数据规模->时间复杂度
<=10^4 😮(n^2)
<=10^7:o(nlogn)
<=10^8:o(n)
10^8<=:o(logn),o(1)
内容

lc 217 :存在重复元素
https://leetcode.cn/problems/contains-duplicate/
提示:
1 <= nums.length <= 10^5
-10^9 <= nums[i] <= 10^9
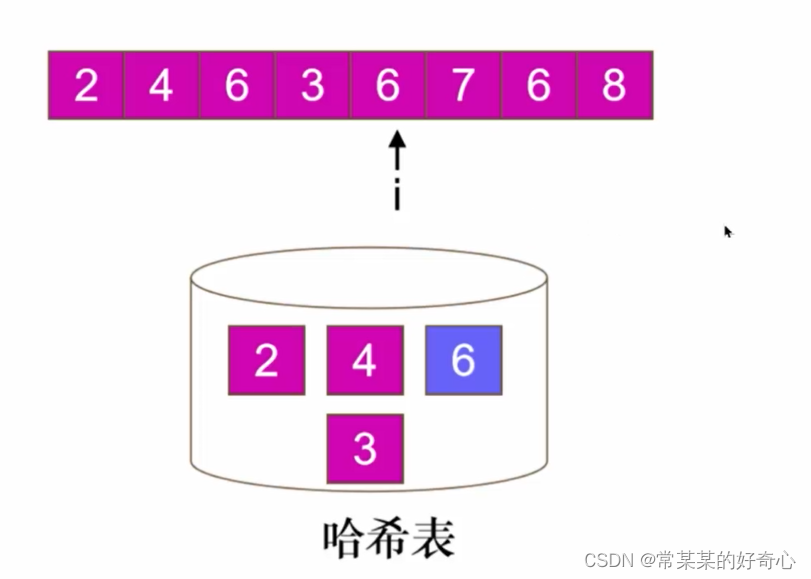
#方案一:哈希
#o(n),o(n)
class Solution:
def containsDuplicate(self, nums: List[int]) -> bool:
#写法1
# visited=set()
# for i in range(len(nums)):
# if nums[i] in visited:return True
# visited.add(nums[i])
# return False
#写法2
# visited={}
# for i in range(len(nums)):
# if visited.get(nums[i]):return True #if nums[i] in visited
# visited[nums[i]]=1
# return False
#写法3
return len(nums)!=len(set(nums))
#方案二:排序
#时:o(nlogn),空:o(logn)/o(n)
class Solution:
def containsDuplicate(self, nums: List[int]) -> bool:
#nums.sort()
nums=sorted(nums)
for i in range(1,len(nums)):
if nums[i]==nums[i-1]:return True
return False
lc 219 :存在重复元素 II
https://leetcode.cn/problems/contains-duplicate-ii/
提示:
1 <= nums.length <= 10^5
-109 <= nums[i] <= 10^9
0 <= k <= 10^5
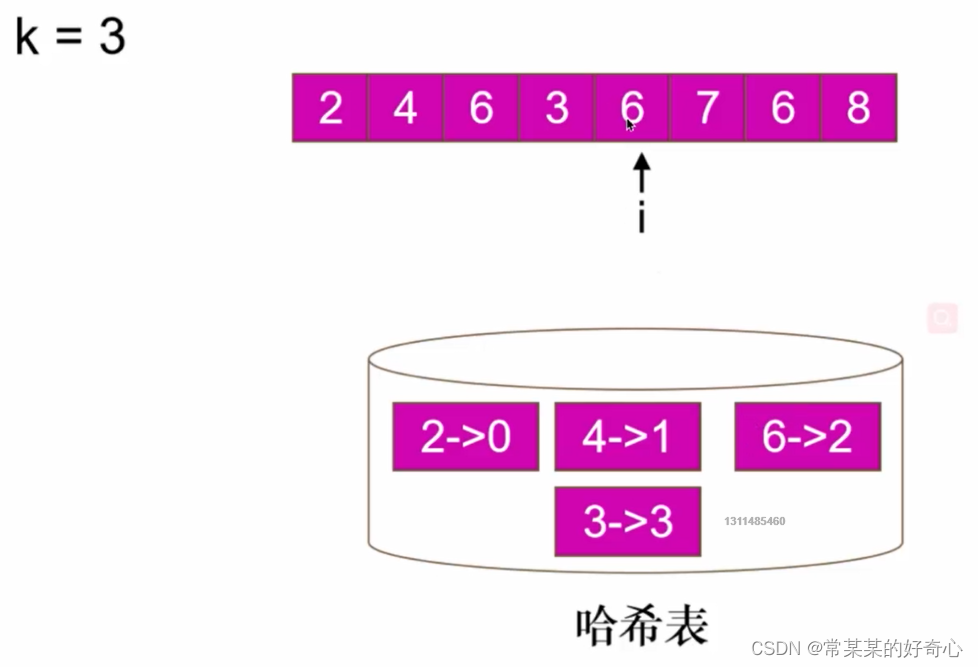
#方案一:哈希
#o(n),o(n)
class Solution:
def containsNearbyDuplicate(self, nums: List[int], k: int) -> bool:
visited={}
for i in range(len(nums)):
if nums[i] in visited and i-visited[nums[i]]<=k:return True #visited.get(nums[i])等价于visited[nums[i]]
visited[nums[i]]=i
