摘要:OOP(面向对象),namespace,cout and cin,缺省参数,函数重载,引用,内联函数,auto,范围 for,nullptr
20世纪80年代,计算机界提出了OOP(object oriented programming:面向对象)思想,支持面向对象的程序设计语言应运而生。C++是基于C语言而 产生的,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行面向对象的程序设计。
A major design goal of C++ is to let programmers define their own types that are as easy to use as the built-in types.
——《C++ Primer》
1. 命名空间_namespace
namespace fantasy
{
int a = 13;
int l = 7;
struct MyStructRB
{
int capacity;
int size;
}RB;
}
int main()
{
int sum = fantasy::a + fantasy::l;
fantasy::RB.size = 0;
fantasy::RB.capacity = 0;
return 0;
}导入_why
Question:全局变量与局部变量冲突时,优先哪个?
#include<stdio.h>
int num = 7;
int main()
{
int num = 13;
printf("%d",num);
return 0;
}Answer:局部变量,因为查找的顺序是:先局部 ⇢ 再全局(![]() output: 13)
output: 13)
- 为了解决变量名冲突的问题,命名空间应运而生
namespace_what
- namespace:C++关键字
- [name_of_namespace]:: 域作用限定符(::) ,左操作数为
name_of_namespace ,意为在该命名空间的区域内查找变量,如果左操作数为空,则表示在全局查找。
Rules_use
- 命名空间的名称不应有空格,错误示例:
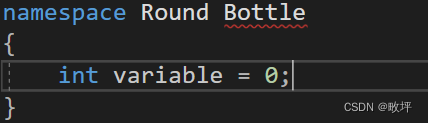
- 同名的命名空间会被合并
