DataxWeb安装部署及使用–真香警告
文章目录
- 1.Datax简介
- 1.1 Datax是什么?
- 1.2 Datax的架构
- 1.3 设计理念
- 1.4 DataX3.0框架设计
- 1.5 DataX3.0插件体系
- 1.6 DataX3.0核心架构
- 1.6.1 核心模块介绍
- 1.6.2 DataX调度流程
- 2.DataxWeb简介
- 2.1 DataxWeb是什么?
- 2.2 DataxWeb架构
- 3.DataxWeb安装部署
- 3.1 创建数据库表用户及授权
- 3.2 sql脚本执行
- 3.3 bootstrap配置文件挂载位置
- 3.4 docker命令启动
- 3.5 修改core.json 配置修改
- 3.6 访问首页
- 4.全量同步
- 5.增量同步
- 5.1时间段增量同步
- 5.2id段增量同步
- 6.遇到的问题及决绝办法
- 7.总结
1.Datax简介
DataX
https://github.com/alibaba/DataX
1.1 Datax是什么?
DataX 是阿里巴巴使用 Java 和 Python 开发的一个异构数据源离线同步工具
异构数据源:不同存储结构的数据源
致力于实现包括关系型数据库 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS等各种异结构数据源之间稳定高效的数据同步功能
- Sqoop 是用于在 HDFS 与 RDBMS 之间数据迁移工具
- DataX 是阿里开源的一个异构数据源离线同步工具(任意两种数据源之间)
1.2 Datax的架构
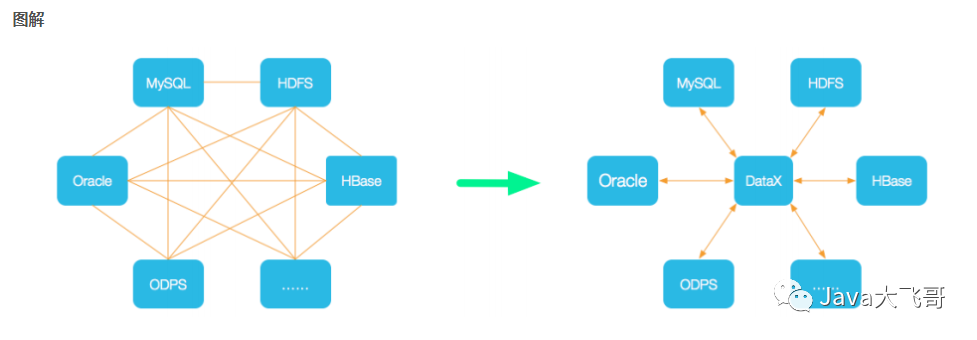
1.3 设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
1.4 DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader�为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
1.5 DataX3.0插件体系
经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 达梦 | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。详情请看:DataX数据源指南
