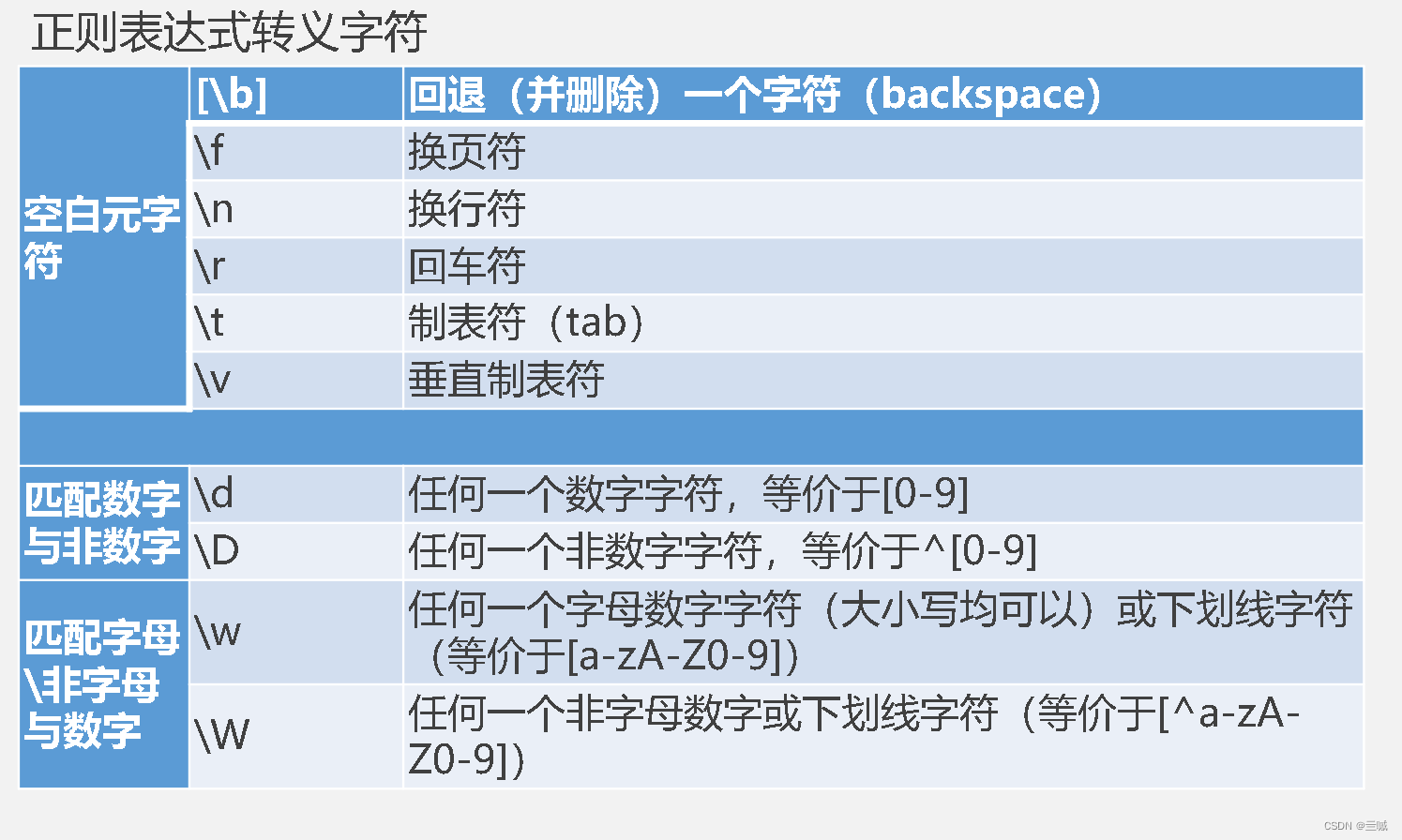
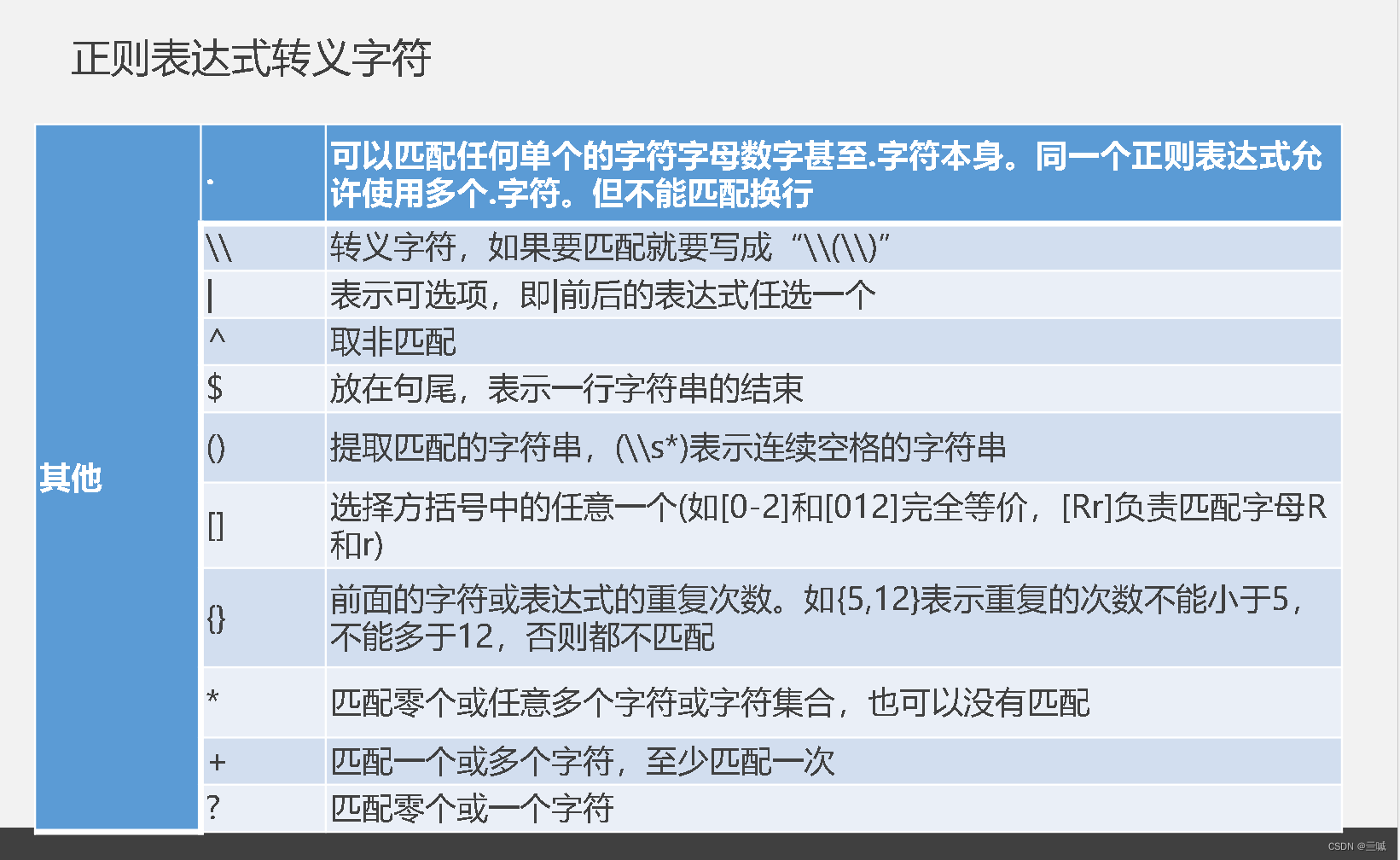
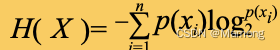什么狗吧发明的结业考,站出来和我对线
第一章 绪论
吊码没有,就算考R语言特点我也不背,问就是叫么这没用。
第二章 R语言入门
x<-1:20 赋值语句 x 1到20
在x上添加均值为0、标准差为2的正态分布噪声
y <- x + rnorm (20, 0, 2)
这段代码就是生成随机数
20:生成20个数
0: 均值
2: 标准差
记住就完了
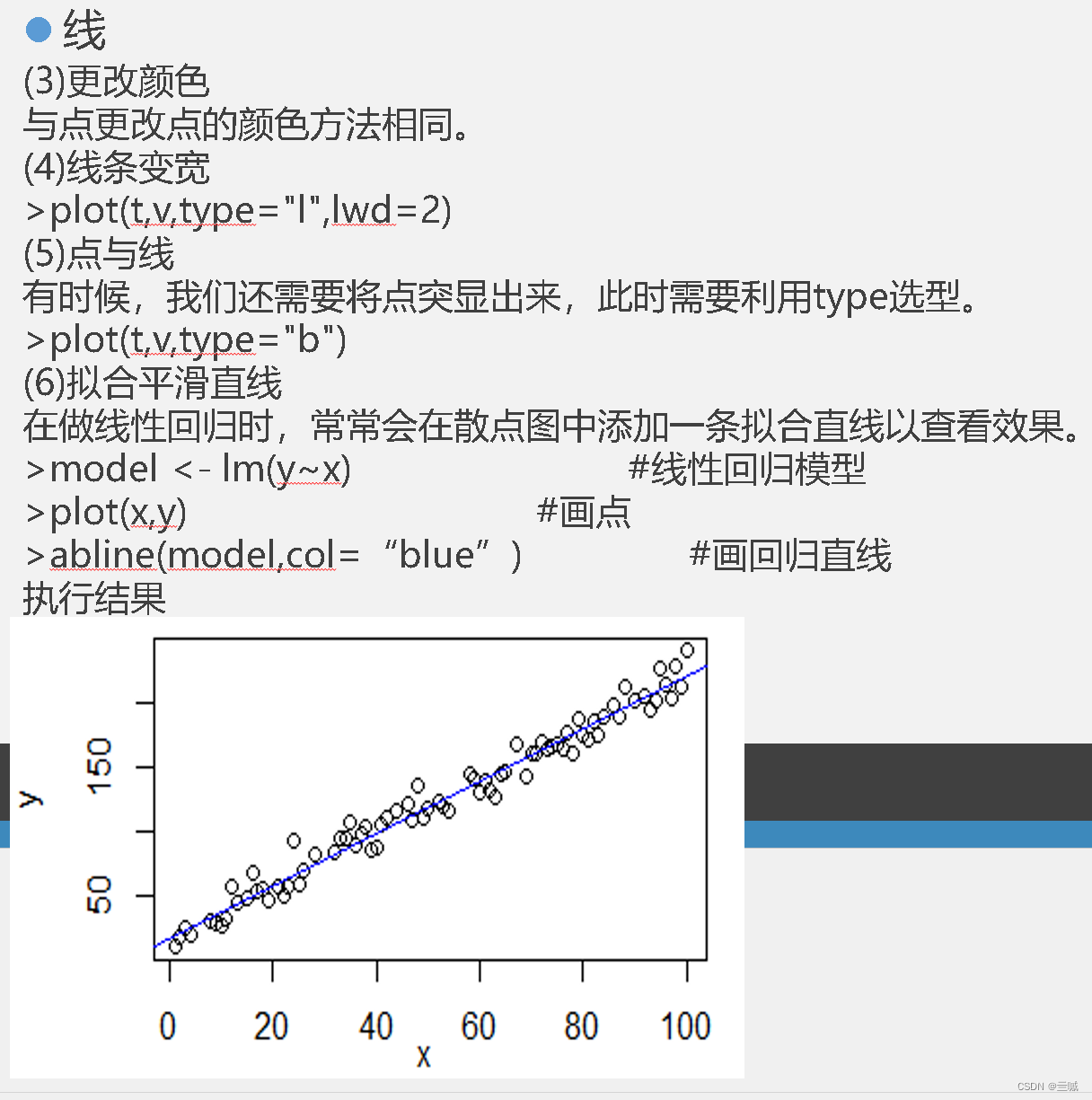
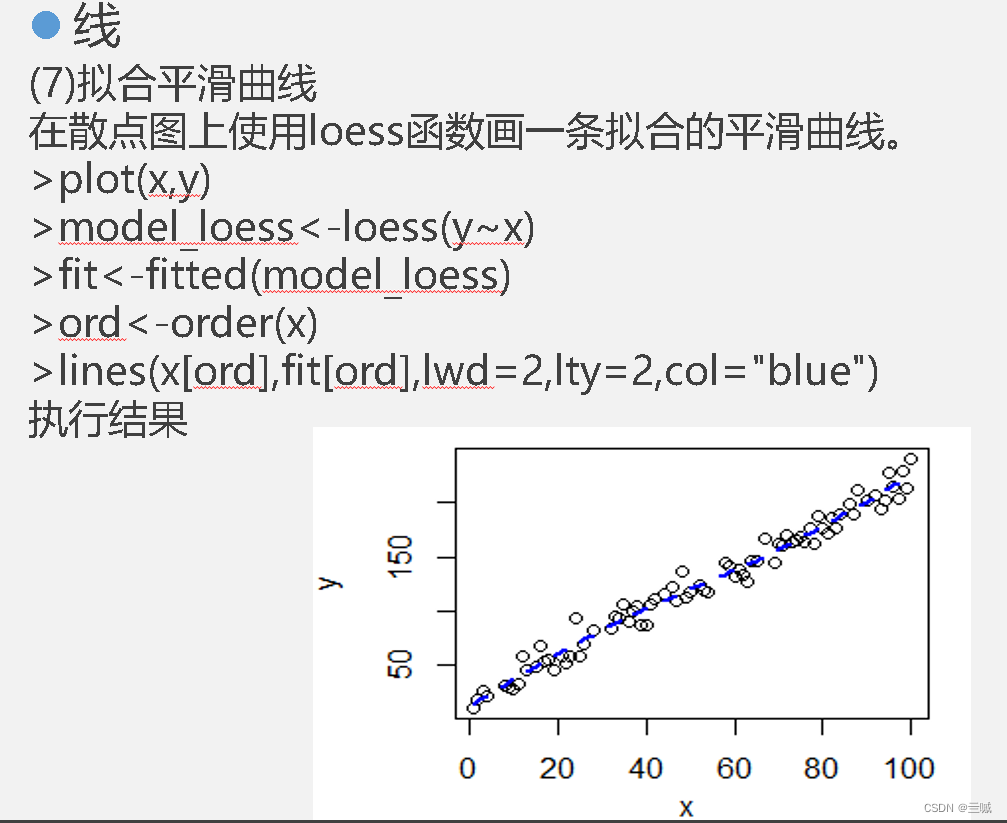
fit <- lm (y ~ x) y~x的线性回归
summary (fit) 概要显示fit
age<-c(1,3,5,2,11,9,3,9,12,3) 还是赋值,官方叫产生向量,我的评价是别忘写c
mean(weight) 求weight的平均值
sd(weight) 求weight的标准差
cor(age,weight) 求age和weight之间的相关系数
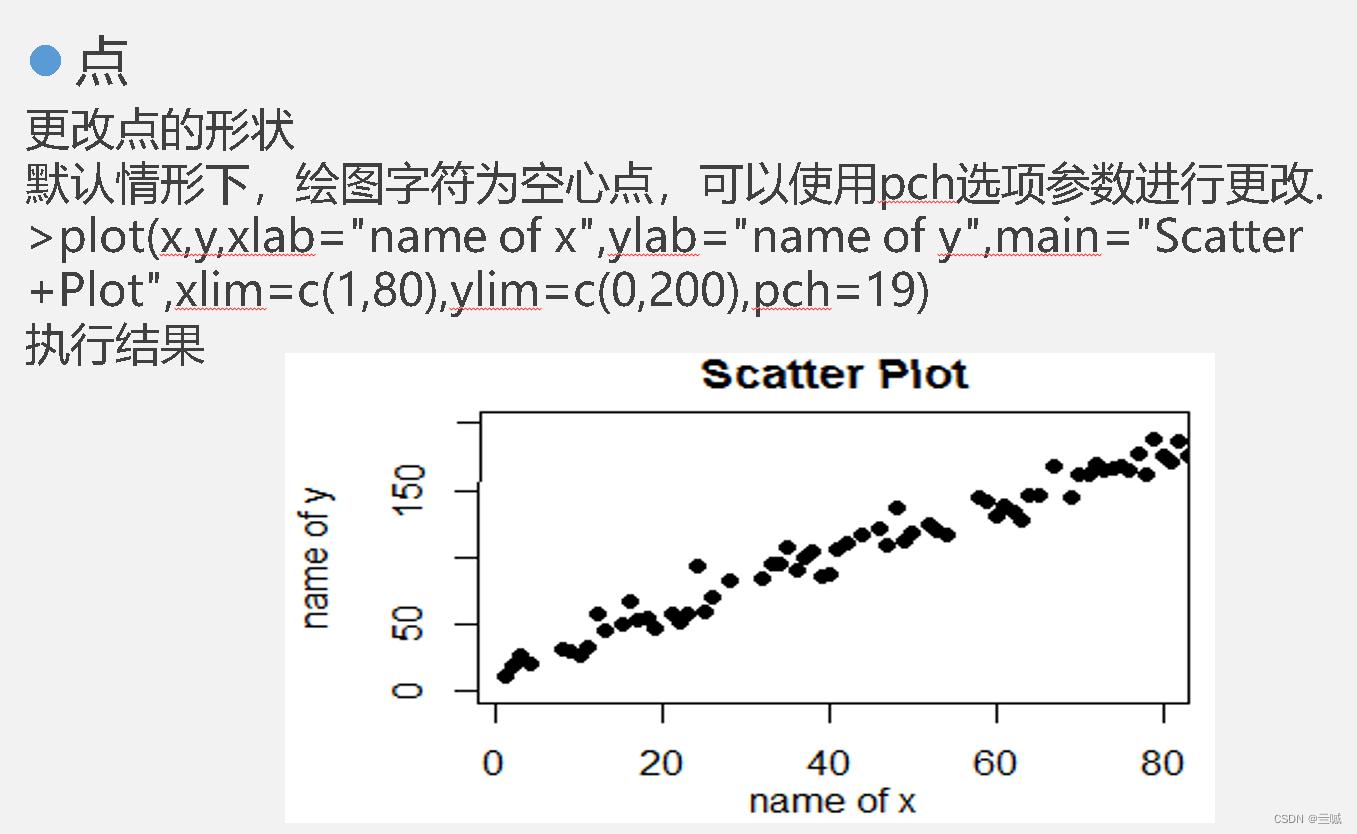
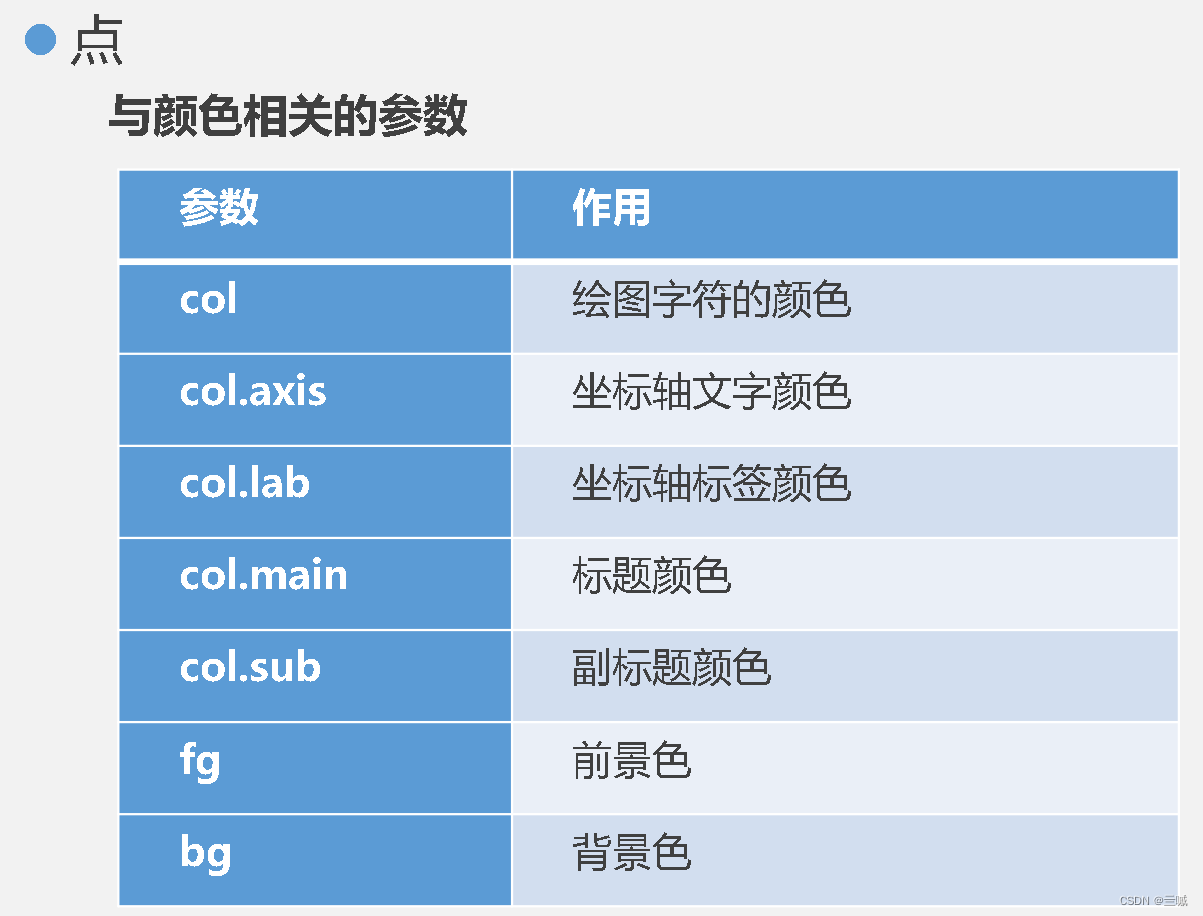
plot(age,weight) 绘制以age为横坐标和以weight为纵坐标的散点图
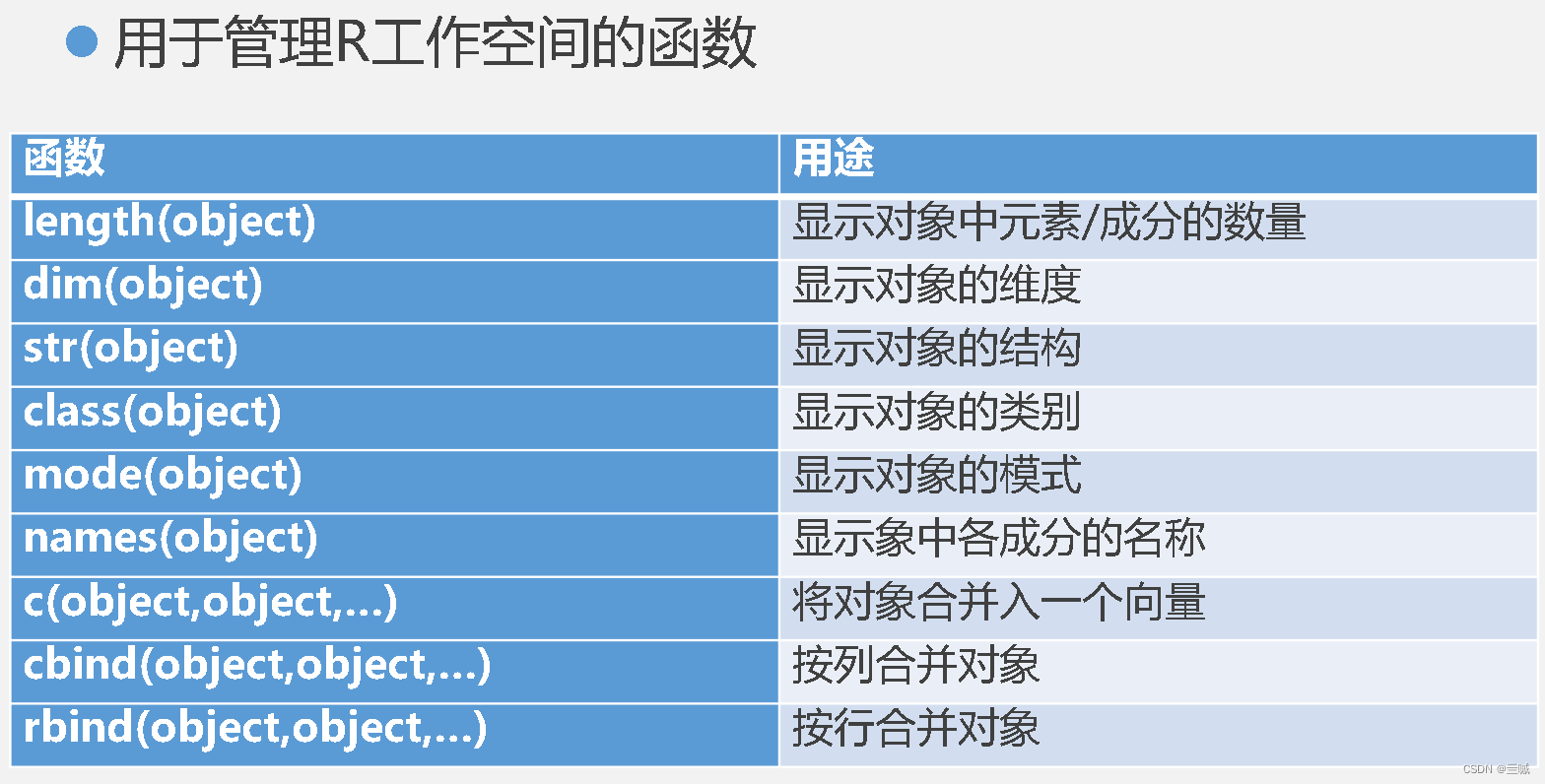
getwd() 显示当前的工作目录
setwd("mydirectory")修改当前的工作目录为mydirectory
ls() 列出当前工作空间中的对象
rm(objectlist) 移除(删除)一个或多个对象
q() 退出R
source("test") 可在当前会话中执行一个脚本
sink("filename") 将输出重定向到文件filename中。默认情况下,如果文件已经存在,则它的内容将被覆盖
install.packages("gclus")安装R包
library(gclus) 加载到内存
.libpath() 显示包所在位置
习题
输入命令help.start()在浏览器中显示帮助文档,并学会使用帮助文档。
函数source("test")可在当前会话中执行一个脚本。
函数sink("myfile") 将输出重定向到文件myfile中。
R是开源的
安装datasets包:install.packages("datasets")
加载datasets包到内存:library(datasets)
显示datasets包所在位置:system.file(package = "datasets") / find.package("datasets")
显示已加载的包:search()
列出当前已加载包中所含的所有可用示例数据集:data()
显示当前工作目录,并修改当前的工作目录为myworkspace:getwd() + setwd("myworkspace")
查看函数foo的帮助,并运行函数foo的使用示例:?foo
列出3种有关用于保存图形输出的函数:
1
png("plot.png") # 保存为plot.png文件
plot(x, y) # 绘制图形
dev.off() # 关闭设备
2
pdf("plot.pdf") # 保存为plot.pdf文件
plot(x, y) # 绘制图形
dev.off() # 关闭设备
3
library(ggplot2)
p <- ggplot(data, aes(x, y)) + geom_point() # 创建ggplot2绘图对象 aes(x, y):表示定义了 x 和 y 轴的变量名 geom_point():是一个几何对象函数,用于在散点图中添加点。
ggsave("plot.png", plot = p) # 保存为plot.png文件,p要替换为实际的绘图对象
简要介绍R语言的优点:
免费且开源、强大的数据分析和统计功能、大型生态系统、数据可视化能力、复现性和文档化、平台跨度、教育和学习资源丰富
加载shiny包:library(shiny)
列出包shiny中可用的函数和数据集:
# 列出shiny包中的函数
functions <- ls("package:shiny", pattern = "^[A-Za-z].*")
# 列出shiny包中的数据集
data <- ls("package:shiny", pattern = "^data")
运行01_hello / 运行runExample()查看shiny自带的demo:runExample("01_hello")
退出R:q()
第三章
在R语言中,行不叫行,列不叫列,行叫观测,列叫变量/因子
R中定义了一些常量类型:
NA: 表示不可用
Inf: 无穷
-Inf: 负无穷
TRUE: 真
FALSE:假
seq() 产生一个等差向量序列
格式:seq(from = n, to =m, by = k,len w)
例子:
> seq(2, 10 ) #默认公差为1
[1] 2 3 4 5 6 7 8 9 10
> seq(2, 10 ,2) #如果不指定长度,form,to,by关键词可以省略
[1] 2 4 6 8 10
> seq(from =2, by = 2,len=10) #关键词to和len不能同时使用
[1] 2 4 6 8 10 12 14 16 18 20
rep() 重复一个对象
格式1:rep(x,times):
x是要重复的对象(例如向量c(1,2,3)),times为对象中每个元素重复的次数(如times=c(9,7,3)就是将x向量的1重复9次,2重复7次,3重复3次)。
格式2:rep(x, each=n)
重复x元素n次;rep(c(1,2,3),2)得到1 2 3 1 2 3;rep(c(1,2,3),each=2)得到1 1 2 2 3 3。
rnorm()随机产生正态分布向量
格式:rnorm(个数,均值,方差)
例子:
> x<-rnorm(100) #默认均值为0,方差为1
> x<-rnorm(5,2,3)
说明1:同一向量中无法混杂不同类型的数据。
说明2:f <- 3表示只有一个元素的向量。
> x<-seq(2, 10 )
> x
[1] 2 3 4 5 6 7 8 9 10
> x[3] #下标为正数,取出下标对应的元素
[1] 4
> x[-3] #下标为负数,排除下标对应的元素
[1] 2 3 5 6 7 8 9 10
> x[c(3,5,8)] #如果一次取出多个元素,需要用向量做下标
[1] 4 6 9
> x[-c(3,5,8)]
#如果一次排除多个元素,需要用向量做下标,注意负号
[1] 2 3 5 7 8 10
> x[which(x>6)] #取出满足条件的元素,要使用which()函数
[1] 7 8 9 10
> x[which.max(x)] #取出最大元素,最小元素小标为which.min
[1] 10
> x[3:5] #取出连续的元素
[1] 4 5 6
向量运算
R语言最强大的方面之一就是函数可以直接对向量的每个元素进行操作。
【例】产生两个不等长整数向量x和y,计算√𝑥 ,x+y, xy, xy,及x的长度。
【解】
> y<-2:5 #产生向量x
> x<-seq(2, 10 ) #产生向量y
> sqrt(x) #向量开方
> x+y #向量加,如果两个向量的长度不同,R将重复较短的向量
#元素,直到得到的向量长度与较长的向量的长度相同为止。
[1] 4 6 8 10 8 10 12 14 12
> crossprod(x,x) #內积
> tcrossprod(x,x) #外积
>length(x) #向量长度
矩阵引用
方法1:使用下标和方括号来选择矩阵中的行、列或元素。
y[i,]:返回矩阵y中的第i行;
y[,j]:返回第j列;
y[i,j]:返回第i行第j列元素。
y[i,-j]:返回第i行,但排除第j列元素。
y[-i,j]:返回第j行,但排除第i行元素。
方法2:使用向量和方括号来选择矩阵中的行、列或元素。
y[c(1,3),c(2:4)]:返回第1,3行,第2,4列元素。
y[c(1,3),-c(2:4)]:返回第1,3行,但排除第2,4列元素。
矩阵运算
转置:t(y);
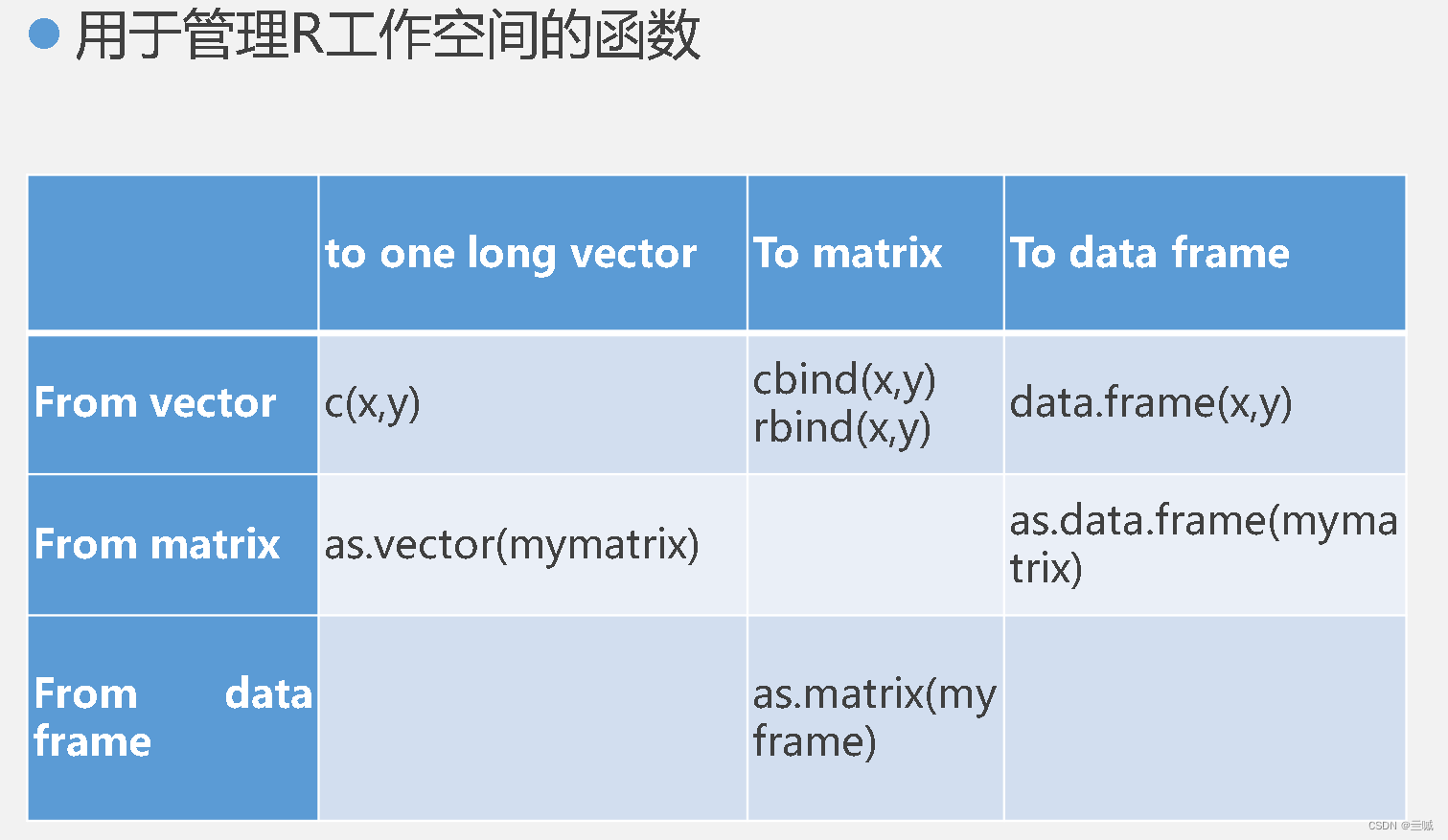
横向合并矩阵:cbind();
纵向合并矩阵:rbind();
将矩阵转化为向量:as.vector();
返回矩阵维度:dim()、nrow() 和ncol();
对矩阵各列求和:colSums();
求矩阵各列的均值:colMeans();
对矩阵各行求和:rowSums();
求矩阵各列的均值:rowMeans();
计算行列式:det();
数组(array)与矩阵类似,但是维度大于2。数组可通过array函数创建,形式如下:
格式:myarray<-array(data,dimentins)
data包含了数组中的数据,
dimensions给出了各个维度下标的最大值。
例子:
z<-array(1:24,c(2,3,4)) #4个两行三列以1到24为数据的矩阵
数组是矩阵的一个自然推广,在编写新的统计方法时,数组可能很有用。像矩阵一样,数组中的数据也只能拥有一种类型。
数组引用与矩阵相同,如,元素z[1,2,3]为15。# 第三个矩阵的一行二列元素
创建数据框
x<-data.frame(col1, col2, col3,……)
其中的列向量col1, col2, col3,… 可为任何类型(如字符型、数值型或逻辑型)。
创建数据框
x<-data.frame(col1, col2, col3,……)
其中的列向量col1, col2, col3,… 可为任何类型(如字符型、数值型或逻辑型)。
例:
mydataset <- data.frame(
Site = c("A", "B", "A", "A", "B"),
Season = c("winter", "summer", "summer", "spring", "fall"),
PH = c(7.3, 6.4, 8.6, 7.2, 8.9)
)
# Site、Season、PH为列名
数据框引用
数据框的引用与矩阵一样,如,x[1:3,],x[2,c(2,4)]。除此之外,增加通过变量引用数据框元素的方法,如把表2-1的数据狂定义为x,则x$age等价于x[,3]。