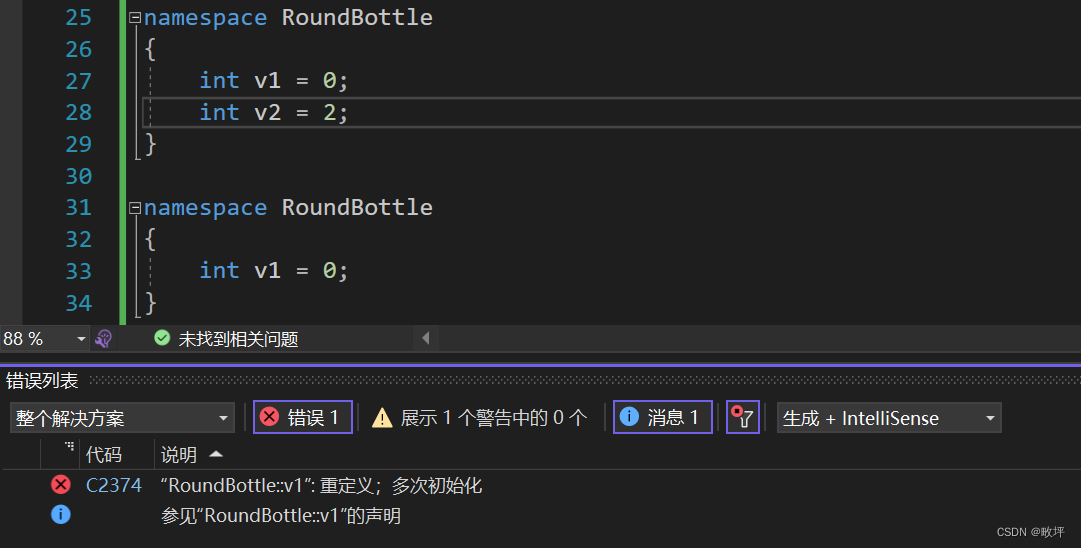
- 命名空间支持嵌套
namespace fantasy { int a = 13; int l = 7; namespace RoundBottle { struct MyStructRB { int* array; int size; }RB; } } int main() { fantasy::RoundBottle::RB.size = 0; fantasy::RoundBottle::RB.array = nullptr; return 0; }
访问命名空间_declaration
- 指定命名空间访问
std::cout << "Hello"; - 全局展开(日常练习中可以,项目中一般不会用全局展开):
using namespace name_of_namespace;using namespace std;
2. C++ 输入&输出
- std:C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
- cout:输出流
- cin:输入流
- endl : 换行符(作用是换行并清空缓存区的数据)
- << 流插入运算符;>> 是流提取运算符;箭头方向可以理解为 “数据的流向 ”
#include <iostream>
using namespace std;
int main()
{
int num = 0;
// 可以自动识别变量的类型
cin >> num;//把数据输入到 num 这个变量中进行储存
cout << num << endl;//将num中储存的数据输出(到屏幕)
return 0;
}3. 缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
示例_example
- 缺省参数分为全缺省和部分缺省
//全缺省
int Add(int x = 1, int y = 2)
{
return x + y;
}
//部分缺省
int Sum(int x, int y, int z = 3)
{
return x + y + z;
}Rules_use
- 缺省参数不能跳跃,必须从左往右连续使用。错误示例:
#include<iostream> using namespace std; int Sum(int x = 1, int y, int z = 3) { return x + y + z; } int main() { int ret = Sum(1, 2); cout << ret << endl; return 0; }上述情况下,参数将无法确定传给谁,例如,参数“1”可能传给 x,也可能传给 y,因此这里出现了歧义,导致编译错误。同样的,上述代码也不支持写成: ret = Sum( , 1, 2);
- 当函数的声明和定义分离时,缺省参数不能在声明和定义中同时出现,推荐在函数声明的时候给缺省参数(以下代码为错误示例)
//函数声明: int Add(int x = 1, int y = 2); //函数定义: int Add(int x = 1, int y = 2) { return x + y; }
应用场景_apply
(举例:栈的初始化)
C:
// 初始化栈
void StackInit(Stack* ps)
{
STDataType* tmp = (STDataType*)malloc(4 * sizeof(STDataType));
if (!tmp)
{
perror("malloc fail");
exit(-1);
}
ps->_a = tmp;
ps->_top = 0;
ps->_capacity = 4;
}CPP:
// 初始化栈
void StackInit(Stack* ps, int initsize = 4)
{
int* tmp = (int*)malloc(initsize * sizeof(int));
if (!tmp)
{
perror("malloc fail");
exit(-1);
}
ps->_a = tmp;
ps->_top = 0;
ps->_capacity = initsize;
}-
知道栈中最多存100个数据:
StackInit(&stack, 100);
-
不知道栈中最多存多少数据:
StackInit(&stack);
4. 函数重载
函数重载 → 在同一个命名空间,且函数名相同,参数不同,体现为三种方式:
- 类型不同 e.g.function(int p); function(double p);
