近日,清华大学、昆明理工大学、北京邮电大学联合在模式识别权威杂志 Pattern Recognition (IF 8.0) 上发表论文,报告了一种最大化高斯性 (Maximum Gaussianality) 的训练准则,用于对数据分布进行规整。

分布规整与标准化流模型
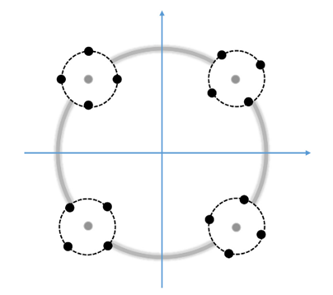
我们知道数据的概率分布对如何选择模式识别算法至关重要。通常我们希望概率分布越简单越好,最好是高斯分布,这样就可以选择简单的模型对其进行建模,进而完成分类、生成等模式识别任务。例如在随机线性区分性分析 (Probabilistic LDA, PLDA),数据必须是服从一些协方差一致的一组高斯分布,且这些高斯分布的均值本身也是一个高斯分布。形象的理解,如下图所示。
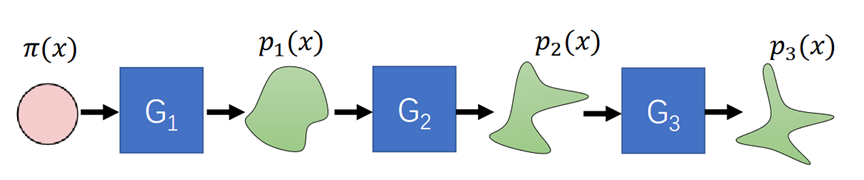
问题在于,现实应用中大部分数据都很复杂,这就必须用一个复杂的模型来建模。那么,有没有可能把一个复杂的分布映射成一个简单的分布呢?是有可能的,标准化流模型 (Normalization Flow, NF) 就是这样一个模型。它可以通过一串可逆映射把复杂分布映射到高斯分布,或反过来将高斯分布再映射回观察数据空间,如下图所示。
NF模型的天然缺陷
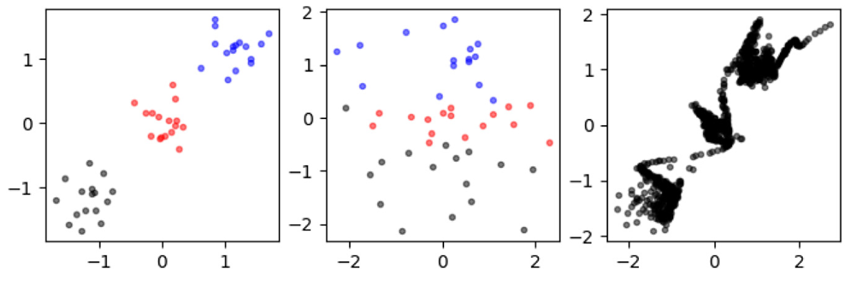
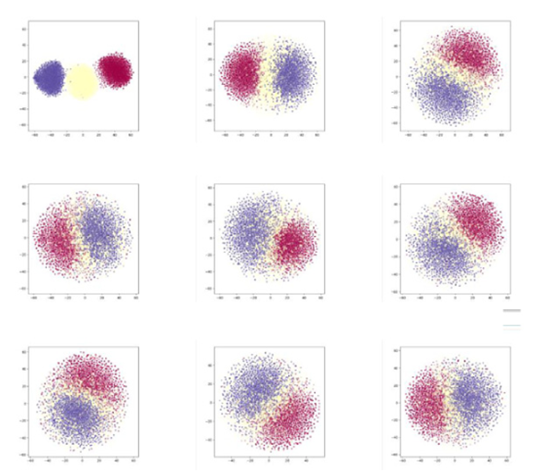
NF模型训练采用最大似然准则 (Maximum Likelihood, ML),目的是使得隐空间的高斯分布映射回数据空间后在数据样本点处的概率最大。这一ML准则在数学上没有问题,但在实际应用中很容易陷入过拟合。这是因为训练数据是有限的,而NF模型可以非常灵活,总可以通过提高每个数据样本点处的概率密度来提高整体似然值。过拟合导致NF网络及相应的高斯隐空间并不能真正代表训练数据。如下图所示,基于左侧的数据学习得到了中间图所表示的高斯隐空间;对这一隐空间进行采样并映射回数据空间后得到了右图,可见隐空间所代表的分布与原始数据分布相差甚远。事实上,这一过拟合问题是ML准则用于训练连续数据模型时的天然缺陷,本质上是连续分布的概率密度函数在有限训练样本点上的无界性造成的。
