目录
动态内存
new 和 delete 运算符
命名空间
定义命名空间
using 指令
不连续的命名空间
嵌套的命名空间
模板
函数模板
类模板
C++ 中 typename 和 class 的区别
函数模板的重载
动态内存
了解动态内存在 C++ 中是如何工作的是成为一名合格的 C++ 程序员必不可少的。C++ 程序中的内存分为两个部分:
- 栈:在函数内部声明的所有变量都将占用栈内存。
- 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存。
很多时候,您无法提前预知需要多少内存来存储某个定义变量中的特定信息,所需内存的大小需要在运行时才能确定。
在 C++ 中,您可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址。这种运算符即 new 运算符。
如果您不再需要动态分配的内存空间,可以使用 delete 运算符,删除之前由 new 运算符分配的内存。
new 和 delete 运算符
在 C++ 中,使用 new 运算符来动态分配内存,以便在运行时创建对象或数组。new 运算符首先会在堆上分配所需大小的内存,并返回指向这块内存的指针。然后,您可以使用该指针来操作这块内存。
以下是使用 new 运算符动态分配内存的一些示例:
1、动态分配单个对象的内存:
T* pointer = new T;
其中,T 是要分配的对象的类型,pointer 是指向新分配的对象的指针。
示例:
int* p = new int; // 动态分配一个整数类型的内存
*p = 10; // 在分配的内存中存储值
2、动态分配数组的内存:
T* arrayPointer = new T[size];
其中,T 是数组元素的类型,size 是数组的大小,arrayPointer 是指向新分配数组的指针。
示例:
int* arr = new int[5]; // 动态分配一个包含 5 个整数的数组的内存
arr[0] = 1; // 在分配的数组中存储值
当您不再需要动态分配的内存时,应使用 delete 运算符将其释放。释放内存后,内存将返回给操作系统以供其他程序使用。
以下是使用 delete 运算符释放动态分配的内存的示例:
1、释放通过 new 运算符分配的单个对象的内存:
delete pointer;
其中,pointer 是通过 new 运算符分配的指针。
示例:
int* p = new int;
*p = 10;
delete p; // 释放通过 new 分配的内存
2、释放通过 new[ ] 运算符分配的数组的内存:
delete[] arrayPointer;
其中,arrayPointer 是通过 new[ ] 运算符分配的指针。
示例:
int* arr = new int[5];
arr[0] = 1;
delete[] arr; // 释放通过 new[] 分配的内存
请注意以下几点:
- 使用完动态分配的内存后,务必记得释放内存,以免造成内存泄漏。
- 如果使用 new 分配了内存,必须使用 delete 释放;如果使用 new[ ] 分配了数组,必须使用 delete[ ] 释放。
- 避免重复释放内存或释放非动态分配的内存,这可能导致未定义行为。
- 在动态内存分配失败的情况下,需要进行适当的错误处理,例如捕获 std::bad_alloc 异常或检查指针是否为 nullptr。
使用动态内存分配可以在程序运行时根据需要动态地分配内存。这使得您能够灵活地管理内存资源,但也需要小心使用以避免内存泄漏和其他相关问题。
命名空间
命名空间是 C++ 中的一种机制,用于避免全局作用域中的命名冲突。命名空间定义了一个范围,称为命名空间作用域,在该范围内定义的名称不会与其他命名空间或全局作用域中的名称冲突。
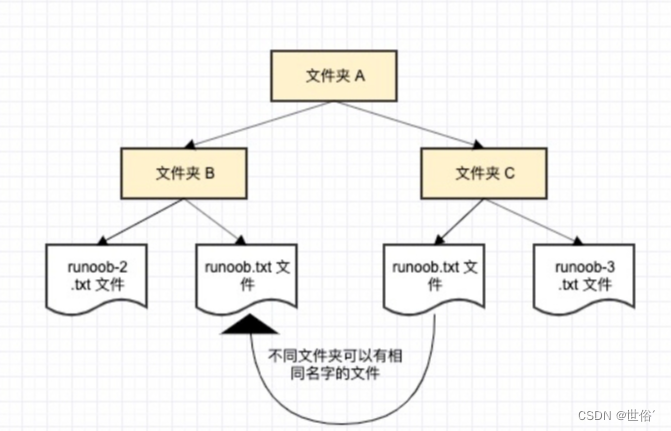
我们举一个计算机系统中的例子,一个文件夹(目录)中可以包含多个文件夹,每个文件夹中不能有相同的文件名,但不同文件夹中的文件可以重名。
定义命名空间
