一、说明
近年来,随着 Transformer 的引入,语言模型发生了显着的演变,它彻底改变了我们执行日常任务的方式,例如编写电子邮件、创建文档、搜索网络甚至编码方式。随着研究人员在代码智能任务中应用大型语言模型,神经代码智能的新领域已经出现。该领域旨在通过解决代码摘要、生成和翻译等任务来提高编程效率并最大限度地减少软件行业中的人为错误。
随着 Code Llama 的最新版本(Meta AI 用于代码生成和理解的最先进模型),本文回顾了代码大型语言模型 (LLM) 从 RNN 到 Transformer 的演变。
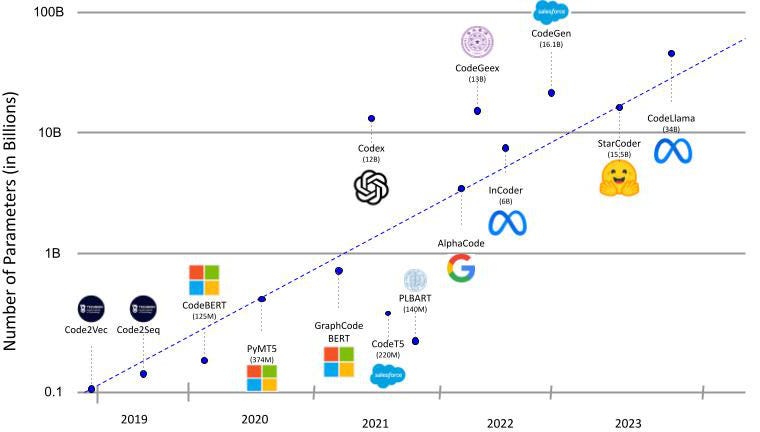
图 1:大型代码语言模型的时间表。图片由作者提供。
二、代码2Vec,2018
这是语言模型理解代码的首次尝试之一。Code2Vec旨在将代码片段表示为嵌入。这些嵌入从代码中捕获语义和结构信息,使其可用于各种软件工程任务,例如代码分类、检索和理解。
模型尝试通过对命名良好的标记和 AST(抽象语法树)路径进行编码,并应用神经注意力来聚合成固定长度的向量表示,从而从代码片段中预测方法名称。

图 2:Code2Vec 模型架构:程序首先分解为包含 token 和 AST 路径的上下文袋,然后通过全连接层和注意力层生成代码向量。图像灵感来自 Uri Alon 等人的原始论文。来自Code2Vec的 al
训练集: 14M Java 程序示例
模型架构:RNN + 前馈网络
新颖性:
- 基于路径的注意力模型- 作者提出了一种新颖的神经网络架构,该架构使用代码片段的抽象语法树(AST)中的语法路径作为输入特征。该模型学习为每条路径分配不同的注意力权重,并将它们聚合成单个代码向量。然后,代码向量可用于预测片段的标签分布,或测量片段之间的相似性和类比。
您可以在这里使用模型
三、代码BERT,2020
CodeBERT由微软研究团队开发,通过在基于 Transformer 的BERT 模型上引入多模态数据预训练、结合自然语言和编程语言 (NL + PL),代表了代码大型语言模型 (LLM) 领域的重大进步。该模型在包含双峰数据点对和单峰数据点的多样化数据集上进行训练,用于掩码语言建模 (MLM)和替换令牌检测 (RTD)任务。CodeBERT 在多个领域展示了卓越的性能,尤其是在自然语言代码搜索和代码到文档生成方面表现出色。
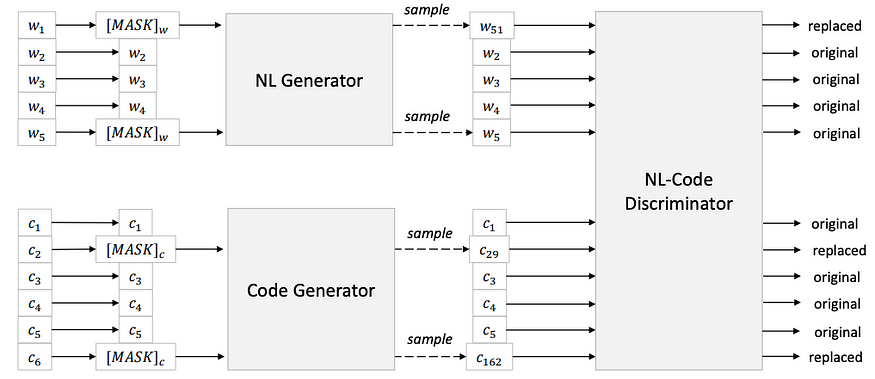
图 3:使用替换令牌检测 (RTD) 任务的 CodeBERT 模型预训练。自然语言生成和代码生成器用不同的标记替换标记,并且训练 CodeBERT 模型以将每个标记分类为替换的或原始的。图片来自 Feng 等人。等人,代码BERT
训练数据集:
Codesearch Net 数据集- 2.1M 双峰数据点 (NL + PL)、6.4M 单峰数据点(6 种语言 — Python、Java、Javascript、PHP、Ruby、Go) 参数大小:125M 模型架构
: RoBERTa
- base
Novelty :
- 双模态训练:CodeBERT 引入了一种创新的训练方法,其中包含自然语言和编程语言标记。这种双模态训练技术通过考虑人类可读的描述和编程语言元素之间复杂的相互作用,增强了模型理解和生成代码的能力。
