一、PVT++: A Simple End-to-End Latency-Aware Visual Tracking Framework
paper:
https://openaccess.thecvf.com/content/ICCV2023/papers/Li_PVT_A_Simple_End-to-End_Latency-Aware_Visual_Tracking_Framework_ICCV_2023_paper.pdf
github: https://github.com/Jaraxxus-Me/PVT_pp.git
1、摘要
视觉物体跟踪对智能机器人至关重要。现有的大多数方法都忽略了在现实处理过程中所带来的在线延迟可能导致严重的性能下降。特别是对于无人机(uav),其中鲁棒跟踪更具挑战性,机载计算有限,延迟问题可能是致命的。在这项工作中,我们提出了一个简单的端到端延迟感知跟踪框架,即端到端预测视觉跟踪(PVT++)。与现有的在跟踪器之后添加卡尔曼滤波器的解决方案不同, PVT++可以联合优化,因此它不仅需要运动信息,还可以利用大多数预训练的跟踪器模型中丰富的视觉知识进行鲁棒预测。 此外,为了弥合训练-评估领域的差距,我们提出了一个 相对的运动因子 ,使PVT++能够推广到具有挑战性和复杂的无人机跟踪场景中。这些精心的设计使小容量轻型PVT++成为一个广泛有效的解决方案。此外,这项工作提出了一个扩展的延迟感知评估基准,用于评估在线设置中的任意速度跟踪器。从空中角度在机器人平台上的实验结果表明,PVT++可以在各种跟踪器上获得显著的性能提高,并且比之前的解决方案具有更高的精度,在很大程度上减轻了延迟带来的退化。
🔺该思路能在uav场景提点的原因在于处理好了高帧率。对于uav场景,无人机的运动加上目标运动,会造成目标在画面中有较大的位移,有一定概率会脱离sot tracker的search范围,提高帧率可以避免该情况。然而相机的旋转等运动也会让目标在画面中有较大的形变,仅仅依靠卡尔曼滤波来做propagation是不具有准确框的回归预测能力的。这篇工作中加入了视觉特征弥补了这一点。
2、方法
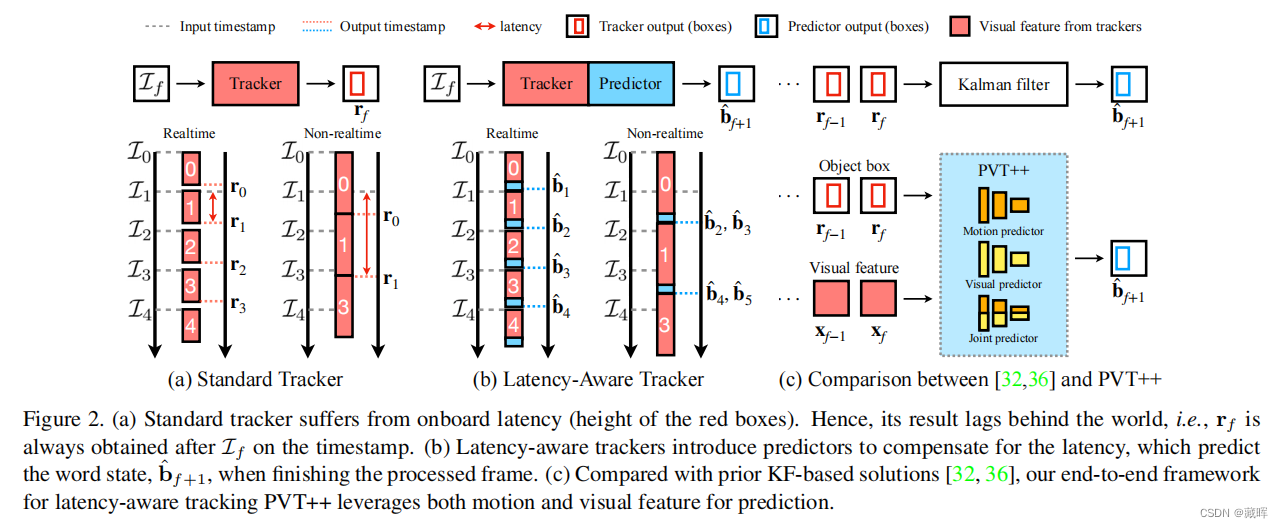
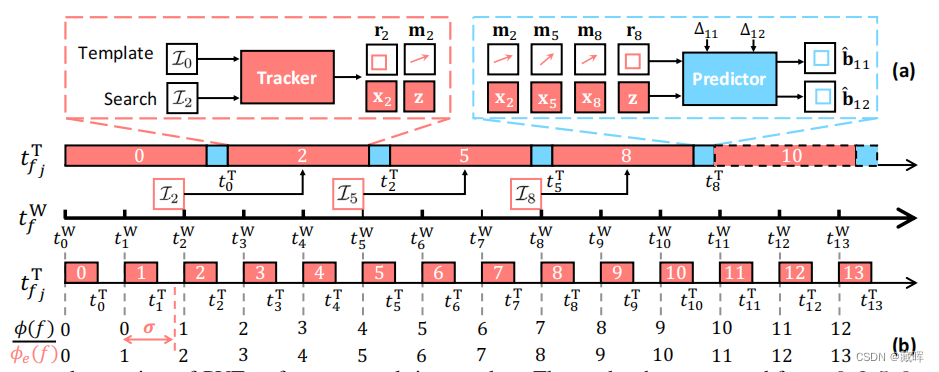
作者提出了一个predictor网络,与SOT tracker一起结合,实现real-time的跟随。
perdictor网络利用历史帧的图像视觉信息和运动预测信息(速度,编码方式文中做了些巧妙的编码处理)为输入,结合帧间间隔,预测在中间帧的box。
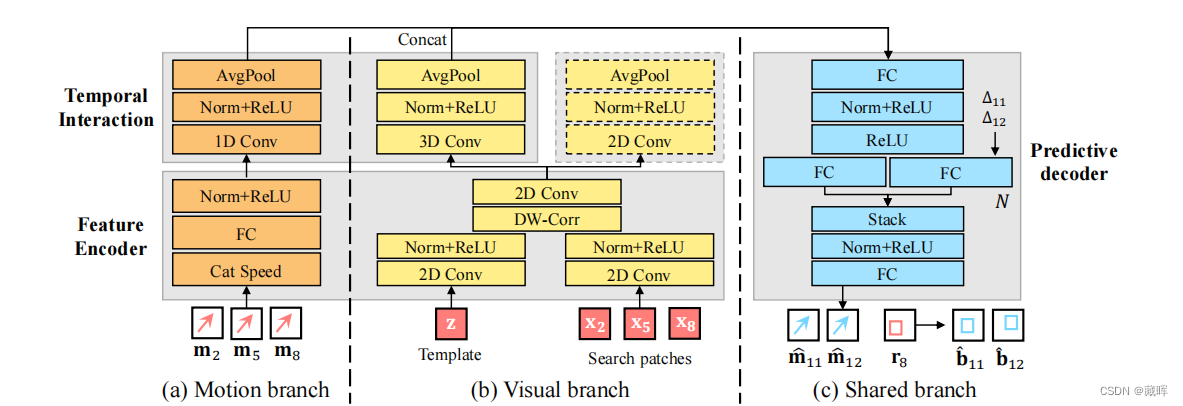
predictor网络结构如下图所示,由于feature encoder部分可以共用之前的结构,predictor网络的计算量不大,这也使得其推理速度得到保证。
二、Tracking by 3D Model Estimation of Unknown Objects in Videos
paper:
https://openaccess.thecvf.com/content/ICCV2023/papers/Rozumnyi_Tracking_by_3D_Model_Estimation_of_Unknown_Objects_in_Videos_ICCV_2023_paper.pdf
1、摘要
大多数无模型的视觉目标跟踪方法将跟踪任务表述为由每个视频帧中的mask或者box的iou matching。我们认为这种表示是有限的,而是建议用一个显式的物体表示来指导和改进二维跟踪,即在每个视频帧中的纹理三维形状和6自由度姿态。我们的表示解决了一个复杂的长期密集的所有三维点之间的对应问题,包括一些点是不可见的帧。为了实现这一点,估计是通过重新渲染输入的视频帧以及可能通过可微渲染来驱动的,这是以前没有用于跟踪的。提出的优化最小化一个新的损失函数,以估计最佳三维形状,纹理和6自由度姿态。我们改进了最先进的二维分割跟踪在三个不同的数据集与大多数刚性对象。
