文章目录
- 一、概述
- 1.数据挖掘能做什么?
- 2.数据挖掘在哪些方面有应用?
- 3.数据挖掘与数据分析的区别?
- 4.数据挖掘的四大类模型
- 5.什么是数据挖掘?
- 6.数据挖掘的常用方法?
- 二、数据
- 1.余弦相似度、欧几里得距离
- 2.近似中位数
- 三、数据预处理
- 1.数据预处理主要有哪些方法,每个方法主要内容是什么?
- 2.在数据挖掘中为什么要对数据进行预处理?
- 3.可以使用概念分层来泛化数据,对于数值属性和分类属性一般可以如何生成概念分层
- 4.距离阈值相关例题(重要)
- 5.规范化例题(重要)
- 6.等宽分箱例题(重要)
- 四、数据仓库与OLAP
- 1.数据库与数据仓库的区别?
- 2.简述数据仓库体系结构
- 3.简述数据仓库的设计步骤
- 4.简述OLAP和数据仓库的关系
- 5.简述有哪些OLAP基本操作
- 6.学生成绩管理系统设计
提示:以下是本篇文章正文内容,下面案例可供参考
一、概述
1.数据挖掘能做什么?
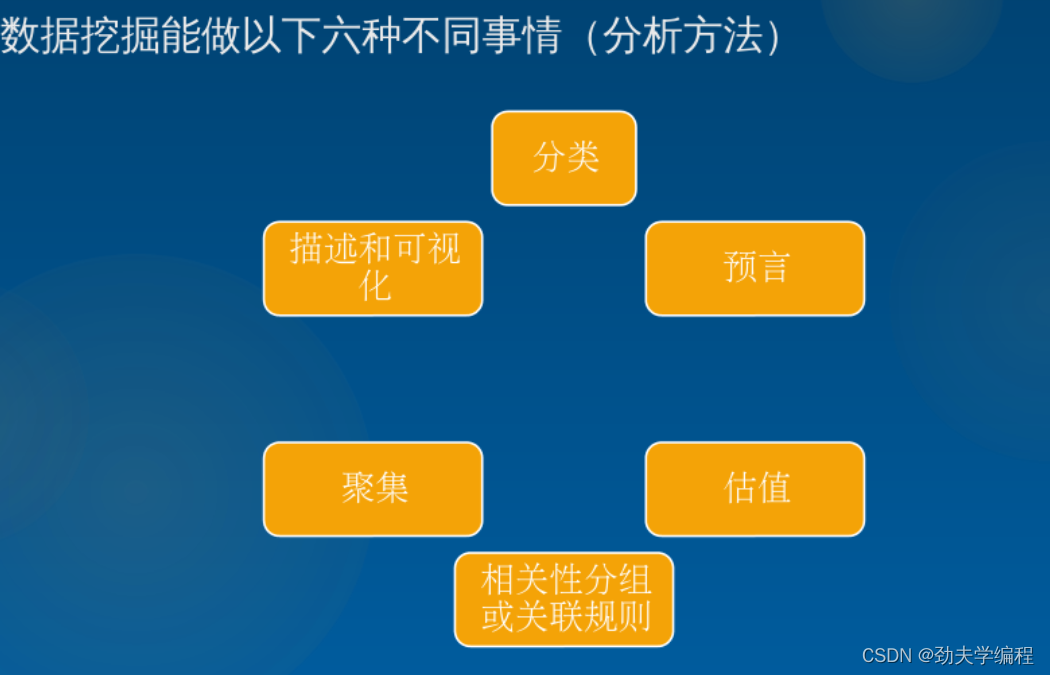
2.数据挖掘在哪些方面有应用?

3.数据挖掘与数据分析的区别?
