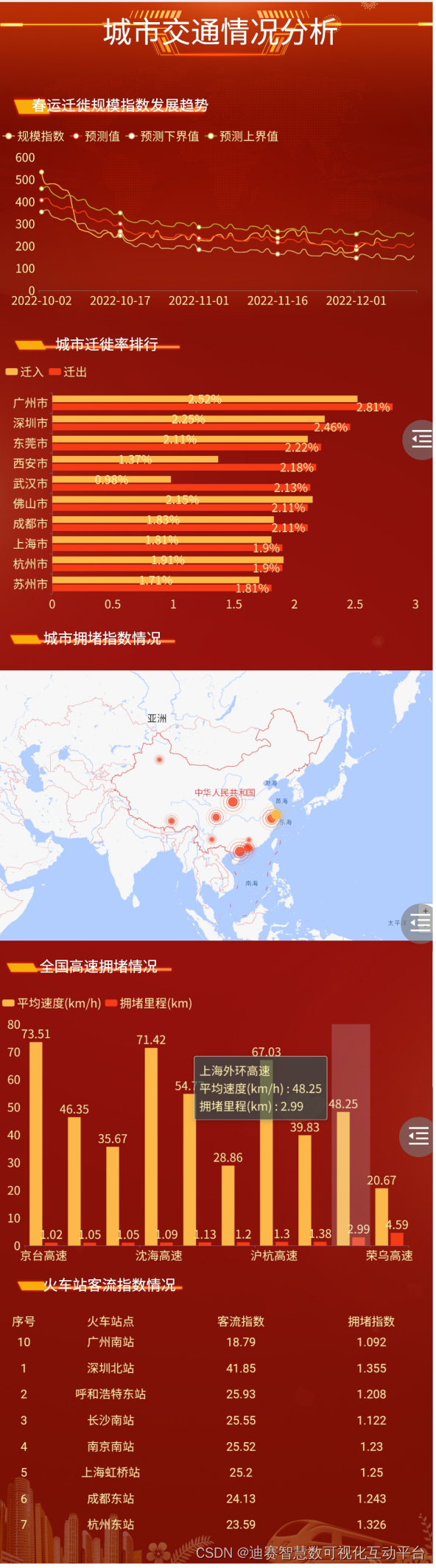
目前抠图(Image Matting)的主流算法有哪些? - 知乎什么是抠图对于一张图I, 我们感兴趣的人像部分称为前景F,其余部分为背景B,则图像I可以视为F与B的加权…![]() https://www.zhihu.com/question/68146993/answer/1914887189MODNet阅读笔记 - 知乎论文地址:https://arxiv.org/pdf/2011.11961.pdf MODNet官方git地址:ZHKKKe/MODNet 首先介绍一些matting有关的预备知识点:影像去背(英语:Image Matting)是指借由计算前景的颜色和透明度,将前景从影像中撷取…
https://www.zhihu.com/question/68146993/answer/1914887189MODNet阅读笔记 - 知乎论文地址:https://arxiv.org/pdf/2011.11961.pdf MODNet官方git地址:ZHKKKe/MODNet 首先介绍一些matting有关的预备知识点:影像去背(英语:Image Matting)是指借由计算前景的颜色和透明度,将前景从影像中撷取…![]() https://zhuanlan.zhihu.com/p/344985719
https://zhuanlan.zhihu.com/p/344985719
抠图类任务目前是基础类任务,是我们不需要去训练的,目前开源的抠图类算法很多,包括通用抠图,头部抠图,物体抠图,人像抠图,视频抠图这些目前都是有相当丰富的开源接口可以使用,通常来说,最多需要finetune一次,基本拿来即用,在基础的ai项目上,其实有很多项目都不需要在训练了,比如说目前的行人识别,行人骨骼点识别,人脸识别等很多项目主要是在部署这块,包括后处理逻辑的开发和多平台的移植这块,算法侧的训练和优化早不是重点了。这也是我们作为算法工程师需要与时俱进的地方。