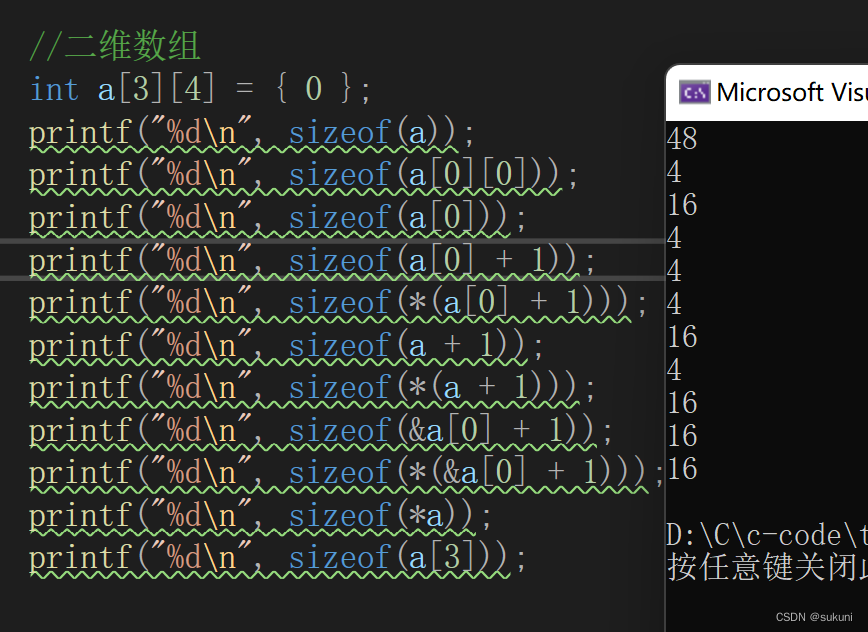
kafka快速入门
- 1、kafka简介
- 1.1 kafka是什么
- 1.2 kafka基础架构
- 1.3 kafka模块概述
- 2、kafkka结构剖析
- 2.1 kafka工作流程
- 2.2 kafka文件存储
- 2.2.1 顺序写
- 2.2.2 分片,索引
- 2.2.3 页缓存
- 2.2.4 零拷贝
- 2.3 broker集群
- 2.3.1 Controller控制器及选举机制
- 2.4 生产者
- 2.4.1 生产者分区策略
- 2.4.2 ACK机制
- 2.5 消费者
- 2.5.1 消费者分区策略
- 2.5.2 offset
- 2.5.3 消费者组
- 3、kafka总结
1、kafka简介
1.1 kafka是什么
分布式的发布订阅模式的消息队列
1.2 kafka基础架构
1.3 kafka模块概述
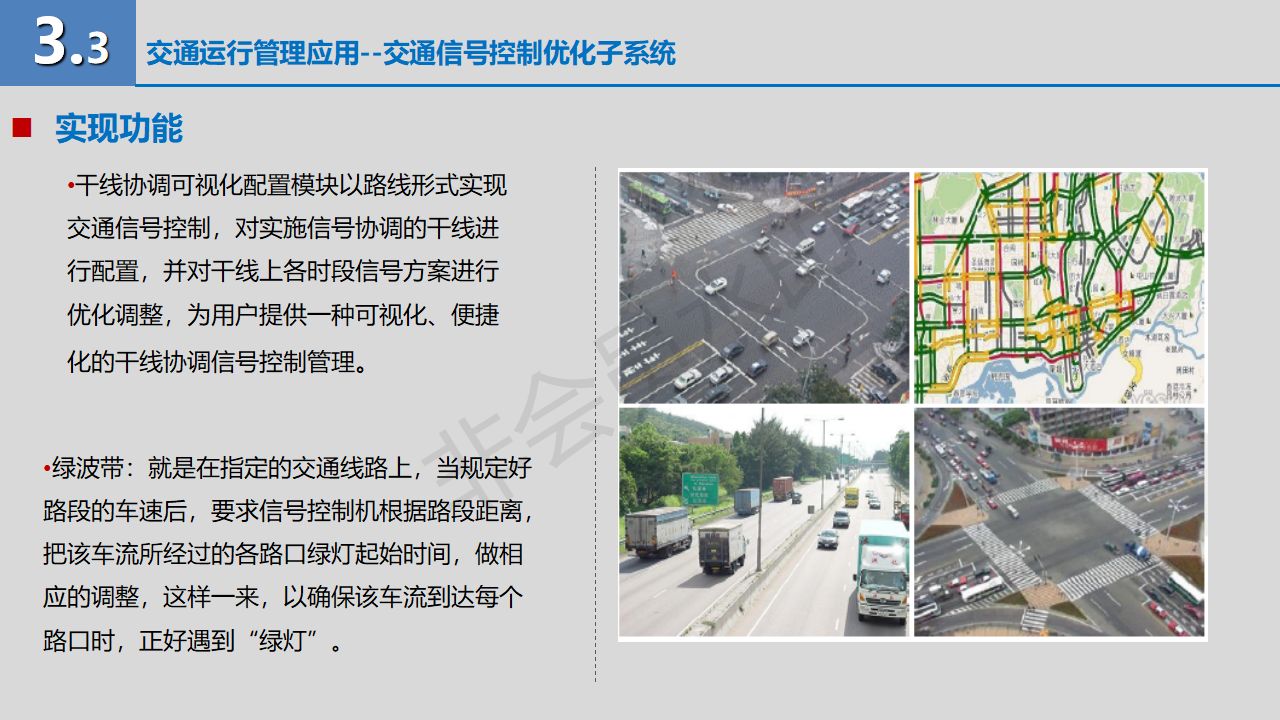
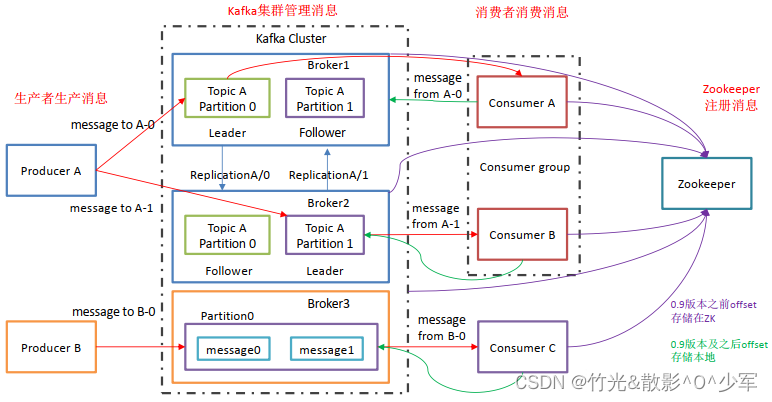
broker: 一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic
topic: kafka的消息主题,逻辑上的概念,用来进行消息分类(生产者和消费者对指定topic的逻辑)
partition: 分区,物理上的概念,一个topic有多个分区,用来进行横向拓展和提高并发
producer: 生产者,向Kafka中发布消息
consumer: 消费者,从Kafka中拉取消息消费的客户端
consumer group: 消费者组,一个消费者组被视为一个消费者,一条消息只能被一个消费者组中的某一个消费。
leader: 每个分区集的leader,负责生产者消息的存储,及消费者消息的消费