return False
#方案二:滑动窗+哈希
#时:o(n),空:o(min(n,k))
class Solution:
def containsNearbyDuplicate(self, nums: List[int], k: int) -> bool:
left=right=0
window=set()
while right<len(nums):
#
if nums[right] in window:return True
#
window.add(nums[right])
if len(window)>k:
window.remove(nums[left])
left+=1
#更新窗口
right+=1
return False
lc 220 【剑指 057】:存在重复元素 III
https://leetcode.cn/problems/contains-duplicate-iii/
提示:
0 <= nums.length <= 2 * 10^4
-2^31 <= nums[i] <= 2^31 - 1
0 <= k <= 10^4
0 <= t <= 2^31 - 1
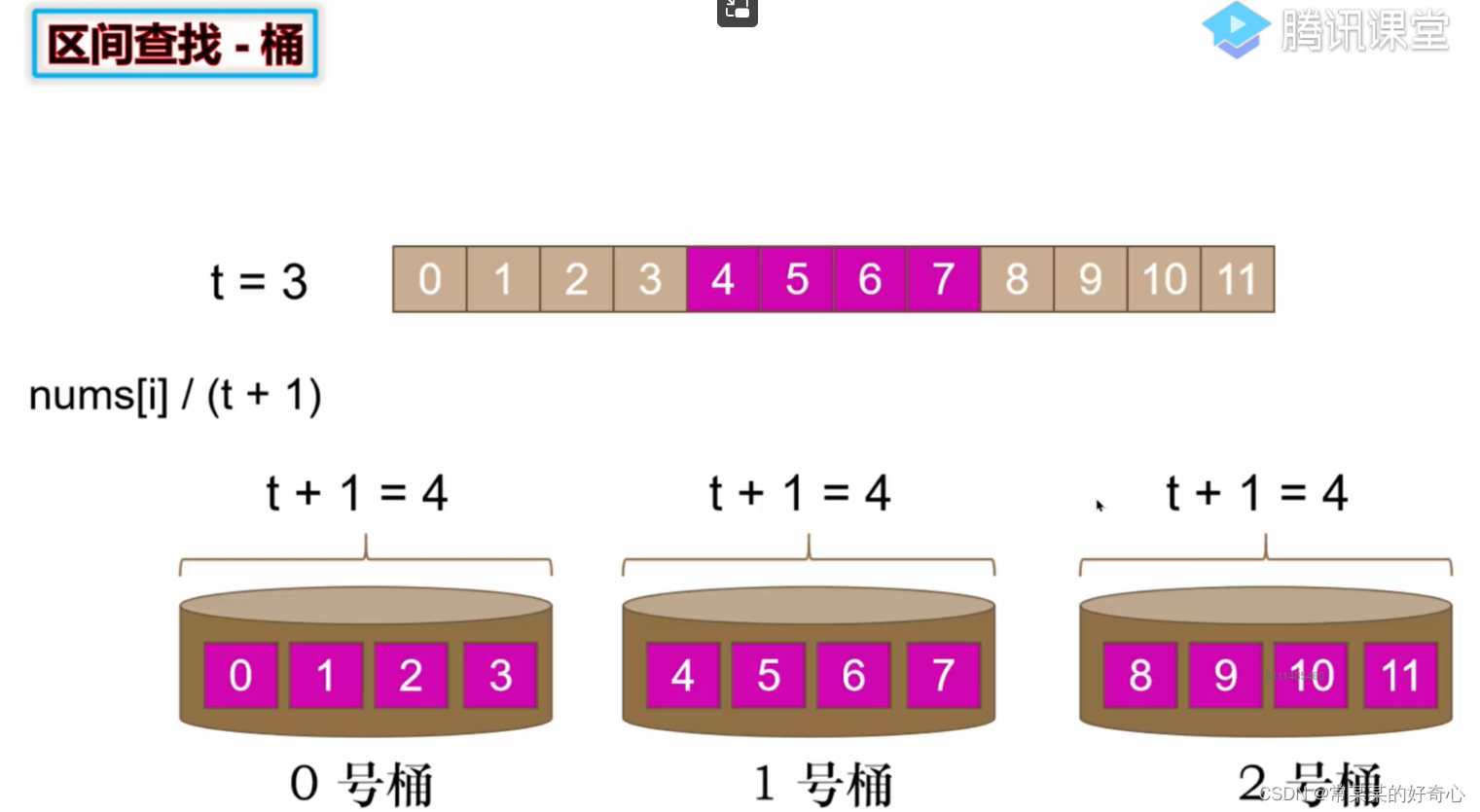
注意:相邻桶也有可能存在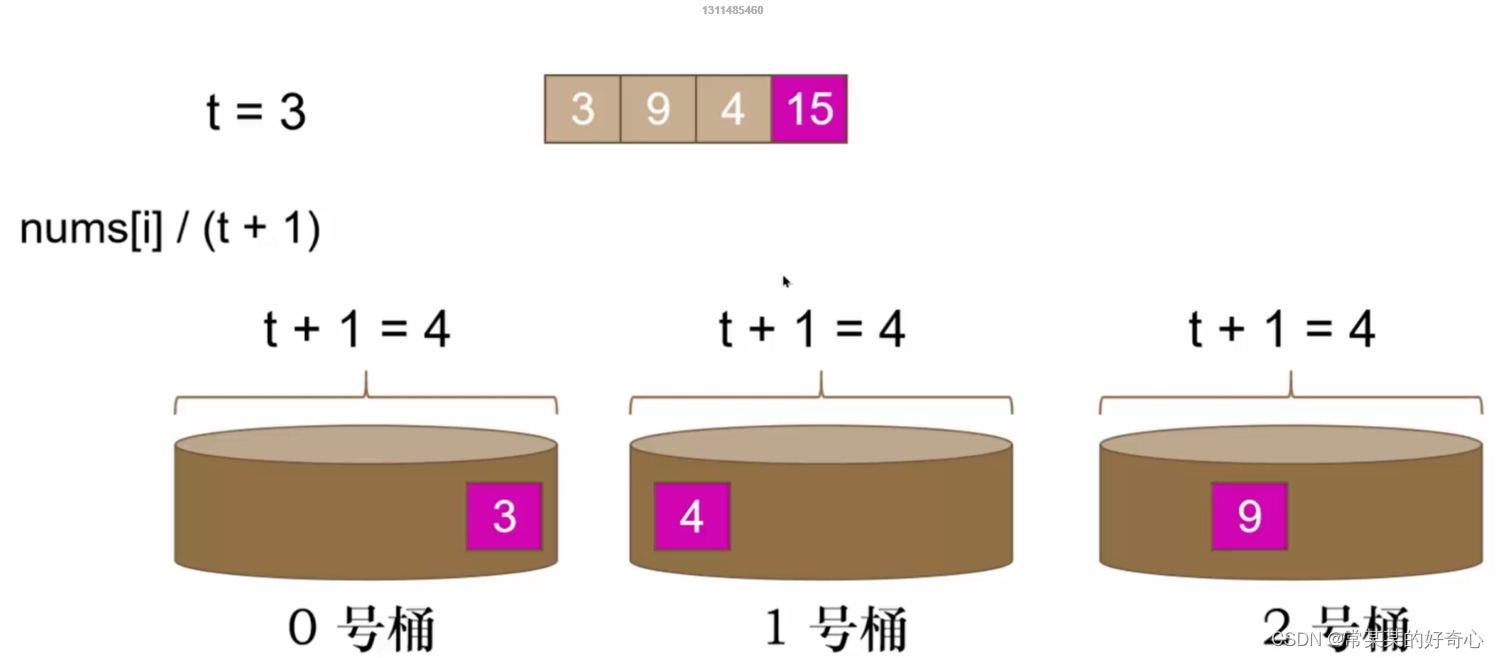
注意:负数/0的情况
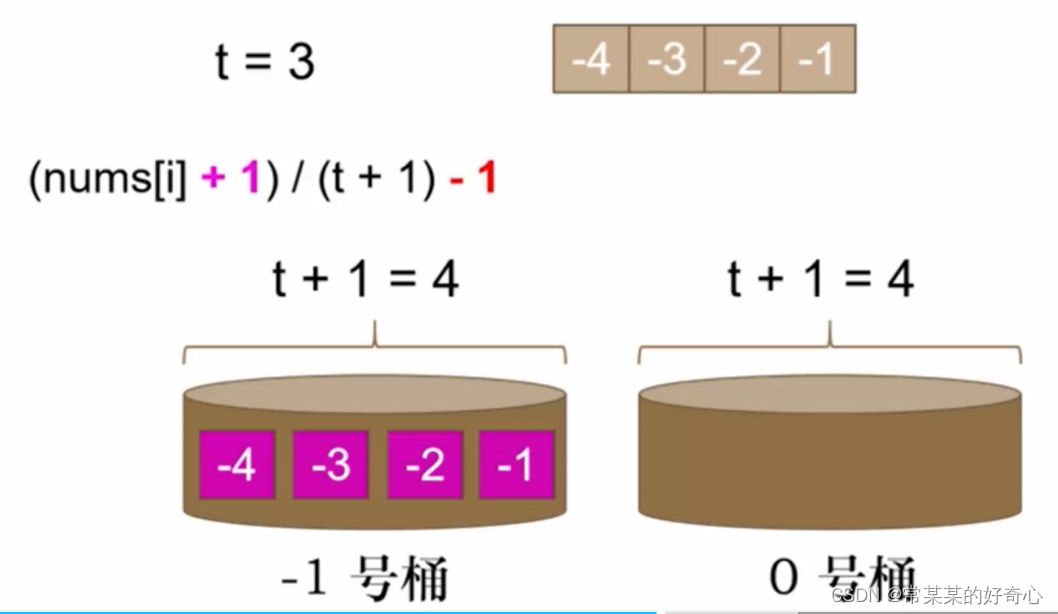
#方案一:滑动窗(位置差)+桶(数值差)
#时:o(n),o(min(n,k))
class Solution:
def containsNearbyAlmostDuplicate(self, nums: List[int], indexDiff: int, valueDiff: int) -> bool:
left=right=0
#key1:保证值区间
bucketsize=valueDiff+1
window_bucket={}
while right<len(nums):
bucketid=self.getbucketid(nums[right],bucketsize)
#考虑单桶/相邻桶情况
if bucketid in window_bucket:return True
if bucketid+1 in window_bucket and window_bucket[bucketid+1]-nums[right]<=valueDiff:
return True
if bucketid-1 in window_bucket and nums[right]-window_bucket[bucketid-1]<=valueDiff:
return True
#
window_bucket[bucketid]=nums[right]
#key2:保证窗口个数区间(桶的个数=min(k,n))
if len(window_bucket)>indexDiff:
del window_bucket[self.getbucketid(nums[left],bucketsize)]
left+=1
#key3:更新窗口
right+=1
return False
def getbucketid(self,x,bucketsize):
if x>:return x//bucketsize
return ((x+1)//bucketsize)-1
lc 258 :各位相加
https://leetcode.cn/problems/add-digits/
提示:
0 <= num <= 2^31 - 1
class Solution:
def addDigits(self, num: int) -> int:
while num>=10:
num=self.sumdig(num)
return num
def sumdig(self,num):
total=0
while num!=0:
total+=num%10
num//=10 #注意:不是/
return total
lc 202 :快乐数
https://leetcode.cn/problems/happy-number/
提示:
1 <= n <= 2^31 - 1
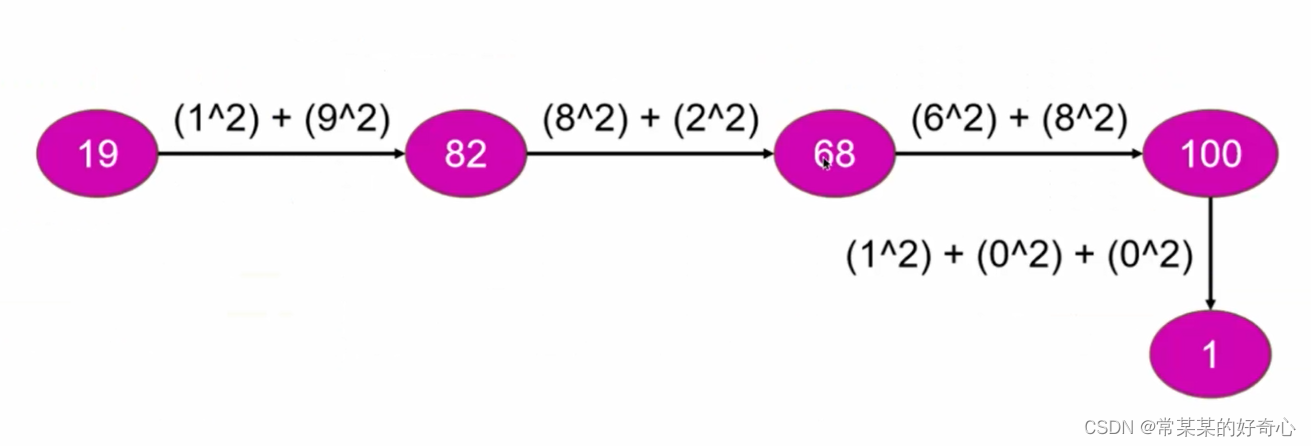
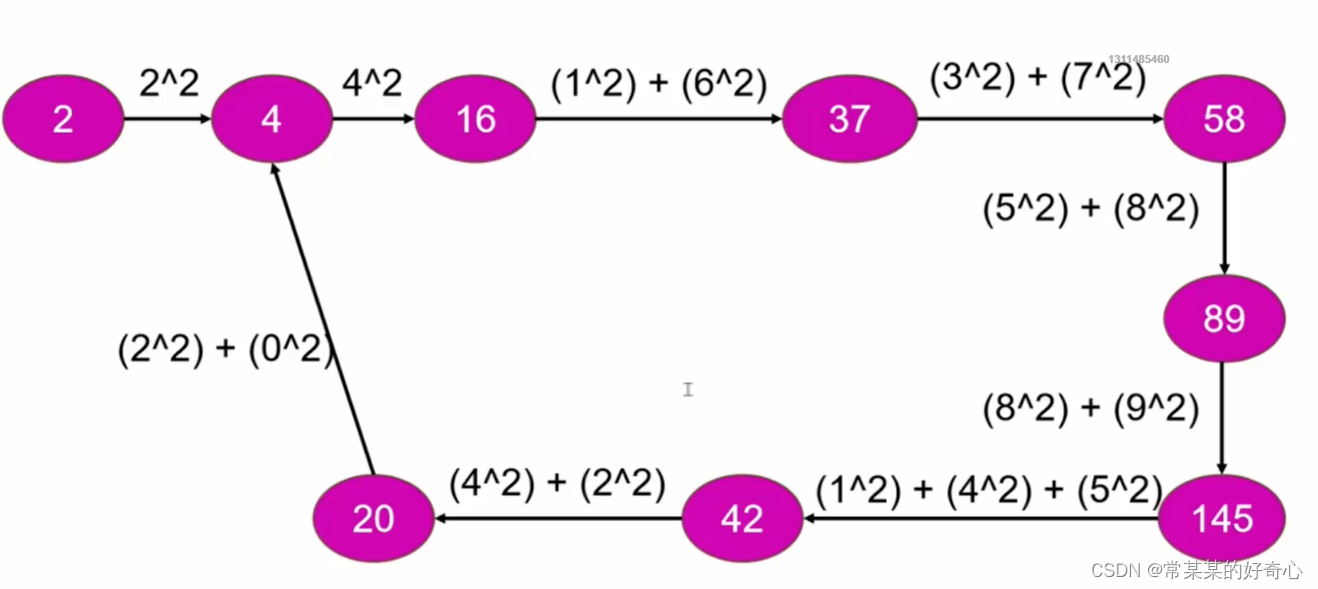
#抽象为“单向链表"是否有环问题
#方案一:哈希
class Solution:
def isHappy(self, n: int) -> bool:
visited=set()
while True:
if n==1:return True
if n in visited:return False
#
visited.add(n)
n=self.squaresum(n)
def squaresum(self,num):
s=0
while num!=0:
s+=(num%10)**2
num//=10
return s
#方案二:快慢指针
class Solution:
def isHappy(self, n: int) -> bool:
if n==1:return True
#
slow=fast=n
while True:
slow=self.squaresum(slow)
fast=self.squaresum(self.squaresum(fast))
if fast==1:return True #slow==1 or
if slow==fast:return False
def squaresum(self,num):
s=0
while num!=0:
s+=(num%10)**2
num//=10
return s
lc 263 :丑数
https://leetcode.cn/problems/ugly-number/
提示:
-2^31 <= n <= 2^31 - 1
