Kafka-Topic创建源码分析
在kafka中,创建topic通过使用kafka-topics.sh脚本或者直接调用AdminClient对外提供的adminApi来进行创建.
即使是使用kafka-topics.sh,其最终会通过生成并调用AdminClient来进行处理.
0,创建topic流程图

1,创建topic示例代码
通过引入AdminClient利用代码实现创建topic的示例代码.
//配置brokerServer的链接地址(`bootstrap.servers`):`host1:port,host2:port`
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
//`Admin.create(props)`:生成`KafkaAdminClient`实例.
//==>jdk8以后可用try来自动执行close
try (Admin admin = Admin.create(props)) {
String topicName = "test-topic";
int partitions = 12;
short replicationFactor = 2;
NewTopic newTopic = new NewTopic(topicName, partitions, replicationFactor).configs(
//配置topic的log的日志清理策略(适合于带有key,value消息的topic)
Collections.singletonMap(TopicConfig.CLEANUP_POLICY_CONFIG, TopicConfig.CLEANUP_POLICY_COMPACT)
);
//向brokerServer发起创建topic的请求(`CreateTopicsRequest`).
CreateTopicsResult result = admin.createTopics(Collections.singleton(newTopic));
//等待response的响应结果.
result.all.get();
}
2,AdminClient处理流程
2,1,Admin.create
Admin.create函数主要用于生成用于与broker节点进行通信的KafkaAdminClient实例.
static Admin create(Properties props) {
return KafkaAdminClient.createInternal(new AdminClientConfig(props, true), null);
}
从Admin.create的实现代码可以看到,其直接调用了KafkaAdminClient内部的createInternal函数来完成adminClient的初始化.
createInternal函数处理流程
Step=>1
生成用于管理client端metadataCache的AdminMetadataManager实例,实例初始化时依赖配置项:
retry.backoff.ms 默认值100ms,当metadata相关请求失败后,下一次重试的backOff时间.
metadata.max.age.ms 默认值5分钟,
client端metadataCache的过期时间,当metadata上一次更新时间超过这个值后,会重新请求获取新的metadata.
此时,其内部默认的updater实例默认为AdminMetadataUpdater.
//初始化AdminMetadataManager实例,其`metadataUpdate`.
AdminMetadataManager metadataManager = new AdminMetadataManager(logContext,
config.getLong(AdminClientConfig.RETRY_BACKOFF_MS_CONFIG),
config.getLong(AdminClientConfig.METADATA_MAX_AGE_CONFIG));
Step=>2
根据bootstrap.servers配置的brokers列表,初始化生成Cluster实例,并添加到metadataManager实例中.
此时: Cluster实例内部的isBootstrapConfigured属性默认值为true
当isBootstrapConfigured值为true时,表示metadataManager处于未准备好的状态.并同时设置metadataManager实例的state为QUIESCENT,
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(
config.getList(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG),
config.getString(AdminClientConfig.CLIENT_DNS_LOOKUP_CONFIG));
//将初始化的Cluster设置到`metadataManager`中,并设置其`state`为`QUIESCENT`状态.
metadataManager.update(Cluster.bootstrap(addresses), time.milliseconds());
Step=>3
生成用于与broker进行网络通信的NetworkClient通道,其对应的metadataUpdater实例为AdminMetadataUpdater.
channelBuilder = ClientUtils.createChannelBuilder(config, time, logContext);
selector = new Selector(config.getLong(AdminClientConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),
metrics, time, metricGrpPrefix, channelBuilder, logContext);
//生成`NetworkClient`实例,其对应的`medataUpdater`实例为`AdminMetadataUpdater`.
networkClient = new NetworkClient(
metadataManager.updater(),null,selector,clientId,1,
config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(AdminClientConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(AdminClientConfig.SEND_BUFFER_CONFIG),
config.getInt(AdminClientConfig.RECEIVE_BUFFER_CONFIG),
(int) TimeUnit.HOURS.toMillis(1),
config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MS_CONFIG),
config.getLong(AdminClientConfig.SOCKET_CONNECTION_SETUP_TIMEOUT_MAX_MS_CONFIG),
time,true,apiVersions,null,logContext,
(hostResolver == null) ? new DefaultHostResolver() : hostResolver);
Step=>4
最后: 根据以上三歩初始化的信息,生成KafkaAdminClient实例.
在adminClient端,其clientId的值默认为adminclient-number这样的值.
在初始化KafkaAdminClient时,会同时初始化启动其内部的AdminClientRunnable线程,此线程用于处理与broker的通信.
return new KafkaAdminClient(config, clientId, time, metadataManager, metrics, networkClient,
timeoutProcessorFactory, logContext);
2,2,MetadataRequest
当KafkaAdminClient实例初始化后,其内部的AdminClientRunnableIO线程被启动,
此时在执行processRequests函数时会生成MetadataRequest请求,并立即向broker节点请求获取集群的metadata信息.
在KafkaAdminClient实例刚初始化完成时,
metadataManager中lastMetadataUpdateMs与lastMetadataFetchAttemptMs属性默认值为0,
因此:metadataManager.metadataFetchDelayMs(now)得到的delay时间为0,此时将执行makeMetadataCall生成MetadataRequest.
同时通过maybeDrainPendingCall立即发起请求.
processRequests函数中判断并发起Metdata请求的代码片段:
pollTimeout = Math.min(pollTimeout, maybeDrainPendingCalls(now));
//判断当前metadata是否过期,初始化实例时metadataFetchDelayMs函数返回0,表示过期需要重新获取metadata.
long metadataFetchDelayMs = metadataManager.metadataFetchDelayMs(now);
if (metadataFetchDelayMs == 0) {
metadataManager.transitionToUpdatePending(now);
//生成`MetadataRequest`请求实例,此时将向`bootstrap.servers`配置的broker节点的随机一个节点发起请求.
Call metadataCall = makeMetadataCall(now);
//将获取metadata信息的`Call`实例添加到`callsToSend`队列中.
if (!maybeDrainPendingCall(metadataCall, now))
pendingCalls.add(metadataCall);
}
//执行sendEligibleCalls函数,发起`MetadataRequest`请求.
pollTimeout = Math.min(pollTimeout, sendEligibleCalls(now));
Step=>1
metadataManager.transitionToUpdatePending(now) 将metadataManager对应的state的状态设置为UPDATE_PENDING.
Step=>2
makeMetadataCall函数,生成用于处理MetadataRequest的Call实例.
**==>**此Call实例对应的nodeProvider实现为MetadataUpdateNodeIdProvider.
其生成MetadataRequest参数的实现代码:
public MetadataRequest.Builder createRequest(int timeoutMs) {
return new MetadataRequest.Builder(new MetadataRequestData()
.setTopics(Collections.emptyList())
.setAllowAutoTopicCreation(true));
}
Step=>3
maybeDrainPendingCall函数,通过MetadataUpdateNodeIdProvider随机获取bootstrap.servers中的一个broker节点,发起Metadata请求.
//根据`MetadataUpdateNodeIdProvider`随机获取一个broker节点.
//==>同时把metadata请求信息添加到`callsToSend`队列中.
Node node = call.nodeProvider.provide();
if (node != null) {
log.trace("Assigned {} to node {}", call, node);
call.curNode = node;
getOrCreateListValue(callsToSend, node).add(call);
return true;
}
Step=>4
执行sendEligibleCalls函数,把callsToSend队列中已经准备好的请求发送到目标broker节点.
在初始化时此队列中默认只有MetadataRequest请求,因此此时只是向目标节点发起获取Metadata请求.
此时:,发起的MetadataRequest请求将由broker端的KafkaApis中的handleTopicMetadataRequest处理程序进行处理.
此请求在broker端将返回当前metadataImage中所有的activeBrokers节点信息,
并从activeBrokers中随机获取一个节点做为Controller节点.
Step=>5
当broker端接收并完成对MetadataRequest请求的处理后进行响应的response将由makeMetadataCall生成的Call实例处理.
=>1, 根据Metadata请求响应的activeBrokers与controller节点信息,重新生成Cluster实例,
此时生成的Cluster实例对应的isBootstrapConfigured属性的值为false(表示metadata已经准备好).
=>2,执行metadataManager的update函数,把最新生成的Cluster更新到metadataManager实例中.
此时:metadataManager对应的lastMetadataUpdateMs属性(metadata最后更新时间)将被更新为当前时间.
public void handleResponse(AbstractResponse abstractResponse) {
MetadataResponse response = (MetadataResponse) abstractResponse;
long now = time.milliseconds();
metadataManager.update(response.buildCluster(), now);
// Unassign all unsent requests after a metadata refresh to allow for a new
// destination to be selected from the new metadata
unassignUnsentCalls(node -> true);
}
2,3,createTopics
发起请求
从示例代码中可以看到,当利用AdminClient来创建topic时,在生成NewTopic实例后,会最终调用KafkaAdminClient.createTopics来进行处理.
createTopics代码实现:
=>1,先迭代传入的newTopics容器,取出每一个NewTopic实例,
根据其自定义配置,topicName,numPartitions以及replicationFactor生成对应的CreatableTopic实例.
=>2,根据新生成的CreatableTopic的容器(一到多个),通过调用getCreateTopicsCall生成用于网络请求的Call实例.此时:
a,Call实例用于查找请求的目标节点的nodeProvider实例为ControllerNodeProvider(metadata必须初始化,有对应的controller节点).
b,生成CreateTopicsRequest请求与其对应的响应处理程序handleResponse(由Call实例定义).