2、方法
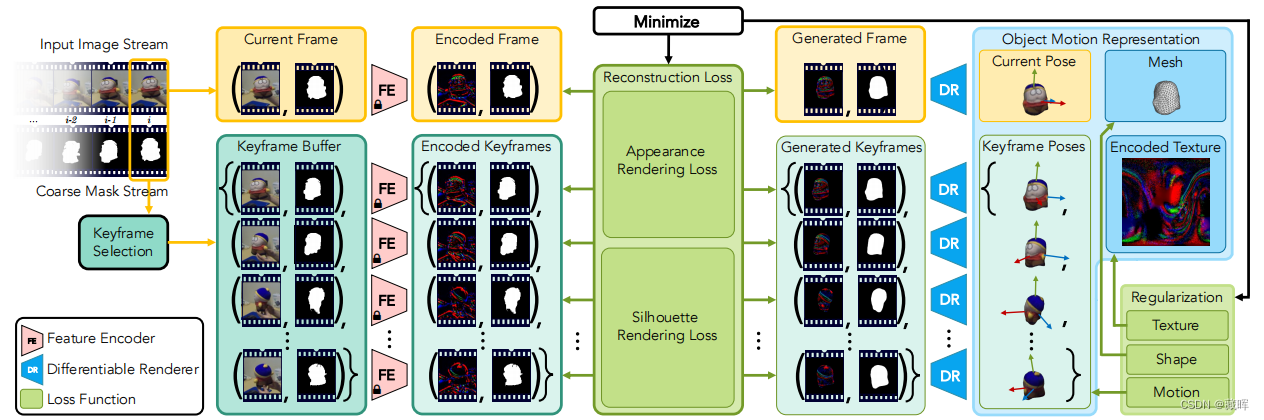
所提出的方法处理一系列的图像和粗糙的mask,估计三维物体的形状、纹理和6个自由度姿态。类似于训练一个GAN的生成网络。在inference的使用通过原始图像和mask信息来渲染目标,目的利用目标渲染的方式去除mask的错误分割(如下图所示),获得精确的跟踪结果。

三、TrackFlow: Multi-Object tracking with Normalizing Flows
paper:
https://openaccess.thecvf.com/content/ICCV2023/papers/Mancusi_TrackFlow_Multi-Object_tracking_with_Normalizing_Flows_ICCV_2023_paper.pdf
1、摘要
多目标跟踪领域最近出现了人们对Tracking-by-detection模式重新产生的兴趣,因为它的简单性和强大的先验使它免于像Tracking-by-attention方法一样需要复杂的设计和细致的设定。鉴于这一点,我们的目标是将通过检测的跟踪扩展到多模态设置,其中必须从异构信息中计算出综合成本,如二维运动线索、视觉外观和姿态估计。更准确地说,我们遵循一个案例研究,其中对3D信息的粗略估计也是可用的,并且必须与其他传统指标(例如,IoU)合并。为了实现这一点,最近的方法诉诸于简单的规则或复杂的启发式方法来平衡每个成本的贡献。然而 i)它们需要仔细调整dataset上的超参数,并且 ii)它们暗示这些成本是独立的,而这在现实中并不成立。我们通过建立一个优雅的概率公式来解决这些问题,该公式将候选关联的代价视为由深度密度估计器产生的负对数似然,通过训练来建模正确关联的条件联合概率分布。我们在模拟和真实基准上进行的实验表明,我们的方法持续地提高了几Tracking-by-detection算法的性能。
2、方法
文中主要分为两部分。
1、提出了一个单目标深度估计网络来估计深度
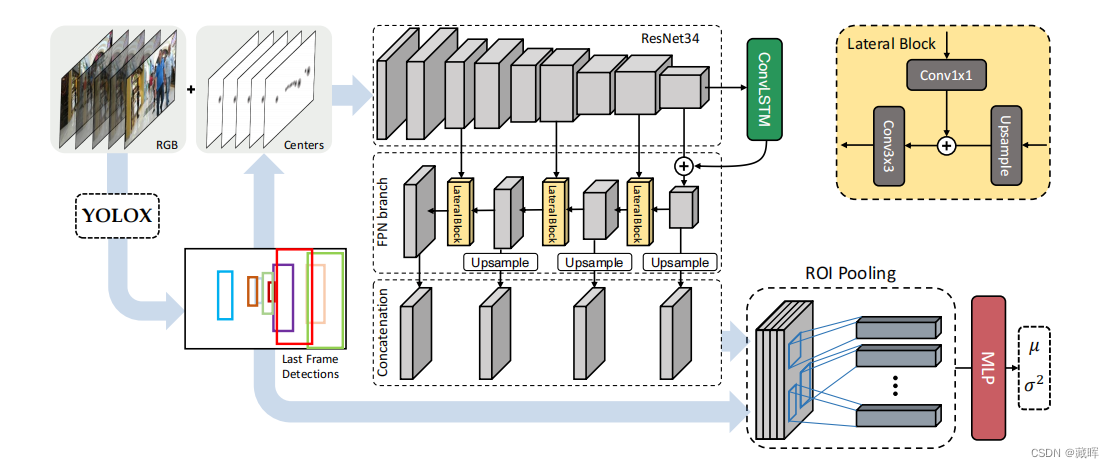
网络从一个短视频剪辑中预测每个物体的距离。文中额外提供了每个边界框的中心作为一个额外的输入通道。在几个卷积块独立处理每一帧之后: i)设计了一个时间模块来提取时间模式;ii)激活地图经历FPN分支,以保留局部细节。最后,来自不同层的特征映射被堆叠并传递到RoI池化层。后者产生每个行人的向量表示,我们最后用它来预测行人的期望距离µ和不确定性σ2。
2、计算匹配距离
简单来说,本文通过位置、框的大小和深度联合计算了一种匹配距离,如下式。
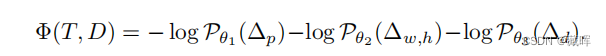
之后通过匈牙利匹配找到最优解。
四、A Fast Unified System for 3D Object Detection and Tracking
paper:
https://openaccess.thecvf.com/content/ICCV2023/papers/Heitzinger_A_Fast_Unified_System_for_3D_Object_Detection_and_Tracking_ICCV_2023_paper.pdf
github: https://github.com/theitzin/FUS3D
1、摘要
我们提出了FUS3D,一个快速和轻量级的系统,用于实时三维目标检测和跟踪边缘设备。我们的方法无缝地将三维目标检测和多目标跟踪的阶段集成到一个单一的、端到端可训练的模型中。FUS3D是专门为室内3D人类行为分析,目标应用于环境辅助生活(AAL)或监测。该系统进行了优化,从而使潜在的敏感数据可以在传感器内处理。此外,我们的系统完全依赖于较少的隐私侵入性的三维深度成像模式,从而进一步突出了我们的方法在敏感领域的应用潜力。当FUS3D在联合检测和跟踪配置中使用时,取得了最好的结果。然而,如果需要,所提出的检测阶段可以作为一个快速独立的目标检测模型。我们在MIPT数据集上对FUS3D进行了广泛的评估,并展示了它在3D对象检测、多目标跟踪和最重要的运行时方面优于现有的最先进方法的性能。