最大化高斯准则
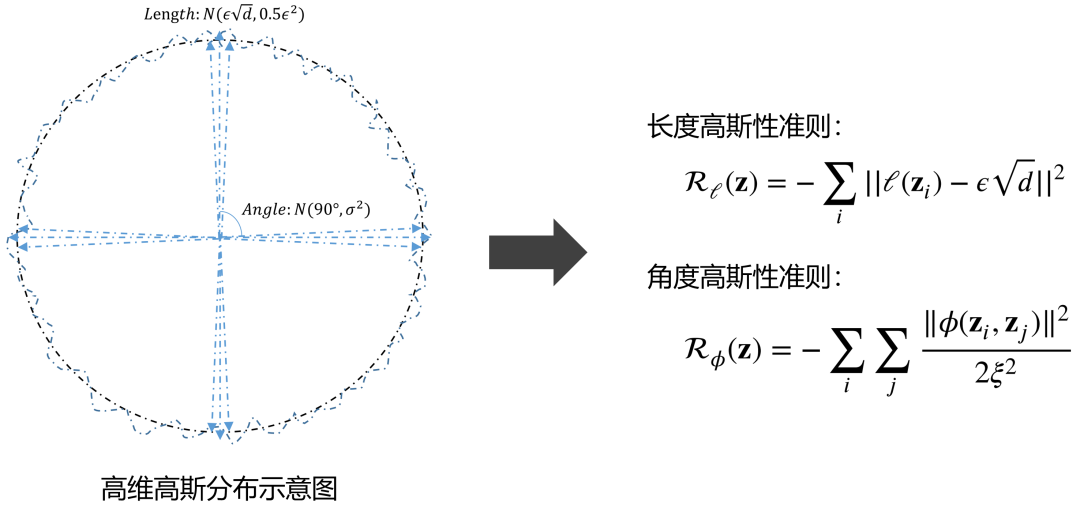
为解决这一问题,本文提出一种基于最大高斯性的训练准则,不是通过ML实现隐空间的高斯化,而是直接优化隐空间分布的属性,使之满足高斯分布条件。文章选择高维高斯分布的两项主要属性作为训练的目标:一是高维高斯分布的大部分概率集中在一个高维球壳上,因此样本向量的长度基本相同;二是从高维高斯分布采样的任意两个随机样本接近正交。基于这两条属性,文章用高斯分布来分别近似采样的长度和采样间的余弦距离,进而得出衡量高斯性的两个准则:

MG准则用于说话人向量规整
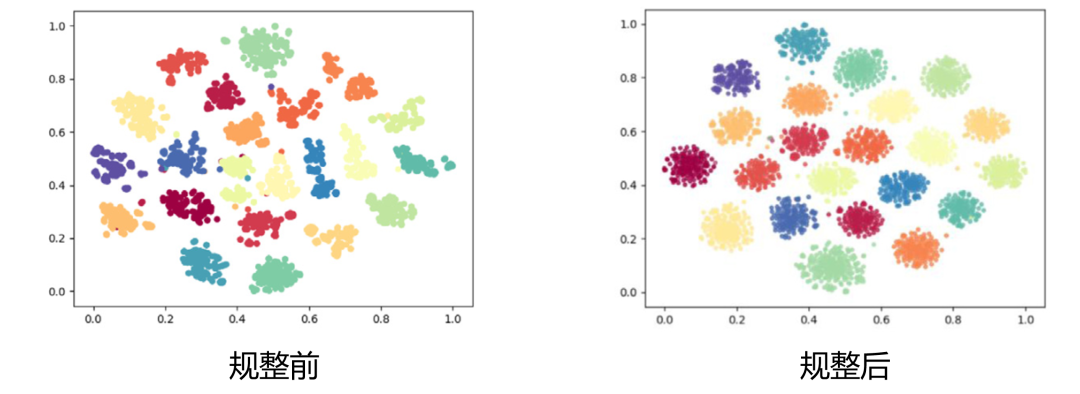
MG是一个通用的训练准则,可对任何数据做正规化。作为例子,文章将MG准则应用于说话人识别,取得了明显的性能提升。当前说话人识别依赖神经网络提取说话人向量,归因于神经网络的灵活性,说话人向量的分布不受约束(下图左),这对后端打分带来很大压力。采用MG准则对类间分布和类内分布分别做高斯化,可使得说话人向量更规整(下图右),从而有利于对说话人的辨识。
论文地址
Yunqi Cai, Lantian Li, Andrew Abel, Xiaoyan Zhu, Dong Wang. Maximum Gaussianality training for deep speaker vector normalization[J]. Pattern Recognition, 2024, 145:109977.
https://www.sciencedirect.com/science/article/abs/pii/S0031320323006751