1.6 DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
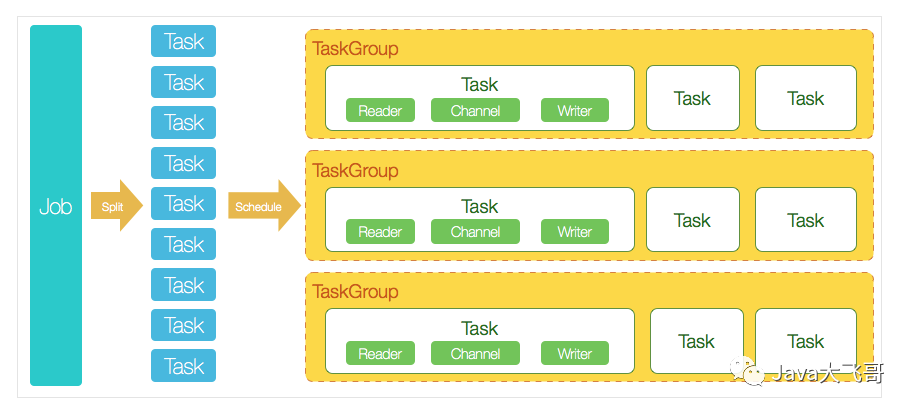
1.6.1 核心模块介绍
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
1.6.2 DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
2.DataxWeb简介
DataxWeb
https://github.com/WeiYe-Jing/datax-web
https://gitee.com/WeiYe-Jing/datax-web
2.1 DataxWeb是什么?
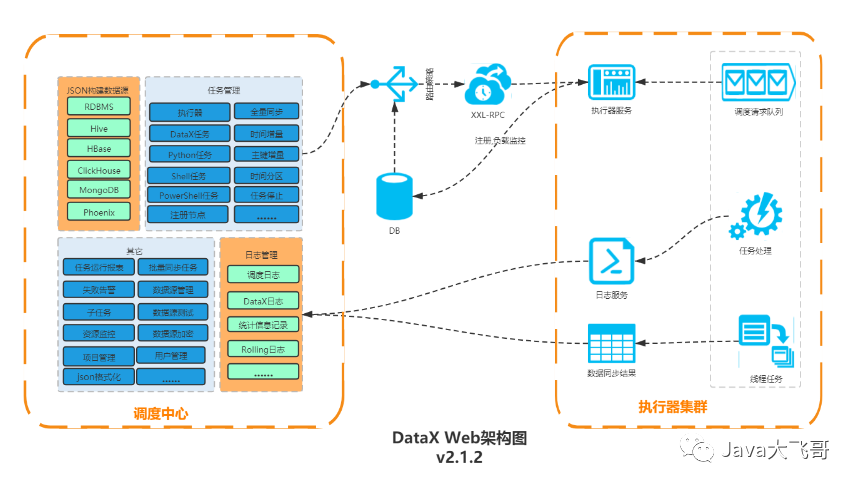
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的 操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。用户可通过页面选择数据源即可创建数据同步任务,支持RDBMS、Hive、HBase、ClickHouse、MongoDB等数据源,RDBMS数据源可批量创建数据同步任务,支持实时查看数据同步进度及日志并提供终止同步功能,集成并二次开发xxl-job可根据时间、自增主键增量同步数据。
任务"执行器"支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU.内存.负载的监控等等。后续还将提供更多的数据源支持、数据转换UDF、表结构同步、数据同步血缘等更为复杂的业务场景。
2.2 DataxWeb架构
3.DataxWeb安装部署
3.1 创建数据库表用户及授权
create database datax_web_db default character set utf8mb4 collate utf8mb4_general_ci;
create user 'datax_web'@'%' identified with mysql_native_password by 'zlf123456';
grant all privileges on datax_web_db.* to 'datax_web'@'%';
flush privileges;
3.2 sql脚本执行
/*
Navicat Premium Data Transfer
Source Server : localhost
Source Server Type : MySQL
Source Server Version : 50725
Source Host : localhost:3306
Source Schema : datax_web
Target Server Type : MySQL
Target Server Version : 50725
File Encoding : 65001
Date: 15/12/2019 22:27:10
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for job_group
-- ----------------------------
DROP TABLE IF EXISTS `job_group`;
CREATE TABLE `job_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '执行器AppName',
`title` varchar(12) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '执行器名称',
`order` int(11) NOT NULL DEFAULT 0 COMMENT '排序',
`address_type` tinyint(4) NOT NULL DEFAULT 0 COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` varchar(512) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器地址列表,多地址逗号分隔',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of job_group
-- ----------------------------
INSERT INTO `job_group` VALUES (1, 'datax-executor', 'datax执行器', 1, 0, NULL);
-- ----------------------------
-- Table structure for job_info
-- ----------------------------
DROP TABLE IF EXISTS `job_info`;
CREATE TABLE `job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_cron` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '任务执行CRON',
`job_desc` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`add_time` datetime(0) NULL DEFAULT NULL,
`update_time` datetime(0) NULL DEFAULT NULL,
`author` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '报警邮件',
`executor_route_strategy` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT 0 COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT 0 COMMENT '失败重试次数',
`glue_type` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL COMMENT 'GLUE源代码',
`glue_remark` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime(0) NULL DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT 0 COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT 0 COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT 0 COMMENT '下次调度时间',
