进程控制
进程创建
对于进程的创建,你肯定知道,在 C/C++ 当中使用 fork()函数,以当前可执行程序生成的进程为 父进程,创建这个父进程的 一个子进程,这个 子进程就是一个新的进程。
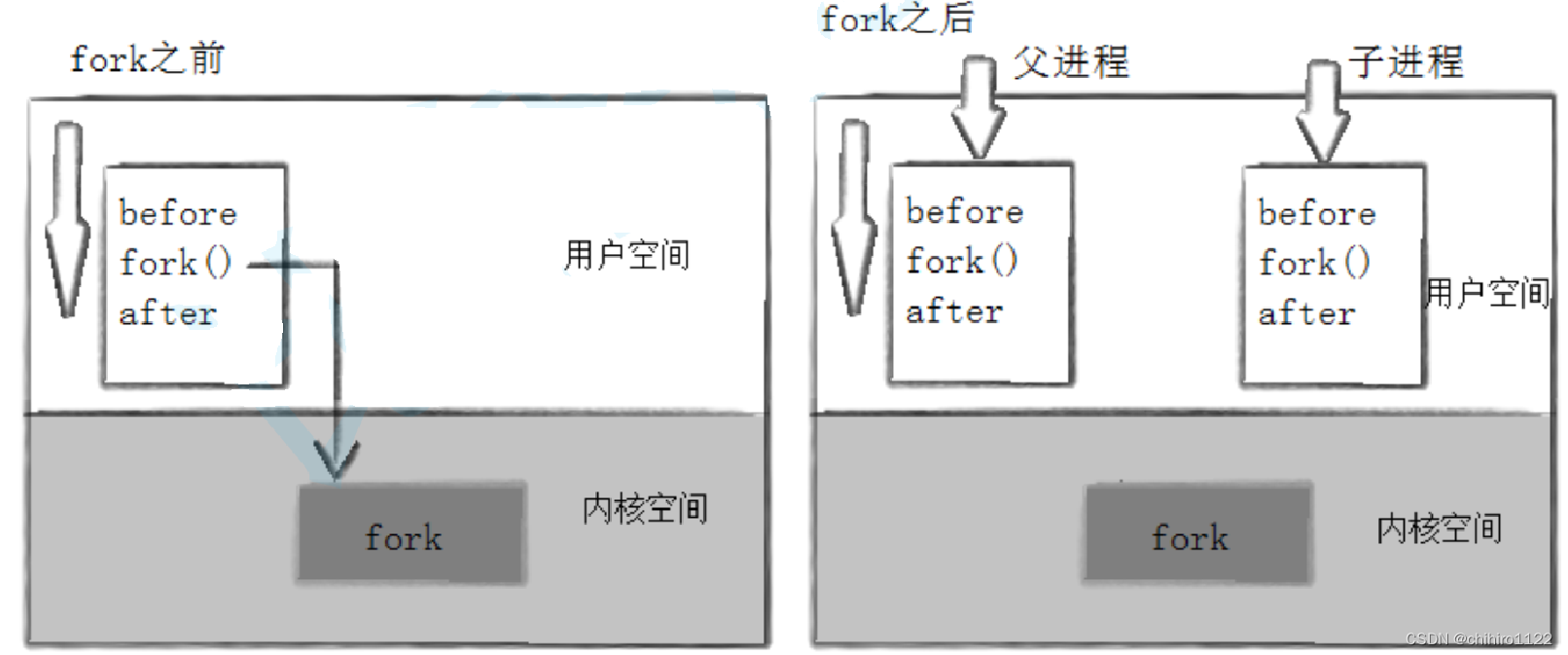
如上图所示:刚开始创建出子进程之时,甚至父子进程的 页表 ,数据 和 代码都可以是共用的,当 子进程 有修改操作之时,才会发生写时拷贝,拷贝子进程修改之后需要有用到的数据。
当父进程 执行到 fork()函数之时,就会在内核当中去找到 fork()函数定义,调用 fork()函数创建子进程,此后,就从fork()函数之后,父子进程就会各自执行,开始各自的“旅程”。
所以,fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
当然,fork()函数创建进程是有创建失败的情况的,比如系统当中进程数太多,内存爆满,或者是 实际用户的进程使用数超过了限制,都是可能会导致 fork()函数创建进程失败的。
除了可是使用 if-else 语句来判断当前是什么进程,把父进程和子进程用来执行不同的代码块之外,你还可以用 循环来 批量化 创建多个进程:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#define N 5
int main()
{
int i = 0;
for (int i = 0; i < N; i++)
{
int fork_ret = fork();
if (fork_ret == 0)
{
// 某一个子进程
printf("child : PID: %d , PPID: %d\n", getpid(), getppid());
exit(0);// 子进程执行完上述的代码就终止
}
}
return 0;
}

这个写时拷贝不仅仅只是子进程会进行写时拷贝,父进程同样会进行写时拷贝,父子进程谁先写,谁就先进行写时拷贝。
如上所示,不管原本的父进程对应的页表项是 什么访问权限,就算是 可读可写,在最后都会修改成只读,会把全部可写的区域,全部改成只读,所以,子进程继承下来也是只读的。
所以,在此之后,不管是哪一个进程想在某一个 区域当中的写的话,都与触发权限方面的问题,此时,操作系统识别到了,是不会进行异常处理的,反而是做写时拷贝的 处理,是谁想修改的,就新开辟空间,拷贝一份数据,给这个 进程使用。然后,再把两个进程对应的页表项的 访问权限标签标成可读的。
而,写时拷贝本质上就是用一种,延迟申请,按需申请,不要盲目的给子进程,直接拷贝一份,开辟一个 和 父进程一样大的空间,给子进程使用,如果父进行当中有100个数据,但是 子进程只用修改一个数据,父进程也不修改数据的话,那么很大部分的子进程的空间就浪费了,因为这些不用修改数据,完全可以和父进程共同使用。所以,才要写时拷贝,需要的时候,再去拷贝数据,开辟新的空间。
进程终止
在上述用循环来创建 多个进程 这个例子当中,我们想提前终止掉 子进程 的运行,所以我们在函数体当中 就 使用 exit()这个函数来终止掉这个 子进程:

要讨论上述的 exit ()函数之前我们先来讨论一下,为什么我们使用 main(),总是喜欢 return 0 呢?那么 return 其他的数可以吗,比如 :return 1 ?
进程终止无外乎就三种终止的情况:
- 代码运行完毕,结果正确;
- 代码运行完毕,结果不正确;
- 代码异常终止;
如果是前两种情况,结果正确的情况,我们是不关心的,我们最关心的是结果为什么是不正确的。如果结果是不正确的,那么我们对程序的返回结果做分析。
所以,其实 return 0 是 进程的退出码,这个退出码表示进程的运行结果是否正确,我们一般用 0->sucess 。0 是我们默认的 程序程序运行的退出码,其他程序员也是这样认为的,如果这个程序返回的是0 ,不仅仅是告诉写这个程序的人,这个程序执行成功了,也告诉 其他程序员,这个程序是正常退出的。
同时,main()函数的返回值,返回给谁了?为什么要返回这个值?
上述所说的 return 0 ,这个退出码,返回给谁了呢?其实这个 退出码,会被这个进程的父进程所拿到,对应到 我们日常在 使用 命令行来运行程序的话,就是被 bash 所拿到。
我们可以在命令行使用 echo $? 命令来查看到最近一个 bash 的子进程的退出码是多少:

之所以父进程要接收子进程的程序退出码,是因为,一般而言,某一个进程的父进程是要关心子进程的运行情况的。
如果子进程返回的是0,那么说明这个程序运行是正确的,父进程知道了子进程返回的是 0 的退出码,他也就放心了,因为 子进程运行结果是正确的。
父进程最关心的是 子进程 的退出码不是 0 的情况,也就对应 程序运行结果不正确的情况;所以,我们可以用 return 不同的数字,来表示不同错误原因。
用这种方式来告知使用这个程序的用户,这个程序出没出错,或者出错了,出的是什么错误;因为一个程序是不一定 一定要在屏幕上打印什么内容的,肯定是有程序是没有打印内存的这个需求的,那么在这种没有任何打印来提示错误的程序当中,要想知道这个程序是否出错的话,使用 程序退出码来表示是最好的。
所以,我们之前在写代码,直接“无脑写” return 0 其实是不太正确的,因为,如果整个程序的运行环境是在多个进程同时运行的环境下,而且这些进程都互相之间有一定关联,或者整个程序就是在各自运行,没有任何的反馈,我们是不知道这个程序到底出没有出错的。
而且,退出码是一个一个的数字,他是比较适合让计算机去看的,不然的话,这个程序退出码是1 表示 内存出错,2 表示数组越界····· 这些报错的退出码,人是不可能每一个都记住的,我们需要去查文档等等的文献来知道,当前程序的退出码表示的是什么意思。
这是一种机械化的操作,不就是查文档吗?那么交给计算机去做不就行了,所以,返回这些不同的退出码,本质上也就是返回一些代表着 不同报错信息的数字,这些数字是给计算机去看的。
当计算机查到当前程序的退出码对应的错误信息,计算机就可以把这个退出码,转换成对应的错误信息的字符串,让我们知道这个程序当中是出现了什么错误。
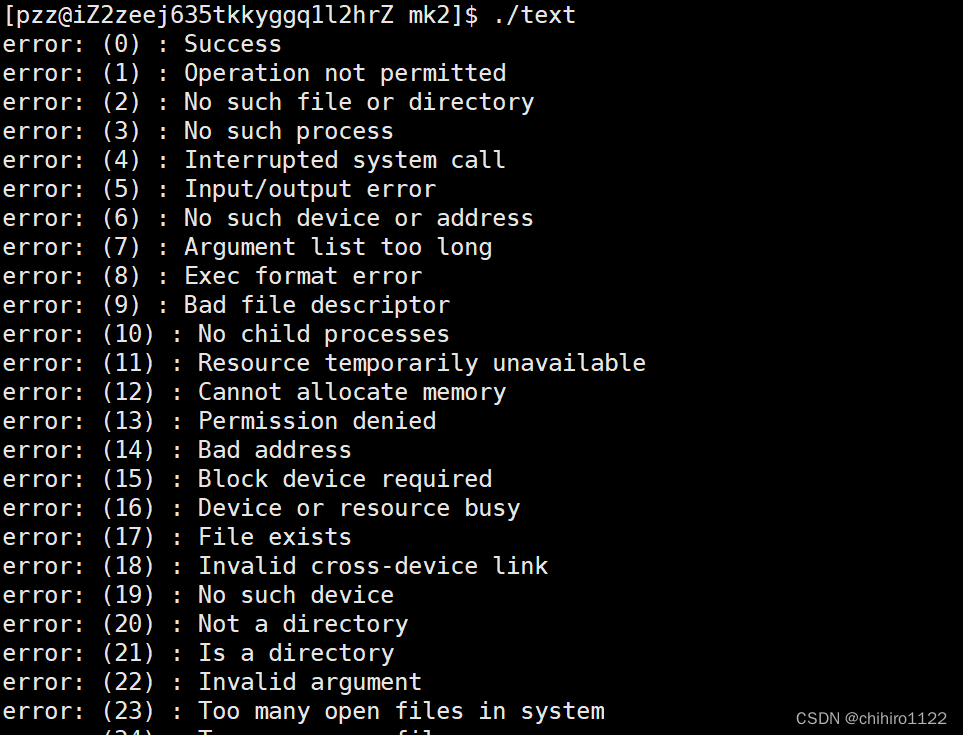
在 Linux 当中,string.h 这个头文件当中有一个 strerror()这个函数接口,这个函数就可以传入一个 退出码,把这个退出码对应的 报错信息,转换成 字符串的形式作为这个函数的返回值:

所以,我们可以简单的使用这个函数来打印一些 退出码代表的 错误信息来查看:

输出:
所以,我们在日常当中,使用各个指令,使用错误的时候,就会报一些错误:

这些错误信息就可以对应得上了。 所以,错误码和错误码对应的描述是有对应关系的。
而,父进程之所以要关心这个 子进程的 这个程序的退出码,其实就是把报错信息打印出来,做一个收集工作。
其实父进程就是一个工具人,一个跑腿的,真正关心这个子进程的 结果对不对的,是使用这个程序的用户,用户才是最关心这个程序的执行结果是不是正确的。
用户根据 父进程接收到的,打印在外设当中的 错误信息,根据这个错误信息, 用户才能更好的使用这个软件。
就像刚刚我们在使用 ls 查看某一个目录的时候,报错了,因为我们输入的文件在当前目录是不存在的,所以它报错“找不到这个文件”。然后,我就去查看当前目录,发现确实没有这个文件,所以用户就去看,区查找它想要访问的文件在哪里,从而正确的使用 ls 这个命令。
由此可见,使用这种方式,用户可以知道是自己使用错了,还是程序的实现出错了。这一切都是为用户服务。
所以,一个进程运行得怎么样,用户如何知道,靠的就是父进程收集这个子进程的 退出码,退出信息,转交给用户,用户才知道 这个 子进程是否运行成功。
所以,一个代码成功运行之后,返回的结果正不正确,统一采用进程的退出码来判定;而这个退出码就是 main()函数的返回值。
自己设置错误码信息
系统当中给的错误码是参考的,你想用就可以用,不想用自己写一套错误码体系也是可以的。
而且实现也是非常的简单,只需要定义一个保存 错误码信息的 全局字符串数组即可。这个字符串数组每一个 元素是一个字符串,那么这个数组的下标代表的就是 每一个字符串代表的错误信息描述所对应的错误码:
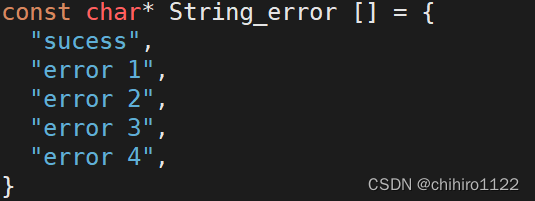
C语言当中的 errno 全局变量
与上述的 退出码 类似的,在 C 语言当中会有一个 errno 的全局变量:
这个全局变量保存的是,最近一次执行的错误码。是什么执行的错误码呢?
在 C 当中有很多的库函数,但是我们调用库函数不是每一次都会调用成功的,比如 malloc ,realloc, fopen 这些函数,都是可能会调用失败的,当我们调用失败,这函数可能会返回 -1 或者是 NULL 的返回值。
像上述,如果我们只看这个函数的返回值的话,就只能知道这个函数究竟有没有调用成功;但是对于调用失败的情况,我们通过函数返回值只能知道 当前函数调用失败了,但是具体,为什么失败,是什么原因导致的,这个函数的返回值是不能体现的。
所以,一旦我们使用 C 当中的库函数,调用失败了,那么,就会把 这个 errno 全局变量设置为对应的数字,这里的每一个数字,和上述说过的 程序的退出码一样,是要各自的含义的。就是我们想要知道的为什么会报错的。
我们把这个数字称之为 错误码。
但是,不排除当前情况下有多个函数都报错的情况,比如:第一个函数报错了,errno 就被更新为这个函数的报错信息了;但是当 第二个报错函数出现的时候, errno 是会继续更新的。会被最新一个报错的函数的错误码覆盖。
所以,如果你想知道某一个C/C++ 程序当中,如果出错了,出错原因是什么,那么可以直接返回这个 errno 全局变量:
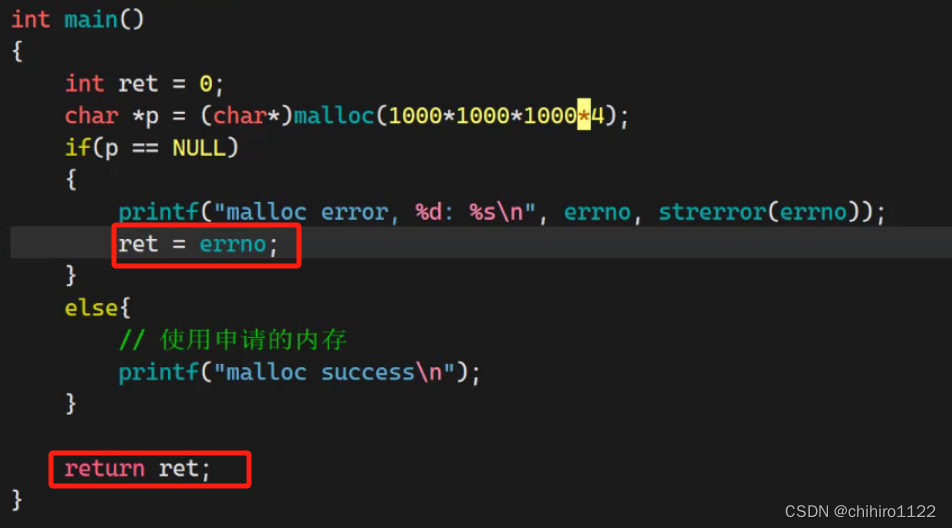
像上述的情况,就是,不仅仅 可以通过 p 变量知道当前 malloc 函数是否调用成功吗,还可以通过 ret 变量接受的 errno 的值,知道错误码是多少,然后通过main()函数返回这个错误码 给 父进程,父进程在 转交给用户,那么用户就可以知道 具体是什么原因发生的错误了。
代码异常终止的情况
代码如果出现异常终止了,那么这个代码可能就是 没有跑完(没有执行完毕)就被操作系统直接干掉了。
如果代码没有跑完,程序直接退出了,那么根本就没有执行main()函数最后一条语句(return 返回退出码),最后一步是没有执行的。
所以,退出码在此处是不是没有意义呢?
是的,退出码在此处是没用了;
就算你执意认为,就算发生异常,但是没有及时捕获,还是执行到了最后的return语句。但是,这个退出码你敢用码?程序发生异常可能在任何位置,任何时候都可能会发生异常,那么最后返回的这个 错误码一定是正确的吗?不一定吧。
就好比的是,你考试作弊考了90 分,回去你更你爸爸说,你考试考90 分,但是要被请家长,你爸爸问你为什么要被请家长,你说,在考试过程当中“发生了异常”,考试作弊比发现了;像这个例子,虽然最后你跟你爸爸说了你考试考了90 分(相当于return 90),但是 是作弊的,程序是异常退出的,你可以在考试期间作弊,也可以在 考试最后作弊,但是不管在那个时候作弊,就是作弊了,那么你爸爸会相信你考的90分吗?
所以,当一个进程以 异常退出的方式结束的话,程序的退出码就没有意义了,我们也就不关心这个退出码了。
如何知道程序是异常退出的?程序是为什么异常的?
进程出现异常,本质其实是进程收到了对应的信号!
