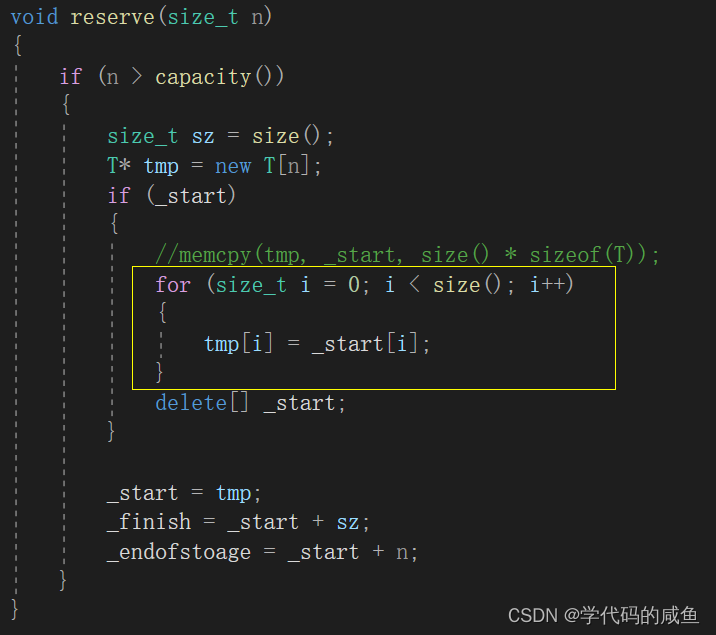
ODS层构建:代码导入
目标:实现Python项目代码的导入及配置
实施
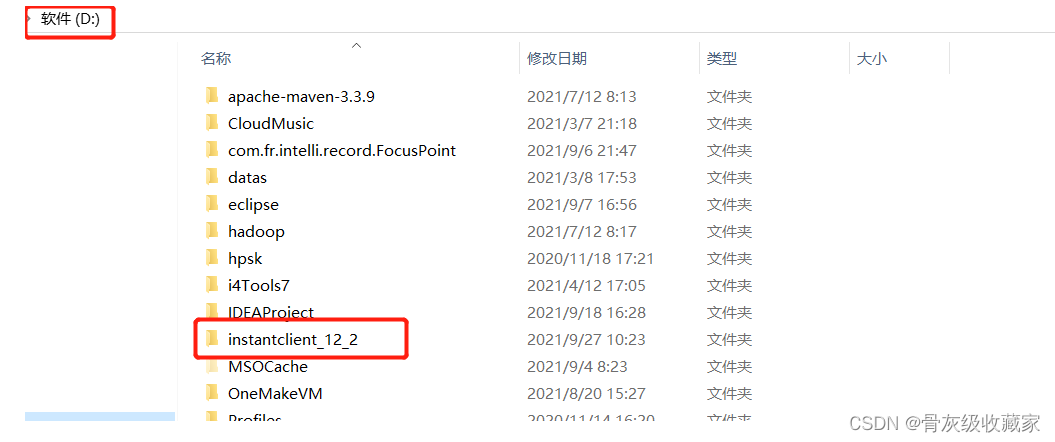
Oracle本地驱动目录**:将提供的**instantclient_12_2**目录放入D盘的根目录下
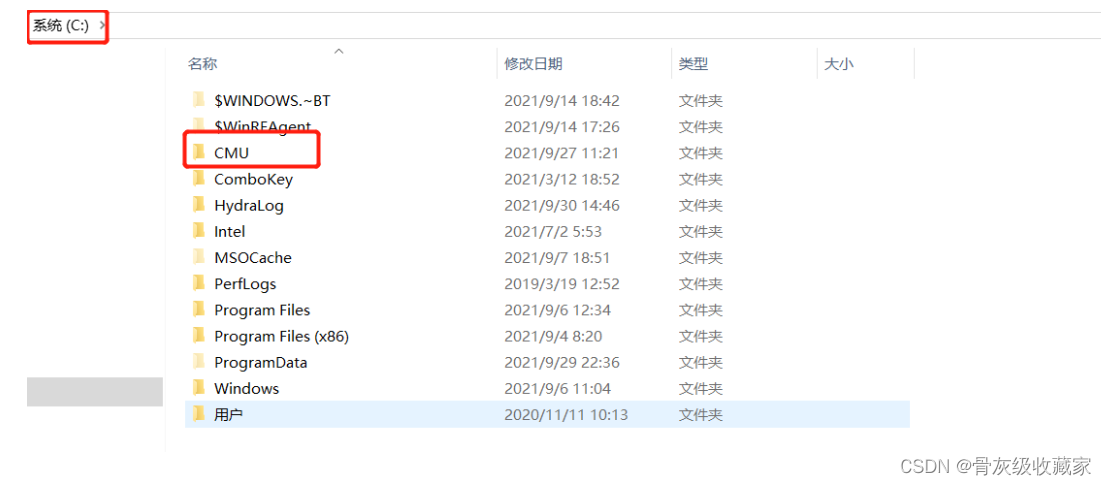
PyHive本地连接配置:将提供的CMU目录放入C盘的根目录下
 auto_create_hive_table包
auto_create_hive_table包
创建路径包

- 在datatohive的init文件中放入如下代码

- 其他包的init都放入如下内容

将对应的代码文件放入对应的包或者目录中
step1:从提供的代码中复制config、log、resource这三个目录直接粘贴到**auto_create_hive_table**包下
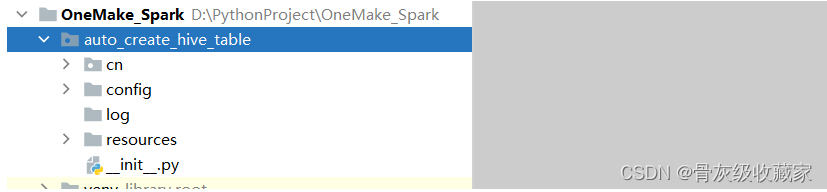
step2:从提供的代码中复制entity、utils、EntranceApp.py这三个直接粘贴到**itcast**包下

step3:从提供的代码中复制fileformat等文件直接粘贴到**datatohive**包下

DW归档目录:将提供的代码中的dw目录直接粘贴到项目中
ODS层构建:代码结构及修改
目标:了解整个自动化代码的项目结构及实现配置修改
路径
- step1:工程代码结构
- step2:代码模块功能
- step3:代码配置修改
实施
工程代码结构

代码模块功能
- `auto_create_hive_table`:用于实现ODS层与DWD层的建库建表的代码
- `cn.itcast`
- `datatohive`
- CHiveTableFromOracleTable.py:用于创建Hive数据库、以及获取Oracle表的信息创建Hive表等
