LLM 洪流滚滚,AI 浪潮席卷全球,在这不断冲击行业认知的一年中,Agent 以冉冉新星之态引起开发者侧目。OpenAI 科学家 Andrej Karpathy 曾言“OpenAI 在大模型领域快人一步,但在 Agent 领域,却是和大家处在同一起跑线上。”
在此背景下,AI 从业者坚信:基于 LLM 的 Agent 会是一个崭新并且充满着机会的蓝海领域。
那么,究竟什么是 Agent?它的框架工作方式是什么?现阶段存在哪些问题?未来有着怎样的可能性?本文将分享一些思考。
01.什么是 Agent?
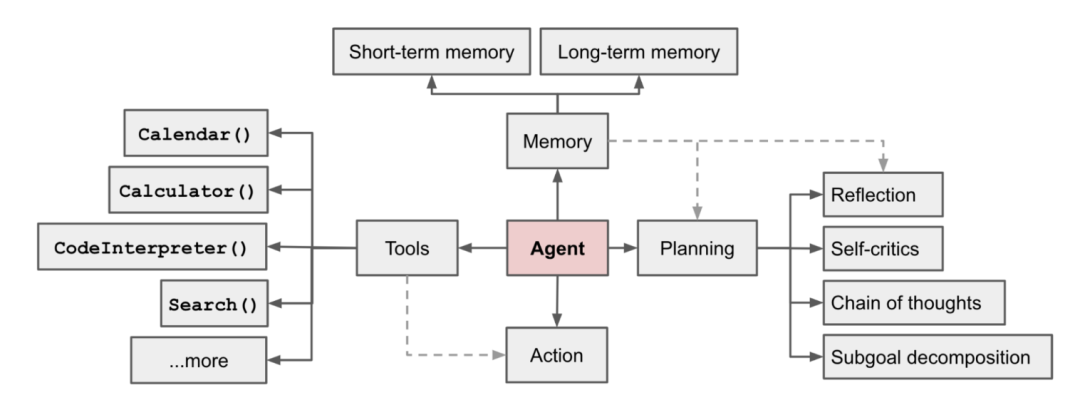
根据 OpenAI 科学家 Lilian Weng 的一张 Agent 示意图 [1] 我们可以了解 Agent 由一些组件来组成。
规划模块
-
子目标分解:Agent 将目标分为更小的、易于管理的子目标,从而更高效地处理复杂的任务。
-
反省和调整:Agent 可以对过去的行为进行自我批评和自我反思,从错误中吸取教训,并针对未来的步骤进行完善,从而提高最终结果的质量。
记忆模块
-
短期记忆:在这里通常是指 in-context learning,即利用提示工程来让模型进行一定的学习。
-
长期记忆:这为 Agent 提供了长时间保留和召回信息的能力,通常是通过利用外部向量存储和快速检索。
工具使用模块
代理学习调用外部 API 来获取模型权重中缺失的额外信息(通常在预训练后很难更改),包括当前信息、代码执行能力、对专有信息源的访问等。
所以当 Agent 接收到一个处理复杂任务的目标时,它会首先进行任务的拆解,并去执行子任务,每次大模型调用之间通过短期记忆连接,使得大模型能理解当前任务处理的状态。接下来 Agent 需要根据任务的状态来获取能够帮助模型处理任务的信息,这些信息可以是历史信息以及与任务有关的额外信息。
由于大模型拥有一定的认知能力,所以在无法精准定义所需信息的情况下,我们可以将与当前状态有相关性的信息组织起来,让大模型自主地去摘取它需要的内容。所以,比起基于关键字精准的匹配的搜索方法,向量数据库所拥有的根据语义相关性的模糊搜索在这一点上受到了 Agent 框架的广泛青睐。通过将长期记忆存放在一个数据库(向量数据库或传统数据库),并且在执行过程中根据需要进行检索,模型能够在任务的执行中获取执行经验以及认识到总体的状态。
02.Agent 框架工作方式
我们以 AutoGPT 为例,看看一个 Agent 框架具体是如何工作的:
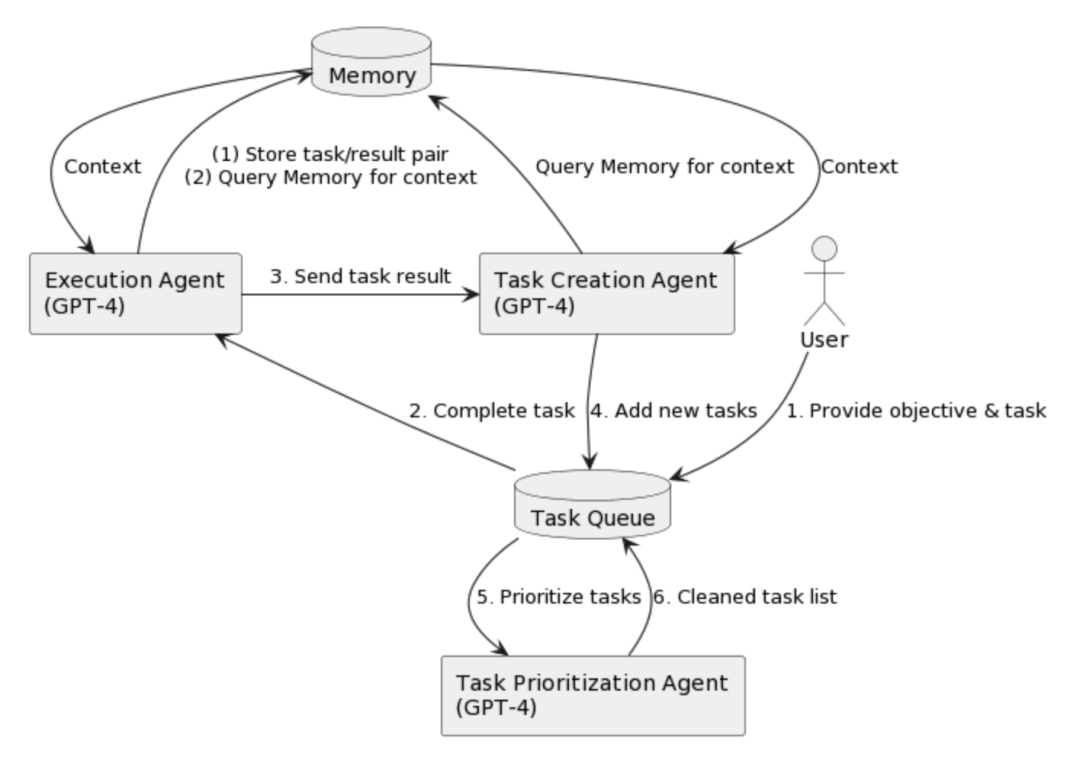