=>3,将新生成用于发起CreateTopicsRequest请求的Call添加到IO线程的newCalls队列中.
public CreateTopicsResult createTopics(final Collection<NewTopic> newTopics,
final CreateTopicsOptions options) {
//生成topic创建是否成功的future监听,client端可通过对函数调用的返回值来监听创建的成功失败.
final Map<String, KafkaFutureImpl<TopicMetadataAndConfig>> topicFutures = new HashMap<>(newTopics.size());
final CreatableTopicCollection topics = new CreatableTopicCollection();
//迭代传入的`NewTopic`集合参数,检查topicName是否为空,
//==>并根据其`name`,`numPartitions`,`replicationFactor`等配置信息生成`CreatableTopic`添加到`topics`集合中.
for (NewTopic newTopic : newTopics) {
if (topicNameIsUnrepresentable(newTopic.name())) {
KafkaFutureImpl<TopicMetadataAndConfig> future = new KafkaFutureImpl<>();
future.completeExceptionally(new InvalidTopicException("The given topic name '" +
newTopic.name() + "' cannot be represented in a request."));
topicFutures.put(newTopic.name(), future);
} else if (!topicFutures.containsKey(newTopic.name())) {
topicFutures.put(newTopic.name(), new KafkaFutureImpl<>());
topics.add(newTopic.convertToCreatableTopic());
}
}
//如果校验并转换为`CreatableTopic`的信息不为空,生成发起`CreateTopicsRequest`请求的`Call`实例.
//==>并添加到runnable线程的`newCalls`队列中.
if (!topics.isEmpty()) {
final long now = time.milliseconds();
final long deadline = calcDeadlineMs(now, options.timeoutMs());
final Call call = getCreateTopicsCall(options, topicFutures, topics,
Collections.emptyMap(), now, deadline);
runnable.call(call, now);
}
return new CreateTopicsResult(new HashMap<>(topicFutures));
}
此时:runnableIO线程(AdminClientRunnable)在processRequests处理时的执行顺序:
=>1, drainNewCalls:将newCalls队列中新生成的Request移动到pendingCalls队列中.
=>2, maybeDrainPendingCalls: 将pendingCalls队列的Request移动到callsToSend队列中(根据Call.nodeProvide查找到node).
=>3,sendEligibleCalls: callsToSend队列中的Request发起网络请求,向指定的目标节点.
此时,请求将由broker端接收到后,会被ForwardingManager组件包装为EnvelopeRequest后,直接转发给activeController进行处理.
通过ForwardingManager中的BrokerToControllerChannelManager 向activeController转发请求.
即: 请求最终将由Controler中的ReplicationControlManager组件来进行CreateTopicsRequest处理.
在controller中ReplicationControlManager组件用于管理集群的topic信息以及各ISR与partitionLeader的平衡.
并在向metadata中写入TopicRecord与PartitionRecord 消息后,由所有kafkaServer节点进行replay来执行真正意义上的创建工作.
同时broker端由到activeController的response后,再重新把response转发给client端.
接收响应
在broker端接收到activeController的响应后,会将response转发给client端,此时:
将由getCreateTopicsCall生成的Call实例的handleResponse来进行处理.
其处理response的代码片段:
ApiError error = new ApiError(result.errorCode(), result.errorMessage());
if (error.isFailure()) {
if (error.is(Errors.THROTTLING_QUOTA_EXCEEDED)) {
ThrottlingQuotaExceededException quotaExceededException = new ThrottlingQuotaExceededException(
response.throttleTimeMs(), error.messageWithFallback());
if (options.shouldRetryOnQuotaViolation()) {
retryTopics.add(topics.find(result.name()).duplicate());
retryTopicQuotaExceededExceptions.put(result.name(), quotaExceededException);
} else {
future.completeExceptionally(quotaExceededException);
}
} else {
future.completeExceptionally(error.exception());
}
} else {
TopicMetadataAndConfig topicMetadataAndConfig;
if (result.topicConfigErrorCode() != Errors.NONE.code()) {
topicMetadataAndConfig = new TopicMetadataAndConfig(
Errors.forCode(result.topicConfigErrorCode()).exception());
} else if (result.numPartitions() == CreateTopicsResult.UNKNOWN) {
topicMetadataAndConfig = new TopicMetadataAndConfig(new UnsupportedVersionException(
"Topic metadata and configs in CreateTopics response not supported"));
} else {
List<CreatableTopicConfigs> configs = result.configs();
Config topicConfig = new Config(configs.stream()
.map(this::configEntry)
.collect(Collectors.toSet()));
topicMetadataAndConfig = new TopicMetadataAndConfig(result.topicId(), result.numPartitions(),
result.replicationFactor(),
topicConfig);
}
future.complete(topicMetadataAndConfig);
}
从response的处理代码中可以看到,其接收到响应后,会根据响应对应的topicId以及topicConfig信息,设置到future中来完成创建.
此时,client端对future的监听将能获取到对应的结果(失败的异常或成功后的topicMetadataAndConfig)
此时,只是代表topic创建成功(metadata消息同步达到高水位线,但broker对partition对应的存储目录与log的创建不一定已经完成).
3,Controller处理Topic创建
当broker节点接收到CreateTopics的请求后,会将请求转发当activeController中,交由其ReplicationControlManager组件处理.
ReplicationControlManager
1,createTopics
adminClient执行createTopics操作时,此操作会由broker中的ForwardingManager组件转发创建topic的请求到activeController中,并最终交由ReplicationControlManager中的此函数来进行处理.
此函数的返回值即是QuorumController状态机中ControllerWriteEvent要向metadataLog中写入的消息并执行相应的replay操作.
createTopics执行流程分析:
Step=>1,
对topicName进行校验,其长度不能超过249个字符,只能是字母、数字、下划线与中划线,最好不要包含”.”号,并判断topic是否已经存在.
在kafka中topicPartition的总长度需要控制在255个字符,其中留给partition的字符数为5,也就是最大不能到100000个partition.
Map<String, ApiError> topicErrors = new HashMap<>();
List<ApiMessageAndVersion> records = new ArrayList<>();
// Check the topic names.
validateNewTopicNames(topicErrors, request.topics(), topicsWithCollisionChars);
// Identify topics that already exist and mark them with the appropriate error
request.topics().stream().filter(creatableTopic -> topicsByName.containsKey(creatableTopic.name()))
.forEach(t -> topicErrors.put(t.name(), new ApiError(Errors.TOPIC_ALREADY_EXISTS,
"Topic '" + t.name() + "' already exists.")));
Step=>2,
根据createTopic时,是否对topic有自定义的配置项,来生成ConfigRecord消息,*client端创建时的自定义配置*中有针对topic的自定义配置项.
其中ConfigRecord消息的resourceName就是topicName.
// Verify that the configurations for the new topics are OK, and figure out what
// ConfigRecords should be created.
Map<ConfigResource, Map<String, Entry<OpType, String>>> configChanges =
computeConfigChanges(topicErrors, request.topics());
//如果有自定义的配置项,此时会根据每一个自定义配置项生成`ConfigRecord`消息.
ControllerResult<Map<ConfigResource, ApiError>> configResult =
configurationControl.incrementalAlterConfigs(configChanges, true);
for (Entry<ConfigResource, ApiError> entry : configResult.response().entrySet()) {
if (entry.getValue().isFailure()) {
topicErrors.put(entry.getKey().name(), entry.getValue());
}
}
records.addAll(configResult.records());
Step=>3,
对请求传入的CreatableTopics进行迭代,执行createTopic函数尝试创建topic.
======>此过程中会生成TopicRecord以及PartitionRecord消息.
在createTopic中会根据numPartitions与replicationFactor对副本应该所在的broker进行分配.具体流程请参考接下来的createTopic部分的分析.
// Try to create whatever topics are needed.
Map<String, CreatableTopicResult> successes = new HashMap<>();
for (CreatableTopic topic : request.topics()) {
if (topicErrors.containsKey(topic.name())) continue;
ApiError error;
//迭代请求的CreatableTopic,对每一个需要创建的topic进行处理(通过createTopic函数).
try {
error = createTopic(topic, records, successes, describable.contains(topic.name()));
} catch (ApiException e) {
error = ApiError.fromThrowable(e);
}
if (error.isFailure()) {
topicErrors.put(topic.name(), error);
}
}
Step=>4,
生成对应的CreateTopicsResponse响应信息,并把createTopics过程中生成的metadata消息集返回给ControllerWriteEvent事件.
由ControllerWriteEvent事件执行时把消息写入到metadataLog中并执行replay操作.
当followerController超过半数完成本次topic创建时写入消息的同步后,生成的CreateTopicsResponse将向请求方响应response.
//生成当消息同步高水位线达到本次topic创建消息对应的offset时,向请求方响应的response信息.
CreateTopicsResponseData data = new CreateTopicsResponseData();
StringBuilder resultsBuilder = new StringBuilder();
String resultsPrefix = "";
for (CreatableTopic topic : request.topics()) {
ApiError error = topicErrors.get(topic.name());
if (error != null) {
data.topics().add(new CreatableTopicResult().
setName(topic.name()).
setErrorCode(error.error().code()).
setErrorMessage(error.message()));
resultsBuilder.append(resultsPrefix).append(topic).append(": ").
append(error.error()).append(" (").append(error.message()).append(")");
resultsPrefix = ", ";
continue;
}
CreatableTopicResult result = successes.get(topic.name());
data.topics().add(result);
resultsBuilder.append(resultsPrefix).append(topic).append(": ").
append("SUCCESS");
resultsPrefix = ", ";
}
**最后:**把本次createTopics处理过程生成的Records交给ControllerWriteEvent事件进行metadata写入与replay.
if (request.validateOnly()) {
log.info("Validate-only CreateTopics result(s): {}", resultsBuilder.toString());
return ControllerResult.atomicOf(Collections.emptyList(), data);
} else {
log.info("CreateTopics result(s): {}", resultsBuilder.toString());
return ControllerResult.atomicOf(records, data);
}
2,createTopic
此函数在createTopics中对adminClient传入的CreatableTopicList迭代调用此函数尝试创建topic并分配对应的broker(根据副本分配策略).
