快速排序
- 快速排序递归实现
- 前言
- 一、Hoare版本
- (一)算法运行图例
- (二)算法核心思路
- (三)算法实现步骤
- (1)单趟
- (2)多趟
- (四)码源详解 递归实现
- (1)Hoare版本:先行版
- (2)Hoare版本:发行版
- (五)Hoare算法 实现背后的理论支持
- (六)效率优化
- Hoare排序的效率分析
- (1)时间复杂度 O(N*logN)
- 稳定性: 不稳定
- (七)代码优化
- (1)三数取中
- 1)优化思路
- 2)三数取中优化 后的代码
- 3)效果对比
- (2)小区间优化—— 小区间不再进行递归分割排序,降低递归次数
- 1)优化思路
- 2)整体优化后的完整代码
- 二、挖坑法版本
- 前言
- (一)算法运行图例
- (二)算法核心思路
- (三)算法实现步骤
- (1)单趟
- (2)多趟
- (四)码源详解
- 三、前后指针版本
- (一)算法运行图例
- (二)算法核心思路
- (三)算法实现步骤
- (1)单趟
- (2)多趟
- (四)码源详解
快速排序递归实现
前言
快速排序是Hoare于1962年提出的一种 二叉树结构的交换排序方法。
一、Hoare版本
(一)算法运行图例

(二)算法核心思路
任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合 分割成两子序列 ,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
(三)算法实现步骤
(1)单趟
- 找一key 【注意:我们实际上控制的是key的下标keyi,而不是用新开辟的变量去储存它的值,用新开辟的变量去储存,最后交换的也只是与该变量进行交换,而不是在数组中与原数组的值进行交换】
【图讲解】 - begin从左开始遍历,左边找比key大的。end从右开始遍历,右边找比key小的。等于key的值不动。
- 两边都找到了,互换
- 最后相遇的地方(就是key排好序后要放的位置(正确的位置))与key互换 【有理论支持的,请看下文】
此时 【左边的都比key小】中间key【右边的都比key大】
要是左右要是都有序 =》整体实现有序 (多趟解决)
(2)多趟
- 对排好的key的左边再进行单趟排序
- 对排好的key的右边再进行单趟排序
- 左边右边分别再排好两边key的位置,再分左右,再进行单趟
类似 二叉树前序递归的思想:根、左子树、右子树。
(四)码源详解 递归实现
(1)Hoare版本:先行版
按照思路写出来 了,大家看看都存在些什么问题。
//递归实现
// Hoare版本(先行版)
int PartSort1(DataType* a,int left,int right) {
int key = a[left];
while (left < right) { //相遇是跳出循环的条件 //right 先走
if (a[key] < a[right]) {
right--;
} //找到a[right]<a[keyi]的情况就停下
if (a[left] < a[key]) { //left 同理
left++;
}
Swap(&a[left], &a[right]); //都找到后互换
}
Swap(&a[left], &a[key]);//相遇后跳出循环 交换a[keyi]和left,right相遇的位置
}
-
坑1:a[key] < a[right],若a[key] 一直比 a[right]要小,则right则回一直向左right–遍历,则会出现越界的问题(同理left那边也是)
- 解决方法:left<right,控制right不要越界,避免该序列本来就是有序(一直比a[keyi]要大而一直right–,越出边界的情况)的情况
-
坑2:a[keyi] < a[right],若不跳则要是两边都遇到相等的值,则两边无法再进入if()语句进行right–或left++,而进入死循环
- 解决方法:a[keyi]<=a[right]时,都跳
- 解决方法:a[keyi]<=a[right]时,都跳
-
坑3:int key = a[left]; Swap(&a[left], &a[key]); 真正在换的是哪个?
