java基本数据类型及对应的字节数?什么是自动拆装箱?int与integer的区别?项目中如何使用?
1.java基本数据类型及对应的字节数?
java总共有8中基本数据类型,整型4种,浮点型2种,字符类型1种,布尔类型1种。
整型为:byte 占1个字节,short 占2个字节,int 占4个字节,long 占8个字节。java中整型默认为int类型
浮点型为:float 占4个字节,double 占8个字节。java中浮点型默认为double类型
字符型为:char 占2个字节。
布尔型为:boolean 不确定,与JVM有关.通常认为占用1个字节(也有可能占4个字节)
2.什么是自动拆装箱?
概念:自动拆装箱是JDK1.5之后的功能。自动装箱:将基本数据类型自动转换为对应的包装类型。比如将int转换为Integer.自动拆箱:将包装类型,自动转换为对应的基本数据类型。比如Integer转换为int,可以通过ValueOf方法进行转换。
个人理解:要说到自动拆装箱就需要题到包装类,java是面向对象编程,包装的存在使我们的代码更加面向对象编程。自动拆装箱的功能,使我们的程序也变得整洁,比如集合中只能存储对象类型,但是有了自动拆装箱,就可以直接存储基本数据类型。
3.int与integer的区别?项目中如何使用?
理解:Integer 是 int 的包装类,它们的区别主要体现在 5 个方面:数据类型不同、默认值不同、内存中存储的方式不同、实例化方式不同以及变量的比较方式不同。包装类的存在解决了基本数据类型无法做到的事情泛型类型参数、序列化、类型转换、高频区间数据缓存等问题。
项目中的使用:项目中一般会分情况使用,比如在定义数据实体,业务实体对象的时候,就会使用Integer类型。在一些代码中,一些局部变量的定义,一般会使用int类型。
4.Long & Integer 在什么范围有缓存功能?
答案:-128 到 127 期间
string,stringBuffer,stringBuilder的区别?
string,stringBuffer,stringBuilder的区别?
概念:
- String的内容不可修改,StringBuffer与StringBuilder的内容可以修改。
- StringBuffer与StringBuilder大部分功能是相似的 。
- StringBuffer采用同步处理,属于线程安全操作;而StringBuilder未采用同步处理,属于线程不安全操作。
性能方面:
大量字符操作的性能比较:
StringBuilder > StringBuffer > String
工作中的使用:
在工作中经常使用的是String,StringBuffer与StringBuilder基本上很少用到,因为没有大量的字符串拼接的业务场景。String都是用于保存数据,展示数据,也不存在线程安全的问题,故在我过往的项目中基本都是使用String
==与equals的区别?
==与equals的区别?
我的理解是这样:==号比较的是栈里面的值(基本数据类型比较的是值,引用类型比较的是地址值),可以用于基本类型比较与引用类型比较
equals用于引用类型比较,在没有重写equals方法的情况下,比较的是地址值,重写equals的情况下,按照重写的规则进行比较,一般用于比较内容。
ArrayList与linkedList的区别?List与Set的区别?
ArrayList与linkedList的区别?
我首先说一下它们两者的相同点:
都是List接口的实现类,都可以用于保存引用数据,都是非线程安全的
其次,在说一下他们之间的不同点
结构方面:
数据结构不同,ArrayList底层采用的数组结构,LinkedList采用的是双向链表结构
执行效率:
查询,修改:ArrayList要优于LinkedList
增加(插入),删除:ArrayList与LinkedList 有一个数据迁移的时间 VS 数据查询的时间
List与Set的区别?
概述:
List与Set都是Collection接口的子接口,都属于单列集合。
List中最常用的实现类有:ArrayList与LinkedList
Set中最常用的实现类由:HashSet(底层采用的是HashMap的key部分)
特点:
List:元素存储有序,具有索引,可以通过索引快速定位元素,可以存储重复的元素
Set:元素存储可以有序,可以无序(要看选择的具体子类 HashSet 无序 LinkedHashSet(有序),TreeSet(排序)),没有索引,不能通过索引获取元素(即也不能使用普通for循环遍历),不可以存储重复的元素
项目中的使用:
在项目中大部分的场景使用的都是List,在一些需要去重的场景可以使用Set,比如在RBAC权限模型中,查询用户具备的权限的时候,就推荐使用Set
hashSet集合无序不重复的原理?(hashMap的put操作做了什么?)
hashSet集合无序不重复的原理?(hashMap的put操作做了什么?)
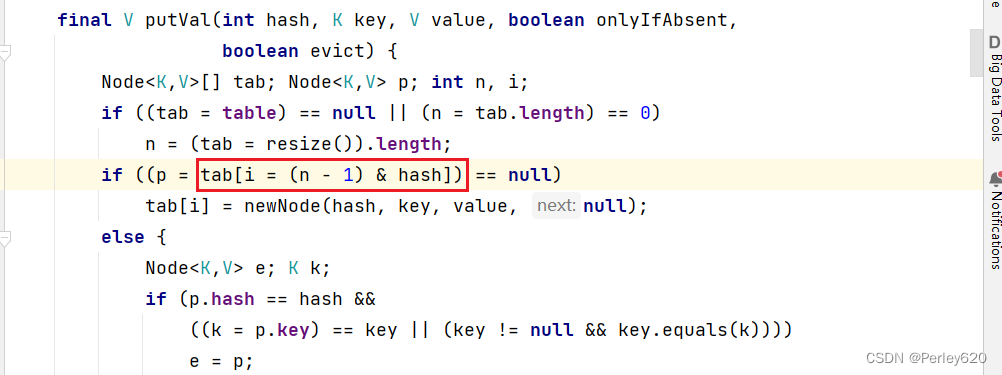
hashMap的put操作时,有以下几步:
1.根据key的hashcode()计算key的hash值,将 hash值& (数组的长度-1) 确定hash表的位置。
2. 判断该位置是否有值,如果没有值,则创建一个节点,将该节点保存到该位置(此处可能出现并发问题)
3. 如果该位置有值,则进行hash,==,equals判断,判断key是否重复,如果不重复,则添加到该链表中
4. 如果当链表中元素的个数达到8,同时数组中的个数超过64时,就会进化成红黑树(进一步提高查询效率)