AutoGPT[2] 使用 GPT-4 来生成任务、确定优先级并执行任务,同时使用插件进行互联网浏览和其他访问。AutoGPT 使用外部记忆来跟踪它正在做什么并提供上下文,使其能够评估其情况,生成新任务或自我纠正,并将新任务添加到队列中,然后对其进行优先级排序。
另一个著名的项目 babyagi[3] 也是采取类似工作的方式。Agent 与一般的 LLM 最大的不同点在于,LLM Agent 通常根据任务的总体目标来去指定以及编排子目标,而 LLM 通常是作为一个被调用的工具,在一个工作流中担任一个具体任务的执行者。
03.LLM Agent 现阶段出现的问题
由于一些 LLM(GPT-4)带来了惊人的自然语言理解和生成能力,并且能处理非常复杂的任务,一度让 LLM Agent 成为满足人们对科幻电影所有憧憬的最终答案。但是在实际使用过程中,大家逐渐发现了通往通用人工智能的道路并不是一蹴而就的,目前 Agent 很容易在一些情况下失败:
-
Agent 会在处理某一个任务上陷入一个循环
-
prompt 越来越长,最终甚至超出最大内容长度
-
记忆模块的策略没有给 LLM 某些关键的信息而导致执行失败
-
LLM 由于幻觉问题错误使用工具,或者让事情半途而废
上述问题随着大家对于 Agent 的了解开始浮出水面,这些问题一部分需要 LLM 自身来解决,另一部分也需要 Agent 框架来进行解决,通用的 Agent 仍需进一步打磨。
04.Agent 的展望
目前,LLM Agent 大多是处于实验和概念验证的阶段,持续提升 Agent 的能力才能让它真正从科幻走向现实。当然,我们也可以看到,围绕 LLM Agent 的生态也已经开始逐渐丰富,大部分工作都可以归类到以下三个方面进行探索:
Agent模型
AgentBench[4] 指出了不同的 LLM 对于 Agent 的处理能力有很大区别,当前的 gpt-4(0613)版本以极大的优势领先于同类竞品,LLM 本身的逻辑推理能力以及更长的 prompt 处理能力都会是 Agent 中极其重要的因素。
sToolLLM[5] 则使用轻量级的 LLaMA 向更加复杂的大模型学习理解 API 和使用 API 的能力,希望能够将这种能力运用在更轻量的模型上。
Agent 框架