key是局部变量,相当于在栈区开辟了一块空间,用于存储a[left]的值。实际与数组a[left]进行交换的,是局部变量这块空间里面的值,对数组原始的最左边并不产生任何影响- 解决方法:int left = keyi; 记录的应该是下标,通过控制下标来达到改变原数组
(2)Hoare版本:发行版
// Hoare版本(发行版)
int PartSort1(DataType* a, int left, int right) {
int keyi = left; //保存left的下标
while (left < right) { //相遇是跳出循环的条件 //right 先走
if (left < right && a[keyi] <= a[right]) { //left<right,控制right不要越界,避免该序列本来就是有序(一直比a[keyi]要大而一直right--,越出边界的情况)的情况
right--;
} //找到a[right]<a[keyi]的情况就停下
if (left < right && a[left] <= a[keyi]) { //left 同理
left++;
}
Swap(&a[left], &a[right]); //都找到后互换
}
Swap(&a[left], &a[keyi]);//相遇后跳出循环 交换a[keyi]和left,right相遇的位置
}
(五)Hoare算法 实现背后的理论支持
★☆ 最后相遇的地方 就是key排好序后要放的位置(正确的位置)是怎么做到的呢?
右边先走做到的。
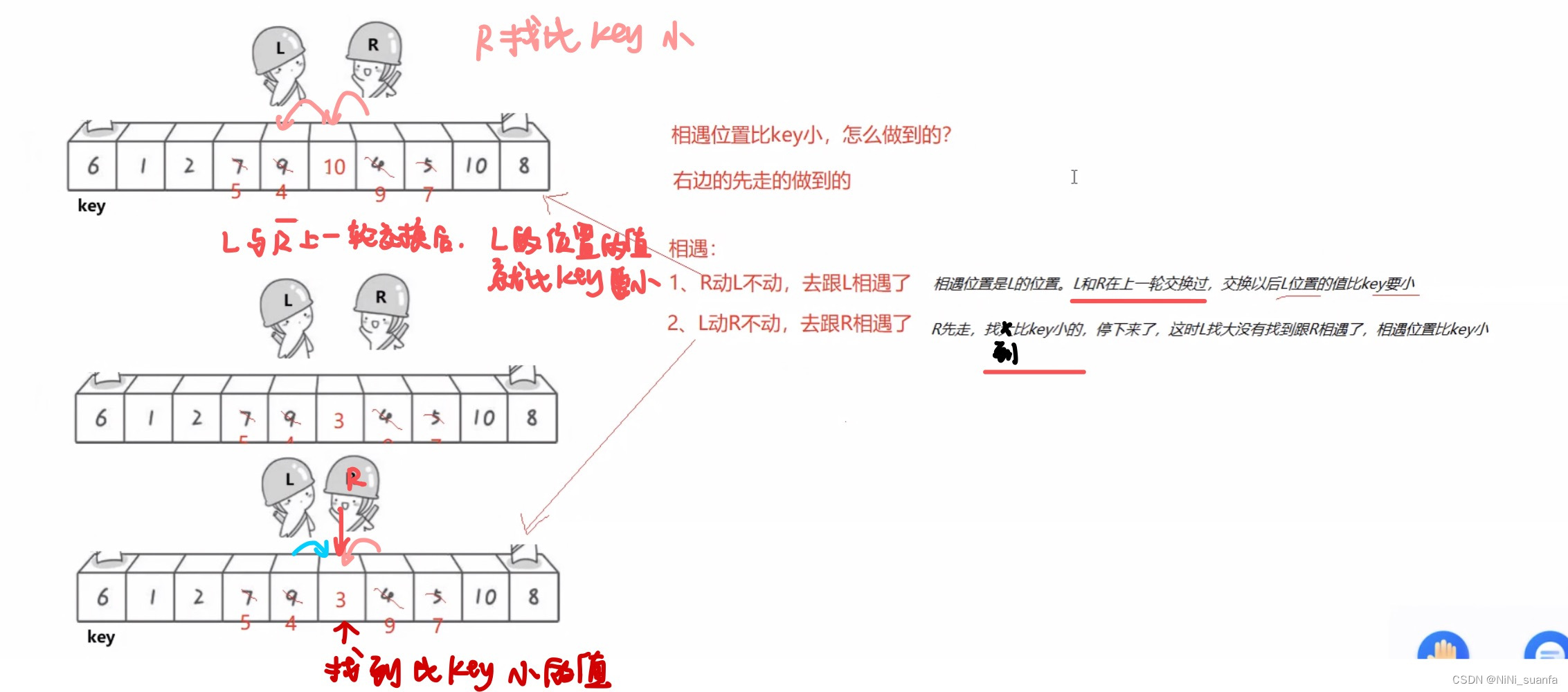
有了上面的理论保证,停下来的值一定比key小,才敢进行交换。
(六)效率优化
Hoare排序的效率分析
(1)时间复杂度 O(N*logN)
