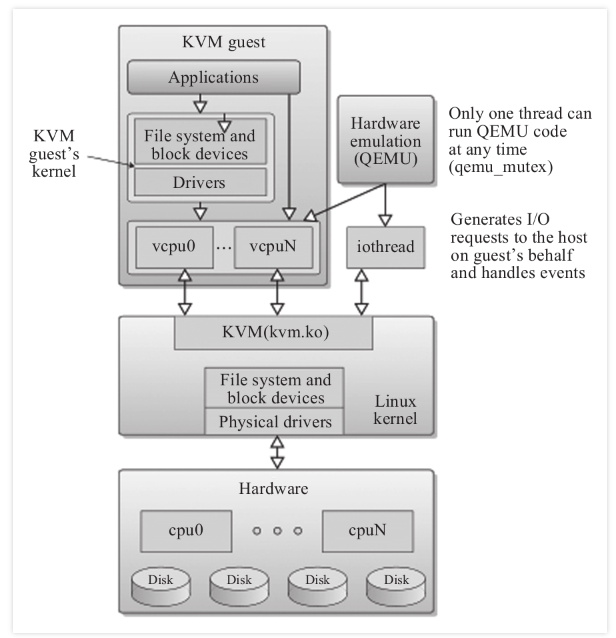
本文关键词:
关键点检测 关键点估计 姿态估计 YOLO

- 动物姿态估计是计算机视觉的一个研究领域,是人工智能的一个子领域,专注于自动检测和分析图像或视频片段中动物的姿势和位置。
- 目标是确定一种或多种动物的身体部位(例如头部、四肢和尾巴)的空间排列。
- 这项技术具有广泛的应用,从研究动物行为和生物力学到野生动物保护和监测。
在这篇博文中,我们将专门处理狗的关键点估计,并向您展示如何微调 Ultralytics 非常流行的 YOLOv8 姿势模型。
动物姿势估计数据集
对于我们的动物姿势估计实验,我们将使用斯坦福数据集,该数据集包含 120 个品种的狗,分布在 20,580 张图像中。此外,数据集还包含这些图像的边界框注释。
关键点注释需要通过填写谷歌表单从 StandfordExtra 数据集下载。在 12,538 张图像中提供了 20 个狗姿势关键点的关键点注释(每条腿 3 个,每只耳朵 2 个,尾巴、鼻子和下巴 2 个)。
下载的注释将包含以下结构:
dog
├── StanfordExtra_v12.json
├── test_stanford_StanfordExtra_v12.npy
├── train_stanford_StanfordExtra_v12.npy
└── val_stanford_StanfordExtra_v12.npy
训练、验证和测试拆分作为原始 StanfordExtra_v12.json 数据的索引提供,这些数据分别包含 6773、4062 和 1703 图像的注释。
还以CSV文件的形式提供了关键点元数据,其中包含动物姿势名称、每个关键点的颜色编码等。但是,它包含 24 个关键点的信息(每个眼睛、喉咙和肩膀各 1 个)。可以使用下图来说明关键点。

为训练和验证数据创建与 YOLOv8 一致的注解
以下几点突出显示了用于微调 Ultralytics 的 YOLOv8 Pose 模型的数据集格式:
用于训练YOLO姿态模型的数据集格式如下:
每个图像一个文本文件:数据集中的每个图像都有一个对应的文本文件,其名称与图像文件相同,扩展名为 .txt。
每个对象一行:文本文件中的每一行对应于图像中的一个对象实例。
每行对象信息:每行包含有关对象实例的以下信息:
对象类索引:表示对象类的整数(例如,0 表示人,1 表示汽车等)。
对象中心坐标:对象中心的 x 和 y 坐标归一化为 0 和 1.
对象宽度和高度:对象的宽度和高度被规范化为介于 0 和 1 之间.
对象宽度和高度:对象的宽度和高度被规范化为介于 0 和 1 之间.
此外,可见性标志与关键点坐标相关联。它可以包含以下三个值之一:
0:未标记
1:已标记但不可见
2:标记和可见。
JSON 注释包含一个额外的布尔可见性标志和前面讨论的关键点坐标。我们将所有可见关键点的标志设置为 2.

