随机链表的复制
138. 随机链表的复制 - 力扣(LeetCode)
我们为什么要拷贝原链表的结点一个个链接到原链表结点的后面?
其实就建立了原链表结点与拷贝链表每个结点的一种映射关系, 方便我们设置拷贝结点的random域。
那我们现在C++有了map:
1.首先我们定义一个map,然后遍历原链表,依次拷贝结点,在map中建立源节点与拷贝结点的映射,并链接拷贝链表.
2.然后, 再遍历原链表用来设置拷贝结点的random域:
如果源节点的random指向空,那么拷贝结点random也指向空;如果源节点不指向空,那拷贝结点就指向map中对应源节点的random指向的结点对应的拷贝结点

class Solution {
public:
Node* copyRandomList(Node* head)
{
map<Node*,Node*> m;
Node* cur = head;
Node* copyhead = nullptr;
Node* copytail = nullptr;
while(cur)
{
Node* node = new Node(cur->val);
m[cur] = node;
if(copyhead == nullptr)
{
copyhead = copytail = node;
}
else
{
copytail->next = node;
copytail = copytail->next;
}
cur = cur->next;
}
cur = head;
while(cur)
{
if(cur->random == nullptr)
{
m[cur]->random = nullptr;
}
else
{
m[cur]->random = m[cur->random];
}
cur = cur->next;
}
return copyhead;
}
};前K个高频单词
692. 前K个高频单词 - 力扣(LeetCode)
