这个题目启的很大,但其实只是最近在复习MySQL知识的一点心得,比较零散。
更新数据时,底层page的变化
下面这个图,我还需要解释么?
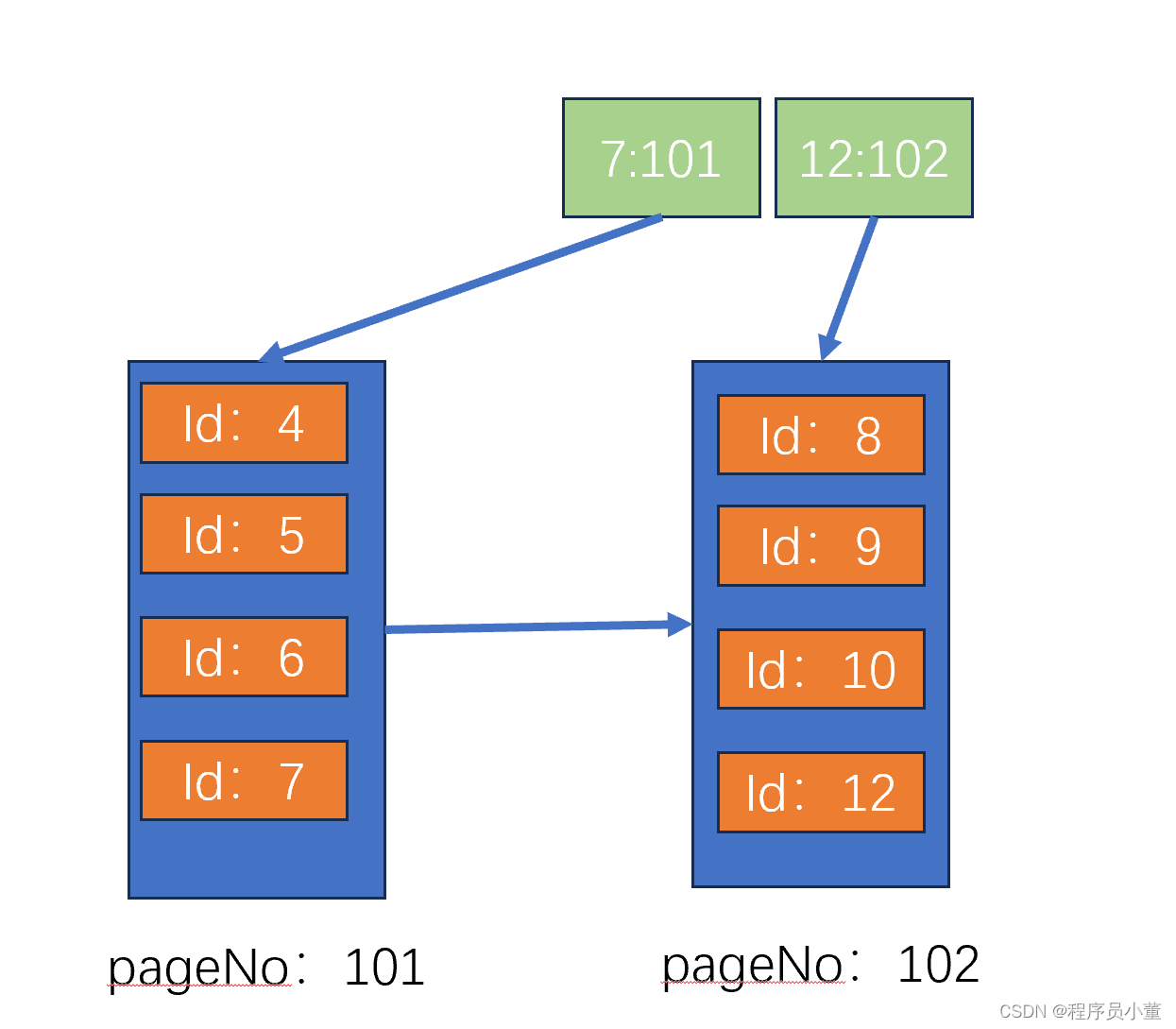
上面的绿色是b+数的索引块,分别说明了101号page的最大id是7,102号page的最大id是12
底下的蓝色块是b+数的叶子节点,使用聚簇索引的组织形式。在每个page里面以记录的id为序顺序存储了记录的所有数据。