修改行/名称
可以通过colnames(<数据框>)来读取并编辑列名称。
>colnames(mydataset)[1]<-"a"
>colnames(mydataset)[2]<-"type"
>colnames(mydataset)
可以通过row.names(<数据框>)来读取并编辑行名称
> row.names(mydataset)<-c("r1","r2","r3","r4","r5")
> row.names(mydataset)
[1] "r1" "r2" "r3" "r4" "r5"
> mydataset
a type PH
r1 A winter 7.3
r2 B summer 6.4
r3 A summer 8.6
r4 A spring 7.2
r5 B fall 8.9
创建列表:
mylist<-list(object1, object1,……)
其中的objecti可以是目前为止讲到的任何结构类型。
【例】构造数据框,并重新命名。
> g<-"my first list"
> h<-c(26,26,18,29)
> j<-matrix(1:10,nrow=5)
> k<-data.frame(c(1,2),c(3,4))
> mylist<-list(title=g,ages=h,j,k) #可以为列表中的对象命名
访问列表中的元素。
mylist[[2]]和mylist[["ages"]]均指那个含有四个元素的向量。由于两个原因,列表成为了R中的重要数据结构。首先,列表允许以一种简单的方式组织和重新调用不相干的信息。其次,许多R函数的运行结果都是以列表的形式返回的。需要取出其中哪些成分由分析人员决定。
函数factor()以一个整数向量的形式存储类别值,整数的取值范围是[2... k ](其中k 是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上。
举例来说,假设有向量:
diabetes<-c(“type1”,“type2”, “type1”, “type1”)
语句diabetes <- factor(diabetes)将此向量存储为(1, 2, 1, 1),并在内部将其关联为1=Type1和2=Type2(具体赋值根据字母顺序而定)
要表示有序型变量,需要为函数factor()指定参数ordered=TRUE。给定向量:
status<-c(“Poor”, “Improved”, “Excellent”, “Poor”)
语句status <- factor(status, ordered=TRUE)会将向量编码为(3, 2, 1, 3),并在内部将这些值关联为1=Excellent、2=Improved以及3=Poor。
通过指定levels选项来覆盖默认排序。例如:
status<-factor(status, levels=c(“Poor”,“Improved”, “Excellent”))
各水平的赋值将为1=Poor、2=Improved、3=Excellent。请保证指定的水平与数据中的真实值相匹配,因为任何在数据中出现而未在参数中列举的数据都将被设为缺失值。
求字符串长度: nchar(data)
字符串合并: paste(data,data1,sep=",")
字符串分割: strsplit(string,sep) # sep:分隔符
读取和替换字符串:substr(string,start,stop) # start / stop 都是下标,从1开始
字符串替换 chartr(old,new,string) # old表示需要被替换的字符,new表示替换后的字符,而string则是要进行字符替换的源字符串。
字符串拼接函数
str_c: 字符串拼接。
str_join: 字符串拼接,同str_c。
str_trim: 去掉字符串的空格和TAB(\t)
str_dup: 复制字符串
str_sub: 截取字符串
str_sub<- 截取字符串,并赋值,同str_sub
字符串计算函数
str_count: 字符串计数
str_length: 字符串长度
str_sort: 字符串值排序
str_order: 字符串索引排序,规则同str_sort
字符串匹配函数
str_split: 字符串分割
str_split_fixed: 字符串分割,同str_split
str_match: 从字符串中提取匹配组。
str_match_all: 从字符串中提取匹配组,同str_match
str_replace: 字符串替换
str_replace_all: 字符串替换,同str_replace
str_replace_na: 把NA替换为NA字符串
str_locate: 找到匹配的字符串的位置。
str_locate_all: 找到匹配的字符串的位置,同str_locate
str_extract: 从字符串中提取匹配字符
str_extract_all: 从字符串中提取匹配字符,同str_extract
字符串变换函数
str_to_upper: 字符串转成大写
str_to_lower: 字符串转成小写,规则同str_to_upper
str_to_title: 字符串转成首字母大写,规则同str_to_upper
查找一下看有没有do组合的单词。
>ext<-c("Don't","aim","for","success","if","you","want","it","just","do","what","you","love","and","believe","in","and","it","will","come","naturally")
>#查找含有DO组合的单词
> grep("[Dd]o",text)#不区分大小写
[1] 1 10
> grep("[D]o",text)#D要大写
[1] 1
> grep("[d]o",text)#D小写
[1] 10
习题
status<-c(“Poor”, “Improved”, “Excellent”, “Poor”)
Status是有序型变量。
R中的数据结构包括向量、矩阵、数组、数据框和列表。
R中最常处理的数据结构是数据框(data frame)。
a=matrix(1:12,nrow=4,ncol=3);a[2,2];结果为:6
如果A是5行x6列的矩阵,t(A)是6行x5列的矩阵
a=det(matrix(1:12,nrow=4,ncol=3,byrow=TRUE)) #行优先
b=det(matrix(1:12,nrow=3,ncol=4,byrow=FALSE)) #列优先两者都显示出错信息-行列式的计算要求矩阵必须是方阵
要将矩阵转换为向量,可以使用函数as.vector()
对于字符型向量,默认情况下,因子的水平(levels)是根据字符的出现顺序创建的。
列表(list)是R语言的数据类型中最为复杂的一种。 一般来说,列表就是一些对象的有序集合。
factor()函数为类别型变量创建值标签
要生成100个满足标准正态分布 N(0,1) 的随机数,可以使用 R 中的函数rnorm()
random_numbers <- rnorm(100, mean = 0, sd = 1)
要横向合并矩阵c(2,1),c(4,3):cbind()
cbind(c(2,1), c(4,3))
请使用seq() 产生一个首相为2,公差为2,长度为10的等差向量序列:seq(from=2, by=2, length.out=10)
建立一个R文件,在文件中输入变量x=(1,2,3)T,y=(4,5,6)T,并作以下运算。
①计算 z=2x+y+e,其中 e=(1,1,1)T;
②计算x与y的內积;
③计算x与y的外积;
# 输入变量 x 和 y
x <- t(c(1, 2, 3))
y <- t(c(4, 5, 6))
# 定义向量 e
e <- t(c(1, 1, 1))
# 计算 z = 2x + y + e
z <- 2 * x + y + e
# 计算 x 与 y 的内积
inner_product <- sum(x * y)
# 计算 x 与 y 的外积
outer_product <- crossprod(x, y)
第四章
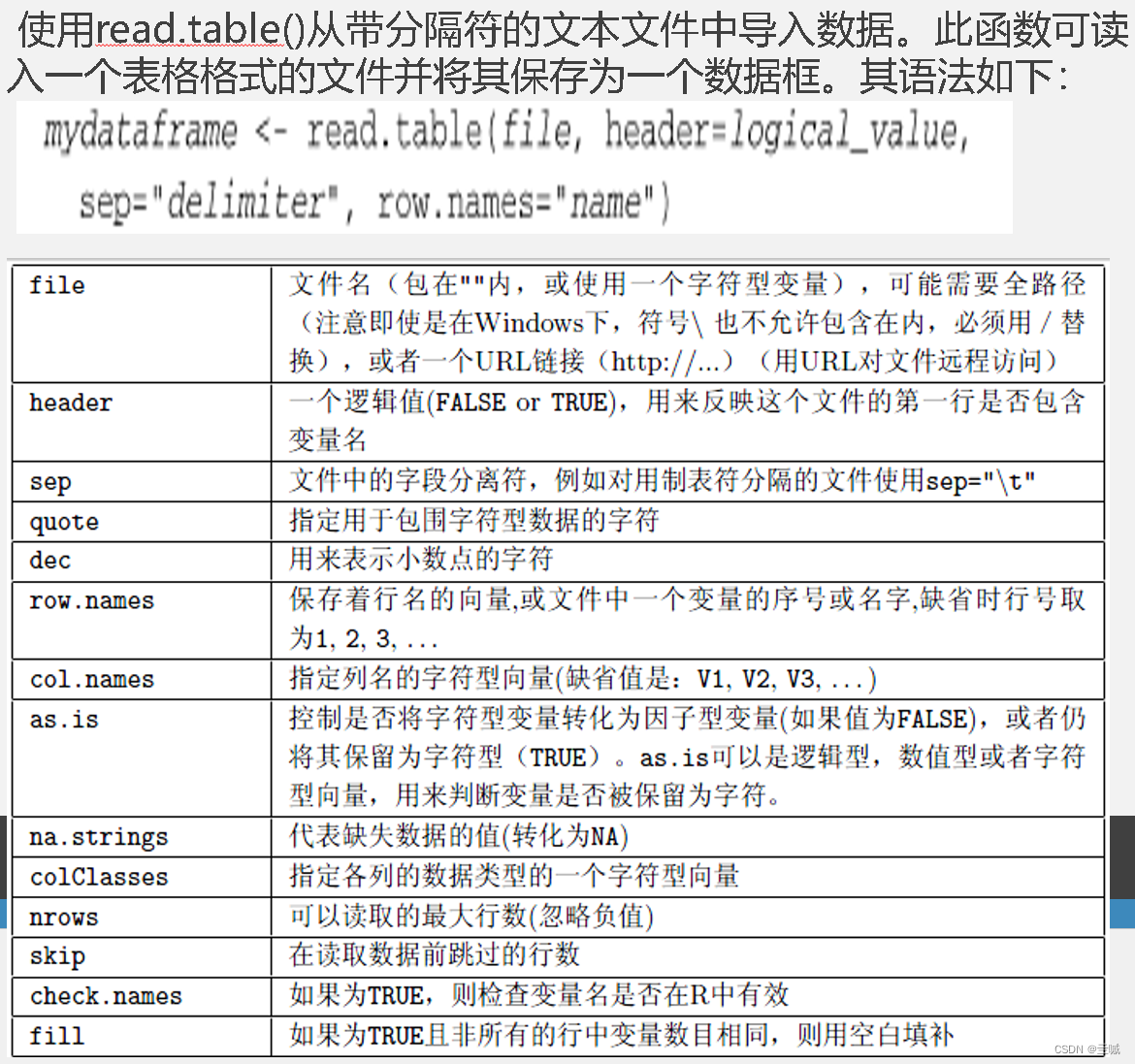
导入Excel数据
>library(xlsx)
>workbook <- "c:/myworkbook.xlsx"
>mydataframe <- read.xlsx(workbook, 1)
导出文本文件
【例】把给定数据框保存为文本文件,以空格分隔数据列,不含行号,不含列名,字符串不带引号。
>age <- c (22,23)
>name <- c ("ken", "john")
>f <- data.frame (age, name)
>write.table (f,file ="f.csv", row.names = FALSE, col.names =FALSE, quote =FALSE)
保存图片
保存为PNG格式:
>png(file="myplot.png", bg="transparent")
保存为JPEG格式:
>jpeg(file="myplot.jpeg")
保存为PDF格式:
>pdf(file="myplot.pdf")
习题
用数据框的形式读入数据:read.csv("data.csv")
读入文本文件abc.txt到数据框,要求包含栏头,使用的R函数是:read.table(“abc.txt”,header=TRUE)
通过函数write.csv()保存表4.4为一个.csv文件,然后通过write.csv()将表格中的数据存到数据框data1中,再将data1中的数据加载到数据框data2中,同时输出data2:
# 保存表4.4为.csv文件
write.csv(table4.4, file = "table4.4.csv", row.names = FALSE)
# 将表格数据存入数据框data1
data1 <- read.csv("table4.4.csv")
# 将data1中的数据加载到数据框data2
data2 <- data1
# 输出data2
print(data2)
write.table()函数参数“header”的功能为:反映这个文件的第一行是否包含变量名
使用于小规模数据集:mydata <- read.table()
第五章