如果每次选到的 key=a[ left ] 都是中位数,这将会非常高效
【因为每单趟排好一次,key就能落入到其正确的位置】
-
理想状态下是:满二叉树的分割【二分 O(N*logN)】
-
而最差的情况:有序(接近有序)【每次取到的key都选到整个数组中次大或次小的数,每个key,left或right都要遍历一遍数组, O(N^2)】 但随机取的值肯定不是像这样有序(或接近有序)的(这种都是已经给你排好了的)
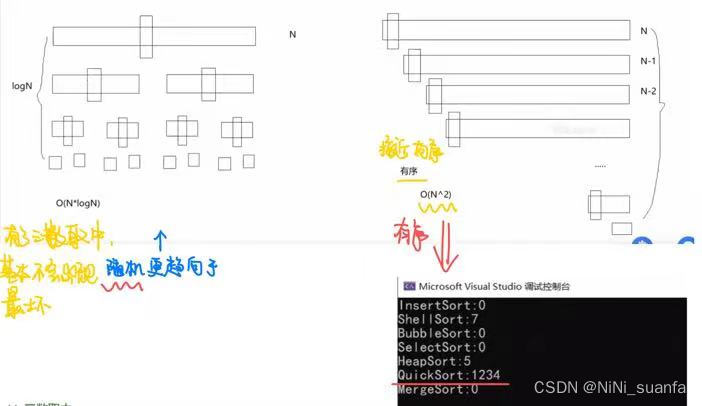
所以总体来说,Hoare在时间复杂度上是更接近于 O(N*logN) 的 。
稳定性: 不稳定
(七)代码优化
(1)三数取中
那么我们针对序列可能会出现最差情况(有序的情况),做一个程序优化——三数取中 。
1)优化思路
int mid=(left+right)/ 2 ;
对比 a[mid]、a[left]、a[right] 三个值,取值大小为中间的那个数 。【大大降低了取两边极端的可能,让取到的数更偏向于有序序列中间的数】
//三数取中 取的不是位置在中间的值,而是值大小位于中间的值
int Getmidi(DataType* a,int left,int right) {
int mid = (left + right) / 2;
//left mid right
if (a[left] < a[mid]) {
if (a[mid] < a[right]) //mid为中间值
return mid;
else if (a[left] > a[right]) { //mid为最大值
return left; //left为中间值
}
else {
return right;
}
}
else { //a[left]>a[mid]