- CreateMetaCommon.py:定义了建表时固定的一些字符串数据,数据库名称、分层名称、文件类型属性等
- CreateHiveTablePartition.py:用于手动申明ODS层表的分区元数据
- LoadData2DWD.py:用于实现将ODS层的数据insert到DWD层表中
- `fileformat`
- AvroTableProperties.py:Avro文件格式对象,用于封装Avro建表时的字符串
- OrcTableProperties.py:Orc文件格式对象,用于封装Orc建表时的字符串
- OrcSnappyTableProperties.py:Orc文件格式加Snappy压缩的对象
- TableProperties.py:用于获取表的属性的类
- `entity`
- TableMeta.py:Oracle表的信息对象:用于将表的名称、列的信息、表的注释进行封装
- ColumnMeta.py:Oracle列的信息对象:用于将列的名称、类型、注释进行封装
- `utils`
- OracleHiveUtil.py:用于获取Oracle连接、Hive连接
- FileUtil.py:用于读写文件,获取所有Oracle表的名称
- TableNameUtil.py:用于将全量表和增量表的名称放入不同的列表中
- ConfigLoader.py:用于加载配置文件,获取配置文件信息
- OracleMetaUtil.py:用于获取Oracle中表的信息:表名、字段名、类型、注释等
- **EntranceApp.py**:程序运行入口,核心调度运行的程序
# todo:1-获取Oracle、Hive连接,获取所有表名
# todo:2-创建ODS层数据库
# todo:3-创建ODS层数据表
# todo:4-手动申明ODS层分区数据
# todo:5-创建DWD层数据库以及数据表
# todo:6-加载ODS层数据到DWD层
# todo:7-关闭连接,释放资源
```
