CRUD
1.注释:在SQL中可以使用"--空格 + 描述"来表示注释说明
2.CRUD即增加(Create), 查询(Retrieve), 更新(Update),删除(Delete)四个单词首字母的缩写
新增(Create)
简述(一般写法): insert into 表名 values(列,列...) ->给出列的数目和类型,都是要和表结构匹配的
具体语法如下:
insert [into] table_name [(column [, column]...)] values (value_list) [, (value_list)]...
value_list: value, [, value]...
//指定列查询(通过特殊的写法,指定列进行插入)基础写法如下:
insert into 表名 (列名, 列名...) values (值, 值...)
案例:
创建一张学生表
drop table if exists student;
create table student (
id int,
sn int comment '学号',
name varchar(20) comment '姓名',
qq_email varchar(20) comment 'qq邮箱'
);
单行数据 + 全列插入
插入两条记录, value_list 数量必须和定义表的列的数量及顺序一致INSERT INTO student VALUES ( 100 , 10000 , ' 唐三藏 ' , NULL );INSERT INTO student VALUES ( 101 , 10001 , ' 孙悟空 ' , '11111' );
多行数据 + 指定列插入
-- 插入两条记录, value_list 数量必须和指定列数量及顺序一致INSERT INTO student (id, sn, name) VALUES( 102 , 20001 , ' 曹孟德 ' ),( 103 , 20002 , ' 孙仲谋 ' );
我们知道,MySQL是一个客户端-服务器结构,客户端和服务器之间,使用网络进行通信.
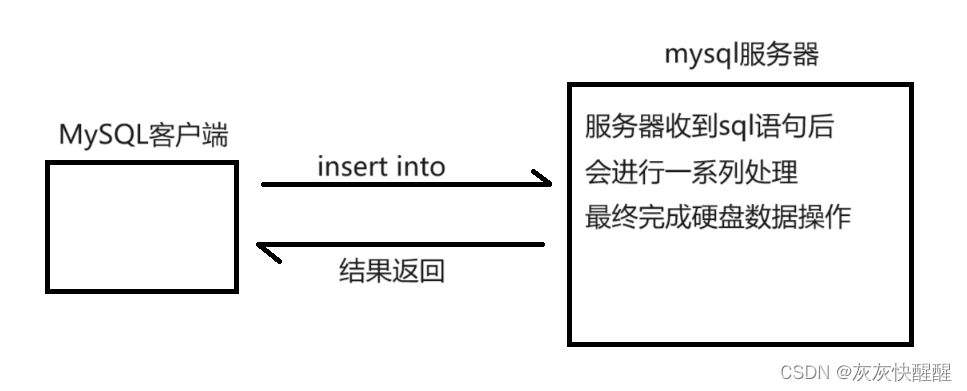
那么所以,
1.如果分10个sql语句进行,就意味着该过程中,有10次网络交互,数据库服务器收到请求之后,也要进行10次处理->(1)检查语法 (2)数据校验 (3)将插入数据放入到硬盘中
2.如果只分一次,虽然单次时间高,但是网络开销更少
查询(Retrieve)(注:这里也包含十分危险的操作)
语法:
select
[distinct] {* | {column [, column]...}
[from table_name]
[where ...]
[order by column [asc | desc],...]
limit...