2、方法
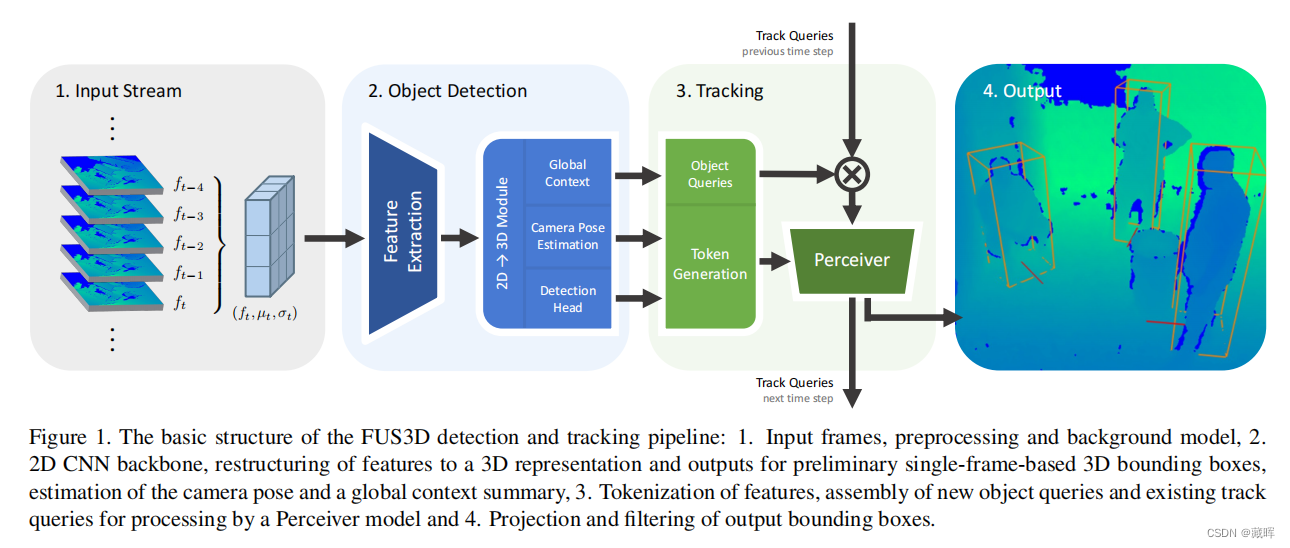
FUS3D基本结构和步骤如下:
1、输入帧预处理,有点像是通过相机的内外参和预估深度将图片中的特征投影到三维空间中
2、2D CNN主干,将特征重组为3D表示和输出初步的基于单帧的三维边界框、摄像机姿态的估计以及联合了上下文信息的特征(文中指用于后续匹配预测的补充信息)。
3、跟随,将历史的track query和当前帧的obj query进行信息融合,用融合后的特征预测匹配结果,类似Trackformer。
4、输出结果。
本文基于轻量化网络可以在嵌入式设备中跑出较快的速度。
五、MixCycle: Mixup Assisted Semi-Supervised 3D Single Object Tracking with Cycle Consistency
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Wu_MixCycle_Mixup_Assisted_Semi-Supervised_3D_Single_Object_Tracking_with_Cycle_ICCV_2023_paper.pdf
github: https://github.com/Mumuqiao/MixCycle
1、摘要
三维单目标跟踪(SOT)是自动驾驶中不可缺少的组成部分。现有的方法严重依赖于大型的、密集标记的数据集。然而,注释点云既昂贵又耗时。受到在无监督的2D SOT中循环跟踪的巨大成功的启发,我们引入了第一种半监督的3D SOT方法。具体来说,我们引入了两种周期一致性的监督策略: 1)自我跟踪周期,利用标签帮助模型在训练的早期阶段更好地收敛;2)前后向循环,增强了跟踪器对运动变化和模板更新策略引起的模板噪声的鲁棒性。此外,我们提出了一种名为SOTMixup的数据增强策略,以提高跟踪器对点云多样性的鲁棒性。SOTMixup通过以混合速率在两点云中采样点生成训练样本,并根据混合速率为训练分配合理的损失权重。由此产生的混合循环方法可以推广到基于外观匹配的跟踪器。在KITTI基准上,基于P2B跟踪器[16],使用10%标签训练的MixCycle优于使用100%标签训练的P2B,当使用1%标签时,精度提高了28.4%。
2、方法
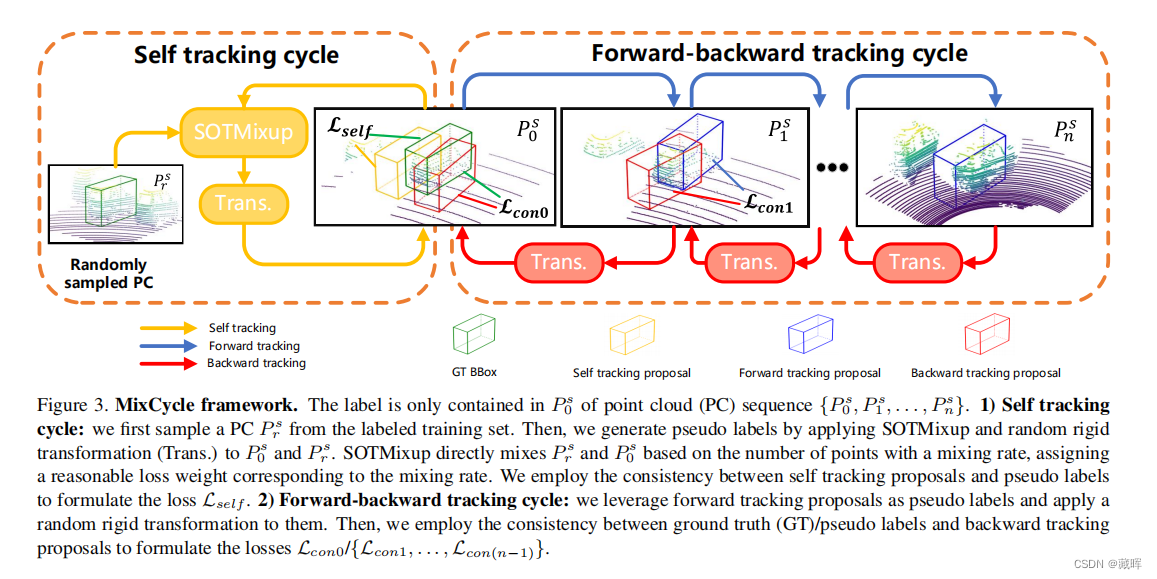
简单来说,这是一个比较经典的自监督方法,用tracking的方式预测一个clip的每一个目标,再反向预测回来,最后用反向预测回来的框和GT算loss(即文中的Forward-backward tracking cycle)。
此外,文中还通过一些随机刚性变换(Trans.)来生成伪标签,用于监督中间过程。
六、Foreground-Background Distribution Modeling Transformer for Visual Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Yang_Foreground-Background_Distribution_Modeling_Transformer_for_Visual_Object_Tracking_ICCV_2023_paper.pdf
1、摘要