`job_json` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT 'datax运行脚本',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for job_jdbc_datasource
-- ----------------------------
DROP TABLE IF EXISTS `job_jdbc_datasource`;
CREATE TABLE `job_jdbc_datasource` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`datasource_name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '数据源名称',
`datasource_group` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT 'Default' COMMENT '数据源分组',
`jdbc_username` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '用户名',
`jdbc_password` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '密码',
`jdbc_url` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT 'jdbc url',
`jdbc_driver_class` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT 'jdbc驱动类',
`status` tinyint(1) NOT NULL DEFAULT 1 COMMENT '状态:0删除 1启用 2禁用',
`create_by` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '创建人',
`create_date` datetime(0) NULL DEFAULT CURRENT_TIMESTAMP(0) COMMENT '创建时间',
`update_by` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '更新人',
`update_date` datetime(0) NULL DEFAULT NULL COMMENT '更新时间',
`comments` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '备注',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 6 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = 'jdbc数据源配置' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for job_lock
-- ----------------------------
DROP TABLE IF EXISTS `job_lock`;
CREATE TABLE `job_lock` (
`lock_name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of job_lock
-- ----------------------------
INSERT INTO `job_lock` VALUES ('schedule_lock');
-- ----------------------------
-- Table structure for job_log
-- ----------------------------
DROP TABLE IF EXISTS `job_log`;
CREATE TABLE `job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`job_desc` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`executor_address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NULL DEFAULT 0 COMMENT '失败重试次数',
`trigger_time` datetime(0) NULL DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL COMMENT '调度-日志',
`handle_time` datetime(0) NULL DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT 0 COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
`process_id` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT 'datax进程Id',
`max_id` bigint(20) NULL DEFAULT NULL COMMENT '增量表max id',
PRIMARY KEY (`id`) USING BTREE,
INDEX `I_trigger_time`(`trigger_time`) USING BTREE,
INDEX `I_handle_code`(`handle_code`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 0 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for job_log_report
-- ----------------------------
DROP TABLE IF EXISTS `job_log_report`;