那我现在问一个问题,假如我现在更新id为6的记录的某个字段,之后b+数是什么样子。
好了别猜了,更新后的数据图如下:
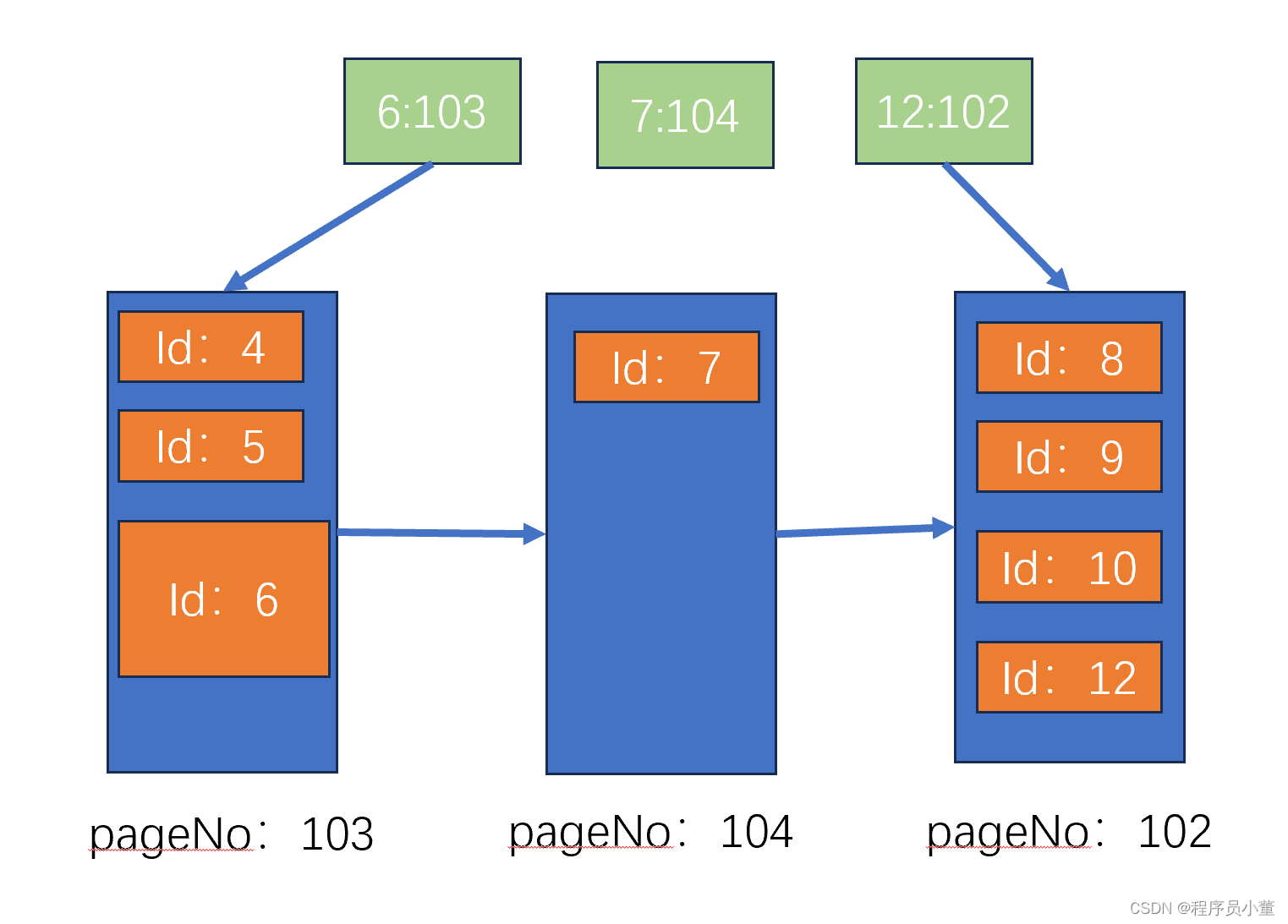
如上图,我们假定id6的记录更新后,数据记录膨胀了,那mysql就会把原来的pageNo101的数据都读出来,更新完之后,重新申请新的page,然后再写入。
假如记录缩短了,还需要重新申请一个新的page在写入么?还是说直接原地更新?
