引言
本博客介绍LLava1.5多模态大模型的安装教程、训练教程、预测教程,也会涉及到hugging face使用与wandb使用。
源码链接:点击这里
demo链接:点击这里
论文链接:点击这里
一、系统环境
ubuntu 20.04
gpu: 2*3090
cuda:11.6
二、LLava环境安装
1、代码下载
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
2、虚拟环境构建
conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
3、模型预测安装
pip install -e .
4、模型训练环境安装
pip install -e ".[train]"
pip install flash-attn --no-build-isolation # 可能安装失败
5、flash-attn离线环境安装
根据对应环境格式下载相应flash-attn,
flash-attn下载链接点击这里
实际为whl的离线文件,在使用pip install *.whl 即可
三、LLava推理运行
1、启动网页预测(类似服务端与客户端)
Launch a controller
python -m llava.serve.controller --host 0.0.0.0 --port 10000
Launch a gradio web server.
python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload
注:host 0.0.0.0表示自动填充本机ip,网页将其替换本机ip即可,web server启动后会有网页ip,若在其它电脑将其0.0.0.0替换运行服务器的ip即可。
2、推理权重下载
我们使用llava-v1.5-7b模型做推理。
llava-v1.5-7b权重下载
权重下载地址:点击这里
权重下载,需要使用hugging face才能下载,自己注册账号即可,文件格式如下:
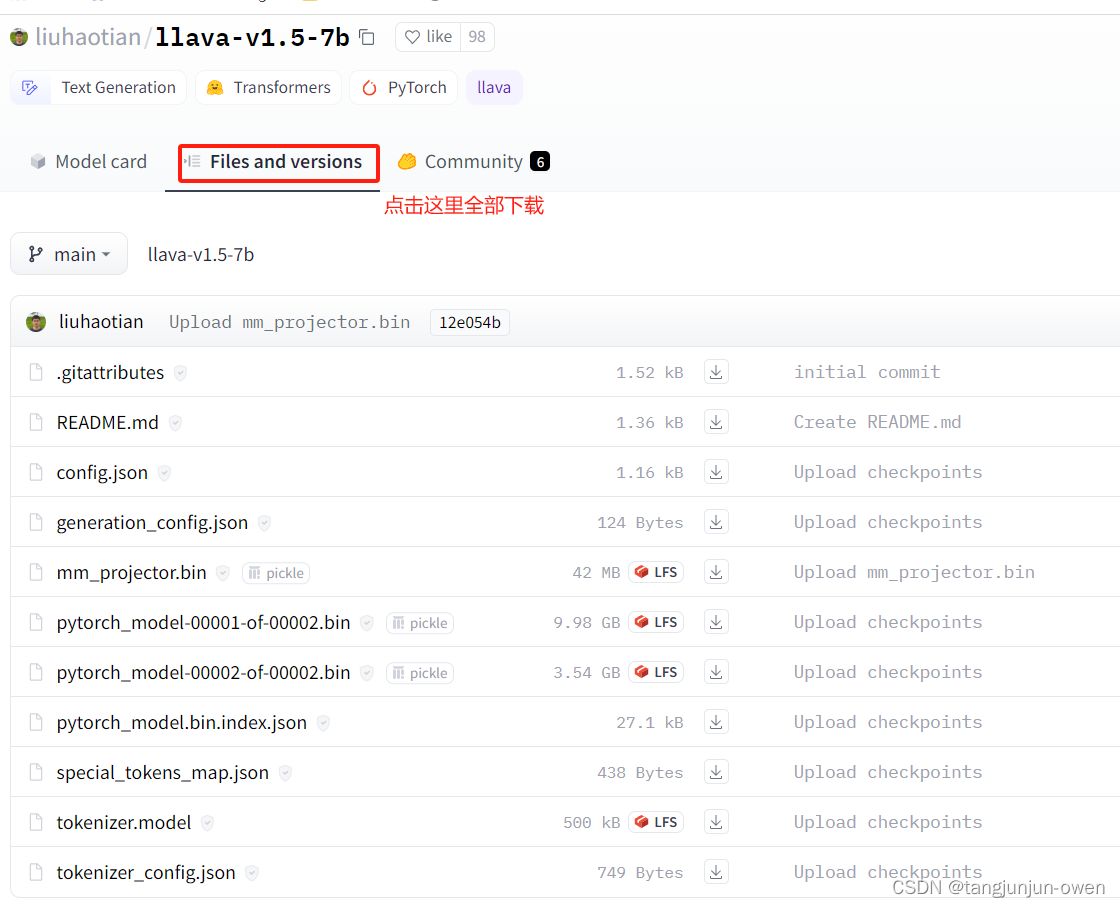
将图示文件全部下载,内有一个config.json文件,该文件很重要,部分内容如下:
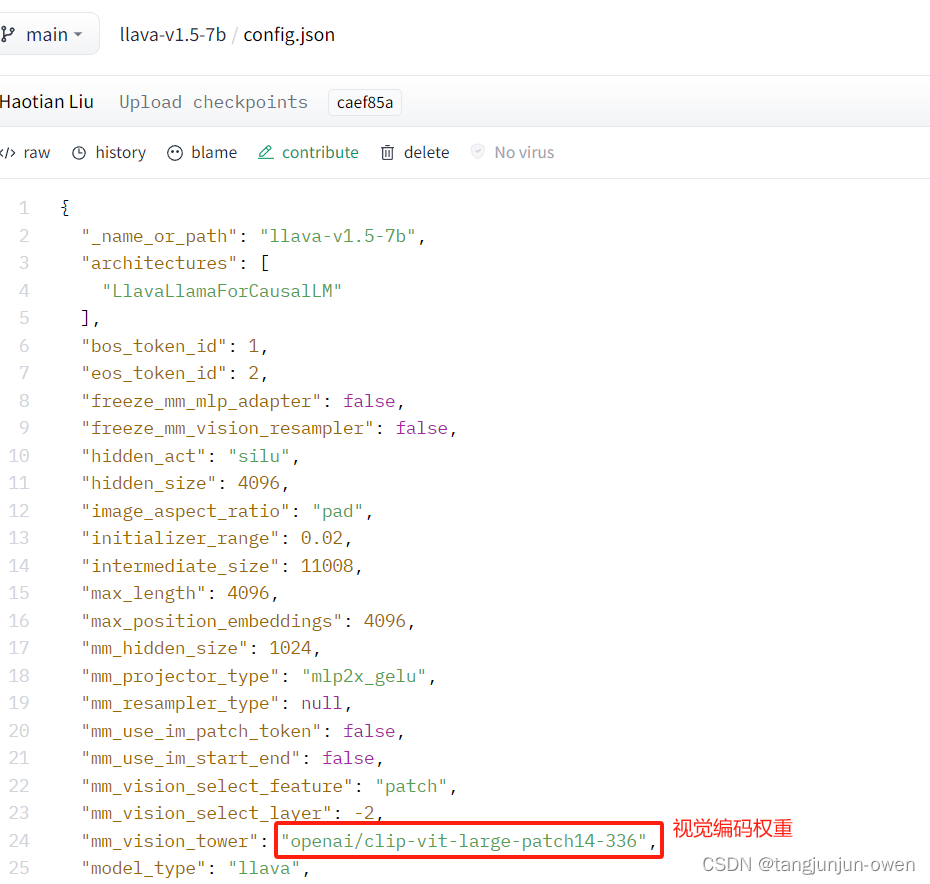
该文件可看出视觉编码也缺少相应权重,需下载如下内容,并将其路径修改本地权重保存文件。
clip-vit-large-patch14-336权重下载
权重下载地址:点击这里
该文件可通过点击链接连接,也可在hugging face自行搜索。
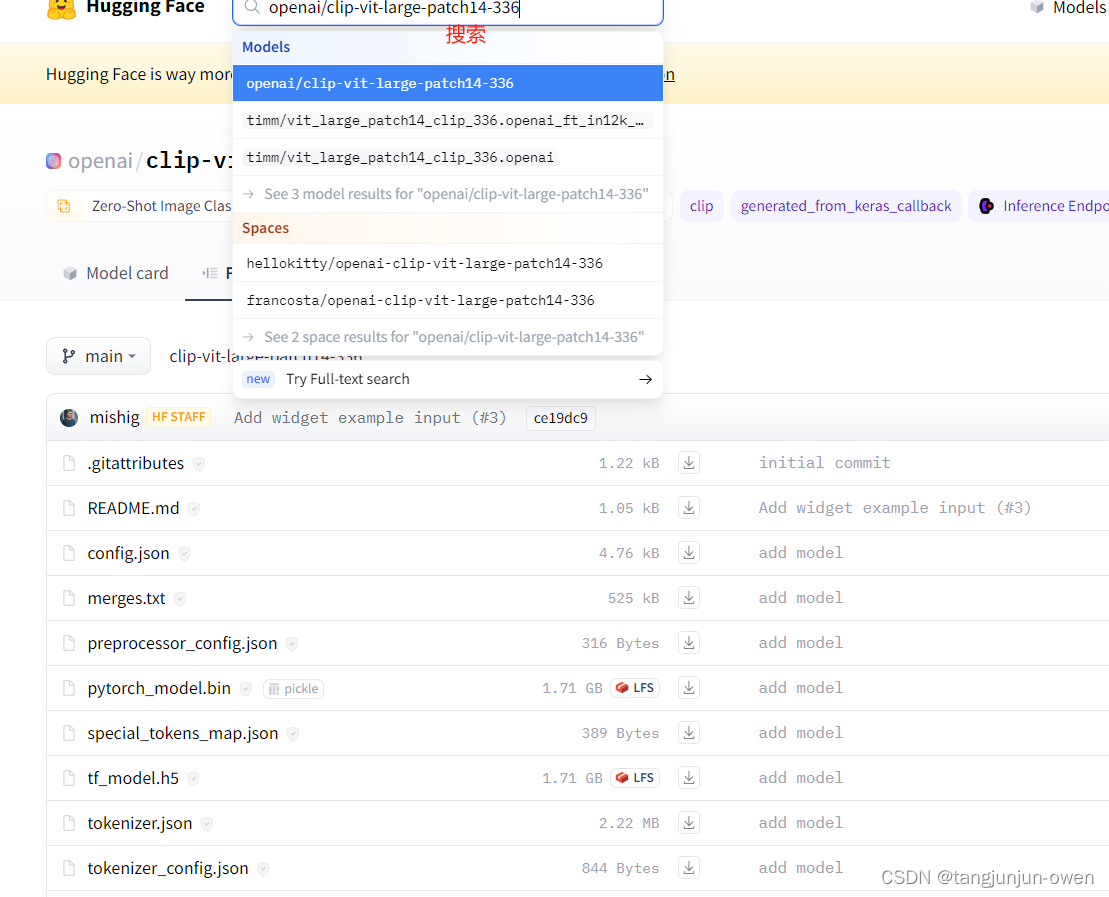
同理,也是全部下载,放到一个文件夹中。
3、启动预测模型
若已完成权重下载,便可执行以下模型启动命令,而–model-path后面需跟模型权重路径文件,若联网能范文hugging face便可无需修改直接使用官方给定命令。
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path liuhaotian/llava-v1.5-13b
–load-4bit: 该指令也可加上,使用4bit模型推理
四、LLava的lora训练
1、权重下载
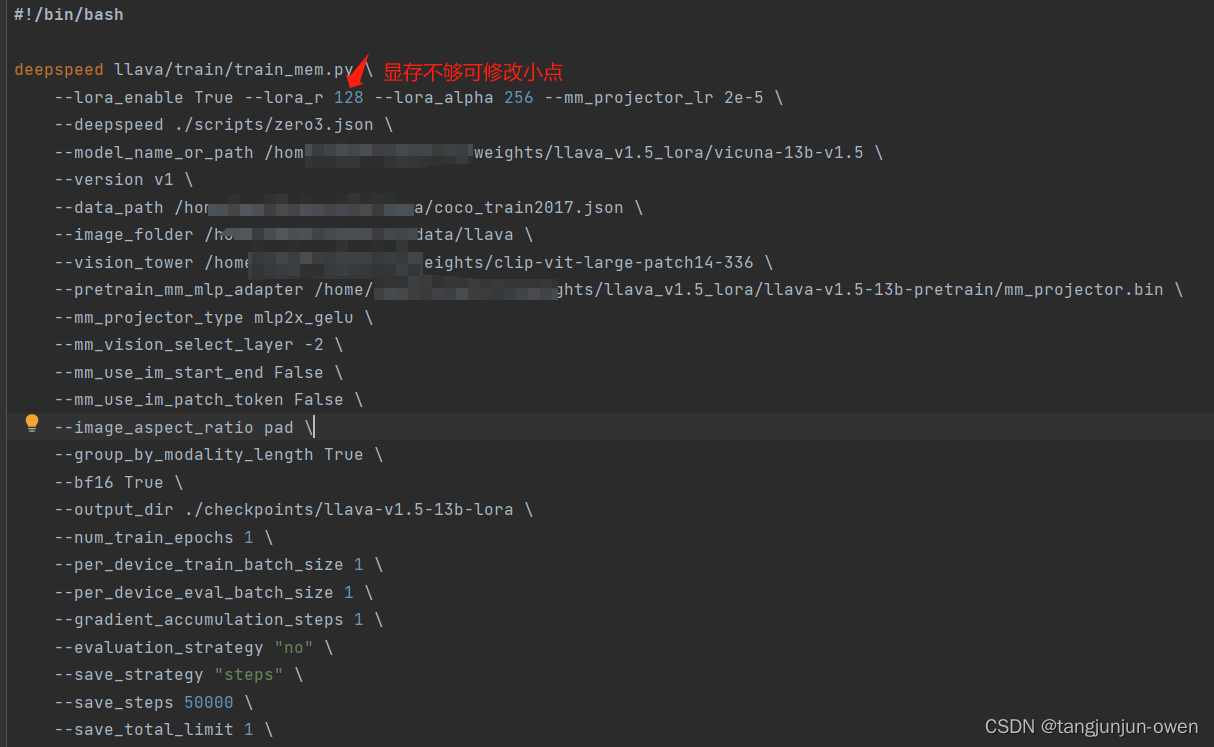
根据下图的finetune_lora.sh文件指定权重在hugging face下载即可,如下图。
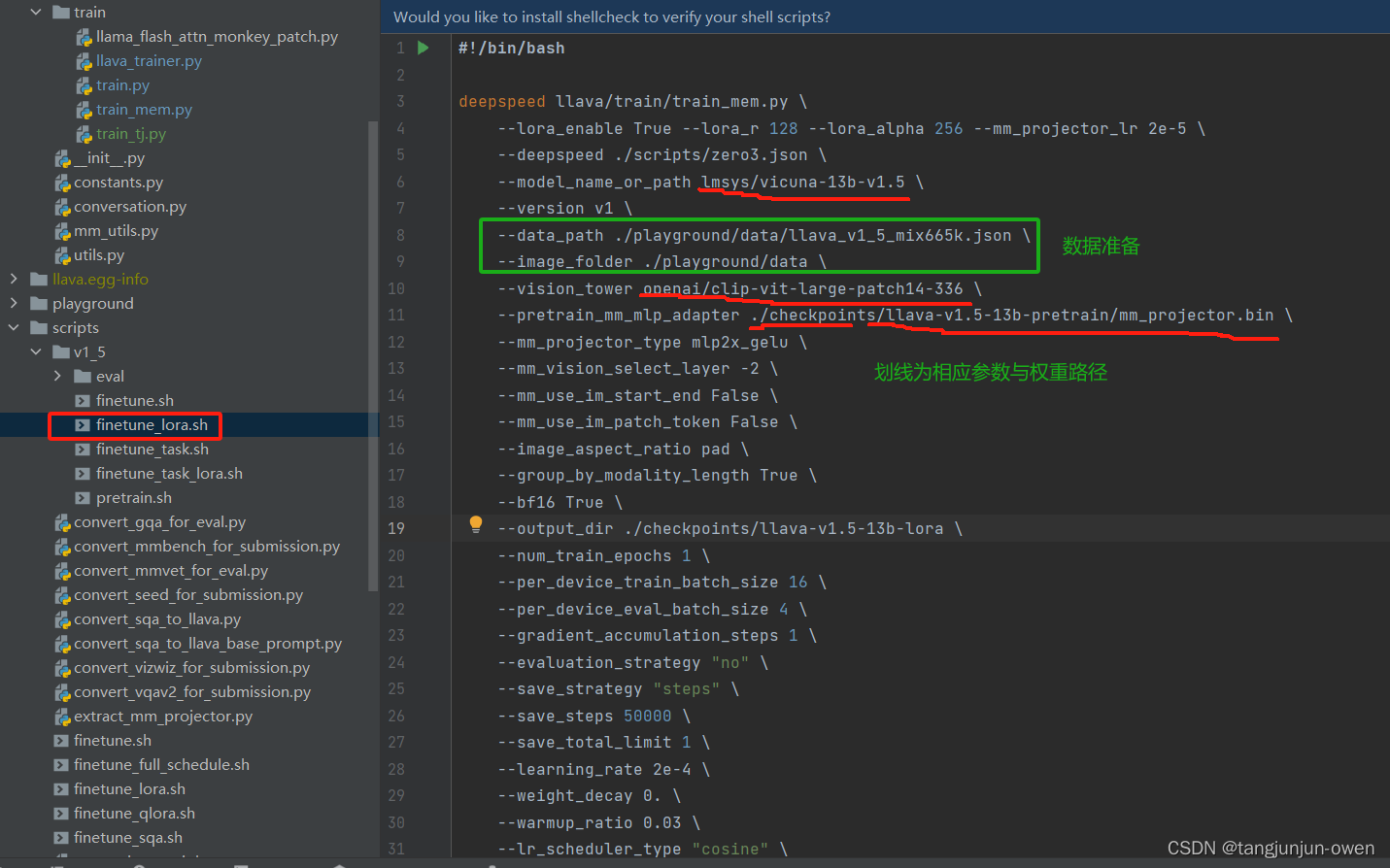
下载好对应权重,即可修改路径路径,如下:
2、数据准备
使用官网也行,若不想下载太多,使用下面代码准备部分也行,如下:
import json
if __name__ == '__main__':
json_root=r'*\llava_v1_5_mix665k.json'
with open(json_root, 'r') as f:
json_info = json.load(f)
save_info=json_info[:1000]+json_info[480000:481000]+json_info[620000:621000]
with open('info.json', 'w') as fp:
json.dump(save_info, fp, indent=4)
数据图如下:

3、训练命令
我是将其移动到LLAVA文件内,直接执行此命令:
finetune_lora.sh
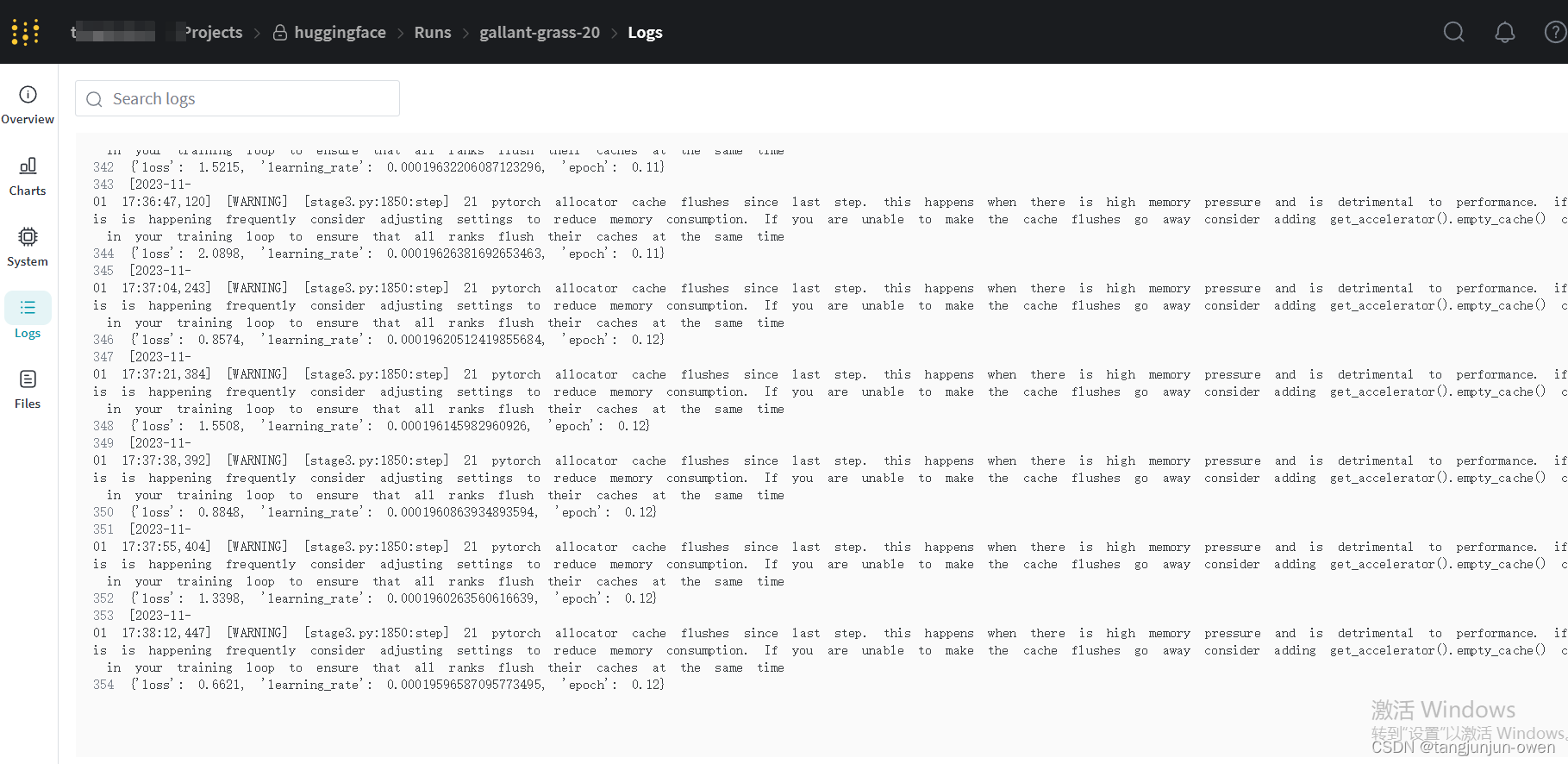
4、报错处理
模型有可能报数据错误,此时不用担心,该问题是数据的问题,如下:
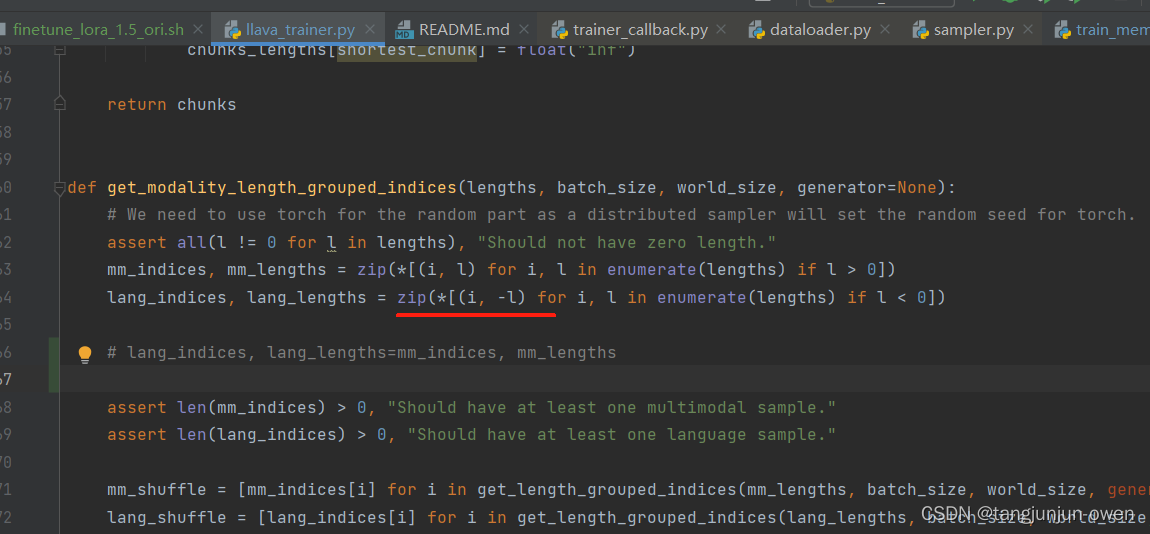
直接修改上面代码如下:
def get_modality_length_grouped_indices(lengths, batch_size, world_size, generator=None):
# We need to use torch for the random part as a distributed sampler will set the random seed for torch.
assert all(l != 0 for l in lengths), "Should not have zero length."
mm_indices, mm_lengths = zip(*[(i, l) for i, l in enumerate(lengths) if l > 0])
# lang_indices, lang_lengths = zip(*[(i, -l) for i, l in enumerate(lengths) if l < 0])
lang_indices, lang_lengths=mm_indices, mm_lengths
assert len(mm_indices) > 0, "Should have at least one multimodal sample."
assert len(lang_indices) > 0, "Should have at least one language sample."