# 计算每行的元素总和
row_sums <- apply(data, 1, sum) # 第二个参数是1,这表示按照行的方向进行操作




ggplot2
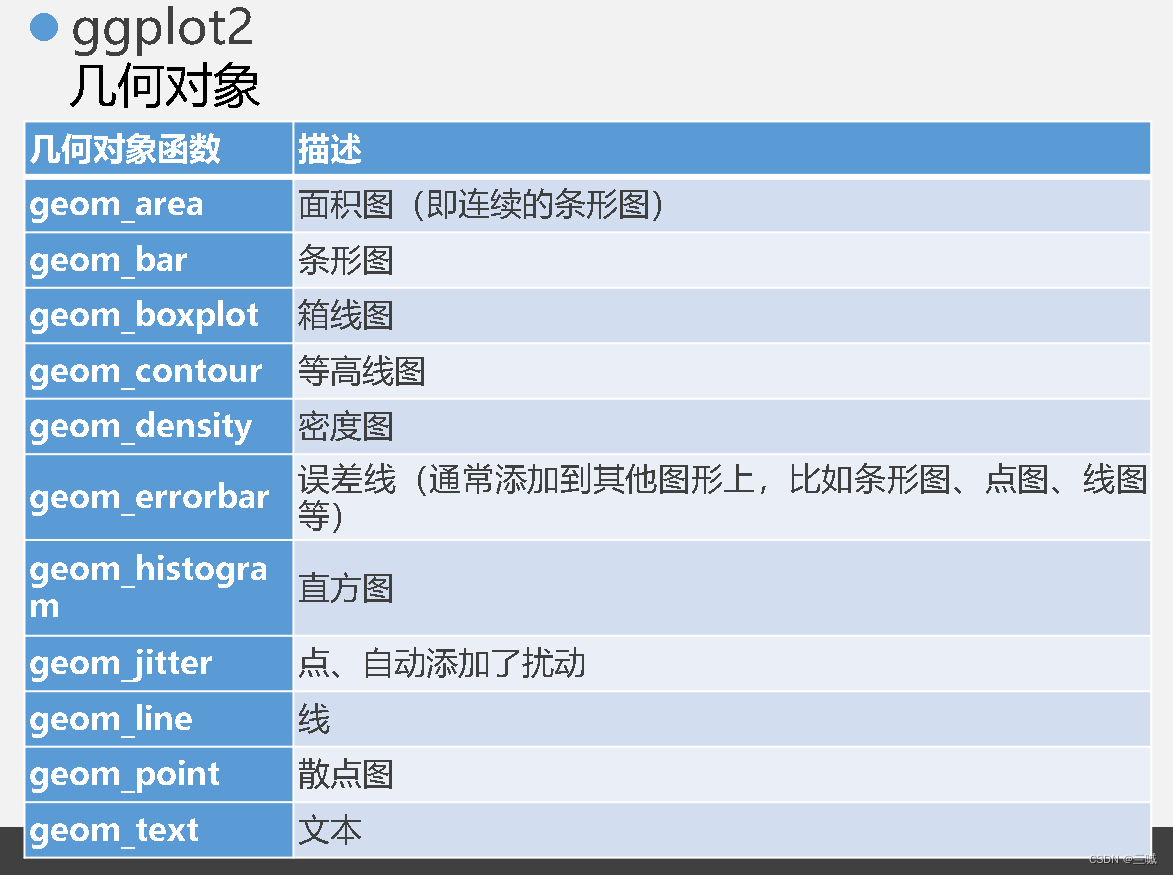
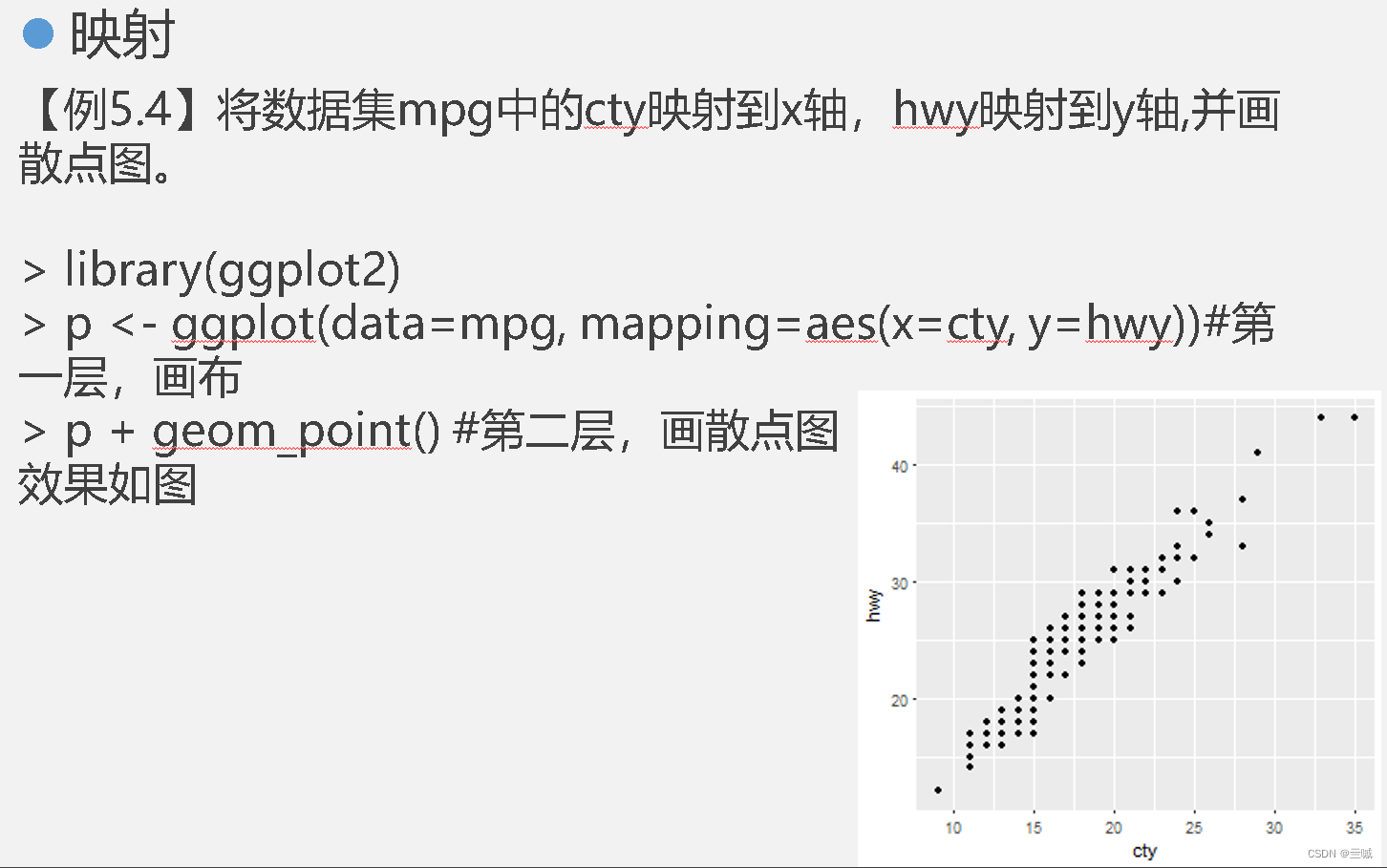
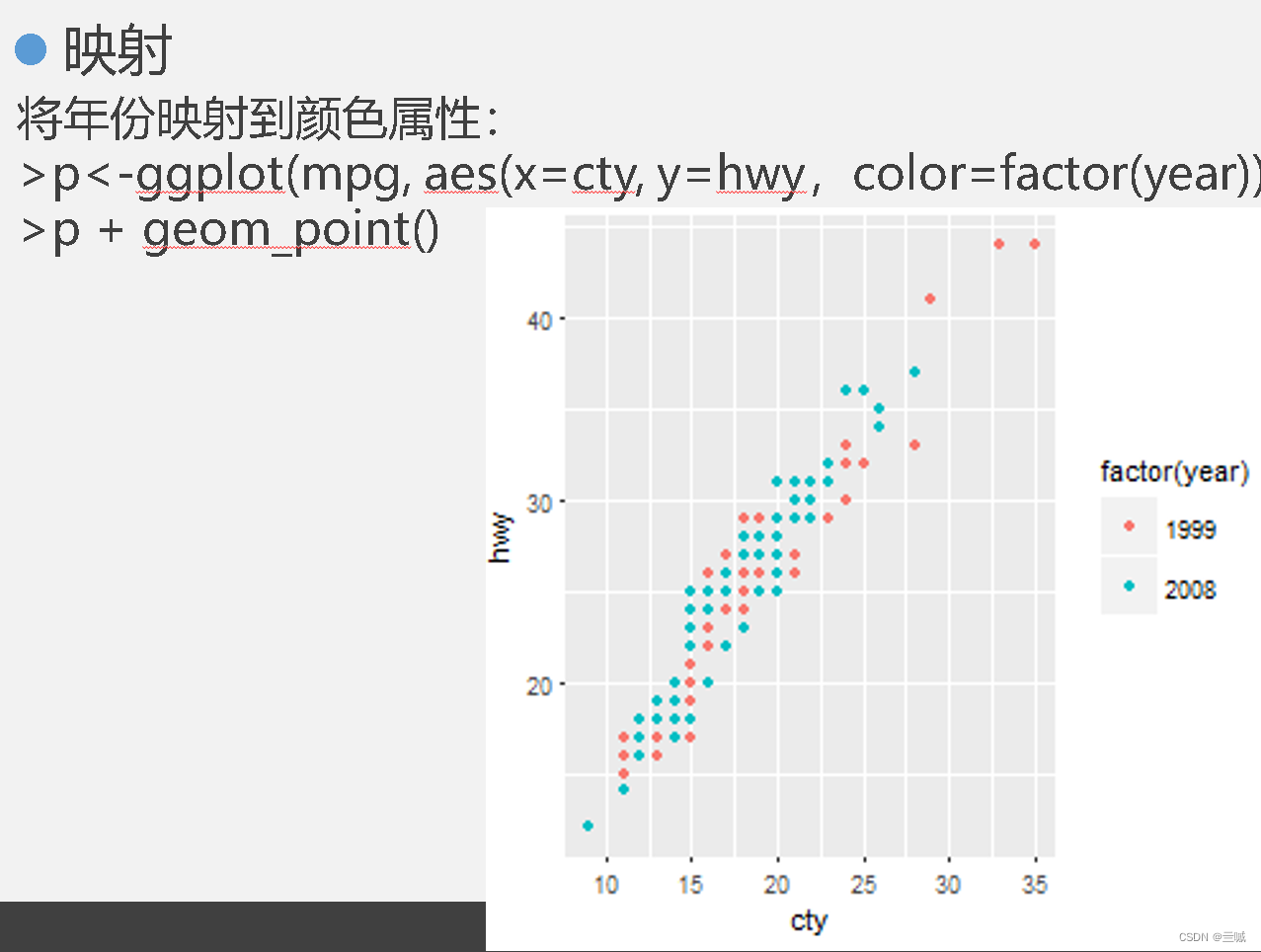

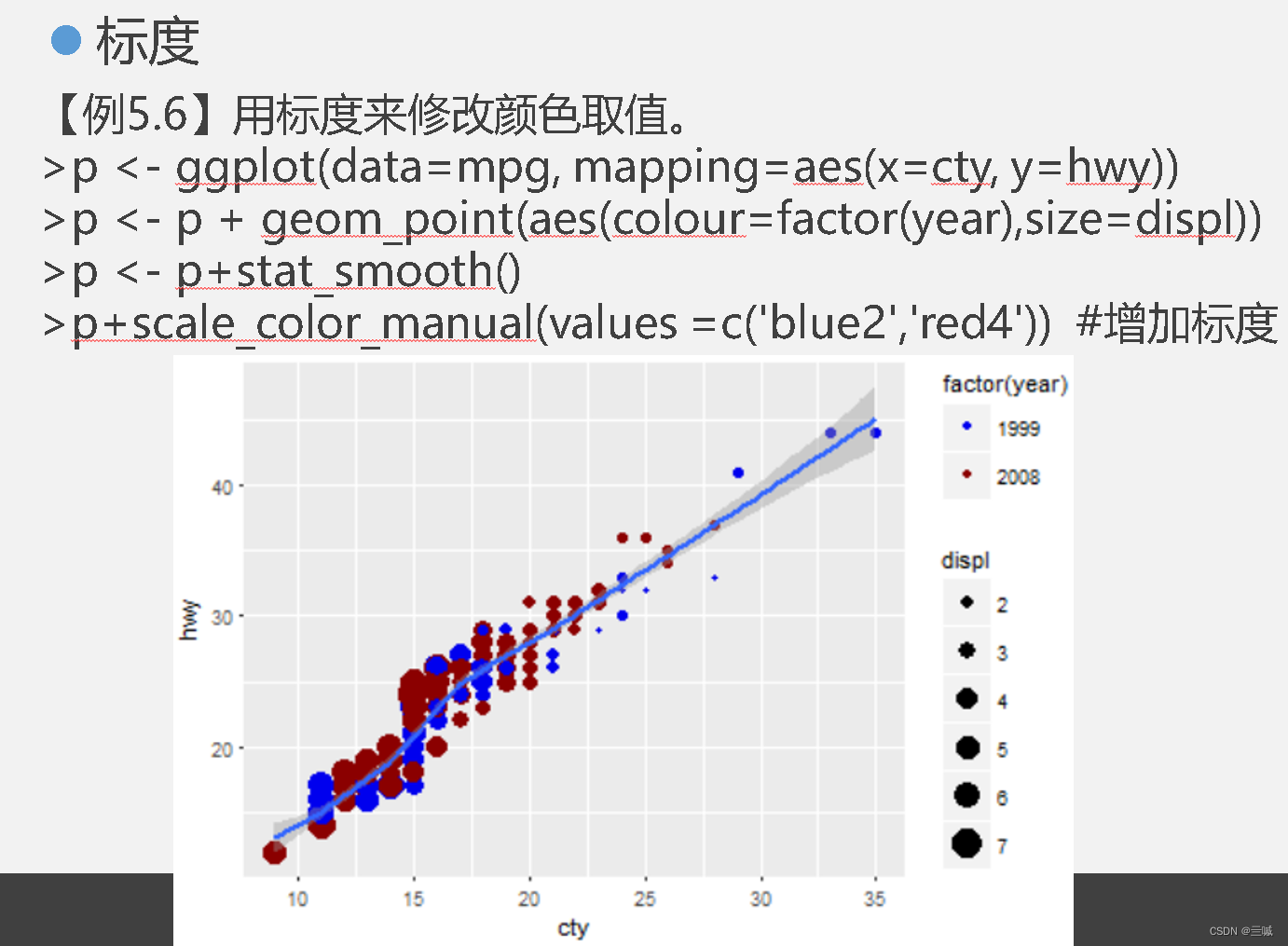
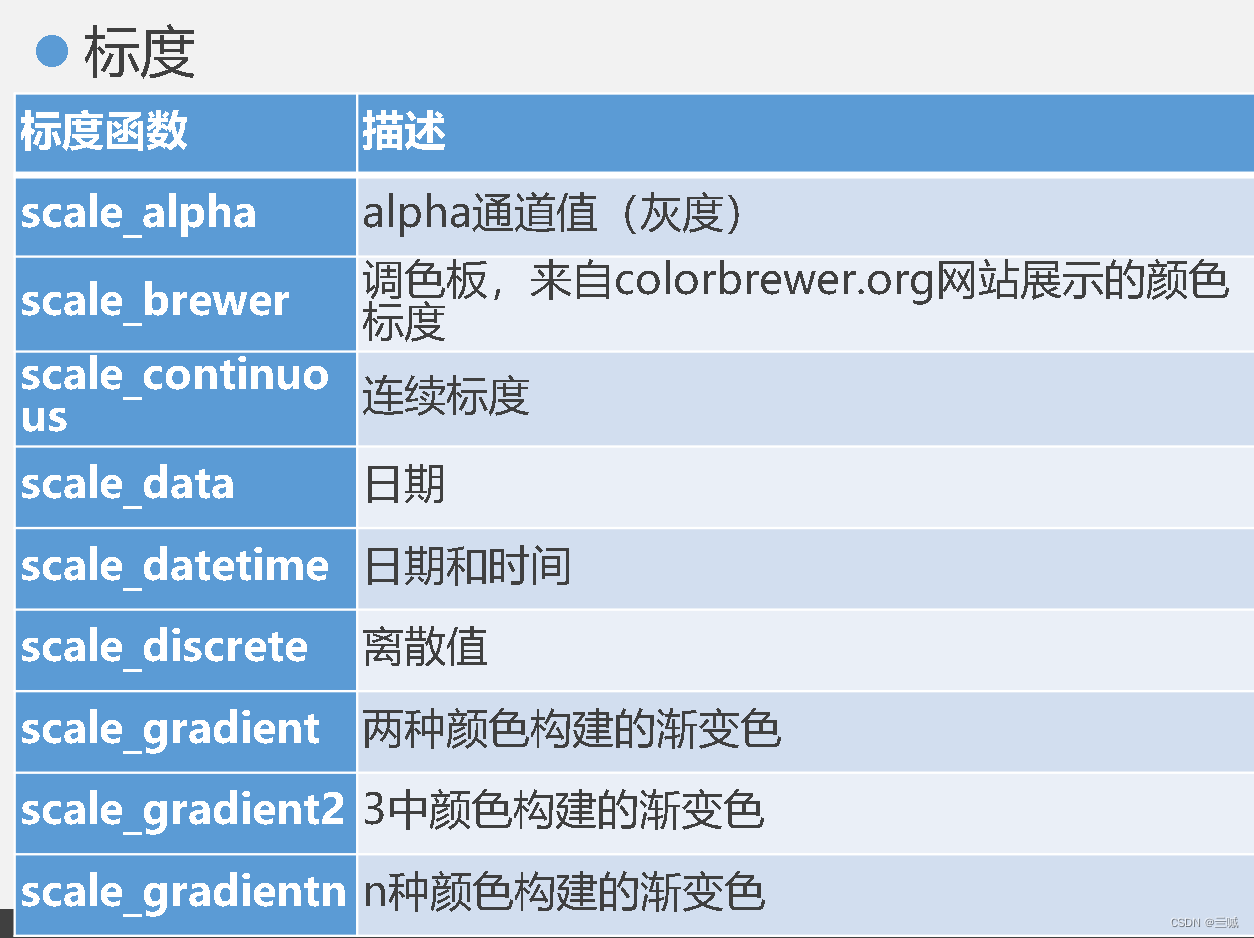
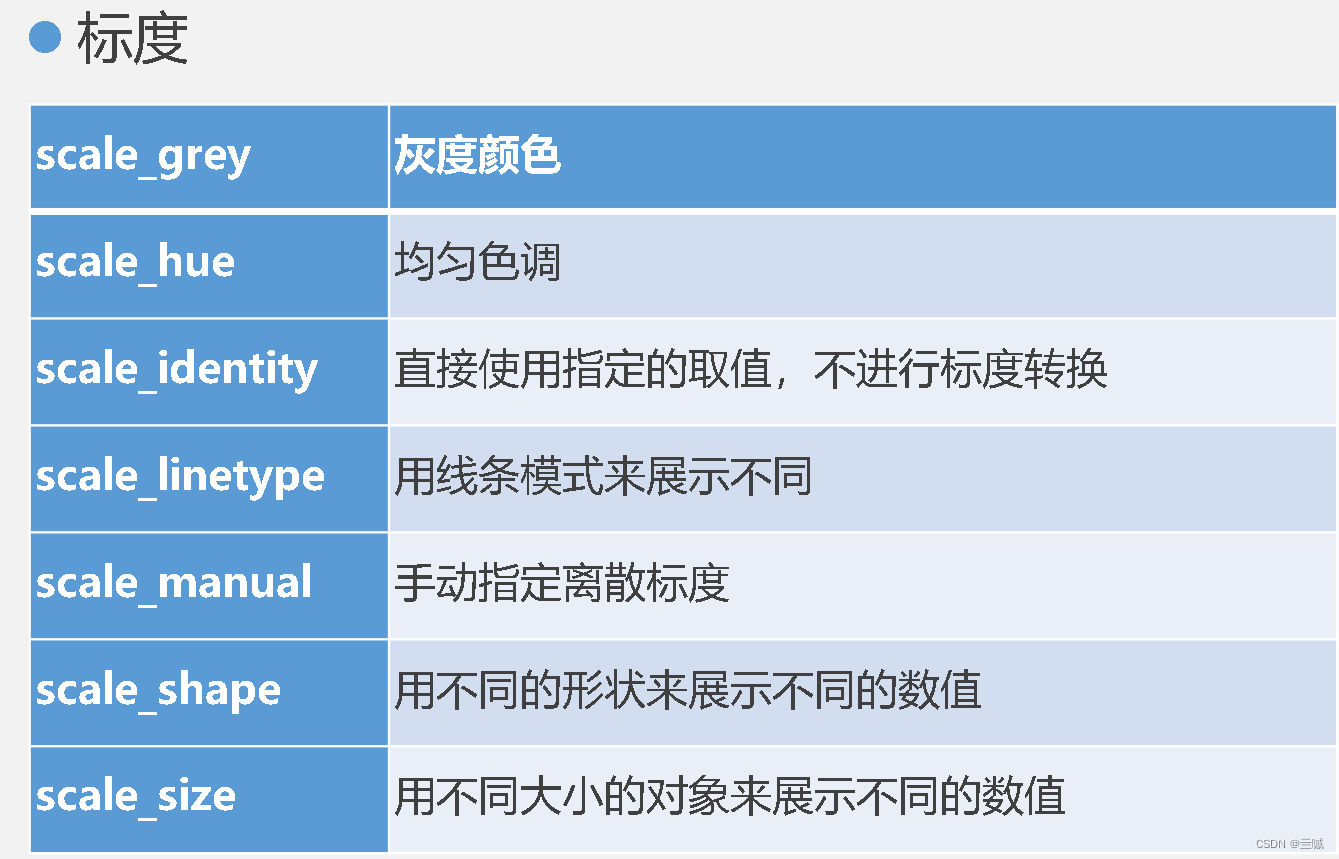

