目前sample中mnist提供了至少caffe、onnx的预训练模型,在TensorRT经过优化生成engine后再进行infer,两种模型的加载处理略有不同,做出简单api处理说明。 最后尝试使用最少的代码来实现整个流程。
文章目录
- 1、主要的C++ API 定义
- 2、minst示例
- 2.1、构建阶段
- 2.2、推理阶段
- 2.3、简化的代码
1、主要的C++ API 定义
目前使用主要API函数位于 "NvInfer.h" 中,根据输入的第三方支持模型类型选择 NvCaffeParser.h 或 NvOnnxParser.h。
主要的一些对象,包含基本的nvinfer1::ILogger、nvinfer1::IBuilder、nvinfer1::INetworkDefinition、nvinfer1::IBuilderConfig,模型解析nvcaffeparser1::ICaffeParser/nvonnxparser::IParser,推理运行nvinfer1::IRuntime、nvinfer1::ICudaEngine、nvinfer1::IExecutionContext,以及其他有关的基本数据结构不列举。
另外为使用方便,在项目示例common目录中提供了大量文件用于测试,例如简单的
(1) Logger对象
常规使用需要传递一个ILogger的派生类,可以实现如下
class Logger : public ILogger
{
void log(Severity severity, const char* msg) noexcept override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
}
简化使用直接使用 sample::gLogger.getTRTLogger()。
(2) std::unique_ptr对象
为通过智能指针管理资源,例如正确使用可能需要如下操作,
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger());
delete builder; // 结束使用
简化使用直接使用
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
2、minst示例
这里以加载caffe模型为例,先说明类
class SampleMNIST
{
public:
SampleMNIST(const samplesCommon::CaffeSampleParams& params)
: mParams(params)
{}
//! 构建优化网络engine
bool build();
//! engine执行infer操作
bool infer();
//! 释放所有资源
bool teardown();
private:
//! 使用caffe解析器创建mnist网络并配置输出
bool constructNetwork(
SampleUniquePtr<nvcaffeparser1::ICaffeParser>& parser, SampleUniquePtr<nvinfer1::INetworkDefinition>& network);
//! 读取输入、均值数据,进行预处理,并将处理结果保存到buffer中
bool processInput(
const samplesCommon::BufferManager& buffers, const std::string& inputTensorName, int inputFileIdx) const;
//! 验证输出是否正确并打印输出
bool verifyOutput(
const samplesCommon::BufferManager& buffers, const std::string& outputTensorName, int groundTruthDigit) const;
std::shared_ptr<nvinfer1::ICudaEngine> mEngine{nullptr}; //!< 运行网络的engine模型对象
samplesCommon::CaffeSampleParams mParams; //!< 当前示例使用的参数
nvinfer1::Dims mInputDims; //!< 网络输入尺寸
SampleUniquePtr<nvcaffeparser1::IBinaryProtoBlob>
mMeanBlob; //!< 均值blob文件数据
};
主函数运行的代码为
int main(int argc, char** argv)
{
// 命令行参数解析
samplesCommon::Args args;
bool argsOK = samplesCommon::parseArgs(args, argc, argv);
if (!argsOK){
sample::gLogError << "Invalid arguments" << std::endl;
printHelpInfo();
return EXIT_FAILURE;
}
if (args.help){
printHelpInfo();
return EXIT_SUCCESS;
}
auto sampleTest = sample::gLogger.defineTest(gSampleName, argc, argv);
sample::gLogger.reportTestStart(sampleTest);
// 当前测试对象
SampleOnnxMNIST sample(initializeSampleParams(args));
sample::gLogInfo << "Building and running a GPU inference engine for Onnx MNIST" << std::endl;
// 构建阶段
if (!sample.build()){
return sample::gLogger.reportFail(sampleTest);
}
// 推理阶段
if (!sample.infer()){
return sample::gLogger.reportFail(sampleTest);
}
return sample::gLogger.reportPass(sampleTest);
}
2.1、构建阶段
(1)创建 builder
为了创建一个builder,首先需要初始化一个ILogger示例作为参数,c++中通常使用智能指针
auto logger = sample::gLogger.getTRTLogger();
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
(2)网络模型解析
在构建网络实例的时候要指定该网络是批处理模式(Explicit Batch Mode)还是隐式(Implicit Batch Mode)。批处理模式更灵活的方式。并且如果使用ONNX网络格式则必须指定为批处理模式。
// caffe, 可以选择隐式flag
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(0));
// onne,必须使用显式flag
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
载入已训练好的模型,进行量化出来并进行推理时优化,其已经集成了各种模型格式的解析器,包括Tensorflow、ONNX、Caffe、Pytorch等。每种解析器位于不同的头文件,但是基本的API是一致的。
// caffe
auto parser = SampleUniquePtr<nvcaffeparser1::ICaffeParser>(nvcaffeparser1::createCaffeParser());
// onnx
auto parser = SampleUniquePtr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));
之后从文件中加载并解析模型文件
// caffe
const nvcaffeparser1::IBlobNameToTensor* blobNameToTensor = parser->parse(
mParams.prototxtFileName.c_str(), mParams.weightsFileName.c_str(), *network, nvinfer1::DataType::kFLOAT);
for (auto& s : mParams.outputTensorNames){
network->markOutput(*blobNameToTensor->find(s.c_str()));
}
