文章目录
-
目录
文章目录
前言
一.awk概念
二.工作流程
三.awk执行方式
四.awk 语法结构及案例
纯命令执行脚本
awk命令调用脚本执行
直接awk纯脚本执行
五.记录和域
概念:
六.awk的变量
总结
前言
前文已详细了介绍了文本三剑客的其中两种grep 和 sed 命令,本文将介绍文本三剑客中的最后一种awk。
一.awk概念
AWK是一种用于文本处理和数据提取的工具。 它可以在命令行中使用,也可以作为脚本运行。 AWK通过处理文本流行来实现数据提取、格式化输出等功能 。
awk 还是一种编程语言环境,它提供了正则表达式的匹 配,流程控制,运算符,表达式,变量以及函数等一系列 的程序设计语言所具备的特性,它从C语言中获取了一些 优秀的思想
二.工作流程
- 第一步:自动从指定的数据文件中读取行文本。
- 第二步:自动更新awk的内置系统变量的值,例如列数变 量NF、行数变量NR、行变量 以及各个列变量1、$2等等
- 第三步:依次执行程序中所有的匹配模式及其操作
- 第四步:当执行完程序中所有的匹配模式及其操作之后, 如果数据文件中仍然还有为读取的数据行,则返回到第 (1)步,重复执行(1)~(4)的操作
三.awk执行方式
任何awk语句都由模式( pattern )和动作( action )组成
- 模式:由一组用于测试输入行是否需要执行动作的规则
- 动作:包含语句,函数和表达式的执行过程
- 简言之,模式决定动作何时触发事件,动作决定执行的处理动作
四.awk 语法结构及案例
语法结构:
纯命令执行脚本
awk 'pattern {action}' file#代表需要被执行的文件
#pattern是正文模式,用于筛选输入数据的行
#上述pattern是三种模式中的一种,剩余两种模式分别是begin和end模式
#action是执行动作,用于对符合特定条件的行执行某些操作- begin模式:处理正文之前的准备工作都在此模式下执行
- end模式:正文处理结束退出之前的工作都在此模式下执行,简称收尾模式
- 例如:awk命令是执行依次正文内容输出一个结果,想要将正文全部处理结束之后一次性输出处理结果,则需要将输出工作放到end模式下
格式:
awk 'BEGIN{ commands } {print item1,item2,……} END{ commands }' [INPUTFILE…]
#begin 模式 命令用逗号隔开 输出以空格输出参数:
- -F:指定分隔符
- -v:定义变量
- -f:从文件中读取awk脚本
- -F: '{print $2}':指定脚本
- -NR:输出指定范围的行
- -NF:输出当前行的字段数
- -OFS:指定输出分隔符
- -ORS:指定输出行分隔符
- -i:直接修改文件
案列 1:
[root@timeserver ~]# vim input
#输入多个回车制造多个空白行
[root@timeserver ~]# awk '/^$/{print "This is a blank line"}' input
This is a blank line
This is a blank line
This is a blank line
This is a blank line
#脚本调用流程为:模式条件/^$/检索空白行,匹配到一个空白行执行一个动作:print "This is a blank line案例 2:
[root@server ~]# awk 'BEGIN{print "BEGIN ...."} {print $0} END{print "The End"}' /etc/fstab
# $0 代表这一行的所有列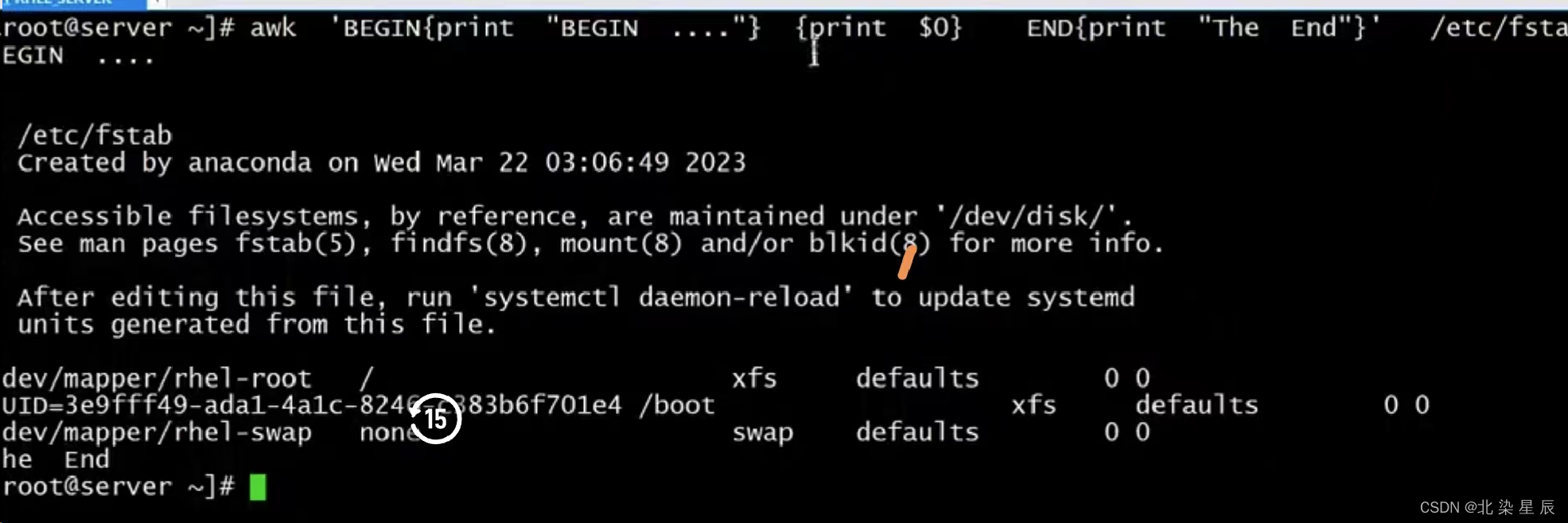
上述命令执行流程:
#首先执行begin 模式打印一个抬头信息 ....