函数的处理结果会生成CreatableTopicResult,用于最终响应给client端.
此函数的分析中,我们只分析createTopics调用时传入numPartitions与replicationFactor的场景.
如果replicationFactor没有输入时,默认副本数量由default.replication.factor配置(默认值1),必须是一个小于32767的值.
如果numPartitions没有输入时,默认的partition个数由num.partitions配置(默认值1),另外partition数量必须是一个小于100000的值.
createTopic执行流程分析:
Step=>1,
根据topic创建时设置的partition个数与副本个数,通过StripedReplicaPlacer副本分配策略,对partition进行分配,见*副本分配策略*.
同时在完成对partition的副本分配后,根据各partition分配的副本信息.
初始创建时partition的ISR是所有活动的副本分配节点(如果broker全部正常).而partition的Leader节点就是ISR列表中的第一个节点.
//根据副本数量与partition的个数,执行副本分配.分配策略默认实例`StripedReplicaPlacer`
int numPartitions = topic.numPartitions() == -1 ?
defaultNumPartitions : topic.numPartitions();
short replicationFactor = topic.replicationFactor() == -1 ?
defaultReplicationFactor : topic.replicationFactor();
try {
//根据副本分配策略`StripedReplicaPlacer`来进行副本分配.
List<List<Integer>> partitions = clusterControl.replicaPlacer().place(new PlacementSpec(
0,numPartitions,replicationFactor), clusterDescriber);
for (int partitionId = 0; partitionId < partitions.size(); partitionId++) {
List<Integer> replicas = partitions.get(partitionId);
//初始创建partition时,其对应的ISR列表与副本分配的brokers相同.
//==>校验所有分配的副本的ISR列表是否都在`activeBroker`列表中(只有正常状态的broker才能是副本的ISR节点)
List<Integer> isr = replicas.stream().
filter(clusterControl::active).collect(Collectors.toList());
if (isr.isEmpty()) {
return new ApiError(Errors.INVALID_REPLICATION_FACTOR,
"Unable to replicate the partition " + replicationFactor +
" time(s): All brokers are currently fenced or in controlled shutdown.");
}
//根据分配的partition对应的副本与ISR列表,初始化PartitionRegistration.
//=>其partitionLeader默认是isr列表中的第一个broker,
//=>同时初始创建时对应的`leaderEpoch`与`partitionEpoch`的值都是0.
//=>`leaderEpoch`在每一次leader切换时会在原epoch的基础上加1.
//=>`partitionEpoch`在每一次partitionChange的过程中会在原epoch的基础上加1.
newParts.put(partitionId,
new PartitionRegistration(
Replicas.toArray(replicas),
Replicas.toArray(isr),
/*初始创建时,removingReplicas与addingReplicas都是None*/
Replicas.NONE,Replicas.NONE,
isr.get(0), //Leader节点,取isr的第一个broker.
LeaderRecoveryState.RECOVERED,
0,0));
}
} catch (InvalidReplicationFactorException e) {
return new ApiError(Errors.INVALID_REPLICATION_FACTOR,
"Unable to replicate the partition " + replicationFactor +
" time(s): " + e.getMessage());
}
Step=>2,
生成用于最终向adminClient响应的CreatableTopicResult的response信息,
并生成ControllerWriteEvent事件向metadata写入的消息TopicRecord(topic创建消息)与PartitionRecord(partition的注册信息).
//向adminClient端返回的信息.
CreatableTopicResult result = new CreatableTopicResult().
setName(topic.name()).setTopicId(topicId).
setErrorCode(NONE.code()).setErrorMessage(null);
......隐藏一些代码......
successes.put(topic.name(), result);
//用于向metadata写入的消息.
//=>生成`TopicRecord`:topic创建的消息(TopicRecord消息必须放在PartitionRecord消息前面).
records.add(new ApiMessageAndVersion(new TopicRecord().setName(topic.name()).
setTopicId(topicId), TOPIC_RECORD.highestSupportedVersion()));
//=>生成`PartitionRecord`:针对每个partition的分配信息.
//==>包含副本集、ISR、LEADER等关键信息.
for (Entry<Integer, PartitionRegistration> partEntry : newParts.entrySet()) {
int partitionIndex = partEntry.getKey();
PartitionRegistration info = partEntry.getValue();
records.add(info.toRecord(topicId, partitionIndex));
}
至此,整个createTopic部分的业务处理完成
此时ControllerWriteEvent事件会将生成的消息写入到metadata中,并同时执行replay操作来具体处理topic的创建动作.
在执行metadata的replay时,
QuorumController的replay会把TopicRecord与PartitionRecord消息路由给ReplicationControlManager组件中对应的replay函数来处理.
当超过半数的standbyController节点完成对消息的replay操作后,整个createTopics请求响应response给调用方.
3,副本分配策略
在创建topic时,会根据partition的数量与副本个数来执行副本分配,
kafka中默认的分配策略为*StripedReplicaPlacer*.通过执行其place函数来进行副本分配.
在StripedReplicaPlacer中的副本分配流程解析:
==>其place函数的实现代码如下所示(请注意代码注释):
public List<List<Integer>> place(PlacementSpec placement,ClusterDescriber cluster) throws InvalidReplicationFactorException {
//step1,根据心跳管理器中所有已经注册的brokers根据其rack进行分组.
//==>其中,每个rack中包含有隔离中的brokerList与非隔离中的brokerList.
RackList rackList = new RackList(random, cluster.usableBrokers());
//step2,对副本个数进行校验,
//=>1,副本个数不能小于1,
//=>2,当前可用的broker(解除隔离的broker数量)个数不能小于1.
//=>3,topic要分配的副本个数必须小于等于当前注册的broker的总数量.
throwInvalidReplicationFactorIfNonPositive(placement.numReplicas());
throwInvalidReplicationFactorIfZero(rackList.numUnfencedBrokers());
throwInvalidReplicationFactorIfTooFewBrokers(placement.numReplicas(),rackList.numTotalBrokers());
List<List<Integer>> placements = new ArrayList<>(placement.numPartitions());
//step3,根据partition的数量,通过rackList中的place来进行每个partition的副本分配.
for (int partition = 0; partition < placement.numPartitions(); partition++) {
placements.add(rackList.place(placement.numReplicas()));
}
return placements;
}
从其实现代码可以看到,根据创建topic时要创建的partition个数,会迭代每一个parition,通过RackList对应的place函数来进行副本分配.
==>RackList.place对partition进行副本分配算法说明:
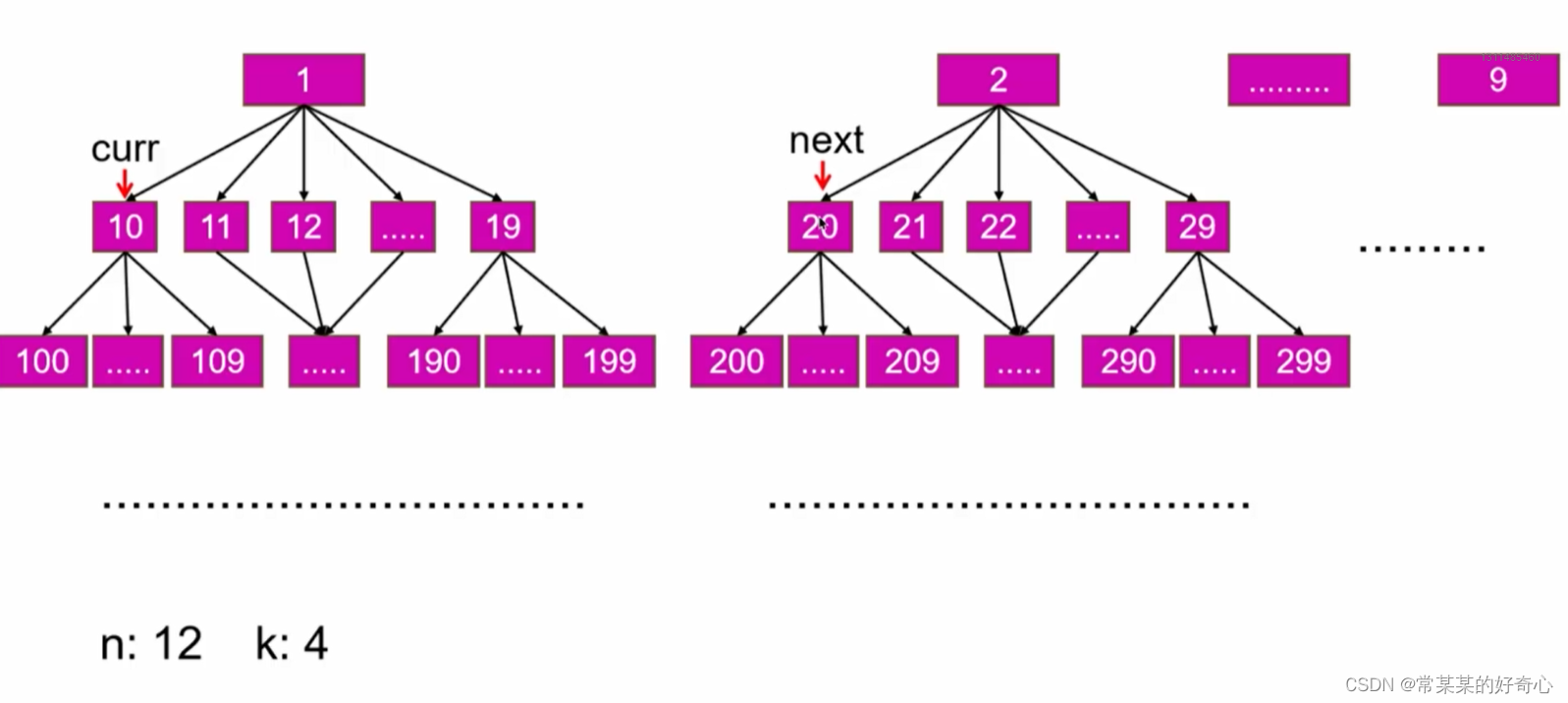
Case1=>,只有一个机架的情况(默认形式)
假定
配置有9个broker节点(全部处于非隔离状态),当前创建的topic包含18个partition,
每个partition两个副本.而rackList中broker的offset从0开始的情况.