- 代码的替换标记检测 (RTD) 任务:CodeBERT 预训练使用替换标记检测 (RTD) 代替下一句预测 (NSP),表现出卓越的性能。
四、Codex,2021 年
Codex是第一个成功地从文档字符串或自然语言提示生成高精度代码的 Code LLM 之一,也是广泛使用的Github Copilot的前身。Codex 由 OpenAI 团队开发,使用GPT3架构和分词器,并在大量 Github 代码上进行预训练。这个大型语言模型有 12B 个参数,是 2021 年最先进的模型,它在人类评估数据集上表现出最佳性能,一次性解决了 28.8% 的问题。
在独立的 python 函数(而不是包括配置、类实现等的整个代码)上进一步微调模型,显示出显着的改进,并且能够解决37.7% 的人类评估数据集问题。
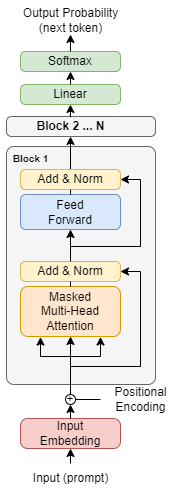
图 4:用于 Codex GPT 模型的仅解码器 Transformer 架构。图像灵感来自 Vaswani 等人的原始Transformer 论文。等人。
训练数据集:来自 54M Github 存储库的 159GB python 文件。
参数大小: 12B (Codex-12B)
模型架构: GPT3
新颖性:
- 第一个成功的模型,在自然语言提示下的代码编写能力方面表现出色。这会在大型 Github 存储库上训练 GPT-3 模型。
- 该模型的作者还创建了一个新的数据集“ HumanEval ”来对代码生成任务的模型进行基准测试。该数据集包含 164 个带有单元测试的手写编程问题。
在这里尝试 OpenAI Playground 的 Codex 模型Code-T5,2021
Code-T5是基于 T5 架构的编码器-解码器模型,与 CodeBERT(仅编码器)和 Codex(仅解码器)模型不同。它引入了独特的标识符感知去噪预训练任务,帮助模型区分和恢复代码中的标识符,增强其对结构的理解。
Code-T5 通过多任务学习,在代码缺陷检测、克隆检测、代码翻译和细化等各种任务中表现出色,需要更少的数据来更快地进行微调。但是,它使用 CodeBleu 分数进行评估,而不是针对 HumanEval 数据集进行基准测试。
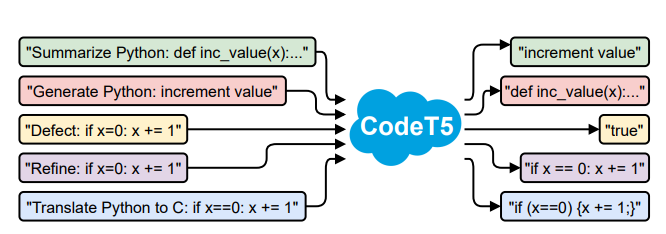
图 5:展示 CodeT5 如何在各种代码理解和生成任务中表现出色的插图。图片取自 Wang 等人的 Paper,CodeT5
训练数据集:Codesearch Net 数据集(与 CodeBERT 相同)
参数大小:220M
模型架构:T5(编码器-解码器架构)
新颖性:
- 编码器-解码器模型l:第一个支持代码理解和代码生成任务的编码器-解码器代码 LLM 之一。
- 提出了一种新颖的预训练目标标识符感知去噪,它可以学习标记类型信息和代码结构。这种方法训练模型区分标识符(变量名称、函数名称)和 PL 关键字(如 if、while 等),并在它们被屏蔽时恢复它们。
- 微调阶段的多任务学习:同时微调各种与代码相关的任务,如代码缺陷检测、克隆检测、代码翻译、细化等。
五、PLBart,2021
PLBART(程序和语言 BART)模型利用 BART 模型架构来自动化一系列软件工程任务,包括 PLUG(程序和语言理解和生成)下的代码汇总、生成和翻译。