- `resource`
- config.txt:Oracle、Hive、SparkSQL的地址、端口、用户名、密码配置文件
- `config`
- common.py:用于获取日志的类
- settings.py:用于配置日志记录方式的类
- `log`
- itcast.log:日志文件
- `dw`:用于存储每一层构建的核心配置文件等
- 重点关注:**dw.ods.meta_data.tablenames.txt**:存储了整个ODS层的表的名称
ODS层构建:连接代码及测试
目标:阅读连接代码及实现连接代码测试
路径
- step1:连接代码讲解
- step2:连接代码测试
实施
- **为什么要获取连接?**
- Python连接Oracle:获取表的元数据
- 表的信息:TableMeta
- 表名
- 表的注释
- list:[列的信息]
- 列的信息:ColumnMeta
- 列名
- 列的注释
- 列的类型
- 类型长度
- 类型精度
- Python连接HiveServer或者Spark的ThriftServer:提交SQL语句
连接代码讲解
- step1:怎么获取连接?

step2:连接时需要哪些参数?
- Oracle:主机名、端口、用户名、密码、SID
- Hive:主机名、端口、用户名、密码
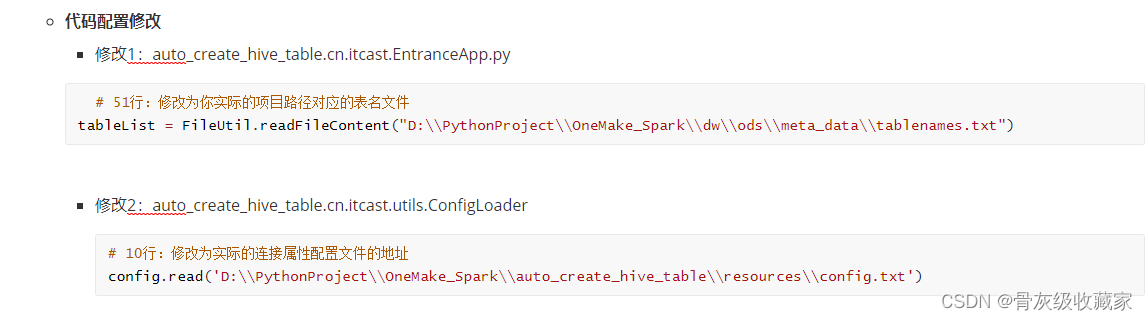
- step3:如果有100个代码都需要构建Hive连接,怎么解决呢?
- 将所有连接参数写入一个配置文件:resource/config.txt
- 通过配置文件的工具类获取配置:ConfigLoader
- step4:在ODS层建101张表,表名怎么动态获取呢?
- 读取表名文件:将每张表的名称都存储在一个列表中
- step5:ODS层的表分为全量表与增量表,怎么区分呢?