if (a[mid] > a[right]) { //mid为中间值
return mid;
}
else if (a[left]<a[right]) { //left为中间值,mid最小
return left;
}
else {
return right;
}
}
}
2)三数取中优化 后的代码
//三数取中 取的不是位置在中间的值,而是值大小位于中间的值
int Getmidi(DataType* a,int left,int right) {
int mid = (left + right) / 2;
//left mid right
if (a[left] < a[mid]) {
if (a[mid] < a[right]) //mid为中间值
return mid;
else if (a[left] > a[right]) { //mid为最大值
return left; //left为中间值
}
else {
return right;
}
}
else { //a[left]>a[mid]
if (a[mid] > a[right]) { //mid为中间值
return mid;
}
else if (a[left]<a[right]) { //left为中间值,mid最小
return left;
}
else {
return right;
}
}
}
// Hoare版本(发行版)
int PartSort1(DataType* a, int left, int right) {
//三数取中
int midi = Getmidi(a, left, right);
Swap(&a[left], &a[midi]); //交换a[left]与a[midi]值的位置
int keyi = left; //保存left的下标
while (left < right) { //相遇是跳出循环的条件 //right 先走
if (left < right && a[keyi] <= a[right]) { //left<right,控制right不要越界,避免该序列本来就是有序(一直比a[keyi]要大而一直right--,越出边界的情况)的情况
right--;
} //找到a[right]<a[keyi]的情况就停下
if (left < right && a[left] <= a[keyi]) { //left 同理
left++;
}
//坑1:a[keyi] < a[right],若不跳则要是两边都遇到相等的值,则两边无法再进入if()语句进行right--或left++,而进入死循环
//更正:a[keyi]<=a[right]时,都跳
Swap(&a[left], &a[right]); //都找到后互换
}
Swap(&a[left], &a[keyi]);//相遇后跳出循环 交换a[keyi]和left,right相遇的位置
}
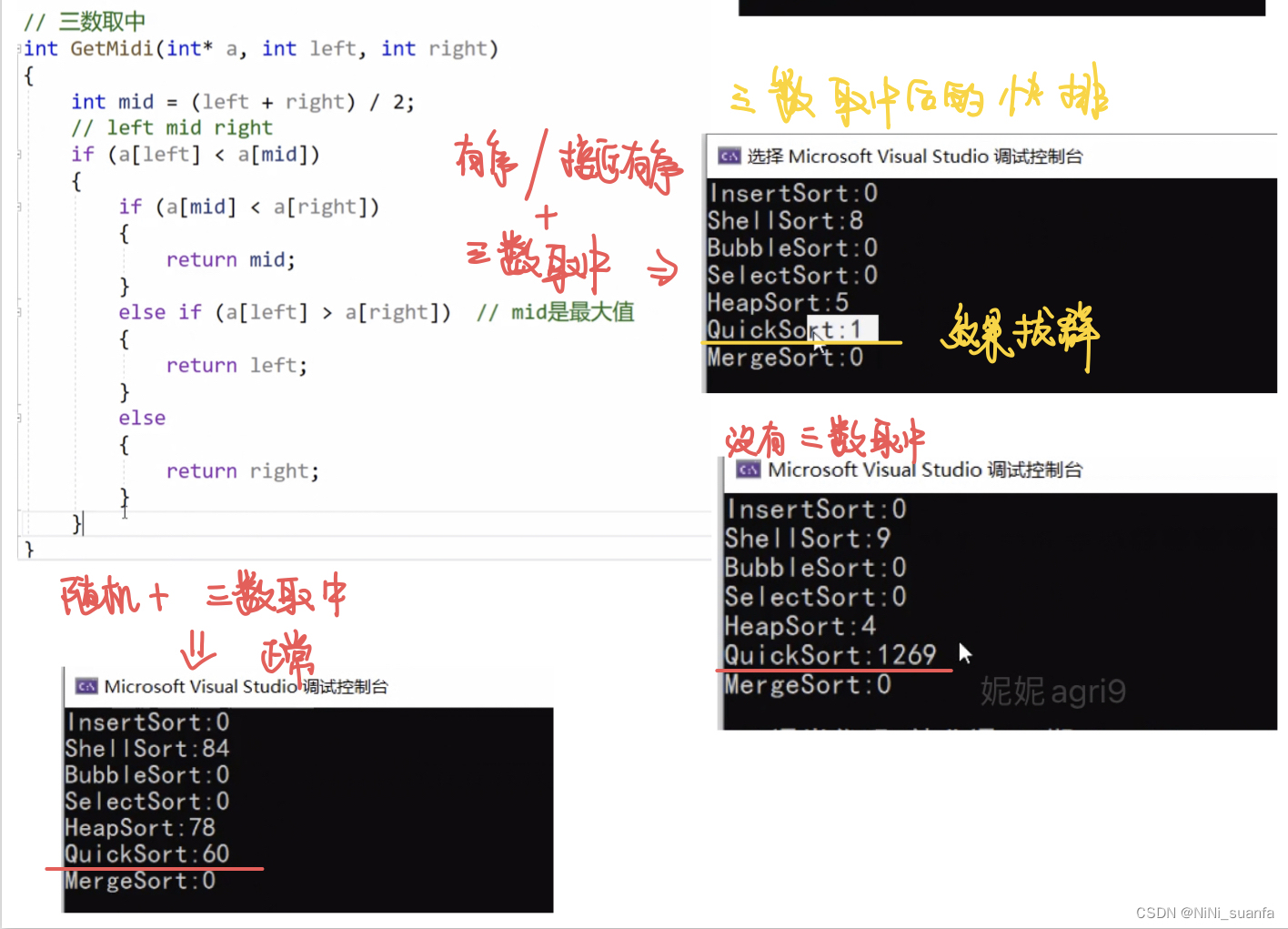
3)效果对比
对 有序/接近有序 的序列中优化效果明显。
对 随机 就正常。
(2)小区间优化—— 小区间不再进行递归分割排序,降低递归次数
1)优化思路
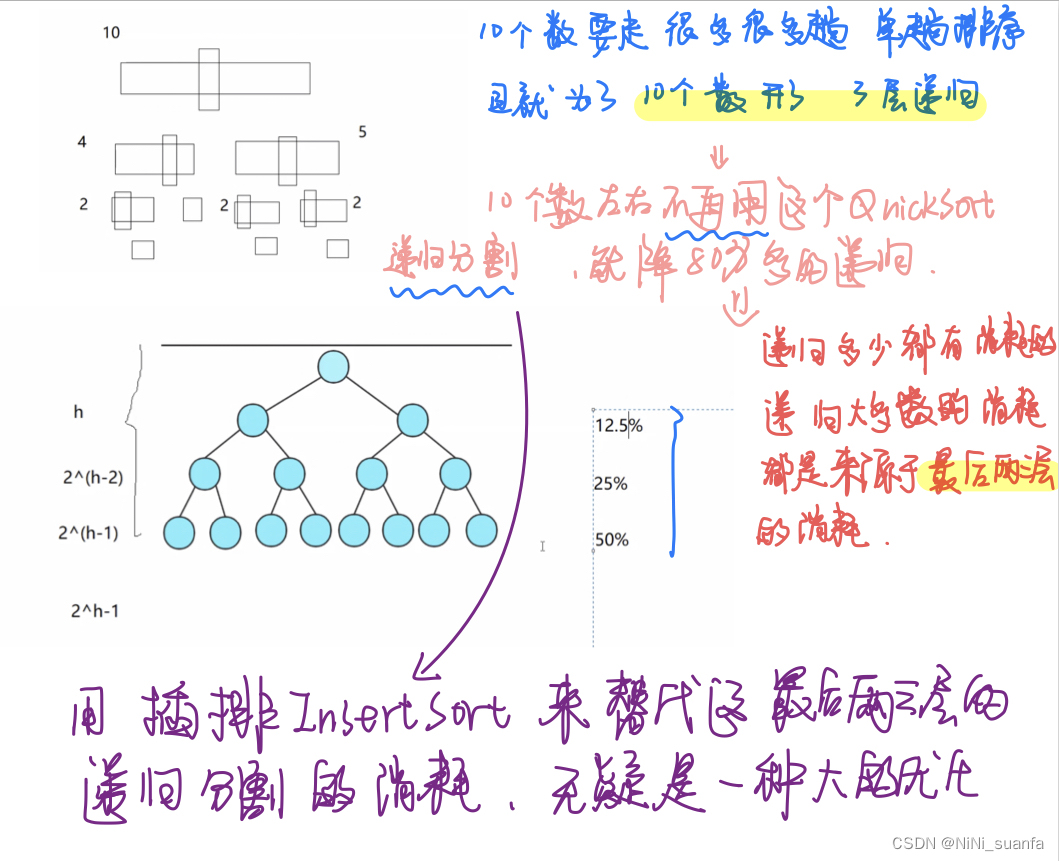
满二叉树整体节点的个数:2^h-1( 等比数列求和 )。
最后一层的节点数就已经占了整体的 50% 。
最后三层的节点数就已经约占整体的 80% 的节点个数了 。
那么最后这三层约占整体80%的节点数,若采用递归的方式,将是对栈帧的一个很大的开销。因为我们最后这三层区间被分的比较小了,若采用更适用于小区间数排序的优化,无疑是对效率很大的提升!
