目录
一、什么是hive
二、为什么要使用Hive
三、Hive与Hadoop的关系
四、Hive与HDFS的关系
五、Hive与传统数据库区别
六、Hive中的数据存储是怎样的
七、对hive进行增删改查
八、排序逻辑
九、hive不支持update数据的解决方案
十、Hive中支持的分区类型有两种
十一、内置函数
十二、hive表数据倾斜问题
1、什么是数据倾斜
2、容易导致数据倾斜的场景
3、数据倾斜会引发什么问题
4、优化思路
十三、Map/Reduce gc严重
优化思路
十四、map/reduce平均运行时间过长
优化思路
十五、MapTask过多,调度开销大
优化思路
一、什么是hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能,适合离线数据处理。

二、为什么要使用Hive
直接使用hadoop很难受,如 学习成本太高、MapReduce实现复杂查询逻辑时的开发难度太大。
hive解决了这方面问题:接口采用类SQL语法(避免了去写MapReduce),提供快速开发的能力
三、Hive与Hadoop的关系

四、Hive与HDFS的关系
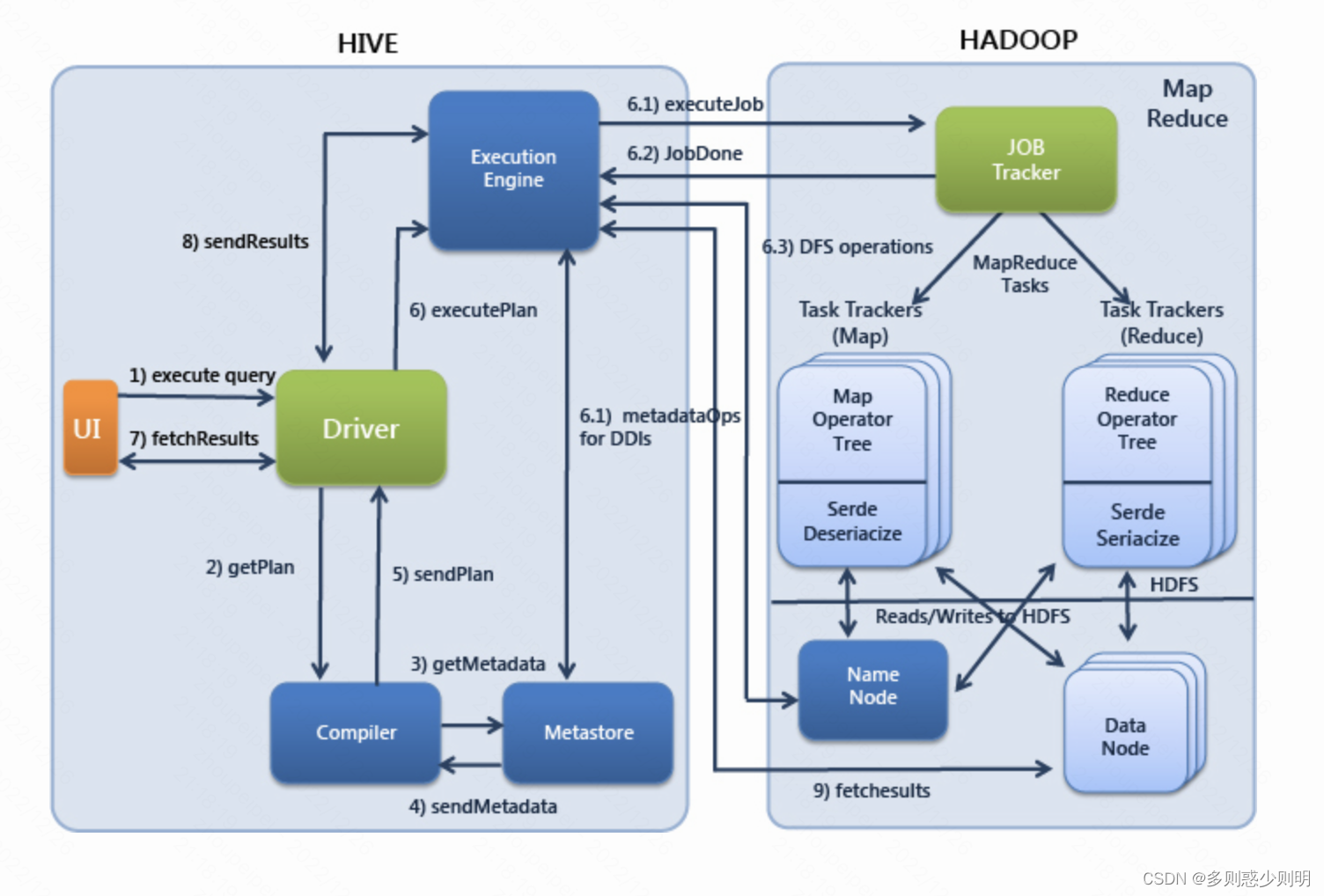
Hive利用HDFS存储数据,利用MapReduce查询数据

五、Hive与传统数据库区别
总结:hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析
ps: 类似MySQL
六、Hive中的数据存储是怎样的
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在hdfs中表现所属db目录下一个文件夹
external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
partition:在hdfs中表现为table目录下的子目录
bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
1)对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。
2)Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
七、对hive进行增删改查
1、分区表的建表:
create table TEST_TABLE
(
Field1 STRING COMMENT '字段1'
,Field2 STRING COMMENT '字段2'
,Field3 DECIMAL(18,7) COMMENT '字段3'
,Field4 INT COMMENT '字段4'
,Field5 DATE COMMENT '字段5'
,Field6 SMALLINT COMMENT '字段6'
)
COMMENT '测试表'
PARTITIONED BY
(PRT_DT STRING COMMENT '分区日期'
)
STORED AS Orc;
2、非分区表的建表:
create table TEST_TABLE_NO
(
Field1 STRING COMMENT '字段1'
,Field2 STRING COMMENT '字段2'
,Field3 DECIMAL(18,7) COMMENT '字段3'
,Field4 INT COMMENT '字段4'
,Field5 DATE COMMENT '字段5'
,Field6 SMALLINT COMMENT '字段6'
)
COMMENT '测试表NO'
STORED AS Orc
;
3、删除表 DROP TABLE TEST_TABLE;
4、清空表 truncate table source_city_list_pr_date_creator;
5、插入数据
--1、分区表插入数据
1)INSERT INTO TABLE TEST_TABLE PARTITION (PRT_DT = '2021-02-18')VALUES ('11','22',33,44,'2021-02-05',66);
2)静态分区方式,从另一个表插入数据
INSERT INTO TABLE TEST_TABLE PARTITION (PRT_DT = '2021-02-20') SELECT * FROM TEST_TABLE_NO;