- 通过对@符号的分割,将全量表和增量表的表名存储在不同的列表中
连接代码测试
- 启动虚拟运行环境

运行测试代码
- 注释掉第2 ~ 第6阶段的内容
- 取消测试代码的注释
- 执行代码观察结果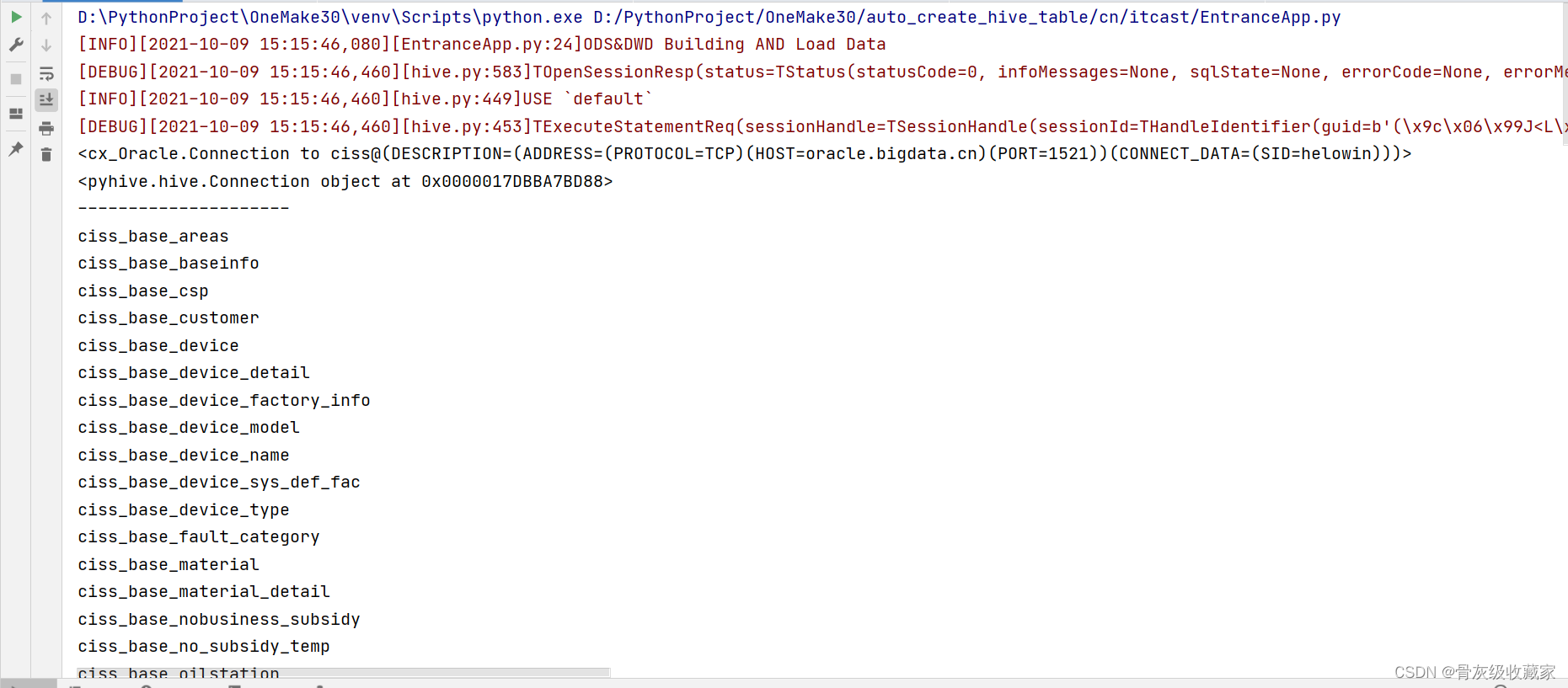
ODS层构建:建库代码及测试
目标:阅读ODS建库代码及实现测试
路径
- step1:代码讲解
- step2:代码测试
实施
代码讲解
step1:ODS层的数据库名称叫什么?
![]()
step2:如何使用PyHive创建数据库?
- 第一步:先获取连接
- 第二步:拼接SQL语句,从连接对象中获取一个游标
- 第三步:使用游标执行SQL语句
- 第四步:释放资源
- **代码测试**
- 注释掉第3 ~ 第6阶段的内容
- 运行代码,查看结果
ODS层构建:建表代码及测试
目标:阅读ODS建表代码及实现测试
路径
- step1:代码讲解
- step2:代码测试
实施
代码讲解
- step1:表名怎么获取?
tableNameList【full_list,incr_list】
full_list:全量表名的列表
incr_list:增量表名的列表
- step2:建表的语句是什么,哪些是动态变化的?