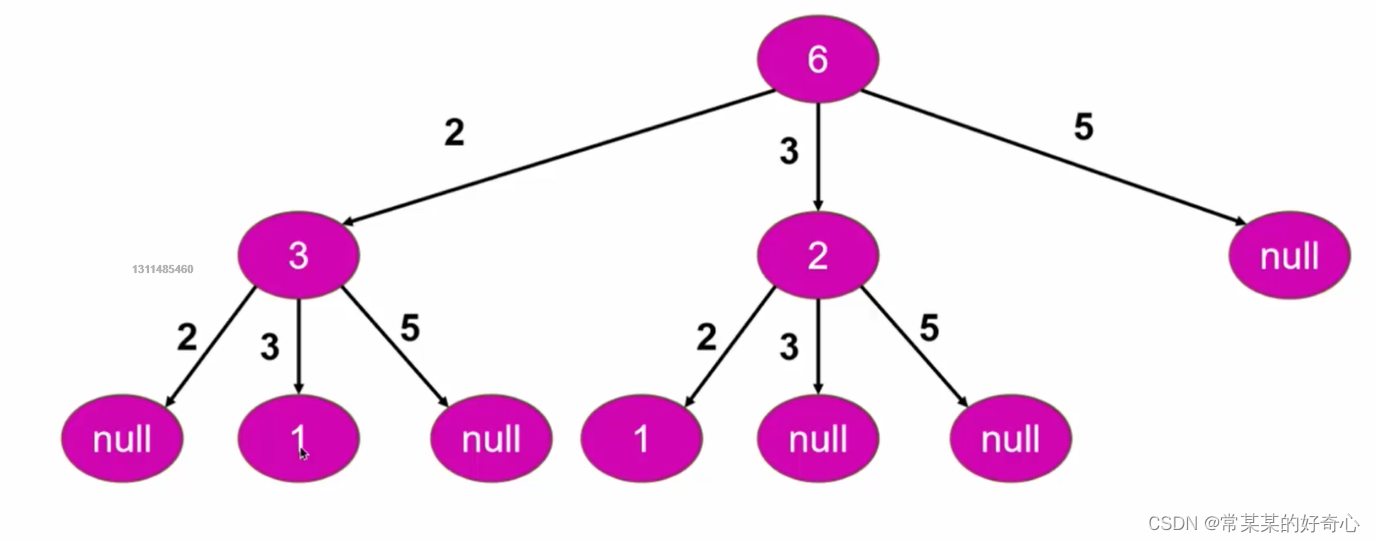
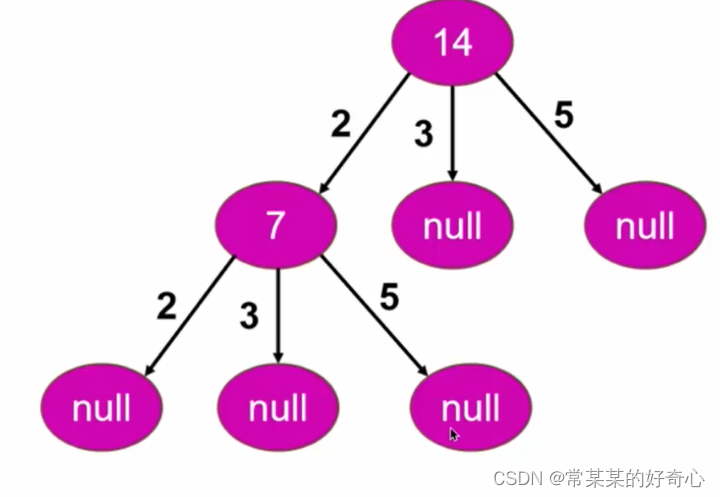
#问题抽象为”树形结构“
#方案一:DFS
class Solution:
def isUgly(self, n: int) -> bool:
if n==0: return False #死循环
return self.dfs(n)
def dfs(self,n):
if n==1:return True
factors=[2,3,5]
for fac in factors:
if n%fac==0 and self.dfs(n/fac): #key:能判断出-能被整除,则对n/fac一直整除下去
return True
return False
#方案二:迭代
class Solution:
def isUgly(self, n: int) -> bool:
if n==0:return False
factors=[2,3,5]
for fac in factors:
while n%fac==0:
n/=fac
return n==1
字典树 - 前缀树 - Tire

#Node:表达节点-表达单词结尾
#功能:添加单词-查询指定单词(哈希表)
class Node:
def __init__(self):
self.children={} #c->Node(c)
self.isend=False #标记每个单词的结尾字符
class trie:
def __init__(self):
self.root=Node()
def add(self,word):
curr=self.root
for c in word:
#key
if c not in curr.children:
curr.children[c]=Node()
curr=curr.children[c]
#
curr.isend=True
def contain(self,word):
curr=self.root
for c in word:
if c not in curr.children:
return False
curr=curr.children[c]
#
return curr.isend
lc 208 【剑指 062】:实现 Trie (前缀树)【top100】
https://leetcode.cn/problems/implement-trie-prefix-tree/
提示:
1 <= word.length, prefix.length <= 2000
word 和 prefix 仅由小写英文字母组成
insert、search 和 startsWith 调用次数 总计 不超过 3 * 10^4 次
#方案一:map
class Node:
def __init__(self):
self.children={}
self.isend=False
class Trie:
def __init__(self):
self.root=Node()
def insert(self, word: str) -> None:
curr=self.root
for c in word:
if c not in curr.children:
curr.children[c]=Node()
curr=curr.children[c]
curr.isend=True
def search(self, word: str) -> bool:
curr=self.root
for c in word:
if c not in curr.children:
return False
curr=curr.children[c]
return curr.isend
def startsWith(self, prefix: str) -> bool:
curr=self.root
for c in prefix:
if c not in curr.children:
return False
curr=curr.children[c]
return True #说明找到最后一个字符时,也未返回False
# Your Trie object will be instantiated and called as such:
# obj = Trie()
# obj.insert(word)
# param_2 = obj.search(word)
# param_3 = obj.startsWith(prefix)
#方案二:数组
class Node:
def __init__(self):
self.children=[None]*26
self.isend=False
class Trie:
def __init__(self):
self.root=Node()
def insert(self, word: str) -> None:
curr=self.root
for c in word:
if curr.children[ord(c)-ord('a')]==None:
curr.children[ord(c)-ord('a')]=Node()
curr=curr.children[ord(c)-ord('a')]
curr.isend=True
def search(self, word: str) -> bool:
curr=self.root
for c in word:
if curr.children[ord(c)-ord('a')]==None:
return False
curr=curr.children[ord(c)-ord('a')]
return curr.isend
def startsWith(self, prefix: str) -> bool:
curr=self.root
for c in prefix:
if curr.children[ord(c)-ord('a')]==None:
return False
curr=curr.children[ord(c)-ord('a')]
return True #说明找到最后一个字符时,也未返回False
# Your Trie object will be instantiated and called as such:
# obj = Trie()
# obj.insert(word)
# param_2 = obj.search(word)
# param_3 = obj.startsWith(prefix)
lc 642 :搜索自动补全系统
https://leetcode.cn/problems/design-search-autocomplete-system/
提示:
n == sentences.length
n == times.length
1 <= n <= 100
1 <= sentences[i].length <= 100
1 <= times[i] <= 50
c 是小写英文字母, ‘#’, 或空格 ’ ’
每个被测试的句子将是一个以字符 ‘#’ 结尾的字符 c 序列。
每个被测试的句子的长度范围为 [1,200]
每个输入句子中的单词用单个空格隔开。
input 最多被调用 5000 次


#①
class trieNode: #for build 前缀树
def __init__(self):
self.children={}
self.end_times=0
#②
class sentenceInfo: #for matchsentences.sort
def __init__(self,content,time):
self.content=content
self.time=time
#③key:如果有多条热度相同的句子,请按照 ASCII 码的顺序输出(ASCII 码越小排名越前)
class compareKey(sentenceInfo):
def __lt__(x,y):
return x.content<y.content if x.time == y.time else x.time>y.time
###########################
class AutocompleteSystem:
def __init__(self, sentences: List[str], times: List[int]):
#
self.root=trieNode()
for i in range(len(sentences)):
self.insert(sentences[i],times[i])#字典树:字符串+热度
#记录当前输入
self.currentinput=""
def input(self, c: str) -> List[str]:
res=[]
if c=="#":
self.insert(self.currentinput, 1)#完整句子情况
self.currentinput=""