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序.如果不同的单词有相同出现频率,按字典顺序 排序。
对列表里面每个单词出现的次数做一个统计, 然后要返回前k个出现次数最多的单词,这就是一个TOP-K问题。那这道题其实比较需要注意的地方是如果有不同的单词出现相同的次数, 这些相同次数的单词要按字典顺序 排序。
先统一一下次数:
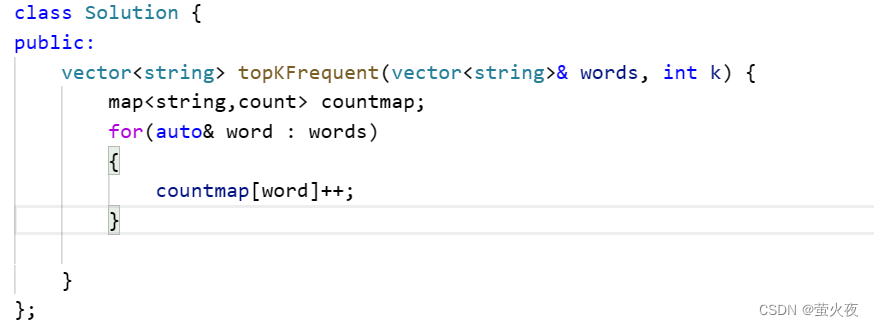
1.TOP-K可以用优先级队列去实现, 这是一种方法,
2.还有一种方法, 可以直接按照次数对所有单词进行一个排序,排个降序,然后前K个单词就是要返回的结果, 但map默认是按照key的大小进行排(插入的时候比较的是key的大小)的,而我们想要的排序是按照次数(value)排的,所以不行。
要排序的话:
库里面不是有一个排序算法sort可以排,但是,map不能用sort,因为sort要求传入的迭代器必须是随机迭代器,而map的迭代器是双向迭代器
所以我们可以把map里面的元素拷贝到vector里面再用sort排序。
 但是, 现在我们的vector里面存的是pair,pair虽然也支持比较大小, 它重载了这些比较运算符, 但是它的比较规则不是这里我们想要的
但是, 现在我们的vector里面存的是pair,pair虽然也支持比较大小, 它重载了这些比较运算符, 但是它的比较规则不是这里我们想要的
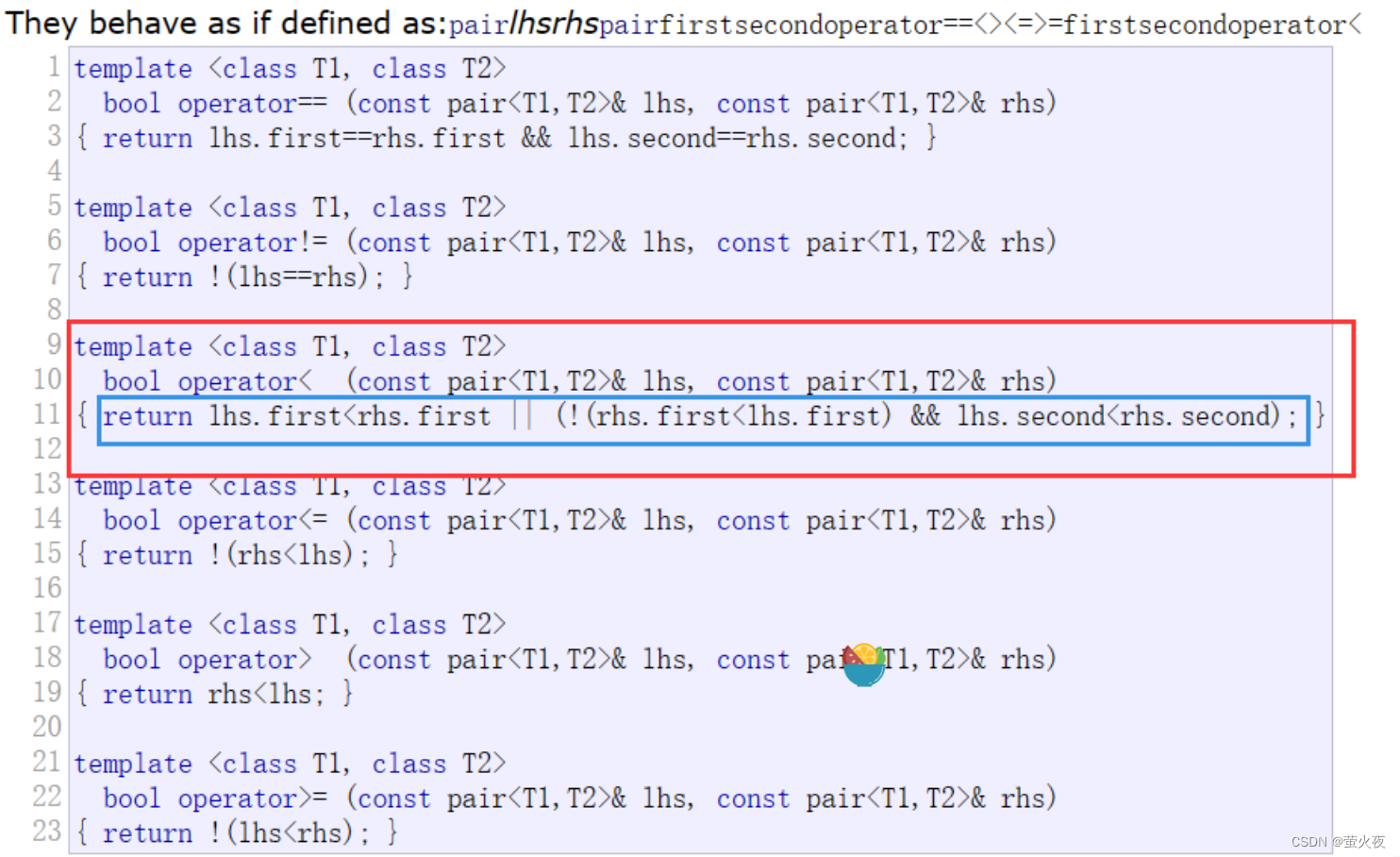
它比较的时候是先看两个的first满不满足小于,不满足再去看second是否满足小于。
但是我们要按照次数和单词综合来进行比较, 还不单是second比较, 另外sort默认还是升序,我们这里取TOP-K的话搞成降序比较好。
那既然不行,我们就可以自己写一个比较的仿函数(也可以写成函数传函数指针),因为sort是可以由我们自己指定比较方式的