视觉目标跟踪是一个具有广泛应用前景的基础研究课题。由于Transformer的快速发展,Transformer tracker取得了很大的进步。然而,这些基于Transformer的跟踪器的特征学习很容易受到复杂背景的干扰。为了解决上述局限性,我们提出了一种用于视觉目标跟踪的前景-背景分布建模Transformer网络(FBDMTrack),包括一个前背景代理学习(FBAL)模块和一个分布感知注意(DA2)模块。提出的F-BDMTrack有几个优点。首先,所提出的FBAL模块可以通过设计的前背景代理有效地挖掘前背景信息。其次,DA2模块可以通过建模前背景分布相似性来抑制前景和背景之间的错误交互。最后,F-BDMTrack可以在不断变化的跟踪场景下提取鉴别特征,以实现更准确的目标状态估计。大量的实验表明,我们的F-BDMTrack在8个跟踪基准上优于之前最先进的跟踪器。
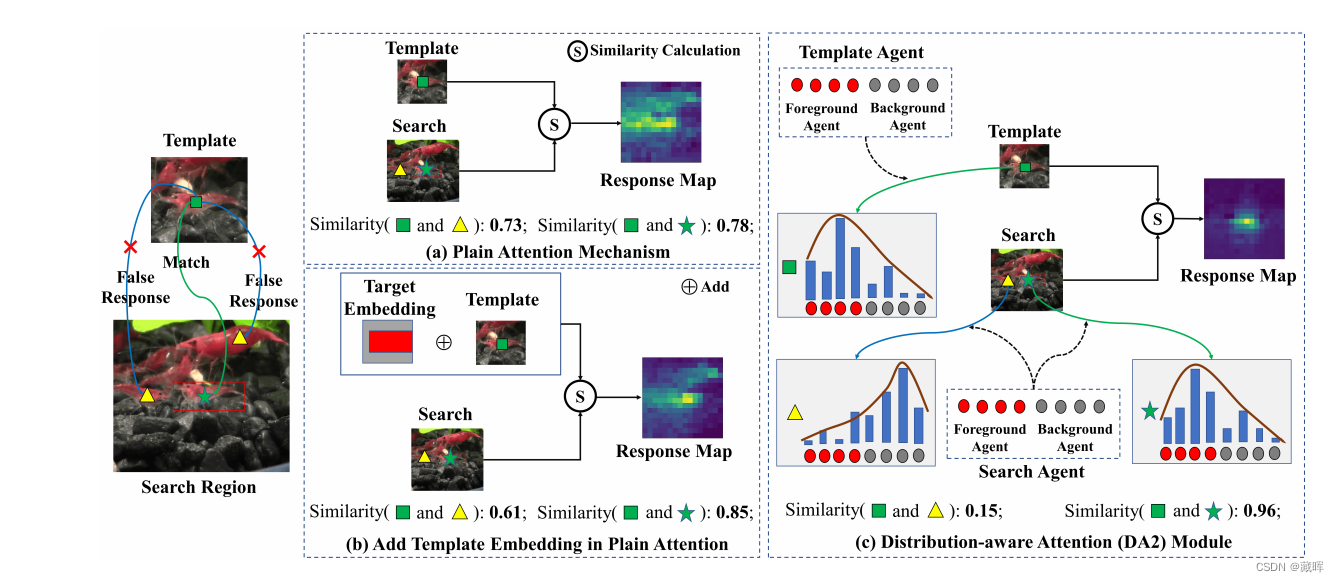
🔺核心思想是通过分布感知让目标与自己更像,与周边其他目标更具有差异性。
2、方法
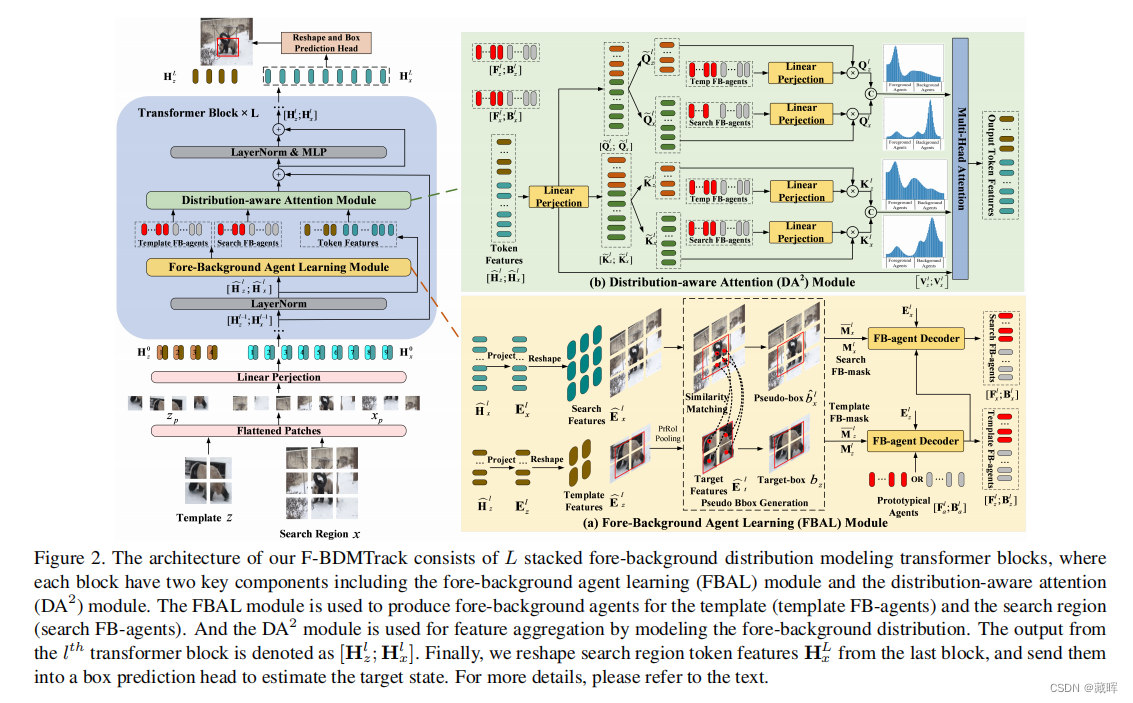
F-BDMTrack的架构由L个堆叠的前背景分布建模transformer模块组成,其中每个块都有两个关键组件,包括前背景代理学习(FBAL)模块和分布感知注意(DA2)模块。
1、FBAL模块
用于为temple和search生成一个高注意力的相应位置。通过计算相似性生成pseudo box,并用该box为权重增强前景的信息。在训练过程中,文中使用搜索区域的真相bbox bx来监督更准确的pseudo bbox生成。
2、DA2模块
通过对前-背景分布进行建模来进行特征聚合(其被作为query和key,而不是外观特性。)。从第1个transformer模块的输出被表示为[Hl z;Hl x]。最后,我们从最后一个块中重塑搜索区域标记特征HL x,并将它们发送到一个盒预测头中,以估计目标状态。
七、Tracking Anything with Decoupled Video Segmentation
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Cheng_Tracking_Anything_with_Decoupled_Video_Segmentation_ICCV_2023_paper.pdf
github: hkchengrex.github.io/Tracking-Anything-with-DEVA
1、摘要
用于视频分割的训练数据的注释成本很高。这阻碍了将端到端算法扩展到新的视频分割任务,特别是在大词汇量设置中。为了在不对每个单独任务的视频数据进行训练的情况下“跟踪任何东西”,我们开发了一种解耦视频分割方法(DEVA),由具有特定任务的图像级分割和类/任务无关的双向时间传播组成。由于这种设计,我们只需要一个针对目标任务的图像级模型(训练成本更低)和一个通用的时间传播模型,该模型只需要训练一次并跨任务进行推广。为了有效地结合这两个模块,我们使用双向传播对来自不同帧的分割假设进行(半)在线融合,以生成一个一致的分割。结果表明,在一些数据稀缺的任务中,大词汇量视频全景分割、开放世界视频分割、参考视频分割等方法都优于无监督视频对象分割。
2、方法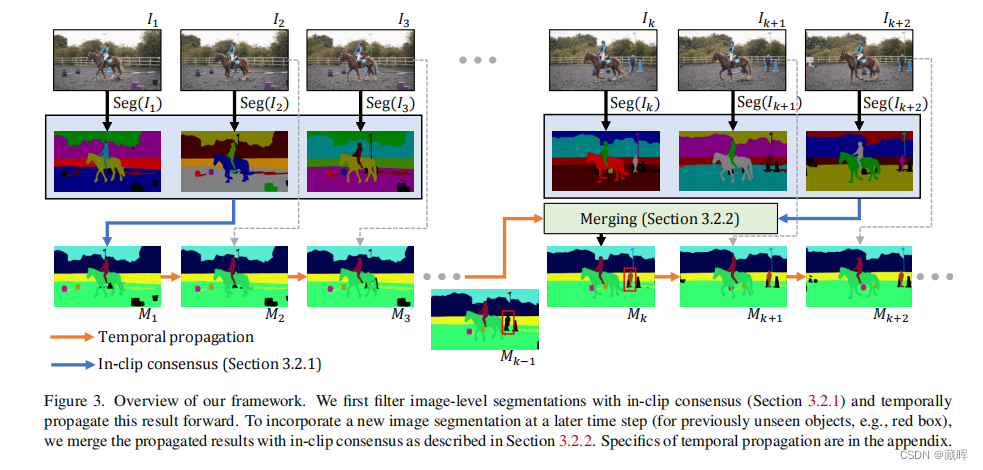
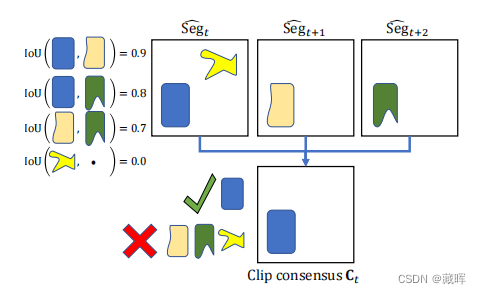
简单来说,就是算相邻帧的iou,并计算iou的总和为支持度。如果一个instance mask的支持度越高,就越可能被关联。
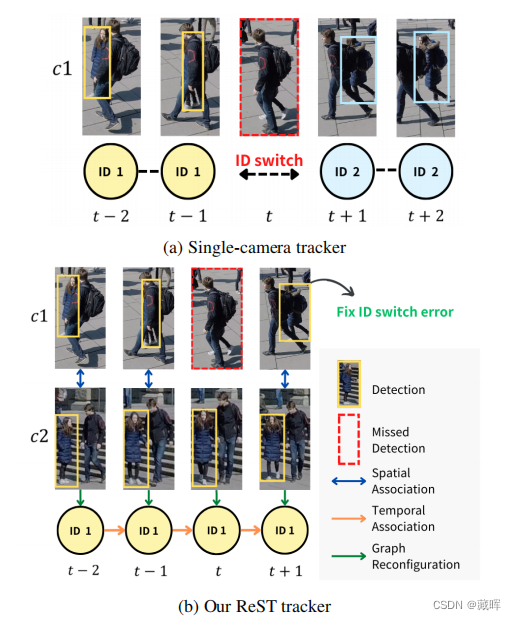
八、ReST: A Reconfigurable Spatial-Temporal Graph Model for Multi-Camera Multi-Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Cheng_ReST_A_Reconfigurable_Spatial-Temporal_Graph_Model_for_Multi-Camera_Multi-Object_Tracking_ICCV_2023_paper.pdf