C++ 中可以使用关键字 namespace 来定义命名空间。下面是一个简单的例子:
namespace myNamespace {
int x;
void func();
}
void myNamespace::func() {
// function body
}
在上面的例子中,我们定义了一个名为 myNamespace 的命名空间,并在其中定义了一个整数变量 x 和一个函数 func。请注意,我们需要在定义函数时指定它所属的命名空间。
在使用命名空间中的名称时,可以使用限定符 :: 来指定其所属的命名空间。例如,在另一个命名空间或全局作用域中,您可以通过 myNamespace::x 和 myNamespace::func() 来访问这些名称。
如果您希望使用命名空间中的所有名称,可以使用 using namespace 语句导入该命名空间,例如:
using namespace myNamespace;
int main() {
x = 10;
func();
return 0;
}
请注意,虽然使用命名空间可以避免名称冲突,但在使用 using namespace 语句时,可能会导致意外的命名冲突。为了避免这种情况,最好只在局部作用域中使用 using namespace。
除此之外,C++ 还支持嵌套的命名空间和匿名命名空间等高级特性。嵌套的命名空间可以将多个命名空间嵌套在一起,以创建更具层次结构的命名空间。匿名命名空间是一个没有名称的命名空间,其中定义的名称只能在当前文件中访问。
using 指令
using 指令是 C++ 中的一个关键字,用于引入命名空间中的特定名称或整个命名空间到当前作用域,以便在代码中可以直接使用这些名称而无需使用限定符。
C++ 中有两种形式的 using 指令:using namespace 和 using 声明。
1、using namespace 指令:
using namespace 指令用于引入整个命名空间到当前作用域,使得该命名空间中的所有名称都可以直接使用,而无需使用限定符。该指令通常放在代码文件的开头或函数的开头,示例:
using namespace std; // 引入 std 命名空间
int main() {
string name = "John"; // 可以直接使用 std 命名空间中的名称 string
cout << "Hello, " << name << endl;
return 0;
}
注意:在使用 using namespace 指令时,应该注意命名空间冲突的问题。如果不同的命名空间中有相同名称的实体,可能会导致命名冲突。为了避免这种情况,最好只在局部作用域中使用 using namespace。
2、using 声明:
using 声明用于引入命名空间中的特定名称到当前作用域,使得这些名称可以直接使用,而无需使用限定符。该指令通常放在函数或作用域的内部,示例:
#include <iostream>
int main() {
using std::cout; // 引入 std 命名空间中的名称 cout
using std::endl; // 引入 std 命名空间中的名称 endl
cout << "Hello, world!" << endl; // 可以直接使用引入的名称
return 0;
}
使用 using 声明时,只有被声明的名称可以直接使用,其他名称仍需使用限定符。
使用 using 指令可以简化代码书写,并提高代码的可读性。但需要注意的是,在较大的项目中,过多地使用 using 指令可能导致命名冲突的问题或不明确的名称来源,所以在使用时需要谨慎选择使用范围,并遵循良好的编码规范。
不连续的命名空间
在 C++ 中,我们可以通过多个不连续的命名空间定义来创建一个命名空间的内容。这意味着我们可以在同一个命名空间中的不同位置多次定义命名空间的内容,以便将其分隔为多个部分。
下面是一个示例:
namespace myNamespace {
void func1(); // 第一部分声明
// 其他代码...
namespace subNamespace {
void func2(); // 第二部分声明
}
}
// 可选的其他代码...
