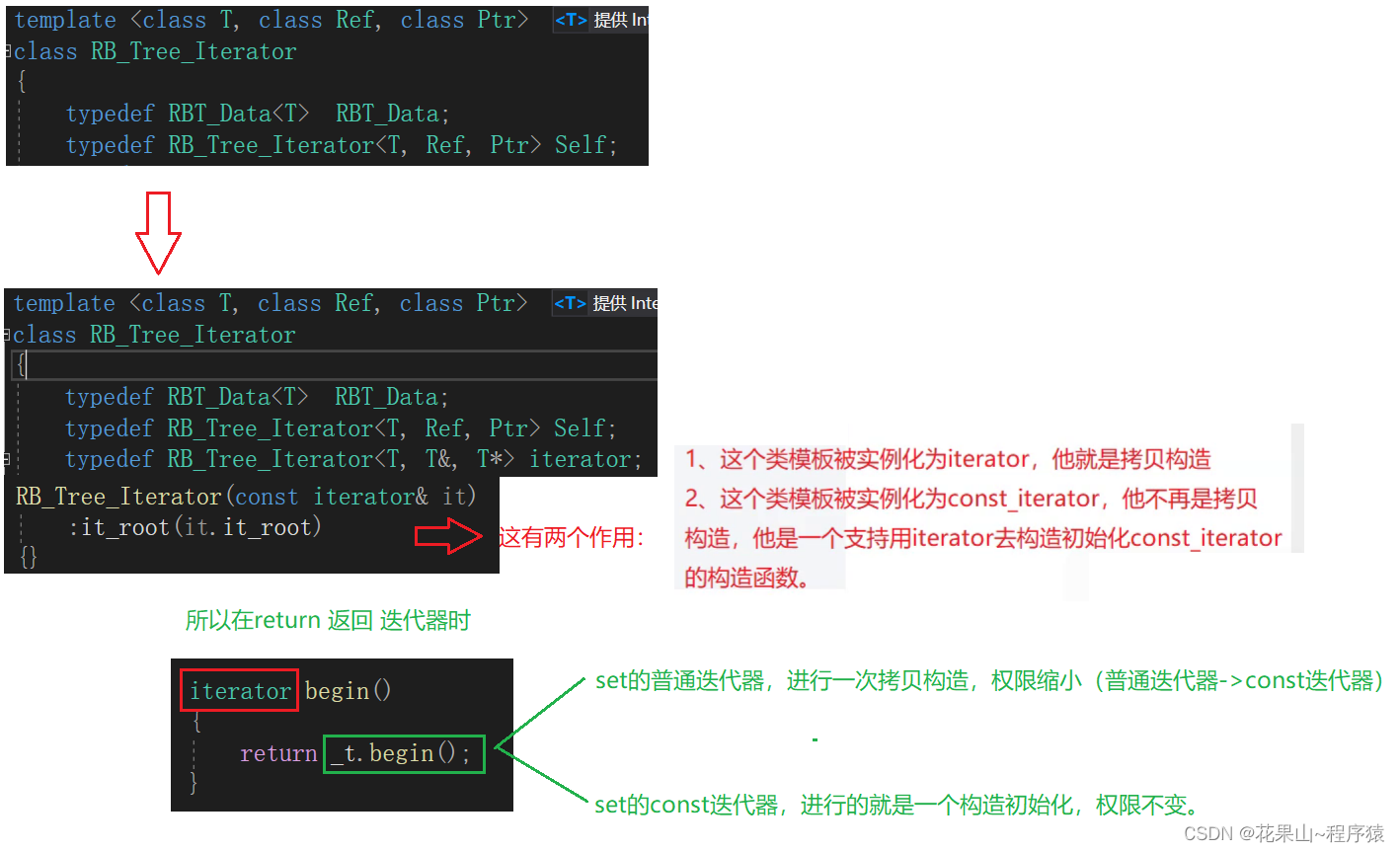
随着生成式人工智能(GAI)应用以及大语言模型(LLM)的快速发展,一种新型数据库也获得了市场和资本的重点关注,它就是向量数据库(Vector Database)。
向量数据库简介
向量数据库是一种专门用于存储和处理向量的数据库。向量数据库使用专门的算法和数据结构来支持相似性搜索,通常用于机器学习或数据挖掘,侧重于性能、可扩展性和灵活性。向量数据库可以帮助 AI 模型理解和储存长期记忆等问题,以完成复杂的任务,加速应用场景落地。

向量数据库采用嵌入向量(embedding vector)技术,对非结构化数据(包括文本、图片、视频、音频等)进行特征抽象。数学上,嵌入向量是一个浮点数或二进制数的数组,即 N 维特征向量空间中的向量。
向量数据库能够将向量存储为高维点并且高效、快速地查找 N 维空间中的最近邻。这些功能通常由近似最近邻搜索(ANN)提供支持,并使用分层可导航小世界(HNSW)和倒排文件索引(IVF)等算法构建。常见的相似性度量包括余弦相似性、点积、欧几里得距离、曼哈顿距离和汉明距离。
向量数据库还提供了其他功能,例如数据管理、容错、身份验证和访问控制以及查询引擎。
向量数据库的应用场景非常广泛,包括:推荐系统、图像检索、自然语言处理、人脸识别和图像搜索、音频识别、实时数据分析、物联网以及生物信息学等。
主流向量数据库
数据库排名网站 DB-Engines 列出了常见的一些向量数据库,包括专用的向量数据库和基于传统数据库的扩展功能。