各Partition副本分配情况如下表所示:
| broker-0 | broker-1 | broker-2 | broker-3 | broker-4 | broker-5 | broker-6 | broker-7 | broker-8 |
|---|---|---|---|---|---|---|---|---|
| part-0-0 | part-0-1 | Part-8-0 | ||||||
| Part-8-1 | Part-1-0 | Part-1-1 | ||||||
| Part-9-0 | Part-9-1 | Part-2-0 | Part-2-1 | Part-16-0 | Part-16-1 | |||
| Part-10-0 | Part-10-1 | Part-3-0 | Part-3-1 | Part-15-0 | Part-15-1 | |||
| Part-17-1 | Part-11-0 | Part-11-1 | Part-4-0 | Part-4-1 | Part-17-0 | |||
| Part-12-0 | Part-12-1 | Part-5-0 | Part-5-1 | |||||
| Part-13-0 | Part-13-1 | Part-6-0 | Part-6-1 | |||||
| Part-14-0 | Part-14-1 | Part-7-0 | Part-7-1 |
**即:从broker0开始,每个副本包含当前对应的位置并向后移动一个broker位置,**依次类推,
到最后节点从broker0再来(不一定是broker0,因为epoch达到broker数量后会对brokerList进行shuffle操作,offset没有发生变化,但broker顺序发生了变化).
Case2=>,多个机架的情况(有配置broker.rack)
在此种场景下,为方便计算,我们把示例的broker与rack数量都设置为偶数.
假定配置有2个rack(A,B),8个broker节点(全部处于非隔离状态),当前创建的topic包含16个partition.
| rack-A | rack-A | rack-A | rack-A | rack-B | rack-B | rack-B | rack-B |
|---|---|---|---|---|---|---|---|
| broker-0 | broker-1 | broker-2 | broker-3 | broker-4 | broker-5 | broker-6 | broker-7 |
| Offset=0 | Offset=1 | Offset=2 | Offset=3 | Offset=4 | Offset=5 | Offset=6 | Offset=7 |
假定:每个partition两个副本.而rackList中rackOffset与brokerOffset与epoch从0开始的情况.
=>1,开始分配第0个partition的副本,此时epoch=rackOffset=brokerOffset=0, 那么:
Partition0: A-Broker-0(即Broker-0),B-Broker-0(即Broker-4),
=>2,开始分配第1个partition的副本,此时epoch=rackOffset=brokerOffset=1, 那么:
Partition1: B-Broker-1(即Broker-5),A-Broker-1(即Broker-1),
=>3,开始分配第2个partition的副本,此时epoch=2,rackOffset=0,brokerOffset=2,
此时rack的迭代达到了上限,开始从0开始,那么:
Partition2: A-Broker-2(即Broker-2),B-Broker-2(即Broker-6),
=>4,开始分配第3个partition的副本,此时epoch=3,rackOffset=1,brokerOffset=3, 那么:
Partition3: A-Broker-3(即Broker-3),B-Broker-3(即Broker-7),
此后,rackOffset与brokerOfffset又回到起点位置(0)开始继续上面的流程,
直到epoch的值迭代完成7后,epcoh从0开始,并对每个rack中的机器排序重新shuffle.
完成shuffle后,offset保持不变,但brokerList顺序已经发生变化.
4,replay(TopicRecord)
当createTopic函数被调用后,会生成一个对应的TopicRecord消息,此消息的回放作用于重启或topic创建动作执行后.
此操作比较简单,只是把对应的topic信息添加到容器中记录起来.
//当执行createTopic操作后针对`TopicRecord`消息的处理.
public void replay(TopicRecord record) {
//根据topicName把name与对应的topicId存储到`topicsByName`容器中.
//==>此容器是一个针对当前内存snapshot的最新增量.
topicsByName.put(record.name(), record.topicId());
//如果topicName包含有"."符号时,把符号替换为"_"后并添加到`topicsWithCollisionChars`容器中.
if (Topic.hasCollisionChars(record.name())) {
String normalizedName = Topic.unifyCollisionChars(record.name());
TimelineHashSet<String> topicNames = topicsWithCollisionChars.get(normalizedName);
if (topicNames == null) {
topicNames = new TimelineHashSet<>(snapshotRegistry, 1);
topicsWithCollisionChars.put(normalizedName, topicNames);
}
topicNames.add(record.name());
}
//根据topicName与topicId生成`TopicControlInfo`实例,并添加到`topics`容器中.
topics.put(record.topicId(),
new TopicControlInfo(record.name(), snapshotRegistry, record.topicId()));
controllerMetrics.setGlobalTopicsCount(topics.size());
log.info("Created topic {} with topic ID {}.", record.name(), record.topicId());
}
5,replay(PartitionRecord)
当adminClient执行createTopic以及createPartition操作后,会生成对应的PartitionRecord消息.
此消息记录topic中partition的增量信息(首次创建时,即partitions的数量).
消息回放的处理流程:
Step=>1,
同时判断partition是否在topic对应的topicInfo中存在(这个步骤必须是在replay(TopicRecord)之后).
解析PartitionRecord消息,从topics中找到partition对应的topic,并根据消息转换为对应的PartitionRegistration实例.
TopicControlInfo topicInfo = topics.get(record.topicId());
if (topicInfo == null) {
throw new RuntimeException("Tried to create partition " + record.topicId() +
":" + record.partitionId() + ", but no topic with that ID was found.");
}
PartitionRegistration newPartInfo = new PartitionRegistration(record);
PartitionRegistration prevPartInfo = topicInfo.parts.get(record.partitionId());
String description = topicInfo.name + "-" + record.partitionId() +
" with topic ID " + record.topicId();
Step=>2,
A,根据对应的PartitionRegistration信息,对topicInfo中的parts信息进行维护(增量),
B,同时更新broker对应的ISR信息记录集到brokersToIsrs组件,
C,最后根据partition是否在进行重新分配触发updateReassigningTopicsIfNeeded函数(partition副本有移出或新增的情况).
把正在进行重新分配的partition添加到reassigningTopics容器中(在针对PartitionRecord的replay中这个操作只会发生在节点重新启动时).
此部分有两个分支的处理,即topicInfo中是否存在当前的partitionId对应的PartitionRegistration.
C-Case1
partitionId在topicInfo中不存在(topicInfo.parts.get(record.partitionId()) == null). 具体逻辑请查看代码片段中的说明.
此时,在brokersToIsrs组件中记录每个broker节点管理的partitions的反向索引.
//topicInfo中不包含新增的partitionId信息时(partition的新增).
if (prevPartInfo == null) {
log.info("Created partition {} and {}.", description, newPartInfo);
//=>把`PartitionRegistration`信息添加到topic的`topicInfo`的partitions记录中.
topicInfo.parts.put(record.partitionId(), newPartInfo);
//=>根据partition对应的副本所在broker,记录broker对应的ISR记录集`brokerId=>topicId=>int[partitions]`.
//==>如果对应的brokerId是partition副本的Leader时,其最高位bit位为1(即partitionId的int值最高位为1)
/*prevIsr=null,prevLeader=NO_LEADER*/
brokersToIsrs.update(record.topicId(), record.partitionId(), null,
newPartInfo.isr, NO_LEADER, newPartInfo.leader);
globalPartitionCount.increment();
controllerMetrics.setGlobalPartitionCount(globalPartitionCount.get());
//如果是启动时首次对topic进行replay时,可能有部分partition正在进行重新分配.
//==>把`partitionId`添加到`reassigningTopics`容器中(表示partition在重新分配中).
updateReassigningTopicsIfNeeded(record.topicId(), record.partitionId(),
/*partition有新增或移出的副本时isReassigning==true*/
false, newPartInfo.isReassigning());
}
C-Case2
partitionId在topicInfo中已经存在(topicInfo.parts.get(record.partitionId()) != null).具体逻辑请查看代码片段中的说明.
此时,
=>1,partition已经注册过,但原注册信息与当前的注册信息不一至,更新topicPartition对应的PartitionRegistration.
=>2,更新brokersToIsrs组件中记录每个broker节点管理的partitions的反向索引.
//partition在topicInfo中已经存在,但注册不一样.
else if (!newPartInfo.equals(prevPartInfo)) {
newPartInfo.maybeLogPartitionChange(log, description, prevPartInfo);
//=>把`PartitionRegistration`信息添加到topic的`topicInfo`的partitions记录中(最新的注册信息).
topicInfo.parts.put(record.partitionId(), newPartInfo);
//=>根据`prevPartInfo`中记录的ISR列表与leader对brokerISR进行更新.
//====>1,`prevPartInfo.isr == null`, 直接把`newPartInfo.isr`添加到broker对应的映射关系.
//====>2,`newPartInfo.isr == null`, 直接移出`prevPartInfo.isr`的所有的ISR记录集.
//====>3,移出prevIsr中比newIsr的最小brokerId小的Isr(Leader切换),并重新更新partition的Leader.
brokersToIsrs.update(record.topicId(), record.partitionId(), prevPartInfo.isr,
newPartInfo.isr, prevPartInfo.leader, newPartInfo.leader);
//如果是启动时首次对topic进行replay时,可能有部分partition正在进行重新分配.
