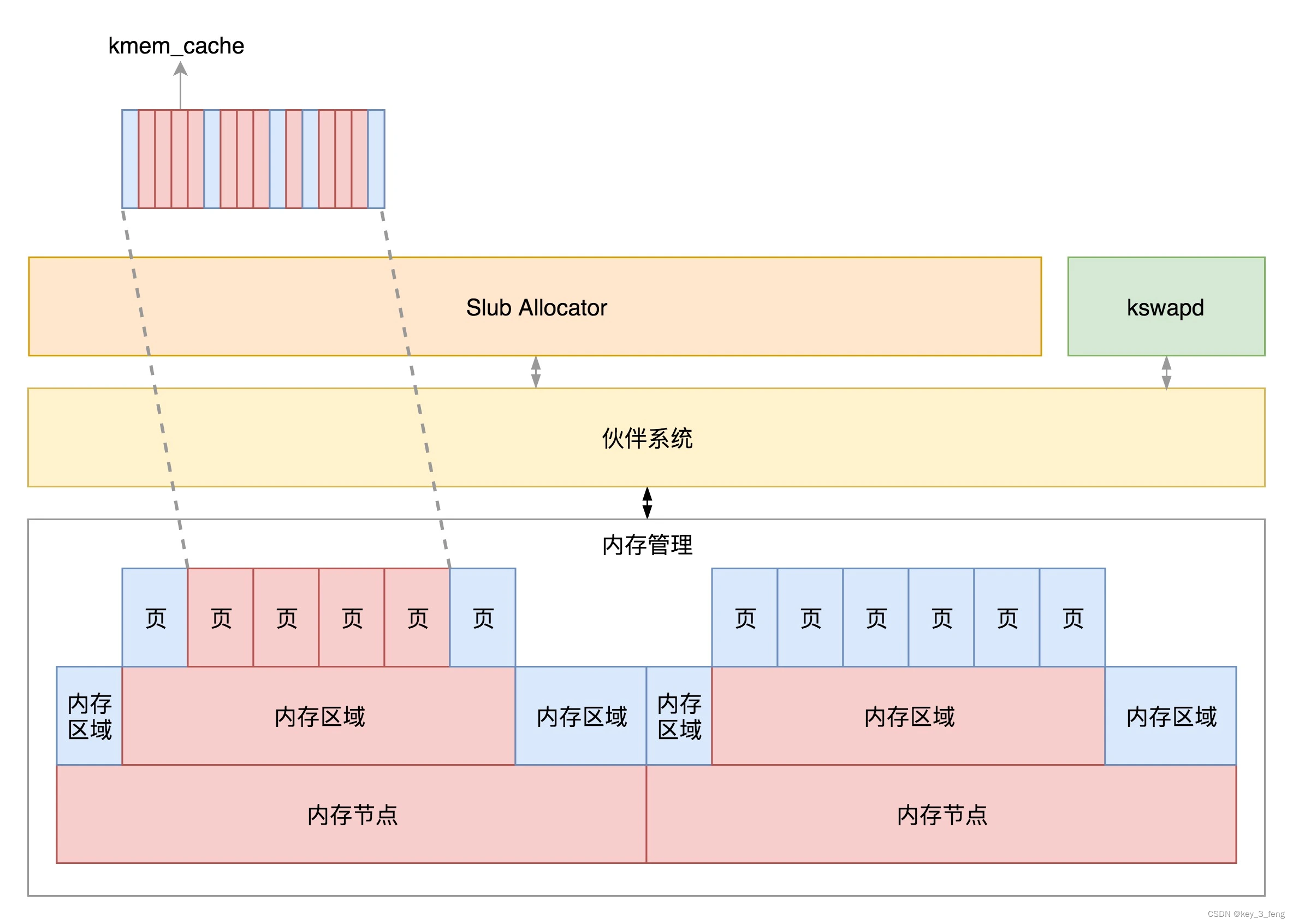
大家好,我是晴天,本周将同大家一起学习设计模式系列的第二篇文章——工厂模式,我们将依次学习简单工厂模式,工厂方法模式和抽象工厂模式。拿好纸和笔,我们现在开始啦~
前言
我们在进行软件开发的时候,虽然不使用任何设计模式也不耽误搬砖,但是,这样会导致代码可重用性、可扩展性、可读性、可维护性都大打折扣。所以强烈建议使用合适的设计模式进行软件开发。设计模式可以划分成三大类:创建型、结构型和行为型。本文将先从最基础的创建型模型——工厂模型介绍,工厂模式具体可以划分成简单工厂模式、工厂方法模式和抽象工厂模式,我们依次来学习一下。
为什么需要工厂模式
我们首先先来看一下下面未使用任何工厂模式的代码,看一下有什么问题?