数据分析更多采用统计学的知识,对源数据进行描述性和探索性分析,从结果中发现价值信息来评估和修正现状。而数据挖掘不仅仅用到统计学的知识,还要用到机器学习的知识,这里会涉及到模型的概念。数据挖掘具有更深的层次,来发现未知的规律和价值
4.数据挖掘的四大类模型
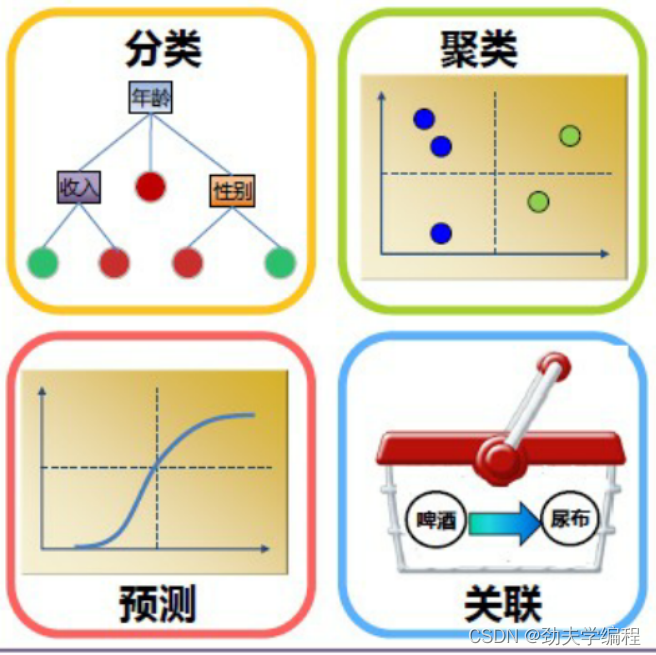
5.什么是数据挖掘?
数据挖掘(Data Mining)就是从大量的数据中,提取隐藏在其中的,事先不知道的、但潜在有用的信息的过程。(简单讲:从海量数据中找到有价值的金矿)
6.数据挖掘的常用方法?
频繁模式、分类与回归、聚类分析、离群点分析
二、数据
1.余弦相似度、欧几里得距离
对于向量x和y,计算指定的相似性或距离度量
求x=(1,1,1,1),y=(2,2,2,2)的余弦相似度、欧几里得距离。
2.近似中位数
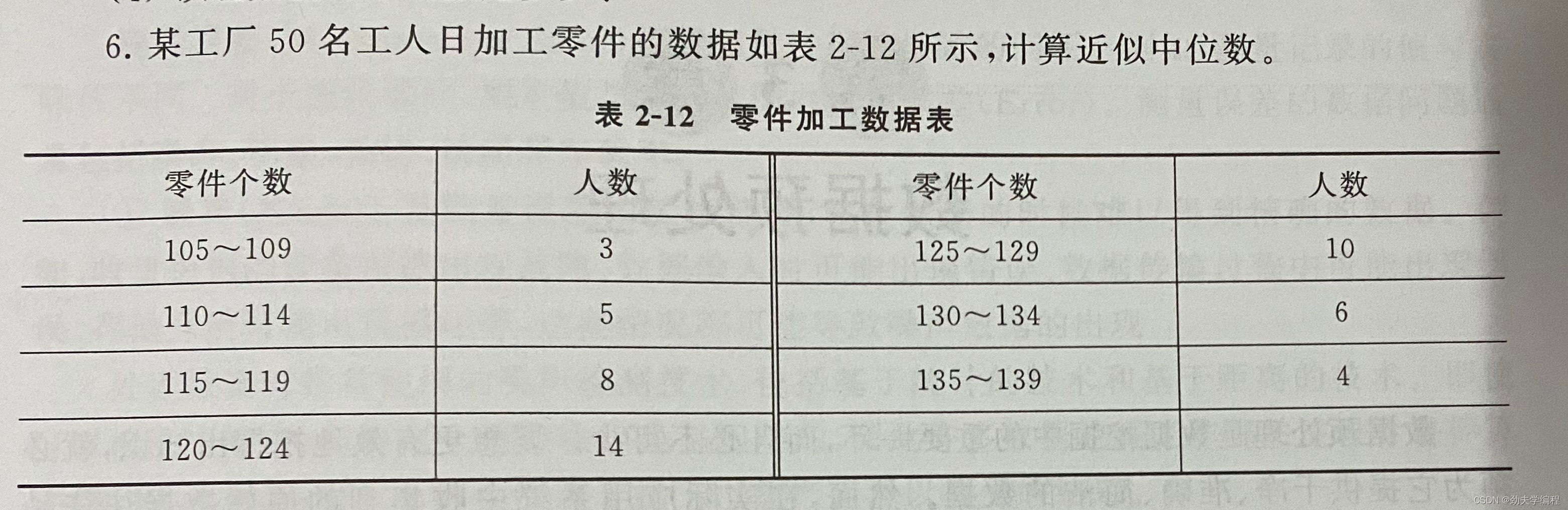


三、数据预处理
1.数据预处理主要有哪些方法,每个方法主要内容是什么?