案例:
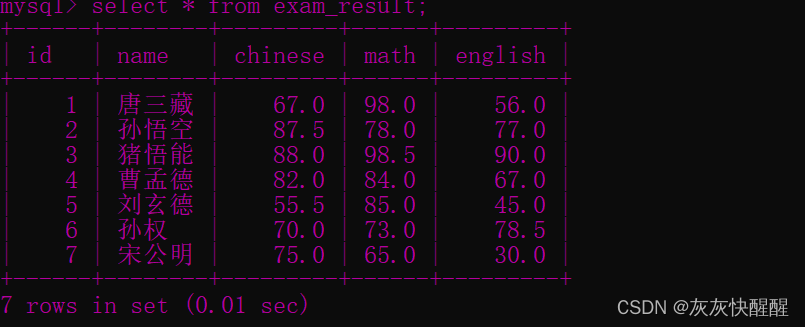
-- 创建考试成绩表DROP TABLE IF EXISTS exam_result;CREATE TABLE exam_result (id INT ,name VARCHAR ( 20 ),chinese DECIMAL ( 3 , 1 ),math DECIMAL ( 3 , 1 ),english DECIMAL ( 3 , 1 ));-- 插入测试数据INSERT INTO exam_result (id,name, chinese, math, english) VALUES( 1 , ' 唐三藏 ' , 67 , 98 , 56 ),( 2 , ' 孙悟空 ' , 87.5 , 78 , 77 ),( 3 , ' 猪悟能 ' , 88 , 98.5 , 90 ),( 4 , ' 曹孟德 ' , 82 , 84 , 67 ),( 5 , ' 刘玄德 ' , 55.5 , 85 , 45 ),( 6 , ' 孙权 ' , 70 , 73 , 78.5 ),( 7 , ' 宋公明 ' , 75 , 65 , 30 );
全列查询
-- 通常情况下不建议使用 * 进行全列查询
为什么?在实际开发的过程当中,这样的操作是十分危险的.因为一旦数据量很大,此时这个操作就会产生大量的硬盘IO和网络IO,就可能把硬盘或者网络的带宽给吃满,而一旦带宽吃满了,此时,服务器就无法正常响应其它客户端的要求.
-- 可能会影响到索引的使用(索引后面讲解)
select * from exam_result;
指定列查询
-- 指定列的顺序不需要按照定义表的顺序来
select id, name, english from exam_result;
查询的字段为表达式
-- 表达式不包含字段
select id, name, 10 from exam_result;
-- 表达式包含一个字段
select id, name, english + 10 from exam_result;
-- 表达式包含多个字段
select id, name, chinese + math + english from exam_result;
把查询出来的每一行,都代入表达式进行计算
1.当前表达式查询,并未修改服务器上硬盘中存储的数据本体,只是在查询结果的基础上进行运算的,得到的只是"临时表",即select的所有操作并不会影响到数据本体.
2.此处查询出的临时表,每个列的类型不再受限于原始表,会保证数据的正确性
3.一边查询,一边针对查询结果进行计算
别名(起了个绰号)
为查询结果中的列指定别名,表示返回的结果集中,以别名作为该列的名称,语法:
select column [as] alias_name [...] from table_name;
-- 结果集中,表头的列名 = 别名
select id, name, chinese + math + english as 总分 from exam_result;
去重:DISTINCT
定义:当查询结果中如果存在重复的元素,就只保留一个.
使用DISTINCT对某列关键字进行去重:
select distinct math from exam_result;
举例:
去重前:
-- 98 分重复了SELECT math FROM exam_result;+--------+| math |+--------+| 98 || 78 || 98 || 84 || 85 || 73 || 65 |+--------+7 rows in set ( 0.00 sec)