github: https://github.com/chengche6230/ReST
1、摘要
多摄像机多对象跟踪(MC-MOT)利用来自多个视图的信息来更好地处理遮挡和拥挤场景的问题。近年来,利用基于图的方法来解决跟踪问题已经变得非常流行。然而,目前许多基于图形的方法并没有有效地利用有关时空一致性的信息。相反,他们依赖于单摄像头跟踪器作为输入,这很容易出现碎片化和ID开关错误。在本文中,我们提出了一种新的可重构图模型,该模型首先将所有检测到的物体进行空间关联,然后将其重新配置为时间关联的时间图。这种两阶段的关联方法使我们能够提取鲁棒的空间和时间感知特征,并解决碎片化轨迹的问题。此外,我们的模型是为在线跟踪而设计的,使其适合于真实世界的应用程序。
2、方法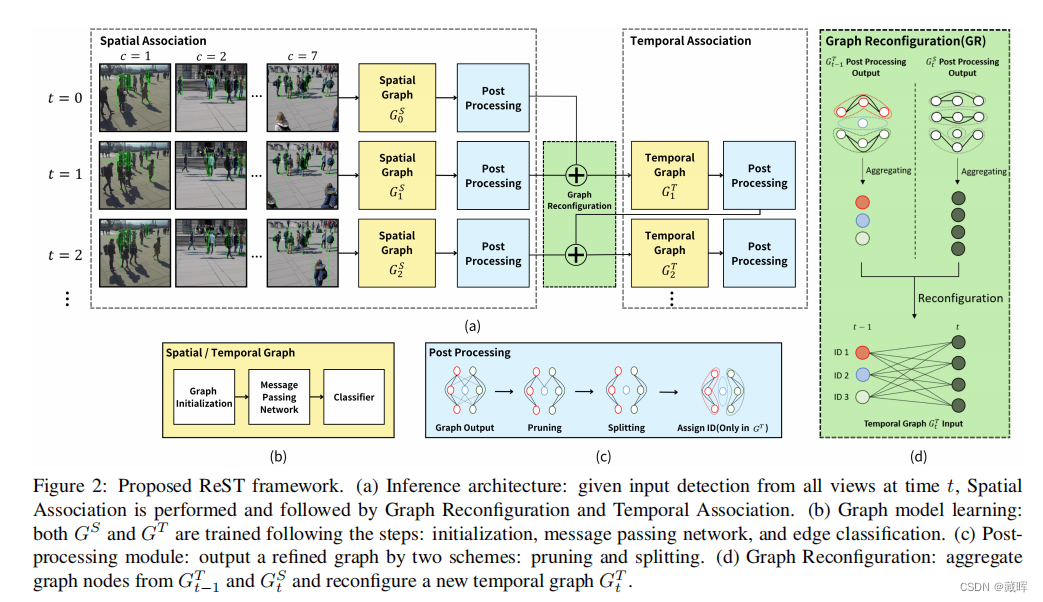
提出的ReST框架。
(a)推理体系结构:给定来自t时刻所有视图的输入检测,执行空间关联,然后进行图重构和时间关联。
(b)图模型学习:GS和GT都按照以下步骤进行训练:初始化、消息传递网络和边缘分类。
©后处理模块:通过修剪和分割两种方案输出一个细化的图(卡阈值,利用一些空间信息做策略)。
(d)图重新配置:从GT t−1和GS t中聚合图节点,并重新配置一个新的时间图GT t。
九、Heterogeneous Diversity Driven Active Learning for Multi-Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Li_Heterogeneous_Diversity_Driven_Active_Learning_for_Multi-Object_Tracking_ICCV_2023_paper.pdf
1、摘要
现有的单级多目标跟踪(MOT)算法,利用大量的标记数据,取得了令人满意的性能。然而,在实际应用中,获取label时间长费力。为了降低人工注释的成本,我们提出了异构多样性驱动的主动多对象跟踪(HD-AMOT),通过观察样本的异构线索来推断任何MOT跟踪器的信息最丰富的帧。HD-AMOT通过对几何信息和语义信息进行编码来定义多样化的信息表示,并将框架推理策略制定为一个马尔可夫决策过程,基于所设计的信息表示来学习最优抽样策略。具体来说,HD-AMOT由一个多样化的信息表示模块和一个信息帧选择网络组成。前者产生表征帧分集和分布的信号,后者接收信号并进行多帧合作,使批帧采样。

🔺作者认为无监督学习不能均匀采样,因为不同帧的信息不同(如上述例子)。文中的方法有利于选出高信息帧。
2、方法
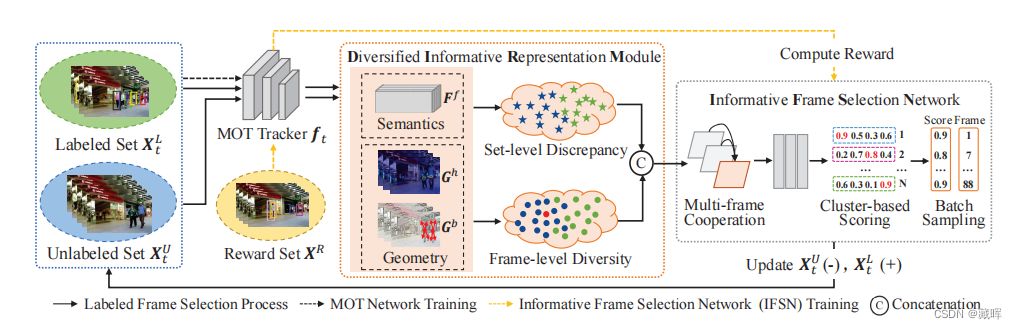
在HD-AMOT方法中执行多次迭代,直到获得标记帧的预算B(采样频率)。在第t次迭代中,步骤如下:
(I) 采用单级MOT跟踪器ft获取各帧上的语义特征Ff和几何信息Gh、Gb等异构线索;
(II)估计设置级差异和帧级多样性,并构建MDP状态-动作对(st,at);
(Ⅲ)进行基于(st、at)的多帧合作;
(Ⅳ) IFSN在多帧合作的协助下,推断出N个需要进行高分标注的未标记帧。同时,通过将新标注的帧从XL t替换到XU t,XL t更新为XU t+1,XL t+1。
(V) 跟踪器ft在XL t+1上重新训练,以获得更新的ft+1。
(Ⅵ)基于XR计算基于ft和ft+1的奖励rt+1,以更新IFSN的参数(在训练数据集中一个奖励集,在这个奖励集合上inference,用实际的MOTA和IDF1来做奖励)。
十、Humans in 4D: Reconstructing and Tracking Humans with Transformers