package main
import "fmt"
// 不使用工厂方法模式
// 实现层
type Car struct {
name string
}
func (c *Car) Show(name string) {
if name == "AUDI" {
c.name = "奥迪"
} else if name == "BMW" {
c.name = "宝马"
} else {
c.name = "保时捷"
}
fmt.Println("我是:" + c.name)
}
func NewCar(name string) Car {
var c Car
if name == "BMW" {
c.name = "宝马"
} else if name == "AUDI" {
c.name = "奥迪"
} else {
c.name = "保时捷"
}
return c
}
// 业务逻辑层
func main() {
// 定义Car
var c Car
// 创建一个具体的AUDICar
c = NewCar("AUDI")
c.Show("AUDI") // 我是:奥迪
c = NewCar("BMW")
c.Show("BMW") // 我是:宝马
c = NewCar("CHEVROLET")
c.Show("CHEVROLET") // 我是:保时捷
}
代码解释:首先在实现层定义了一个Car产品,且有一个Show方法展示自己的品牌,同时写了一个构造函数,用来根据入参来创建具体的Car。在业务逻辑层,创建了一个具体的Car,并通过给NewCar传入不同的参数,创建不同的Car。
存在的问题:
- 当我们新增车的品牌时,需要对NewCar进行调整和改造,并且也需要对Show方法进行改造,这就涉及到新增产品类别的时候,需要修改类的源代码,这显然违背了开闭原则;同时还会使得Show这个方法变得越来越庞大,这也违背了类的单一职责原则。(对这两个原则不太清楚的小伙伴,可以参考这篇文章一文搞懂设计模式之七大原则)
- 实现层和业务逻辑层是高度耦合的,业务逻辑层既要负责创建对象,又要负责使用对象,如果要修改某些逻辑,不仅要修改实现层的代码,业务逻辑层的代码也需要进行改动,会使得创建的逻辑下沉到了业务逻辑层。这显然也是不符合设计模式最基本的一个思想——高内聚,低耦合
为了解决上述问题,我们使用了工厂模式。
简单工厂模式
类图
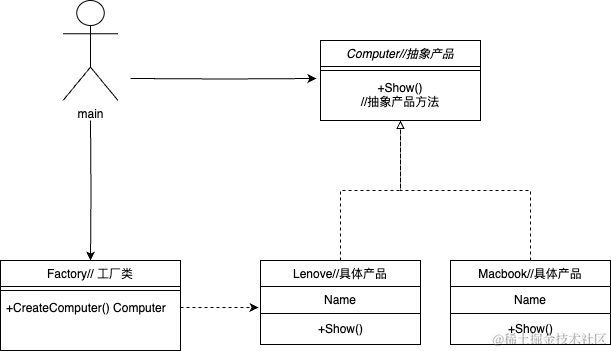
先来看一下简单工厂的类图,主要分为四个部分:抽象产品类、具体产品类、具体工厂类和main(业务逻辑)。
抽象产品类定义了一个Show方法,需要具体产品类去实现这个Show方法;具体产品类实现Show方法,打印出自己属于哪个具体的产品类型;具体工厂类有一个具体的生产产品的方法CreateComputer,且返回值为抽象产品类Computer(这里一定要返回抽象产品类,方法内部生产具体的产品对象,使用父类指针指向子类指针实现多态)
tips:类图中抽象产品类和具体产品类之间的箭头表示继承的意思,具体产品类需要继承抽象产品类的方法,即需要完成该方法的具体实现。工厂类和具体产品类之间的箭头表示依赖的意思,表示CreateComputer方法内部需要用到具体产品类的对象。
代码示例:
package main
import "fmt"
// 练习题:
// 实现简单工厂模式
// 产品类是电脑
// 抽象层
// 抽象电脑,有一个Show方法
type Computer interface {
Show()
}
// 实现层
// 具体产品类
type Macbook struct {
Name string
}
func (m *Macbook) Show() {
fmt.Println(m.Name)
}
type Lenovo struct {
Name string
}
func (l *Lenovo) Show() {
fmt.Println(l.Name)
}
// 工厂类
type EasyFactory struct {
}
// 根据入参,生产具体的产品