//==>把`partitionId`添加到`reassigningTopics`容器中(表示partition在重新分配中).
updateReassigningTopicsIfNeeded(record.topicId(), record.partitionId(),
prevPartInfo.isReassigning(), newPartInfo.isReassigning());
}
4,Broker处理Topic创建
1,MetadataDelta
当broker节点内部的raftManager组件完成对metdata的副本同步后,会通过BrokerMetadataListener来处理消息的重放(replay).
此时会通过当前未publish的MetadataDelta增量信息来执行相应的replay操作.
在处理topic创建时,当监听到TopicRecord与PartitionRecord后,将调用replay(TopicRecord)与replay(PartitionRecord)来进行回放处理.
1,1,repaly(TopicRecord)
当执行topic创建时,controller处理完成副本的分配并把消息写入到metadata后,listener监听到TopicRecord消息时的处理动作.
其代码实现比较简单,
当有topic创建时,只是简单生成一个TopicImage实例,
同时根据新创建的topic生成一个TopicDelta增量实例(用于记录partition的增加与变更),并添加到changedTopics容器中.
此增量消息在执行publish操作时会由ReplicaManager进行处理.
//处理topic创建的消息`TopicRecord`
public void replay(TopicRecord record) {
TopicDelta delta = new TopicDelta(
//根据topic信息生成TopicImage信息.
new TopicImage(record.name(), record.topicId(), Collections.emptyMap()));
//根据topicId记录当前topic的增量到`changedTopics`中(在replay(Partitionxxxx)相关消息时使用).
changedTopics.put(record.topicId(), delta);
}
1,2,repay(PartitionRecord)
当执行topic创建或partitoion的新增时,controller处理完成副本的分配并把消息写入到metadata后,listener监听到PartitionRecord消息时的处理动作.
此处对PartitionRecord消息的replay流程依然很简单,
只是添加到topic对应的TopicDelta中,等待执行publish操作时会由ReplicaManager进行处理.
//处理topic创建或新增partition时的消息`PartitionRecord`
public void replay(PartitionRecord record) {
//从`changedTopics`容器中取对topic对应的TopicDelta.
TopicDelta topicDelta = getOrCreateTopicDelta(record.topicId());
topicDelta.replay(record);
}
//TopicDelta中处理`PartitionRecord`消息的replay
public void replay(PartitionRecord record) {
//记录partition的注册消息到`partitionChanges`中.
partitionChanges.put(record.partitionId(), new PartitionRegistration(record));
}
2,ReplicaManager
2,1,applyDelta(PartitionChanges)
当每次执行createTopic、createPartition以及topic的修改(partition、副本等)后,
会在MetadataDelta中生成针对topicChange的增量信息,并在执行publish时调用此函数应用本次增量的修改.
即:在listener监听到TopicRecord,PartitionRecord,PartitionChangeRecord消息后,在执行publish时处理topic的创建等具体操作.
在applyDelta的处理中,从大的分支上分析,可以分为两类:
A. topic或partitions是新创建的场景(或重新启动).
B. partitions的ISR发生变化,Leader节点有变更.
在BrokerMetadataPublisher的publish中处理topic与partition变更的代码片段:
try {
// Notify the replica manager about changes to topics.
replicaManager.applyDelta(topicsDelta, newImage)
} catch {
case t: Throwable => metadataPublishingFaultHandler.handleFault("Error applying topics " +
s"delta in ${deltaName}", t)
}
而在applyDelta函数中,处理topic变更的操作分为如下几个场景:
1,如果partitions对应的副本已经不在包含当前broker节点时,删除对应的partitions(在当前节点)
2,如果partitions的leader是当前broker节点时,根据是否是新的Partition,创建对应的数据目录与log文件.
3,如果partitions的follower已经不在是当前broker节点时(新创建是分配的leader非当前节点也算),
此时,通过replicaFetcherManager启动fetch线程,同步leader节点的messages到当前节点的副本中.
这里主要分析applyDelta函数处理topic与partition新创建时的代码实现流程分析:
=>1,有partitions的leader副本被分配到当前broker节点时,执行applyLocalLeadersDelta处理.
=>2,有partitions的副本被分配到当前broker节点时,执行applyLocalFollowersDelta处理.
// Handle partitions which we are now the leader or follower for.
if (!localChanges.leaders.isEmpty || !localChanges.followers.isEmpty) {
val lazyOffsetCheckpoints = new LazyOffsetCheckpoints(this.highWatermarkCheckpoints)
val changedPartitions = new mutable.HashSet[Partition]
//处理当前节点是partition的Leader节点时的场景
if (!localChanges.leaders.isEmpty) {
applyLocalLeadersDelta(changedPartitions, delta, lazyOffsetCheckpoints, localChanges.leaders.asScala)
}
//处理当前节点是partition的Follower节点时的场景
if (!localChanges.followers.isEmpty) {
applyLocalFollowersDelta(changedPartitions, newImage, delta, lazyOffsetCheckpoints, localChanges.followers.asScala)
}
maybeAddLogDirFetchers(changedPartitions, lazyOffsetCheckpoints,
name => Option(newImage.topics().getTopic(name)).map(_.id()))
replicaFetcherManager.shutdownIdleFetcherThreads()
replicaAlterLogDirsManager.shutdownIdleFetcherThreads()
}
2,2,applyLocalLeadersDelta
当有partitions的Leader副本被分配到当前的broker节点时,此时会通过此函数来进行处理.
=>1,执行replicaFetcherManager.removeFetcherForPartitions,将对应partitions的fetch线程停止.
因为此时当前节点已经是这些partitions的leader节点,不在需要同步副本.
=>2,对要切换为leader的partitions进行迭代处理.
==>2,1,执行getOrCreatePartition获取或创建对应的Partition实例,因为是处理的创建流程,这里会创建对应的Partition.
关于getOrCreatePartition见后续的分析
==>2,2,根据Partition对应的PartitionRegistration生成对应的state实例(LeaderAndIsrPartitionState).
val state = info.partition.toLeaderAndIsrPartitionState(tp, isNew)
==>2,3,执行Partition.makeLeader函数,来处理partition转换为leader.
传入参数是当前partition的注册状态LeaderAndIsrPartitionState,以及副本对应的"replication-offset-checkpoint"(高水位线信息).
"replication-offset-checkpoint"文件中记录有当前节点副本对应的高水位线(log.highWatermark),
此文件由ReplicaManager中的定时器KafkaScheduler定时flush到磁盘(在ReplicaManager完成初始化启动后启动定时器).
定时执行间隔由"replica.high.watermark.checkpoint.interval.ms"配置,默认为5秒.
private def applyLocalLeadersDelta(
changedPartitions: mutable.Set[Partition],
delta: TopicsDelta,
offsetCheckpoints: OffsetCheckpoints,
localLeaders: mutable.Map[TopicPartition, LocalReplicaChanges.PartitionInfo]
): Unit = {
stateChangeLogger.info(s"Transitioning ${localLeaders.size} partition(s) to " +
"local leaders.")
//由于节点已经从非`leader`状态变更为`leader`时,此时需要停止对应`partitions`的`fetch`线程.
//==>此时节点就是partition的leader,因此不再需要从leader同步.
replicaFetcherManager.removeFetcherForPartitions(localLeaders.keySet)
localLeaders.forKeyValue { (tp, info) =>
//获取topicPartition对应的`Partition`实例,此时在创建topic过程是执行createPartition操作.
getOrCreatePartition(tp, delta, info.topicId).foreach { case (partition, isNew) =>
try {
//根据`PartitionRegisteration`获取到对应的partition状态(LeaderAndIsrPartitionState).
val state = info.partition.toLeaderAndIsrPartitionState(tp, isNew)
//执行partition中的makeLeader函数来处理partition切换为leader副本.
partition.makeLeader(state, offsetCheckpoints, Some(info.topicId))
changedPartitions.add(partition)
} catch {
case e: KafkaStorageException =>
stateChangeLogger.info(s"Skipped the become-leader state change for $tp " +
s"with topic id ${info.topicId} due to a storage error ${e.getMessage}")
markPartitionOffline(tp)
}
}
}
}
Partition.makeLeader函数,设置当前节点为partition的Leader节点
Step=>1,
执行updateAssignmentAndIsr函数,存储此partition对应的副本分配信息与ISR信息.
把所有的follower节点放入到Partition实例的remoteReplicasMap容器中.
把所有的副本分配状态存储到Partition实例的assignmentState中(包含删除与新增的).
=>1, 如果addingReplicas或者removingReplicas不为空时,此时assignmentState变更 为OngoingReassignmentState.
=>2,否则,此时assignmentState任然是SimpleAssignmentState,但partition对应的所有副本节点已经被初始化.
把ISR列表信息存储到Partition实例的partitionState中(此时partitionState对应的ISR被初始化).
//当发生过leader的切换时,`isNewLeader = isNewLeaderEpoch = true`.
val isNewLeader = !isLeader
val isNewLeaderEpoch = partitionState.leaderEpoch > leaderEpoch
val replicas = partitionState.replicas.asScala.map(_.toInt)
val isr = partitionState.isr.asScala.map(_.toInt).toSet
val addingReplicas = partitionState.addingReplicas.asScala.map(_.toInt)
val removingReplicas = partitionState.removingReplicas.asScala.map(_.toInt)
if (partitionState.leaderRecoveryState == LeaderRecoveryState.RECOVERING.value) {
stateChangeLogger.info(s"The topic partition $topicPartition was marked as RECOVERING. " +
"Marking the topic partition as RECOVERED.")