数据清洗:去掉数据中的噪声,纠正不一致
数据集成:将多个数据源合并成一致的数据存储,构成一个完整的数据集
数据转换:将一种格式的数据转换成另一种格式的数据
数据规约:通过聚集、删除冗余属性或聚类等方法来压缩数据
2.在数据挖掘中为什么要对数据进行预处理?
数据预处理的目的是使得数据更易于数据挖掘模型处理
3.可以使用概念分层来泛化数据,对于数值属性和分类属性一般可以如何生成概念分层
数值属性:概念分层可以根据数据的分部自动地构造
分类属性:如果分类属性是序数属性,可以使用类似于处理连续属性方法的技术以减少分类值的个数
如果分类属性是标称的或者无序的,就需要使用其他方法。
4.距离阈值相关例题(重要)
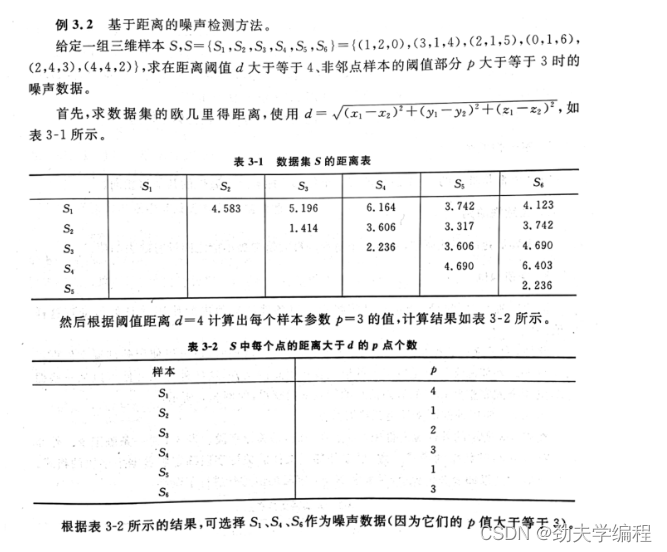
引例:使用例3.2中的数据,求出距离阈值为6,非邻点样本的阈值部分为2的噪声数据。
5.规范化例题(重要)


6.等宽分箱例题(重要)
用等宽分箱技术对排序后的数据集D=(0,0,2,2,2,4,8,8,8,12,12,12,12,15,15,16,16,16,16,21,21,21,25,25,25,25,25,28,28,29,34,34,34,34,37,37,44,44,44,58,58,58,58,58,63,63,66,66,66,69,74,74,74,78,78)进行离散化,使得每箱宽度不大于5,形成概念分层。