答案是原地更新。
还有一个问题,假定我先给某个page里面写了id为1和5的数据,然后又写了id为3的数据(暂时不要管为什么id乱序了)那么page里面的数据会怎么变呢?换句话说在一个page内部记录是使用顺序存储还是链式存储呢?
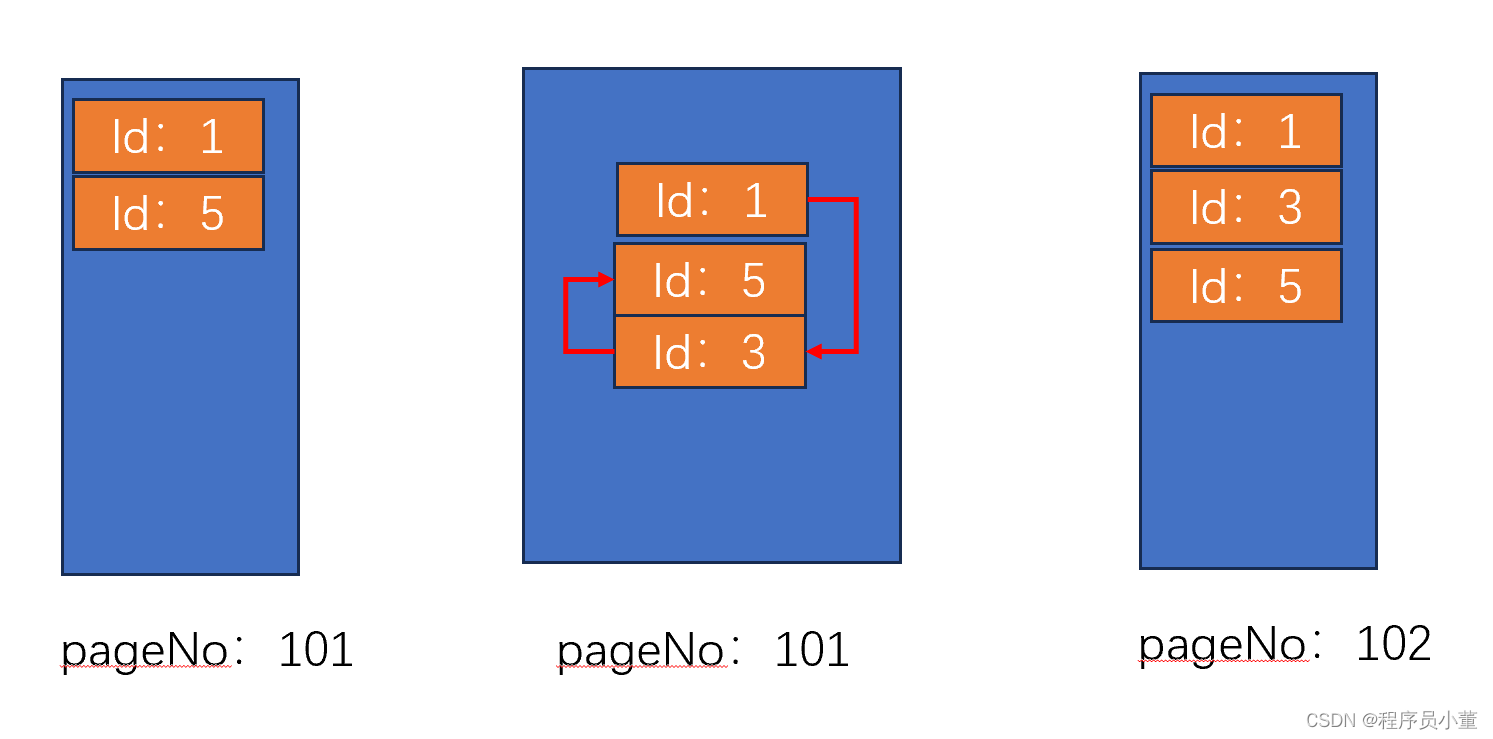
其实就是上面的图,新加入的3是跟在5后面写入然后使用链表维护先后关系(上图中间的示意),还是整体先把101page读到内存,加入id为3的数据后,进行排序然后再整体写入新的page呢(上图右边的示意,也就是说page内部是绝对的顺序存储)?