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Goel_Humans_in_4D_Reconstructing_and_Tracking_Humans_with_Transformers_ICCV_2023_paper.pdf
github: https://shubham-goel.github.io/4dhumans/
1、摘要
我们提出了一种重建人类并随时间跟踪它们的方法。在我们方法的核心,我们提出了一个完全“transformer”版本的人类网格恢复网络。这个网络,HMR 2.0,进步了最先进的技术水平,并展示了分析过去难以从单一图像中重建的不寻常姿态的能力。为了分析视频,我们使用HMR 2.0的3D重建作为输入到3D操作的跟踪系统的输入。这使我们能够处理多人,并通过遮挡事件来保持身份。我们完整的方法,4DHumans,在单摄像头跟踪(类别为人)中实现了最先进的结果。此外,我们还展示了HMR 2.0在动作识别的下游任务上的有效性,与以往的基于姿态的动作识别方法相比,它取得了显著的改进。

2、方法
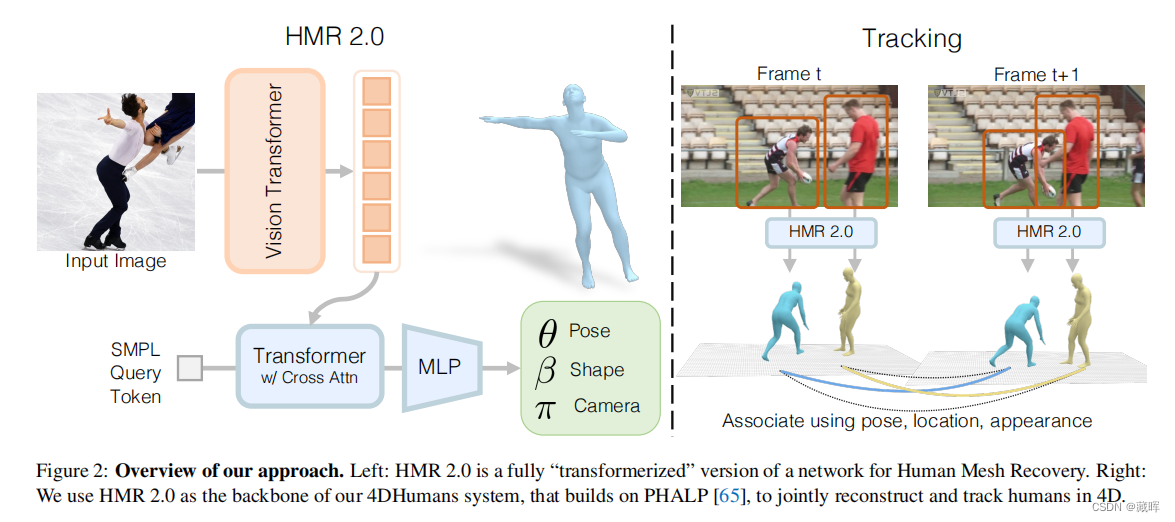
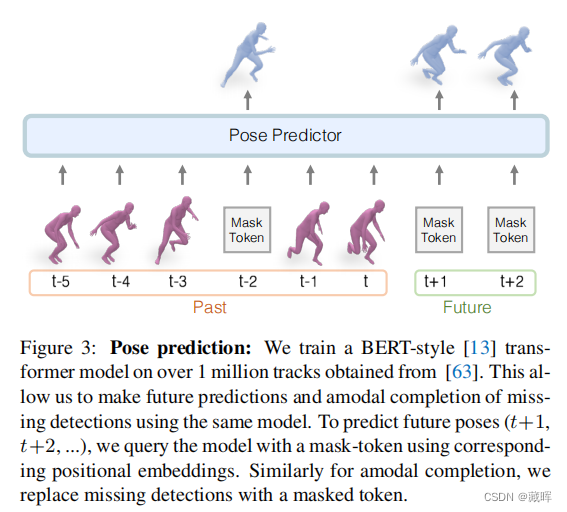
文中思想是通过pose网络预测物体在3D上的外观、位置和姿态,用这些信息做关联。
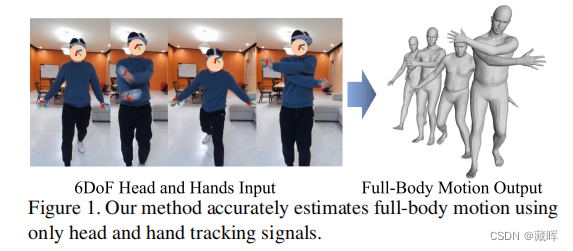
十一、Realistic Full-Body Tracking from Sparse Observations via Joint-Level Modeling
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Zheng_Realistic_Full-Body_Tracking_from_Sparse_Observations_via_Joint-Level_Modeling_ICCV_2023_paper.pdf
github: https://zxz267.github.io/AvatarJLM
1、摘要
为了为快速开发的VR/AR应用程序连接物理世界和虚拟世界,现实地驱动3D全身化身的能力具有重要意义。虽然仅使用头戴式显示器(hmd)和手控制器的实时身体跟踪约束严重不足,但精心设计的端到端神经网络通过大规模运动数据学习具有解决这个问题的巨大潜力。为此,我们提出了一个两阶段的框架,它可以仅通过头部和手的三个跟踪信号来获得准确和平滑的全身运动。我们的框架在第一阶段明确地建模了联合级特征,并利用它们作为交替时空转换块的时空标记,以捕获第二阶段的联合级相关性。此外,我们设计了一组损失项来约束高自由度的任务,这样我们就可以利用我们的联合级建模的潜力。通过对累积运动数据集和真实捕获数据的大量实验,我们验证了我们设计的有效性,并表明与现有的方法相比,我们提出的方法可以实现更准确和平滑的运动。
2、方法
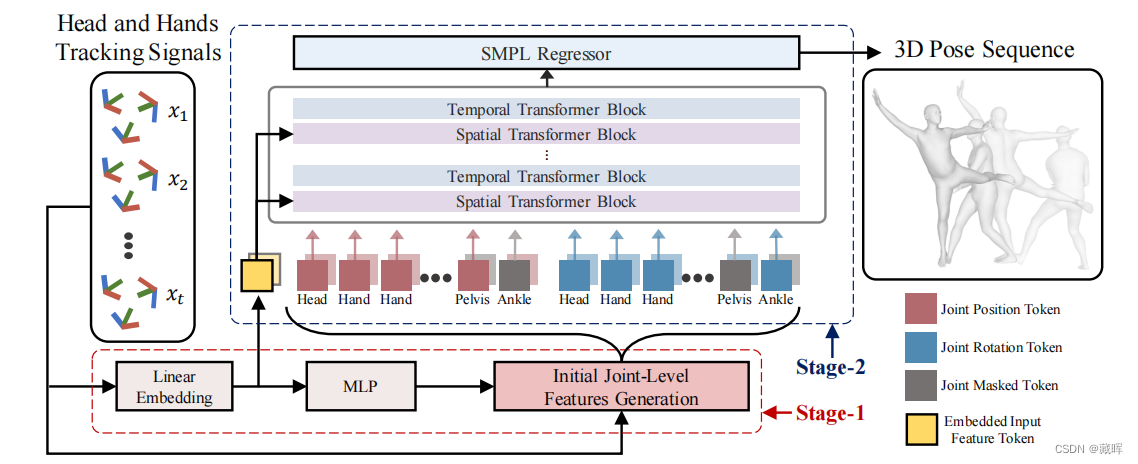
该方法分为两个阶段。
在第一阶段,我们将一系列稀疏信号(head和heand的跟随观测)嵌入到高维输入特征中。然后,我们利用一个MLP从这些特征中获得初始的全身姿态。然后,我们结合初始全身姿态和稀疏输入信号,生成初始关节级特征。
在第二阶段,我们将初始的联合级特征转换为联合级标记,然后将这些标记输入Transformer网络中,以交替捕获空间和时间维度上的联合级依赖关系。在每个空间transformer块中,我们补充了一个由高维输入特征生成的附加嵌入式输入特征令牌。最后,我们使用SMPL回归器将时空建模的关节级特征转换为三维全身姿态序列。