#接着执行pattern模式处理正文(print $0),读取正文第一行的所有列然后输出,
#第一行处理结束输出之后继续处理第二行输出,awk是按行顺序进行处理的
#最后执行end模式,进行最后的收尾工作awk命令调用脚本执行
- 推荐模式和动作有多个时使用此方式执行
[root@server ~]# vim scr.awk
#编辑以下内容
/^$/{print "This is a blank line"}
#使用awk命令调用脚本执行
[root@server ~]# awk -f scr.awk input
This is a blank line
This is a blank line
This is a blank line直接awk纯脚本执行
[root@server ~]# vim scr.awk
#首先编辑抬头申明脚本解释器
#!/bin/awk -f
/^$/{print "This is a blank line"}
#使用如下命令执行脚本
[root@server ~]chmod o+x scr.awk
[root@server ~]./scr.awk inout#被处理的文件名五.记录和域
概念:
域:在awk中,域(field)是一行文本中的一个单独的数据项,通常由空格或制表符分隔。默认情况下,awk将输入行按照空格或制表符来划分域,默认为空格或tab。
记录:记录(record)是指awk处理的一行完整的输入文本。默认情况下,记录是以换行符为分隔符来定义的。在awk中,每个记录可以包含多个域,每个域可以通过域分隔符来分隔。$1表示第一个域 $0表示所有域 。
简尔言之:记录代表行,域代表列
案例1:处理每一行每一列
[root@timeserver ~]# awk '{print $0}' awk1.txt
#截取第一列为$1 第二列为$2
案例2:$之后的域使用变量定义
[root@server ~]# awk 'BEGIN{one=1 ; two=2} {print $(one+two)}' awk1.txt 
案例3:查询包含 l 的行显示第三列
[root@server ~]# awk '/^l/{print $3}' awk1.txt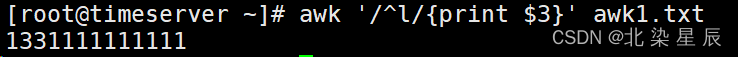
案列4: 输出所有账户
[root@server ~]# awk -F ":" '{print $1}' /etc/passwd
- awk默认识别空格来识别列与列,特殊文件中没有空格及awk默认识别的分隔符
- 需要使用参数 -F 来指定分割符
六.awk的变量
$0: 记录变量表示所有域(列) $n 字段变量,表示第n个域(列)
NF: 当前记录的域个数
NR :显示每一行的行号
FS: 输入字段分隔符,默认值是空格或者制表 符,可使用-F指定分隔符
OFS: 输出字段分隔符 ,OFS=”#”指定输出分割符 为# RS 记录分隔符,默认值是换行符 \n ENVIRON:当前shell环境变量及其值的关联数组
FILENAME:被awk处理的文件名
案列1:输出所有账户
[root@server ~]# awk 'BEGIN{FS=":"} {print $1}' /etc/passwd
#在begin 模式下设置分隔符案列2:使用 NR NF显示行数 列数
[root@server ~]# awk '{print NF,NR,$0} END{print FILENAME}' awk1.txt
#FILENAME 代表处理的文件名
[root@server ~]# awk '{print "第",NR,"行","有",NF,"列"}' > "/root/t1.txt" awk1.txt 
案例 3:
[root@server ~]# awk -F ":" 'BEGIN{OFS="\t"} {print $1,$3}' /etc/passwd案例4:
[root@server ~]# vim awk2.txt
zhangsan 68 88 92 45 71
lisi 77 69 43 52 84
wangwu 61 99 85 77 56
[root@server ~]# vim test.awk
{
print
print "$0:" , $0
print "$1:" , $1
print "$2:" , $2
print "NF:" , NF
print "NR:" , NR
print "FILENAME: " , FILENAME
}
[root@server ~]# awk -f test.awk awk2.txt
#执行过程如下
#awk按行处理,执行第一条命令
处理结果如下
zhangsan 68 88 92 45 71
$0: zhangsan 68 88 92 45 71
$1: zhangsan
$2: 68
NF: 6
NR: 1
FILENAME: awk2.txt
lisi 77 69 43 52 84
$0: lisi 77 69 43 52 84
$1: lisi
$2: 77
NF: 6
NR: 2
FILENAME: awk2.txt
wangwu 61 99 85 77 56
$0: wangwu 61 99 85 77 56
$1: wangwu
$2: 61
NF: 6
NR: 3
FILENAME: awk2.txt