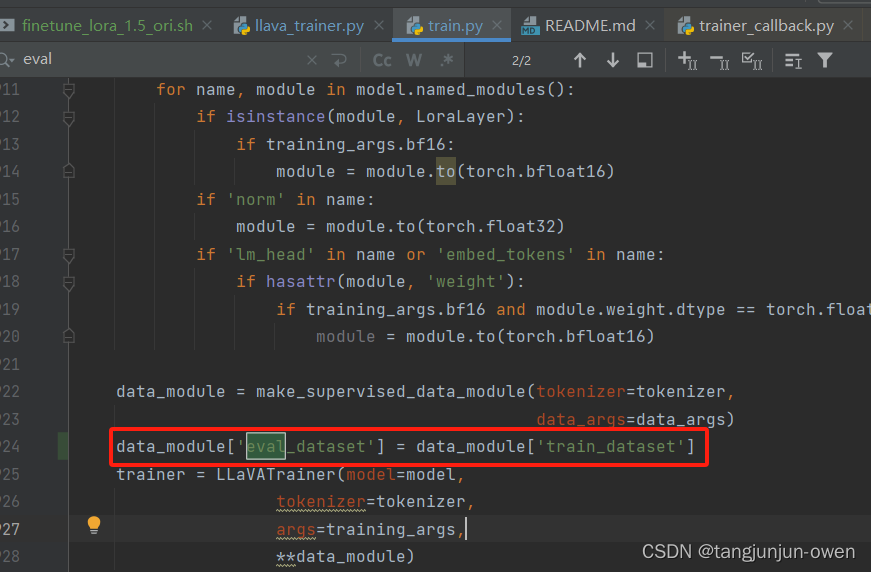
也有可能有其它数据问题,是可能无eval数据,添加以下红色框即可,如下:
5、训练效果
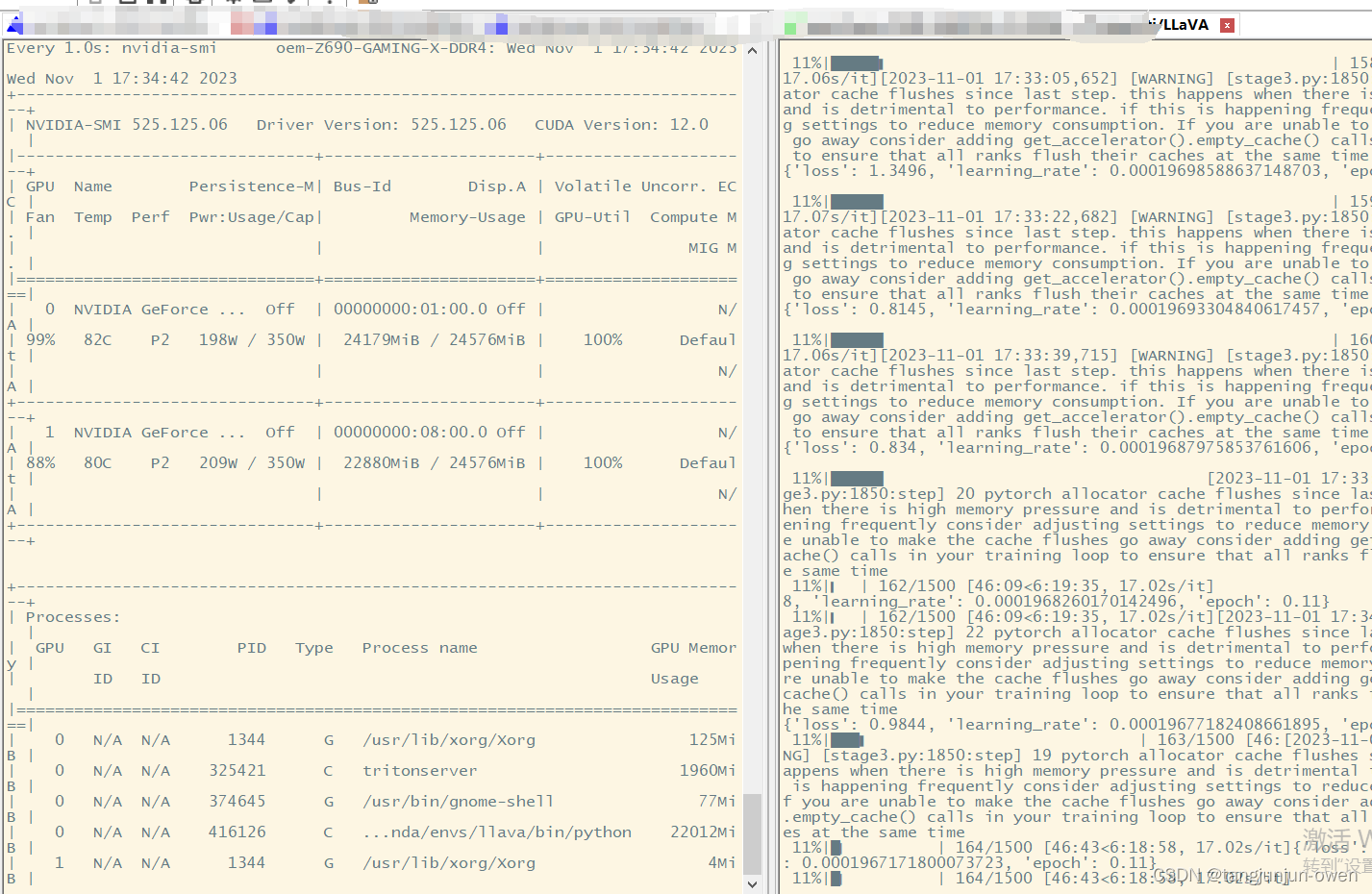
若完成以上方式,使用训练命令,可实现如下训练效果:
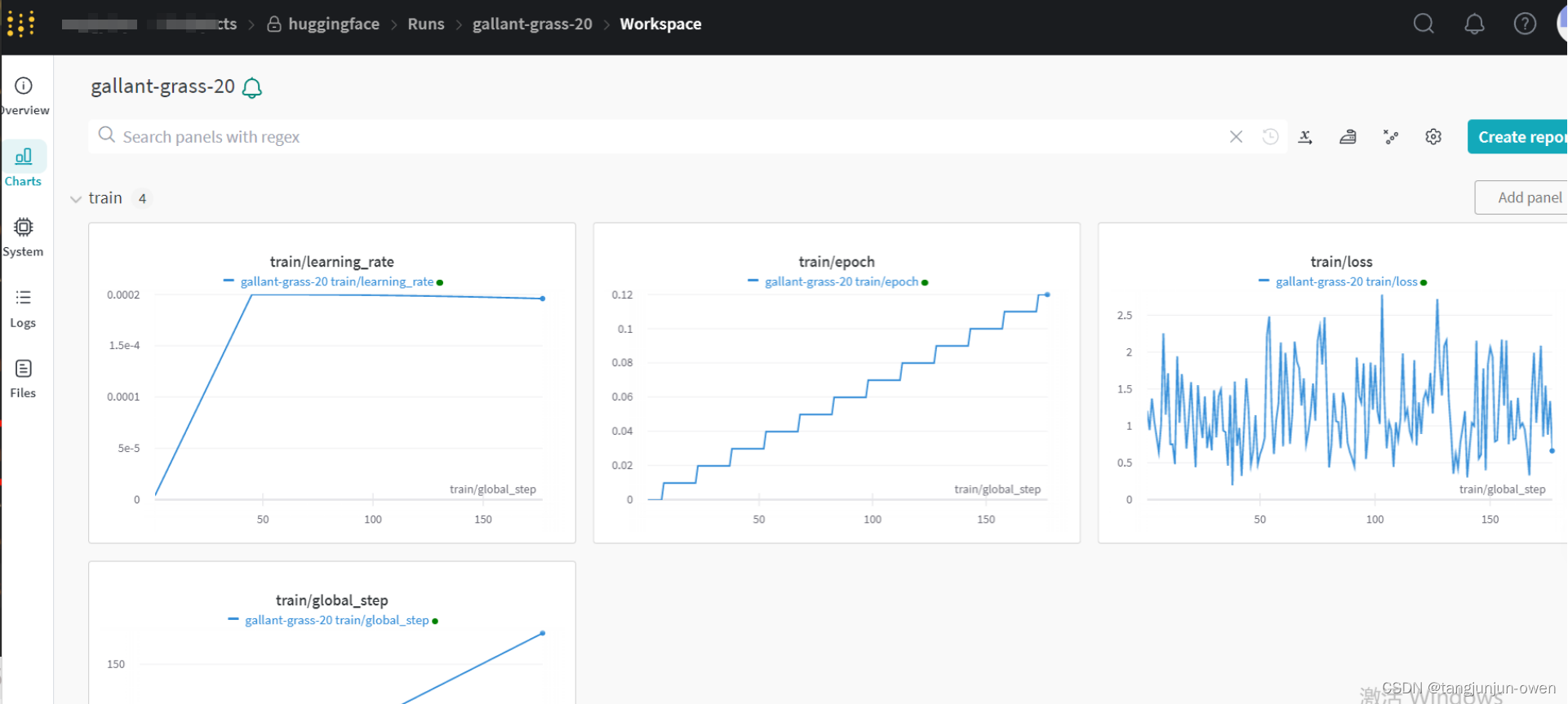
6、训练使用wandb
llava训练自带wandb方式显示化查看,训练代码会自动提醒你,你只需注册,然后将其key复制,即可实现,其效果如下:
总结
以上便llava所有运行过程,愿踩过的坑对你有帮助。最后,我额外说下,我使用4090显卡搭建,跑测试问题不大,大概16g左右吧,跑训练一张24G卡有些够呛。