四、数据仓库与OLAP
1.数据库与数据仓库的区别?
1.数据库存储的是原始数据,没有经过任何加工;
数据仓库是为了满足数据分析需要设计的,
对源数据进行了ELT过程,数据抽取工作分抽取、清洗、转换、装载
2.数据仓库的数据量要比数据库大很多
2.简述数据仓库体系结构
数据从操作型数据库、文件、网络等数据源,通过ETL集成工具进行数据抽取、清洗、转换、加载等工作,进入到数据仓库和数据集市中,进而通过OLAP服务器支持前台的多维分析,查询报表、数据挖掘等操作
3.简述数据仓库的设计步骤
概念模型设计、技术准备工作、逻辑模型设计、物理模型设计、数据仓库生成、数据仓库运行与维护
4.简述OLAP和数据仓库的关系
数据仓库与OLAP的关系是互补的,现代OLAP系统一般以数据仓库为基础,即从数据仓库中抽取详细数据的一个子集并经过必要的聚集存储到OLAP存储器中供前端分析工具读取
5.简述有哪些OLAP基本操作
OLAP允许用户从多种角度分析多维数据,包括以下五种基本操作:上卷、下钻、切片、切块、旋转
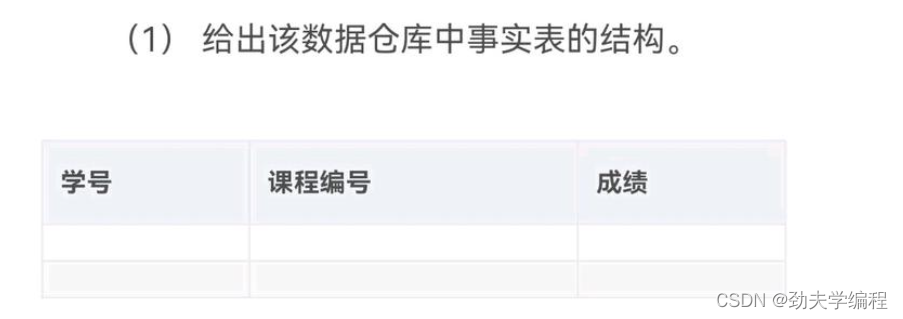
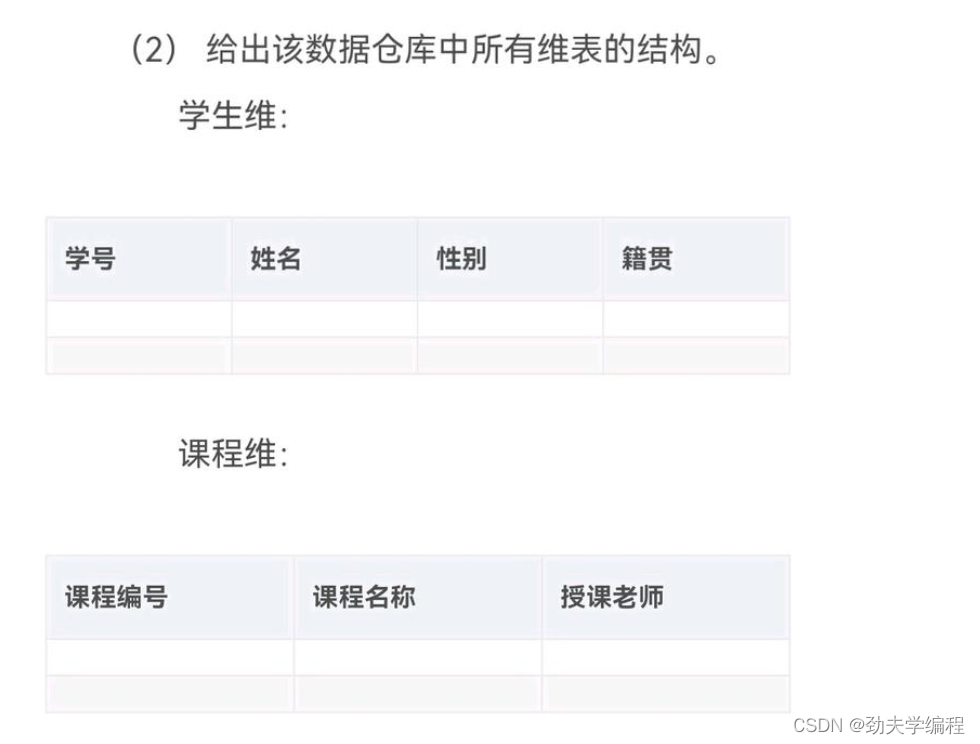
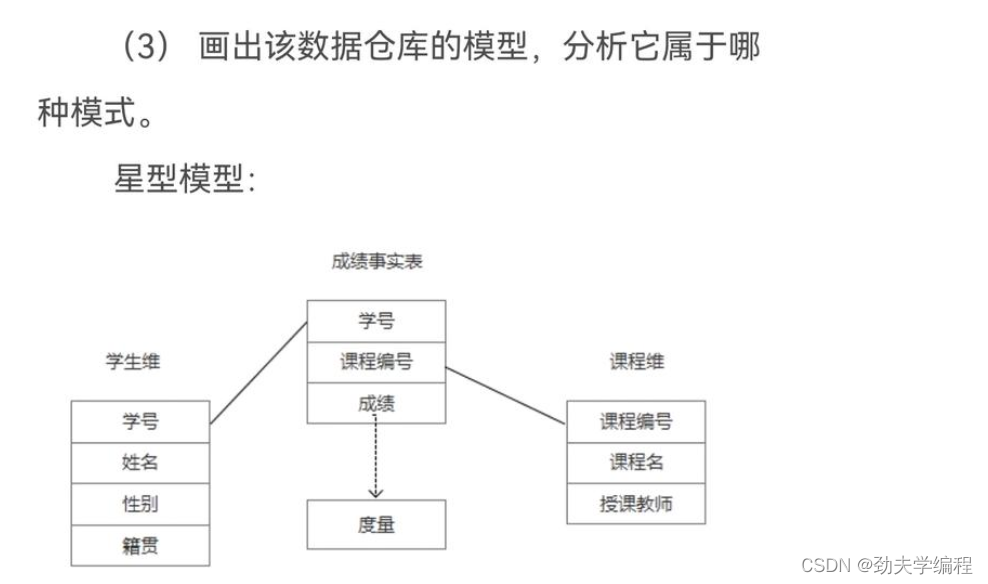
6.学生成绩管理系统设计