CREATE TABLE `job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime(0) NULL DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT 0 COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT 0 COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT 0 COMMENT '执行失败-日志数量',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `i_trigger_day`(`trigger_day`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 28 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of job_log_report
-- ----------------------------
INSERT INTO `job_log_report` VALUES (20, '2019-12-07 00:00:00', 0, 0, 0);
INSERT INTO `job_log_report` VALUES (21, '2019-12-10 00:00:00', 77, 52, 23);
INSERT INTO `job_log_report` VALUES (22, '2019-12-11 00:00:00', 9, 2, 11);
INSERT INTO `job_log_report` VALUES (23, '2019-12-13 00:00:00', 9, 48, 74);
INSERT INTO `job_log_report` VALUES (24, '2019-12-12 00:00:00', 10, 8, 30);
INSERT INTO `job_log_report` VALUES (25, '2019-12-14 00:00:00', 78, 45, 66);
INSERT INTO `job_log_report` VALUES (26, '2019-12-15 00:00:00', 24, 76, 9);
INSERT INTO `job_log_report` VALUES (27, '2019-12-16 00:00:00', 23, 85, 10);
-- ----------------------------
-- Table structure for job_logglue
-- ----------------------------
DROP TABLE IF EXISTS `job_logglue`;
CREATE TABLE `job_logglue` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL COMMENT 'GLUE源代码',
`glue_remark` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT 'GLUE备注',
`add_time` datetime(0) NULL DEFAULT NULL,
`update_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for job_registry
-- ----------------------------
DROP TABLE IF EXISTS `job_registry`;
CREATE TABLE `job_registry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`registry_key` varchar(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`registry_value` varchar(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`update_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `i_g_k_v`(`registry_group`, `registry_key`, `registry_value`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 26 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Table structure for job_user
-- ----------------------------
DROP TABLE IF EXISTS `job_user`;
CREATE TABLE `job_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '账号',
`password` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '密码',
`role` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `i_username`(`username`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 10 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of job_user
-- ----------------------------
INSERT INTO `job_user` VALUES (1, 'admin', '$2a$10$2KCqRbra0Yn2TwvkZxtfLuWuUP5KyCWsljO/ci5pLD27pqR3TV1vy', 'ROLE_ADMIN', NULL);
/**
v2.1.1脚本更新
*/
ALTER TABLE `job_info`
ADD COLUMN `replace_param` VARCHAR(100) NULL DEFAULT NULL COMMENT '动态参数' AFTER `job_json`,
ADD COLUMN `jvm_param` VARCHAR(200) NULL DEFAULT NULL COMMENT 'jvm参数' AFTER `replace_param`,
ADD COLUMN `time_offset` INT(11) NULL DEFAULT '0'COMMENT '时间偏移量' AFTER `jvm_param`;
/**
增量改版脚本更新
*/
ALTER TABLE `job_info` DROP COLUMN `time_offset`;
ALTER TABLE `job_info`
ADD COLUMN `inc_start_time` DATETIME NULL DEFAULT NULL COMMENT '增量初始时间' AFTER `jvm_param`;