那么小区间优化我们可以选择哪个小区间数排序方式呢?
希尔排序:数据大时比较有序(目的:让大的数更快的到后面去)
插入排序:少的数(最坏情况:逆序,比所有数都小)
因为小区间,数比较少,对比起来比较快,所以这里选择 插入排序 更快速便捷高效。
//小区间优化版本—— 小区间不再进行递归分割排序,降低递归次数
void QuickSort1(DataType* a, int begin, int end) {
if (begin >= end)
return;
//10个数就已经占3层递归了,而递归层数中,尾三层所占节点的总数 约占80%,这尾三层再继续用递归的方法,而改用小区间数据排序优化的思路,能让程序整体得到进一步的优化
if ((end - begin + 1) > 10) {
int keyi = PartSort3(a, begin, end);
QuickSort1(a, begin, keyi - 1);
QuickSort1(a, keyi+1, end);
}
else { //改用小区间数据优化排序
InsertSort(a + begin, end - begin + 1); // a+begin 找到对应数组所在的位置
}
}
2)整体优化后的完整代码
//三数取中 取的不是位置在中间的值,而是值大小位于中间的值
int Getmidi(DataType* a,int left,int right) {
int mid = (left + right) / 2;
//left mid right
if (a[left] < a[mid]) {
if (a[mid] < a[right]) //mid为中间值
return mid;
else if (a[left] > a[right]) { //mid为最大值
return left; //left为中间值
}
else {
return right;
}
}
else { //a[left]>a[mid]
if (a[mid] > a[right]) { //mid为中间值
return mid;
}
else if (a[left]<a[right]) { //left为中间值,mid最小
return left;
}
else {
return right;
}
}
}
// Hoare版本(发行版)
int PartSort1(DataType* a, int left, int right) {
//三数取中
int midi = Getmidi(a, left, right);
Swap(&a[left], &a[midi]); //交换a[left]与a[midi]值的位置
int keyi = left; //保存left的下标
while (left < right) { //相遇是跳出循环的条件 //right 先走
if (left < right && a[keyi] <= a[right]) { //left<right,控制right不要越界,避免该序列本来就是有序(一直比a[keyi]要大而一直right--,越出边界的情况)的情况
right--;
} //找到a[right]<a[keyi]的情况就停下
if (left < right && a[left] <= a[keyi]) { //left 同理
left++;
}
//坑1:a[keyi] < a[right],若不跳则要是两边都遇到相等的值,则两边无法再进入if()语句进行right--或left++,而进入死循环
//更正:a[keyi]<=a[right]时,都跳
Swap(&a[left], &a[right]); //都找到后互换
}
Swap(&a[left], &a[keyi]);//相遇后跳出循环 交换a[keyi]和left,right相遇的位置
}
//小区间优化版本—— 小区间不再进行递归分割排序,降低递归次数
void QuickSort1(DataType* a, int begin, int end) {
if (begin >= end)
return;