去重后:
-- 去重结果SELECT DISTINCT math FROM exam_result;+--------+| math |+--------+| 98 || 78 || 84 || 85 || 73 || 65 |+--------+6 rows in set ( 0.00 sec)
排序:ORDER BY
select 列名 from 表名 order by 列名;//最后的列名就是排序的依据
语法:
-- asc为升序(从小到大)
-- desc为降序(从大到小)
-- 默认为asc
select ... from table_name [where ...] order by column [asc|desc],[...];
-- 注意这里的desc与查询表时describe的缩写desc不同
1.没有order by子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
2.NULL数据排序,视为比任何值都小,升序出现在最上面,降序出现在最下面
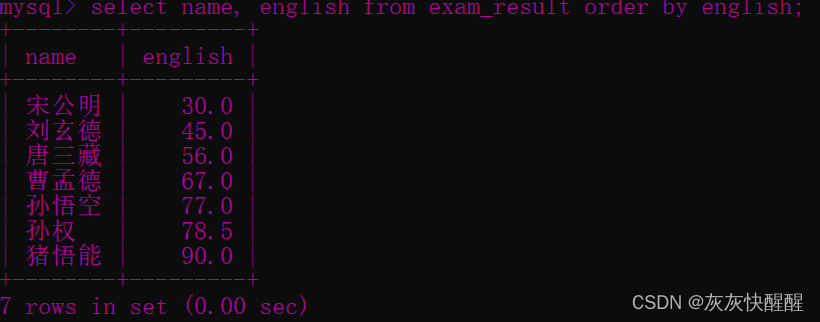
-- 查询同学姓名和英语成绩, 按英语成绩排序显示
select name, english from exam_result order by english;
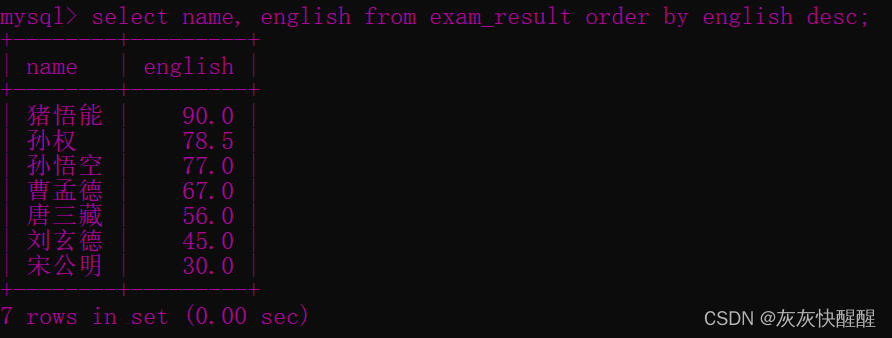
select name, english from exam_result order by english desc;
3.使用表达式或者别名进行排序
-- 查询同学总分,由高到低
1.select name, chinese + english + math from exam_result
order by chinese + english + math;
2.select name, chinese + english + math from exam_result
order by total desc;//在这里使用别名会报错
4.可以对多个字段进行排序,排序优先级随书写顺序
-- 查询同学们各门成绩,一次按照数学降序, 英语升序, 语文升序的方式显示
select name, math, english, chinese from exam_result
order by math desc, english,chinese;
条件查询:WHERE
定义:查询的时候,指定筛选条件,条件满足,这个数据就会被保留(作为结果集)
最终的结果集,就是满足所有条件的数据.同时,执行查询操作时,就会遍历整张表
比较运算符:
| 运算符 | 说明 |
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,null不安全,例如null = null的结果是null(false) |
| <=> | 等于,null安全,例如null<=>null的结果是null(true) |
| !=, <> | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果a0 <= value <= a1,返回true |
| in(option...) | 如果是option中的任意一个,返回true |
| is null | 是null |
| is not null | 不是null |
| like | 模糊匹配.%表示任意多个(包括0个任意字符);_严格地表示为一个字符 |