--2、非分区表插入数据
INSERT INTO TABLE TEST_TABLE_NO VALUES ('1','2',3,4,'2021-02-05',6);
6、删除一个分区数据
ALTER TABLE table_name DROP PARTITION (dt='20200909');
7、删除多个分区数据
ALTER TABLE table_name DROP PARTITION (dt >="20200901",dt <='20200930')
8、删除多字段分区
ALTER TABLE table_name DROP PARTITION (dt='2020901', hour='10');
9、 删除分区内部的部分数据,这时使用重写方式对满足条件的分区进行 overwrite 操作,并通过 where 来限定需要的信息,未过滤的的信息将被删除
insert overwrite table table_name partition(partition_name='value')
select column1,column2,column2 FROM table_name
where partition_name='value' and column2 is not null
10、设置分区大小
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
set hive.exec.max.dynamic.partitions=100000;
11、查看分区
show partitions tableName;
12、查看表信息
show create table tableName;
desc tableName
13、从csv导入数据/加载数据
load data inpath '/user/test/test1.csv' into table source_city_list_pr_date_creator;
load data inpath '/test/pt_hour=2022072400' into table ods_binlog_test partition (dt='2022072400')
14、重命名表:
--ALTER TABLE [原表名] RENAME TO [新表名]
ALTER TABLE TEST_TABLE RENAME TO TEST_TABLE2;八、排序逻辑
1、order by order by是与关系型数据库的用法是一样的。select * from emp order by empno desc;
针对全局数据进行排序,所以最终只会有1个reduce,因为一个reduce对应一个输出文件,全局排序的话只能有一个输出文件,这个是不受hive的参数控制的。如果要查询的结果集数据量比较大的话,只有一个reduce运行,那么效率会非常低,所以在实际应用中一定要谨慎使用order by。
2、sort by 对每一个reduce内部进行排序,而对全局结果集来说是没有进行排序的。
1)一般在实际使用中会比较经常使用sort by。2)需要先设置reduce的数量; 设置执行时reduce的个数: set mapreduce.job.reduces=<number> 查询语句为: select * from emp sort by empno asc;
3)可以看到每个输出结果的文件中的数据都是按empno进行排好序的。
3、distribute by 类似于MapReduce中的partition的功能,对数据进行分区,一般和sort by结合进行使用。 以员工表为例,按照部门进行排序的查询语句写法如下: insert overwrite local directory '/opt/datas/distby-res' select * from emp distribute by deptno sort by empno asc
注意,distribute by必须要在sort by之前,原因是要先进行分区,然后才能进行排序。第一个文件的部门编号是30,第二个文件的部门编号是10,第三个部门编号是20。然后每个部门的员工数据都是按照员工编号进行升序排列的。
4、cluster by