func (e *EasyFactory) CreateComputer(name string) Computer {
var c Computer
if name == "Macbook" {
c = &Macbook{Name: name}
} else if name == "Lenovo" {
c = &Lenovo{Name: name}
}
return c
}
// 对产品类符合开闭原则
// 对于工厂类来说,不符合开闭原则,每新增一个产品种类,都需要修改工厂类的方法
// 业务逻辑
func main() {
// 1.创建一个抽象产品
var c Computer
// 2.创建一个具体工厂对象
var ef = EasyFactory{}
// 3.调用工厂方法,生产具体产品
c = ef.CreateComputer("Macbook")
// 4.调用具体产品的方法
c.Show()
// 5.再次调用工厂方法,生产具体产品 (实现多态)
c = ef.CreateComputer("Lenovo")
c.Show()
}
代码解释:定义一个Computer抽象产品,定义两个品牌的具体产品类Macbook和Lenovo,定义一个具体工厂类,并且定义一个根据入参创建具体电脑品牌的产品。main函数内部的注释就是按照步骤创建抽象产品、创建工厂、创建具体产品并调用产品方法的过程。
优点:
- 把具体产品对象的创建和使用进行了解耦合,由工厂实现对具体产品对象的创建,业务逻辑层只需要跟工厂交互,然后使用工厂生产出来的具体产品即可,不用关心对象的创建过程如何。
- 将具体产品的初始化工作放到了工厂方法里面,做到了对产品的面向接口编程。
缺点:
- 对工厂来说,不符合开闭原则,每新增一个具体产品,都需要修改工厂方法。
- 工厂的创建方法业务逻辑过于繁重,如果该方法不能顺利执行,将会发生非常严重的问题,整个程序将无法正常运行。
工厂方法模式
工厂方法模式可以理解成:简单工厂模式+开闭原则
类图
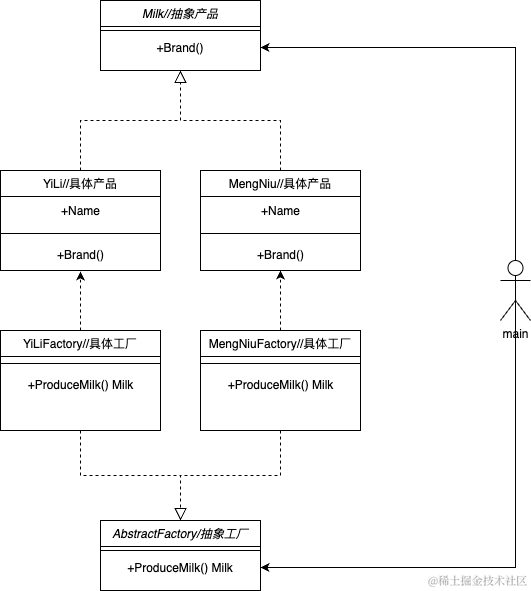
来看一下工厂方法模式的类图,分为五个部分:抽象产品类、具体产品类、抽象工厂类、具体工厂类和main(业务逻辑)。抽象产品类定义了一个Brand方法,需要具体产品类去实现这个Brand方法;具体产品类实现Brand方法,打印出自己属于哪个具体的产品品牌;抽象工厂类定义了ProduceMilk方法,具体工厂类继承抽象工厂类,需要实现ProduceMilk方法,且返回值为抽象产品类Milk(这里一定要返回抽象产品类,方法内部生产具体的产品对象,使用父类指针指向子类指针实现多态)
代码示例:
package main
import "fmt"
// 工厂方法就是:简单工厂+开闭原则
// 抽象层
// 抽象产品类
type Milk interface {
Brand()
}
// 抽象工厂类
type AbstractMilkFactory interface {
ProduceMilk() Milk
}
// 实现层
// 牛奶类的具体产品类
type MengNiu struct {
brand string
}
func (m *MengNiu) Brand() {
fmt.Println("品牌:" + m.brand)
}
// 牛奶类的具体产品类
type YiLi struct {
brand string
}
func (y *YiLi) Brand() {
fmt.Println("品牌:" + y.brand)
}
// 工厂类的具体对象
// 蒙牛工厂
type MengNiuFactory struct {
}
func (m *MengNiuFactory) ProduceMilk() Milk {
var mengNiu MengNiu
mengNiu.brand = "蒙牛"
return &mengNiu
}
// 伊利工厂
type YiLiFactory struct {
}
func (y *YiLiFactory) ProduceMilk() Milk {
var yili YiLi
yili.brand = "伊利"