逻辑运算符:
| 运算符 | 说明 |
| and | 多个条件必须为true,结果才是true |
| or | 任意一个条件为true,结果为true |
| not | 条件为true,结果为false |
注:
1.where条件可以使用表达式,但不能使用别名
2.and的优先级高于or,在使用的同时,需要使用小括号()包裹优先执行的部分(真正写代码时,还是要多使用(),显式指定先后顺序)
基本查询:
-- 查询英语不及格的同学及英语成绩 ( < 60 )SELECT name, english FROM exam_result WHERE english < 60 ;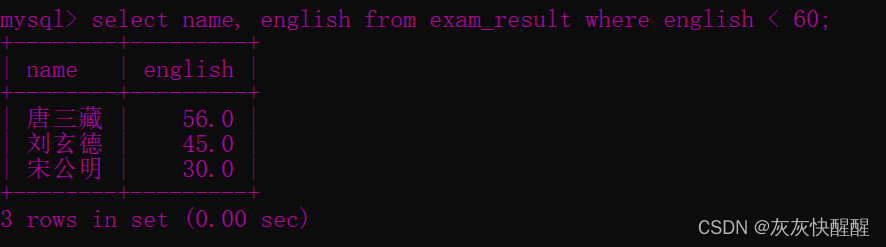 -- 查询语文成绩好于英语成绩的同学SELECT name, chinese, english FROM exam_result WHERE chinese > english;
-- 查询语文成绩好于英语成绩的同学SELECT name, chinese, english FROM exam_result WHERE chinese > english;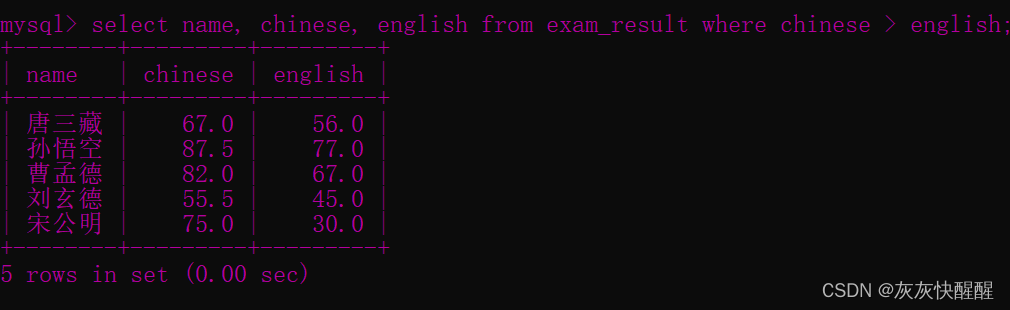 -- 查询总分在 200 分以下的同学SELECT name, chinese + math + english 总分 FROM exam_resultWHERE chinese + math + english < 200 ;
-- 查询总分在 200 分以下的同学SELECT name, chinese + math + english 总分 FROM exam_resultWHERE chinese + math + english < 200 ;
注意:当在where中使用别名会报错
注意SQL语句的执行顺序:
1.取出一条记录(遍历表)
2.把记录代入条件,判定是否满足
3.如果条件满足,再把select后面的指定的列取出来,并进行表达式运算
上面的过程中,先执行where,后执行表达式中取别名的操作.
and和or
-- 查询语文成绩大于 80 分,且英语成绩大于 80 分的同学SELECT * FROM exam_result WHERE chinese > 80 and english > 80 ;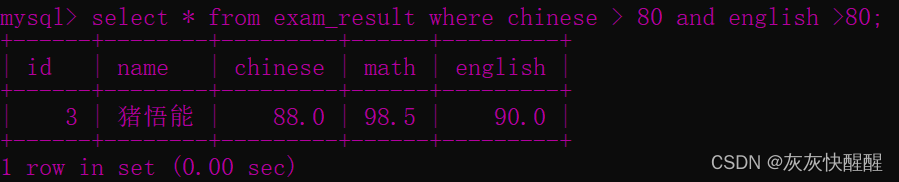 -- 查询语文成绩大于 80 分,或英语成绩大于 80 分的同学SELECT * FROM exam_result WHERE chinese > 80 or english > 80 ;
-- 查询语文成绩大于 80 分,或英语成绩大于 80 分的同学SELECT * FROM exam_result WHERE chinese > 80 or english > 80 ;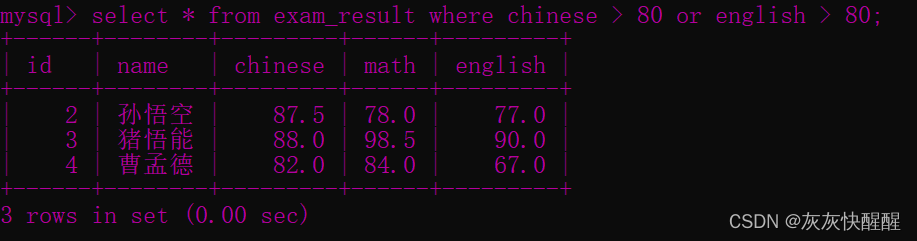 -- 观察 AND 和 OR 的优先级:SELECT * FROM exam_result WHERE chinese > 80 or math> 70 and english > 70 ;
-- 观察 AND 和 OR 的优先级:SELECT * FROM exam_result WHERE chinese > 80 or math> 70 and english > 70 ;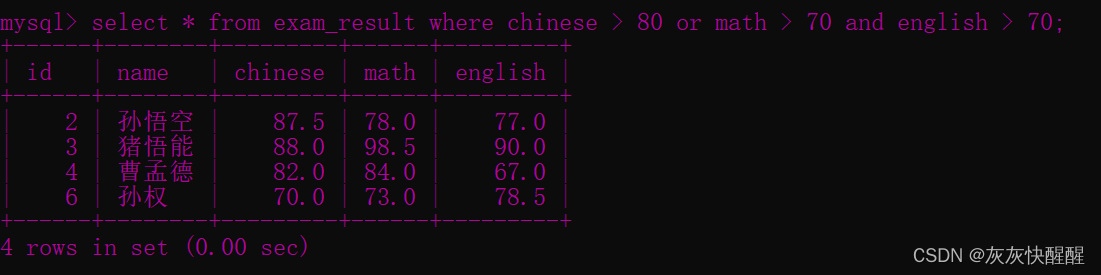 SELECT * FROM exam_result WHERE (chinese > 80 or math> 70 ) and english > 70 ;
