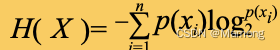本文的主题是多模态融合和图文理解,文中提出了一种名为RegionSpot的新颖区域识别架构,旨在解决计算机视觉中的一个关键问题:理解无约束图像中的各个区域或patch的语义。这在开放世界目标检测等领域是一个具有挑战性的任务。
关于这一块,大家所熟知的大都是基于图像级别的视觉-语言(ViL)模型(如CLIP),以及使用区域标签对的对比模型的训练等方法。然而,这些方法存在一些问题,包括:
计算资源要求高;
容易受到数据噪音的干扰;
对上下文信息的不足;
为了解决这些问题,作者门提出了RegionSpot,其核心思想是将来自局部基础模型的位置感知信息与来自ViL模型的语义信息相结合。这种方法的优势在于能够充分利用预训练的知识,同时最小化训练的开销。此外,文中还介绍了一种轻量级的基于注意力机制的知识集成模块,以优化模型性能。
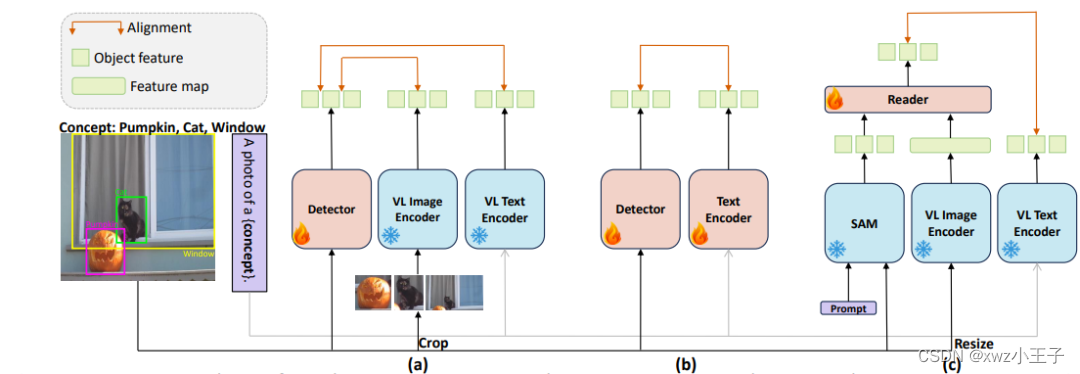
图1展示了区域级视觉理解架构:
(a)表示通过从裁剪区域中提取图像级 ViL 表示并将其合并到检测模型中来学习区域识别模型。
(b)表示使用大量区域标签对数据集完全微调视觉和文本模型。
©表示本文方法,其集成了预训练(冻结)定位和 ViL 模型,强调学习它们的表征相关性。
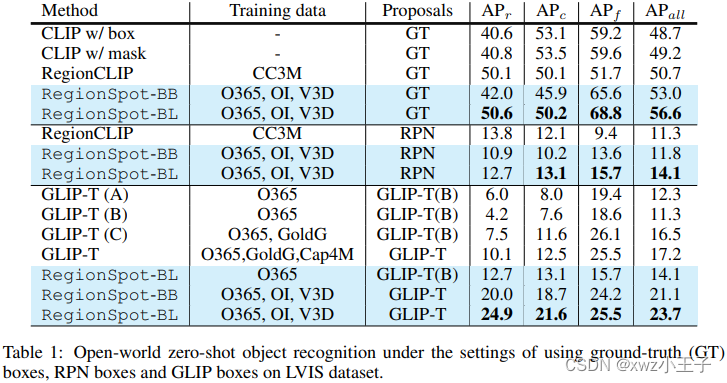
通过在开放世界物体识别的背景下进行的大量实验表明,所提方法相对于以前的方法取得了显著的性能改进,同时节省了大量的计算资源。例如,使用8个V100 GPU,仅在一天内便可对300万数据对进行training。最终,该模型在mAP指标上比GLIP还要高出6.5%,尤其是在更具挑战性和罕见的类别方面,提升高达14.8%!