follower: 每个分区集的follower,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
ISR: 有效的副本集(leader+follower),当某个副本长时间不与leader保持同步时,将会被剔除ISR;当leader发生故障时,从ISR中选举leader。
2、kafkka结构剖析
2.1 kafka工作流程
2.2 kafka文件存储
2.2.1 顺序写
kafka只能在日志文件的尾部追加新的消息,并且也不允许修改已写入的消息。
结果: 写入速度可以达到600MB/s,而随机写入速度只有100KB/s。
2.2.2 分片,索引
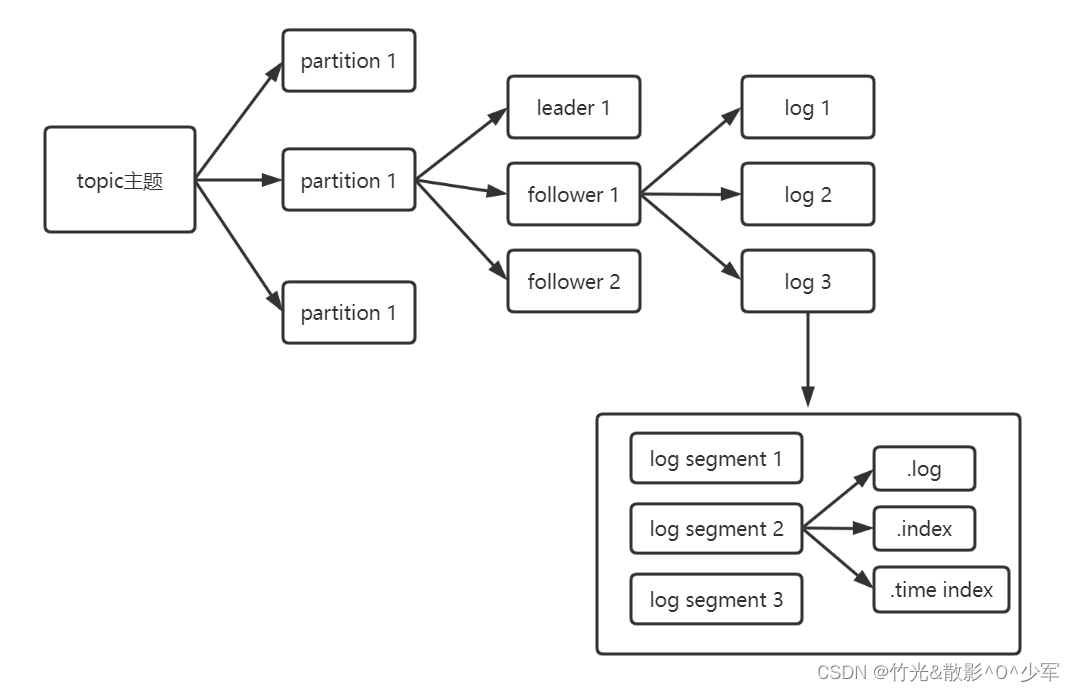
每个分区副本,实际对应一个存储的log文件;而为了防止log文件过大导致定位效率低下,log文件以1G为一个分界点,当.log文件大小超过1G的时候,此时会创建一个新的.log文件,同时为了快速定位大文件中消息位置,Kafka采取了分片和索引的机制来加速定位。
最后一个log文件为activeSegment,只对activeSegment进行追加写;当activeSegment大小满足条件时,则创建新的activeSegment。
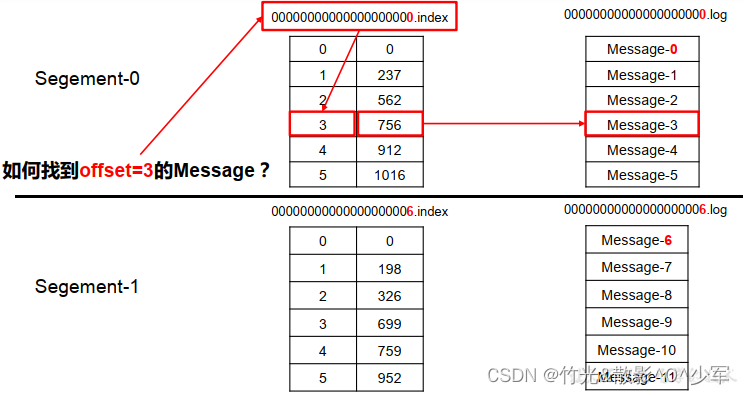
此时快速定位数据步骤:
- 首先通过二分查找.index文件到查找到当前消息具体的偏移,如上图所示,查找为2,发现第二个文件为6,则定位到一个文件中。
- 然后通过第一个.index文件通过seek定位元素的位置3,定位到之后获取起始偏移量+当前文件大小=总的偏移量。
- 获取到总的偏移量之后,直接定位到.log文件即可快速获得当前消息大小。
2.2.3 页缓存