//10个数就已经占3层递归了,而递归层数中,尾三层所占节点的总数 约占80%,这尾三层再继续用递归的方法,而改用小区间数据排序优化的思路,能让程序整体得到进一步的优化
if ((end - begin + 1) > 10) {
int keyi = PartSort3(a, begin, end);
QuickSort1(a, begin, keyi - 1);
QuickSort1(a, keyi+1, end);
}
else { //改用小区间数据优化排序
InsertSort(a + begin, end - begin + 1); // a+begin 找到对应数组所在的位置
}
}
二、挖坑法版本
前言
挖坑法是Hoare排序的一个思路上的优化:不用再考虑为什么右边先走。
因为一开始的坑就在左边,那么一开始就得先从右边开始找,找比坑小的数。
(一)算法运行图例

(二)算法核心思路
和Hoare的思路一样,只不过这里是先挖好一个坑,再开始排。如果在左边挖坑,则从右边开始找;如果在右边挖坑,则从左边开始找。
(三)算法实现步骤
(1)单趟
- int key = a[left]; //保存好key值以后,左边形成第一个坑
- 右边先走,找小,填到左边的坑,右边形成新的坑
- 左边再走,找大,填到右边的坑,左边形成新的坑位
- left、right 相遇,跳出循环。最终相遇,一定在坑上相遇(因为left、right其中一个必在坑位上)且该坑位就是key值该在的有序序列中正确的位置( 和Hoare版本的同理 ) 。将key保留的最开始坑位的值赋给现在left、right相遇所在的坑位。
(2)多趟
- 对排好的key的左边再进行单趟排序
- 对排好的key的右边再进行单趟排序
- 左边右边分别再排好两边key的位置,再分左右,再进行单趟
(四)码源详解
// 快速排序——挖坑法
int PartSort2(int* a, int left, int right) {
//三数取中——取位值位于中间的值
int midi = Getmidi(a, left, right);
Swap(&a[left], &a[midi]);
int key = a[left]; //保存好key值以后,左边形成第一个坑
int hole = left;
//单趟完成的返回的条件
while (left < right) {
//右边先走,找小,填到左边的坑,右边形成新的坑
while (left < right && key <= a[right]) {
right--;
}
a[hole] = a[right];
hole = right;
//左边再走,找大,填到右边的坑,左边形成新的坑位
while (left < right && a[left] <= key) {
left++;
}
a[hole] = a[left];
hole = left;
}
//最后把储存的key的值填入坑位,不用怕坑位的数被覆盖,因为原坑位的数在这之前就已经赋到其他地方了
a[hole] = key;
return hole; //返回已经排好正确位置的坑位位置
}
三、前后指针版本
(一)算法运行图例

(二)算法核心思路
cur一直向前遍历,不管是遇到大的还是遇到小的。
而prev遇小的向前++,把小的交换过来;遇到大的就停下,等遇到小的时候就++将其交换覆盖。旨在把小的放其左边,大的放其右边。
cur越界后,遍历结束。此时 prev 所在的地方,正是key值该在的有序序列中正确的地方。
(三)算法实现步骤
(1)单趟
- 三数取中 _ 取中间值 赋给key
- int prev = left ; int cur = prev + 1;
cur遇比key小的,交换Swap(&a[++prev],&a[cur]);(把小的放其左边) - cur越界,遍历结束
- Swap ( &a[prev],&a[keyi] ); 此时 prev 所在的地方,正是key值该在的有序序列中正确的地方。
(2)多趟
- 对排好的key的左边再进行单趟排序
- 对排好的key的右边再进行单趟排序
- 左边右边分别再排好两边key的位置,再分左右,再进行单趟
(四)码源详解
- 先行版
这样写存在什么问题?