SELECT * FROM exam_result WHERE (chinese > 80 or math> 70 ) and english > 70 ;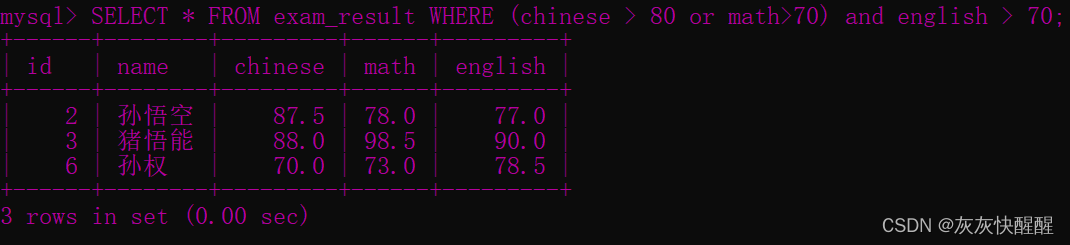
范围查询:
1.between...and...
-- 查询语文成绩在 [80, 90] 分的同学及语文成绩SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90 ;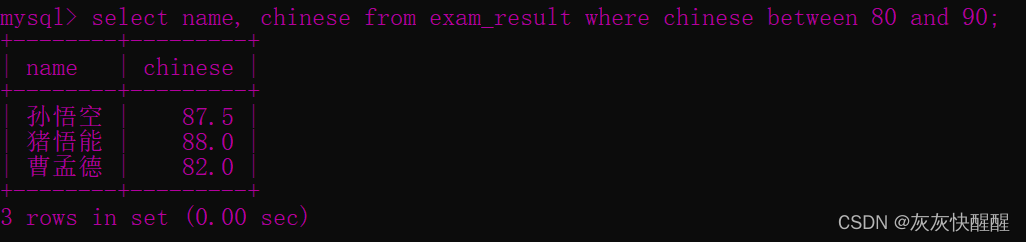 -- 使用 AND 也可以实现SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese<= 90 ;
-- 使用 AND 也可以实现SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese<= 90 ;
2.in
-- 查询数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩SELECT name, math FROM exam_result WHERE math IN ( 58 , 59 , 98 , 99 );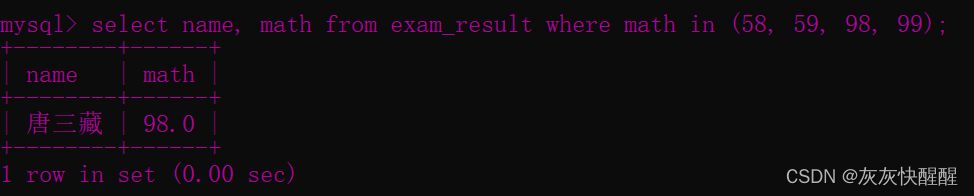 -- 使用 OR 也可以实现SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math= 98 OR math = 99 ;
-- 使用 OR 也可以实现SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math= 98 OR math = 99 ;
模糊查询: like
-- % 匹配任意多个(包括 0 个)字符SELECT name FROM exam_result WHERE name LIKE ' 孙 %' ; -- 匹配到孙悟空、孙权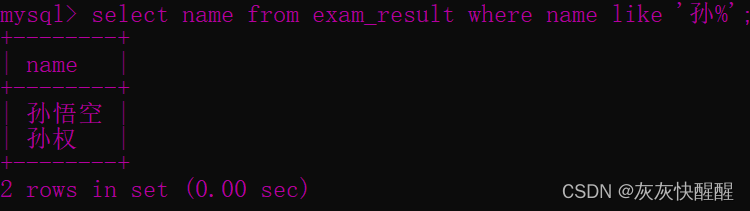 -- _ 匹配严格的一个任意字符SELECT name FROM exam_result WHERE name LIKE ' 孙 _' ; -- 匹配到孙权
-- _ 匹配严格的一个任意字符SELECT name FROM exam_result WHERE name LIKE ' 孙 _' ; -- 匹配到孙权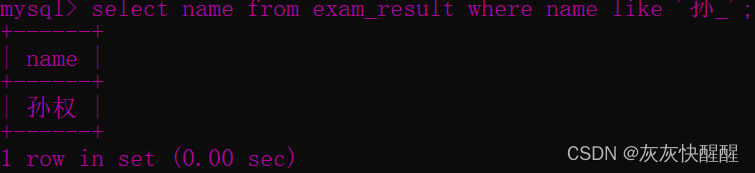
null的查询:is[not] null
-- 查询 qq_mail 已知的同学姓名SELECT name, qq_mail FROM student WHERE qq_mail IS NOT NULL ;-- 查询 qq_mail 未知的同学姓名SELECT name, qq_mail FROM student WHERE qq_mail IS NULL ;
分页查询:limit
限制这次表,返回多少条记录(一页多少条)
语法:
-- 起始下标是0
-- 从0开始,筛选n条结果
select ... from table_name [where...] [order by ...] limit n;
-- 从s开始,筛选n条结果
select ... from table_name [where...] [order by ...] limit s, n;