十二、PointOdyssey: A Large-Scale Synthetic Dataset for Long-Term Point Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Zheng_PointOdyssey_A_Large-Scale_Synthetic_Dataset_for_Long-Term_Point_Tracking_ICCV_2023_paper.pdf
github: https://pointodyssey.com
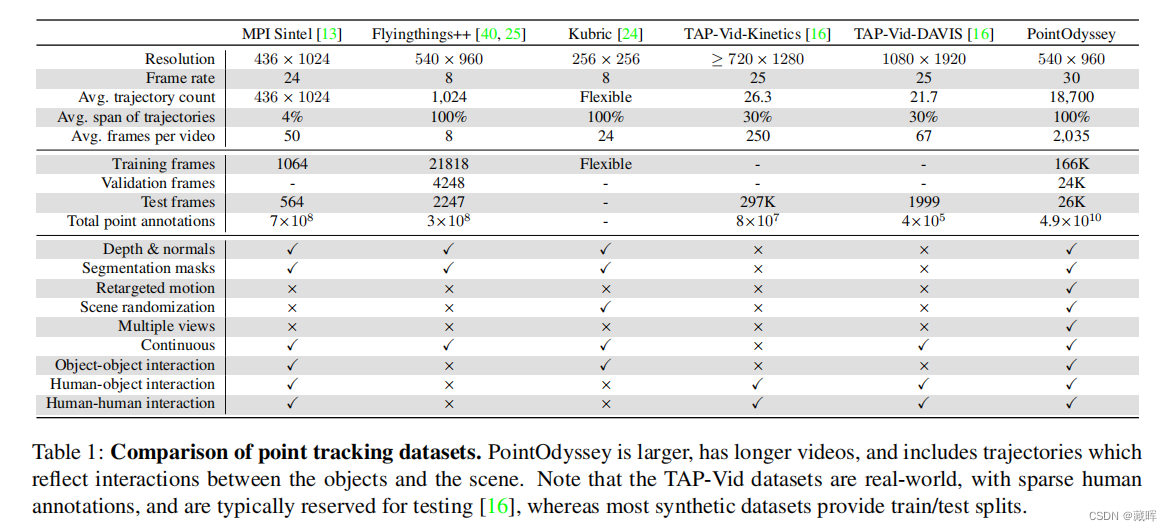
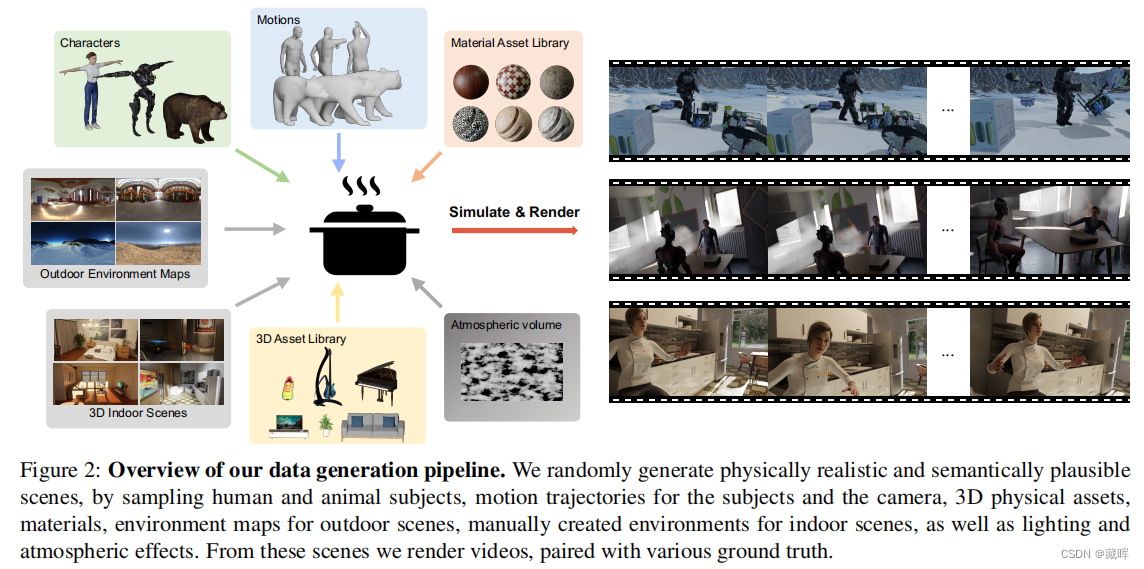
1、摘要
我们介绍了PointOdyssey,一个大规模的合成数据集和数据生成框架,用于训练和评估长期的细粒度跟踪算法。我们的目标是通过目标自然运动的长视频来推进最先进的技术的发展。为了实现自然主义的目标,我们使用真实世界的动作捕捉数据对可变形角色进行动画,我们构建3D场景来匹配动作捕捉环境,我们使用真实视频中通过结构挖掘的轨迹来渲染摄像机视点。我们通过随机化角色外观、运动轮廓、材料、照明、3D资产和大气效果来创建组合多样性。我们的数据集目前包括104个视频,平均2000帧长,比之前的工作多几个数量级。我们展示了现有的方法可以在我们的数据集中从头开始训练,并且优于已发布的变体。最后,我们对pip点跟踪方法进行了修改,极大地扩大了其时间接受域,提高了其在PointOdyssey和两个真实基准测试上的性能。
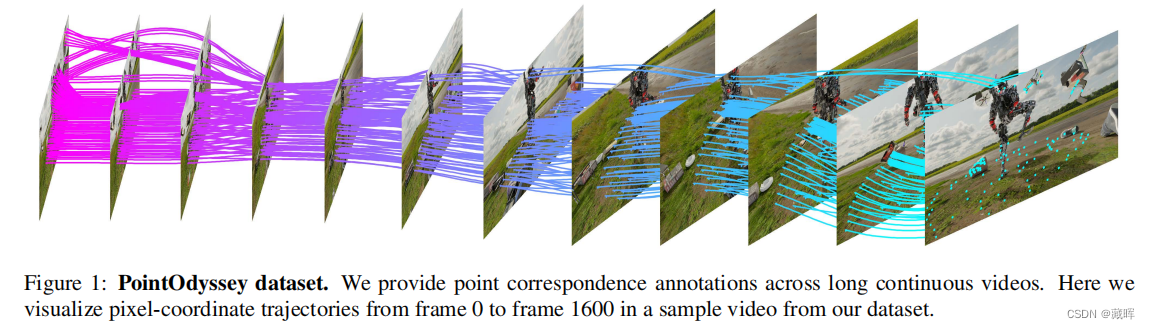
十三、MeMOTR: Long-Term Memory-Augmented Transformer for Multi-Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Gao_MeMOTR_Long-Term_Memory-Augmented_Transformer_for_Multi-Object_Tracking_ICCV_2023_paper.pdf
github: https://github.com/MCG-NJU/MeMOTR
1、摘要
多目标跟踪(MOT)作为一种视频任务,有望有效地捕获目标的时间信息。不幸的是,大多数现有的方法只显式地利用相邻帧之间的对象特征,而缺乏建模长期时间信息的能力。在本文中,我们提出了一种用于多目标跟踪的长期记忆增强变压器MeMOTR。我们的方法能够利用定制的记忆注意层,使同一对象的轨迹嵌入更加稳定和可区分。这显著提高了我们的模型的目标关联能力。在舞蹈跟踪技术上的实验结果表明,MeMOTR在HOTA和AssA指标上分别比目前最先进的方法多出了7.9%和13.0%。
2、方法
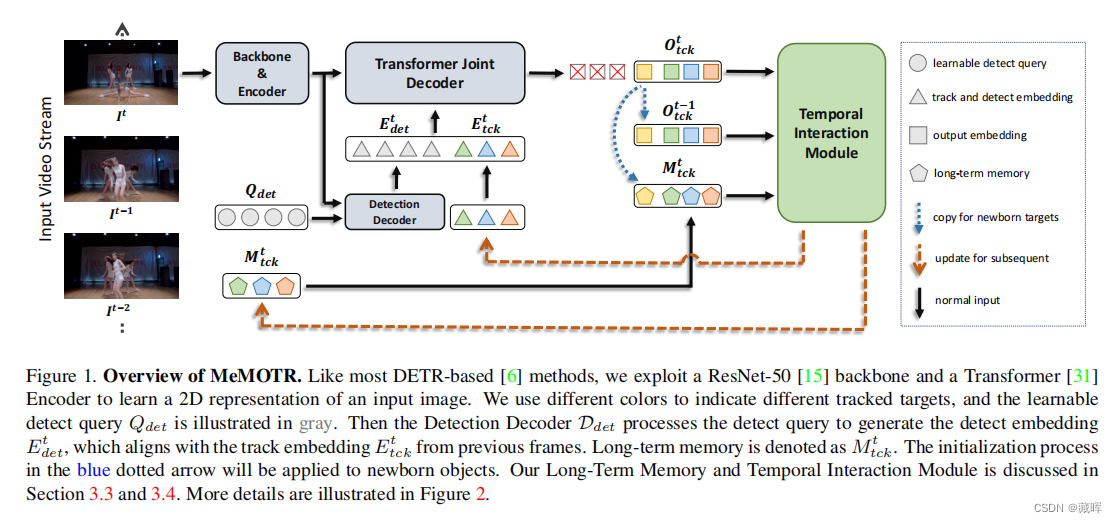
像大多数基于detr的方法一样,我们利用一个ResNet-50主干和一个Transformer编码器来学习输入图像的二维表示。我们使用不同的颜色来表示不同的跟踪目标,可学习的检测查询Qdet用灰色表示。然后检测解码器Ddet对检测查询进行处理,生成检测嵌入E t det,与之前帧的轨迹嵌入E t tck一致。长期记忆被记为Mt tck。蓝色虚线箭头中的初始化过程将应用于新生对象。
🔺相比于MOTR,这篇文章新增了一个Temporal Interaction Module,用于增强时序信息的使用。
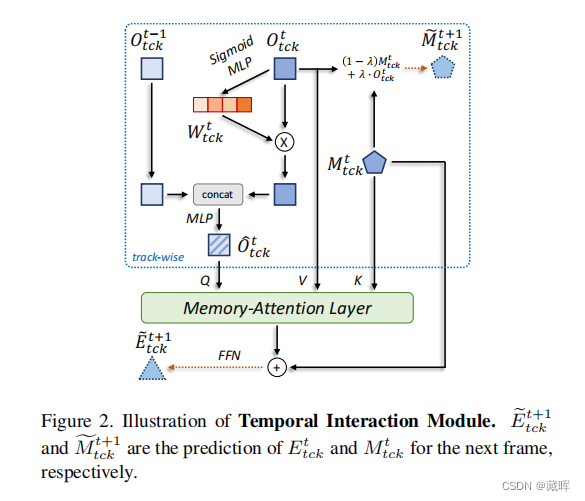
设计思路是用了线性相加,将历史特征保存在Mt tck中,此外Temporal Intraction Module结合历史特征Mt加强了当前的Ot特征预测,输出最终的track预测Et。
十四、Robust Object Modeling for Visual Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Cai_Robust_Object_Modeling_for_Visual_Tracking_ICCV_2023_paper.pdf