首先判断p1和p2的second谁大, p1大排在前面, 如果p1和p2的second相等再按字典序判断,即判断p1和p2谁的first小, 谁排在前面
为什么还需要额外去判断字典序?
我们放到map里面统计好次数, 这时候虽然不是按次数进行排序,是按照key即first排序的。所以我们放到map里面之后单词的前后顺序其实就是按照字典顺序排好了,我们后面的排序只需要按照次数再排一下就好了。
但是:
这涉及到排序是否稳定, 因为有可能有次数相同的单词, 本来没按次数排之前它们的前后顺序是正确的(是按字典顺序的),但是如果按次数排序的时候,快排不稳定,会导致这些次数相同的单词的前后顺序发生改变啊。
sort底层是快排,不稳定,所以需要再额外调整字典序
排好序的话我们取到前k个就好了(注意最终返回只要单词)

class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
struct cmp
{
bool operator()(pair<string,int> p1, pair<string,int> p2)
{
return p1.second > p2.second || p1.second == p2.second && p1.first < p2.first;
}
};
map<string,int> countmap;
for(auto& word : words)
{
countmap[word]++;
}
vector<pair<string,int>> v(countmap.begin(),countmap.end());
sort(v.begin(),v.end(),cmp());
vector<string> ret;
for(int i = 0;i <k;i++)
{
ret.push_back(v[i].first);
}
return ret;
}
};法二:
除了sort,算法库里面还提供了一个稳定的算法——stable_sort
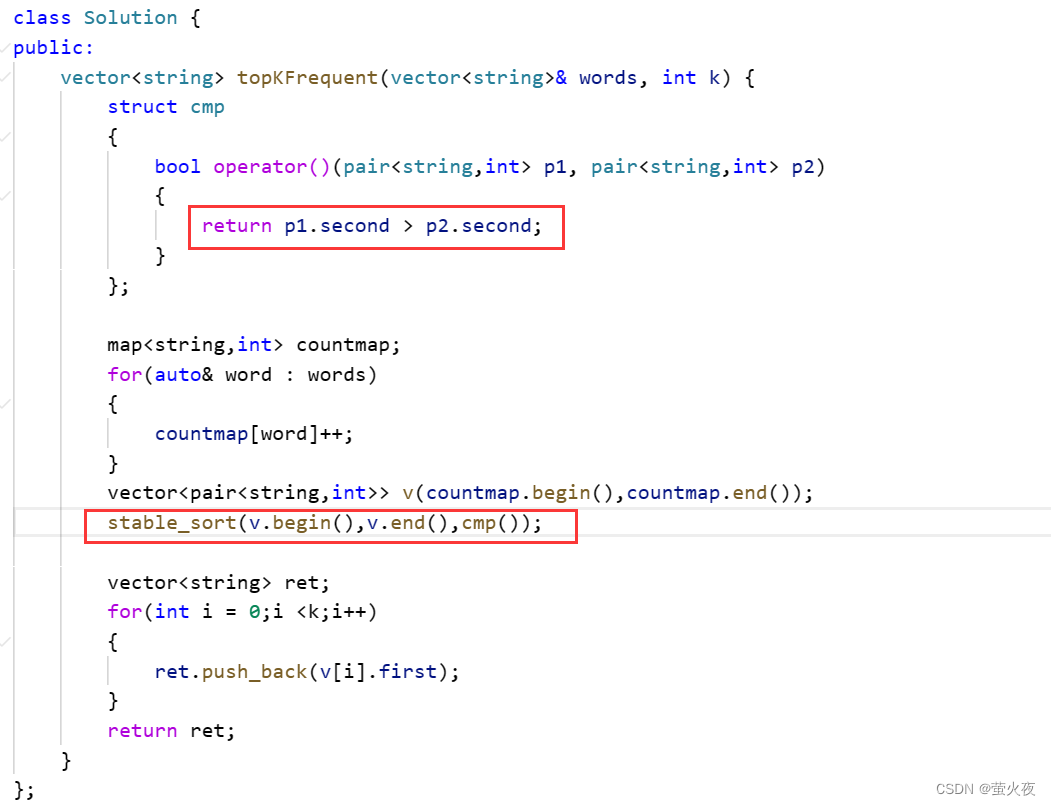
用stable_sort保证原来初始的字典序, 然后只需要再按照second排序即可
法三:
那其实不用sort,也可以用利用set排序.
怎么做呢?
前面我们统计好次数不是放到一个map里面了, 那我们可以把它再放到一个set里面,但是set默认的排序肯定是不行的, 我们排序的时候要按次数比较, 但是次数相同的时候要保证字典顺序小的在前面。所以我们还是要自己写一个仿函数:

注意我们这个仿函数, 有时候他里面会用const对象调用, 所以以后写这个仿函数最好把const加上
两个数组的交集
349. 两个数组的交集 - 力扣(LeetCode)

给我们两个数组,要求我们返回它们的交集,交集中每个元素必须是唯一的。
第一步我们先对两个数组进行排序加去重(因为最终输出结果中元素要唯一, 排序的话有助于我们后面找),那排序的话我们可以用sort, 然后去重其实库里面也有去重算法——unique
但是直接一个set就搞定了:

其实算法库里面也是有求这些集合的算法的:
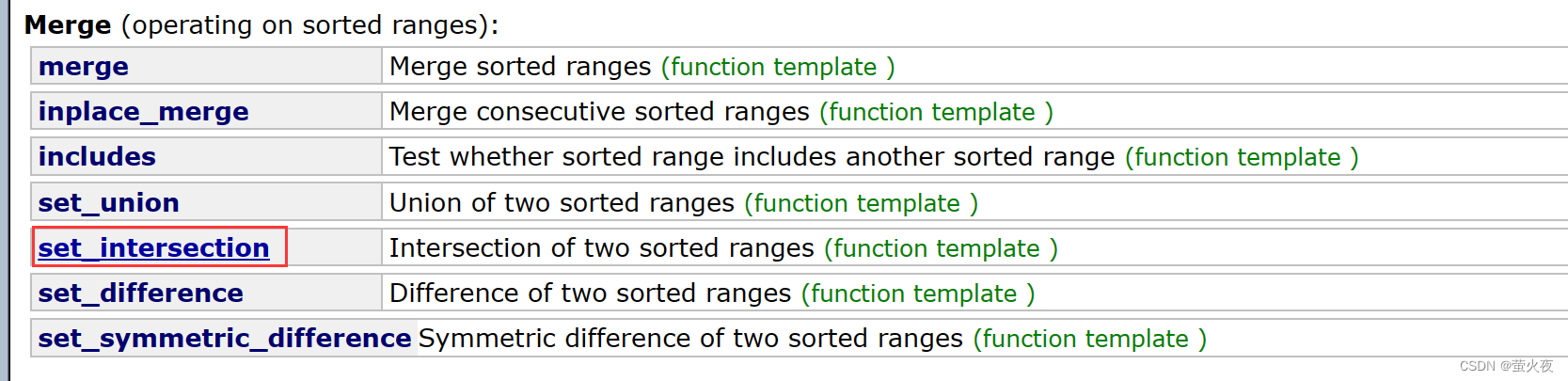

目标容器ret必须具有足够的空间来存储交集元素。可以使用std:back_inserter迭代器适配器或者事先调整目标容器的大小来确保这一点
如果正常写怎么求交集?
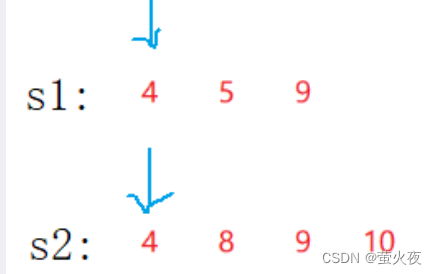
双指针去遍历,两个元素相同,就是交集,同时++;不相同,小的++.为什么要小的++?因为两者不相同,小的++后面还有可能与大的相同, 而大的后面不可能有与这个小的相同的了.
有一个集合遍历完就结束 .
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2)
{
set<int> s1(nums1.begin(),nums1.end());
set<int> s2(nums2.begin(),nums2.end());
auto it1 = s1.begin();
auto it2 = s2.begin();
vector<int> ret;
while(it1 != s1.end() && it2 != s2.end())
{
if(*it1 == *it2)
{
ret.push_back(*it1);
it1++;
it2++;
}
else if(*it1 < *it2)
{
it1++;
}
else
{
it2++;
}
}
return ret;
}
};









![[云原生1. ] Docker consul的详细介绍(容器服务的更新与发现)](https://img-blog.csdnimg.cn/3366663e031649bfbb3ba037ab0d8625.png)