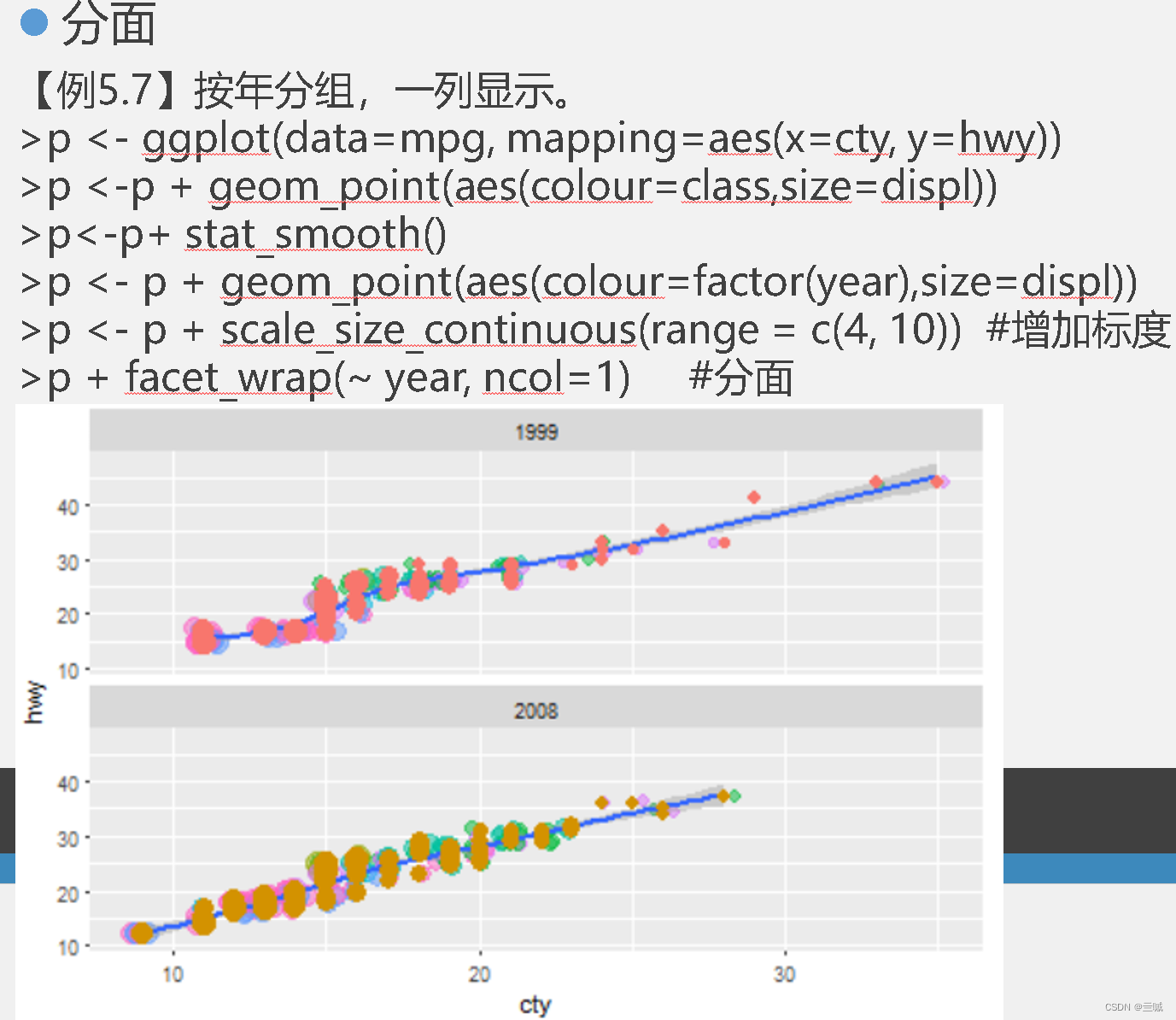
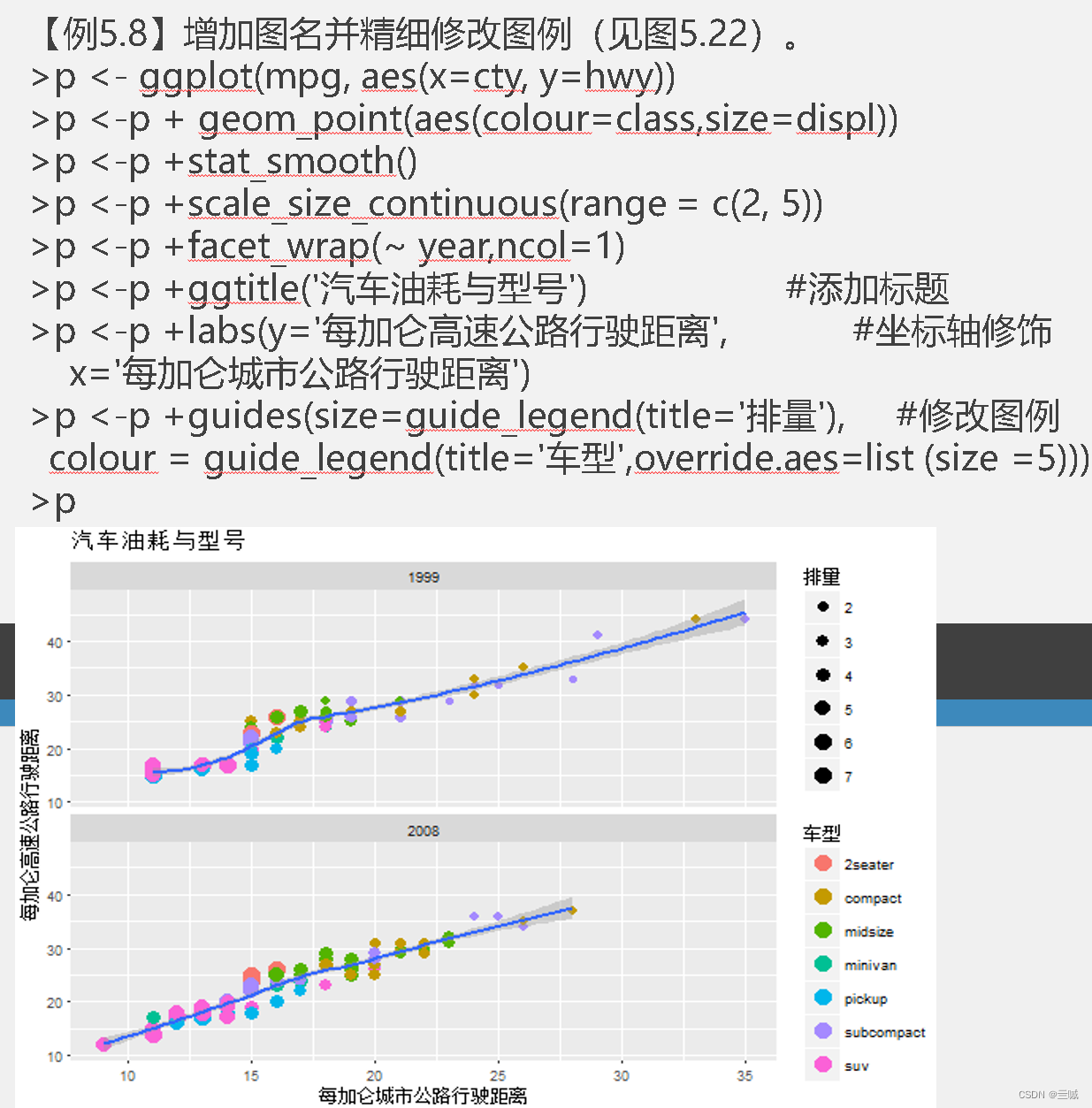
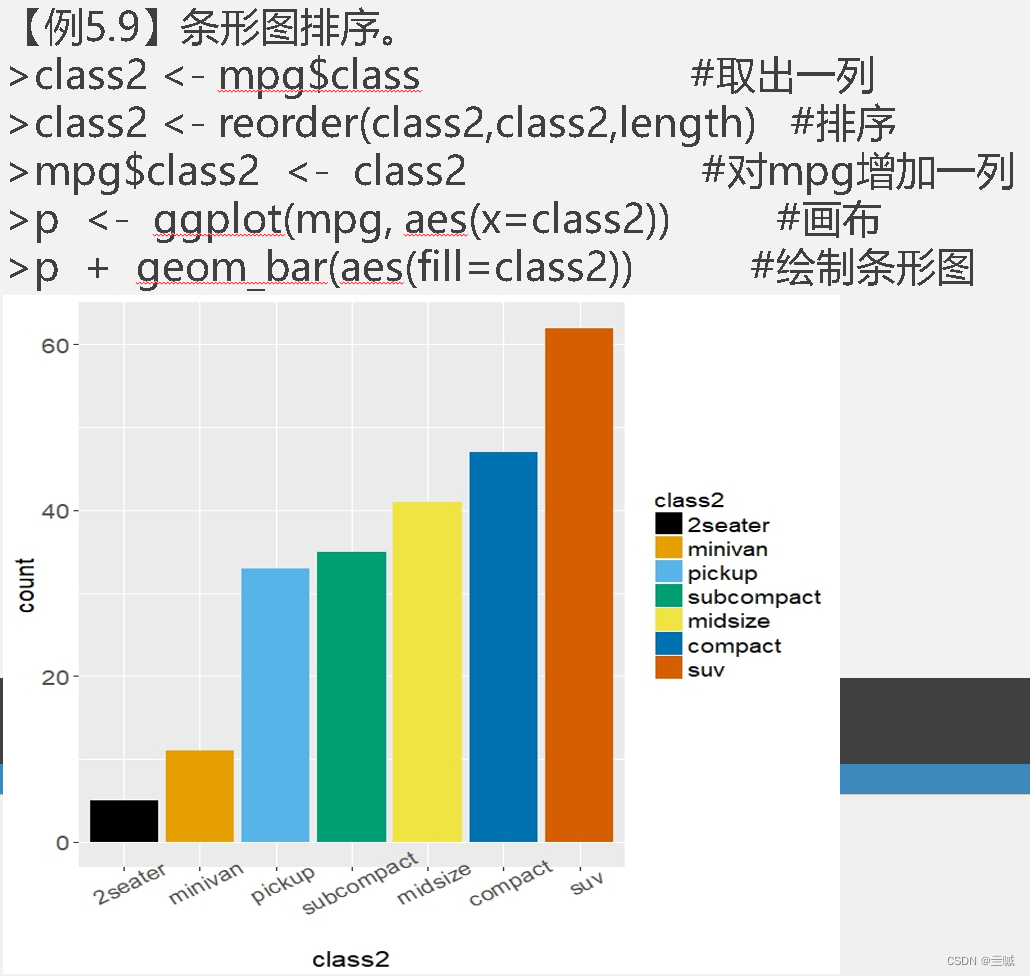
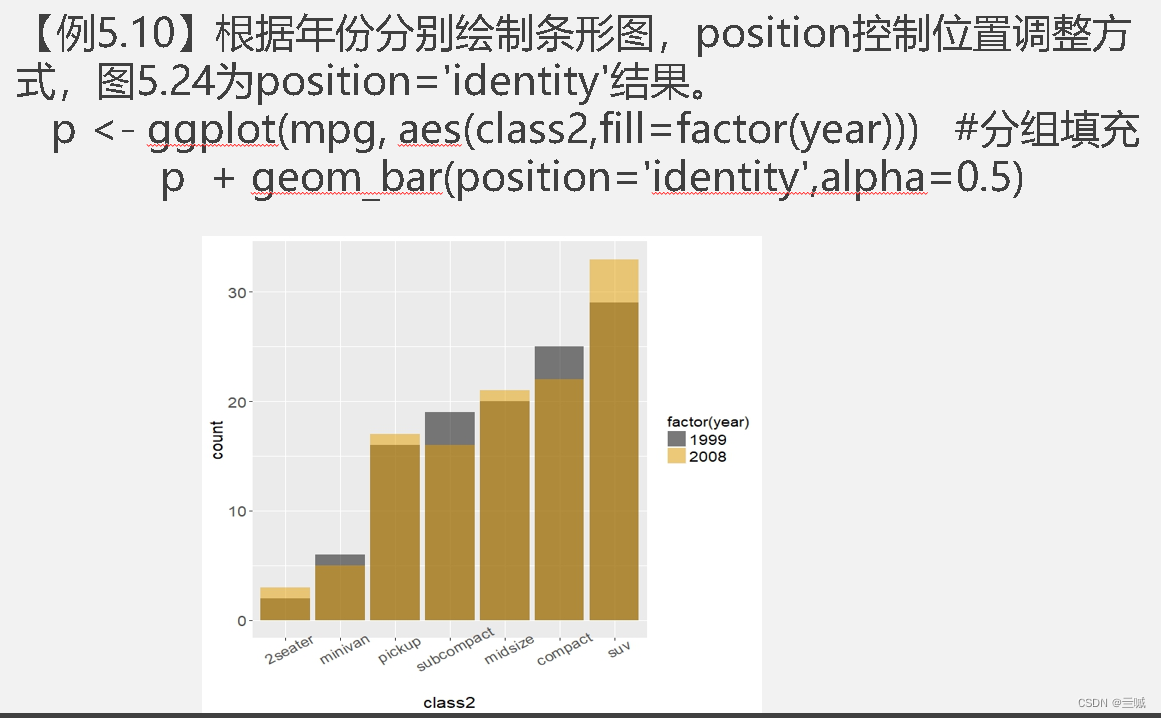
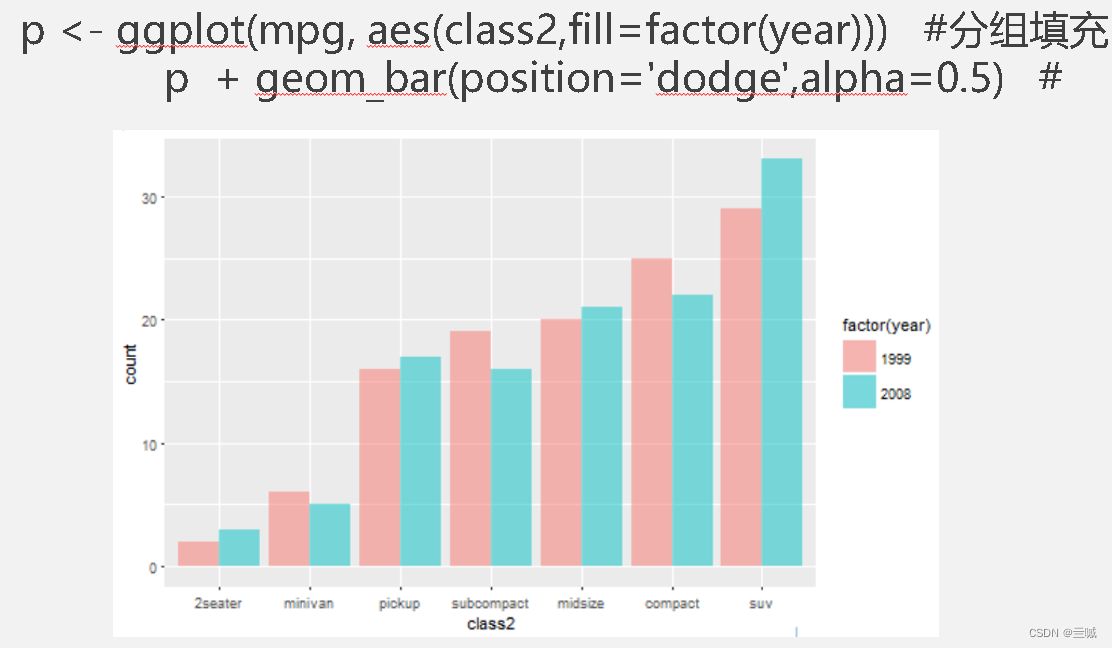
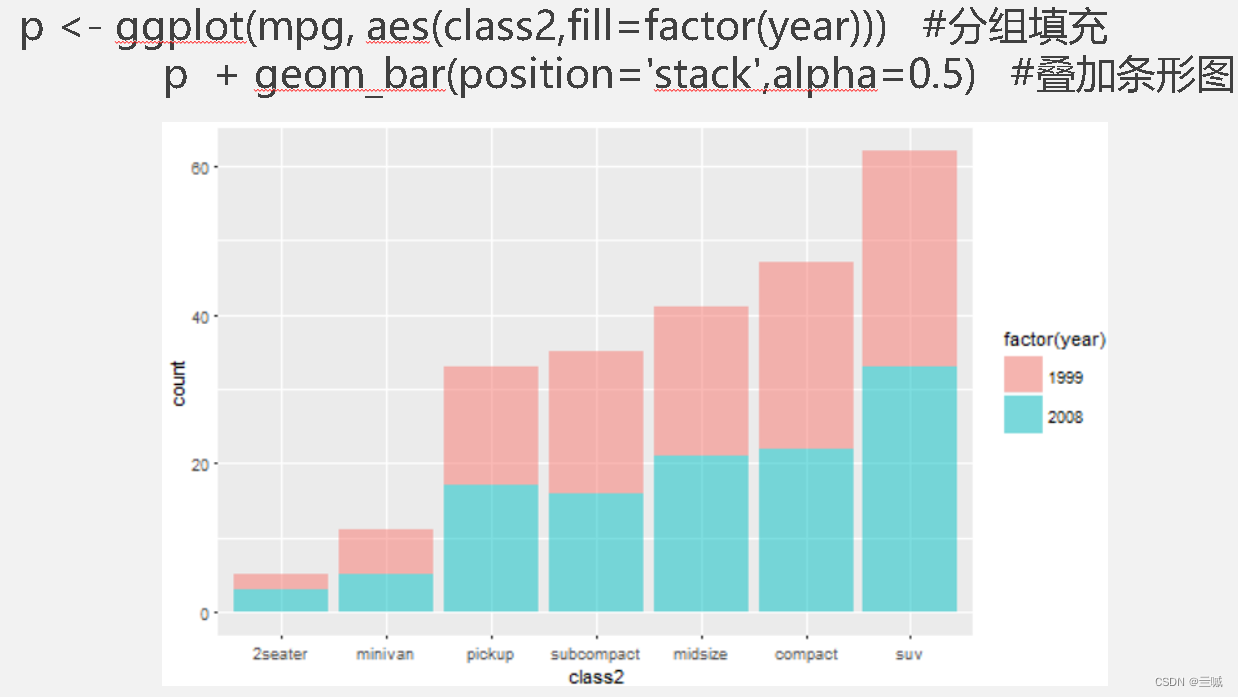
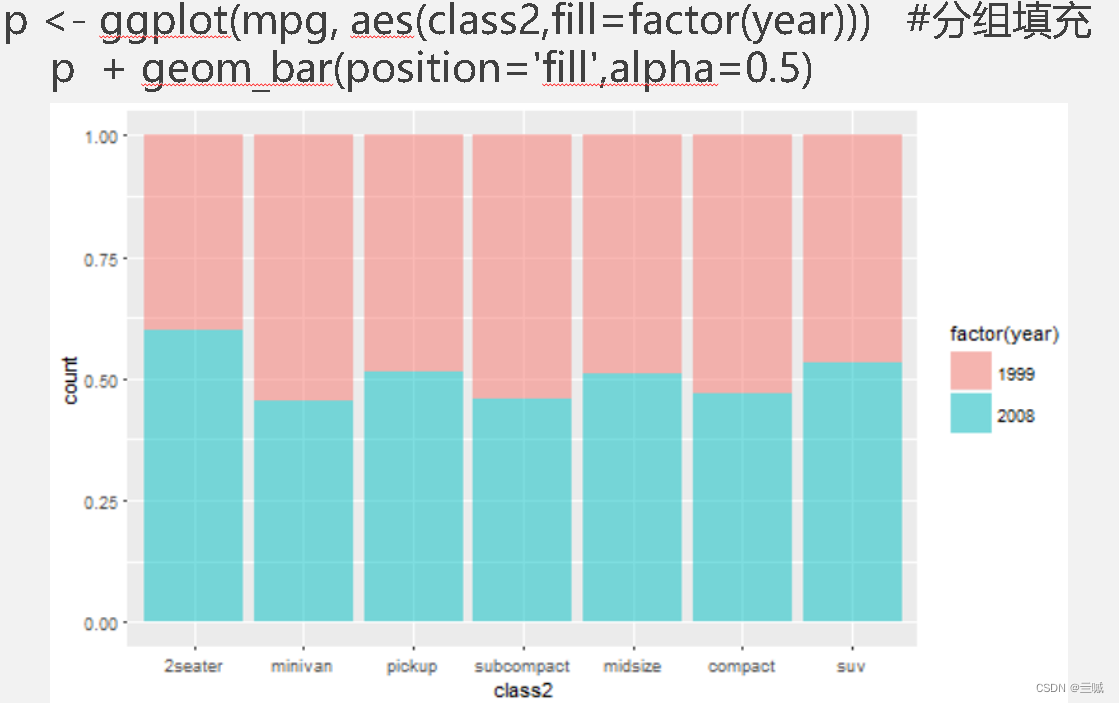