- 表名
- 表的注释
- 表的HDFS地址
- Schema文件的HDFS地址
- step3:怎么获取表的注释?
- 从Oracle中获取:从系统表中获取某张表的信息和列的信息

step4:全量表与增量表有什么区别?
- 区别1:表名不一样
- full_table_list
- incr_table_list
- 区别2:路径不一样
- `/data /dw /ods /one_make /full /Oracle库名.表名`
- `/data /dw /ods /one_make /incr /Oracle库名.表名`
- step5:如何实现自动化建表?
- 自动化创建全量表
- 获取全量表名
- 调用建表方法:数据库名称、表名、全量标记
- 通过Oracle工具类获取表的信息【表的名称、表的注释、字段信息等】
- 拼接建表语句
- 执行SQL语句
- 自动化创建增量表
- 获取增量表名
- 调用建表方法:数据库名称、表名、增量标记
- 通过Oracle工具类获取表的信息【表的名称、表的注释、字段信息等】
- 拼接建表语句
- 执行SQL语句
代码测试
- 注释掉第4~ 第6阶段的内容
- 运行代码,查看结果

ODS层构建:申明分区代码及测试
目标:阅读ODS申明分区的代码及实现测试
路径
- step1:代码讲解
- step2:代码测试
实施
代码讲解
step1:为什么要申明分区?
- 表的分区数据由Sqoop采集到HDFS生成AVRO文件
![]()
- HiveSQL基于表的目录实现了分区表的创建

但是Hive中没有对应分区的元数据,无法查询到数据
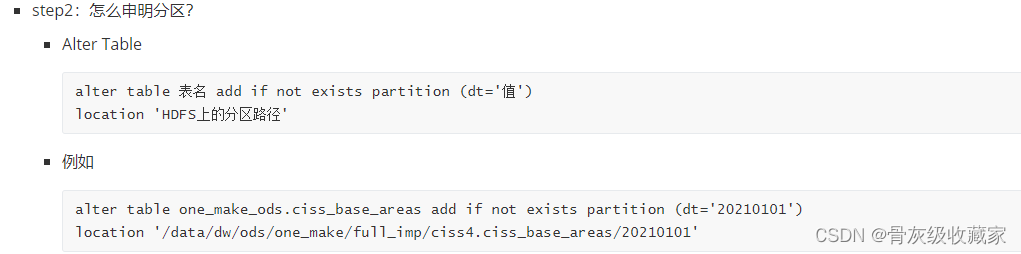
step3:如何自动化实现每个表的分区的申明?
- 获取分区工具类实例
- 调用申明分区的方法
- 对所有全量表调用申明分区的方法:数据库名称、表名、全量标记、分区值
- 对所有增量表调用申明分区的方法:数据库名称、表名、增量标记、分区值
- 拼接SQL
- 执行SQL
- **代码测试**
- 注释掉第5 ~ 第6阶段的内容
- 运行代码,查看结果
ODS层与DWD层区别
目标:理解ODS层与DWD层的区别
路径
- step1:内容区别
- step2:设计区别
- step3:实现区别
实施
内容区别
- ODS:原始数据
- DWD:对ODS层ETL以后的数据
- 本次数据来源于Oracle数据库,没有具体的ETL的需求,可以直接将ODS层的数据写入DWD层
设计区别
- ODS层:Avro格式分区数据表
- DWD层:Orc格式分区数据表
实现区别
- ODS层建表:基于avsc文件指定Schema建表

- DWD层建表:自己指定每个字段的Schema建表

DWD层构建:需求分析
目标:掌握DWD层的构建需求
路径
- step1:整体需求
- step2:建库需求
- step3:建表需求
实施
整体需求:将ODS层的数据表直接加载到DWD层

建库需求:创建DWD层数据库one_make_dwd
建表需求:将ODS层中的每一张表创建一张对应的DWD层的表
- 问题1:建表的语法是什么?
- 问题2:表的名称名是什么,怎么获取?