namespace myNamespace {
void func1() {
// 第一部分的实现
}
}
namespace myNamespace::subNamespace {
void func2() {
// 第二部分的实现
}
}
在上面的示例中,我们首先声明了一个命名空间 myNamespace,并在其中分隔了两个部分。第一部分的声明包含了函数 func1 的声明,而第二部分的声明位于命名空间 subNamespace 中,包含了函数 func2 的声明。
然后,在后续的代码中,我们通过不连续的命名空间定义来实现这些函数。在第一个命名空间定义中,我们实现了函数 func1,在第二个命名空间定义中,我们实现了函数 func2。
使用不连续的命名空间定义可以使代码更加模块化和可读性更强。它允许我们将命名空间的内容分散到不同的位置,以便更好地组织和管理代码。但是,需要注意的是,多个命名空间定义之间必须位于同一个命名空间中,否则会导致编译错误。
此外,还可以将不同的命名空间定义放在不同的源文件中,并在需要使用命名空间内容的源文件中进行引用,以进一步分隔代码。
嵌套的命名空间
在 C++ 中,我们可以创建嵌套的命名空间,也就是将一个命名空间定义在另一个命名空间内部。嵌套的命名空间可以帮助我们更好地组织和管理代码,并提供更好的命名空间层次结构。
下面是一个示例:
#include <iostream>
namespace outer {
void func1(); // 外部命名空间中的函数声明
namespace inner {
void func2(); // 内部命名空间中的函数声明
}
}
// 外部命名空间中的函数实现
void outer::func1() {
std::cout << "这是外部命名空间。" << std::endl;
}
// 内部命名空间中的函数实现
void outer::inner::func2() {
std::cout << "这是内部命名空间." << std::endl;
}
int main() {
// 调用外部命名空间函数
outer::func1();
// 调用嵌套命名空间函数
outer::inner::func2();
return 0;
}这段代码定义了一个外部命名空间 outer,并在其中定义了一个嵌套命名空间 inner。在 outer 中,我们声明了一个名为 func1 的函数,在 inner 中,我们声明了一个名为 func2 的函数。然后我们通过限定符分别实现了这两个函数:
- 在外部命名空间中的函数 func1 的实现中,我们使用命名空间限定符 outer:: 来指明该函数所在的命名空间。
- 在内部命名空间中的函数 func2 的实现中,我们使用命名空间限定符 outer::inner:: 来指明该函数所在的命名空间。
在 main() 函数中,我们通过命名空间限定符来调用外部命名空间函数 func1() 和嵌套命名空间函数 func2()。
需要注意的是,这两个函数实现位于同一个源文件中。
使用命名空间可以更好地组织和管理代码,并提高代码的可读性和可维护性。嵌套命名空间可以进一步将功能相关的内容进行归类,使得代码的模块化程度更高。
模板
模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。
模板是创建泛型类或函数的蓝图或公式。库容器,比如迭代器和算法,都是泛型编程的例子,它们都使用了模板的概念。
每个容器都有一个单一的定义,比如 向量,我们可以定义许多不同类型的向量,比如 vector <int> 或 vector <string>。
您可以使用模板来定义函数和类,接下来让我们一起来看看如何使用。
函数模板
函数模板是一种通用的函数定义,它可以使用不同的数据类型进行实例化。函数模板允许编写一个函数定义,该定义可以接受任何数据类型作为函数的参数或返回值,从而提供了一种通用的算法实现方法。模板函数定义的一般形式如下所示:
template <typename type> ret-type func-name(parameter list)
{
// 函数的主体
}在这里,type 是函数所使用的数据类型的占位符名称。这个名称可以在函数定义中使用。
下面是一个简单的函数模板示例,演示如何在C++中定义和使用函数模板:
#include <iostream>
template <typename T>
T max(T a, T b) {
return a > b ? a : b;
}
int main() {
int x = 1, y = 2;
std::cout << "max(" << x << ", " << y << ") = " << max(x, y) << std::endl;
double m = 2.0, n = 1.5;
std::cout << "max(" << m << ", " << n << ") = " << max(m, n) << std::endl;
return 0;
}
在这个示例中,我们定义了一个函数模板 max,它具有一个类型参数 T。这个函数模板比较两个类型为 T 的参数,并返回它们之间的最大值。
在 main 函数中,我们分别使用了 int 和 double 类型的数据类型来调用 max 函数。通过使用不同的数据类型,我们可以实例化函数模板 max,并生成相应的函数定义。
运行以上代码将输出如下结果:
max(1, 2) = 2
max(2, 1.5) = 2类模板
类模板是一种通用的类定义,它可以使用不同的数据类型进行实例化。类模板允许编写一个类定义,该定义可以处理不同的数据类型,并提供通用的数据结构和算法。
泛型类声明的一般形式如下所示:
template <class type> class class-name {
.
.
.