由 Lilian Weng 列出来的每一个组件都有探索的空间,目前学术探索较多的是利用框架提升 LLM 推理的能力,从 COT[6]、ReAct[7]、Reflexion[8] 等一系列方法,都是在不改变大模型的方法下,利用 prompt 去提升大模型的理性。关于记忆和搜索,目前普遍是将内容存储在数据库和搜索引擎中,Refexion 认为可以将执行过程中的观察以轨迹的形式存储在短期记忆中,而将接受反馈后的评估和自我反省总结的经验放在长期记忆中。在其他方向,AutoGen[9] 也在探索多智能体之间的通信与协作。
Agent 应用
实现真正意义上的 Agent 道阻且长,因为现实世界具有太多不确定性。在特定、具体的可控环境下,Agent 便可以如工厂中实现一道道供需的机器人一般,针对更多的场景特点进行针对性的设计,从而更好的去完成一些特定的任务,达到预期的效果。
MetaGPT[10] 是一个针对软件开发场景的 Agent,针对这一具体场景设计了各种具有不同技能的角色协作完成这一任务。Voyager[11] 是一个可以在 Minecraft 中可以进行自主探索、学习技能,并且会合成道具的 Agent。VoxPoser 结合了 RGB-D 信息以及 LLM 的推理能力后,可以完成更多复杂的机器人抓取操作。当下,Agent 尚不能做到完全可靠,针对更多场景的设计可以保障 Agent 不会在大部分简单场景下失败。
我们置身于一个充满无限可能性的时刻,人工智能的进步将继续塑造我们的未来,而 LLM Agent 无疑是这一演进过程中的亮点之一。人们探索人工智能,最终还是希望能够让人工智帮助人类完成自己无法做到的复杂任务,而 Agent 恰恰是从自动化走向智能化的一个关键的里程碑……
参考链接
[1]https://lilianweng.github.io/
[2]https://github.com/Significant-Gravitas/Auto-GPT
[3]https://github.com/yoheinakajima/babyagi
[4]https://arxiv.org/abs/2308.03688
[5]https://arxiv.org/abs/2307.16789
[6]https://arxiv.org/abs/2201.11903
[7]https://arxiv.org/abs/2210.03629
[8]https://arxiv.org/abs/2303.11366
[9]https://arxiv.org/abs/2308.08155
[10]https://arxiv.org/abs/2308.00352
[11]https://arxiv.org/abs/2305.16291
[12]https://arxiv.org/abs/2307.05973
本文由 mdnice 多平台发布