cluster by是sort by和distribute by的组合,当sort by和distribute by的字段相同的时候,可以使用cluster by替代。1)参考查询语句如下: insert overwrite local directory '/opt/datas/clustby-res' select * from emp cluster by empno ;
2)注意,cluster by 后面不能指定desc或者asc,否则会报错。
总结:
order by : 全局排序,一个reduce
sort by: 每个reduce内部排序,全局不排序
distribute by:分区排序,需要结合sort by使用
cluster by: 当sort by和distribute by的字段相同的时候使用
九、hive不支持update数据的解决方案
更新数据:
频繁的update和delete操作已经违背了hive的初衷。不到万不得已的情况,还是使用增量添加的方式最好。
方法1:
insert overwrite table table1
select id,修改后的内容 as cols from table1 where id = 你修改行的id ----------先弄出你要修改的那个增量行
union all --------最后合并起来就得到所有的行
select * from table1 where id !=你想修改的内容的所在id ----------然后弄出排除旧行所剩余的所有行
方法2:用select 字段值 字段插入一条数据到表里
https://www.cnblogs.com/meirenyu/p/16575306.html
十、Hive中支持的分区类型有两种
•静态分区(static partition)
•动态分区(dynamic partition)
两者的区别:
主要在于静态分区需要手动指定,而动态分区是基于查询参数的位置去推断分区的名称,从而建立分区。
总的来说就是,静态分区的列是在编译时期通过用户传递来决定的;动态分区只有在SQL执行时才能确定。
十一、内置函数
round(double a) ceil(double a)
upper(string A) lower(string A)
trim(string A)
year(string date) month(string date) day(string date)
sum(col), sum(DISTINCT col)
count(*), count(expr),
min(col) max(col)十二、hive表数据倾斜问题
1、什么是数据倾斜
一个或少数reduce task处理的数据量远超其他task,即存在数据热点。
2、容易导致数据倾斜的场景
Join/GroupBy/CountDistinct,在存在热点key(例如某个字段存在大量空值)的时候,都会导致一个或少数reduce task处理的数据量远超其他task
3、数据倾斜会引发什么问题
根据mapreduce架构的原理,会按照key把不同的数据hash到不同的reduce task,当存在数据热点时,就会导致某些reduce task处理的数据量远远超过其他task(几倍乃至数十倍),最终表现为少量reduce task执行长尾,任务整体进度长时间卡在99%或者100%。
4、优化思路
- 过滤掉不符合预期的热点key;
- 加入随机因素,打散热点key;
- 使用map join解决小表关联大表造成的数据倾斜问题
map join是指将做连接的小表全量数据分发到作业的map端进行join,从而避免reduce task产生数据倾斜;
十三、Map/Reduce gc严重
优化思路
- 加大内存
- sql中有join和group by操作,可以调整参数缩小内存buffer检查间隔
- 可以选择关闭GBY的map端优化来争取节约内存hive.map.aggr=false;
十四、map/reduce平均运行时间过长
通常是在输入数据量不大,但是由于计算逻辑复杂导致作业执行时间特别长
优化思路
- map运行时间过长:加大map并发
- reduce运行时间过长:加大reduce并发
十五、MapTask过多,调度开销大
当sql的输入数据量太大,导致map task个数特别多,虽然每个task执行时间都不长,但是由于计算资源有限,在资源紧张的时候,一个作业内的多个task只能分批串行执行,导致资源调度开销成为任务执行时间过长的主要因素
优化思路
- 加大单个map处理的数据量,来减少map task个数
- 合理设置sql查询的分区范围,尽量避免全表扫描