答案是上图右边的示意,也就是说整体先读入内存,然后内存整理好了之后,再顺序写入磁盘(当然此时也有可能没有申请新的page,直接写到原来的page101也是有可能的)
有朋友说,那上面的写放大岂不是很大?
理论上是的。但是其实不是问题,为什么?原因见后面的随机写入一节。
另外,就上面那个图,page104里面空了很大空间怎么办?
mysql后面肯定会进行page整理的,如果相邻的两个块里有效数据变短了(包括update甚至直接delete),那mysql自然就会merge两个page为一个新的page。
分表后的主键策略
我们知道,InnoDB为每个表构建索引的时候,是使用表的主键来做索引的。一般情况我们都会为表指定一个不会出现重复数据的字段为主键。当然即使你不指定,系统也会为你默认来一个。
ok,在一个物理表表内部,我们大家都是默认存在一个唯一的主键。
那么假定数据急剧膨胀,我把一个逻辑表拆分成了1024个物理子表。那么这个时候,表1和表2的主键可以重叠么?
我个人认为可以重叠也可以不重叠。(当然在某个具体的物理子表内部,主键肯定是不能重复的)
-
为什么说可以重叠呢?
因为从mysql的角度来讲,那两个物理子表是没有任何关系,两个表的b+索引也是没有任何关系的,mysql并没有强制要求两个表的主键一定不能重叠。
那既然没有禁止重叠,那我自然就可以重叠么。 -
另一种说法是尽量不要重叠。
为啥?因为这样业务更方便处理。
其实多个表不重叠,从业务层来说自然是更好的,但是为了保证全局不重复,还是需要一些额外的技术方案的。例如淘宝的tddl-sequence或者SnowFlake雪花算法等等。
随机写入(更新的写放大问题)
在上面那一节说的,假定我要求业务的各个分表的主键不能重复,也就是我需要全局唯一,那每个表的主键就不能设置成自增,那每次insert的时候,id我就得指定。
假如我使用tddl-sequence的方案,一共有5个应用服务器。服务器A使用0-99号段,服务B使用100-199号段。。。。
假定5个应用服务器此时收到的请求,最终数据都落到了相同的某一个物理表上。
那再负载均衡的情况下,那个表收到的id 就有可能是0,100,200,300,400,1,101,201,301,401。。。。
那大家想想,底层的叶子节点的数据岂不是要一直变动。
其实上面的前置条件就构造的很没有必要,用户对表的update本身就是完全无序的。用户就是完全无顺序的更新任意的数据,那写放大怎么办?
我上面的各种读写例子都是完全基于磁盘的,但是我问大家一个例子。难道mysql是每收到一个请求都需要数据立刻落盘然后再返回给用户结果么?这个延迟大家有想过么?