1、摘要
对象建模已经成为最近跟踪框架的核心组成部分。目前流行的跟踪器使用Transformer的注意力机制来单独或与搜索区域交互地提取模板特征。然而,单独的模板学习缺乏模板与搜索区域之间的通信,这使得人们难以提取可区分的面向目标的特征。另一方面,交互式模板学习产生了混合的模板特征,这可能会通过杂乱的搜索区域引入潜在的干扰物到模板中。为了享受这两种方法的优点,我们提出了一个鲁棒的视觉跟踪对象建模框架(ROMTrack),它同时对固有模板和混合模板特征进行建模。因此,通过结合目标对象的固有特征和搜索区域的引导,可以抑制有害的干扰物。还可以使用混合模板提取与目标相关的特征,从而得到一个更健壮的对象建模框架。为了进一步增强鲁棒性,我们提出了新的变异标记来描述目标对象不断变化的外观。变异标记适用于物体变形和外观变化,可以提高整体性能,可忽略计算。实验表明,我们的ROMTrack在多个基准测试上设置了一种新的最先进的技术。
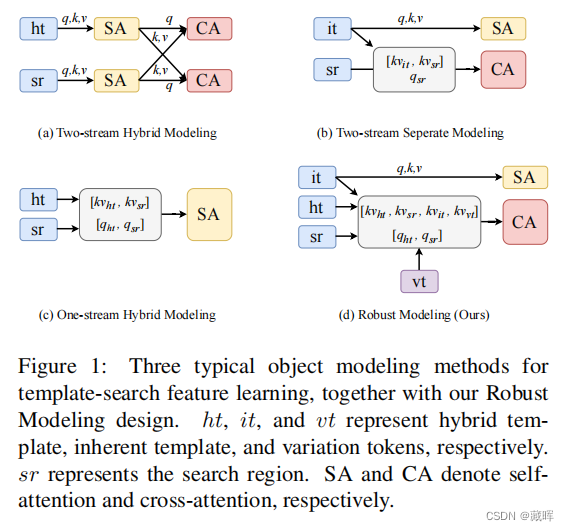
2、方法
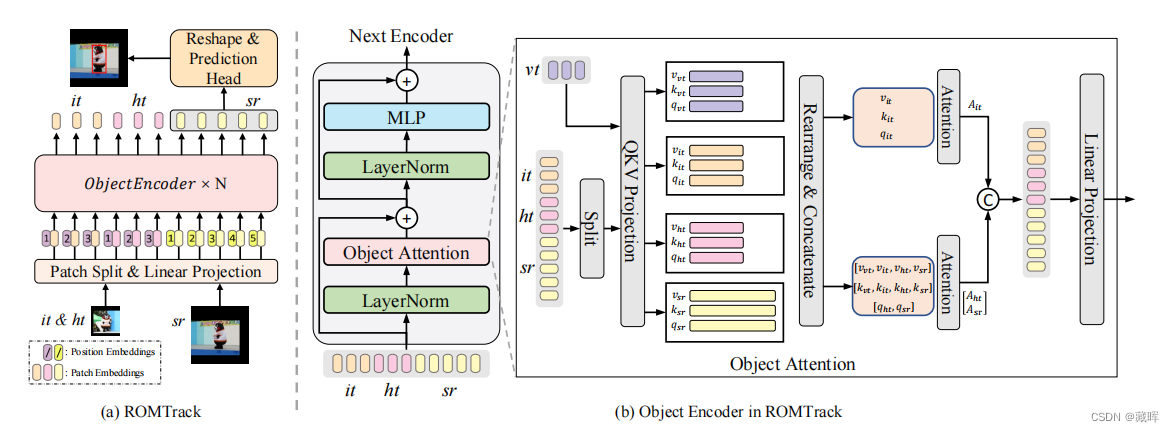
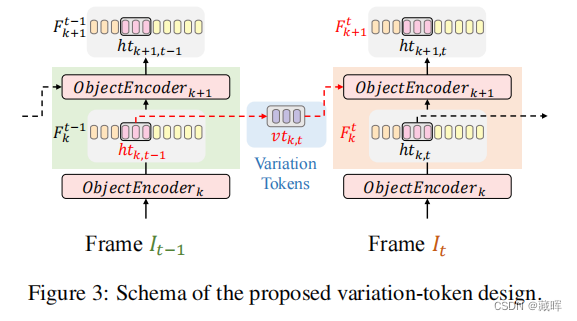
ROMTrack框架的概述。模板和搜索区域的图像被分割成补丁,然后线性投影、连接,并输入到堆叠的编码器层中,以进行鲁棒的对象建模。it、ht和sr分别表示固有模板、混合模板和搜索区域。对象编码器层的体系结构。vt表示变异标记。
变异标记vt来自于上一帧的ht。
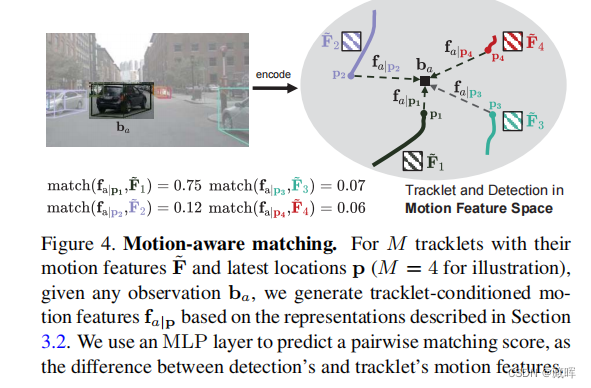
十五、Delving into Motion-Aware Matching for Monocular 3D Object Tracking
paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Huang_Delving_into_Motion-Aware_Matching_for_Monocular_3D_Object_Tracking_ICCV_2023_paper.pdf
github: https://github.com/kuanchihhuang/MoMA-M3T
1、摘要
单目三维目标检测的最新进展有助于实现基于低成本摄像机传感器的三维多目标跟踪任务。在本文中,我们发现物体沿不同时间框架的运动线索在三维多目标跟踪中是至关重要的,而这在现有的单眼跟踪方法中研究较少。为此,我们提出了MoMA-M3T,一个主要由三个运动感知组件组成的框架。首先,我们将特征空间中与所有物体轨迹相关的物体的可能运动表示为它的运动特征。然后,我们通过运动Transformer网络从时空视角下沿时间框架进一步建模历史对象轨迹。最后,我们提出了一个运动感知匹配模块,将历史对象轨迹和当前观测结果作为最终的跟踪结果。我们在nuScenes和KITTI数据集上进行了广泛的实验,以证明我们的MoMA-M3T实现了与最先进的方法更有竞争力的性能。
在这里插入图片描述
2、方法
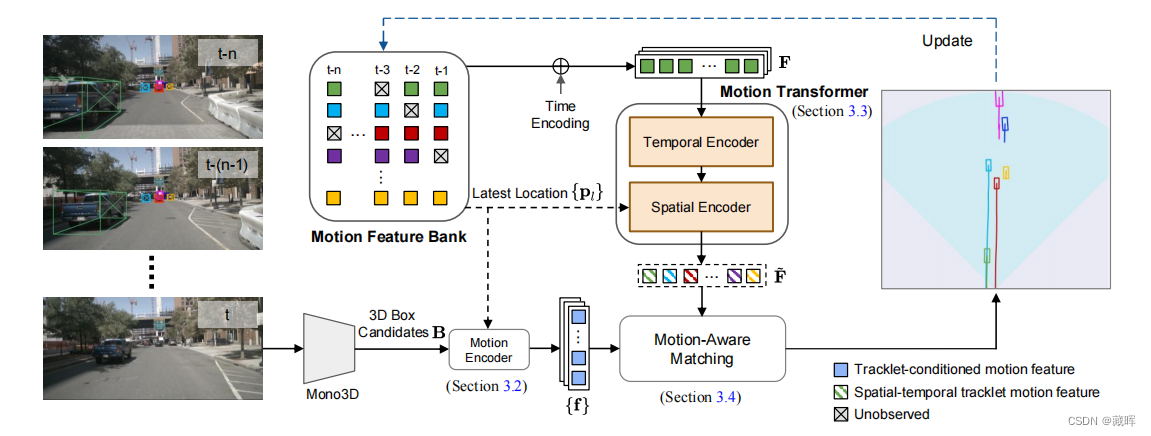
该网络分为以下几步。
1、在每个时间戳中,利用一个单目3D对象检测器来生成3D边界盒候选对象B。
2、我们取轨迹的最新3D位置{pl},为每个轨迹检测对生成所有可能的运动,然后用运动编码器提取轨迹条件下的运动特征{f}。简单说就是用一定形式表征位置信息,用MLP网络编码当前帧和先前帧的位置信息来生成f。
3、应用运动Transformer模块从不同时间戳的时间和空间上聚合运动线索F,得到每个被跟踪对象的运动特征˜F。
4、采用运动感知匹配策略将学习到的运动特征与轨迹与检测关联。即使用一个MLP层来预测一个两两匹配的分数,作为检测的运动特征和轨迹的运动特征之间的差异。