return &yili
}
// 业务逻辑层
func main() {
// 1.创建蒙牛抽象牛奶工厂
var mnFacroty AbstractMilkFactory
// 2.实例化成蒙牛工厂
mnFacroty = new(MengNiuFactory)
// 3.生产蒙牛牛奶
mnMilk := mnFacroty.ProduceMilk()
// 4.显示牛奶品牌
mnMilk.Brand()
// 5.创建伊利抽象牛奶工厂
var ylFactory AbstractMilkFactory
// 6.实例化成伊利工厂
ylFactory = new(YiLiFactory)
// 7.生产伊利牛奶
ylMilk := ylFactory.ProduceMilk()
// 8.显示牛奶品牌
ylMilk.Brand()
}
代码解释:定义抽象牛奶产品和抽象牛奶工厂,定义蒙牛和伊利两种具体牛奶产品和具体牛奶工厂。main函数(业务逻辑层)只需要跟抽象牛奶产品和抽象牛奶工厂进行交互,符合依赖倒转原则(对这个原则不太清楚的小伙伴,可以参考这篇文章一文搞懂设计模式之七大原则)
优点:
- 新增一个具体产品时,无需修改产品和工厂的源代码,符合开闭原则
- 每个工厂只负责创建一个产品,不需要多个if…else判断创建什么产品,符合单一职责原则
- 业务逻辑层只需要跟抽象的产品和抽象的工厂进行交互,符合依赖倒转原则
缺点:
- 每新增一个具体产品类,都需要新增一个对应的工厂类,代码新增程度是1:1的,增加了程序的复杂程度和代码工作量。
- 很难对抽象产品类或者抽象工厂类进行扩展,一旦扩展,所有子类都需要进行修改。
抽象工厂模式
在介绍抽象工厂模式之前先介绍两个概念:产品等级结构和产品族
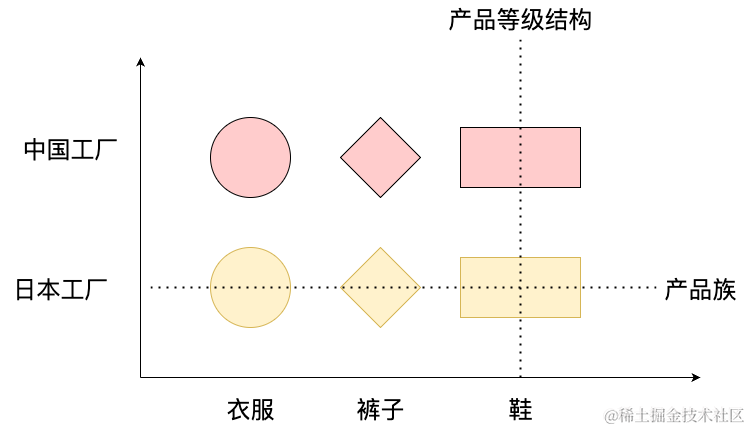
产品等级结构:产品等级结构即产品的继承结构。通俗理解:具有相同功能但是来自于不同生产厂商的产品零部件,它们的一个完备集合叫做产品等级结构。
产品族:指由同一个工厂生产的,位于不同产品等级结构中的一组产品。
类图
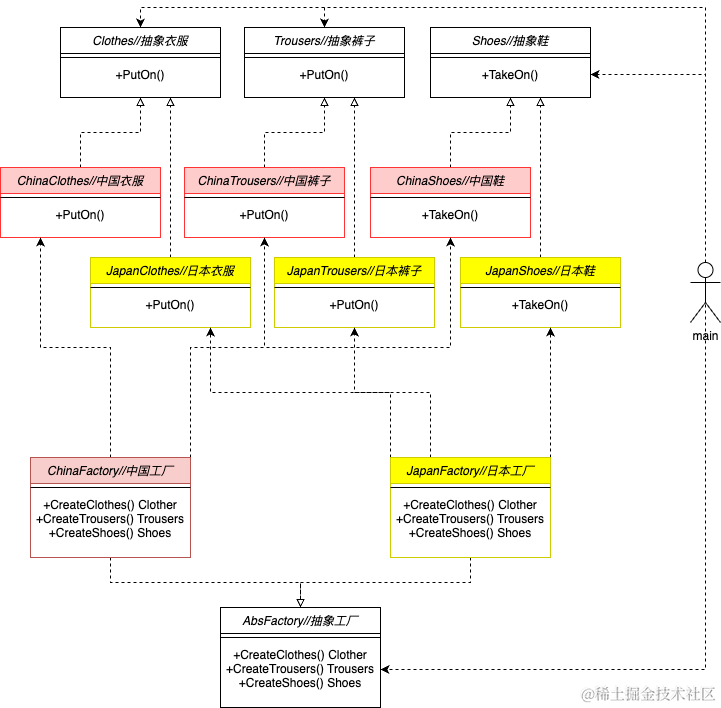
来看一下抽象工厂的类图,首先明确有哪些抽象类和哪些具体类,抽象类是一个完整的产品等级结构,抽象衣服类、抽象裤子类、抽象鞋类,抽象的工厂类;具体类有中国衣服类、中国裤子类、中国鞋类、日本衣服裤子鞋类,中国工厂类和日本工厂类。中国的衣服裤子鞋组成了中国的产品族,日本衣服裤子鞋组成了日本产品族。中国工厂只依赖于(生产)中国的衣服裤子鞋,日本工厂只依赖于(生产)日本的衣服裤子鞋。
代码示例:
package main
import "fmt"
// 抽象工厂的作用在于不用每新建一个品类,都创建一个工厂,每个工厂生产一整套产品等级结构
// 练习:产品等级结构为
// clothes trousers shoes 衣服 裤子 鞋
// 抽象层
// 产品等级结构为Clothes,trousers,shoes
type Clothes interface {
PutOn()
}
type Trousers interface {
PutOn()
}
type Shoes interface {
TakeOn()
}
// 产品族:生产完整的产品等级结构的工厂
// 一个工厂能生产出完整的产品
type AbsFactory interface {
CreateClothes() Clothes
CreateTrousers() Trousers
CreateShoes() Shoes
}
// 实现层
// 不同产品族的产品等级结构全部创建完成
type ChinaClothes struct {
}
func (c *ChinaClothes) PutOn() {
fmt.Println("穿上中国衣服")
}
type ChinaTrousers struct {
}
func (c *ChinaTrousers) PutOn() {
fmt.Println("穿上中国裤子")
}
type ChinaShoes struct {
}
func (c *ChinaShoes) TakeOn() {