答案是不言而喻的,数据肯定是先在内存里然后才写到磁盘的。
这个内存的大于,就是mysql的bufferPoolSize 那这个值一般会设置多少呢?
对于真实的db服务器(也就是说这个机器上,只有mysql,不再部署别的应用服务),我查询到的bufferpool一般是物理机内存的60%-80%。
知道了有这么大的bufferpool,那你还担心什么。以上面的例子为准,虽然mysql收到的请求0,100,200,300,400,1,101,201,301,401。。。 但是最终写入的时候 相邻的数据量早都凑够了一个page的大小了。
看看下面几个命令
show variables like 'innodb_buffer_pool_size';
show variables like 'Innodb_buffer_pool_pages_data';
show variables like 'Innodb_buffer_pool_pages_total';
这些参数的意义如下:
Innodb_buffer_pool_pages_data:缓存池中包含数据的页的数目,包括脏页。单位是page。
Innodb_buffer_pool_pages_dirty:缓存池中脏页的数目。单位是page。
Innodb_buffer_pool_pages_flushed:缓存池中刷新页请求的数目。单位是page。
Innodb_buffer_pool_pages_free:剩余的页数目。单位是page。
Innodb_buffer_pool_pages_misc:缓存池中当前已经被用作管理用途或hash index而不能用作为普通数据页的数目。单位是page。
Innodb_buffer_pool_pages_total:缓冲池的页总数目。单位是page。
我自己机子上的mysql配置如下:BufferPool 是默认的128MB
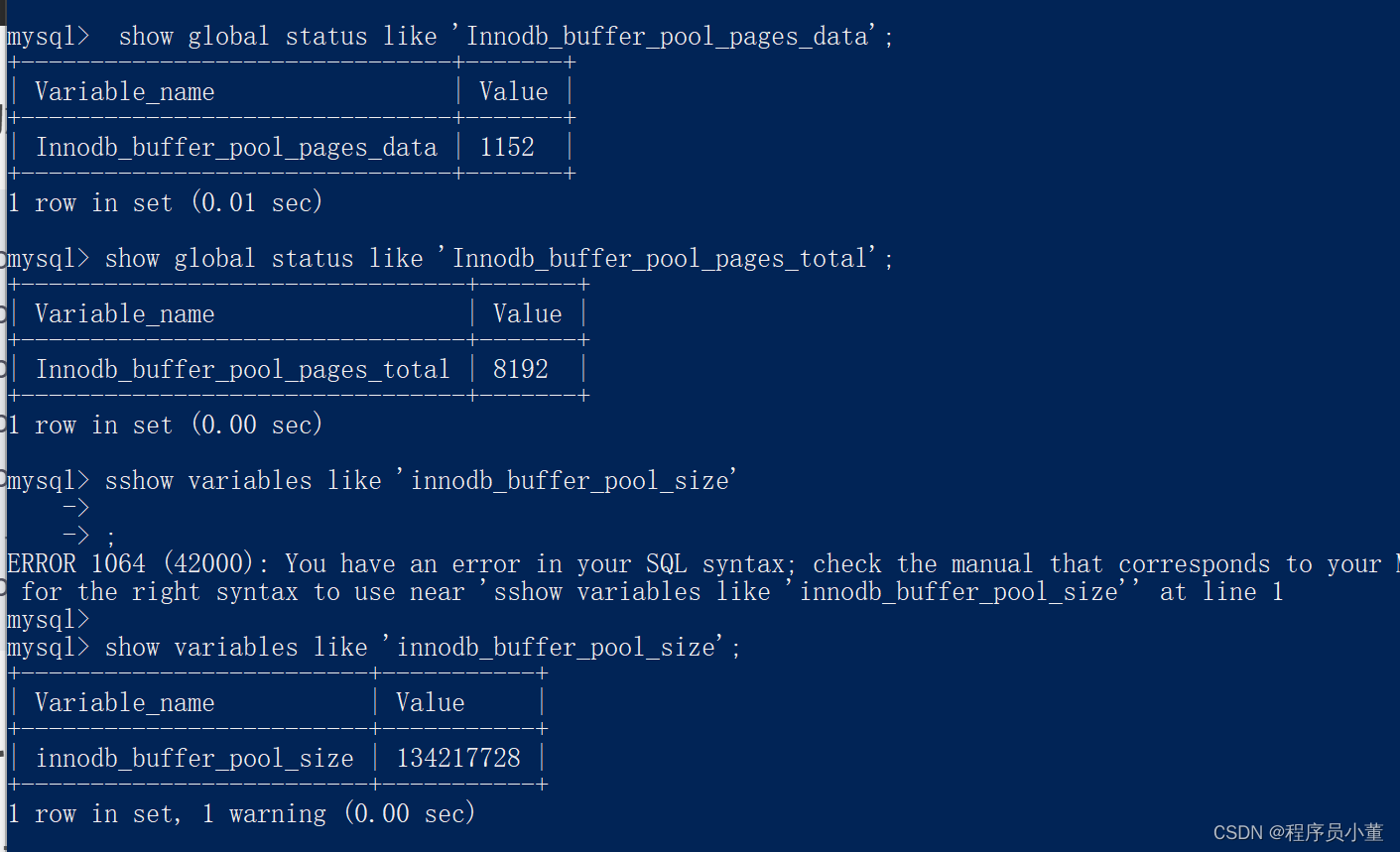
咱们看看一共8192个page,使用了1152个page 使用率14%,嗯bufferpoolsize还是够的。
另外 总共128MB的size,单个page16KB,那算下来一共也就是8192个page,嗯数据是能对得上的。
参考资料
https://blog.csdn.net/qq_41044636/article/details/123483334
https://blog.csdn.net/wzngzaixiaomantou/article/details/121064577
https://blog.csdn.net/wangqinyi574110/article/details/131984748