方法
如上所述,RegionSpot 旨在使用预训练的ViL模型和局部模型来获取区域级别的表示,以实现鲁棒的物体概念化,特别是在开放世界的区域识别中。下面我们为大家详细地介绍下。
预备知识
Vision-language foundation models:这些模型使用对比学习的技术将视觉和文本数据映射到一个共享的嵌入空间,以最小化图像和其文本描述之间的距离,并最大化无关对之间的距离,例如CLIP和ALIGN。
Localization foundation models:这些模型旨在进行图像的局部理解,特别是在目标检测和分割任务中。比如Meta开源的SAM模型,它是一个里程碑式的工作,已经在大规模数据集上进行了训练,包括超过10亿自动生成的掩模,以及1100万张图像。
使用冻结基础模型的区域文本对齐
这一部分我们重点关注下如何获取位置感知标记和图像级语义特征,并通过交叉注意力机制进行区域文本对齐。
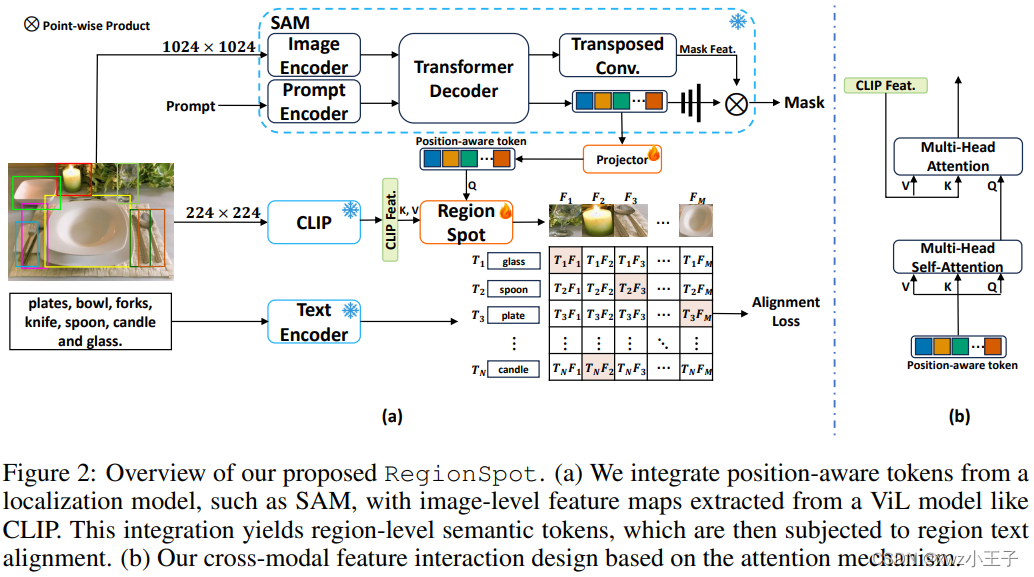
区域级别的位置感知标记:作者使用手动标注的目标边界框来表示图像的兴趣区域。对于这些区域,文中是使用SAM模型来提取位置感知标记。这些标记通过一个Transformer解码器生成,这个过程有点像DETR的架构,生成一个称为“位置感知”的标记,它包含了有关目标的重要信息,包括其纹理和位置。
图像级语义特征图:一幅图像可以包含多个对象和多个类别,捕捉了综合的上下文信息。为了充分利用 ViL 模型,作者将输入图像调整到所需的尺寸,然后输入到 ViL 模型中,获得图像级语义特征图。
关联位置感知标记和语义特征图:RegionSpot 中使用了交叉注意力机制来建立区域级别的位置感知标记和图像级语义特征图之间的联系。在这个机制中,位置感知标记充当查询,而语义特征图充当键和值。这种关系可以通过公式表示:
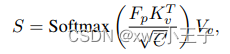
其中 是得分, 是位置感知标记的转换, 和 是来自 的线性投影, 则是投影特征维度。其实就是常规的 QKV 操作,可以有效地实现信息融合,至于融合的 gap 可能只有上帝知道。
损失函数:最后便是生成文本嵌入,通过处理类别特定的文本和提示模板,例如场景中类别的照片,使用文本编码器。然后,执行每个语义标记和其相应文本特征的点积操作,以计算匹配分数。这些分数可以使用Focal loss进行监督。
整体来说,方法部分的核心便是如何从两个不同的基础模型中提取信息,并通过交叉注意力机制实现区域文本对齐,以获得区域级别的语义表示。通过下面的实验部分我们可以直观感受到该方法在解决开放世界的物体识别问题中表现出色,其提供了丰富的细节来支持RegionSpot。
实验
训练数据
RegionSpot 模型采用了多个包含不同类别标签的数据集,以构建强大的训练环境。这种灵活的架构允许我们将独热标签(one-hot labels)替换为类别名称字符串。其中,作者提到了使用了公开可用的检测数据集,总共包括大约300万张图像。这些数据集包括 Objects 365 (O365)、OpenImages (OI) 和 V3Det (V3D)。
Objects 365:大规模的目标检测数据集,包含了365个不同的对象类别,总共有约66万张图像。文中是使用一个经过优化的版本,其中包含超过1000万个边界框,每张图像平均约15.8个注释。
OpenImages:这是目前最大的公共对象检测数据集,包括约1460万个边界框注释,每张图像平均约8个注释。
V3Det:这个数据集通过详细的组织,在类别树中构建了多达13,029个类别。

基线设置
Benchmark 使用了LVIS检测数据集,该数据集包含1203个类别和19809张图像用于验证。作者强调不仅仅优化在COCO数据集上表现的性能,因为COCO只包括Objects365训练数据集中的80个常见类别,这不能充分评估模型在开放世界环境中的泛化能力。
实现细节
优化器: AdamW,初始学习率为2.5 x 10^-5
硬件资源:8个GPU上,batchsize 设置为 16
超参数:450,000 iters,学习率在350,000次和420,000次迭代时除以10
训练策略:
第一阶段是利用Objects365来启动区域-词对齐的学习;
第二阶段是高级学习,使用来自三个不同的对象检测数据集的丰富信息来进行区域-词对齐的学习。
效果

可以看出,相对于 GLIP,RegionSpot 的区域级语义理解能力更强。
总结
简单来说,今天介绍的这篇文章主要贡献是提出了一种有效的多模态融合方法,用于改进图像中区域的语义理解,具有潜在的广泛应用前景。文中提出了将预训练的ViL模型与局部模型相结合的 RegionSpot 架构,以改进区域级别的视觉理解。RegionSpot 的方法旨在优化效率和数据利用方面具有卓越性,避免了从头开始训练的必要。通过大量实验证明,RegionSpot 在开放世界物体理解领域的性能明显优于 GLIP 等现有方法。