写在前面
- 准备考试,整理
Ceph相关笔记 - 博文内容涉及,
管理和定制CRUSH Map以及管理OSD Map - 理解不足小伙伴帮忙指正
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
管理和定制CRUSH Map
CRUSH和目标放置策略
Ceph 通过一种称为 CRUSH(可伸缩哈希下的受控复制)的放置算法来计算哪些osd应该持有哪些对象,对象被分配到放置组(pg), CRUSH 决定这些 放置组 应该使用哪个 osd来存储它们的对象,即 crush 决定了 pg 到 osd 的映射关系
CRUSH的算法
CRUSH算法 使 Ceph客户端能够直接与 osd通信,这避免了集中式服务瓶颈,Ceph客户端和 osd使用CRUSH 算法高效地计算对象位置的信息,而不是依赖于一个中央查找表。
Ceph 客户端检索集群映射,并使用 CRUSH Map 从算法上确定如何存储和检索数据,通过避免单点故障和性能瓶颈,这为Ceph 集群提供了大规模的可伸缩性
CRUSH算法 的作用是将 数据统一分布在对象存储中,管理复制,并响应系统增长和硬件故障,当 新增OSD或已有OSD或OSD主机故障 时,Ceph通过CRUSH在主OSD间实现集群对象的再平衡
CRUSH Map 组件
从概念上讲,一个CRUSH map包含两个主要组件:
CRUSH层次结构
这将列出所有可用的 osd,并将它们组织成树状的桶结构
CRUSH层次结构通常用来表示osd的位置,默认情况下,有一个root桶代表整个层次结构,其中包含每个OSD主机的一个主机桶
[root@clienta ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.09796 root default
-3 0.03918 host serverc
0 hdd 0.00980 osd.0 up 1.00000 1.00000
1 hdd 0.00980 osd.1 up 1.00000 1.00000
2 hdd 0.00980 osd.2 up 1.00000 1.00000
9 hdd 0.00980 osd.9 up 1.00000 1.00000
-5 0.02939 host serverd
3 hdd 0.00980 osd.3 up 1.00000 1.00000
4 hdd 0.00980 osd.4 up 1.00000 1.00000
5 hdd 0.00980 osd.5 up 1.00000 1.00000
-7 0.02939 host servere
6 hdd 0.00980 osd.6 up 1.00000 1.00000
7 hdd 0.00980 osd.7 up 1.00000 1.00000
8 hdd 0.00980 osd.8 up 1.00000 1.00000
[root@clienta ~]#
OSD是树的叶子节点,默认情况下,同一个OSD主机上的所有OSD都放在该主机的桶中,可以自定义树状结构,重新排列,增加层次,将OSD主机分组到不同的桶中,表示其在不同的服务器机架或数据中心的位置
至少有一条CRUSH规则
CRUSH 规则决定了如何从这些桶中分配放置组的osd,这决定了这些放置组的对象的存储位置。不同的池可能会使用不同的CRUSH规则
CRUSH 桶类型
CRUSH 层次结构将 osd 组织成一个由不同容器组成的树,称为桶。对于大型安装,可以创建特定的层次结构来描述存储基础设施:数据中心、机架、主机和OSD设备。
通过创建一个CRUSH map规则,可以使 Ceph 将一个对象的副本放在独立服务器上的osd上,放在不同机架的服务器上,甚至放在不同数据中心的服务器上
总而言之,桶是 CRUSH层次结构中的容器或分支。osd设备是CRUSH等级中的叶子
一些最重要的桶属性有:
- 桶ID,这些id为负数,以便与存储设备的id区分开来
- 桶的名称
- 桶的类型,默认映射定义了几种类型,可以使用
ceph osd crush dump命令检索这些类型
[root@clienta ~]# ceph osd crush dump | grep type_name
"type_name": "root",
"type_name": "root",
"type_name": "host",
"type_name": "host",
"type_name": "host",
"type_name": "host",
"type_name": "host",
"type_name": "host",
[root@clienta ~]#
桶类型包括root、region、datacenter、room、pod、pdu、row、rack、chassis和host,但你也可以添加自己的类型、位于层次结构根的桶属于根类型
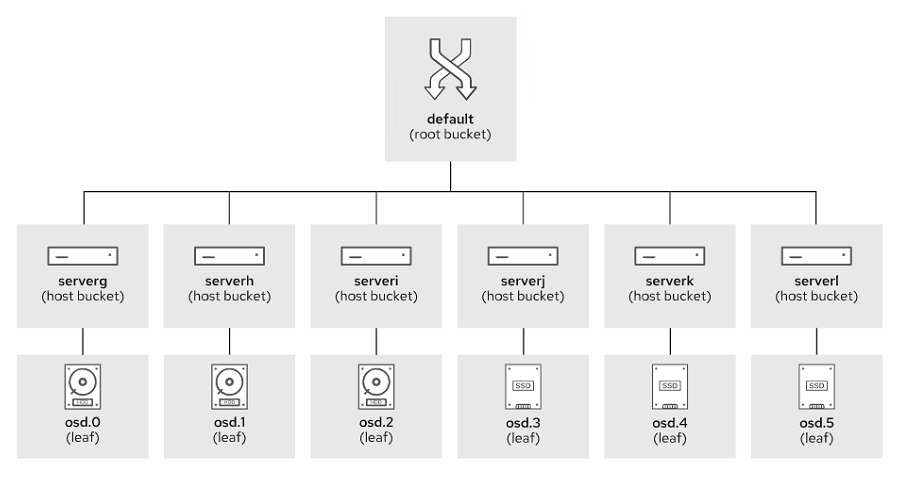
Ceph 在将 PG 副本映射到 osd 时选择桶内物品的算法。有几种算法可用:uniform、list、tree和straw2。每种算法都代表了性能和重组效率之间的权衡。缺省算法为straw2
Uniform(均等分配):Uniform 算法简单地将数据均匀地分配给存储集群中的 OSD(Object Storage Device)。优点是实现简单,能够提供基本的负载均衡效果。然而,它无法考虑 OSD 的实际负载情况,可能导致一些 OSD 负载过高而其他 OSD 负载较轻。
List(列表调度):List 算法根据预定义的 OSD 列表顺序来分配数据。优点是可以根据需求灵活地配置 OSD 列表,适用于特定的负载均衡需求。然而,如果 OSD 列表中的 OSD 负载不均匀,可能导致一些 OSD 过载而其他 OSD 闲置。
Tree(树状调度):Tree 算法使用树状结构来分配数据,将数据在多个层级的 OSD 中进行选择。优点是可以根据 OSD 的性能和负载情况进行智能调度,将数据分配给性能较好的 OSD。然而,实现相对复杂,需要维护和调整树状结构,适用于较大规模的负载均衡场景。
Straw2(稻草算法):Straw2 算法考虑了 OSD 的负载和权重指标,并根据这些指标计算出一个权重值,然后根据权重值来分配数据。优点是可以根据 OSD 的实时负载情况进行智能调度,将数据分配给负载较轻的 OSD。然而,计算权重值需要一定的计算资源,且可能导致数据在短时间内频繁迁移。
自定义故障和性能域
CRUSH 映射是 CRUSH算法 的 中心配置机制,可以编辑此 map 以影响数据放置并自定义CRUSH算法
- 配置
CRUSH 映射和创建单独的故障域允许 osd 和集群节点发生故障,而不会发生任何数据丢失。在问题解决之前,集群只是以降级状态运行 - 配置
CRUSH Map并创建单独的性能域可以减少使用集群存储和检索数据的客户机和应用程序的性能瓶颈。
定制 CRUSH Map 的典型用例
- 针对
硬件故障提供额外的保护。可以配置CRUSH Map以匹配底层物理基础设施,这有助于减轻硬件故障的影响
默认情况下,CRUSH算法将复制的对象放置在不同主机上的osd上。可以定制CRUSH map,这样对象副本就可以跨osd放置在不同的架子上,或者放置在不同房间的主机上,或者放置在具有不同电源的不同架子上
- 将带有
SSD驱动器的osd分配给需要快速存储的应用程序使用的池,而将带有传统hdd的osd分配给支持要求较低的工作负载的池
CRUSH map可以包含多个层次结构,你可以通过不同的CRUSH规则进行选择。通过使用单独的 CRUSH 层次结构,可以建立单独的性能域。例如,CRUSH 可以为 hdd 创建一个层次结构,为 ssd 创建另一个层次结构
配置单独性能域的用例示例如下:
-
分离虚拟机使用的块存储和应用使用的对象存储 -
将包含不经常访问的数据的
“冷”存储区与包含经常访问的数据的“热”存储区分开
一个实际的CRUSH map定义,它包含:
- 所有可用物理存储设备的
列表 - 所有基础设施
桶的列表,以及每个桶中存储设备或其他桶的id。请记住,bucket是基础结构树中的容器或分支,例如,它可能表示一个位置或一块物理硬件 - 将
pg映射到osd的CRUSH规则列表 - 其他
CRUSH可调参数及其设置的列表
集群安装过程部署一个默认的CRUSH映射,可以使用ceph osd crush dump命令打印JSON格式的crush map。你也可以导出映射的二进制副本,并将其反编译为文本文件:
[ceph: root@node /]# ceph osd getcrushmap -o ./map.bin
[ceph: root@node /]# crushtool -d ./map.bin -o ./map.txt
自定义OSD CRUSH设置
CRUSH Map包含集群中所有存储设备的列表。对于每台存储设备,已获取如下信息:
- 存储设备的
ID - 存储设备的
名称 - 存储设备的
权重,通常以tb为单位。
例如,4tb的存储设备重量约为4.0。这是设备可以存储的相对数据量,CRUSH算法使用这一数据来帮助确保对象的均匀分布
host serverc {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.039
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.010
item osd.1 weight 0.010
item osd.2 weight 0.010
item osd.9 weight 0.010
}
可以通过ceph osd crush reweight命令设置OSD的权重。CRUSH的树桶权重应该等于它们的叶子权重的总和。
如果手动编辑 CRUSH Map权重,那么应该执行以下命令来确保CRUSH树桶的权重准确地反映了桶内叶片osd的总和