-- ----------------------------
-- Table structure for job_template
-- ----------------------------
DROP TABLE IF EXISTS `job_template`;
CREATE TABLE `job_template` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_cron` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '任务执行CRON',
`job_desc` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`add_time` datetime(0) NULL DEFAULT NULL,
`update_time` datetime(0) NULL DEFAULT NULL,
`user_id` int(11) NOT NULL COMMENT '修改用户',
`alarm_email` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '报警邮件',
`executor_route_strategy` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '执行器参数',
`executor_block_strategy` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT 0 COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT 0 COMMENT '失败重试次数',
`glue_type` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL COMMENT 'GLUE源代码',
`glue_remark` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime(0) NULL DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_last_time` bigint(13) NOT NULL DEFAULT 0 COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT 0 COMMENT '下次调度时间',
`job_json` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL COMMENT 'datax运行脚本',
`jvm_param` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT 'jvm参数',
`project_id` int(11) NULL DEFAULT NULL COMMENT '所属项目Id',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 22 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
/**
添加数据源字段
*/
ALTER TABLE `job_jdbc_datasource`
ADD COLUMN `datasource` VARCHAR(45) NOT NULL COMMENT '数据源' AFTER `datasource_name`;
/**
添加分区字段
*/
ALTER TABLE `job_info`
ADD COLUMN `partition_info` VARCHAR(100) NULL DEFAULT NULL COMMENT '分区信息' AFTER `inc_start_time`;
/**
2.1.1版本新增----------------------------------------------------------------------------------------------
*/
/**
最近一次执行状态
*/
ALTER TABLE `job_info`
ADD COLUMN `last_handle_code` INT(11) NULL DEFAULT '0' COMMENT '最近一次执行状态' AFTER `partition_info`;
/**
zookeeper地址
*/
ALTER TABLE `job_jdbc_datasource`
ADD COLUMN `zk_adress` VARCHAR(200) NULL DEFAULT NULL AFTER `jdbc_driver_class`;
ALTER TABLE `job_info`
CHANGE COLUMN `executor_timeout` `executor_timeout` INT(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位分钟' ;
/**
用户名密码改为非必填
*/
ALTER TABLE `job_jdbc_datasource`
CHANGE COLUMN `jdbc_username` `jdbc_username` VARCHAR(100) CHARACTER SET 'utf8mb4' NULL DEFAULT NULL COMMENT '用户名' ,
CHANGE COLUMN `jdbc_password` `jdbc_password` VARCHAR(200) CHARACTER SET 'utf8mb4' NULL DEFAULT NULL COMMENT '密码' ;
/**
添加mongodb数据库名字段
*/
ALTER TABLE `job_jdbc_datasource`
ADD COLUMN `database_name` VARCHAR(45) NULL DEFAULT NULL COMMENT '数据库名' AFTER `datasource_group`;
/**
添加执行器资源字段
*/
ALTER TABLE `job_registry`
ADD COLUMN `cpu_usage` DOUBLE NULL AFTER `registry_value`,
ADD COLUMN `memory_usage` DOUBLE NULL AFTER `cpu_usage`,
ADD COLUMN `load_average` DOUBLE NULL AFTER `memory_usage`;
-- ----------------------------
