsplit | 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数 |
举例:
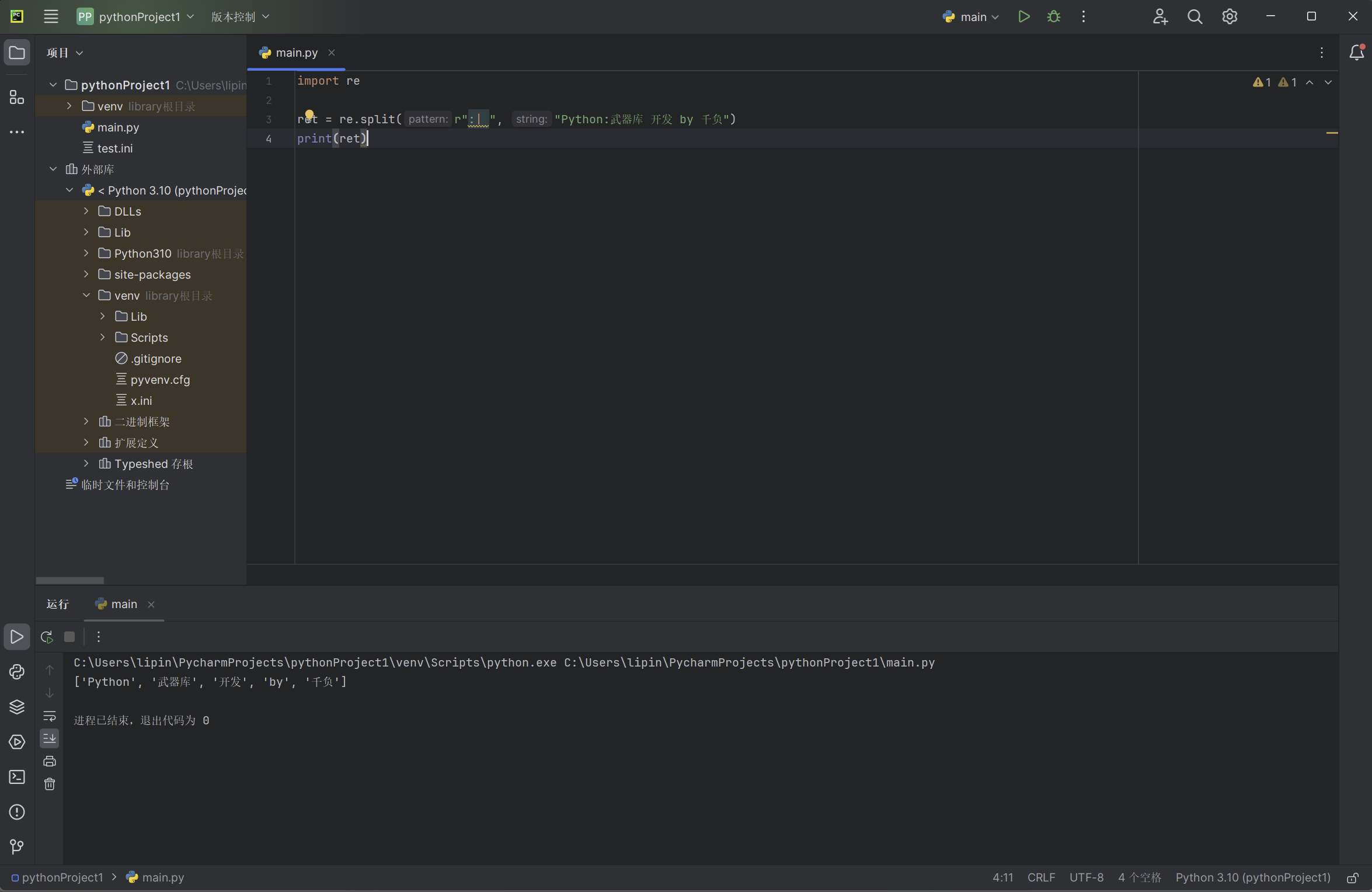
import re
ret = re.split(r":| ", "Python:武器库 开发 by 千负")
print(ret)
以上代码输出的实例: