文章目录
- 1. 代码解读
- 1.1 代码展示
- 1.2 流程介绍
- 1.3 debug的方式逐行介绍
- 3. 知识点
1. 代码解读
1.1 代码展示
import json
import numpy as np
from tqdm import tqdm
bert_model = "bert-base-chinese"
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(bert_model)
# spo中所有p的关系标签 (text --> p label)
p_entitys = ['丈夫', '上映时间', '主持人', '主演', '主角', '作曲', '作者', '作词', '出品公司', '出生地', '出生日期', '创始人', '制片人', '号', '嘉宾', '国籍',
'妻子', '字', '导演', '所属专辑', '改编自', '朝代', '歌手', '母亲', '毕业院校', '民族', '父亲', '祖籍', '编剧', '董事长', '身高', '连载网站']
max_length = 300
train_list = []
label_list = []
with open(file="../data/train_data.json", mode='r', encoding='UTF-8') as f:
data = json.load(f)
for line in tqdm(data):
text = tokenizer.encode(line['text'])
token = text[:max_length] + [0] * (max_length - len(text))
train_list.append(token)
# 获取当前文本的标准答案 (spo中的p)
new_spo_list = line['new_spo_list']
label = [0.] * len(p_entitys) # 确定label的标签长度
for spo in new_spo_list:
p_entity = spo['p']['entity']
label[p_entitys.index(p_entity)] = 1.0
label_list.append(label)
train_list = np.array(train_list)
label_list = np.array(label_list)
val_train_list = []
val_label_list = []
# 加载和预处理验证集
with open('../data/valid_data.json', 'r', encoding="UTF-8") as f:
data = json.load(f)
for line in tqdm(data):
text = line["text"]
new_spo_list = line["new_spo_list"]
label = [0.] * len(p_entitys)
for spo in new_spo_list:
p_entity = spo["p"]["entity"]
label[p_entitys.index(p_entity)] = 1.
token = tokenizer.encode(text)
token = token[:max_length] + [0] * (max_length - len(token))
val_train_list.append((token))
val_label_list.append(label)
val_train_list = np.array(val_train_list)
val_label_list = np.array(val_label_list)
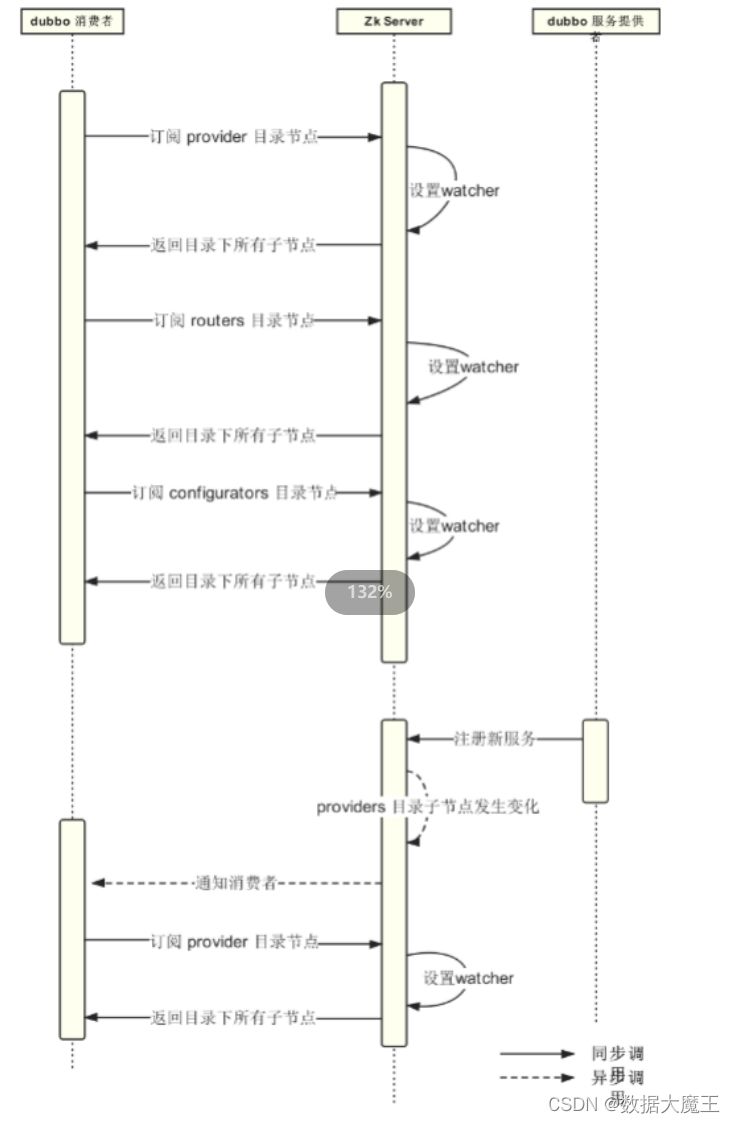
1.2 流程介绍
这段代码的整体流程和目的是为了对中文文本进行自然语言处理任务的准备工作,这里似乎是为了一个文本分类或关系提取任务。具体步骤如下:
-
导入必要的库:
json:用于处理JSON数据格式。numpy:科学计算库,用于高效地处理数组操作。tqdm:用于在循环操作中显示进度条。
-
指定BERT模型的类型(
bert-base-chinese),用于中文文本。 -
使用
transformers库中的AutoTokenizer来加载指定BERT模型的分词器。 -
定义一组中文实体关系标签(
p_entitys),这些看起来是用于文本中特定实体之间关系的标签。 -
设置一个最大序列长度(
max_length)为300,以限制处理文本的长度。 -
初始化两个空列表
train_list和label_list,用于存储训练数据的特征和标签。 -
加载并处理训练数据(
train_data.json):- 使用
json.load()读取文件内容。 - 使用
tokenizer.encode()将每行文本转换为BERT词汇表中的token IDs。 - 如果文本长度短于
max_length,则用0填充。 - 解析每个文本的
new_spo_list以构建标签向量,其中如果关系存在于文本中,则相应位置为1,否则为0。
- 使用
-
将
train_list和label_list转换为NumPy数组,以便进一步处理。 -
对验证集进行与训练集相同的处理,并存储在
val_train_list和val_label_list。
代码的目的是将中文文本及其对应的实体关系标签转换为机器学习模型可以接受的数值格式。这个过程通常是自然语言处理任务中文本预处理的一部分,特别是在使用BERT这类预训练语言模型的情况下。
你需要完成的工作可能包括:
- 确保你有正确配置的环境和库来运行这段代码。
- 如果这是第一次运行,确保你下载了
bert-base-chinese模型和分词器。 - 准备
train_data.json和valid_data.json数据文件。 - 运行代码并监视进度条以确保数据正在被正确处理。
1.3 debug的方式逐行介绍
下面逐行解释代码的功能:
import json
import numpy as np
from tqdm import tqdm
这三行代码是导入模块,json用于处理JSON格式的数据,numpy是一个广泛使用的科学计算库,tqdm是一个用于显示循环进度的库,可以在长循环中给用户反馈。
bert_model = "bert-base-chinese"
这行代码定义了变量bert_model,将其设置为"bert-base-chinese",指的是BERT模型的中文预训练版本。
from transformers import AutoTokenizer
从transformers库导入AutoTokenizer,这是Hugging Face提供的一个用于自动获取和加载预训练分词器的类。
tokenizer = AutoTokenizer.from_pretrained(bert_model)
使用from_pretrained方法创建了一个tokenizer对象,这个分词器将根据bert_model变量指定的模型进行加载。
p_entitys = [...]
这里列出了所有可能的关系标签,用于将文本中的关系映射为一个固定长度的标签向量。
max_length = 300
定义了一个变量max_length,设置为300,用于后面文本序列的最大长度。
train_list = []
label_list = []
初始化两个列表train_list和label_list,分别用于存储处理后的文本数据和对应的标签数据。
with open(file="../data/train_data.json", mode='r', encoding='UTF-8') as f:
打开训练数据文件train_data.json,以只读模式('r')和UTF-8编码。
data = json.load(f)
加载整个JSON文件内容到变量data。
for line in tqdm(data):
对data中的每一项进行迭代,tqdm将为这个循环显示一个进度条。
text = tokenizer.encode(line['text'])
使用分词器将文本编码为BERT的输入ID。
token = text[:max_length] + [0] * (max_length - len(text))
这行代码截取或填充编码后的文本至max_length长度。
train_list.append(token)
将处理后的文本添加到train_list列表中。
new_spo_list = line['new_spo_list']
提取当前条目的关系列表。
label = [0.] * len(p_entitys)
创建一个与关系标签数量相同长度的零向量。
for spo in new_spo_list:
遍历当前条目的每一个关系。
p_entity = spo['p']['entity']
从关系中提取实体。
label[p_entitys.index(p_entity)] = 1.0
在标签向量中,将对应实体的索引位置设为1.0,表示该关系在文本中出现。
label_list.append(label)
将构建好的标签向量添加到label_list。
train_list = np.array(train_list)
label_list = np.array(label_list)
将列表转换为NumPy数组,便于后续处理。
接下来的代码块与之前的相似,只是针对验证数据集valid_data.json进行操作。
val_train_list = []
val_label_list = []
初始化用于验证集的两个列表。
with open('../data/valid_data.json', 'r', encoding="UTF-8") as f:
打开验证数据文件。
接下来的代码块与处理训练数据时相同,也是加载数据、对文本进行编码、生成标签向量、然后将它们添加到相应的验证集列表中。
val_train_list = np.array(val_train_list)
val_label_list = np.array(val_label_list)
最后,同样地,将验证集的列表转换为NumPy数组。
这段代码整体上是用来处理和准备数据,使其适合输入到一个神经网络模型中去。它不仅编码文本,还构造了与之相对应的标签,这在训练和验证机器学习模型时是必需的。
3. 知识点

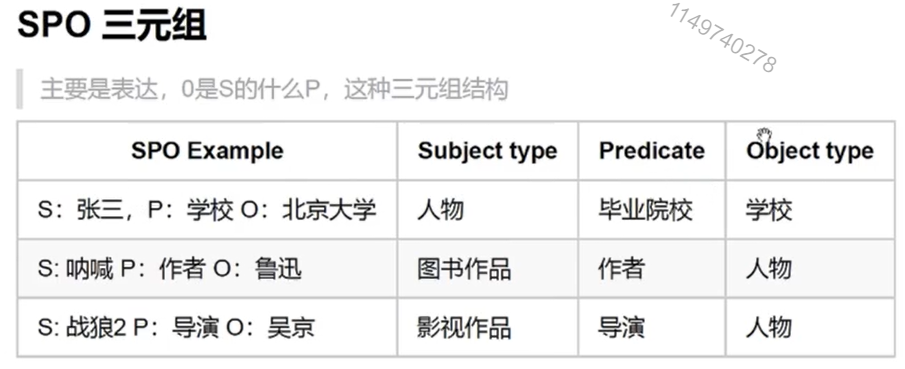
三元组解释了两个实体或者实体和属性之间的关系。
O是S的什么P,例如鲁迅是《呐喊》的导演;吴京是《战狼》的导演。





![[vmware]vmware虚拟机压缩空间清理空间](https://img-blog.csdnimg.cn/a7626de85a264efaa9c957df09fa6f43.png)