-- Table structure for job_permission
-- ----------------------------
DROP TABLE IF EXISTS `job_permission`;
CREATE TABLE `job_permission` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '权限名',
`description` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '权限描述',
`url` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`pid` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
ALTER TABLE `job_info`
ADD COLUMN `replace_param_type` varchar(255) NULL COMMENT '增量时间格式' AFTER `last_handle_code`;
ALTER TABLE `job_info`
ADD COLUMN `project_id` int(11) NULL COMMENT '所属项目id' AFTER `job_desc`;
ALTER TABLE `job_info`
ADD COLUMN `reader_table` VARCHAR(255) NULL COMMENT 'reader表名称' AFTER `replace_param_type`,
ADD COLUMN `primary_key` VARCHAR(50) NULL COMMENT '增量表主键' AFTER `reader_table`,
ADD COLUMN `inc_start_id` VARCHAR(20) NULL COMMENT '增量初始id' AFTER `primary_key`,
ADD COLUMN `increment_type` TINYINT(4) NULL COMMENT '增量类型' AFTER `inc_start_id`,
ADD COLUMN `datasource_id` BIGINT(11) NULL COMMENT '数据源id' AFTER `increment_type`;
CREATE TABLE `job_project` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'key',
`name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT 'project name',
`description` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`user_id` int(11) NULL DEFAULT NULL COMMENT 'creator id',
`flag` tinyint(4) NULL DEFAULT 1 COMMENT '0 not available, 1 available',
`create_time` datetime(0) NULL DEFAULT CURRENT_TIMESTAMP(0) COMMENT 'create time',
`update_time` datetime(0) NULL DEFAULT CURRENT_TIMESTAMP(0) COMMENT 'update time',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
ALTER TABLE `job_info`
CHANGE COLUMN `author` `user_id` INT(11) NOT NULL COMMENT '修改用户' ;
ALTER TABLE `job_info`
CHANGE COLUMN `increment_type` `increment_type` TINYINT(4) NULL DEFAULT 0 COMMENT '增量类型' ;
3.3 bootstrap配置文件挂载位置
如果是在Linux上在宿主机创建/home/datax/datax-admin/conf目录,并将bootstrap.properties拷贝到/home/datax/datax-admin/conf目录下
如果是在Windows10专业版上在D:\datax\datax-admin\conf\下新建bootstrap.properties文件
#Database
DB_HOST=xx.xx.xx.xx
DB_PORT=3306
DB_USERNAME=datax_web
DB_PASSWORD=xxxxxx
DB_DATABASE=datax_web_db
3.4 docker命令启动
#linux上的执行命令如下:
docker run -d --name datax_web -p 9527:9527 -v /home/datax/datax-admin/conf/bootstrap.properties:/home/datax/datax-web-2.1.2/modules/datax-admin/conf/bootstrap.properties linshellfeng/datax_web:3.0.1
# windows10专业版上执行命令如下:
docker run -d --name datax_web -p 9527:9527 -v "D:\datax\datax-admin\conf\bootstrap.properties":/home/datax/datax-web-2.1.2/modules/datax-admin/conf/bootstrap.properties linshellfeng/datax_web:3.0.1
3.5 修改core.json 配置修改
docker exec -it b9b /bin/bash
vim /home/datax/datax/conf/core.json
byte字段 由原来的的-1改为:2000000
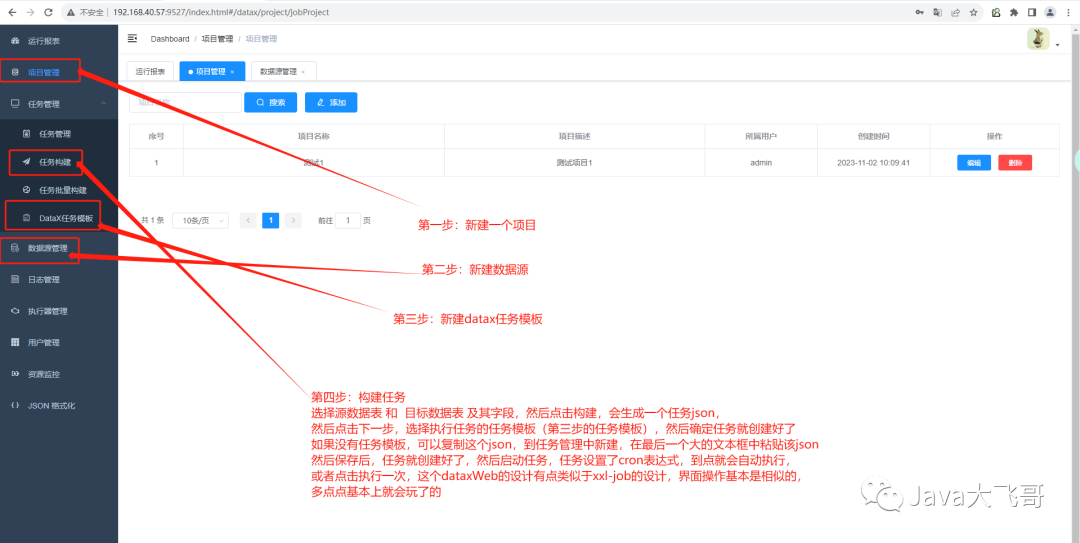
3.6 访问首页
账号密码:admin/123456
http://ip:9527/index.html
4.全量同步
这个比较简单,省略该步骤
这里做一个简单的说明:本篇文章中实践的是mysql8.0数据库的一个数据库test1中的test1表(源数据),然后需要同步到test1数据库的test2(目标数据),都是同一个数据库,test1表和test2表的结构是一样的,这个是简单的数据库(同库或异库)表对表的数据同步,还可以写表与表的关联查询,然后将关联数据同步到目标库的目标表中,这个本文没有搞,有兴趣的可以去探索尝试下它的一些新玩法和新姿势。