- 个数不同 e.g.function(int p); function(int p1 , int p2)
- (类型的)顺序不同 e.g.function(int p , double p); function(double p , int p );
- Question:仅返回值不同,能构成函数重载吗?
Answer:❌不能!函数调用的时候并不能指明返回值,当两个函数只有返回值的类型不同时,在尝试调用函数时无法确认将要调用哪个函数,将发生编译错误!返回值类型是否相同与函数构成重载不相关。
函数重载是如何实现的?
首先,我们需要了解代码的编译过程:(这里简单描述一下)
- 预处理:头文件展开(注意:头文件展开不同于“命名空间展开”,头文件展开是把头文件的内容复制一份,“命名空间展开”是授权,允许在该空间内进行查找),宏替换,去注释,条件编译 (test.cpp → test.i)
- 编译:检查语法,生成汇编代码(指令级代码)(test.i → test.s)
- 汇编:汇编代码 → 二进制机器码 (test.s → test.o)
- 链接:合并多个 .cpp/.c 文件,生成可执行文件 (test.o →test.exe/test.out)
在链接的环节会生成符号表,类似这样:
| name | address |
|---|---|
| function | xxxxxxxxxx |
| main | xxxxxxxxxx |
| …… | …… |
链接的时候会通过 name 找到 address,函数地址是一个跳转指令,如果函数没有定义只有声明就不会有地址,这将发生链接错误。
- C语言:直接用函数名充当符号表中的name,如下图。
- C++:对函数名进行修饰,不同平台下的修饰规则不同(从下图的链接错误中,可以看见vs2022平台下对函数名的修饰)。
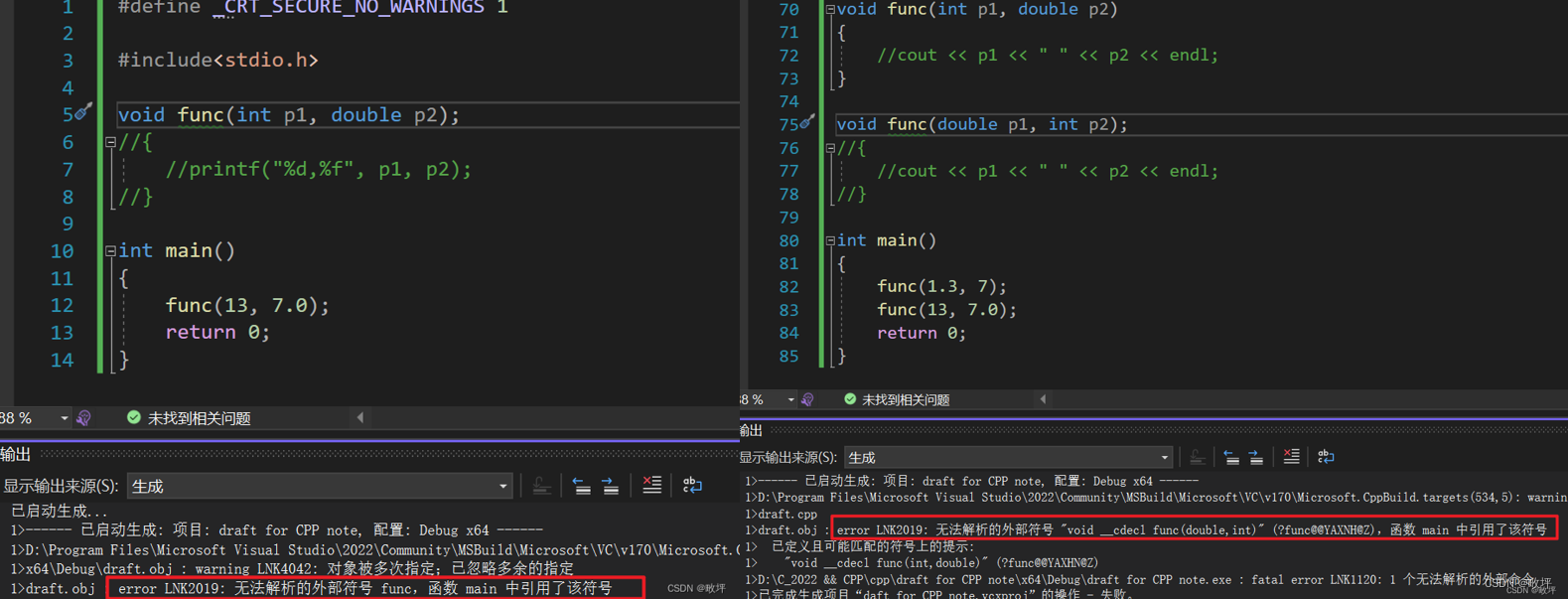
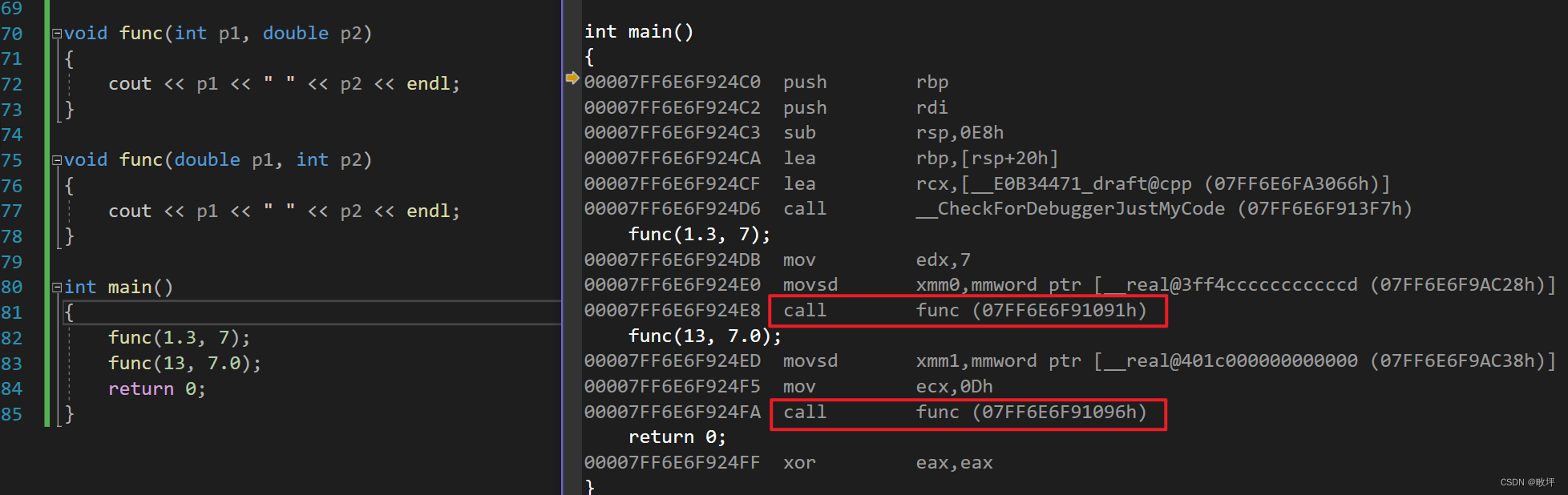
sum.
- C++对函数名进行了修饰,不同平台下的修饰规则不同
- 能自动识别函数参数的类型 (会不会使运行速度变慢?👉不会,可能影响编译速度,但不影响运行速度)
5. 引用_References
#include<iostream>
using namespace std;
int main()