// onnx
auto parsed = parser->parseFromFile(
locateFile(mParams.onnxFileName, mParams.dataDirs).c_str(),
static_cast<int>(sample::gLogger.getReportableSeverity()));
在当前caffe模型中,还需要读取均值,增加均值数据的读取、修改均值处理的网络。
// add mean subtraction to the beginning of the network
nvinfer1::Dims inputDims = network->getInput(0)->getDimensions();
mMeanBlob
= SampleUniquePtr<nvcaffeparser1::IBinaryProtoBlob>(parser->parseBinaryProto(mParams.meanFileName.c_str()));
nvinfer1::Weights meanWeights{nvinfer1::DataType::kFLOAT, mMeanBlob->getData(), inputDims.d[1] * inputDims.d[2]};
// For this sample, a large range based on the mean data is chosen and applied to the head of the network.
// After the mean subtraction occurs, the range is expected to be between -127 and 127, so the rest of the network
// is given a generic range.
// The preferred method is use scales computed based on a representative data set
// and apply each one individually based on the tensor. The range here is large enough for the
// network, but is chosen for example purposes only.
float maxMean
= samplesCommon::getMaxValue(static_cast<const float*>(meanWeights.values), samplesCommon::volume(inputDims));
//
auto mean = network->addConstant(nvinfer1::Dims3(1, inputDims.d[1], inputDims.d[2]), meanWeights);
if (!mean->getOutput(0)->setDynamicRange(-maxMean, maxMean)){
return false;
}
if (!network->getInput(0)->setDynamicRange(-maxMean, maxMean)){
return false;
}
auto meanSub = network->addElementWise(*network->getInput(0), *mean->getOutput(0), ElementWiseOperation::kSUB);
if (!meanSub->getOutput(0)->setDynamicRange(-maxMean, maxMean)){
return false;
}
network->getLayer(0)->setInput(0, *meanSub->getOutput(0));
samplesCommon::setAllDynamicRanges(network.get(), 127.0f, 127.0f);
(3)编译生成engine
创建一个配置config用于指明如何优化编译生成engine。
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
这个接口有很多属性用来控制优化,一个重要的属性是最大工作空间大小,用于限定网络层实现最大的控件占用,例如
config->setMemoryPoolLimit(MemoryPoolType::kWORKSPACE, 1U << 20);
//其他配置
// CUDA stream used for profiling by the builder.
auto profileStream = samplesCommon::makeCudaStream();
config->setProfileStream(*profileStream);
builder->setMaxBatchSize(mParams.batchSize);
config->setFlag(BuilderFlag::kGPU_FALLBACK);
if (mParams.fp16){
config->setFlag(BuilderFlag::kFP16);
}
if (mParams.int8){
config->setFlag(BuilderFlag::kINT8);
}
当配置指定后,就可以进行编译生成engine,其数据保存在HostMemory中。可以进一步保存在本地文件中
SampleUniquePtr<IHostMemory> plan{builder->buildSerializedNetwork(*network, *config)};
// write engine to disk file
std::ofstream ofs("engine.trt", std::ostream::binary);
ofs.write((char*)plan->data(), plan->size());
一旦序列化engine之后,之前的所有有关对象就可以进行资源释放。
注意:序列化engine不能跨平台移植或跨越不同TensorRT版本,只能指定用于特定编译使用的特定平台、特定版本、特定设备gpu上。
2.2、推理阶段
(1)反序列化
一旦我们保留好优化后的engine,后续使用仅需要进行反序列化加载再进行推理。这里需要用到运行时API接口。
// 用ILogger初始化一个IRuntime
SampleUniquePtr<IRuntime> runtime{createInferRuntime(logger)};
// 从内存数据中反序列化
mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
runtime->deserializeCudaEngine(plan->data(), plan->size()), samplesCommon::InferDeleter());
(2)执行上下文和数据管理对象
通过反序列化得到的mEngine创建一个上下文对象IExecutionContext,并初始化一个BufferManager数据管理对象用于将输入数据、执行结果在host和device之间同步。
auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
// Create RAII buffer manager object
samplesCommon::BufferManager buffers(mEngine, mParams.batchSize);
(3)输入
输入图像为 (inputH,inputW)大小的灰度图,可以先读取到内存中
std::vector<uint8_t> fileData(inputH * inputW);
readPGMFile(locateFile(std::to_string(inputFileIdx) + ".pgm", mParams.dataDirs), fileData.data(), inputH, inputW);
之后,将图像数据拷贝到BufferManager的输入数据中。注意数据类型不一致,从uint8_t转换为float:
float* hostInputBuffer = static_cast<float*>(buffers.getHostBuffer(inputTensorName));
for (int i = 0; i < inputH * inputW; i++){
hostInputBuffer[i] = float(fileData[i]);
}
之后使用异步方式将host数据拷贝到device中
// Create CUDA stream for the execution of this inference.