-- 从s开始,筛选n条结果,相比于第二种方法更加明确,建议使用
select ... from table_name [where...] [order by ...] limit n offset s;
案例:按id进行分页,每页三条记录,分别显示第1,2,3页
-- 第 1 页SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3OFFSET 0 ;-- 第 2 页SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3OFFSET 3 ;-- 第 3 页,如果结果不足 3 个,不会有影响SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3OFFSET 6 ;
修改
语法:
update table_name set column = expr [, column = expr ...]
[where ...] [order by ...] [limit ...]
-- 进行修改时要定位到行和列,再修改.如果条件不写,就是针对所有的行进行修改.
案例:
-- 将孙悟空同学的数学成绩变更为 80 分UPDATE exam_result SET math = 80 WHERE name = ' 孙悟空 ' ;-- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分(修改多个列只需要加多个逗号)UPDATE exam_result SET math = 60 , chinese = 70 WHERE name = ' 曹孟德 ' ;-- 将总成绩倒数前三的 3 位同学的数学成绩加上 10 分UPDATE exam_result SET math = math + 1 0 ORDER BY chinese + math + english LIMIT3 ;-- 将所有同学的语文成绩更新为原来的 2 倍UPDATE exam_result SET chinese = chinese * 2 ;-- 注:update也是一个危险操作-- 给定的一个sql语句,就是一个整体,要么整个都执行成功,要么都失败,就全部不执行
删除(delete)
定义:把条件匹配出来符合要求的数据,给删掉.
语法:
delete from table_name [where ...] [order by ...] [limit ...]
--如果删除语句中为指定条件,就会删除所有数据
案例:
-- 删除孙悟空同学的考试成绩DELETE FROM exam_result WHERE name = ' 孙悟空 ' ;-- 删除整张表数据-- 准备测试表DROP TABLE IF EXISTS for_delete;CREATE TABLE for_delete (id INT ,name VARCHAR ( 20 ));-- 插入测试数据INSERT INTO for_delete (name) VALUES ( 'A' ), ( 'B' ), ( 'C' );-- 删除整表数据DELETE FROM for_delete;





![[云原生案例2.1 ] Kubernetes的部署安装 【单master集群架构 ---- (二进制安装部署)】节点部分](https://img-blog.csdnimg.cn/043e8e22185749df8d6ae3386453e179.png)