{
int v1 = 13;
int& v2 = v1;
v2 = 7;
cout << v1 << endl; //output:7
return 0;
}References_what
- 引用 —— 一块存储空间的 “别名”
- Type& variable_reference = variable_entity ,Type 后跟“& ”表示引用,variable_reference 与 variable_entity 表示的是同一块存储空间的不同名称。注意:variable_entity 应该与 Type 相符合。

Rules_use
-
定义时必须初始化

-
一个变量可以有多个引用
int main() { int v1 = 13; int& v2 = v1; int& v3 = v1; int& v4 = v1; int* p = &a; int*& pb = p; return 0; } -
引用在定义的时候必须初始化,因此只能引用一个实体,并且不能改变,否则会出现重定义
int main() { int v1 = 13; int v2 = 7; int& v3 = v1; v3 = v2;//这是赋值,将v2的数据赋值给v3,同样的也是指v1 int& v3 = v2;//错误:重定义!! return 0; }
常引用_const
- Type_const
int main() { const int v = 13; int& v1 = 13;//error const int& v2 = 13; const int& v3 = v2;//correct return 0; }上述代码中,“13” 的 Type 是 const int,是只读不可修改的常量,在语句 int& v1 = 13 中本是上发生了权限放大,导致错误。v1 的是 Type 是 int,是可读可修改的变量。权限可以平移、缩小,但不能放大。
-
隐式类型转化_Type Conversion
int main() { int v_i = 0; double& v_d = v_i;//error double v_d2 = v_i;//correct,同样发生了类型转化,但这只是赋值语句 return 0; }上述代码发生了隐式类型转化,int → double ,转化过程中会产生临时变量,临时变量具有常属性!本质上来说这里仍发生了权限放大。