}
updateAssignmentAndIsr(
replicas = replicas,
isLeader = true,
isr = isr,
addingReplicas = addingReplicas,
removingReplicas = removingReplicas,
LeaderRecoveryState.RECOVERED
)
Step=>2,
执行createLogIfNotExists函数创建topicPartition对应的数据存储目录与Log文件(新创建的partition).
createLogIfNotExists(partitionState.isNew, isFutureReplica = false, highWatermarkCheckpoints, topicId)
在此步骤中,执行logManager组件的getOrCreateLog函数来创建Partition对应的UnifiedLog实例.
如果是非topic或者partition的创建时,从logManager中得到原有的log实例.
初始化此topicPartition的高水位线(highWatermarkMetadata)offset值.
初始创建时,高水位线值为0,否则从"replication-offset-checkpoint"文件中获取到上一次保存的值.
关于初始创建UnifiedLog实例见后续的分析
try {
createLogIfNotExists(partitionState.isNew, isFutureReplica = false, highWatermarkCheckpoints, topicId)
} catch {
case e: ZooKeeperClientException =>
stateChangeLogger.error(s"A ZooKeeper client exception has occurred and makeLeader will be skipping the " +
s"state change for the partition $topicPartition with leader epoch: $leaderEpoch.", e)
return false
}
val leaderLog = localLogOrException
==>Partition.createLog函数实现代码片段:
logManager.initializingLog(topicPartition)
var maybeLog: Option[UnifiedLog] = None
try {
//创建`UnifiedLog`实例,如果是新创建的partition,此时会创建一个`UnifiedLog`实例并生成对应的存储目录与segment文件.
val log = logManager.getOrCreateLog(topicPartition, isNew, isFutureReplica, topicId)
maybeLog = Some(log)
updateHighWatermark(log) //更新log的高水位线的值.
log
} finally {
logManager.finishedInitializingLog(topicPartition, maybeLog)
}
Step=>3,
isNewLeaderEpoch==true的场景: partitionState.leaderEpoch > leaderEpoch
当前节点切换为partition的leader节点时,其对应的epoch值发生了变更(比原来的epoch值大)
==>此时,说明节点是新切换为leader节点(如partition变更时只培养follower节点的情况leaderEpoch变不会变化),
=>1,将当前最新的leaderEpoch与当前本地副本对应的logEndOffset写入缓存"leader-epoch-checkpoint"文件中.
==>此过程通过leaderLog.maybeAssignEpochStartOffset函数来完成.
=>2,重置当前partition在remoteReplicasMap记录的所有副本的副本状态(ReplicaState),见下面的resetReplicaState函数注释.
=>3,更新partition的leaderEpoch值为当前replay的最新的epoch .
==>leaderEpoch = partitionState.leaderEpoch
=>4,更新partition的leaderEpochStartOffsetOpt为本地副本的logEndOffset.
==>leaderEpochStartOffsetOpt = Some(leaderEpochStartOffset)
if (isNewLeaderEpoch) {
val leaderEpochStartOffset = leaderLog.logEndOffset
stateChangeLogger.info(s"Leader $topicPartition with topic id $topicId starts at ..")
//新切换leader,记录当前最新的epoch对应本地副本的endOffset.
leaderLog.maybeAssignEpochStartOffset(partitionState.leaderEpoch, leaderEpochStartOffset)
// Initialize lastCaughtUpTime of replicas as well as their lastFetchTimeMs and
// lastFetchLeaderLogEndOffset.
remoteReplicas.foreach { replica =>
replica.resetReplicaState(
currentTimeMs = currentTimeMs,
leaderEndOffset = leaderEpochStartOffset,
isNewLeader = isNewLeader,
isFollowerInSync = partitionState.isr.contains(replica.brokerId)
)
}
// We update the leader epoch and the leader epoch start offset iff the
// leader epoch changed.
leaderEpoch = partitionState.leaderEpoch
leaderEpochStartOffsetOpt = Some(leaderEpochStartOffset)
}
==>replica.resetReplicaState函数,重置follower节点副本的状态:
此时要判断本次partition的副本变更是否有变更leader节点.
//最后完成同步的时间,如果副本在`ISR`列表内,设置为当前时间,否则设置为0.
val lastCaughtUpTimeMs = if (isFollowerInSync) currentTimeMs else 0L
if (isNewLeader) {
//当前leader发生变更,此时leader由原来其它的节点(或没有)切换到当前节点,重置ReplicaState记录的offset.
ReplicaState(
logStartOffset = UnifiedLog.UnknownOffset,
logEndOffsetMetadata = LogOffsetMetadata.UnknownOffsetMetadata,
lastFetchLeaderLogEndOffset = UnifiedLog.UnknownOffset,
lastFetchTimeMs = 0L,
lastCaughtUpTimeMs = lastCaughtUpTimeMs
)
} else {
//当前节点原本就是leader节点,此次partition的变更并不涉及到leader的变更,保持原状态不变.
ReplicaState(
logStartOffset = currentReplicaState.logStartOffset,
logEndOffsetMetadata = currentReplicaState.logEndOffsetMetadata,
lastFetchLeaderLogEndOffset = leaderEndOffset,
/*判断副本所在的节点是否在ISR列表中,如果在设置最后一次fetch的时间为当前时间,否则设置为0*/
lastFetchTimeMs = if (isFollowerInSync) currentTimeMs else 0L,
lastCaughtUpTimeMs = lastCaughtUpTimeMs
)
}
Step=>4,
=>1,更新Partition的partitionEpoch的值为当前最新的值(每次变更partitionEpoch都会增加).
=>2,更新Partition中leaderReplicaIdOpt记录的leader节点为当前节点的brokerId.
partitionEpoch = partitionState.partitionEpoch
leaderReplicaIdOpt = Some(localBrokerId)
//检查是否需要更新高水位线,这个在partition的副本变更时可能会导致ISR的增减(先不分析).
// We may need to increment high watermark since ISR could be down to 1.
(maybeIncrementLeaderHW(leaderLog, currentTimeMs = currentTimeMs), isNewLeader)
Step=>5,
最后: 如果partition的高水位线发生变化,唤醒等待中的delayed操作(如fetch,producer等)
// Some delayed operations may be unblocked after HW changed.
if (leaderHWIncremented)
tryCompleteDelayedRequests()
isNewLeader
2,3,applyLocalFollowersDelta
当有partitions的Follower副本被分配到当前的broker节点时,此时会通过此函数来进行处理.
Step=>1,
对要切换为follower的partitions进行迭代处理localFollowers.forKeyValue.
=>1,执行getOrCreatePartition获取或创建对应的Partition实例,因为是处理的创建流程,这里会创建对应的Partition.
关于getOrCreatePartition见后续的分析
=>2,根据Partition对应的PartitionRegistration生成对应的state实例(LeaderAndIsrPartitionState).
val state = info.partition.toLeaderAndIsrPartitionState(tp, isNew)
=>3,执行Partition.makeFollower函数,来处理partition转换为Follower(如果leader未发生变化时,此函数的返回值为false).
=>4,如果此次partition的变更涉及到leader的变更时,根据**=>3**得到isNewLeaderEpoch == true的场景.
此时,将partition添加到partitionsToStartFetching容器中(表示副本需要启fetch线程从leader同步副本).
localFollowers.forKeyValue { (tp, info) =>
getOrCreatePartition(tp, delta, info.topicId).foreach { case (partition, isNew) =>
try {
followerTopicSet.add(tp.topic)
if (shuttingDown) {
stateChangeLogger.trace(s"Unable to start fetching $tp with topic " +
s"ID ${info.topicId} because the replica manager is shutting down.")
} else {
val state = info.partition.toLeaderAndIsrPartitionState(tp, isNew)
val isNewLeaderEpoch = partition.makeFollower(state, offsetCheckpoints, Some(info.topicId))
if (isInControlledShutdown && (info.partition.leader == NO_LEADER ||
!info.partition.isr.contains(config.brokerId))) {
partitionsToStopFetching.put(tp, false)
} else if (isNewLeaderEpoch) {
partitionsToStartFetching.put(tp, partition)
}
}
changedPartitions.add(partition)
} catch {
case e: KafkaStorageException =>
stateChangeLogger.error(s"Unable to start fetching $tp " +
s"with topic ID ${info.topicId} due to a storage error ${e.getMessage}", e)
replicaFetcherManager.addFailedPartition(tp)
markPartitionOffline(tp)
case e: Throwable =>
stateChangeLogger.error(s"Unable to start fetching $tp " +
s"with topic ID ${info.topicId} due to ${e.getClass.getSimpleName}", e)
replicaFetcherManager.addFailedPartition(tp)
}
}
}
Partition.makeFollower函数,设置当前节点为partition的Follower节点
3-Step=>1,
执行updateAssignmentAndIsr函数,更新partition在当前节点的assignment状态信息.
从remoteReplicasMap容器中清空当前所有follower的节点信息(非leader副本不负责其它副本的数据同步).
把所有的副本分配状态存储到Partition实例的assignmentState中(包含删除与新增的).
=>1, 如果addingReplicas或者removingReplicas不为空时,此时assignmentState变更 为OngoingReassignmentState.
=>2,否则,此时assignmentState任然是SimpleAssignmentState,但partition对应的所有副本节点已经被初始化.
清空Partition在当前节点副本的partitionState中ISR信息(Follower节点不记录partition的ISR列表).
updateAssignmentAndIsr(
replicas = partitionState.replicas.asScala.iterator.map(_.toInt).toSeq,
isLeader = false,
isr = Set.empty, //非leader节点,不记录ISR信息.
addingReplicas = partitionState.addingReplicas.asScala.map(_.toInt),
removingReplicas = partitionState.removingReplicas.asScala.map(_.toInt),
LeaderRecoveryState.of(partitionState.leaderRecoveryState)
)
3-Step=>2
==>1,执行createLogIfNotExists函数创建topicPartition对应的数据存储目录与Log文件(新创建的partition).
createLogIfNotExists(partitionState.isNew, isFutureReplica = false, highWatermarkCheckpoints, topicId)
在此步骤中,执行logManager组件的getOrCreateLog函数来创建Partition对应的UnifiedLog实例.