操作系统的页缓存,将磁盘数据按页大小缓存到内存空间
2.2.4 零拷贝
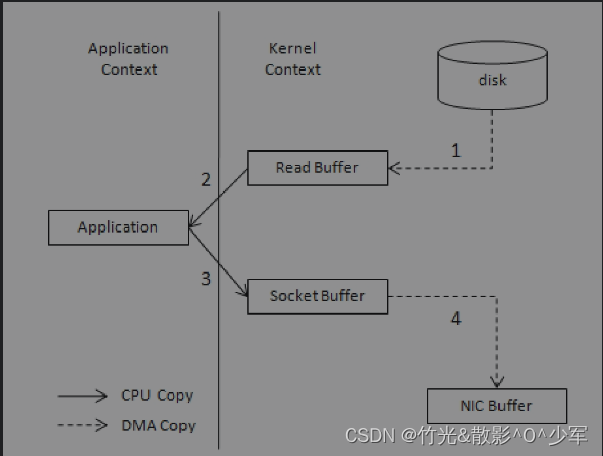
正常过程:
1、磁盘读取到内核态缓存空间
2、内核态缓存读取到用户态缓存
3、用户态缓存读取到socket缓存
4、socket缓存复制到网卡中传输
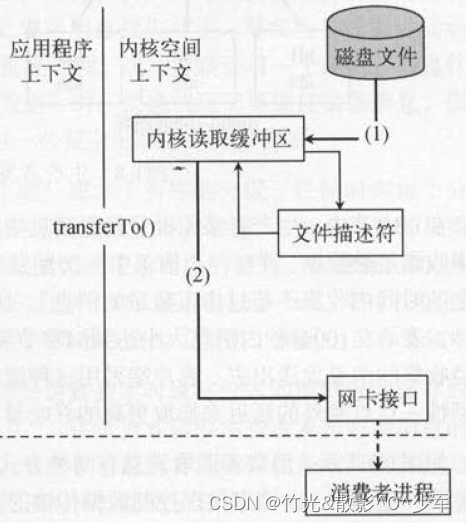
零拷贝过程:
1、磁盘读取到内核态缓存空间
2、内核态复制到网卡中
2.3 broker集群
2.3.1 Controller控制器及选举机制
控制器: 本质上是一台broker,管理集群的分区副本状态;进行leader的选举;ISR发生变化时,通知broker更新元数据
初始过程: 每一台broker在启动过程中,会独取zookeeper的/controller的brokerId值,若存在则说明有了controller,缓存此时的brokerId;若不存在,或为-1,则尝试创建这个节点,若创建成功则成为controller。
leader选举策略: 在创建分区或分区上线时,从AR中取第一个副本,并且副本存在于ISR中。
2.4 生产者
2.4.1 生产者分区策略
- 指定了partition,直接将指定的值作为partition的值
- 指定了key,将key的hash值与topic的partition数进行取余得到partition值
- 生成一个随机数,对随机数与分区数取余;之后将随机数递增,与分区数取余。
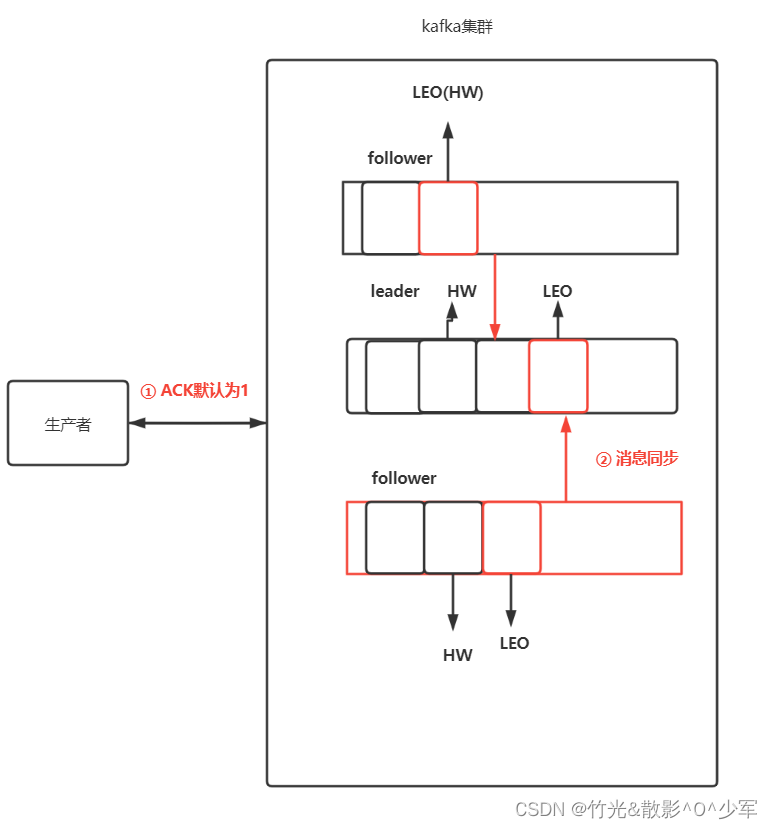
2.4.2 ACK机制
-
0:producer不等待broker的ack,这一操作提供了最低的延迟,但broker接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据。
-
1:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将丢失数据。(只是leader落盘)
kafka默认的ACK,在吞吐量与可靠性之间做的取设。 -
-1(all):producer等待broker的ack,partition的leader和ISR的follower全部落盘成功才返回ack,但是如果在follower同步完成后,broker发送ack之前,如果leader发生故障,会造成数据重复。(这里的数据重复是因为没有收到,所以继续重发导致的数据重复)
极端情况也可能数据丢失(ISR只有leader,发送完ack后leader故障)
2.5 消费者
2.5.1 消费者分区策略
- round-robin循环: 将所有待分配的分区和消费者集合起来,按照hashcode排序,再进行轮询分配。
- range: 以topic的纬度进行分区分配,列出topic的所有分区,轮询分配给订阅的消费者。
2.5.2 offset
消费者需要offset记录消费的位置,以在发生故障、重新分区分配后,能续着上一次消费的位置继续消费而不重复消费或发生消息丢失。
offset存储位置: kafka的内部topic,__consumer_offsets中。也可存储在其它位置(如db中),根据seek()方法重新指定消费位置。
offset commit问题:
- 默认自动提交,当前批次的最大offset,可能导致消息丢失
- 手动同步提交,降低吞吐量,可能导致重复消费
- 手动异步提交,可能导致消息丢失
2.5.3 消费者组
消费者需指定一个消费者组,一个分区只能被同一个消费者组中的一个消费者消费。
3、kafka总结


![[网络工程师]-STP](https://img-blog.csdnimg.cn/6b2f663c6ea74422b7a02905de188a45.png)