ABSTRACT

深度神经网络在语音识别、计算机视觉和自然语言处理等方面取得了巨大的成果,但是对于推荐系统尚且缺少。虽然即使有用深度学习作为推荐,但是都是对建模起辅助作用。当涉及到用户和项目之间的交互,都会选择流行的矩阵分解(MF),因此基于上面的情况这篇论文的作者提出了一个基于协同过滤的神经网络通用框架——NCF,其中选择使用MLP来学习用户-项目的交互函数。
1. INTRODUCTION
个性化推荐主要使用矩阵因子分解,通过用户过去与项目的互动来建模从而得出用户对项目的偏好,同时对于后续的研究也基本都是致力于增强MF,但是提升效果并不是很大。基于此论文做出的主要三点贡献:

(1)提出了一种神经网络结构来建模用户和项目的潜在特征,并设计了一个基于神经网络的协同过滤的通用框架NCF。
(2)表明,MF可以被解释为NCF的一个专门化,并利用一个多层感知器来赋予NCF模型一个高水平的非线性。
(3)在两个真实世界的数据集上进行了广泛的实验,证明NCF方法的有效性和对协作过滤的深度学习的前景。
2.PRELIMINARIES
主要讲述了隐式反馈进行协同过滤的解决方案,简要概括MF
2.1 Learning from Implicit Data
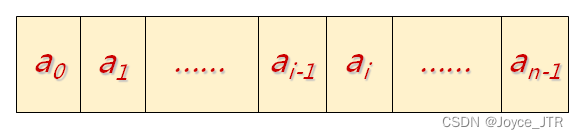
定义Y是一个M*N的用户-项目交互矩阵,矩阵中的元素根据用户和项目之间是否存在交互关系来定义,即:

如下图所示:

注意:这里用户i对应项目i的1并不一定是喜欢,同时用户i对应项目i的0不一定是不喜欢,有可能是因为用户完全还不知道有这个项目,从而导致数据的缺失形成的情况,这也是隐式数据的一个特点。
2.2 Matrix Factorization
将每个用户和物品和一个潜在特征的实值向量联系起来,用和
分别表示用户和项目,通过内积的方法来预测用户对该项目的爱好程度:
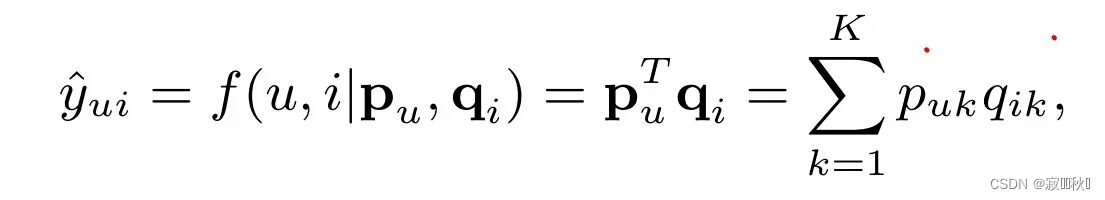
这里通过Jaccard作为两两用户相似性的计算方法:
这样通过简单的计算内积计算得到复杂的用户与项目直接的关系,可能会使MF存在一定的局限性,同时也很容易导致结果过拟合。
3. NCF model
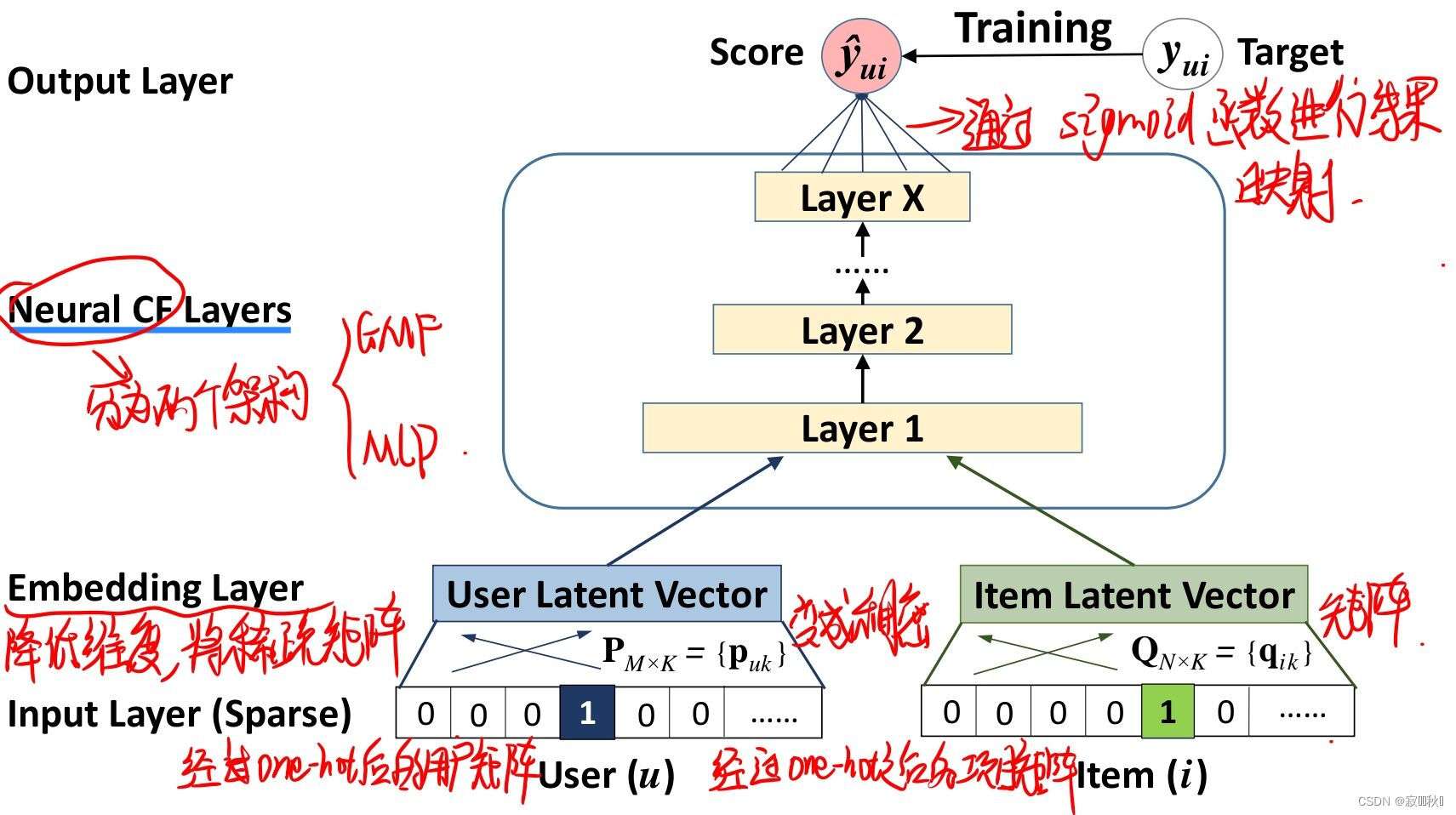
3.1 模型架构图
3.2 模型架构公式
(1)NCF预测模型

(2)上面公式中f()函数定义的多层神经网络,它表示如下:
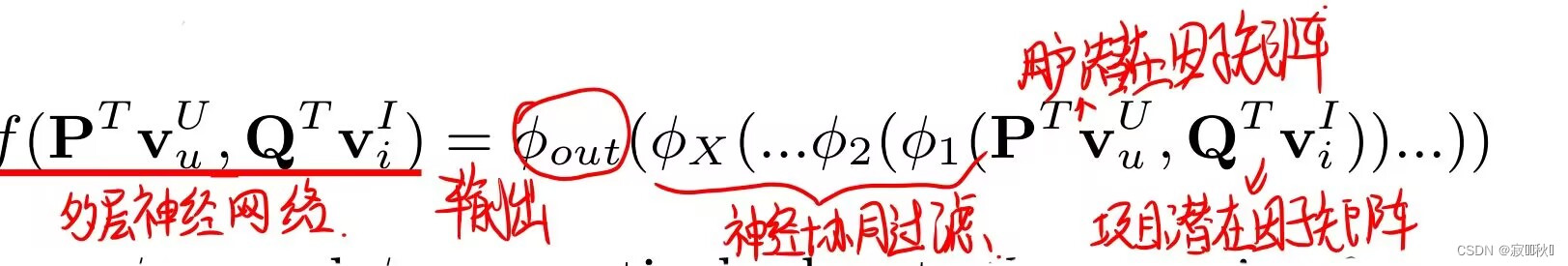
3.3 网络层描述
3.3.1 输入层
输入的是过了一层one-hot用户矩阵向量和项目矩阵向量
3.3.2 embedding层
因为经过one-hot出来的用户矩阵和项目矩阵是稀疏矩阵,这里经过embedding层将稀疏矩阵映射成稠密矩阵
3.3.3 Neutral CF层
网络模型架构这里是经过多层的全连接进行映射,不断的进行维度变化,使得来逼近训练数据的真实概率分布。
(这里也有点困惑,后面的由Neutral CF的模型架构与这又是否有区别,我的认识是这里就是多层的下面的模型架构堆叠,当然这只是我自己的理解。)
3.3.4 输出层
通过sigmoid函数将结果映射到输出的维度,得到最后的预测结果。
3.4 损失函数
(1)一般常用的损失函数是平方损失回归:
(2)论文中提出来一个新关注于隐式数据的损失函数
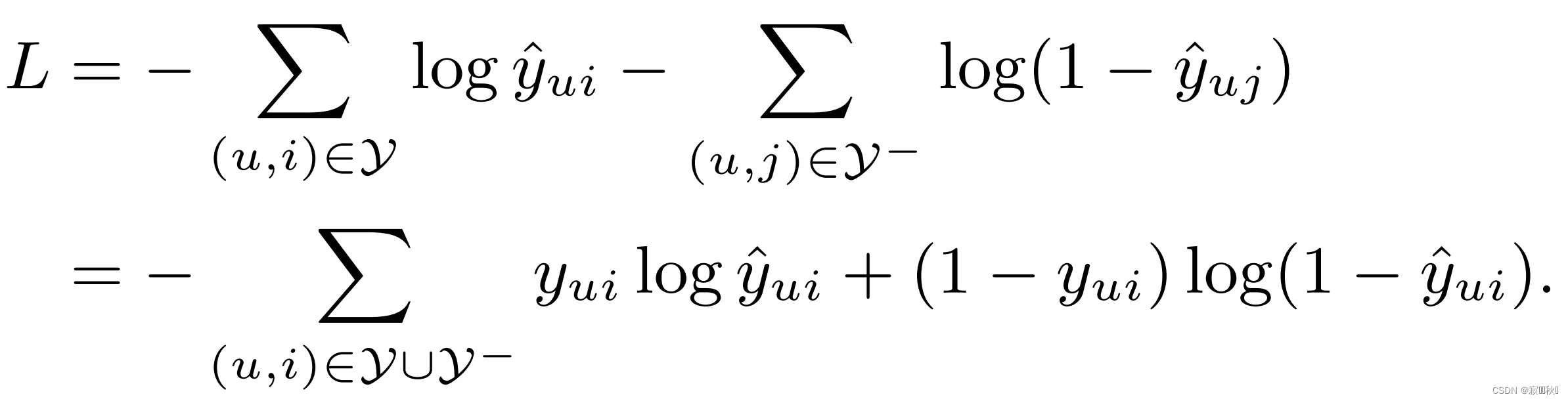
3.5 Neutral CF
3.5.1 模型架构图
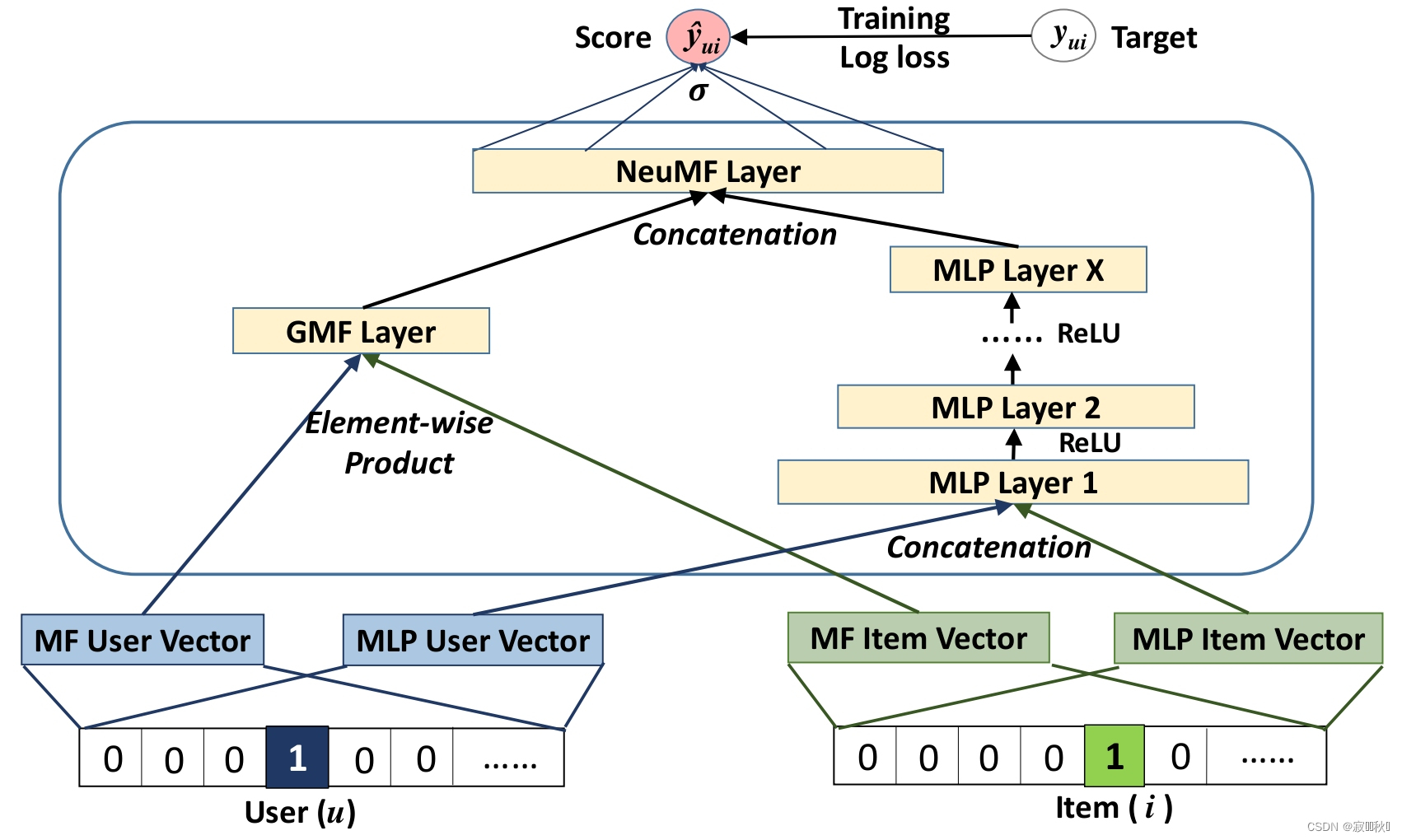
3.5.2 GMF
(1)模型架构在上面就是将用户和项目矩阵做内积,然后通过一层激活函数,进行维度映射。(激活函数选择为sigmoid函数)
(2)模型公式

3.5.3 MLP
(1)和我们平常理解的MLP模型相同,这里主要是对用户和项目做交互,更换了以前的MF的简单不足,当然这里的模型架构也是在上面图中,用户和项目经过多层MLP进行不同维度的全连接,网络层级为塔型,逐级减半,提取更多的隐式特征。(选择的激活函数是ReLU)
(2)模型公式(n层MLP)

3.5.4 GMF和n层MLP的fusion
(1) 一种简单的方法
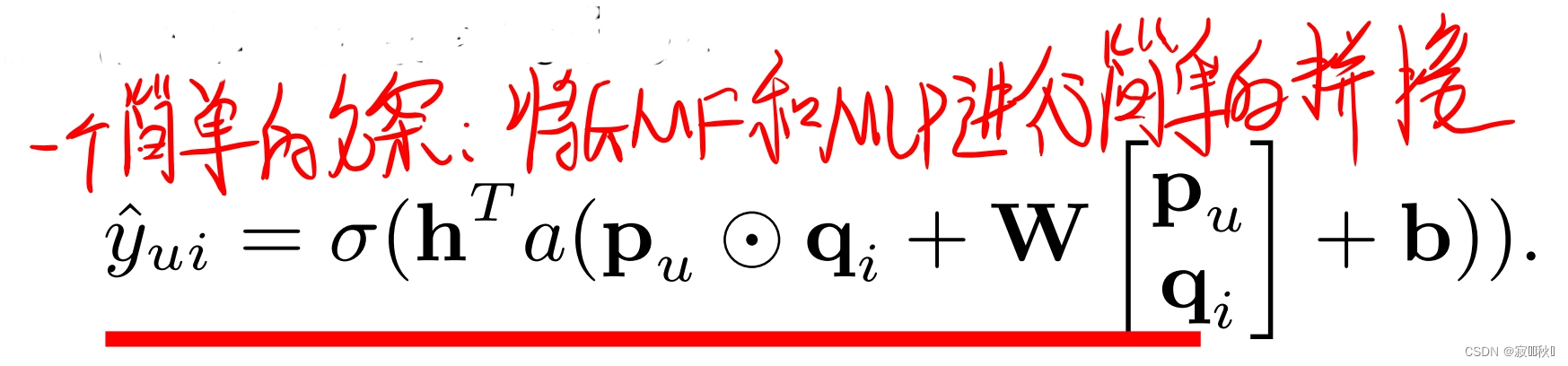
(2)分开训练,最后连接隐藏层h。

3.4 Pre-training
将GMF和MLP单独分开训练,然后加载预训练好的权重,通过给出不同的权重值进行组合,从而实现Pre-training(个人理解,不是很清楚)

4.具体案例代码
4.1 NCF实例代码模型架构
此代码来自Datawhale推荐系统论文组队学习task1中的代码实现,以下主要展示模型的架构。
class NCF(nn.Module):
def __init__(self,
# 经过embedding层之后的维度
embedding_dim = 16,
# 映射层
vocab_map = None,
# 损失函数
loss_fun = 'torch.nn.BCELoss()'):
super(NCF, self).__init__()
# 定义各个层的维度变化
# embedding层
self.embedding_dim = embedding_dim
# 映射层
self.vocab_map = vocab_map
# 损失函数
self.loss_fun = eval(loss_fun) # self.loss_fun = torch.nn.BCELoss()
# 用户矩阵过embedding层
self.user_emb_layer = nn.Embedding(self.vocab_map['user_id'],
self.embedding_dim)
# 项目矩阵过embedding层
self.item_emb_layer = nn.Embedding(self.vocab_map['item_id'],
self.embedding_dim)
# MLP层
self.mlp = nn.Sequential(
nn.Linear(2*self.embedding_dim,self.embedding_dim),
nn.ReLU(inplace=True),
nn.BatchNorm1d(self.embedding_dim),
nn.Linear(self.embedding_dim,1),
nn.Sigmoid()
)
def forward(self,data):
# embedding层
user_emb = self.user_emb_layer(data['user_id']) # [batch,emb]
item_emb = self.item_emb_layer(data['item_id']) # [batch,emb]
# 进行全连接
mlp_input = torch.cat([user_emb, item_emb],axis=-1)
# 过n层MLP
y_pred = self.mlp(mlp_input)
if 'label' in data.keys():
loss = self.loss_fun(y_pred.squeeze(),data['label'])
output_dict = {'pred':y_pred,'loss':loss}
else:
output_dict = {'pred':y_pred}
return output_dict4.2 Neural MF实例代码模型架构
此代码经过自己修改上面的模型架构得到的Neural MF模型,当然各个网络层的映射与上面原论文中的参数设置并不相同。
class NeuralMF(nn.Module):
def __init__(self,
embedding_dim = 32,
vocab_map = None,
loss_fun = 'torch.nn.MSELoss()'):
super(NeuralMF, self).__init__()
self.dim_mlp = [64, 256, 128, 64, 32]
self.embedding_dim = embedding_dim
self.vocab_map = vocab_map
self.loss_fun = eval(loss_fun) # self.loss_fun = torch.nn.BCELoss()
# gmf对用户id和项目id进行编码(输出为16)
self.user_emb_layer_gmf = nn.Embedding(self.vocab_map['uid'], 32)
self.item_emb_layer_gmf = nn.Embedding(self.vocab_map['iid'], 32)
# mlp对用户id和项目id进行编码(输出为16)
self.user_emb_layer_mlp = nn.Embedding(self.vocab_map['uid'], 32)
self.item_emb_layer_mlp = nn.Embedding(self.vocab_map['iid'], 32)
# 过一个线性+激活函数+归一化+(这里线性先不进行)
self.fc_layers = torch.nn.ModuleList()
for idx, (in_size, out_size) in enumerate(zip(self.dim_mlp[:-1], self.dim_mlp[1:])):
self.fc_layers.append(torch.nn.Linear(in_size, out_size))
# 最后过一个线性
self.affine_output = nn.Linear(2 * 32, 1)
self.logistic = torch.nn.Sigmoid()
def forward(self,data):
# gmf_vector进行矩阵相乘
user_emb_gmf = self.user_emb_layer_gmf(data['uid']) # [batch,emb]