接下来我们介绍其中常见的几个向量数据库。
Milvus
Milvus 是一款云原生的开源向量数据库,专为向量相似性搜索和 AI 应用赋能。

Milvus 是一款云原生向量数据库,采用存储与计算分离的架构设计,所有组件均为无状态组件,极大地增强了系统弹性和灵活性。整个系统分为四个层面:
- 接入层(Access Layer)。系统的门面,由一组无状态 proxy 组成。对外提供用户连接的 endpoint,负责验证客户端请求并合并返回结果。
- 协调服务(Coordinator Service)。系统的大脑,负责分配任务给执行节点。协调服务共有四种角色,分别为 root coord、data coord、query coord 和 index coord。
- 执行节点(Worker Node)。系统的四肢,负责完成协调服务下发的指令和 proxy 发起的数据操作语言(DML)命令。执行节点分为三种角色,分别为 data node、query node 和 index node。
- 存储服务 (Storage)。系统的骨骼,负责 Milvus 数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。

Milvus 已有应用场景包括:
- 图片检索系统。以图搜图,从海量数据库中即时返回与上传图片最相似的图片。
- 视频检索系统。将视频关键帧转化为向量并插入 Milvus,便可检索相似视频,或进行实时视频推荐。
- 音频检索系统。快速检索海量演讲、音乐、音效等音频数据,并返回相似音频。
- 分子式检索系统。超高速检索相似化学分子结构、超结构、子结构。
- 推荐系统。根据用户行为及需求推荐相关信息或商品。
- 智能问答机器人。交互式智能问答机器人可自动为用户答疑解惑。
Pipecone
Pipecone 是一个托管的、云原生的向量数据库,具有简单的API和无需基础架构的优势。

Pinecone具有以下特点:
- 快速:即使有数十亿个条目,也可以获得超低的查询延迟。
- 实时:添加、编辑或删除数据时,可以获得实时的索引更新。
- 过滤:将向量搜索与元数据过滤器相结合,以获得更相关、更快速的结果。
- 完全托管:轻松开始、使用和扩展,我们会让事情保持平稳和安全。
Pinecone适用于广泛的应用程序。以下是一些最常见的应用程序:
- 语义文本搜索:使用像NLP转换器和句子嵌入模型将文本数据转换为向量嵌入,然后使用Pinecone索引和搜索这些向量。
- 生成问答:从Pinecone检索与查询相关的上下文,并将其传递给像OpenAI这样的生成模型,以生成由真实数据来源支持的答案。
- 混合搜索:在一个查询中执行语义和关键字搜索,并将结果组合以获得更相关的结果。
- 图像相似度搜索:将图像数据转换为向量嵌入,并使用Pinecone构建索引。然后将查询图像转换为向量并检索相似图像。
- 产品推荐:基于代表用户的向量生成电子商务的产品推荐。
Chroma
Chroma 是一个开源向量嵌入数据库,它使得构建 LLM 应用更加容易。通过将知识、事实和技能可插件化到大语言模型,Chroma 更易于构建大语言模型应用。

Chroma 提供了以下工具:
- 存储嵌入及其元数据
- 嵌入文档和查询
- 搜索嵌入
Chroma 目前处于 Alpha 阶段,不适合生产使用。
Weaviate
Weaviate 是一个开源的向量数据库,可以存储对象、向量,支持将矢量搜索与结构化过滤与云原生数据库容错和可拓展性等能力相结合。

Weaviate 是一个低延迟的向量数据库,它支持多种媒体类型(如文本、图片等),并且具有语义搜索、问题答案提取、分类等功能,还支持可定制的模型(例如 PyTorch/TensorFlow/Keras)。它完全使用 Go 语言构建,存储了对象和向量,允许将向量搜索与结构化过滤器相结合,并具有云原生数据库的容错性。可以通过 GraphQL、REST 和各种客户端编程语言进行访问。
pgvector
pgvector 是基于 PostgreSQL 数据库的扩展插件,支持向量数据的存储和相似性搜索。

pgvector 支持精确和近似最近邻搜索、L2 距离、内积和余弦距离、各种开发语言以及 PostgreSQL 数据库功能。
其他产品
除了以上向量数据库之外,还有很多相关产品,包括:Qdrant、腾讯云向量数据库、Vearch、星环科技(Transwarp Hippo)等。
关于一些常见向量数据库的性能比较,可以参考 VectorDBBench。VectorDBBench 提供多个主流向量数据库和云服务的性能测试结果。







![[一] C++入门](https://img-blog.csdnimg.cn/8ae10e69cefe4c16bdb078035e34a003.png)