else:
self.currentinput+=c #莫忘
matchsentences=self.searchmatchs(self.currentinput)#找匹配
matchsentences.sort(key=lambda x:(-x.time,x.content))#排个序 #???-x.time
for i in range(min(3,len(matchsentences))):#存前三
res.append(matchsentences[i].content)
return res
##########################################
#构建前缀树
def insert(self,s,time):
curr=self.root
for c in s:
if c not in curr.children:
curr.children[c]=trieNode()
curr=curr.children[c]
#key:热度可叠加
curr.end_times+=time
#搜索以s开头的所有句子
def searchmatchs(self,s):
matchs=[] #注意位置
##curr->指向前缀末端(比如do的o)
curr=self.root
for c in s:
if c not in curr.children:
curr.children[c]=trieNode()
curr=curr.children[c]
##dfs->每个matchsentence(dog,door,does···)
def dfs(curr,s):
#
if curr.end_times>0:
matchs.append(sentenceInfo(s, curr.end_times))
#
for c,node in curr.children.items():#key:.items() #[c,node]也行
dfs(node,s+c)
dfs(curr, s)
return matchs
# Your AutocompleteSystem object will be instantiated and called as such:
# obj = AutocompleteSystem(sentences, times)
# param_1 = obj.input(c)
lc 421【剑指 067】 :数组中两个数的最大异或值
https://leetcode.cn/problems/maximum-xor-of-two-numbers-in-an-array/
提示:
1 <= nums.length <= 2 * 10^5
0 <= nums[i] <= 2^31 - 1
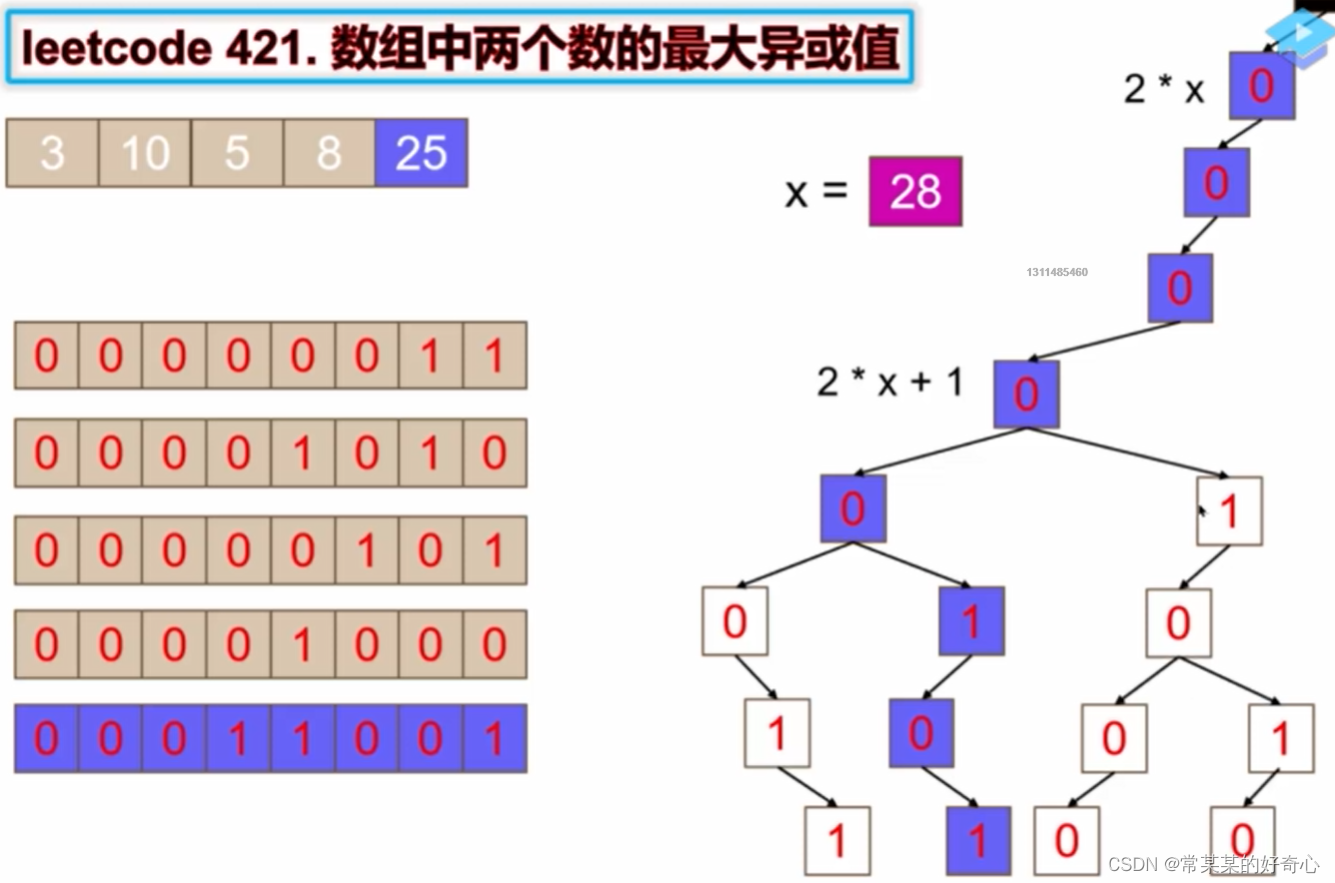

#二进制前缀树
class Node:
def __init__(self):
self.zero=None