}
在这里,type 是占位符类型名称,可以在类被实例化的时候进行指定。您可以使用一个逗号分隔的列表来定义多个泛型数据类型。
以下是一个示例代码,展示了如何定义和使用类模板来实现一个栈(Stack)数据结构:
#include <iostream>
template <class T>
class Stack {
private:
T* stackArray;
int top;
int capacity;
public:
Stack(int size) : capacity(size), top(-1) {
stackArray = new T[capacity];
}
~Stack() {
delete[] stackArray;
}
void push(T element) {
if (top == capacity - 1) {
std::cout << "堆栈已满。无法推送元素。" << std::endl;
return;
}
stackArray[++top] = element;
}
T pop() {
if (top == -1) {
std::cout << "堆栈为空。无法弹出元素。" << std::endl;
return T();
}
return stackArray[top--];
}
bool isEmpty() const {
return top == -1;
}
};
int main() {
Stack<int> intStack(5);
intStack.push(1);
intStack.push(2);
intStack.push(3);
std::cout << "Popped: " << intStack.pop() << std::endl;
std::cout << "Popped: " << intStack.pop() << std::endl;
Stack<double> doubleStack(3);
doubleStack.push(1.23);
doubleStack.push(4.56);
std::cout << "Popped: " << doubleStack.pop() << std::endl;
return 0;
}
在这个示例中,我们定义了一个类模板 Stack,它表示一个栈数据结构。通过使用类型参数 T,我们可以在栈中存储任意类型的元素。
在 main 函数中,我们分别实例化了 Stack<int> 和 Stack<double>。通过调用类模板中的方法,我们可以对不同的数据类型进行入栈和出栈操作。
运行以上代码将输出如下结果:
Popped: 3
Popped: 2
Popped: 4.56这个示例展示了类模板的基本用法。通过使用类模板,我们可以定义通用的数据结构,以处理不同的数据类型。类模板提供了一种灵活和可扩展的方式来操作各种数据类型,并提高代码的复用性和可读性。
C++ 中 typename 和 class 的区别
在 C++ 中,typename 和 class 关键字都可以用来定义类模板中的类型参数,但它们在某些情况下有一些区别。
typename 关键字用于指示后面的名称是一个类型,可以用在类型推导、嵌套依赖类型和模板别名等场景中。例如,以下是一个使用 typename 的示例:
template <typename T>
void printSize(const T& container) {
typename T::size_type size = container.size();
std::cout << "Size of container: " << size << std::endl;
}
在这个示例中,我们使用 typename 关键字来指示 T::size_type 是一个类型。T::size_type 是容器类型的一个嵌套类型,表示容器中元素的数量。
class 关键字也可以用来指示一个类型参数,但有时候使用 class 可能会导致歧义或编译错误。例如,以下是一个由于使用了 class 关键字而导致编译错误的示例:
template <typename T>
void foo(typename T::iterator iter) {}
template <class T>
void bar(T t) {
foo(t.begin());
}
在这个示例中,foo 函数接受一个迭代器类型作为参数。然而,当我们在 bar 函数中调用 foo 时,使用 T::iterator 语法会导致编译器无法确定 iterator 是否为一个类型,因为它也可能是一个静态成员变量。
在这种情况下,我们需要使用 typename 关键字来明确告诉编译器 T::iterator 是一个类型:
template <typename T>
void bar(T t) {
foo(typename T::iterator(t.begin()));
}
在这个示例中,我们使用了 typename 关键字来说明 T::iterator 是一个类型。这样编译器就不会将其解析为静态成员变量了。
因此,虽然在定义类模板时可以使用 class 或 typename 关键字来指示类型参数,但在某些情况下,使用 typename 更加明确和安全。
函数模板的重载
函数模板的重载是指在同一个作用域内,定义多个具有相同名称但参数类型不同的函数模板。通过函数模板的重载,可以根据不同的参数类型来选择相应的函数模板进行调用。
函数模板的重载遵循以下规则:
- 与普通函数一样,函数模板的重载必须在参数数量或参数类型上有所区别。
- 当存在多个匹配的函数模板时,编译器使用一套优先级规则来选择最佳匹配的函数模板。
- 编译器会尽量选择能够实现精确匹配的函数模板,如果有多个精确匹配的函数模板,则选择最特化的版本。
- 如果没有找到完全匹配的函数模板,编译器将尝试进行隐式类型转换来匹配其他函数模板。
- 如果存在多个可行的匹配,但没有一个明显的最佳匹配时,编译器将报错。
以下是一个示例,展示了如何在函数模板中进行重载:
#include <iostream>
template <typename T>
void print(const T& value) {
std::cout << "Generic print: " << value << std::endl;
}
template <typename T>
void print(T* value) {
std::cout << "Pointer print: " << *value << std::endl;
}
int main() {
int num = 10;
print(num); // 调用第一个重载的 print 函数模板
print(&num); // 调用第二个重载的 print 函数模板
double pi = 3.14159;
print(pi); // 调用第一个重载的 print 函数模板
return 0;
}
在这个示例中,我们定义了两个函数模板 print 的重载版本。第一个重载版本接受一个值类型的参数,而第二个重载版本接受一个指针类型的参数。
在 main 函数中,我们分别调用了相应的函数模板。根据参数的类型,编译器将选择最匹配的函数模板进行调用。
运行以上代码将输出如下结果:
Generic print: 10
Pointer print: 10
Generic print: 3.14159通过函数模板的重载,我们可以根据不同的参数类型来实现相应的函数逻辑,提高代码的复用性和灵活性。