它引入了一种去噪序列到序列建模方法,以增强程序和语言理解,战略性地结合了 BERT 和 GPT 模型的优势。这是通过将双向编码器与自回归解码器相结合来实现的,从而可以更全面地掌握上下文和通用的生成过程。该模型采用令牌屏蔽、令牌删除和令牌填充三种去噪策略来有效地训练和微调其能力。
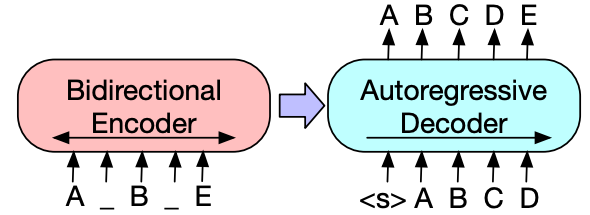
图 6:可视化 BART 模型(也在 PLBART 中使用)架构的图示,该架构具有双向编码器和自回归解码器。图片来自 Lewis 等人的原始BART 论文。等人。
训练数据集:从 Github、Stackoverflow 收集的 2M 个 Java 和 Python 函数及其自然语言描述(代码)。
参数大小:140M(6 个编码器层 + 6 个解码器层 + 编码器和解码器上的附加规范层)
模型架构:BART
新颖性:
- 去噪自动编码器方法:采用去噪自动编码器方法,通过有效利用编码器和解码器的双向和自回归特性,结合 BERT 和 GPT 模型的优势,增强代码理解和生成。
- 多样化的去噪策略:提出了多种去噪策略,如token屏蔽、token删除、token填充等。这种噪声技术的多样性增强了模型从噪声数据中学习的稳健性和有效性,有助于改进代码理解和生成。
并非所有模型都使用相同的基准来评估性能。PLBART 作者不会在 HumanEval(大多数其他模型用于基准测试的数据集)上评估模型性能。
六、Code Llama,2023
Code Llama是 Meta 发布的最新 Code LLM,它在多个基准数据集中击败了所有现有的开源模型。它在HumanEval 数据集上得分为 53% ,在 MBPP 数据集上得分为 55%(只有 GPT-4 具有更好的性能)。这些收益可归因于 16K 的较长上下文长度(Llama2 的 4 倍)以及使用来自程序和自然语言的额外 500B 令牌对预训练的 Llama 2 进行训练。
该模型最适合代码生成和填充任务,并且可以在基于 IDE 的软件开发过程中充当最佳副驾驶。Code Llama模型家族有3种模型-
- 代码骆驼
- 代码 Llama Python
- 代码 Llama-指导
每款都有 3 种尺寸 - 7B、13B 和 34B

图 7:以预训练的 Llama-2 模型作为输入的代码 Llama 训练和微调管道。图片来自 Rozière 等人的原始Code Llama 论文。等人。
训练数据集:500B 代币 + 用于公共代码上的 Code llama Python 的额外 100B 代币
模型架构:Llama 2
参数大小:有 3 种大小可供选择 - 7B、13B 和 34B。
新颖性:
- 提出了一个处理长序列的微调步骤,称为“长上下文微调”,它将上下文长度增加到 16,384(Llama 2 上下文长度的 4 倍,即 4096)
- 指令微调和自指令:执行指令微调的少数模型之一,在微调过程中使用显式指令或提示。作者提出了一种新颖的执行反馈方法来构建自指令数据集,而不是创建昂贵的人类反馈数据。
七、结论
Open AI 创始人之一安德烈·卡拉帕蒂 (Andrej Karapathy) 最近称变形金刚是人工智能中最好的想法。他补充说,变压器就像一台通用的可微分计算机,它同时具有表现力、可优化性和高效性(X post)。从过去 3-4 年带来的转变来看,Transformer 模型具有巨大的潜力,可以进一步改变我们作为软件工程师的编码方式,而我认为这只是一个开始。