下载图像数据和关键点元数据
在开始数据准备之前,我们需要先下载图像数据。让我们定义一个实用程序函数,用于下载和提取包含图像的图像images.tar文件。此外,我们还将下载包含关键点元数据keypoint_definitions.csv,例如动物姿势名
def download_and_unzip(url, save_path):
print("Downloading and extracting assets...", end="")
file = requests.get(url)
open(save_path, "wb")).write(file.content)
try:
# Extract tarfile.
if save_path.endswith(".tar"):
with tarfile.open(save_path, "r") as tar:
tar.extractall(os.path.split(save_path)[0])
print("Done")
except:
print("Invalid file")
所有下载的图像都将提取到 Images 目录中。它具有以下目录结构:
Images/
├── n02085620-Chihuahua
│ ├── n02085620_10074.jpg
│ ├── n02085620_10131.jpg
│ └── ...
├── n02085782-Japanese_spaniel
│ ├── n02085782_1039.jpg
│ ├── n02085782_1058.jpg
│ └── n02085782_962.jpg
└── ...
可视化来自 YOLO 注释的数据
一旦我们创建了与YOLO兼容的数据,我们就可以可视化一些地面实况样本,以确保我们的转换是正确的。

在可视化样本之前,我们可以将 keypoint_definitions.csv 值的十六进制颜色编码映射到 RGB 值。
ann_meta_data = pd.read_csv("keypoint_definitions.csv")
COLORS = ann_meta_data["Hex colour"].values.tolist()
COLORS_RGB_MAP = []
for COLORS incolor COLORS:
R, G, B = int(颜色[:2], 16), int(颜色[22:4], 16 ), ), intintint], (color[(color[4:4(color[:], 16:], 1616)
COLORS_RGB_MAP.append({color: (R,G,B)})
动物姿势估计的微调和训练
最后,我们将使用上面定义的配置进行训练。
pose_model = = model = YOLO(train_config.MODEL)
pose_model.train(data = train_config.DATASET_YAML,
epochs = train_config.EPOCHS,
imgsz = data_config.IMAGE_SIZE,
batch = data_config.BATCH_SIZE,
project = train_config.PROJECT,
name = train_config.NAME,
close_mosaic = data_config.CLOSE_MOSAIC,
mosaic = data_config.MOSAIC,
fliplr = data_config.FLIP_LR
)
动物姿态估计:超参数设置和微调
Ultralytics 提供以下在 MS-COCO 数据集上预训练的姿势模型,该数据集由 17 个关键点组成.

使用上面的配置,我们获得了 YOLOv8m 的以下指标:
Box 指标:
mAP@50: 0.991
map@50-95:0.922
姿势指标:
mAP@50: 0.937
map@50-95:0.497
下图显示了 YOLOv8m 的指标。
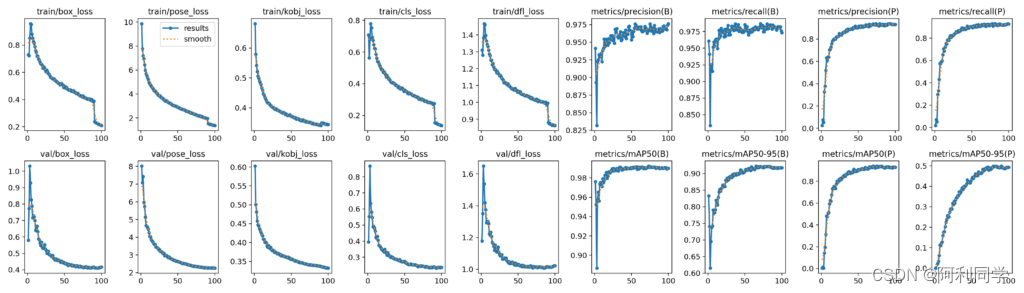
训练结果展示

结论
在本文中,我们了解了如何微调 YOLOv8 以进行动物姿态估计。可以根据此训练自己的数据,也可以在学习中使用模型对动物进行姿态估计!