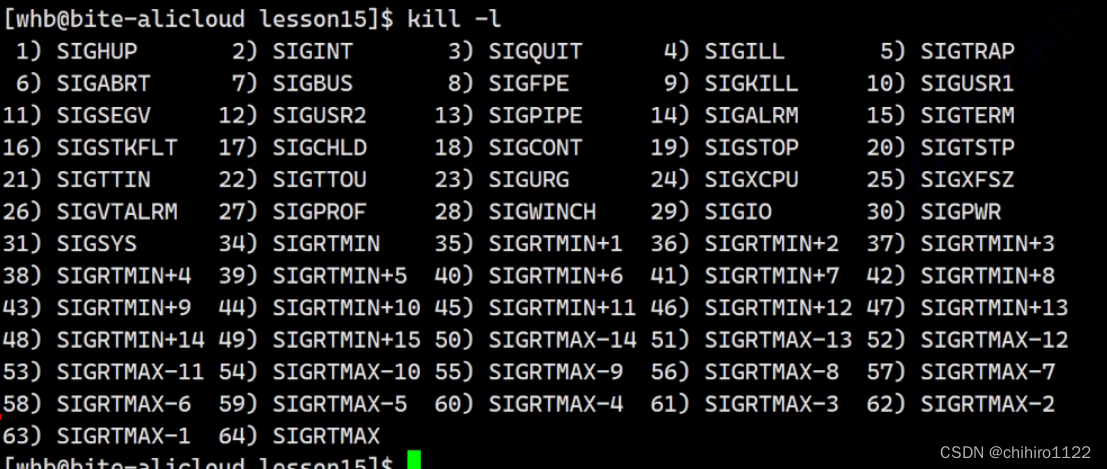
使用 kill -l 可以查看所以的信号代表的是什么意义:
比如:野指针访问的错误,其实访问指针指向地址空间,这个地址其实是一个虚拟地址,这个虚拟地址由页表映射到内存当中的实际存储数据的物理地址。
如果访问一个野指针的话,也就是访问某一个虚拟地址,但是这个虚拟地址在页表当中不存在,找不到这个虚拟地址的映射关系。
还是就是除数为0的情况,其实是在cpu当中的 状态寄存器就会出现溢出的情况。
像出现上述的两个情况,运行程序就会发生下面异常报错:
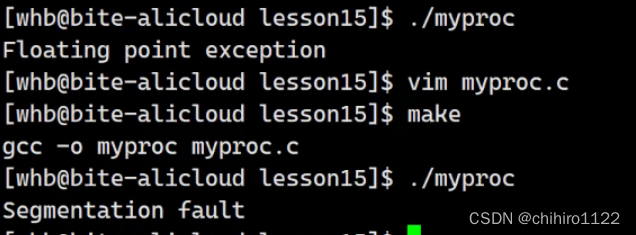
分别对应 进程信号当中的 8 和 11。
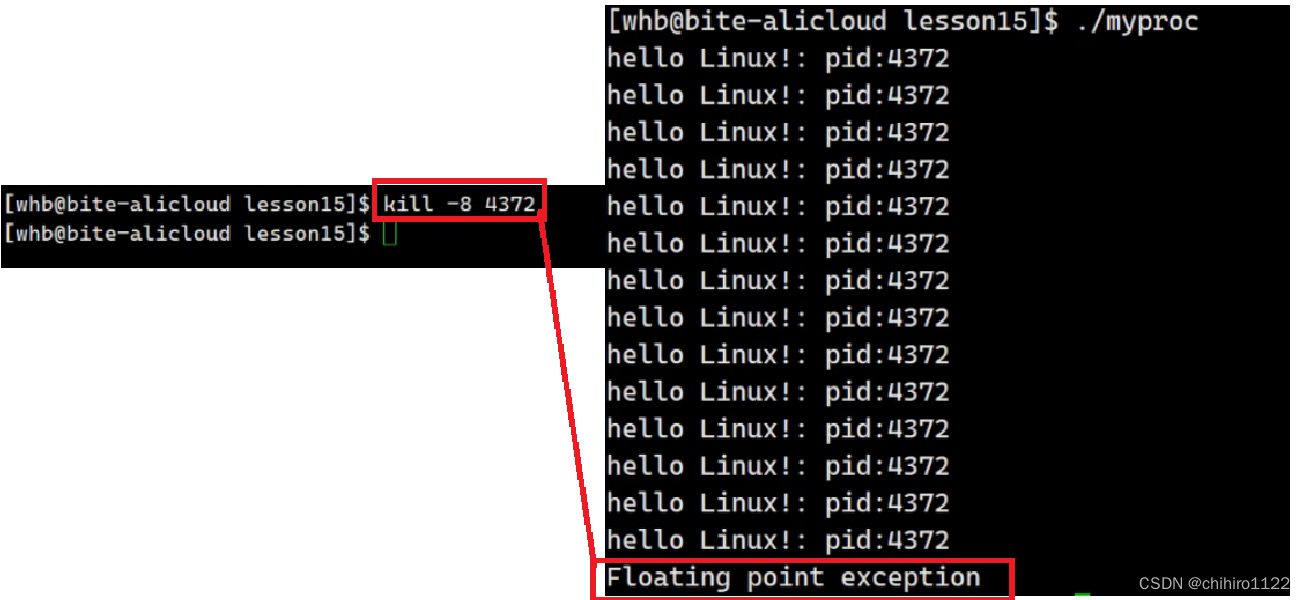
使用 kill 信号,可以给某一个进程发送某一个信号,那么这个进程就会因为这个信号而发生一些改变,比如使用 8 号信号的话,就会直接抛出 野指针的异常:
在程序当中主动退出程序(使用 exit()函数 和 _exit())
所以,父进程想要关系某一个子进程运行状态的话,首先要关心,子进程退出之时有没有接收到对应的信号,如果没有,说明程序是正常退出的,代码是跑完的;那么再去看子进程的退出码。
所以,我们在使用 exit ()函数,我们在其中可能会写 0 等等数字,这些个数字代表的就是我们想要退出这个程序所使用 退出码。
exit()函数可以在程序代码的任意地址被调用,都可以表示在exit()调用处,进程直接按照所给退出码直接退出。