fmt.Println("穿上中国鞋")
}
type JapanClothes struct {
}
func (j *JapanClothes) PutOn() {
fmt.Println("穿上日本衣服")
}
type JapanTrousers struct {
}
func (j *JapanTrousers) PutOn() {
fmt.Println("穿上日本裤子")
}
type JapanShoes struct {
}
func (j *JapanShoes) TakeOn() {
fmt.Println("穿上日本鞋")
}
// 创建中国和日本工厂
type ChinaFactory struct {
}
func (c *ChinaFactory) CreateClothes() Clothes {
return &ChinaClothes{}
}
func (c *ChinaFactory) CreateTrousers() Trousers {
return &ChinaTrousers{}
}
func (c *ChinaFactory) CreateShoes() Shoes {
return &ChinaShoes{}
}
type JapanFactory struct {
}
func (j *JapanFactory) CreateClothes() Clothes {
return &JapanClothes{}
}
func (j *JapanFactory) CreateTrousers() Trousers {
return &JapanTrousers{}
}
func (j *JapanFactory) CreateShoes() Shoes {
return &JapanShoes{}
}
// 业务逻辑层
func main() {
// 1.定义抽象中国工厂
var chinaFac AbsFactory
// 2.实例化中国工厂
chinaFac = new(ChinaFactory)
// 3.中国工厂生产中国衣服
chinaClothes := chinaFac.CreateClothes()
// 4.中国工厂生产中国裤子
chinaTrousers := chinaFac.CreateTrousers()
// 5.中国工厂生产中国鞋
chinaShoes := chinaFac.CreateShoes()
// 6.调用中国产品的方法
chinaClothes.PutOn()
chinaTrousers.PutOn()
chinaShoes.TakeOn()
// 日本工厂同理
var japanFac AbsFactory
japanFac = new(JapanFactory)
japanClothes := japanFac.CreateClothes()
japanTrousers := japanFac.CreateTrousers()
japanShoes := japanFac.CreateShoes()
japanClothes.PutOn()
japanTrousers.PutOn()
japanShoes.TakeOn()
}
优点:
- 拥有工厂模式的优点
- 新增一个产品族的时候,只需要新增一个具体的工厂即可,符合开闭原则
缺点:
- 如果产品等级结构发生变化,对于工厂类来说,抽象工厂类需要新增方法,所有产品族都需要进行修改,不符合开闭原则。
- 抽象程度比较高,代码理解起来有一定的困难
总结:
- 简单工厂模式:让一个工厂类创建所有的产品,不利于扩展和维护,违背了开闭原则
- 工厂方法模式:就是在简单工厂模式的基础上,增加了开闭原则,但是每个工厂类只能创建一种产品,使得代码中类的数量过于庞大
- 抽象工厂模式:拥有工厂方法模式的优点,但是对于扩充产品等级结构不友好,违反开闭原则。
写在最后:
感谢大家的阅读,晴天将继续努力,分享更多有趣且实用的主题,如有错误和纰漏,欢迎给予指正。 更多文章敬请关注作者个人公众号 晴天码字。 我们下期不见不散,to be continued…