应用场景_apply
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
传引用的作用:①减少拷贝;②调用者可以修改该对象
1)做函数参数:
传引用传参:输出型函数,形参的改变需要影响实参
void Swap(int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
}
int main()
{
int x = 13, y = 7;
Swap(x, y);
cout << x << " " << y << endl;
return 0;
}
2)做返回值:
传引用返回:函数的返回类型为一个引用
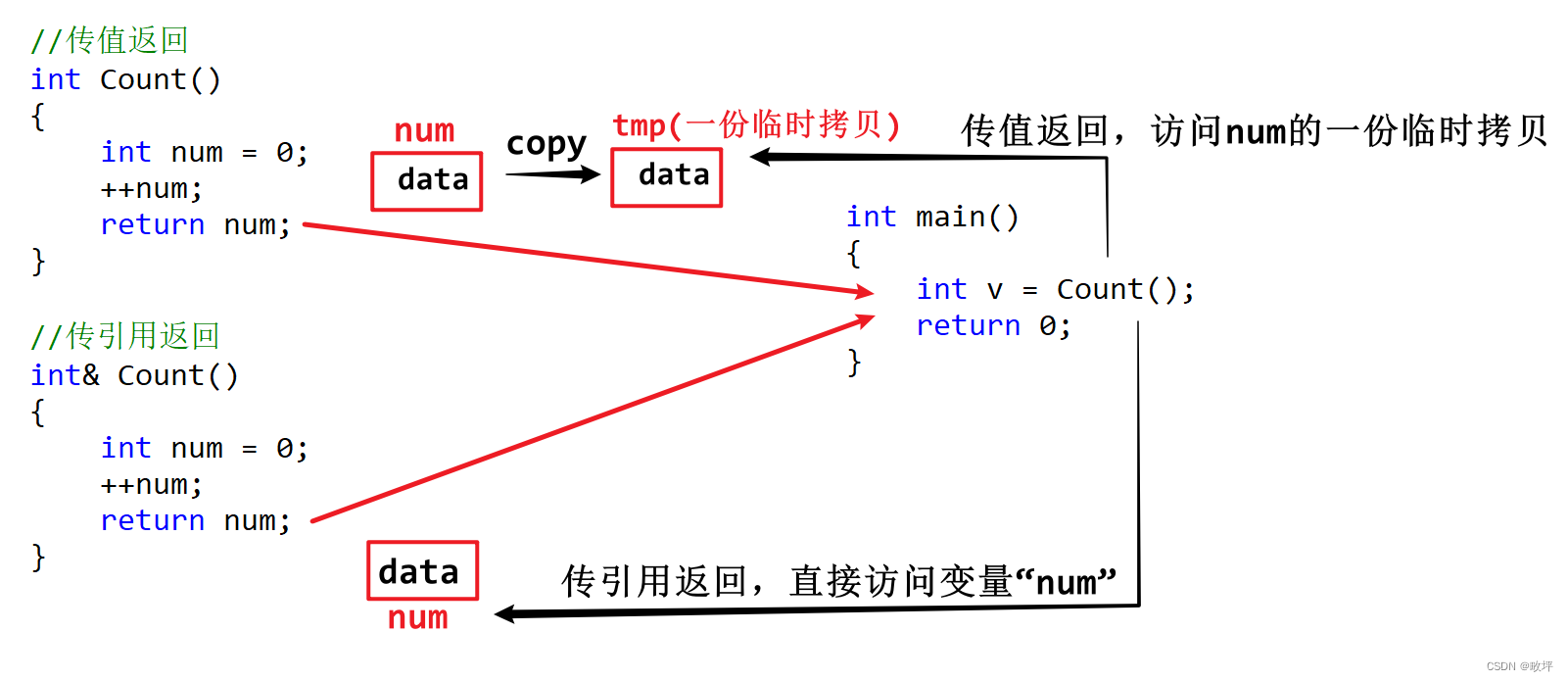
方式一:上图中的传引用返回可以直观的理解为下图中的代码 ⬇ ,_num 与 num 是同一块存储空间的不同名称,然后将这个空间中存储的数据赋值给变量 v 。warning:这样的行为是未定义的,因为 num 在出函数作用域时候被销毁,该存储空间被归还,再次访问这块空间会得到什么数据是不确定的。
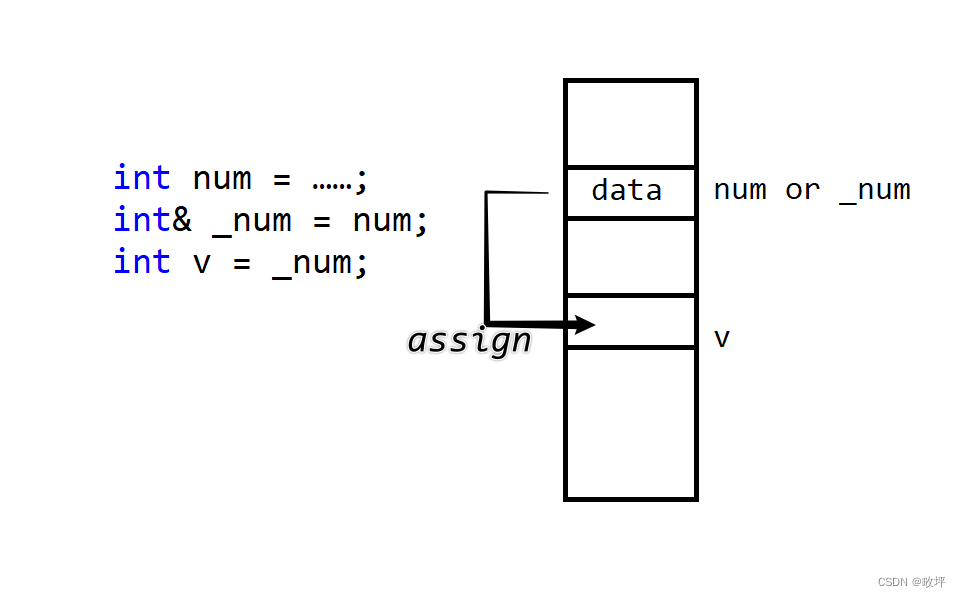
方式二:“用引用来接收引用返回”,以下代码中,v 与 num 是同一块存储空间的不同名称,即表示同一块存储空间。
int& Count()
{
int num = 0;
++num;
return num;
}
int main()
{
int& v = Count();
cout << v << endl;//ouput:1
cout << v << endl;//ouput:随机值
return 0;
}
- 注意:如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
引用和指针的区别⭐
语法上有区别,但底层实现本质上是相同的。
- 引用概念上定义一个变量的别名,指针存储一个变量地址。引用不开空间,指针开空间。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
6. 内联函数_inline
当我们尝试实现一个可以进行加法运算的宏函数:以下 3 种写法都容易在使用 ADD宏函数的时候出现问题。