而 return 和 exit()函数的区别在于,return只表示当前函数返回,程序继续向后运行。

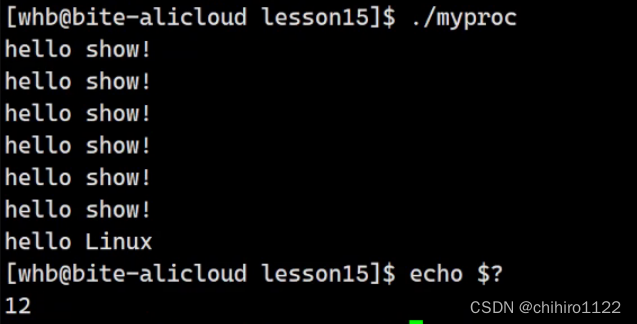
调用这个函数输出的是:


发现,最后四个的 end show 没有打印。而且,返回的是 exit()当中的13,而不是 main函数当中的 12。

上述现在使用的是 return返回,发现,返回的退出码不是 exit ()函数当中的 13,而且是在main函数当中的 12。
还有一个 _exit()函数,可以提前终止掉进程:

使用这个 函数,都可以终止进程,进程的退出码及时其中参数 status。
那么,exit() 和 _exit()有什么区别呢?
_exit()函数是纯正的 系统调用函数。当我们要终止进程的时候,是直接在操作系统内部直接终止掉这个进程,而,缓冲区当中的数据不做刷新。他会直接调用操作系统层面上的接口,直接关闭掉进程。
而 exit()函数,在终止程序之前,会先执行用户定义的清理函数,再冲刷缓冲区,关闭流等等,然后 exit() 调用 _exit()。

例子:printf()函数一定是先把数据写到缓冲区当中,在合适的时候,在进程刷新到屏幕上(这个合适的时候,比如是 遇到 "\n" 或者是 进程退出)
这个缓冲区,绝对不在 内核区当中。因为是在内核区当中(也就是上图当中的 kernel 当中),那么 _exit()函数,在结束进程之时,就可以在内核区当中对缓冲区当中的数据进行刷新,但是实际上是没有刷新的。所以操作系统只要维护缓冲区,那么就一定会刷新。