习题
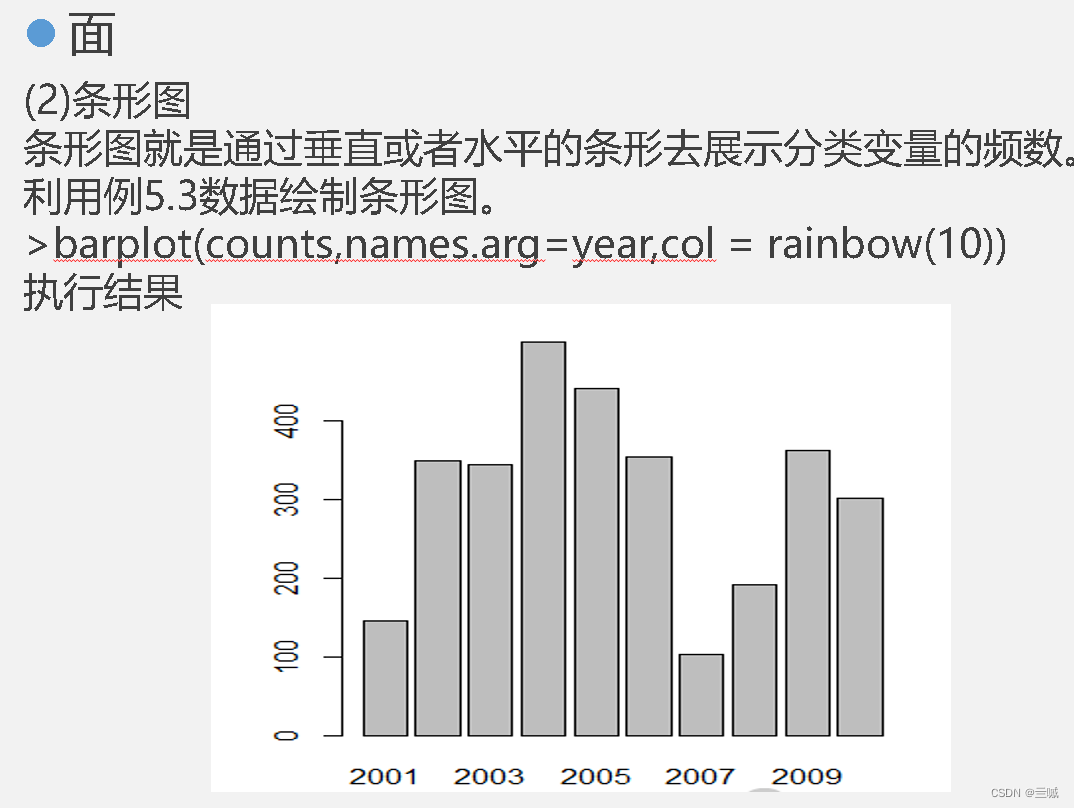
向日葵散点图可以用来克服散点图中数据点重叠问题。
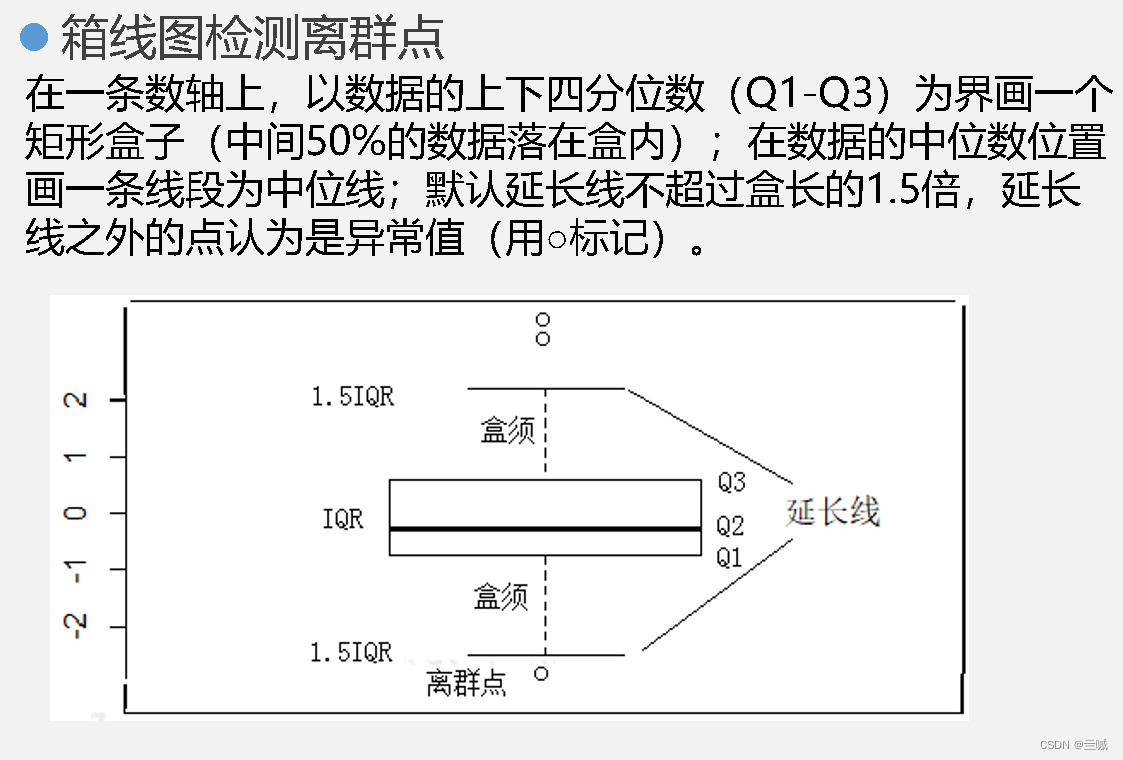
在“箱线图”中,箱体的底部表示下四分位数
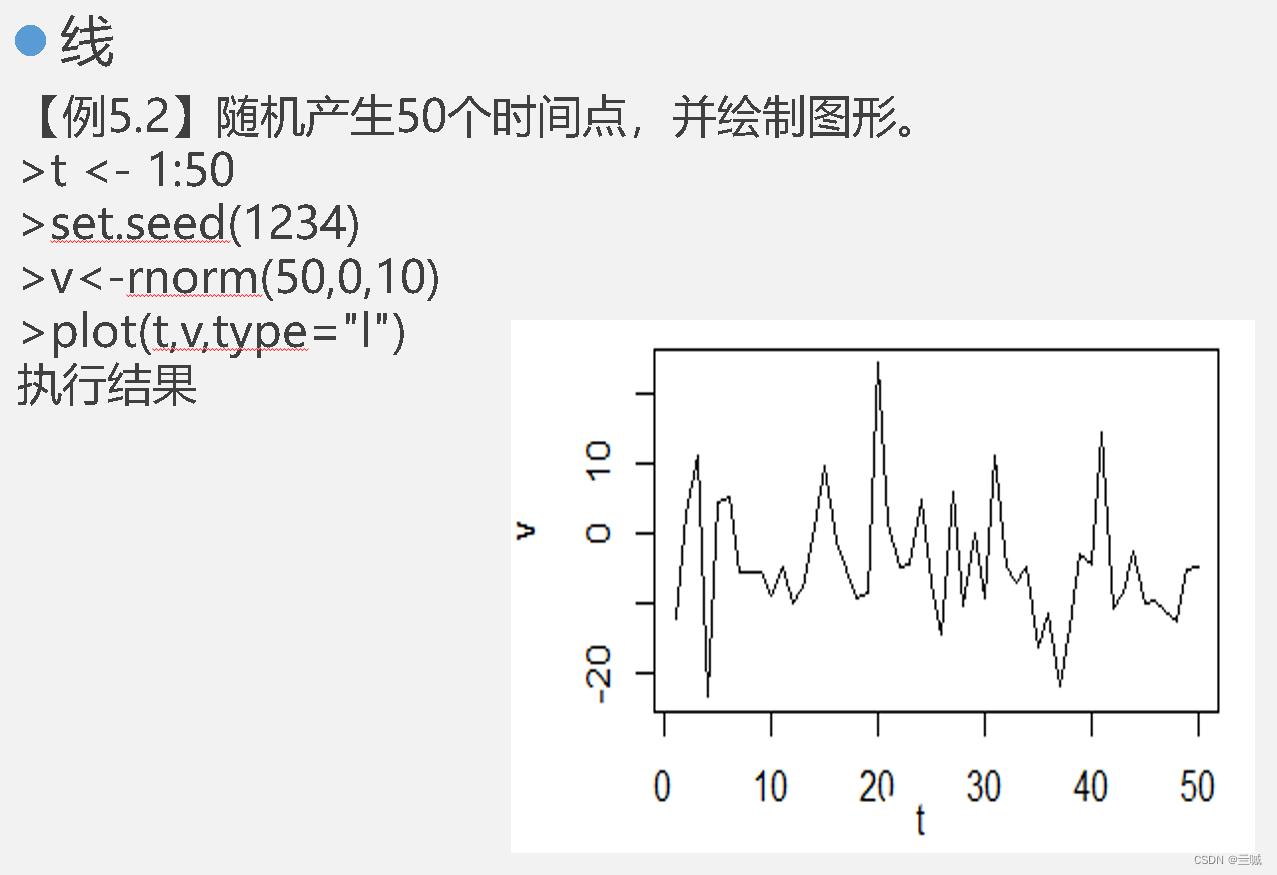
散点图和线图有助于描绘两个变量之间的关系。
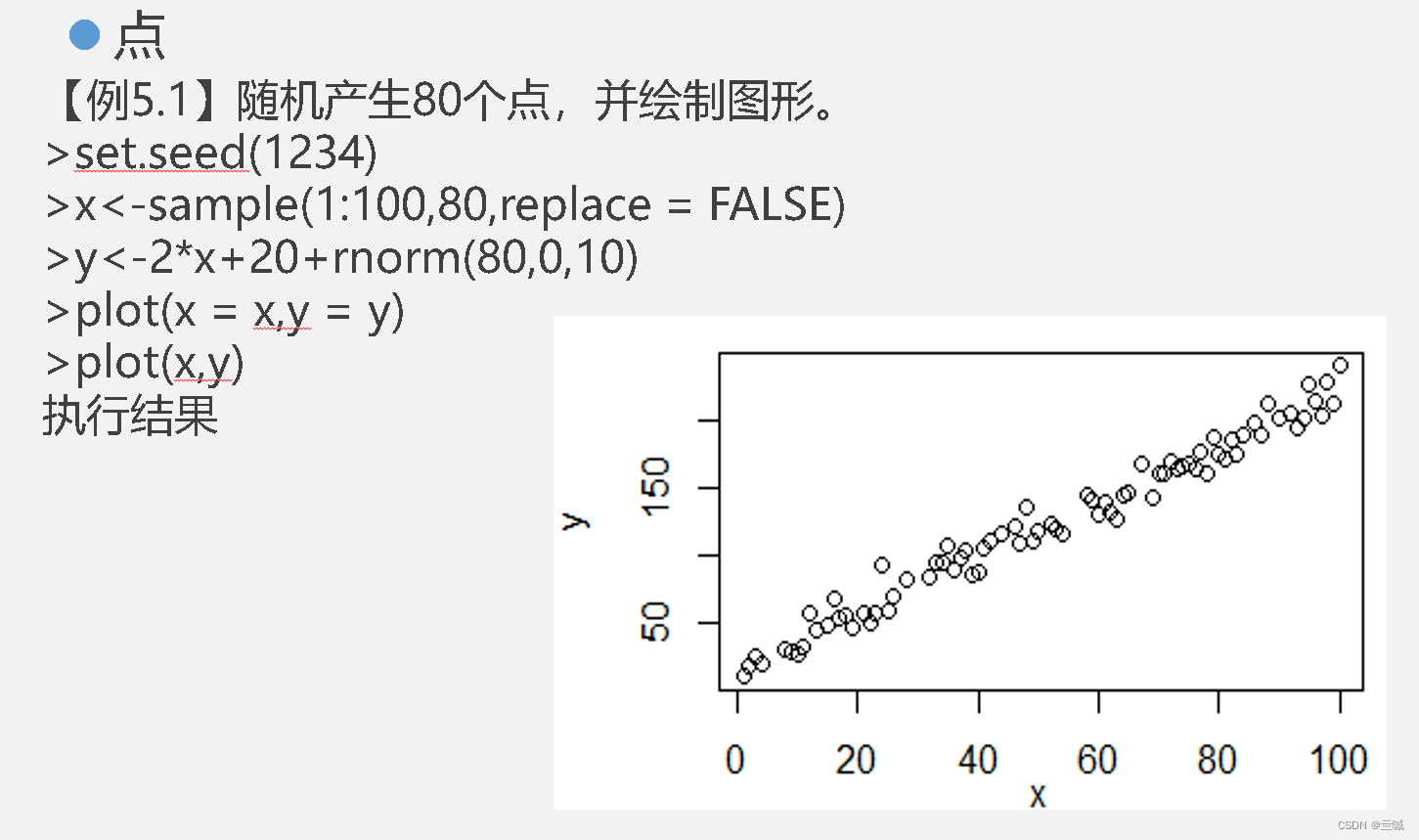
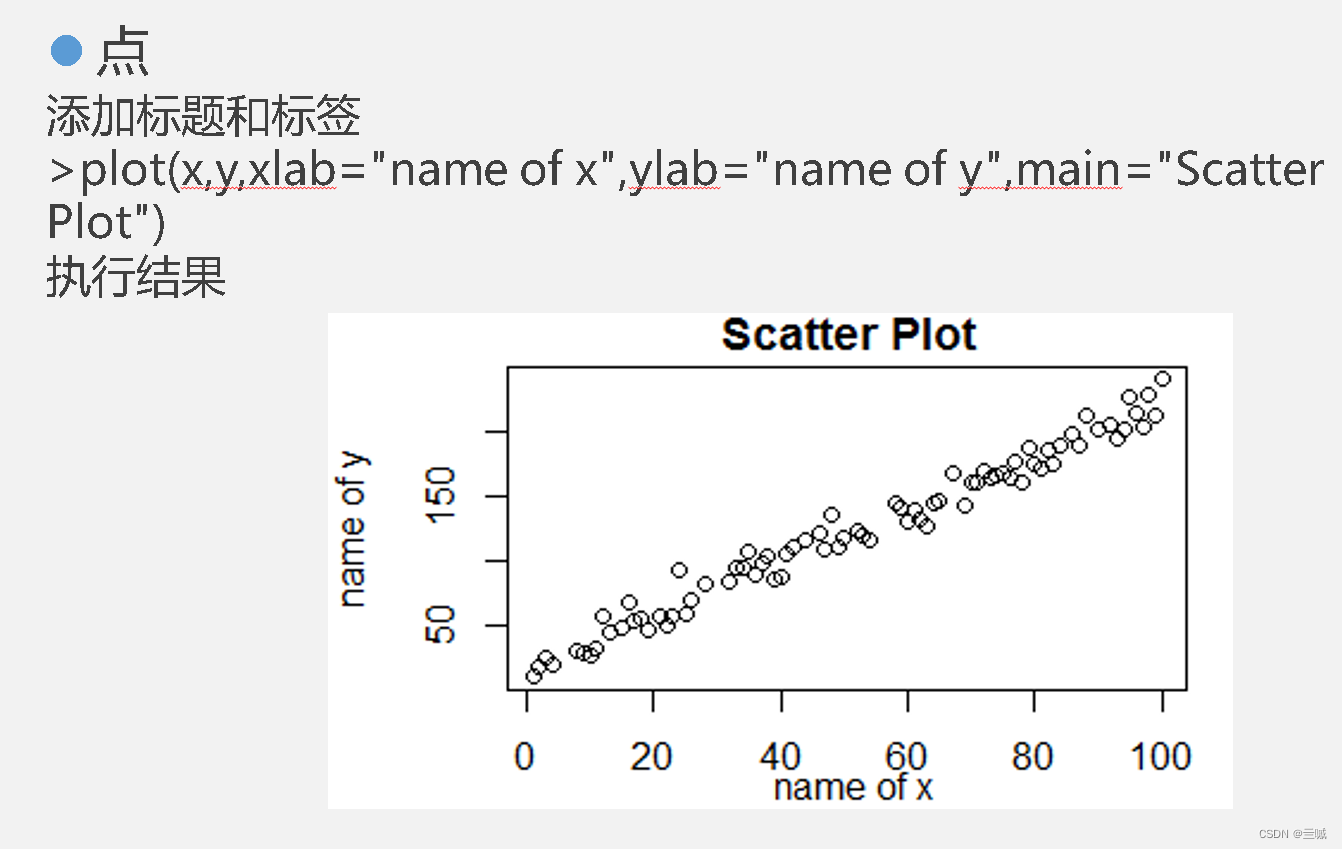
plot()函数可以按照向量绘制图形。
第六章


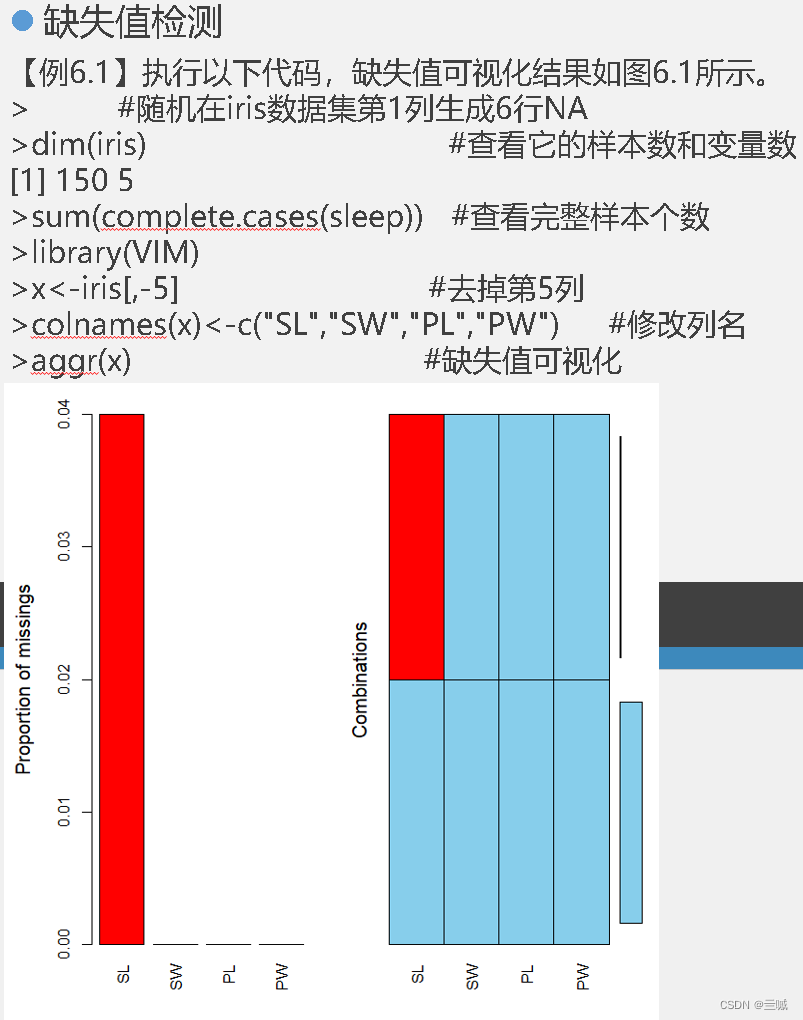


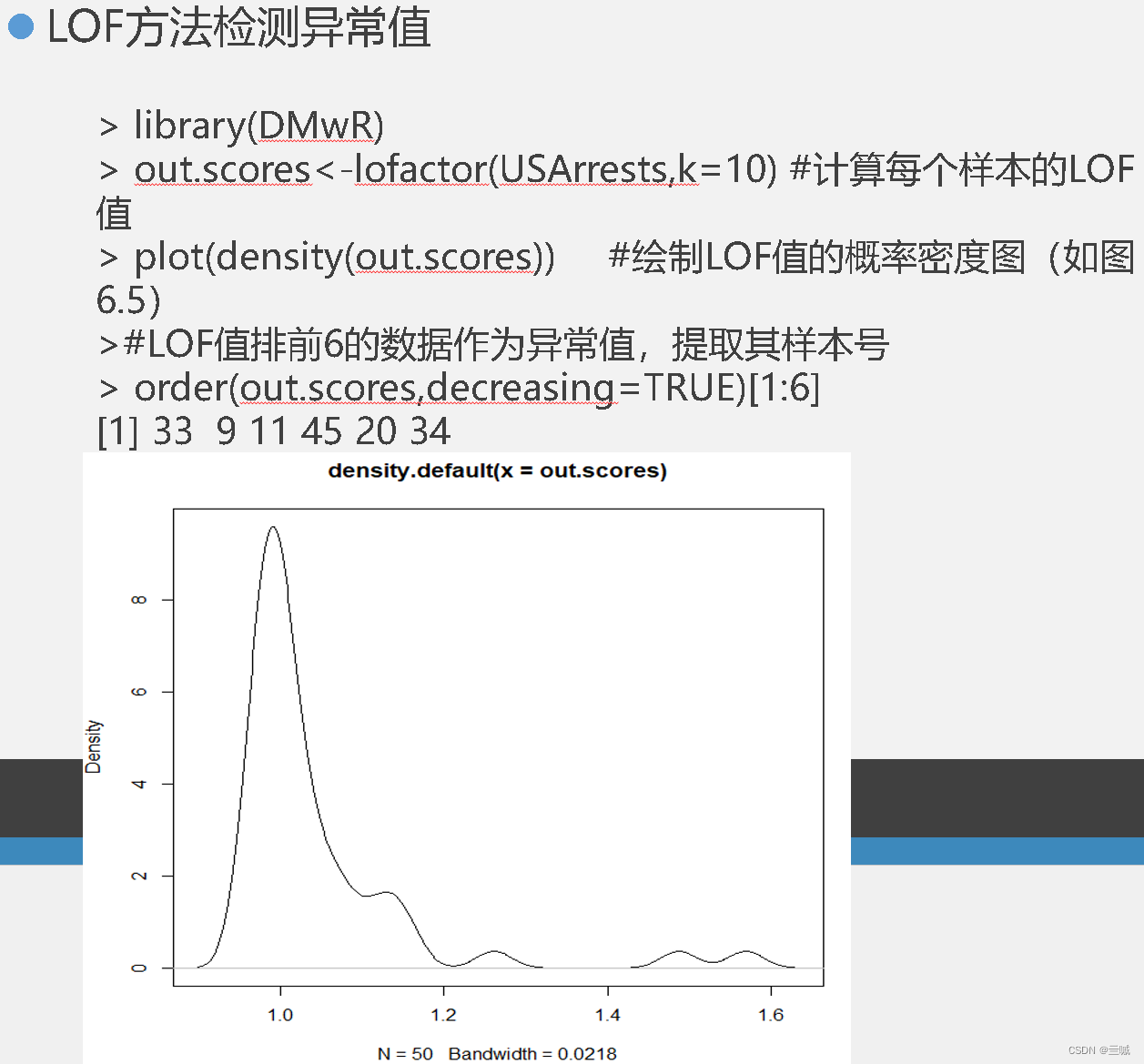




习题
判断是否有缺失值的函数是 is.na()
对于缺失数据,通常有三种常见的处理方法:
删除缺失数据、插补缺失数据、将缺失数据作为一个单独的类别或指标
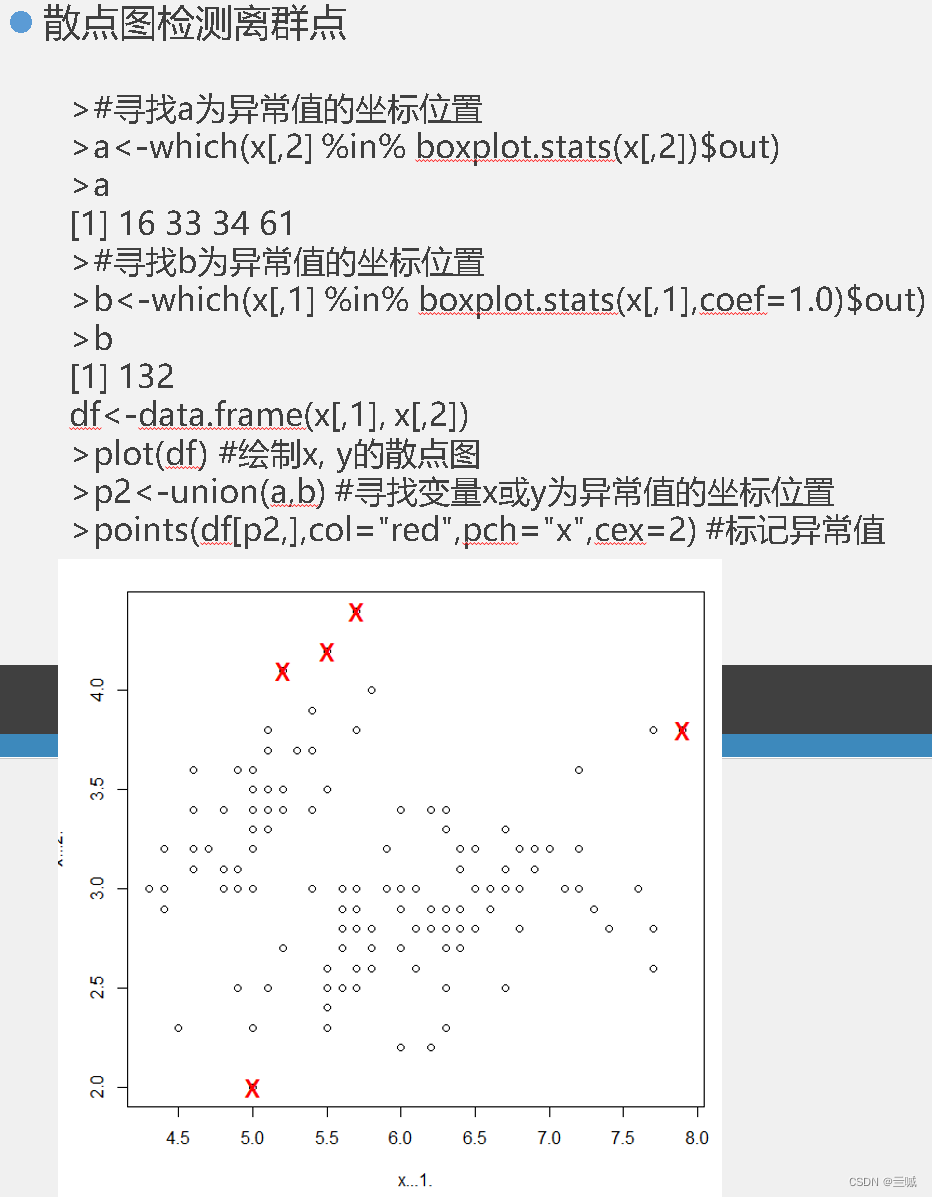
检测数据的异常值是使用函数:outlier() / outlier.test() / boxplot()
如何判定离群:
根据统计指标:使用均值、标准差、分位数等统计指标,将超过一定阈值的观测值定义为离群值。
基于箱线图:通过观察箱线图中的异常观测点,超过上下四分位距的1.5倍或3倍的观测值被认为是离群值。
基于专业知识或领域经验:根据特定领域的专业知识或经验,对数据中的异常观测值进行判定。
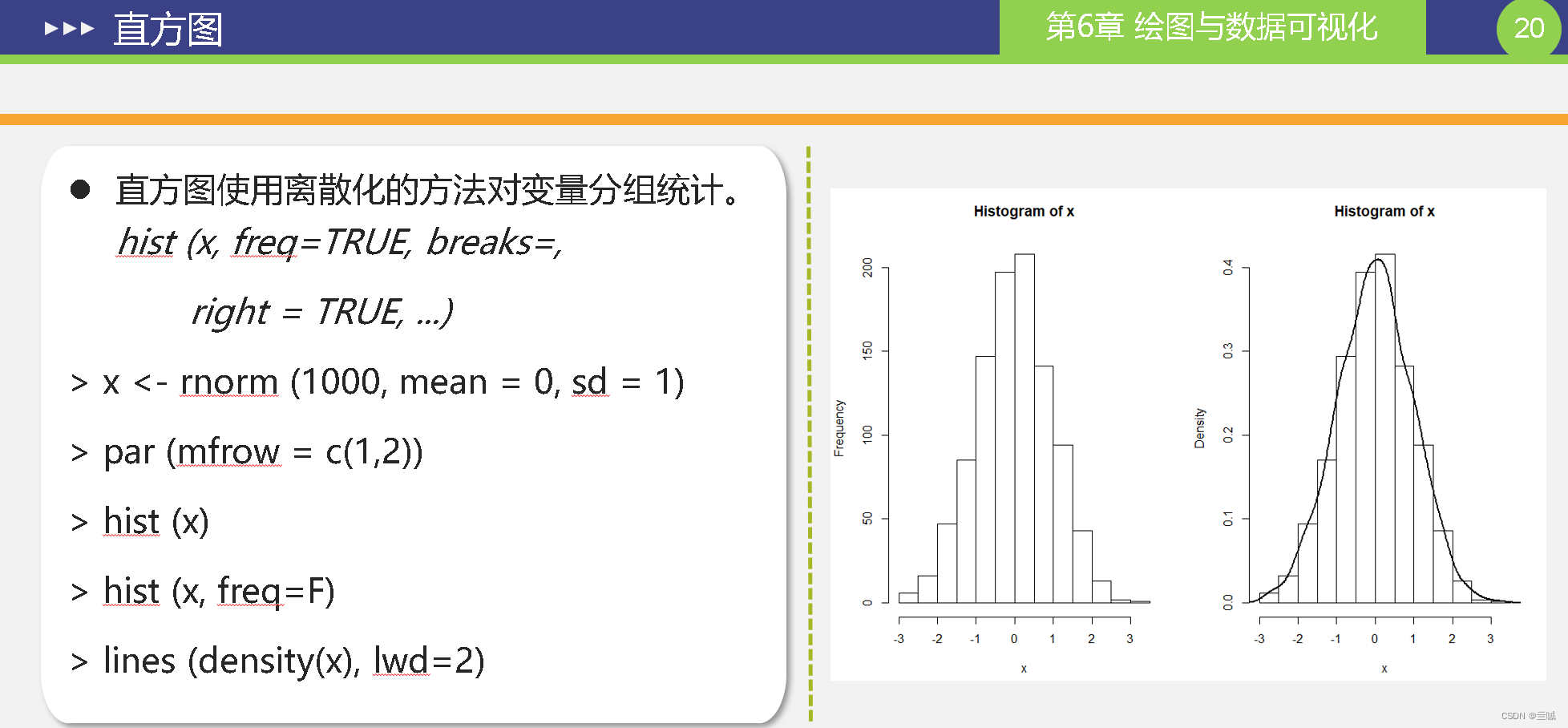
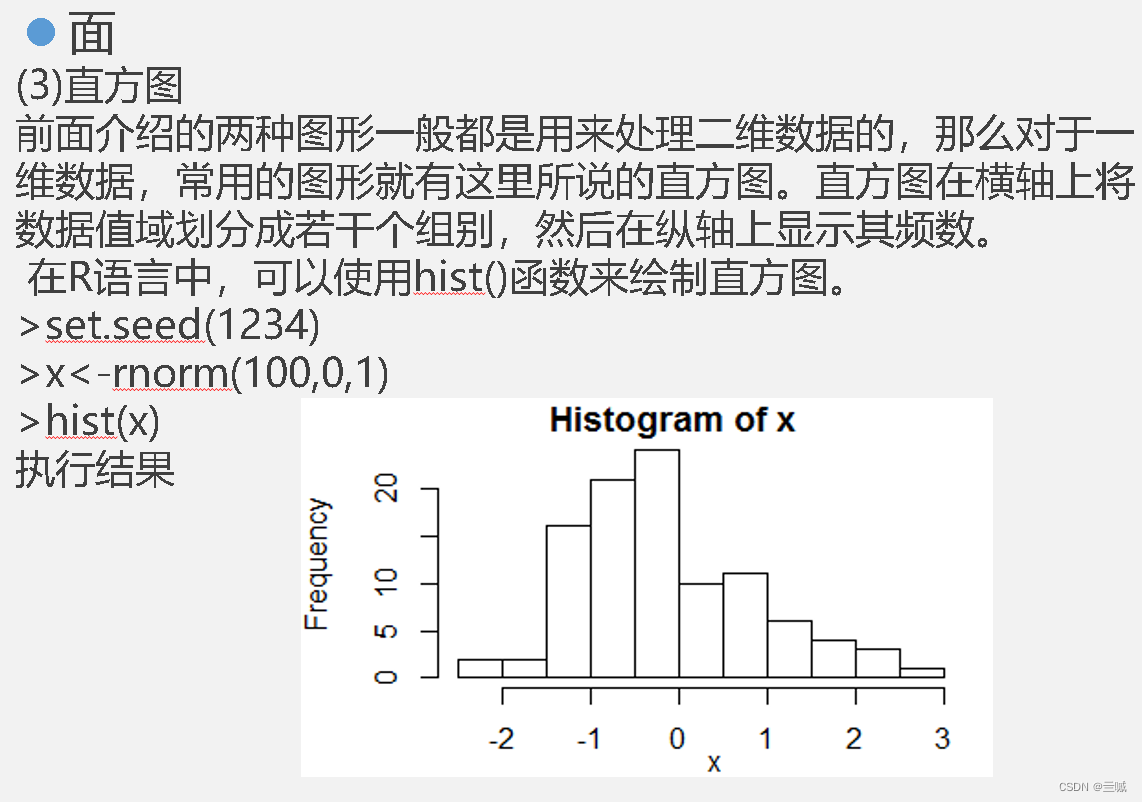
在R语言中,通常使用 hist() 函数来绘制直方图。
当对数据进行批量操作时,可以通过对函数返回值进行约束,根据是否提示错误判断是否存在数据不一致问题,可以通过 stopifnot() 函数。
第七章

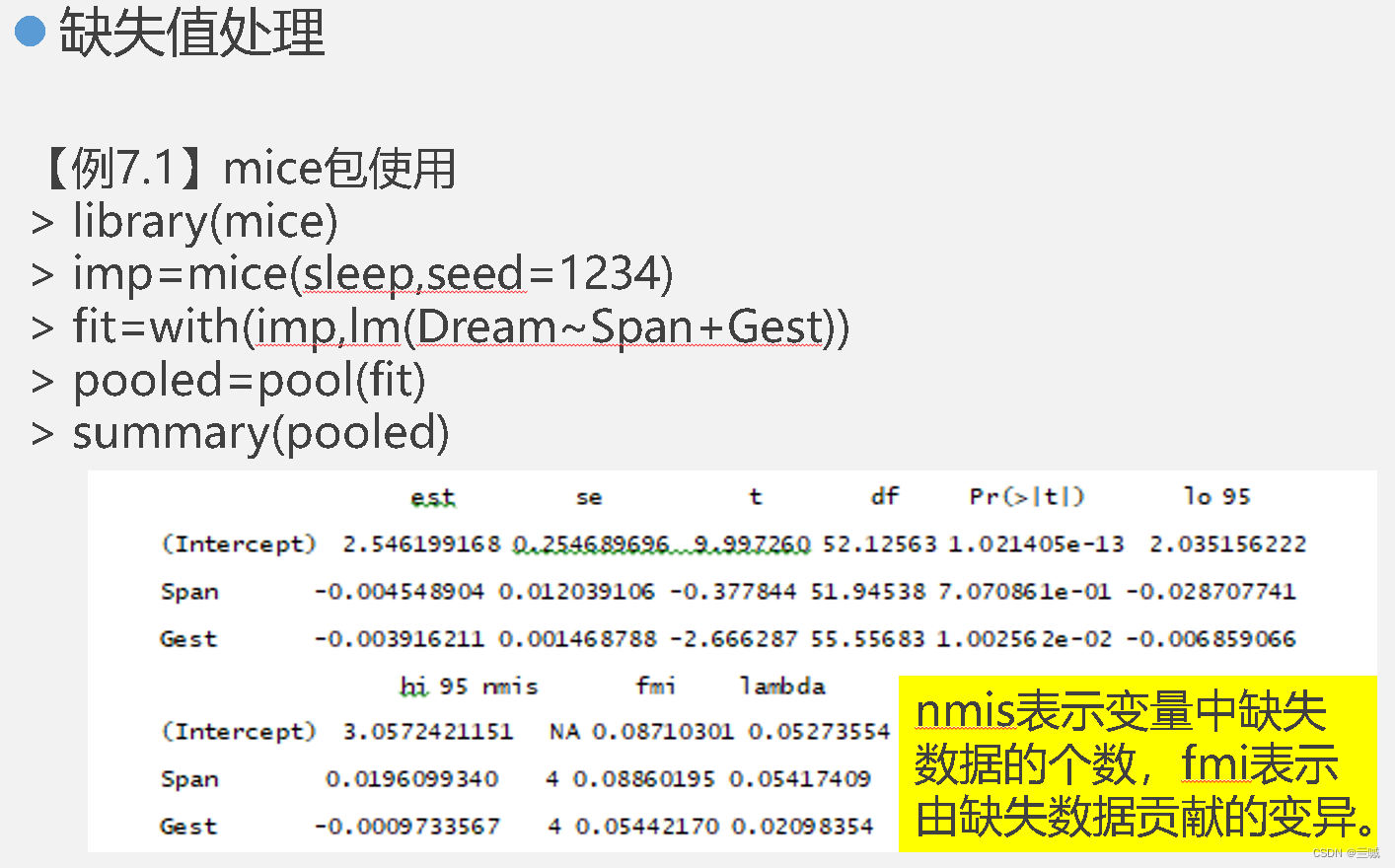






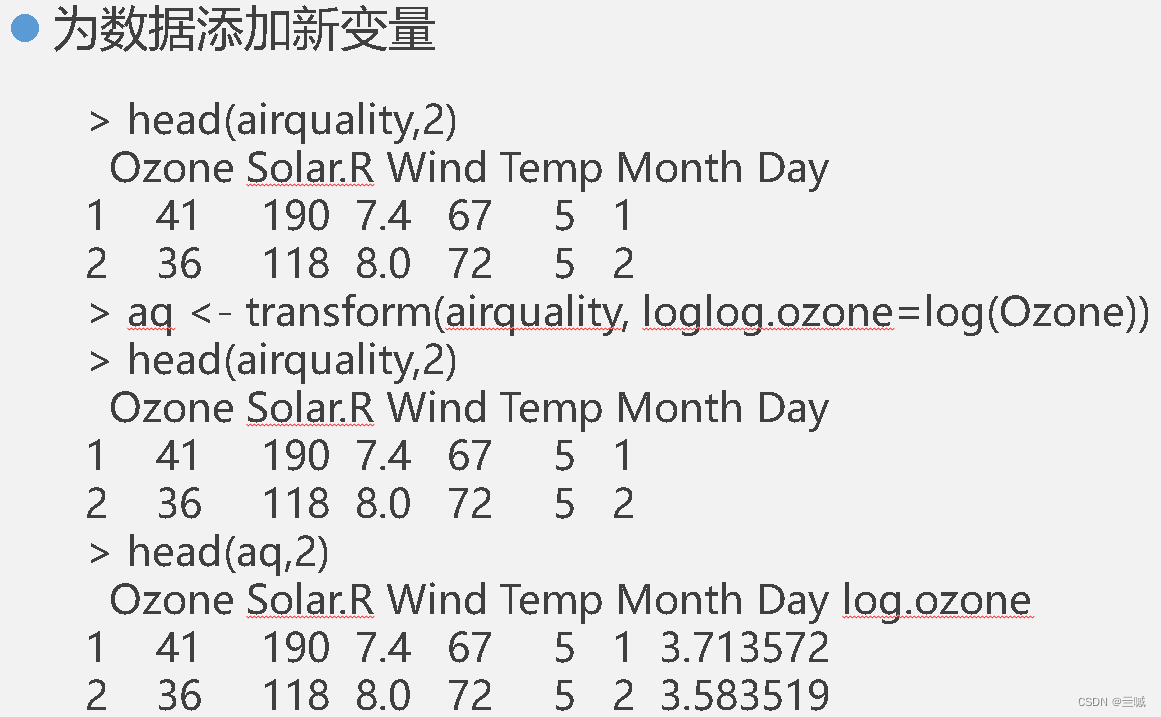

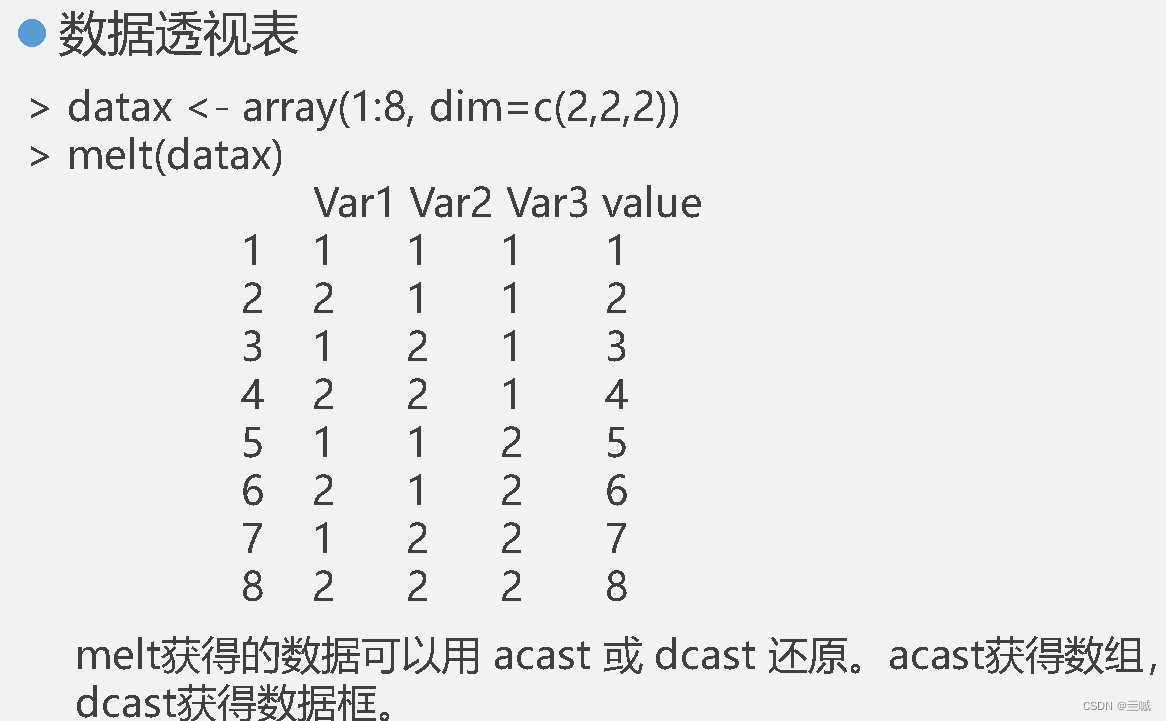




习题
矩阵和多维数组的向量化有直接的类型转换函数: as.vector,向量化后的结果顺序是:列优先
在数据分析体系中,ETL功能不包括:进行数据挖掘
包括:对错误的源数据进行清洗、对数据格式进行必须的转换、读取源数据
数据集1, 2, 3, 6, 3经过中间化的结果是:-2,-1,0,3,0
数据集1, 2, 3, 6, 3经过数据的标准化后的结果是:
数据的标准化是一种常见的数据预处理技术,它使得数据的均值为0,标准差为1。要计算数据集的标准化结果,可以按照以下步骤进行操作:
1 计算数据集的均值(mean)。
2 计算数据集的标准差(standard deviation)。
3 对每个数据点,将其减去均值,然后除以标准差。
对于给定的数据集 1, 2, 3, 6, 3,我们可以按照上述步骤进行标准化计算。请注意,这里假设使用样本标准差进行计算。
均值:(1 + 2 + 3 + 6 + 3) / 5 = 3
标准差:sqrt(((1-3)^2 + (2-3)^2 + (3-3)^2 + (6-3)^2 + (3-3)^2) / 4) ≈ 1.82574
标准化结果:(1-3)/1.82574, (2-3)/1.82574, (3-3)/1.82574, (6-3)/1.82574, (3-3)/1.82574
计算结果为:-1.09545, -0.54772, 0, 1.64316, 0
因此,数据集 1, 2, 3, 6, 3 经过标准化后的结果是 -1.09545, -0.54772, 0, 1.64316, 0。
R函数的参数传递方式是按值传递(pass-by-value),变量不可能原地址修改后再放回原地址。
数据聚集函数包括:sum()、avg()、max()、min()。
aggregate函数的作用,根据数据对象不同它的用法有:对数据框、数组或矩阵进行聚合

第八章









source(“SumSquareFunc.R”) 是 R 中的一个函数调用,用于加载并执行指定文件中的 R 代码。




习题
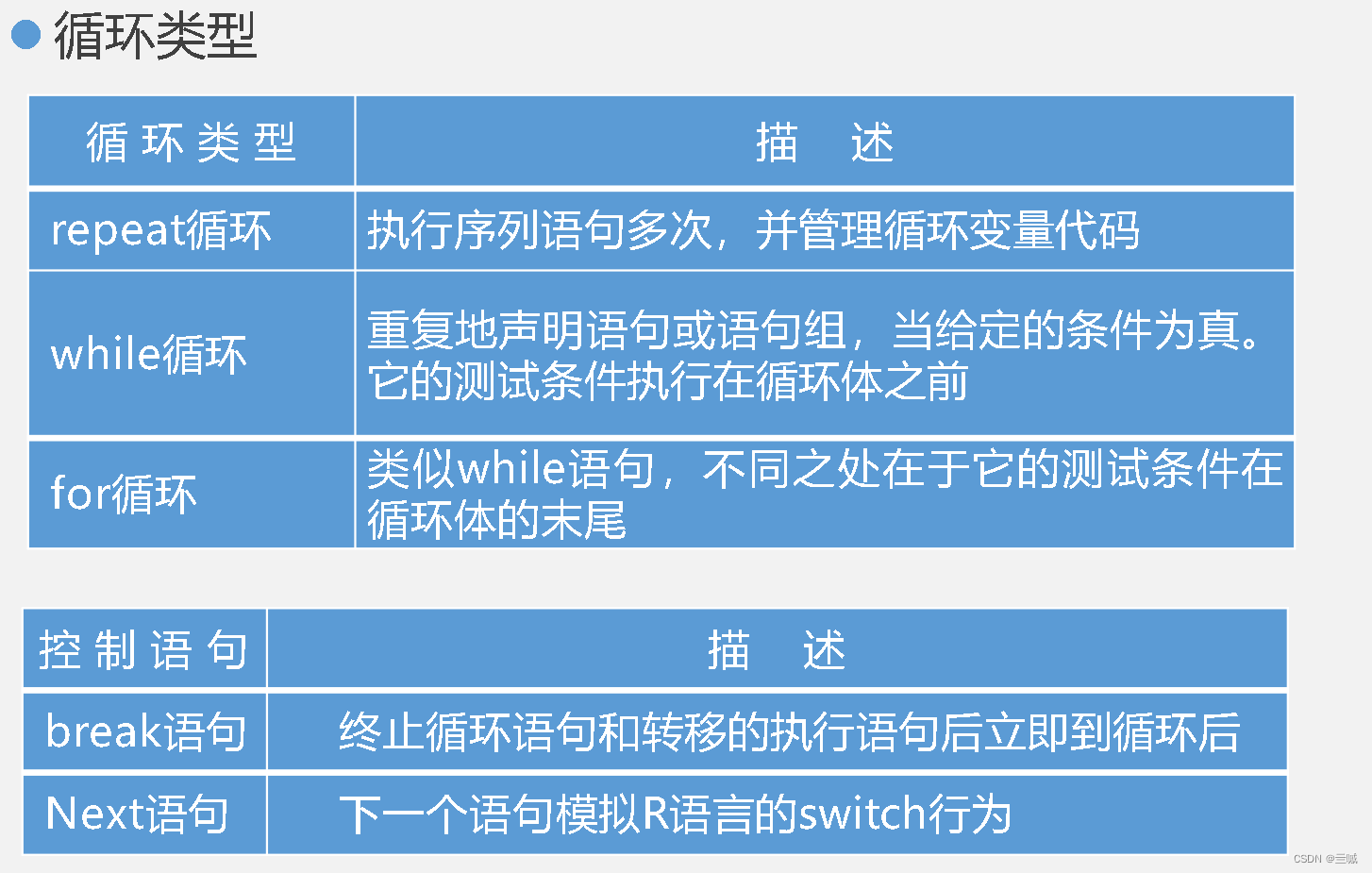
R 语言的选择控制结构包括 if、else 和 switch。
R语言中适用于一个条件有多个分支的情况的选择结构是:switch
除了常见的 while 循环和 for 循环,R 语言还提供了 repeat 循环。
R 语言中需要通过 break 来结束循环的循环结构是:repeat
R 语言中测试条件在循环体的末尾的循环结构是:for
R 语言中的函数可以包含任意数量的参数,并且这些参数可以具有默认值。
第九章

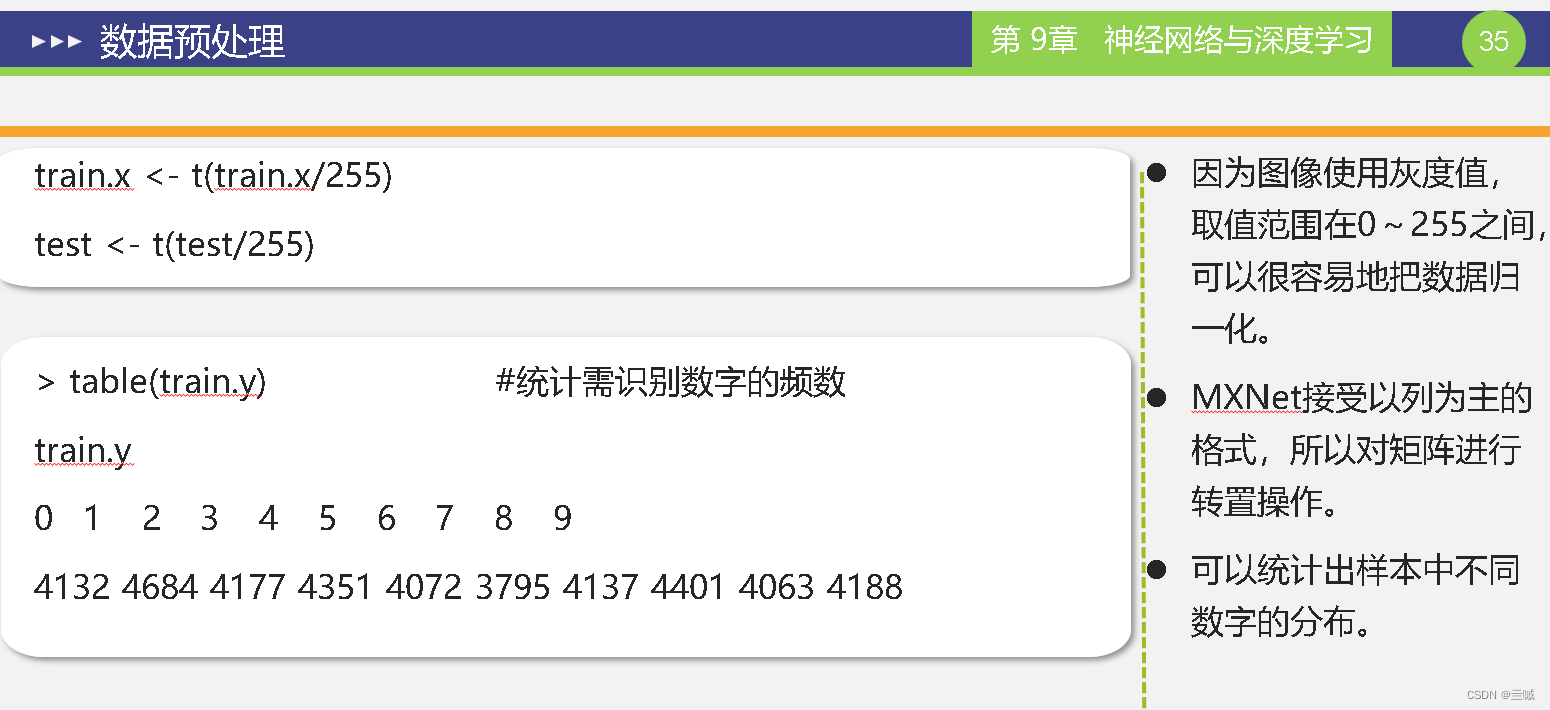
在 R 语言中,table() 函数用于创建频数表,它接受一个向量作为输入,并返回一个由唯一值和相应频数组成的表格。
head(faithful, 3) 预览faithful数据集的前三行。
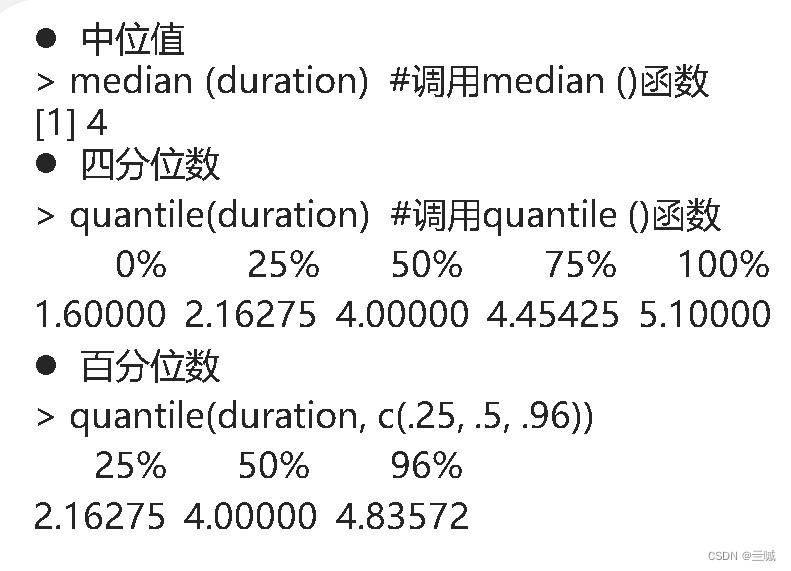
使用range()函数得到数据上下界
seq() 函数在 R 语言中用于创建等差数列(sequence),三个参数:from(起始值)、to(结束值)和 by(步长)。
cut() 函数在 R 语言中用于将连续变量分割为离散的组(bins)。
三个参数:
x:要分割的连续变量。
breaks:指定分割点的方法,可以是一个数值向量或一个整数表示分割成的组数。
right:一个逻辑值,指定是否包含右边界,默认为 TRUE,表示右闭区间。
str() 函数用于查看对象的结构信息,包括对象的类型、尺寸和成员等
cumsum() 函数用于计算给定向量的累计和。
stem() 函数在 R 语言中用于创建茎叶图,它接受一个向量作为输入,并将该向量的值分解为茎部和叶部。
par 是 R 语言中用于设置图形参数的函数。
mfrow 是 R 语言中用于设置多个图形的布局的参数。







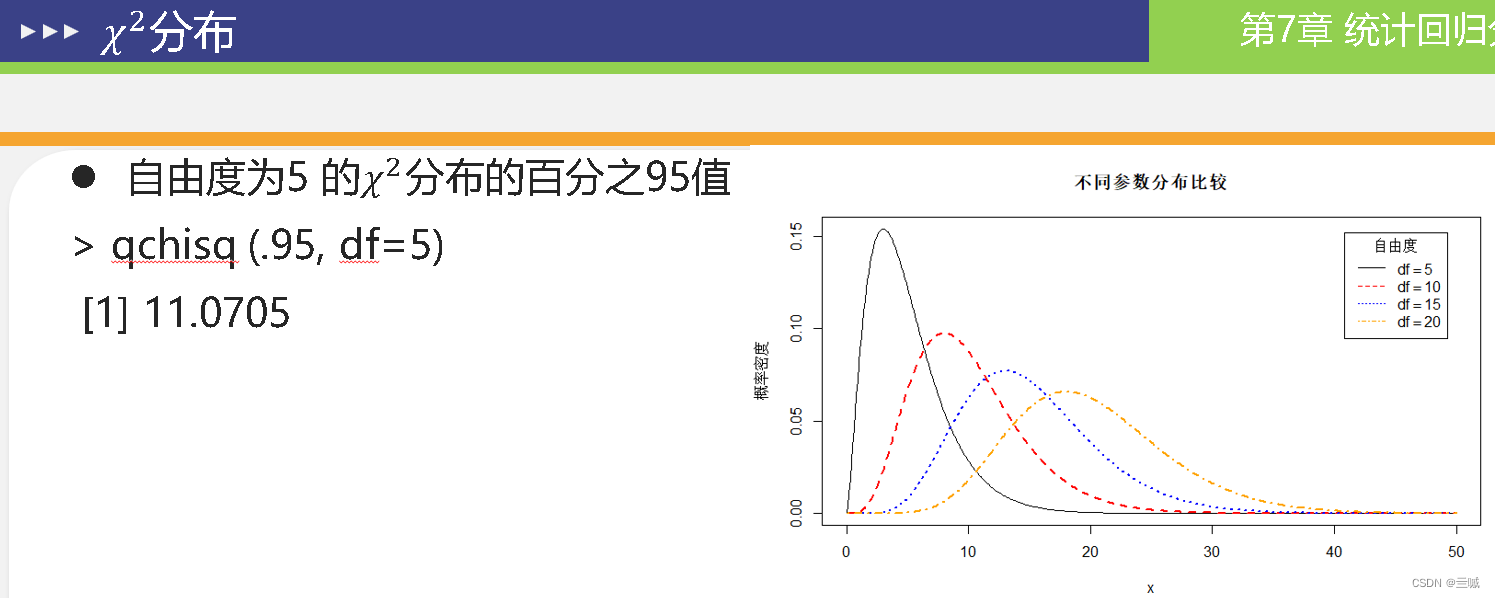
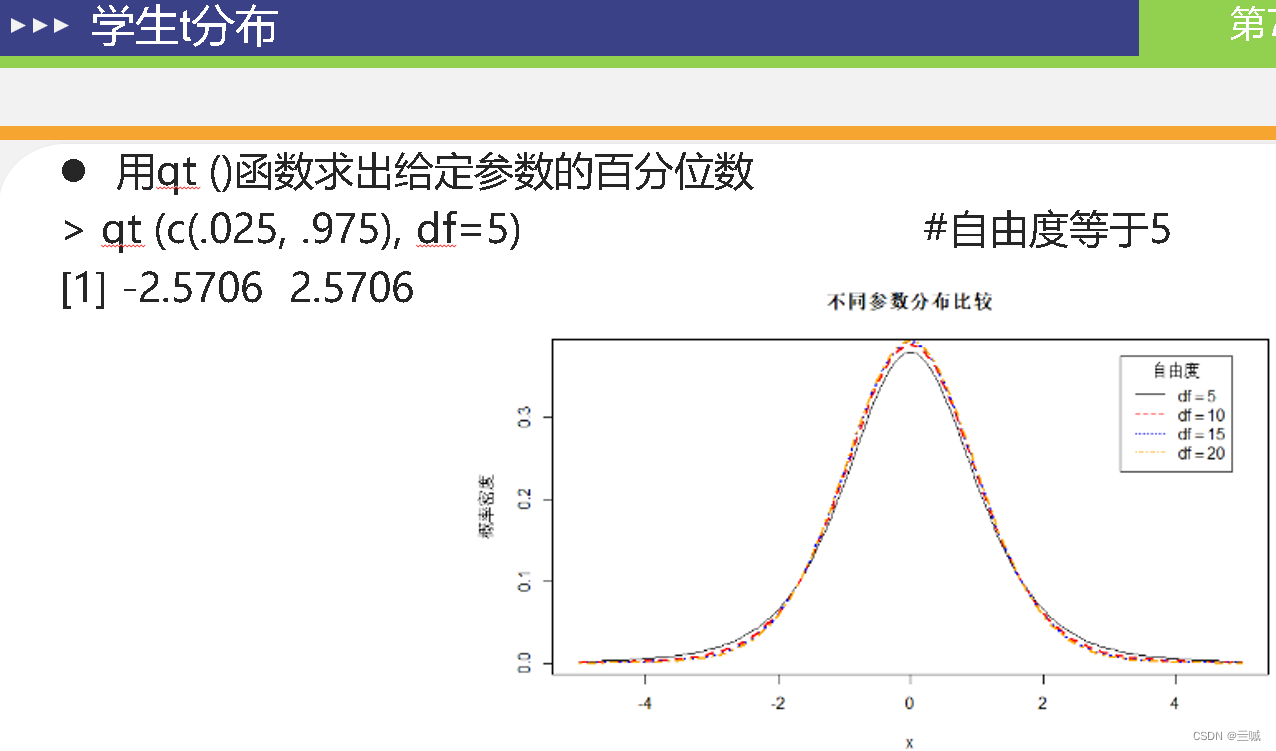