#define ADD(x,y) x+y
#define ADD(x,y) (x+y)
#define ADD(x,y) ((x)+(y));
//better
#define ADD(x,y) ((x)+(y))
宏函数的优点:
- 没有严格的类型 (Type) 检查;
- 针对频繁调用的简单函数,无需建立栈帧,提高了效率。
宏函数的缺点:
- 容易出错,语法坑很多;
- 不能调试(预处理阶段将被直接替换);
- 没有类型 (Type) 的安全检查。
内联函数展开_what
基于此,C++选择使用内联函数:以 inline 修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升了程序运行的效率。
为了在调试的时候看到内联函数的展开我们需要关闭优化:步骤如下列图片
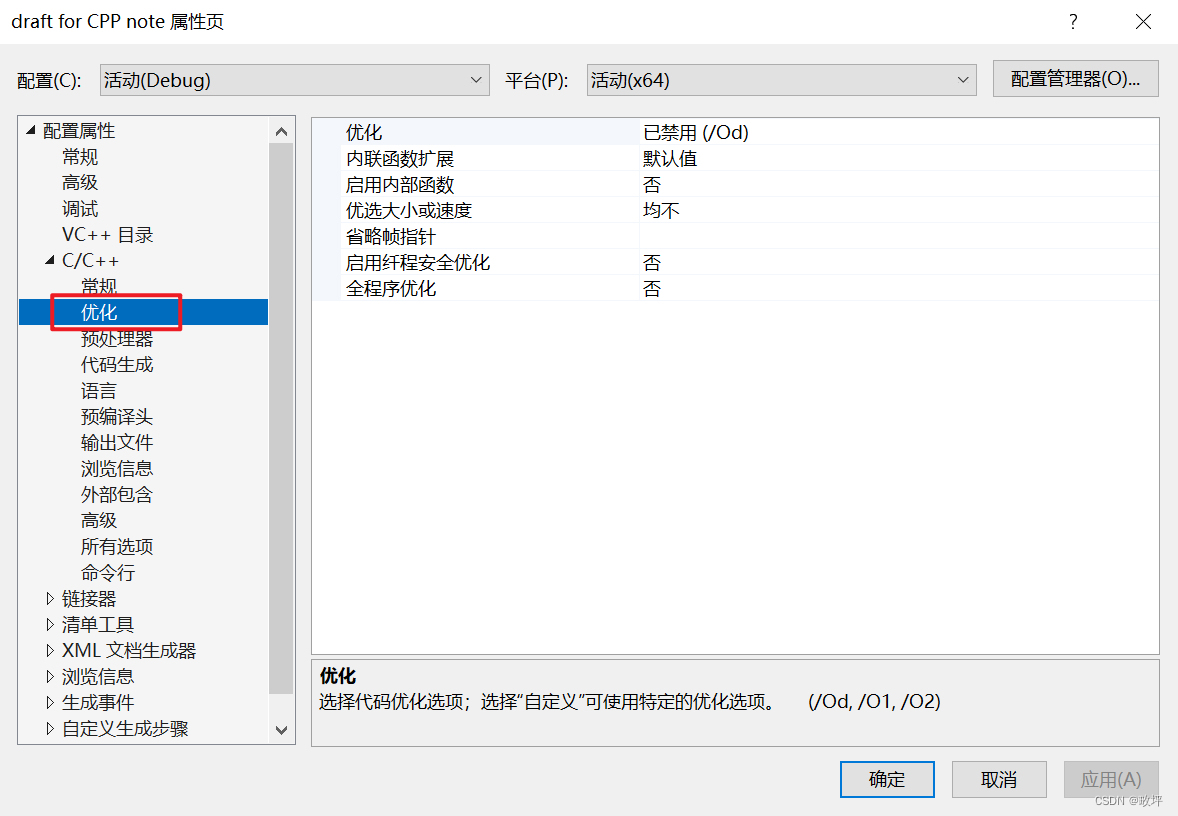
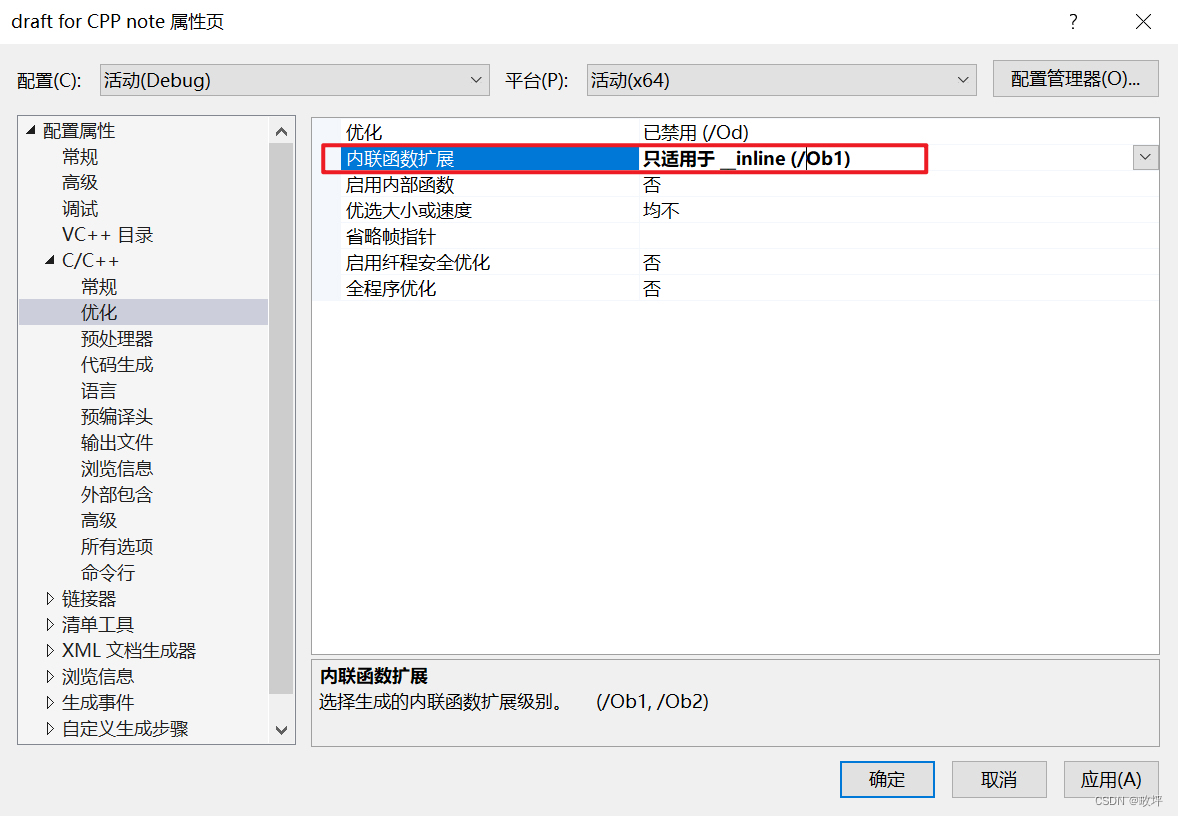

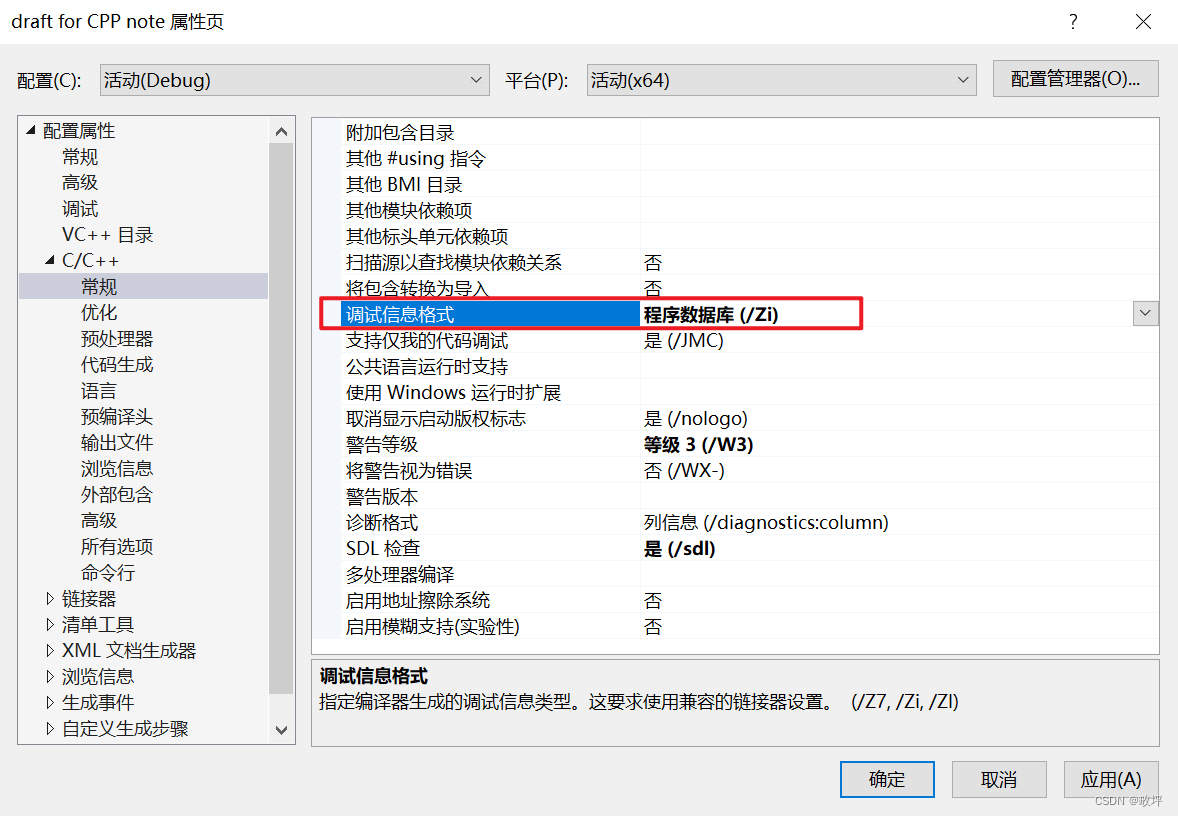
- 调用函数:
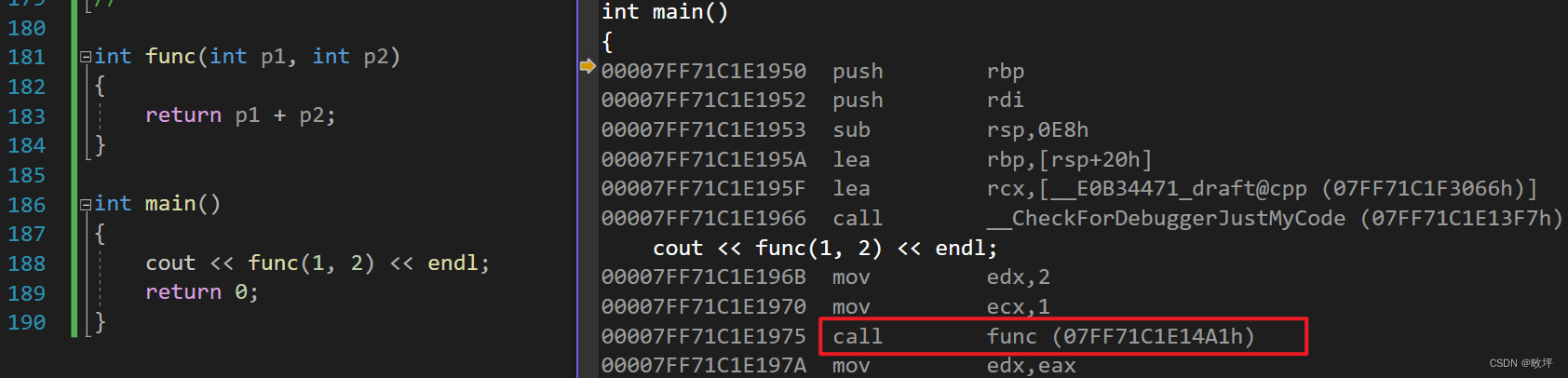
- 内联函数:

内联函数的特性
- inline 是一种以空间换时间的做法。
- inline 内联说明只是向编译器发送一个请求,最终是否展开由编译器决定。
- inline 不建议声明和定义分离,分离会导致链接错误。因为内联函数会被直接展开,不进符号表 ,链接就会找不到。
补充:关于代码膨胀
对于内联函数,如果该函数定义包含 100 行代码,调用该函数 100 次,如果被内联展开,最终会被编译成 100*100 行指令,导致代码膨胀。对于非内联函数,如果该函数定义包含 100 行代码,调用该函数 100 次,最终会被编译成 100+100 行指令。因此,体量过大的、调用频繁的函数不建议内联展开。
7. auto_关键字
功能:自动识别类型
int main()
{
int i = 0;
auto v = i;
auto v2 = 0;
return 0;
}Rules_use
- 不能用在函数参数类型声明上:❌void func(auto p){……}