modnet我试过,比pphumanv2效果要好,目前字节新出来一个rvm,号称要比modnet要好,但基本是目前抠图的sota。目前比较流行的抠图算法大致可以分为两类,一种是需要先验信息trimap-based的方法,三元图类似于光流图,是一种先验信息,每个像素值为[0,128,255]其中之一,分别代表前景,未知与背景。宽泛的先验信息包括trimap,mask,无人的背景图像,pose信息等,网络使用先验信息和图片信息共同预测alpha,另一种是trimap-free的方法,仅根据图片信息预测alpha,实际应用更加友好,modnet属于后者。其中trimap-based方法包括有deep image matting,background matting v1/v2,trimap-free方法包括semantic human matting,modnet等。以后类似于抠图,图像擦除,文字擦除的通用基础视觉ai推理模块,我会单独写一个git来实践,https://github.com/leeguandong/Queban。
modnet主要就看结构图:
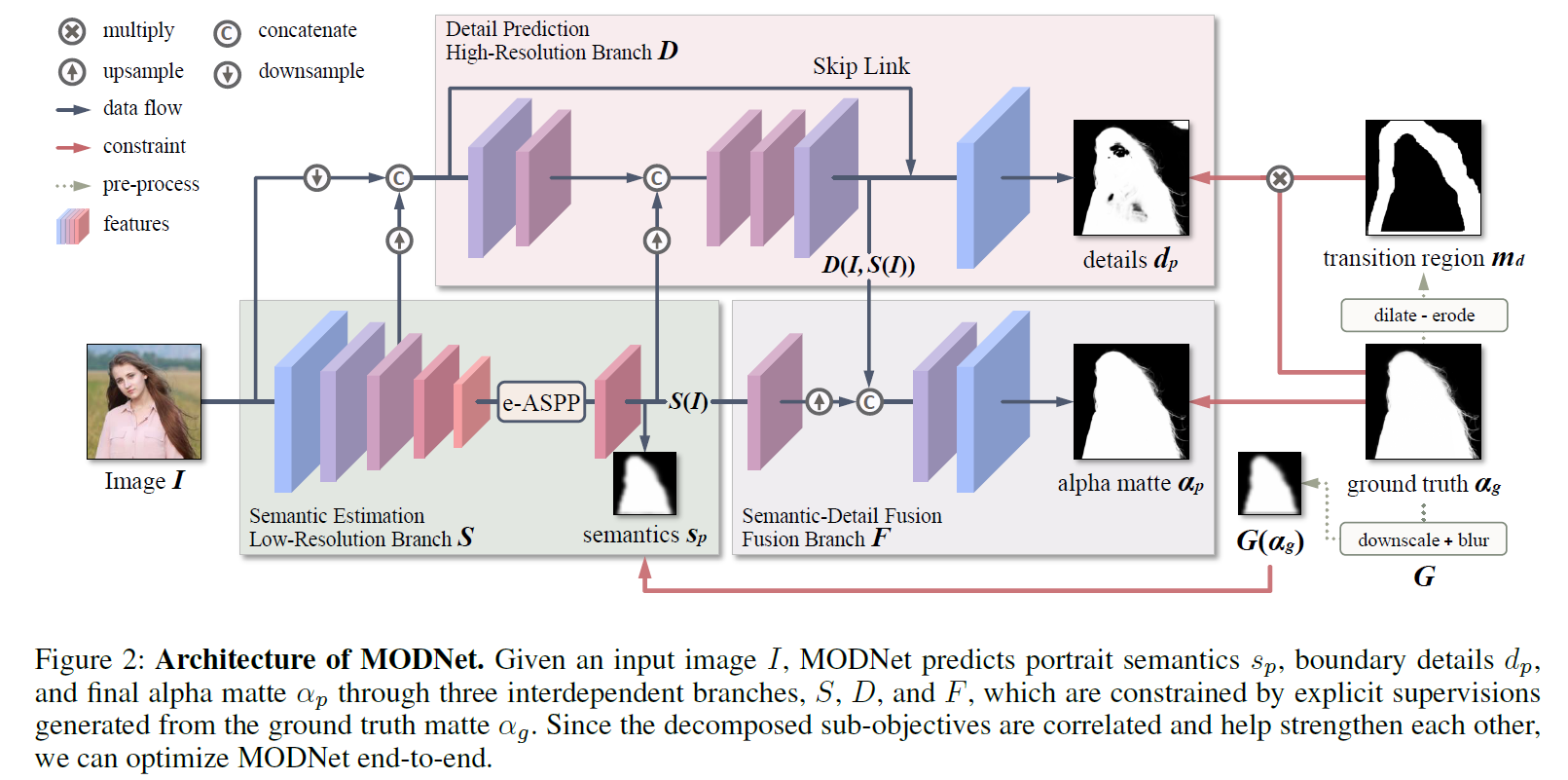
上面这张图讲了modnet的三个部分,semantic esitimation模块,low-resolution branch,S模块;Detail prediction模块,high-resolution branch,D模块;Semantic-Detail Fusion模块,Fusion branch,F模块,一共是S/D/F三个模块,这三个模块重点关注其损失函数对应的gt。
1.Semantic esitimation
S模块是一个encoder,没有decoder,输出是下采样16倍的特征图,backbone的encoder一般使用mobilenetv2这样的轻量化结构,其中还使用了e-ASPP,是ASPP的改进版本,ASPP在deeplab系列中已经证明在语义分割任务上的有效性。S模块的监督信号是将gt的matte进行downsample + gauss blur得到的,可以去掉一些语义分割用不到的细节信息,l2损失,将S(l)送入通道为1的卷积层,输出经过sigmoid得到Sp,与G(αg)计算损失,损失函数如下:
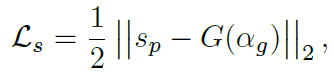
S模块主要作用是预测人像的整体轮廓,用一个低分辨率的监督信号就可以了。
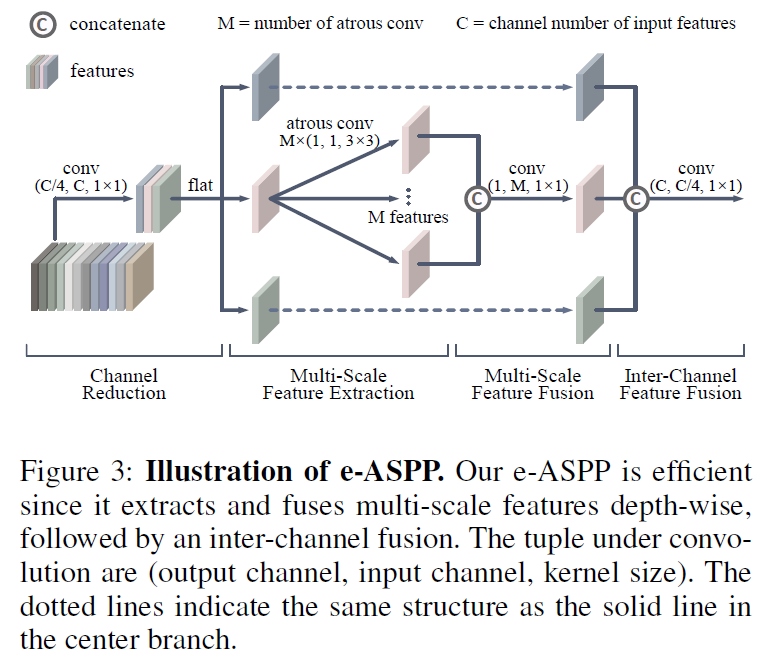
说实话类似的改进我觉得意义都不大,像这种模块的优化也很难去测评有效性。
2.Detail Prediction
D模块有三个输入,原始图像+S的中间特征+S的输出特征,D是encoder-decoder结构,其中S的输出作为decoder输入的一部分,这里多了一些特征融合的操作,l1损失,D的监督信号是:
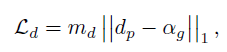
其中md是对αg进行dilate-erode操作得到的,膨胀后的结果减去腐蚀后的结果常用来做边缘检测,此处做了一个权重,人像到背景的过渡区域,md=1,其余为0,可以看出md=1即使trimap中的unkown区域,其实这里相当于对结果做了个加权,让loss只关注边缘区域,用来学习边缘细节的。
3.Semantic-Detail Fusion
F模块的输入包括了上采样的S(l)和D(I,S(l)),监督信号:
![]()
其中Lc是compositional loss,Lc是用来度量αp+原图抠出来的图像和αg+原图抠出来的图像之间的差异的,Lc相当于根据原图个位置像素取值对αp个位置的取值进行reweight。
网络最终的loss为:
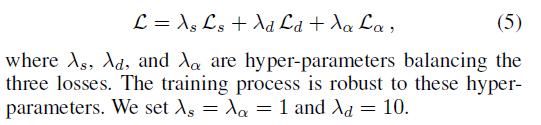
作者还提了SOC一种自监督的策略以及为了解决视频抠图中闪烁提出来的OFD策略。
modnet主要就是S/D/F三个模块,S模块为了人像定位,D模块是为了预测边缘特征,F则是最终的α,三个信号同时进行监督。