如果是非topic或者partition的创建时,从logManager中得到原有的log实例.
初始化此topicPartition的高水位线(highWatermarkMetadata)offset值.
初始创建时,高水位线值为0,否则从"replication-offset-checkpoint"文件中获取到上一次保存的值.
关于初始创建UnifiedLog实例见后续的分析
==>2,判断当前副本跟随的leader节点是否发生变化(isNewLeaderEpoch == true表示leader发生了切换).
在applyLocalFollowersDelta函数的后续的步骤中,需要更新leader是否切换来判断是否需要新启动fetch线程来同步leader的数据
=>3,更新Partition中leaderReplicaIdOpt记录的leader节点为当前partition中最新的leader节点所对应的brokerId.
=>4,记录当前leader节点此partition最新的leaderEpoch,让所有副本的leaderEpoch都保持与leader的同步.
=>5,更新Partition的partitionEpoch的值为当前最新的值(每次变更partitionEpoch都会增加).
=>6,设置leaderEpochStartOffsetOpt的值为None,只有在leader节点才记录每次切换为leader时对应的epoch与logEndOffset.
//创建`topicPartition`对应的数据存储目录与Log文件(**新创建的partition**).
try {
createLogIfNotExists(partitionState.isNew, isFutureReplica = false, highWatermarkCheckpoints, topicId)
} catch {
case e: ZooKeeperClientException =>
stateChangeLogger.error(s"A ZooKeeper client exception has occurred. makeFollower will be skipping the " +
s"state change for the partition $topicPartition with leader epoch: $leaderEpoch.", e)
return false
}
val followerLog = localLogOrException //获取到刚生成的UnifiedLog实例.
//判断当前partition的leader节点是否发生切换(如果切换leaderEpoch会增加)
val isNewLeaderEpoch = partitionState.leaderEpoch > leaderEpoch
//就是打印几行日志,不用管.
if (isNewLeaderEpoch) {
val leaderEpochEndOffset = followerLog.logEndOffset
stateChangeLogger.info(s"Follower $topicPartition starts at leader epoch ${partitionState.leaderEpoch} from " +
s"offset $leaderEpochEndOffset with partition epoch ${partitionState.partitionEpoch} and " +
s"high watermark ${followerLog.highWatermark}. Current leader is ${partitionState.leader}. " +
s"Previous leader epoch was $leaderEpoch.")
} else {
stateChangeLogger.info(s"Skipped the become-follower state change for $topicPartition with topic id $topicId " +
s"and partition state $partitionState since it is already a follower with leader epoch $leaderEpoch.")
}
leaderReplicaIdOpt = Option(partitionState.leader)
leaderEpoch = partitionState.leaderEpoch
leaderEpochStartOffsetOpt = None
partitionEpoch = partitionState.partitionEpoch
//返回leader是否切换的信息,在调用方的后续步骤中会使用到.
isNewLeaderEpoch
Step=>2
此时Partition.makeFollower函数执行完成,流程回到applyLocalFollowersDelta函数中.
启动当前节点新增加的partition副本与其对应的leader节点的副本同步线程(见Step=>1中的=>4的部分).
=>1,初始化所有待同步的follower对应的副本同步状态为InitialFetchState(其initOffset的值为当前的logEndOffset).
=>2,利用replicFetcherManager组件启动ReplicaFetcherThread线程来不断从leader节点拉取最新的消息同步到本地副本中.
此步骤涉及到两个配置项:
replica.fetch.backoff.ms,默认值(1秒),当leader没有最新的消息可同步时,follower节点backoff时间.
num.replica.fetchers,默认值(1),相同的leaderBroker节点最大可启动的fetch线程的个数,
即:默认情况下一个leaderBroker只有一个线程来获取所有在此broker上的leader节点的消息副本.
//partition的`follower`副本是当前节点,同时部分partitions对应的leader节点发生切换时,
if (partitionsToStartFetching.nonEmpty) {
//先停止掉原来监听的leader节点的`fetch`线程.
replicaFetcherManager.removeFetcherForPartitions(partitionsToStartFetching.keySet)
stateChangeLogger.info(s"Stopped fetchers as part of become-follower for ${partitionsToStartFetching.size} partitions")
//初始化`follower`对应的`FetchState`为`InitialFetchState`.
val listenerName = config.interBrokerListenerName.value
val partitionAndOffsets = new mutable.HashMap[TopicPartition, InitialFetchState]
//迭代所有leader变化的partitions,初始化与leader的副本同步状态,并设置leader正确的网络通信的endpoint.
partitionsToStartFetching.forKeyValue { (topicPartition, partition) =>
val nodeOpt = partition.leaderReplicaIdOpt
.flatMap(leaderId => Option(newImage.cluster.broker(leaderId)))
.flatMap(_.node(listenerName).asScala)
nodeOpt match {
case Some(node) =>
val log = partition.localLogOrException
partitionAndOffsets.put(topicPartition, InitialFetchState(
log.topicId,
new BrokerEndPoint(node.id, node.host, node.port),
partition.getLeaderEpoch,
/*初始化当前follower对应的initOffset的值为本地副本的logEndOffset*/
initialFetchOffset(log)
))
case None =>
stateChangeLogger.trace(s"Unable to start fetching $topicPartition with topic ID ${partition.topicId} " +
s"from leader ${partition.leaderReplicaIdOpt} because it is not alive.")
}
}
//利用`replicaFetcherManager`
replicaFetcherManager.addFetcherForPartitions(partitionAndOffsets)
stateChangeLogger.info(s"Started fetchers as part of become-follower for ${partitionsToStartFetching.size} partitions")
partitionsToStartFetching.keySet.foreach(completeDelayedFetchOrProduceRequests)
updateLeaderAndFollowerMetrics(followerTopicSet)
}
getOrCreatePartition
getOrCreatePartition函数初始化创建Partition实例(只针对applyDelta涉及到新增Partition的场景的分析):
=>1,根据topicPartition的信息,初始化生成Partition实例
=>2,将新生成的Partition实例添加到allPartitions容器中,此时其状态默认为Online状态.
case HostedPartition.None =>
if (delta.image().topicsById().containsKey(topicId)) {
stateChangeLogger.error(s"Expected partition $tp with topic id " +
s"$topicId to exist, but it was missing. Creating...")
} else {
stateChangeLogger.info(s"Creating new partition $tp with topic id " +
s"$topicId.")
}
// it's a partition that we don't know about yet, so create it and mark it online
val partition = Partition(tp, time, this)
allPartitions.put(tp, HostedPartition.Online(partition))
Some(partition, true)
Partition实例初始化构建的代码片段:
配置项说明:
"replica.lag.time.max.ms",默认值(30秒),follower节点的超时时间,当超过这个时间未来向leader同步,表示副本不在可用.
初始化时Partition的关键属性值:
remoteReplicasMap 当前partition对应的follower节点信息,默认为空容器.
partitionEpoch 记录当前partition的副本更新次数,初始时值为0,每次partition变更(ISR等)时epoch值加1.
leaderEpoch 记录当前partition对应的leaderEpoch的值,每次leader切换时更新,初始值为-1.
leaderEpochStartOffsetOpt 节点在被切换为leader时记录的epoch与当前log.endOffset的值,初始为None.
leaderReplicaIdOpt 记录当前partition对应的leader节点,初始时值为None.
partitionState 当前partition的状态,记录有partition的ISR与状态,
初始为CommittedPartitionState(Set.empty, LeaderRecoveryState.RECOVERED)
assignmentState 记录partition对应的副本分配信息,初始为SimpleAssignmentState(Seq.empty).
//delayedOperations:作用于处理`fetch`或者`producer`等消息的延时响应.即:
//=>当leader有新的消息写入后唤醒delayedFetch的等待.
//=>当follower节点同步副本超过最小副本数量后delayedProduce的等待.
val delayedOperations = new DelayedOperations(
topicPartition,
replicaManager.delayedProducePurgatory,
replicaManager.delayedFetchPurgatory,
replicaManager.delayedDeleteRecordsPurgatory)
//初始化生成`Partition`实例.
new Partition(topicPartition,
replicaLagTimeMaxMs = replicaManager.config.replicaLagTimeMaxMs,
interBrokerProtocolVersion = replicaManager.config.interBrokerProtocolVersion,
localBrokerId = replicaManager.config.brokerId,
time = time,
alterPartitionListener = isrChangeListener,
delayedOperations = delayedOperations,
metadataCache = replicaManager.metadataCache,
logManager = replicaManager.logManager,
alterIsrManager = replicaManager.alterPartitionManager)
getOrCreateLog(LogManager)
此函数在broker节点的listener监听到TopicsDelta变化后(如创建topic/partition,以及副本、ISR的变更后).
由ReplicaManager组件的applyDelta函数(createLog)来触发调用.此部分的流程分析主要分析topic/partition的新增时的流程(即createLog).
主要作用是根据新增的partition在最合适的logDir目录下创建topicPartition的存储目录,
==>并在初始化UnifiedLog实例时生成log存储的首个segment文件.
val log = getLog(topicPartition, isFuture).getOrElse {
.....主要分析else部分的创建log的流程.....
log
}
在执行createLog操作时,其处理逻辑如下:
Step=>1,
根据logDirs中存储的topicPartitions的个数按从少到多的顺序排列.