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// Asynchronously copy data from host input buffers to device input buffers
buffers.copyInputToDeviceAsync(stream);
(4)推理
使用enqueue函数对输入进行异步处理
// Asynchronously enqueue the inference work
if (!context->enqueue(mParams.batchSize, buffers.getDeviceBindings().data(), stream, nullptr)){
return false;
}
(5)输出
处理结果保存在device中,需要将其拷贝到host中
// Asynchronously copy data from device output buffers to host output buffers
buffers.copyOutputToHostAsync(stream);
// Wait for the work in the stream to complete
CHECK(cudaStreamSynchronize(stream));
// Release stream
CHECK(cudaStreamDestroy(stream));
const float* prob = static_cast<const float*>(buffers.getHostBuffer(outputTensorName));
prob指针指向的就是10个digtis的概率内存区域。
2.3、简化的代码
这里以onnx的模型为例,代码分为两个部分 (1)模型优化和序列化 (2)模型序列化和推理。 第一部分执行一次即可,后面部署仅需要执行第二部分。
int simple_test()
{
1. 构建优化模型、序列化 ---------------------------------------------------------
/// 1.1 基本参数
samplesCommon::OnnxSampleParams params;
params.dataDirs.push_back("data/mnist/");
params.dataDirs.push_back("data/samples/mnist/");
params.onnxFileName = "mnist.onnx";
params.inputTensorNames.push_back("Input3");
params.outputTensorNames.push_back("Plus214_Output_0");
params.dlaCore = -1;
params.int8 = true;
params.fp16 = true;
auto& logger = sample::gLogger.getTRTLogger();
/// 1.2 优化需要使用的临时变量
// builder
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(logger));
// network
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
// onnx parser
auto parser = SampleUniquePtr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, logger));
auto parsed = parser->parseFromFile(locateFile(params.onnxFileName, params.dataDirs).c_str(),
static_cast<int>(sample::gLogger.getReportableSeverity()));
// config
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if(params.fp16)
config->setFlag(BuilderFlag::kFP16);
if(params.int8) {
config->setFlag(BuilderFlag::kINT8);
samplesCommon::setAllDynamicRanges(network.get(), 127.0f, 127.0f);
}
samplesCommon::enableDLA(builder.get(), config.get(), params.dlaCore);
auto profileStream = samplesCommon::makeCudaStream();
config->setProfileStream(*profileStream);
/// 1.3 编译优化engine并序列化
// serialize
SampleUniquePtr<IHostMemory> plan{builder->buildSerializedNetwork(*network, *config)};
if(!plan) {
return false;
}
std::ofstream ofs("engine.trt", std::ostream::binary);
ofs.write(static_cast<const char*>(plan->data()), plan->size());
ofs.close();
2. 反序列化、推理 ( 后期部署仅需要后面的步骤 ) ---------------------------------------