5.增量同步
时间段增量同步和id段增量同步
下面的是错误的例子:这种写的博客有好多坑的博客都是这种写的,这种写不报错,就是执行跑不出你想要的增量数据:
错误demo:
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "==",
"password": "==",
"splitPk": "Id",
"connection": [
{
//这种方式是错误的,没有效果的
"querySql": [
"select Id,Name,Addrress,CreateTime,UpdateTime from products where UpdateTime >= ${lastTime} and UpdateTime < ${currentTime} "
],
"jdbcUrl": [
"jdbc:mysql://192.168.31.132:3306/demo"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "==",
"password": "==",
"writeMode": "update",
"column": [
"`Id`",
"`Name`",
"`Addrress`",
"`CreateTime`",
"`UpdateTime`"
],
"connection": [
{
"table": [
"products2"
],
"jdbcUrl": "jdbc:mysql://192.168.31.132:3306/demo"
}
]
}
}
}
]
}
}
正确的是在where条件当中:
"where": " create_time >= ${lastTime} and create_time < ${currentTime}",
id段也是这种搞的,id的这个我没有试过,但是我相信是可以的,时间段增量的都可以的,id的也是没有啥问题的,放在where条件当中
正确demo:
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "xxxxxx",
"password": "xxxxxx",
"column": [
"`id`",
"`order_id`",
"`create_time`",
"`update_time`",
"`remark`"
,,,,,,,,,,,,
],
"where": " create_time >= ${lastTime} and create_time < ${currentTime}",
"splitPk": "",
"connection": [
{
"table": [
"bc_order"
],
"jdbcUrl": [
"jdbc:mysql://ip:3306/test"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "xxxxxx",
"password": "xxxx",
"column": [
"`id`",
"`order_id`",
"`create_time`",
"`update_time`",
"`remark`"
,,,,,,,,,,,,
],
"connection": [
{
"table": [
"bc_order_copy1"
],
"jdbcUrl": "jdbc:mysql://ip:3306/test"
}
]
}
}
}
]
}
}
这个json不需要手写的,由dataxWeb给我们自动生成的,也很方便。
5.1时间段增量同步
页面任务配置:
打开菜单任务管理页面,选择添加任务
按下图中步骤进行配置
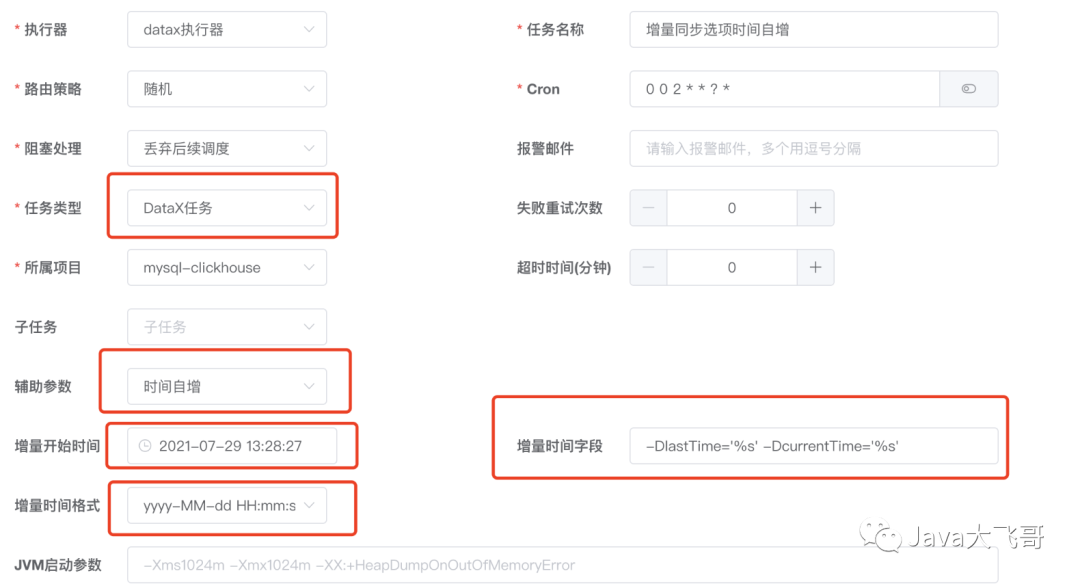
说明:
- 1.任务类型选DataX任务
- 2.辅助参数选择时间自增
- 3.增量开始时间选择,即sql中查询时间的开始时间,用户使用此选项方便第一次的全量同步。第一次同步完成后,该时间被更新为上一次的任务触发时间,任务失败不更新。
- 4.增量时间字段,-DlastTime=‘%s’ -DcurrentTime=‘%s’ 先来解析下这段字符串
1.-D是DataX参数的标识符,必配
2.-D后面的lastTime和currentTime是DataX json中where条件的时间字段标识符,必须和json中的变量名称保持一致
3.='%s'是项目用来去替换时间的占位符,比配并且格式要完全一致
4.注意-DlastTime='%s'和-DcurrentTime='%s'中间有一个空格,空格必须保留并且是一个空格
5.时间格式,可以选择自己数据库中时间的格式,也可以通过json中配置sql时间转换函数来处理
demo如下:
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": -1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "7aAw6fAFXgqP2weyjjwIAw==",
"password": "1Sh8F0VGrkzgnRXsNXowUAxSS1xnCyE8TrEgzQ7ZE40=",
"column": [
"ID",
"CREATE_TIME",
"USER_ID",
"UPDATE_TIME",
"LAST_MODIFY_USER_ID"
],
//如果选择的是时间戳需要用FROM_UNIXTIME这个函数进行转换下的,下面有说明
"where": " CREATE_TIME >= FROM_UNIXTIME(${lastTime}) and CREATE_TIME < FROM_UNIXTIME(${currentTime})",
"splitPk": "ID",
"connection": [
{
"table": [
"t_test"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/test"
]
}
]
}
},
"writer": {
"name": "clickhousewriter",
"parameter": {
"username": "OhlJ4g2KfCRznayQNh0eng==",
"password": "ONwWYPUDMPXDIREymhWAMQ==",
"column": [
"ID",
"CREATE_TIME",
"USER_ID",
"UPDATE_TIME",
"LAST_MODIFY_USER_ID"
],
"connection": [
{
"table": [
"tb"
],
"jdbcUrl": "jdbc:clickhouse://localhost:8123/local"
}
]
}
}
}
]
}
}
说明:
1.此处的关键点在${lastTime},${currentTime},${}是DataX动态参数的固定格式,lastTime,currentTime就是我们页面配置中 -DlastTime='%s' -DcurrentTime='%s'中的lastTime,currentTime,注意字段一定要一致。
2.如果任务配置页面,时间类型选择为时间戳但是数据库时间格式不是时间戳,例如是:2019-11-26 11:40:57 此时可以用FROM_UNIXTIME(${lastTime})进行转换。
select * from test_list where operationDate >= FROM_UNIXTIME(${lastTime}) and operationDate < FROM_UNIXTIME(${currentTime})
5.2id段增量同步
页面任务配置
打开菜单任务管理页面,选择添加任务
按下图中步骤进行配置
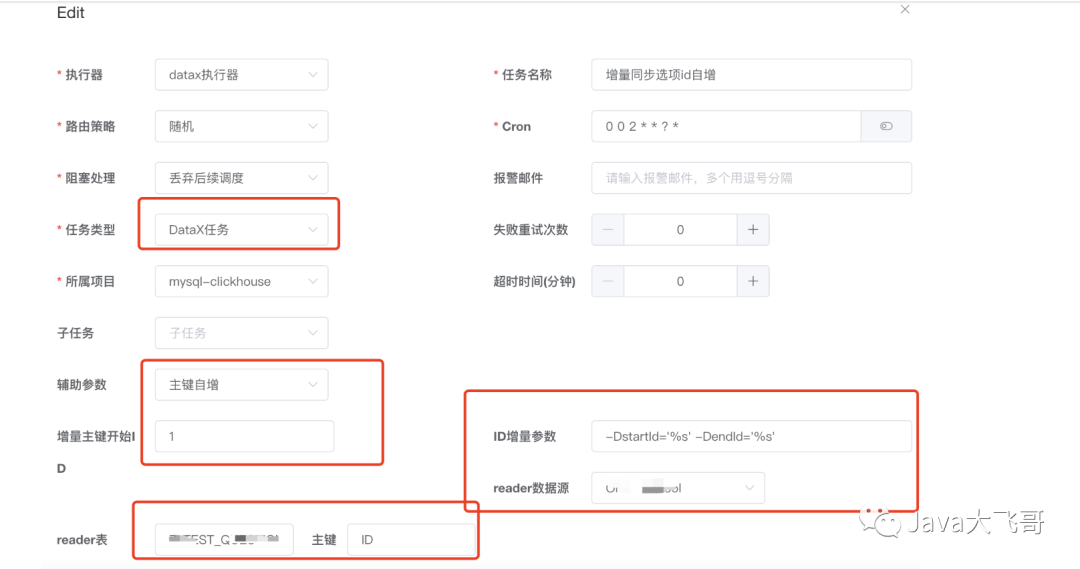
说明:
- 1.任务类型选DataX任务
- 2.辅助参数选择主键自增
- 3.增量主键开始ID选择,即sql中查询ID的开始ID,用户使用此选项方便第一次的全量同步。第一次同步完成后,该ID被更新为上一次的任务触发时最大的ID,任务失败不更新。
- 4.增量时间字段,-DstartId=‘%s’ -DendId=‘%s’ 先来解析下这段字符串
1.-D是DataX参数的标识符,必配
2.-D后面的startId和endId是DataX json中where条件的id字段标识符,必须和json中的变量名称保持一致
3.='%s'是项目用来去替换时间的占位符,比配并且格式要完全一致
4.注意-DstartId='%s'和-DendId='%s' 中间有一个空格,空格必须保留并且是一个空格
5.reader数据源,选择任务同步的读数据源
6.配置reader数据源中需要同步数据的表名及该表的主键
此处的关键点在 s t a r t I d , {startId}, startId,{endId},${}是DataX动态参数的固定格式,startId,endId就是我们页面配置中 -DstartId=‘%s’ -DendId='%s’中的startId,endId,注意字段一定要一致。
demo如下:
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": -1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "7aAw6fAFXgqP2weyjjwIAw==",
"password": "1Sh8F0VGrkzgnRXsNXowUAxSS1xnCyE8TrEgzQ7ZE40=",
"column": [
"ID",
"CREATE_TIME",
"USER_ID",
"UPDATE_TIME",
"LAST_MODIFY_USER_ID"
],
"where": " ID >= ${startId} and ID < ${endId} ",
"splitPk": "ID",
"connection": [
{
"table": [
"t_test"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/test"
]
}
]
}
},
"writer": {
"name": "clickhousewriter",
"parameter": {
"username": "OhlJ4g2KfCRznayQNh0eng==",
"password": "ONwWYPUDMPXDIREymhWAMQ==",
"column": [
"ID",
"CREATE_TIME",
"USER_ID",
"UPDATE_TIME",
"LAST_MODIFY_USER_ID"
],
"connection": [
{
"table": [
"tb"
],
"jdbcUrl": "jdbc:clickhouse://localhost:8123/local"
}
]
}
}
}
]
}
}
6.遇到的问题及决绝办法
在做这个实践的时候,我用的是之前本地flink-cdc的实践所安装的mysql5.7.1的数据库,使用的是windows10操作系统的docker环境,本文也是使用windows10操作系统的docker环境,然后在执行的任务的时候就会报一个加载mysql-connector-java-8.0.30.jar异常的错误,后面我在docker容器文件界面找到了dataxWeb的lib所在的路径下把这个8.0的驱动包删除,换了一个5.7x的版本的jar包,你后面启动,然后执行报了一个如下错误:
readlag fail, logFile not exists
我还以为是我之前改动了上面那个jar包导致镜像文件改变了,后面我把之前的启动的容器和下载的镜像全部删除,重新执行docker命令,重新下载镜像,拉起容器,然后继续尝试,结果还是报这个错误,后面我进入到datax下面的bin目录下,执行了datax的自检,一直是自检有问题,看日志是jar的依赖冲突导致,关于datax的启动自检(datax、dataxWeb使用可执行包安装就有这个步骤了,这个源码暗转比较复杂,可以参考网上的教程,本文使用docker镜像的方式简单方便快捷的就可以使用体验上datax和dataxWeb,这个镜像都包含这个两个,都是开箱即可使用,只需要安装上面的步骤配置下即可快速使用),网上也有教程,这里就不过多的讲解,否则对大家带来误解,后面左搞右搞还是这个错误,我就怀疑是不是mysql5.7x的数据库这个dataxWeb的镜像不支持,后面使用了一个mysql8.x的数据库进行了再一次尝试,结果发现没有这个问题了,这个也是很坑的一个问题。
要解决这个问题有两个方法:
1.上网找dataxWeb镜像支持mysql数据库5.7x的镜像
2.把dataxWeb的源码拉到本地修改pom的mysql依赖改成5.7.1重新打包构建,然后重新构建一个dataxWeb的镜像
这个两个只是一个思路提供给大家,有兴趣的可以去尝试下。
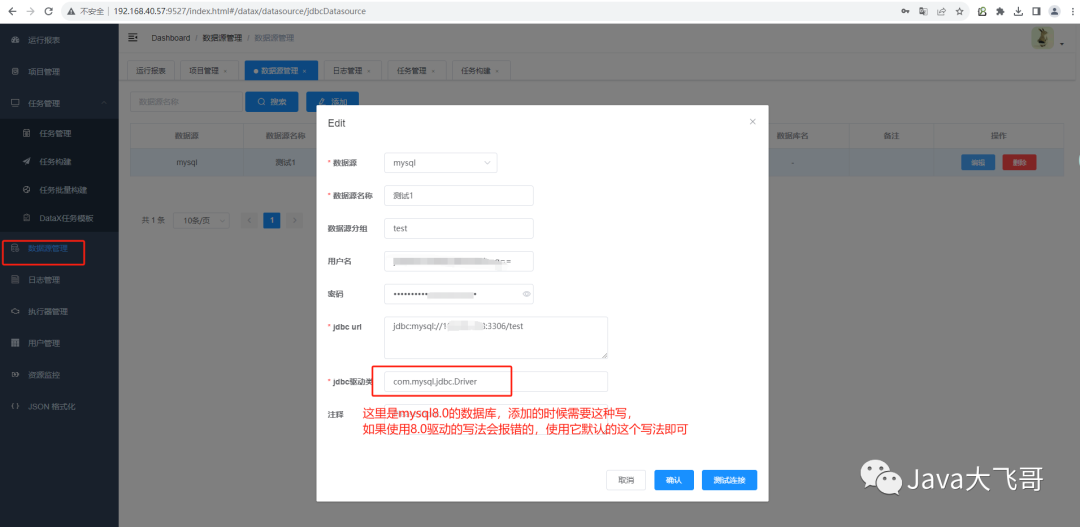
数据库为mysql8.0时添加数据源需要注意:
7.总结
本次分享到此结束,会使用datax同步数据,在异构数据源的情况下,如果不会这个工具,那只能写crud的方式写一大堆业务代码来完成数据的同步,很容易出问题,一个装B的写法一个不小心就会写出bug导致翻车,造成一些问题和事故,所以能不写代码实现就不写代码,不一定要写代码才可以实现,只会写代码实现就是一种定式思维和惯性思维,条条大路通罗马,没有必要一上来就写代码,保持好奇心,每天学习研究点新东西,不至于天天月月年年在crud,希望我的分享对你有所帮助,请一键三连,么么么哒!