此步骤的目的是为创建topicPartition数据存储目录获取到一个最少partition数量的目录.
val logDirs: List[File] = {
//alterLogdirs的情况下才会发生,先不考虑.
val preferredLogDir = preferredLogDirs.get(topicPartition)
if (isFuture) {
...先不考虑future类型的partition...
}
if (preferredLogDir != null)
List(new File(preferredLogDir))
else
//按每个logDir下存储的topicPartitions个数进行排序.
nextLogDirs()
}
Step=>2,
根据topicPartition生成此partition的数据目录存储名称,并在排序后的第一个(最少partitions)目录中创建对应的topicPartition的数据存储目录.
采用iterator惰性加载,执行createLogDirectory成功后就结束,此时topicPartition在logDir下的具体存储目录已经创建完成.
//生成topicPartition的数据目录名称(topicName-partitionIndex)
val logDirName = {
if (isFuture)
UnifiedLog.logFutureDirName(topicPartition)
else
UnifiedLog.logDirName(topicPartition)
}
//得到logDir/topic-partition对应的全路径.
val logDir = logDirs
.iterator.map(createLogDirectory(_, logDirName))
.find(_.isSuccess)
.getOrElse(Failure(new KafkaStorageException("No log directories available. Tried...)))
.get
Step=>3,
生成topicPartition下用于管理log读写的UnifiedLog实例.
此实例负责管理partition下所有的segments,以及log中的startOffset,高水位,endOffset等关键信息,并提供消息的写入与读取统一入口.
关于UnifiedLog实例在新增partition时的初始化,见UnifiedLog部分的分析.
在初始生成UnifiedLog实例时,其对应的logStartOffset = recoveryPoint = 0
val log = UnifiedLog(
dir = logDir,config = config,logStartOffset = 0L,recoveryPoint = 0L,
maxTransactionTimeoutMs = maxTransactionTimeoutMs,
maxProducerIdExpirationMs = maxPidExpirationMs,
producerIdExpirationCheckIntervalMs = LogManager.ProducerIdExpirationCheckIntervalMs,
scheduler = scheduler,time = time,
brokerTopicStats = brokerTopicStats,
logDirFailureChannel = logDirFailureChannel,topicId = topicId,
//`keepPartitionMetadataFile=true`.
keepPartitionMetadataFile = keepPartitionMetadataFile)
Step=>4,
最后,把新创建的UnifiedLog实例添加到对应的currentLogs容器中.
//把topicPartition对应的log实例添加到容器中.
if (isFuture)
futureLogs.put(topicPartition, log)
else
currentLogs.put(topicPartition, log)
UnifiedLog
UnifiedLog是TopicPartition日志服务的统一入口,所有消息的写入读取、segments以及offset等都由此组件进行维护.
初始化(新增partition)
针对一个新增的partition的UnifiedLog实例的初始化部分由LogManager中的getOrCreateLog函数来触发.
见getOrCreateLog(LogManager)中的Step3部分,其直接使用UnifiedLog静态实例听apply来进行实例的初始化.
几个关键传入属性logStartOffset与recoveryPoint的值都是初始的0(表示刚新增).
==>UnifiedLog.apply辅助构建UnifiedLog实例的代码实现:
Step=>1,
初始化用于存储segment的数据结构LogSegments(跳表),
同时生成用于记录append时每个batch对应epoch与baseOffset记录的"leader-epoch-checkpoint"文件.
由于是新增partition时的初始化UnifiedLog,因此其lastShutdownClean默认为true,表示上一次正常关闭,不需要进行recovery操作.
// create the log directory if it doesn't exist
Files.createDirectories(dir.toPath)
val topicPartition = UnifiedLog.parseTopicPartitionName(dir)
//生成用于存储topicPartition的segment日志段文件的结构.
//==>其内部维护一个SkipList的结构用于记录log中的所有segment.
val segments = new LogSegments(topicPartition)
//初始化新增partition的"leader-epoch-checkpoint"文件.
//==>当broker是当前partition的Leader时,
//====>在切换为leader的同时会向此文件中写入最新的epoch与leaderLog.endOffset.
val leaderEpochCache = UnifiedLog.maybeCreateLeaderEpochCache(
dir,topicPartition,logDirFailureChannel,config.recordVersion,
s"[UnifiedLog partition=$topicPartition, dir=${dir.getParent}] ")
Step=>2,
构造LogLoader实例,并通过其load函数来执行segments的加载并清理相应的snapshot文件.
在新增partition初始化时:
LogLoader中的logStartOffsetCheckpoint与recoveryPointCheckpoint的值都是0.
由于此时topicPartition下没有任何的segment日志段与snapshot文件,因此:
会通过如下代码片段生成topicPartition下的第一个Segment日志段文件.
执行recoverLog函数初始化一个segment文件,此时:返回值中的newRecoveryPoint == nextOffset == 0.
val (newRecoveryPoint: Long, nextOffset: Long) = {
if (!dir.getAbsolutePath.endsWith(UnifiedLog.DeleteDirSuffix)) {
val (newRecoveryPoint, nextOffset) = retryOnOffsetOverflow(recoverLog)
//对segment的`OffsetIndex`文件与`TimeIndex`文件大小进行重置.
//=>1,`OffsetIndex`文件的大小: 8 * 10mb / 8(单条offset索引的大小)
//====>ofsetIndex = offset(高32位,4byte) + offset在segemnt中的Postition(4byte)
//=>2,`TimeIndex`文件的大小: 12 * (10mb / 12(单条time索引的大小))
//====>timeIndex = timestamp(8byte) + offset的高32位(4byte)
segments.lastSegment.get.resizeIndexes(config.maxIndexSize)
(newRecoveryPoint, nextOffset)
} else {
....这里不会执行(只有topicPartition是deleted时才执行)....
}
}
注意:此时LogLoader中的属性hadCleanShutdown == lastShutdownClean == true.
**因此:**在recoverLog函数中会跳过logReovery的日志恢复处理.
由于此时LogSegments中没有任何的segment文件,此时会执行如下代码片段生成一个新的Segment.
每个segment文件的文件名”baseOffset(固定20个字符长度).log”.
if (segments.isEmpty) {
// no existing segments, create a new mutable segment beginning at logStartOffset
segments.add(
LogSegment.open(
dir = dir,
/*baseOffset此时初始化值为0*/
baseOffset = logStartOffsetCheckpoint,
config, time = time,
/*
根据:`log.preallocate`的配置(默认为false),如果为true时,
segment会提前按`log.segment.bytes`的配置(默认1g)提前生成一个指定大小的文件.
否则默认初始化的文件大小是0.
*/
initFileSize = config.initFileSize,
//`log.preallocate`默认值为false.
preallocate = config.preallocate))
}
生成segment实例时,有如下几个配置项需要使用到:
=>log.segment.bytes : 默认值(1g),每个segment的文件大小.
=>log.preallocate : 默认值(false),配置是否预先创建一个segmentSize大小的空文件.
提前创建segment文件有助于使segment文件在磁盘中分配连续的存储块.
=>log.index.size.max.bytes : 默认值(10mb),segment的索引文件的大小.
=>index.interval.bytes : 默认值(4kb),当append的数据量达到指定的大小后,生成一个index条目.
这个值建议每个topic根据自身单条消息的大小进行设置.
=>log.roll.hours : 默认值(168),即segment未达到指定的文件大小,但已经超过这个时间后,任然会滚动创建一个新的segment.
=>log.roll.jitter.hours : 默认值(0),与log.roll.hours配合使用,防止segment同时滚动(让每个segment滚动都有一个漂移时间).
最后:Loader中的load函数将返回对logRecovery操作后的offset信息(初始时不做recovery)
//初始生成时,涉及到的offset都是0.
val activeSegment = segments.lastSegment.get
LoadedLogOffsets(
newLogStartOffset, //初始时值为0
newRecoveryPoint, //初始时值为0
//nextOffset初始时值为0
LogOffsetMetadata(nextOffset, activeSegment.baseOffset, activeSegment.size))
Step=>3,
构造LocalLog实例,此实例作用于log存储(appendOnly)本地消息与segment的滚动.
注意:LocalLog实例是非线程安全的实例,此实例的线程安全保证由UnifiedLog来进行保证.
//初始化LocalLog实例,此实例对activeSegment进行appendOnly操作.
//=>partition初始创建时:segments只有一个segment文件,
val localLog = new LocalLog(dir, config, segments, offsets.recoveryPoint,
offsets.nextOffsetMetadata, scheduler, time, topicPartition, logDirFailureChannel)
Step=>4,
此时,根据**Step1~3**获取到的相应信息,对UnifiedLog实例进行初始化.
new UnifiedLog(offsets.logStartOffset, //新增partition时值为0
localLog, brokerTopicStats,
producerIdExpirationCheckIntervalMs,
leaderEpochCache, producerStateManager, topicId,
//keepPartitionMetadataFile == true.
keepPartitionMetadataFile)
注意:
当UnifiedLog实例初始化时,其默认的高水位线的值为log.logStartOffset的值.
其高水位线的值会在ReplicaManager中的createLog时获取到返回的UnifiedLog实例后:
通过读取"replication-offset-checkpoint"文件(或初始化时为0)来初始化UnifiedLog的高水位线值.
此文件中记录有每个topicPartition中最后一个flush到磁盘的recoveryPoint的offset记录
文件由replica.high.watermark.checkpoint.interval.ms配置的定时(默认5秒),定时对log.highWatermark进行flush动作.
同时,在UnifiedLog实例初始化时,会执行如下几个函数来进行必要的初始化动作:
=>1, 执行initializePartitionMetadata函数,创建或加载"partition.metadata"文件.
=>2, 执行initializeTopicId函数,把新增的partition对应的topicId写入到"partition.metadata"文件.
到此处,针对于新增partition时的UnifiedLog实例的初始化过程结束.