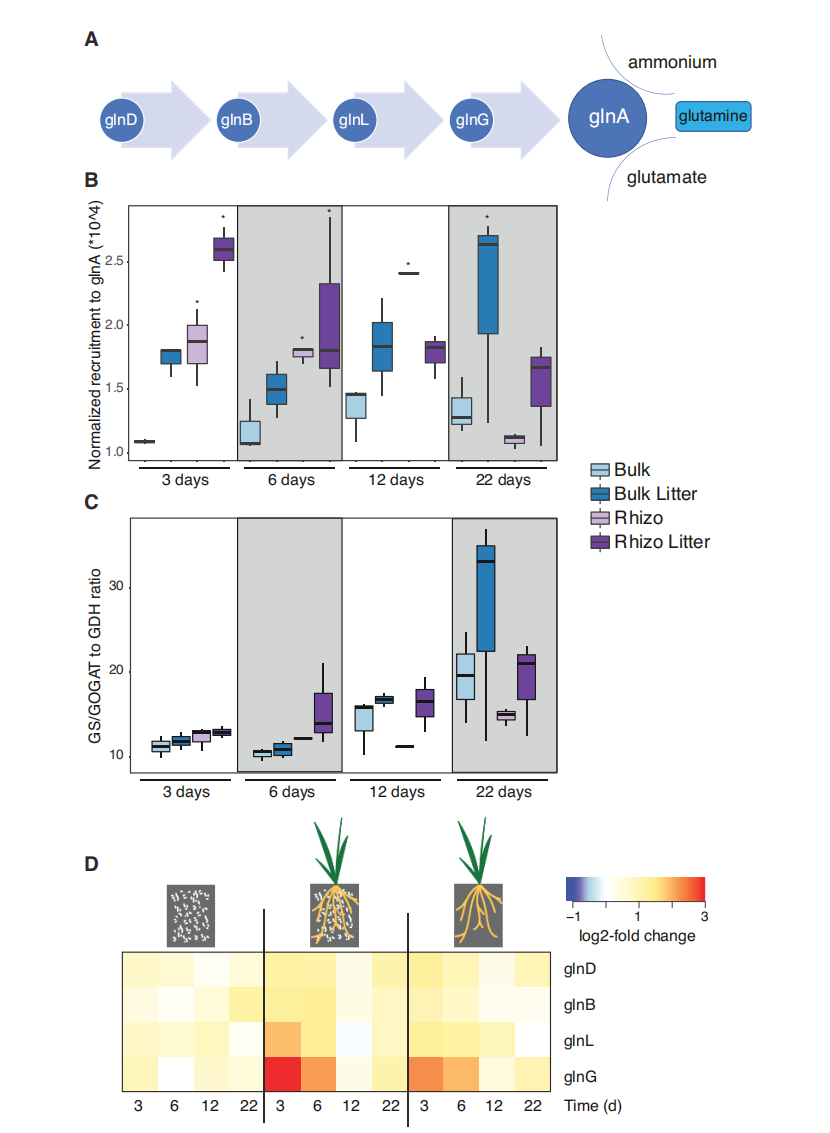
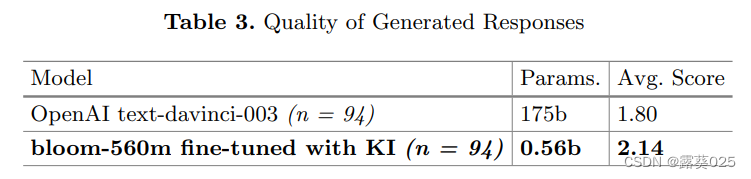curl库是一个用于传输数据的工具和库,它支持多种协议,包括HTTP、FTP、SMTP等。在爬虫中,curl库可以用来获取网页内容,从而实现爬取网页的功能。通过设置curl的选项,可以实现对网页的请求、响应、重定向等操作。在使用curl库时,需要先初始化一个curl资源,然后设置相应的选项,最后执行curl操作并关闭curl资源。

这是一个使用curl库下载网站图片并使用R语言进行下载的程序。
首先,我们需要安装curl库。在R中,我们可以使用以下命令进行安装:
install.packages("curl")
然后,我们可以使用以下代码来下载网站图片:
library(curl)
# 设置proxy_host和proxy_port
proxy_host <- "duoip"
proxy_port <- 8000
# 创建一个curl对象
curl_obj <- curl$new()
# 设置代理
curl_obj$set_proxy(proxy_host, proxy_port)
# 设置URL
curl_obj$set_url("目标网址")
# 设置下载文件的路径
curl_obj$set_filename("dianping_image.jpg")
# 执行下载操作
curl_obj$perform()
以上代码首先设置了proxy_host和proxy_port,然后创建了一个curl对象。然后,我们设置了URL和下载文件的路径,最后执行了下载操作。
注意:在实际使用中,可能需要根据实际情况调整proxy_host和proxy_port,以确保能够正确访问目标网站。同时,也需要确保下载的文件路径是有效的,以确保能够正确保存下载的文件。