// 快速排序前后指针法 —— 先行版
int PartSort3(int* a, int left, int right) {
int midi = Getmidi(a, left, right);
Swap(&a[left], &a[midi]);
int prev = left;
int cur = prev + 1;
int keyi = left;
while (cur <= right) { //cur越界结束
while (cur <= right && a[cur] > a[keyi]) { //没有碰到比key小的就一直向后遍历
cur++;
}
//找到了
++prev; //遇小的了就++prev,Swap(&a[prev], &a[cur]);交换
Swap(&a[prev], &a[cur]);
}
//cur越界后,代表遍历结束
//在a[++prev] 的位置将key值赋予它(key该在的正确位置)
Swap(&a[prev], &a[keyi]);
return prev;
}
当cur一直没有再遇到小的,cur将会越界,而这仅会跳出内层(cur向后遍历)的循环,但程序仍在外层交换的循环中走。
所以cur越界后,程序仍要向下运行代码,这时交换的不再是数组中的数值,而是数组外后一位cur越界后位置的数值。
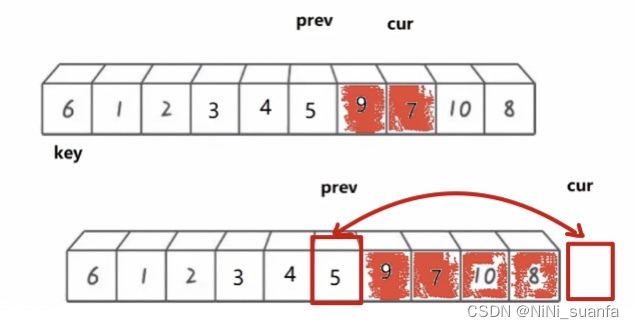
所以应不再进行交换。交换已经结束了。应跳出外层交换 a[prev] 和 a[cur] 的循环。进行下一步 a[prev] 与 a[keyi] 的交换,交换到key在有序中的正确位置。
- 发行版(一)
当判断出cur越界,即可break跳出循环,不再进行 a[prev] 与 a[cur] 的交换
// 快速排序前后指针法 —— 先行版
int PartSort3(int* a, int left, int right) {
int midi = Getmidi(a, left, right);
Swap(&a[left], &a[midi]);
int prev = left;
int cur = prev + 1;
int keyi = left;
while (cur <= right) { //cur越界结束
while (cur <= right && a[cur] > a[keyi]) { //没有碰到比key小的就一直向后遍历
cur++;
}
if (cur > right) { //当判断出cur越界,即可break跳出循环,不再进行 a[prev] 与 a[cur] 的交换
break;
}
//找到了
++prev; //遇小的了就++prev,Swap(&a[prev], &a[cur]);交换
Swap(&a[prev], &a[cur]);
}
//cur越界后,代表遍历结束
//在a[++prev] 的位置将key值赋予它(key该在的正确位置)
Swap(&a[prev], &a[keyi]);
return prev;
}
- 发行版(二)
// 快速排序前后指针法
int PartSort3(int* a, int left, int right) {
int midi = Getmidi(a, left, right);
Swap(&a[left], &a[midi]);
int prev = left;
int cur = prev + 1;
int keyi = left;
while (cur <= right) { //cur越界结束
//写法一
if (a[cur] < a[keyi]) {
Swap(&a[++prev],&a[cur]); //在还没遇到大的之前,cur = prev + 1; a[++prev] = a[cur];数组自己与自己交换
//遇小交换的意义:将比其小的值放左边,比其大的值放右边
}
//写法二
if (a[cur] < a[keyi] && ++prev != cur); { //如果不想要自己与自己交换的这种不必要的交换,++prev != cur条件也可以这么写
Swap(&a[prev], &a[cur]);
}
cur++;
}
//cur越界后,代表遍历结束
//在a[prev] 的位置将key值赋予它(key该在的正确位置)
Swap(&a[prev],&a[keyi]);
return prev;
}