- 不能声明数组:❌auto array[] = { 0 };
补充:查看变量的类型 —— typeid
int main()
{
auto v = 1;
const type_info& vInfo = typeid(v);
cout << vInfo.name() << endl;//output:int
return 0;
}8. 范围 for
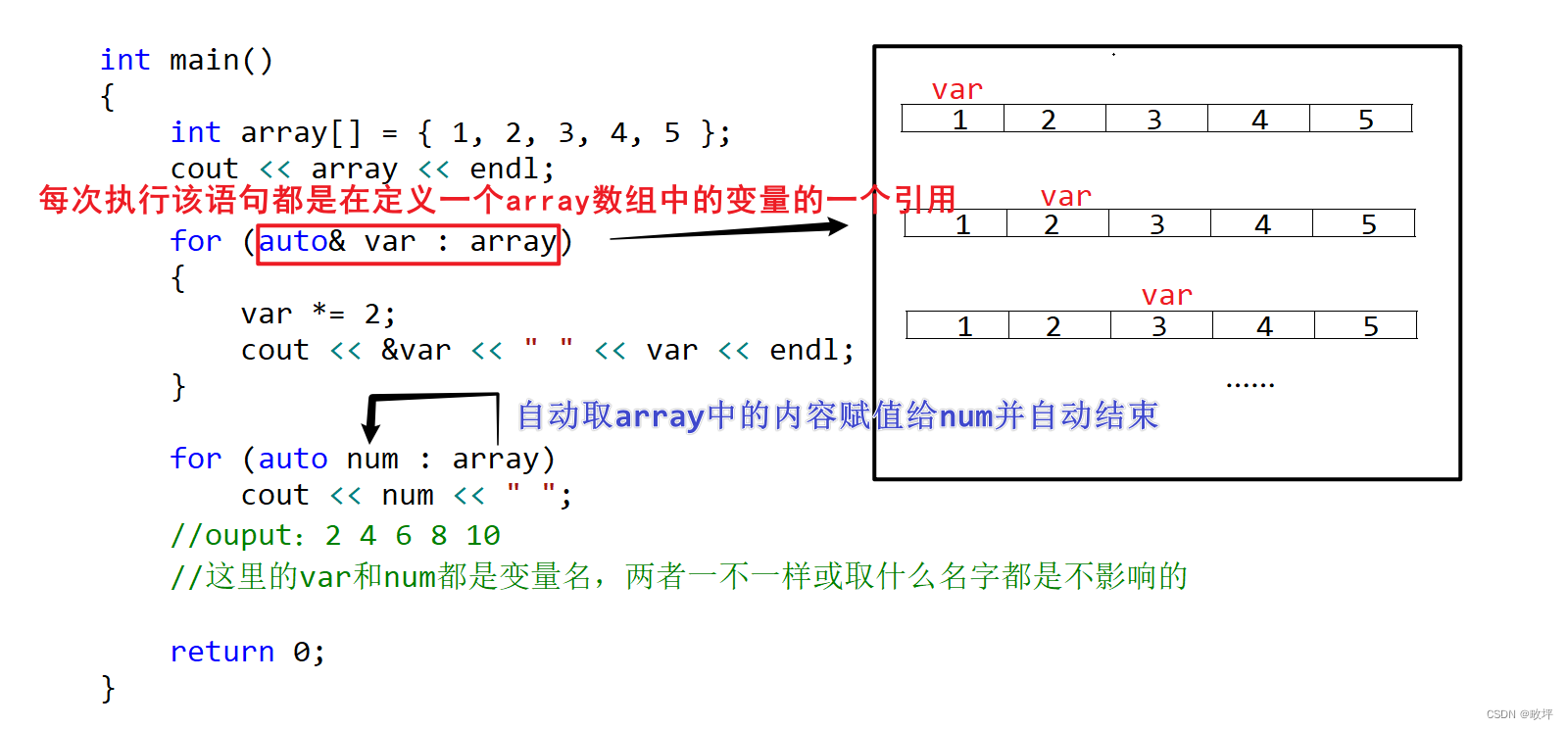
int main()
{
int array[] = { 1, 2, 3, 4, 5 };
cout << array << endl;
for (auto& var : array)
{
var *= 2;
cout << &var << " " << var << endl;
}
for (auto num : array)
cout << num << " ";
//ouput:2 4 6 8 10
//这里的var和num都是变量名,两者一不一样或取什么名字都是不影响的
return 0;
}
注意:
- auto 一般和范围 for 搭配使用,但也可以指明具体的类型,for(int num : array) 类似的写法也是合法的,只是Type 应与 array 的类型相符合;
- 这里的 array 是能是数组名!错误示例如下,函数传参无法传递整个数组,这里实际上只是传过来数组首元素的地址。
void func(int array[]) { for (auto e : array)//error { …… cout << e << endl; } } int main() { int array[] = { 1,2,3,4 }; for (auto e : array[0])//also error { …… } return 0; }
9.nullptr
简而言之,NULL在C++中出现了错误,所以引入 nullptr
#define NULL 0 //error
#define NULL ((void*)0)nullptr 使用注意:
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入 的。
- 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
END