/// 2.1 加载engine到内存
std::ifstream ifs("engine.trt", std::istream::binary);
ifs.seekg(0,std::ios_base::end);
auto buflen = ifs.tellg();
ifs.seekg(0);
std::vector<char> buf(buflen);
ifs.read(buf.data(), buf.size());
/// 2.2 反序列化
SampleUniquePtr<IRuntime> runtime{createInferRuntime(logger)};
auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
runtime->deserializeCudaEngine(buf.data(), buf.size()), samplesCommon::InferDeleter());
// inference上下文
auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
samplesCommon::BufferManager buffers(mEngine);
// 网络输入、输出信息
//auto mInputDims = network->getInput(0)->getDimensions(); // [1,1,28,28]
//auto mOutputDims = network->getOutput(0)->getDimensions(); // [1,10]
auto mInputDims = mEngine->getBindingDimensions(0); // 部署使用
auto mOutputDims = mEngine->getBindingDimensions(1); // 部署使用
int inputH = mInputDims.d[2];
int inputW = mInputDims.d[3];
// 加载一个random image
srand(unsigned(time(nullptr)));
std::vector<uint8_t> fileData(inputH * inputW);
int mNumber = rand() % 10;
readPGMFile(locateFile(std::to_string(mNumber) + ".pgm", params.dataDirs), fileData.data(), inputH, inputW);
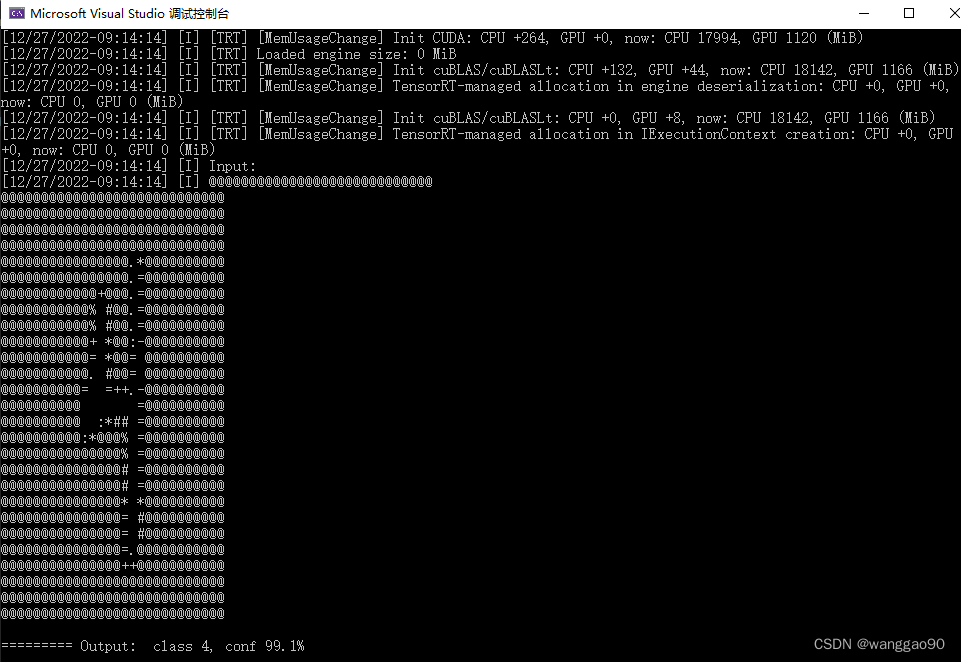
sample::gLogInfo << "Input:" << std::endl;
for(int i = 0; i < inputH * inputW; i++) {
sample::gLogInfo << (" .:-=+*#%@"[fileData[i] / 26]) << (((i + 1) % inputW) ? "" : "\n");
}
sample::gLogInfo << std::endl;
// 将图像数据从host空间拷贝到device空间
float* hostDataBuffer = static_cast<float*>(buffers.getHostBuffer(params.inputTensorNames[0]));
for(int i = 0; i < inputH * inputW; i++) {
hostDataBuffer[i] = 1.0 - float(fileData[i] / 255.0);
}
buffers.copyInputToDevice();
// excution执行推理
bool status = context->executeV2(buffers.getDeviceBindings().data());
// 将推理结果从device空间拷贝到host空间
buffers.copyOutputToHost();
/// 2.3 处理推理结果数据
float* output = static_cast<float*>(buffers.getHostBuffer(params.outputTensorNames[0]));
// softmax
std::vector<float> pred(output, output + samplesCommon::volume(mOutputDims));
std::transform(pred.begin(), pred.end(), pred.begin(), [](float d) { return exp(d); });
auto sum = std::accumulate(pred.begin(), pred.end(), 0.f);
std::transform(pred.begin(), pred.end(), pred.begin(), [sum](float d) { return d / sum; });
// argmax
auto idx = std::distance(pred.begin(), std::max_element(pred.begin(), pred.end()));
std::cout << "========= Output: class " << idx << ", conf " << std::setprecision(3) << pred[idx]*100 << "%" << std::endl;
return 0;
}
执行结果如下





![[网络工程师]-STP](https://img-blog.csdnimg.cn/6b2f663c6ea74422b7a02905de188a45.png)