self.one=None
#o(30)->o(1)
class Trie:
def __init__(self):
self.root=Node()
#不断添加,构造前缀树
def add(self,num):
curr=self.root
#从左往右取二进制位
for k in range(30,-1,-1):
bit=(num>>k)&1
if bit==0:
if not curr.zero:
curr.zero=Node()
curr=curr.zero
else:
if not curr.one:
curr.one=Node()
curr=curr.one
#不断在树中,查询最大异或值
def maxXor(self,num):
#
x=0
curr=self.root
for k in range(30,-1,-1):
bit=(num>>k)&1
#key
if bit==0:
if curr.one!=None:
curr=curr.one
x=2*x +1
else:
curr=curr.zero
x=2*x
else:
if curr.zero!=None:
curr=curr.zero
x=2*x +1
else:
curr=curr.one
x=2*x
return x
#O(n),o(n)
class Solution:
def findMaximumXOR(self, nums: List[int]) -> int:
#
res=0
trie=Trie()
#
for i in range(1,len(nums)):
trie.add(nums[i-1])
res=max(res,trie.maxXor(nums[i]))
return res
lc 440 :字典序的第K小数字
https://leetcode.cn/problems/k-th-smallest-in-lexicographical-order/
提示:
1 <= k <= n <= 10^9
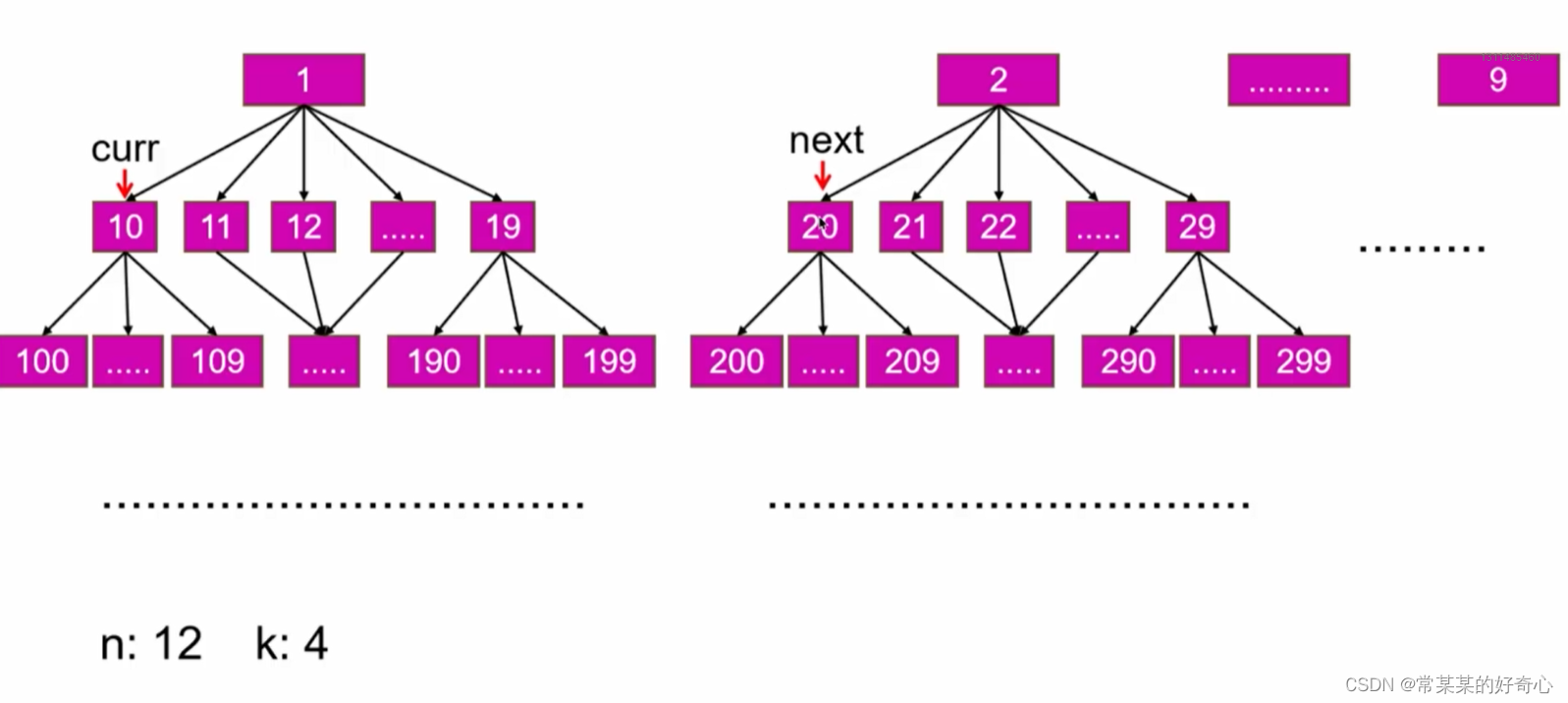
#抽象为十叉树
class Solution:
def findKthNumber(self, n: int, k: int) -> int:
curr=1
k-=1 #key?
#
while k>0:
nums=self.calnodes(n,curr,curr+1)
if nums-1 <k: #不在当前curr前缀树
curr +=1 #去‘下一树’
k -=nums
else:#在当前curr前缀树
#去‘下一层’
curr *=10
k-=1
return curr
#计算当前curr“前缀树”中(小于n)的总节点数
def calnodes(self,n,curr,next):
nums=0
while curr<=n:
nums+=min(n+1,next)-curr
#去“下一层”
curr *=10
next *=10
return nums