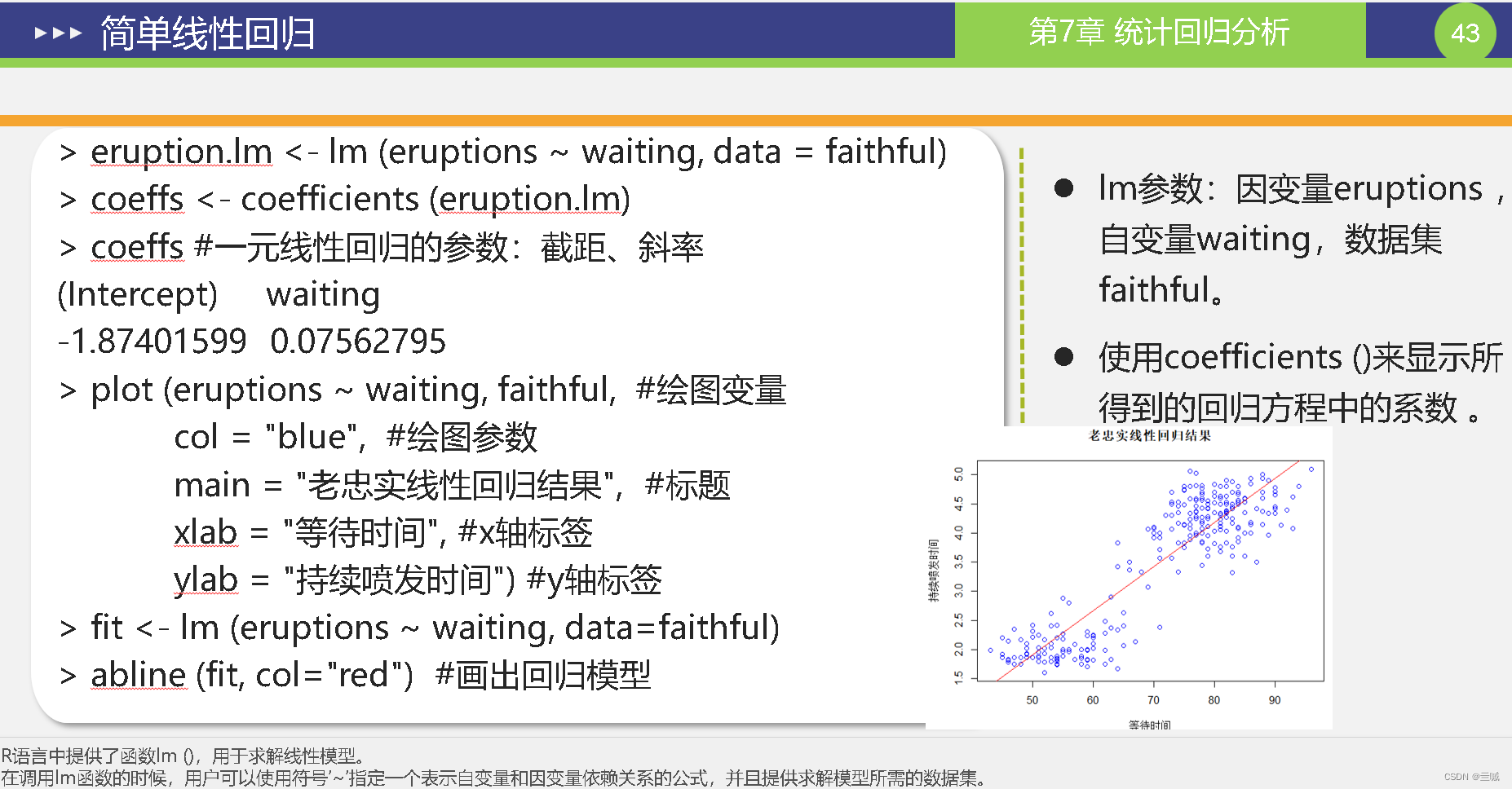




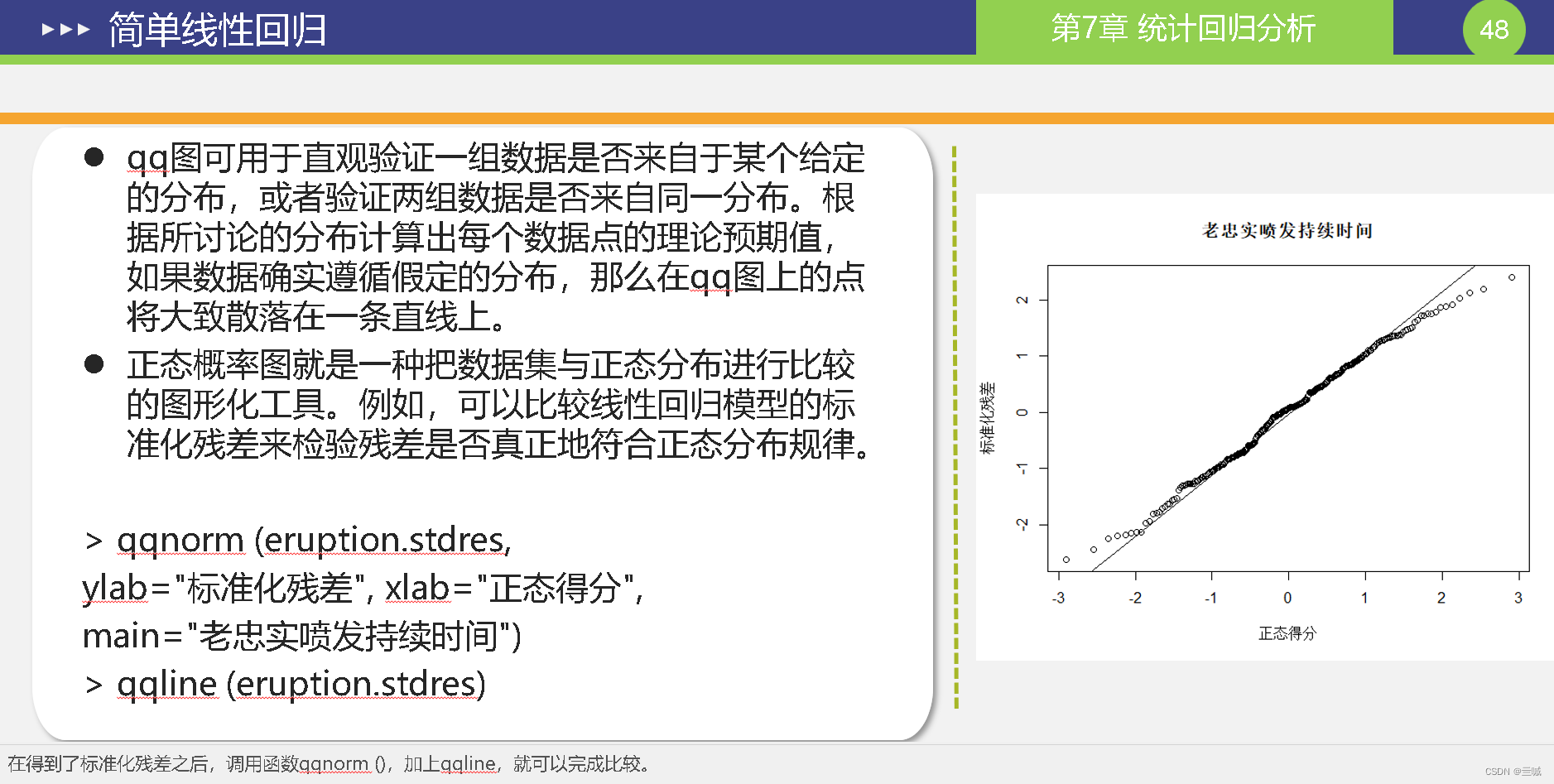







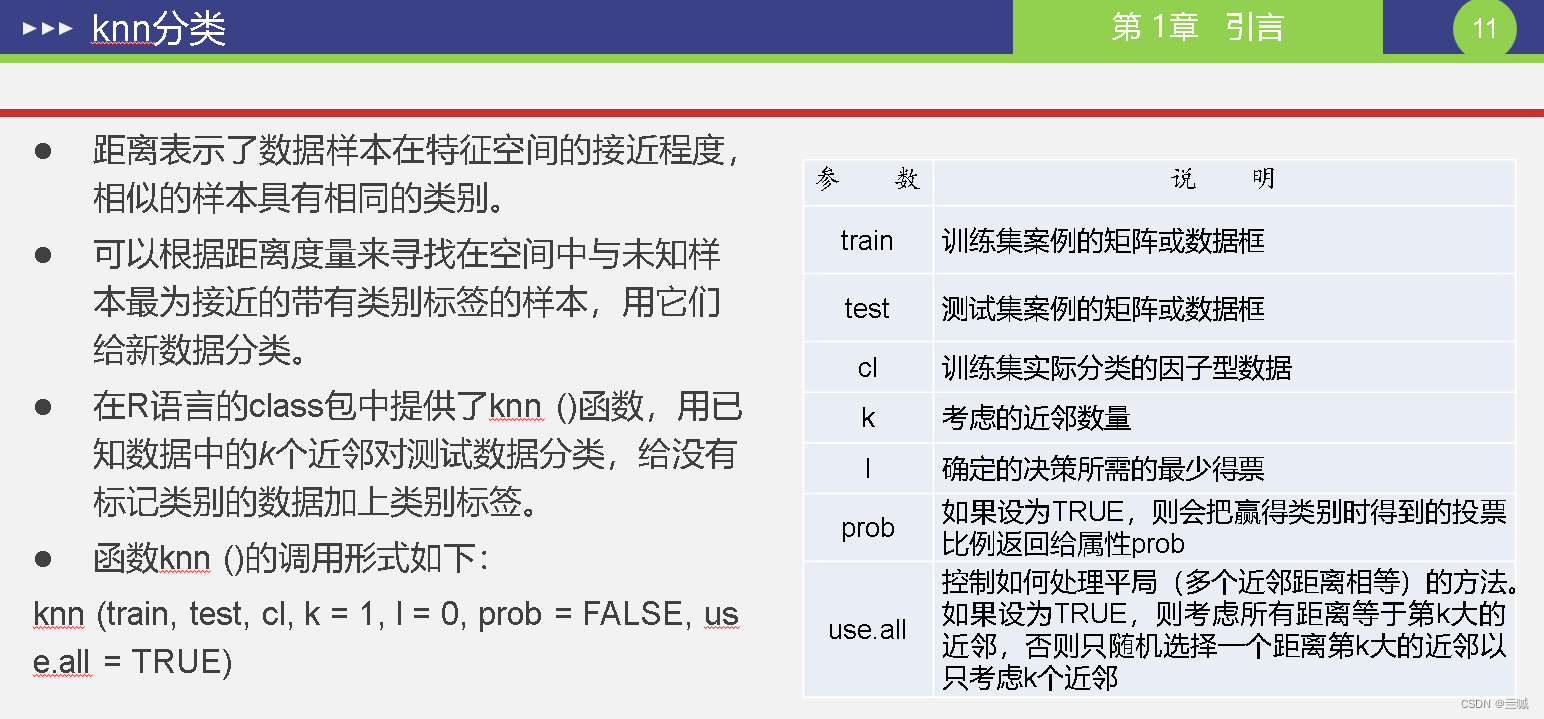







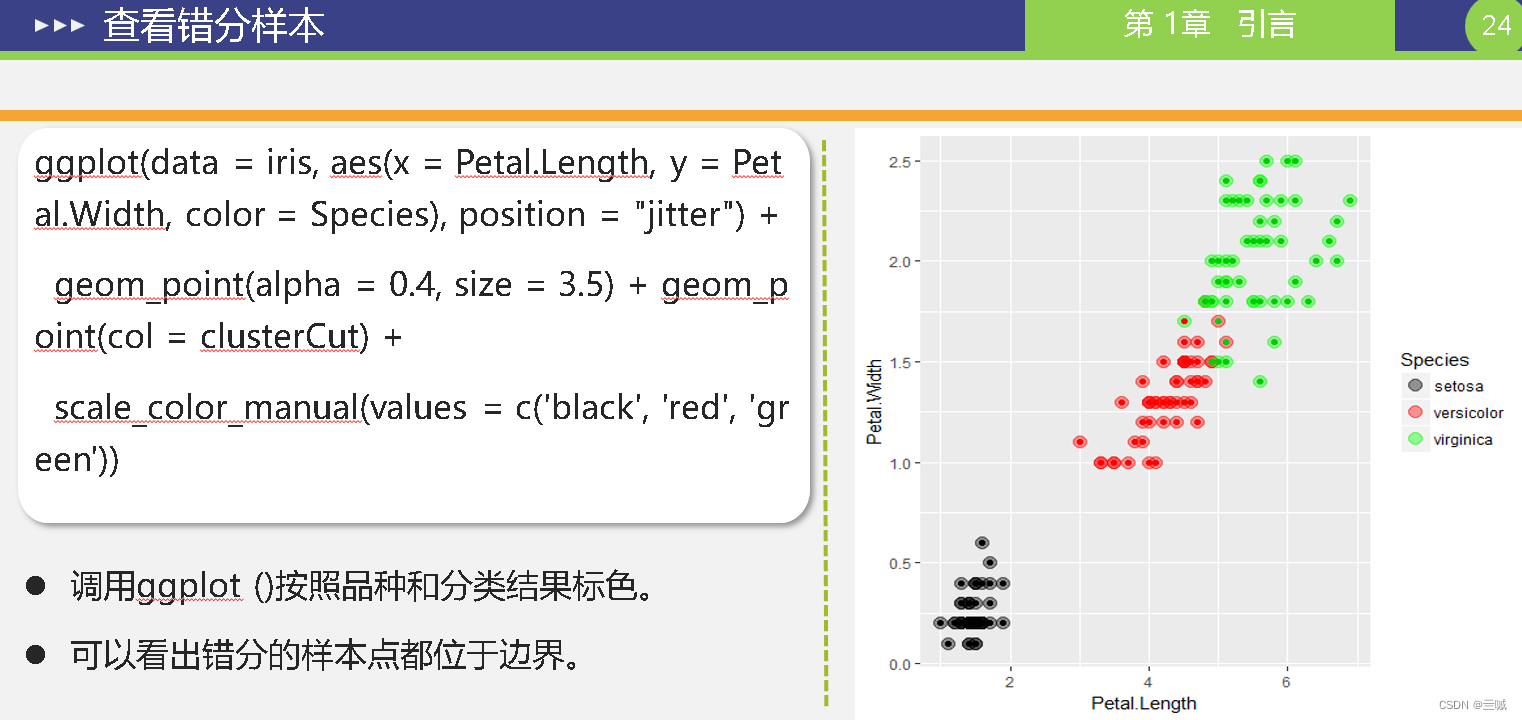
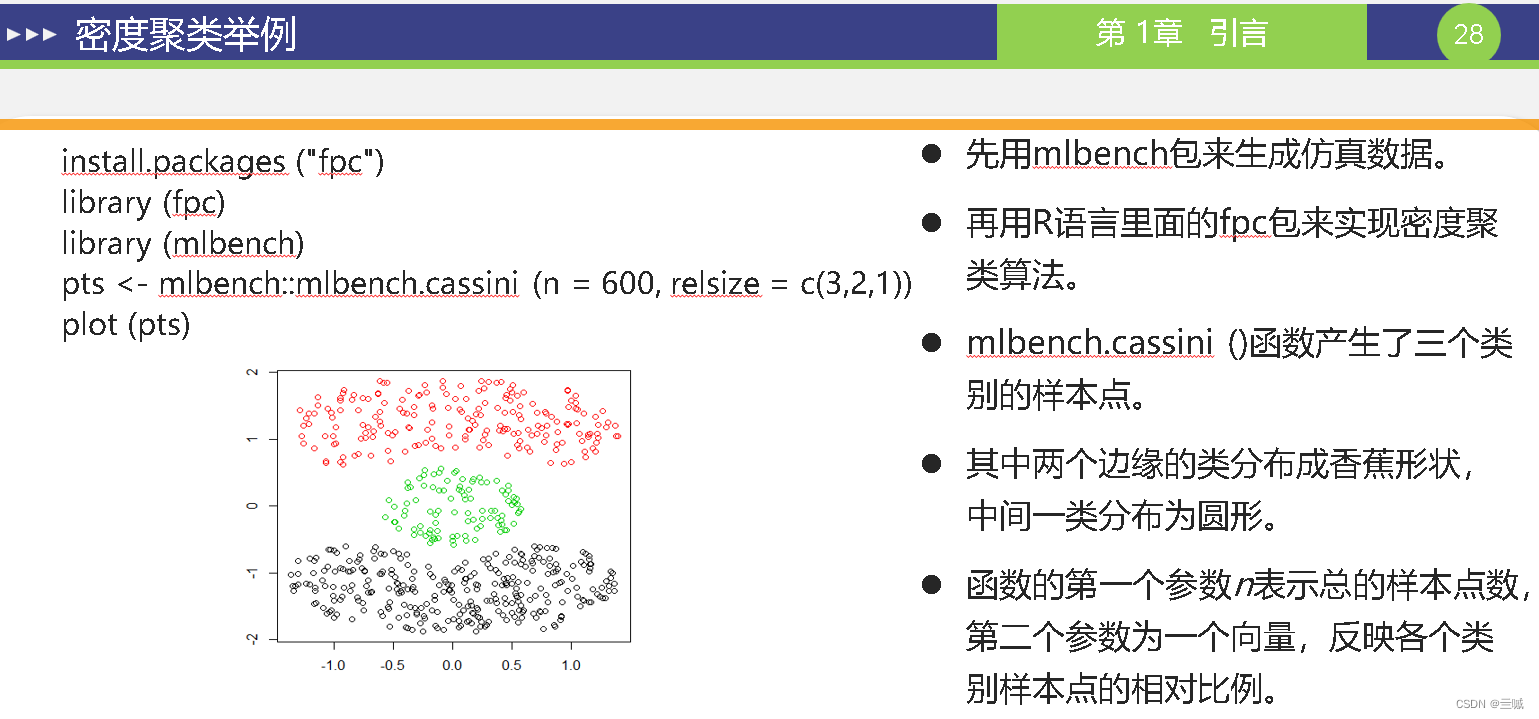
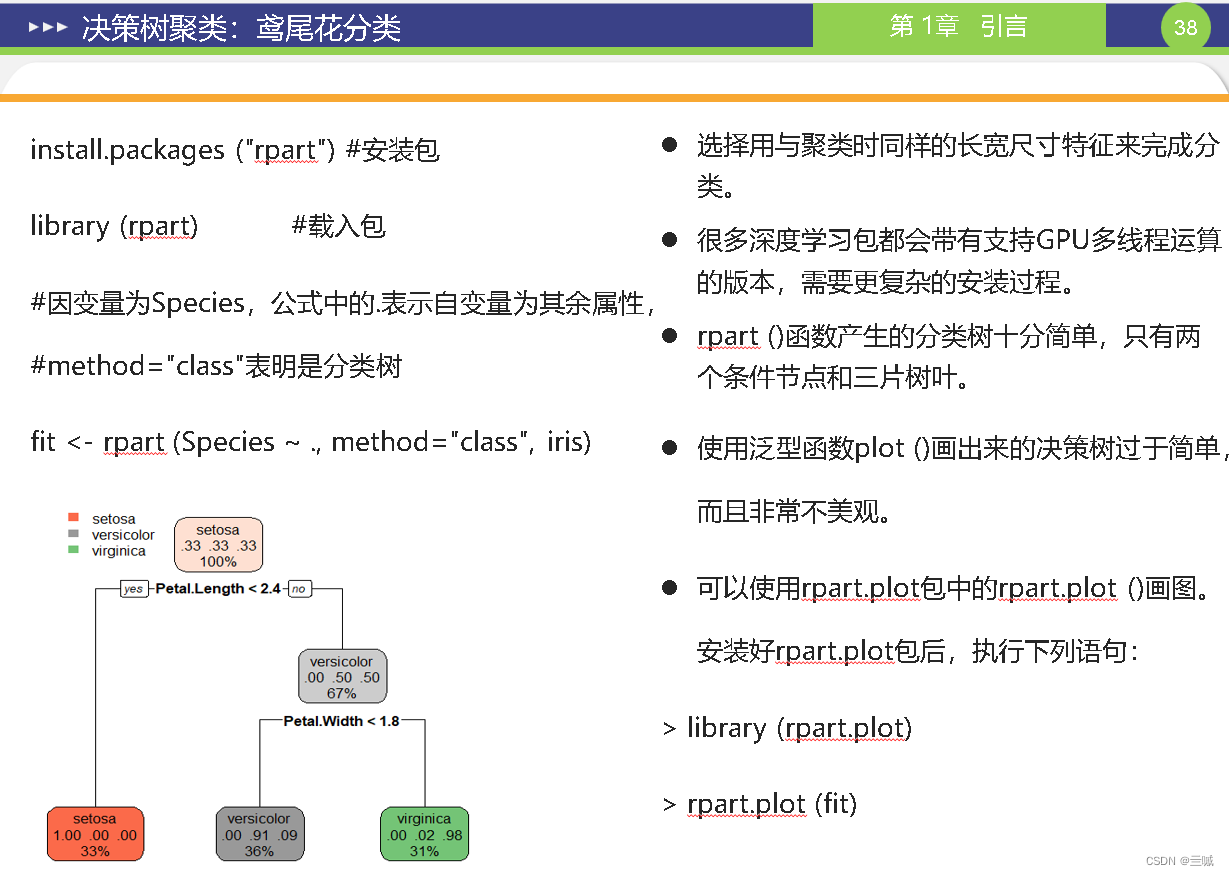

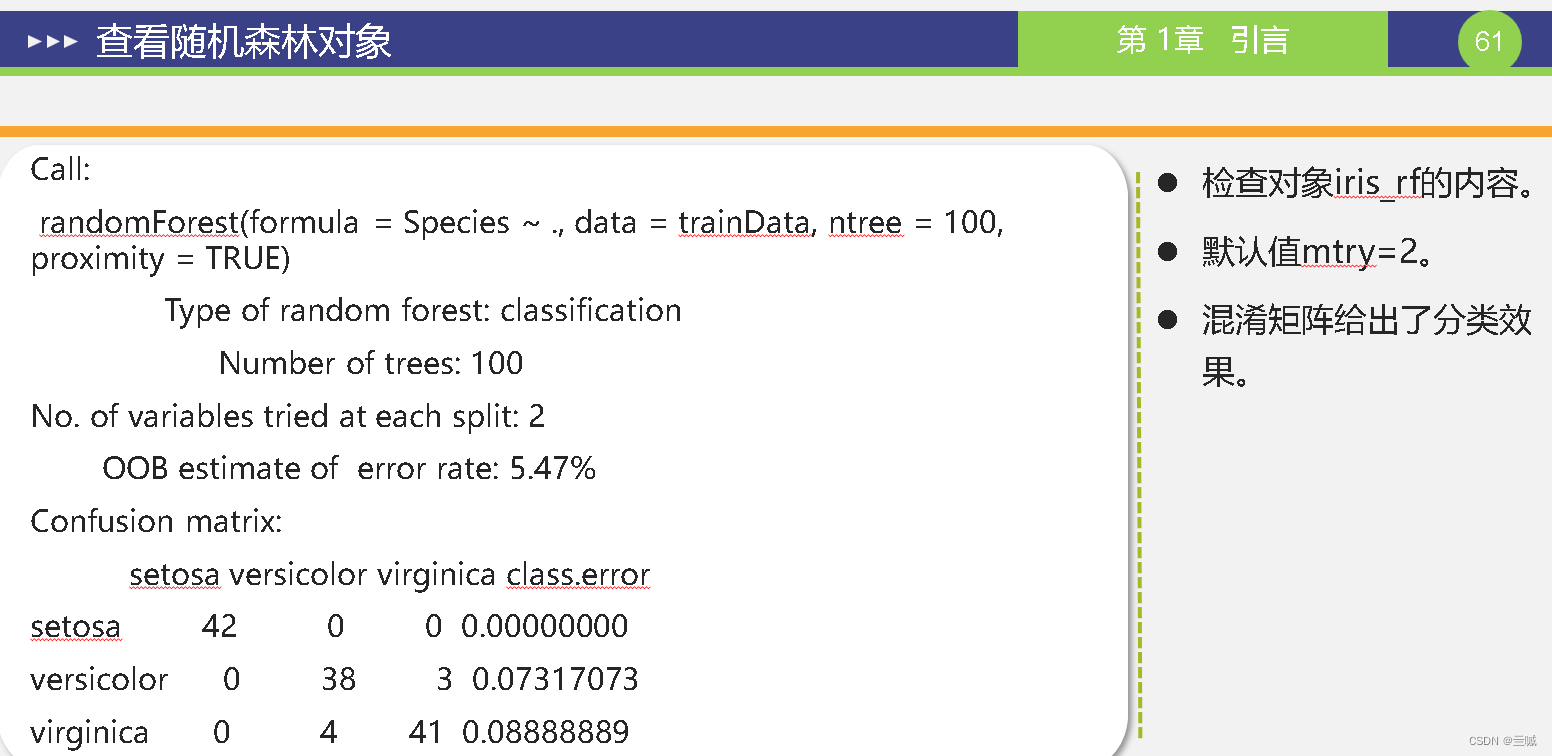
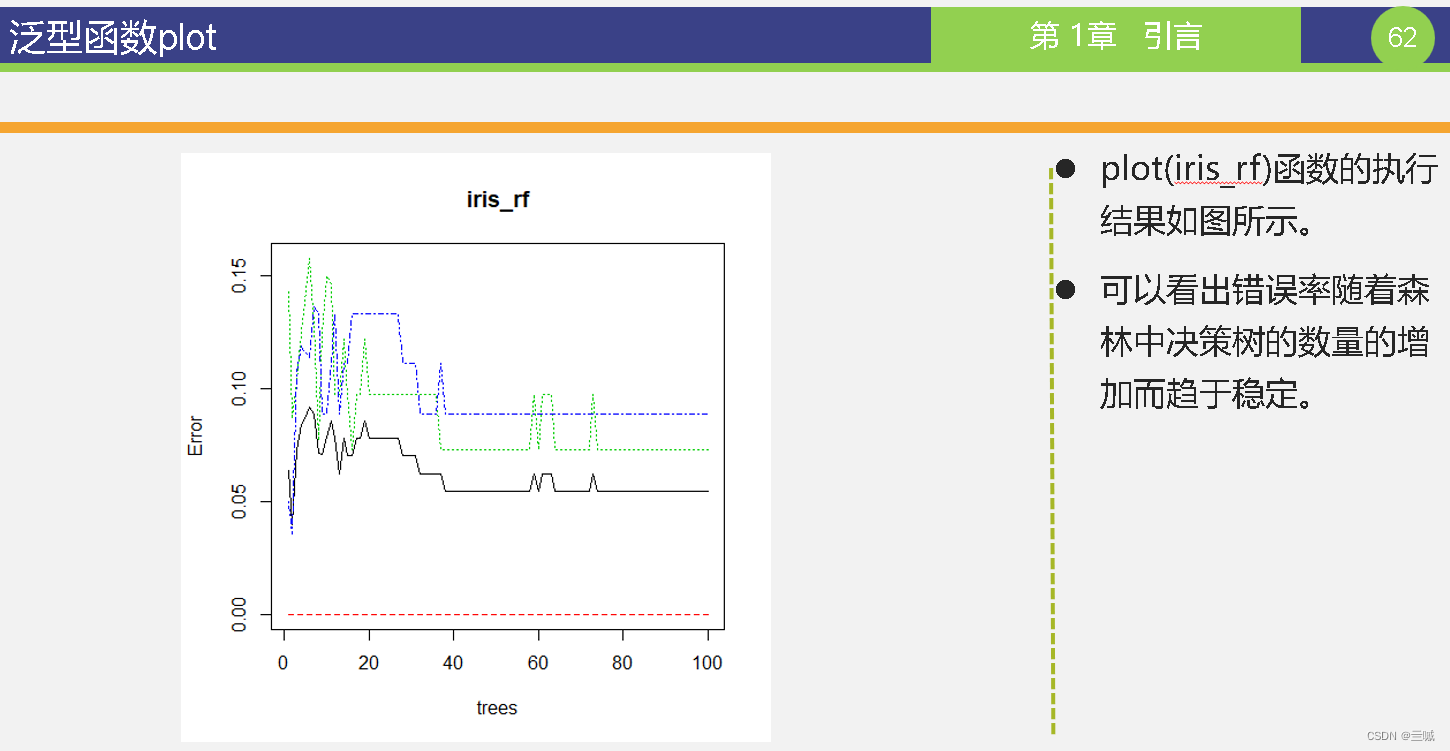



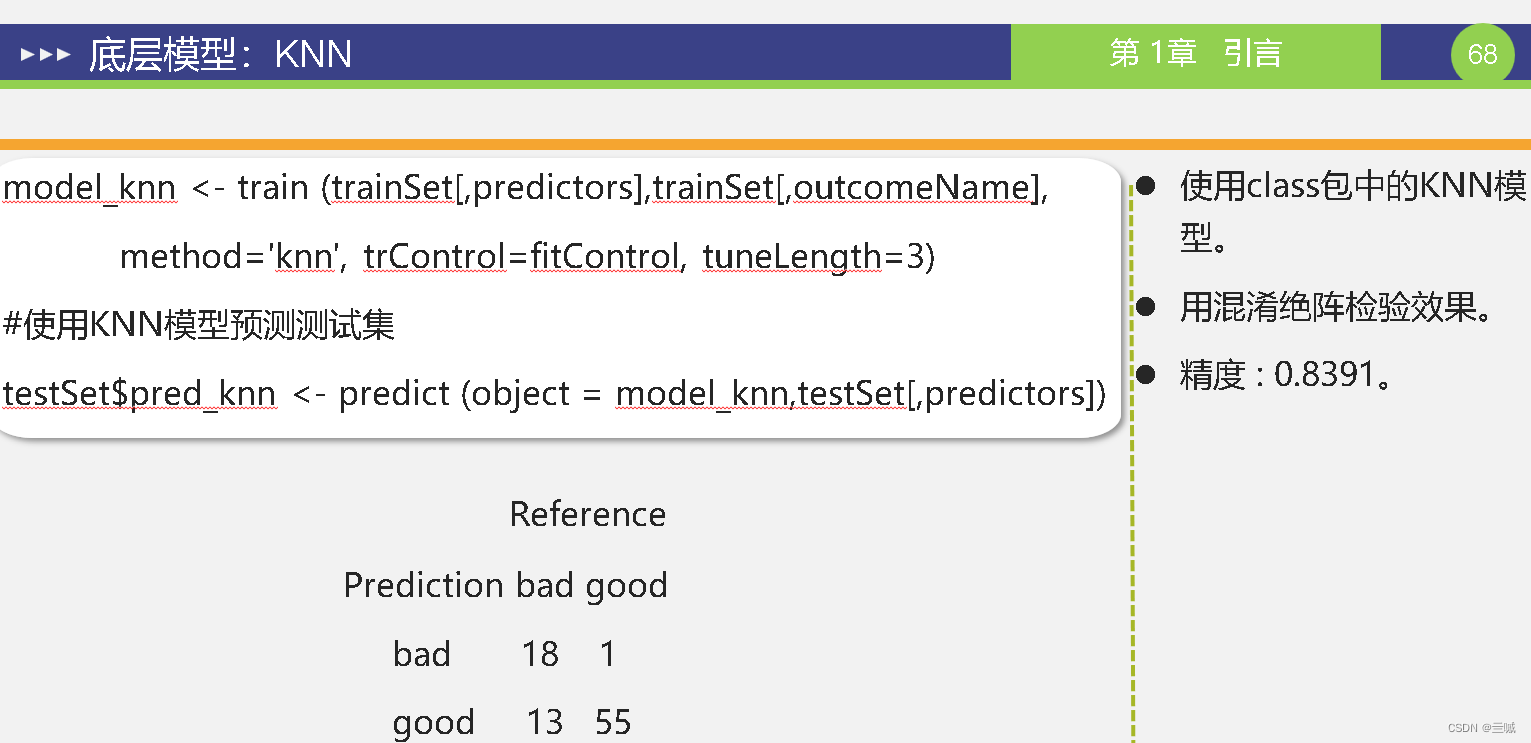
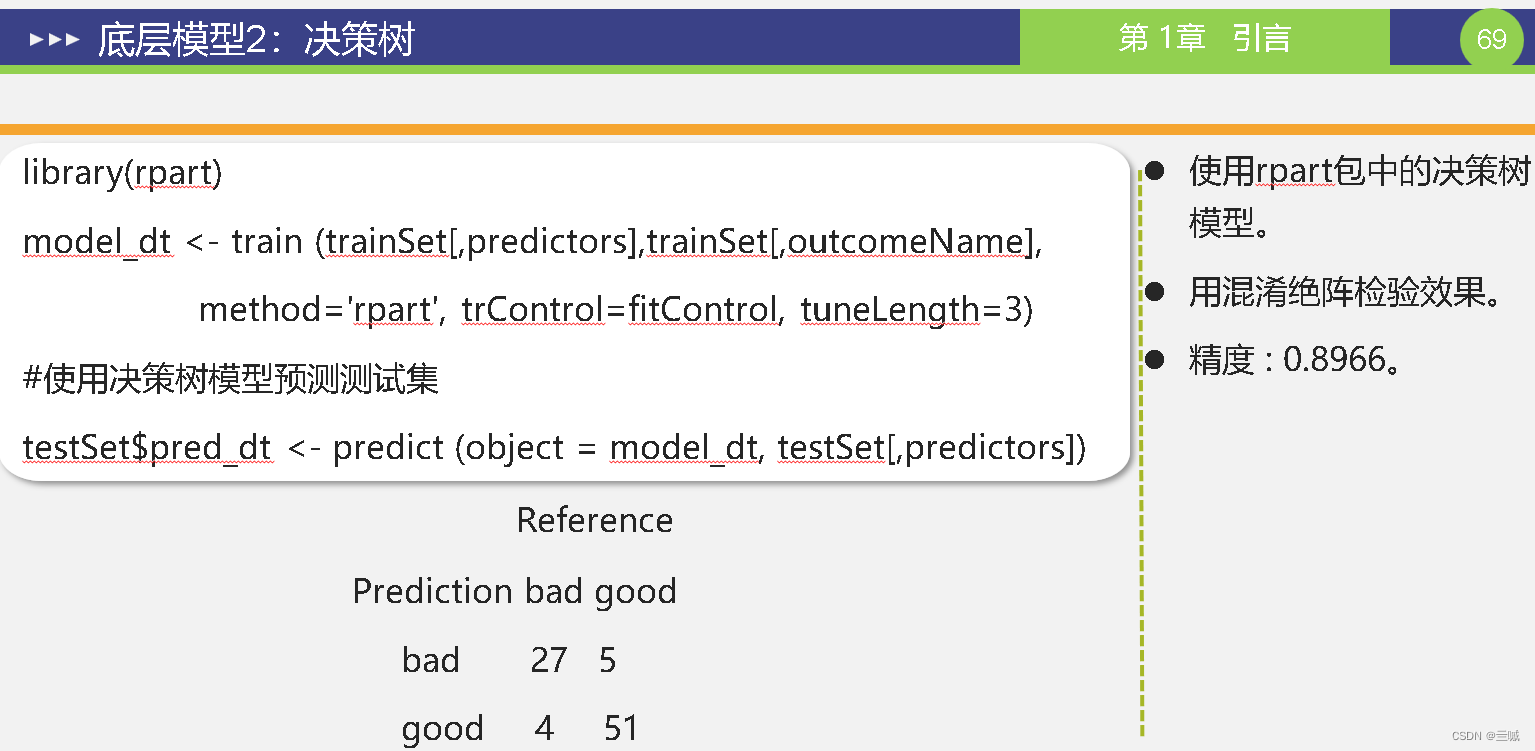



第十章
习题
ROC曲线又称作:敏感曲线
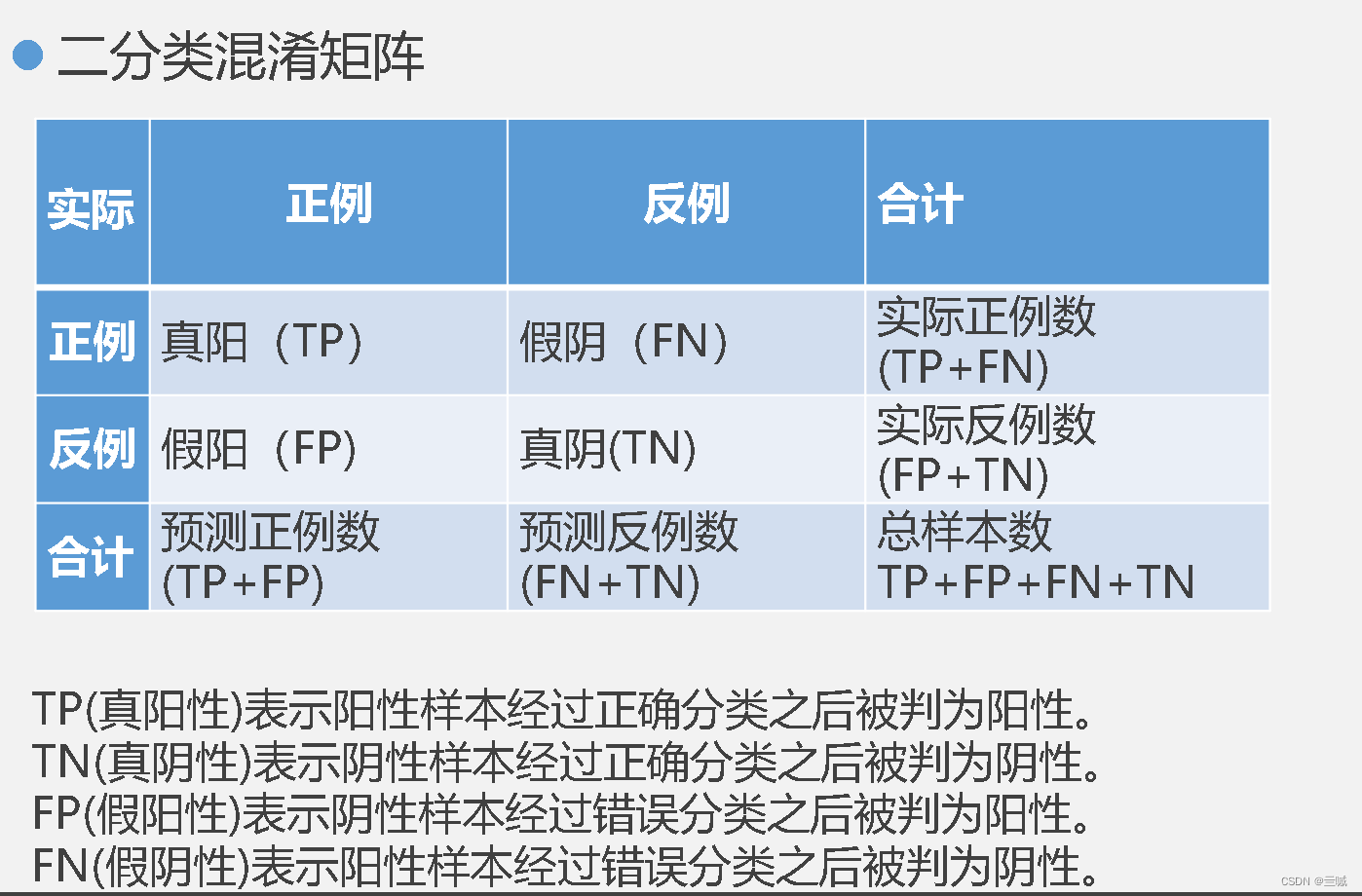
模型评估常用到得方法有:混淆矩阵、风险矩阵、成本曲线、Lift曲线、ROC曲线、精度-召回率曲线等方法。
p-value常用到的标签:显著性水平、原假设、备择假设、单侧检验等。
模型评估的度量参数有:度量,准确率、识别率,错误率、误分类率,敏感度、真正例率、?、特效型、真负例率,精度(precision),F分数,Fb、其中b是非负实数
// 问号处实在是找不到其他的参数
混淆矩阵评价有6个指标分别为:准确度、灵敏度、特异性、错误率、误判率、召回率
分别用公式表达准确度,灵敏度,特异性,错误率,误判率,并解释其含义:



总结
很多PPT我去掉了,因为我觉得不会考所以重点复习有印象和课后题中出现的知识点