- 不分全量和增量
- 所有表的名称都在列表中
- 问题3:表的注释怎么来?
- Oracle元数据中有
- 问题4:表的字段怎么获取?
- Oracle元数据中有
- 问题5:Oracle中的字段类型如果与Hive中的类型不一致怎么办?
- 将Oracle中Hive没有类型转换为Hive的类型
DWD层构建:建库实现测试
目标:阅读DWD建库代码及实现测试
路径
- step1:代码讲解
- step2:代码测试
实施
代码讲解
- step1:DWD层的数据库名称是什么,建库的语法是什么?
![]()
- step2:如何实现DWD层数据库的构建?
![]()
- **代码测试**
- 注释掉第5.2 ~ 第6阶段的内容
- 运行代码,查看结果

DWD层构建:建表实现测试
目标:阅读DWD建表代码及实现测试
路径
- step1:代码讲解
- step2:代码测试
实施
代码讲解
- step1:如何获取所有表名?
![]()
- 列表推导式
- step2:建表的语句是什么,哪些是动态变化的?

- 动态变化的信息如下:
- 表名,表的注释
- 字段
- 路径
- step3:怎么获取字段信息?
- step4:Oracle字段类型与Hive/SparkSQL字段类型不一致怎么办?
- timestamp => long
- number => bigint | dicimal
- other => String
- step4:HDFS上的路径是什么?
```
/data/dw/dwd/one_make/tableName
```
- step5:如何实现自动化
- 遍历表名,对每张表调用自动化建表的方法:数据库名称、表的名称、None【不分全量或者增量】
- 从Oracle中获取字段名,并实现类型转换
- 添加表的注释、分区信息
- 添加表的存储格式
- 指定表的存储路径
- 执行SQL语句
- **代码测试**
- 注释掉 第6阶段的内容
- 运行代码,查看结果

DWD层构建:数据抽取分析
目标:实现DWD层的构建思路分析
路径
- step1:抽取目标
- step2:抽取语法
实施
抽取目标:将ODS层中每张表的数据抽取到DWD层对应的数据表中
抽取语法

DWD层构建:数据抽取测试
目标:实现DWD层数据抽取的测试
路径
- step1:代码讲解
- step2:代码测试
实施
代码讲解
- step1:如何获取所有表名?
- 所有表名都在list中
- step2:如何获取所有字段的信息?
- 从Oracle中获取
- **代码测试**
- 取消第6段代码的注释
- 运行代码,查看结果
整体代码重难点回顾
目标:掌握整体代码的重难点
实施
- 问题1:怎么读取表名的?
- 表名:文件
- FileUitil:读取文件
- TableNameUtil:将表名拆分全量列表和增量列表
- 问题2:怎么构建连接的?
- Oracle:cx_Oracle
- conn(hostname,port,username,password,sid)
- Hive/SparkSQL:PyHive
- conn(hostname,port,username,password)
- 执行SQL规则
- step1:必须构建一个连接
- step2:从连接中获取游标,定义SQL
- step3:使用游标执行SQL语句
- step4:释放资源
- 问题3:为什么要把连接地址写在文件里?
- 开发规范
- df.write.jdbc(url,table,properties)
- 地址
- 端口
- 用户名
- 密码
- 表名
- 问题4:怎么拼接SQL语句的?
- 字符串的拼接
- 问题5:怎么执行SQL语句的?
- 游标:execute(SQL)
- 问题6:怎么获取Oracle的表的信息的?
- Oracle将每张表的每一列的信息都存储Oracle系统表中
- 通过SQL就可以查询到表的这些信息
- TableMeta:表的信息
- 表名:String
- 表的注释:String
- 列的信息:List[ColumnMeta]
- ColumnMeta:列的信息
- 列名
- 列注释
- 列类型
- 长度
- 精度








![洛谷千题详解 | P1026 [NOIP2001 提高组] 统计单词个数【C++、Java语言】](https://img-blog.csdnimg.cn/6a6c26d6ad4344e1ba564f91799986b3.png)