item_emb_gmf = self.item_emb_layer_gmf(data['iid']) # [batch,emb]
mf_vector = torch.mul(user_emb_gmf, item_emb_gmf)
# 进行连接并过一层mlp
user_emb_mlp = self.user_emb_layer_mlp(data['uid']) # [batch,emb]
item_emb_mlp = self.item_emb_layer_mlp(data['iid']) # [batch,emb]
mlp_vector = torch.cat([user_emb_mlp, item_emb_mlp], dim=-1)
for idx, _ in enumerate(range(len(self.fc_layers))):
mlp_vector = self.fc_layers[idx](mlp_vector)
mlp_vector = torch.nn.Dropout(0.8)(mlp_vector)
mlp_vector = torch.nn.ReLU()(mlp_vector)
# 将上面gmf和mlp进行组合
vector = torch.cat([mlp_vector, mf_vector], dim=-1)
y_pred = self.affine_output(vector)
if 'label' in data.keys():
loss = self.loss_fun(y_pred.squeeze(),data['label'])
output_dict = {'pred':y_pred,'loss':loss}
else:
output_dict = {'pred':y_pred}
return output_dict
![[附源码]Python计算机毕业设计 校园疫情防控系统](https://img-blog.csdnimg.cn/a55a42dd06fa4f72be7bb8e3d80e7e38.png)