[ceph: root@node /)# ceph osd crush reweight-all
reweighted crush hierarchy
- 存储设备的
类别,存储集群支持多种存储设备,如hdd、ssd、NVMe ssd等。
存储设备的类反映了这些信息,可以使用这些信息创建针对不同应用程序工作负载优化的池。osd自动检测和设置它们的设备类。ceph osd crush set-device-class命令用于显式设置OSD的设备类。
使用ceph osd crush rm device-class 从 osd 中删除一个设备类
ceph osd crush tree命令显示crush map当前的层级:
[ceph: root@clienta /]# ceph osd crush tree
ID CLASS WEIGHT TYPE NAME
-1 0.08817 root default
-3 0.02939 host serverc
0 hdd 0.00980 osd.0
1 hdd 0.00980 osd.1
2 hdd 0.00980 osd.2
-5 0.02939 host serverd
3 hdd 0.00980 osd.3
5 hdd 0.00980 osd.5
7 hdd 0.00980 osd.7
-7 0.02939 host servere
4 hdd 0.00980 osd.4
6 hdd 0.00980 osd.6
8 hdd 0.00980 osd.8
设备类是通过为每个正在使用的设备类创建一个“影子”CRUSH层次结构来实现的,它只包含该类设备。
然后,CRUSH规则可以在影子层次结构上分发数据。
你可以使用ceph osd crush tree --show-shadow命令查看带有影子的crush 层级`
[ceph: root@serverc /]# ceph osd crush tree --show-shadow
ID CLASS WEIGHT TYPE NAME
-2 hdd 0.09796 root default~hdd
-4 hdd 0.03918 host serverc~hdd
0 hdd 0.00980 osd.0
1 hdd 0.00980 osd.1
2 hdd 0.00980 osd.2
9 hdd 0.00980 osd.9
-6 hdd 0.02939 host serverd~hdd
3 hdd 0.00980 osd.3
4 hdd 0.00980 osd.4
5 hdd 0.00980 osd.5
-8 hdd 0.02939 host servere~hdd
6 hdd 0.00980 osd.6
7 hdd 0.00980 osd.7
8 hdd 0.00980 osd.8
- 使用
ceph osd crush class create命令创建一个新的设备类 - 使用
ceph osd crush class rm命令删除一个设备类 - 使用
ceph osd crush class ls命令列出已配置的设备类
[ceph: root@serverc /]# ceph osd crush class ls
[
"hdd"
]
[ceph: root@serverc /]# ceph osd crush class create ssd
created class ssd with id 1 to crush map
[ceph: root@serverc /]# ceph osd crush class ls
[
"hdd",
"ssd"
]
[ceph: root@serverc /]# ceph osd crush class rm ssd
removed class ssd with id 1 from crush map
[ceph: root@serverc /]# ceph osd crush class ls
[
"hdd"
]
[ceph: root@serverc /]#
使用CRUSH规则
CRUSH map还包含数据放置规则,决定如何将pg映射到osd,以存储对象副本或 erasure coded块
ceph osd crush rule ls命令在已有的规则基础上,打印规则详细信息。ceph osd crush rule dump rule_name命令打印规则详细信息,
[ceph: root@serverc /]# ceph osd crush rule ls
replicated_rule
ecpool
[ceph: root@serverc /]# ceph osd crush rule dump ecpool
{
"rule_id": 1,
"rule_name": "ecpool",
"ruleset": 1,
"type": 3,
"min_size": 3,
"max_size": 5,
"steps": [
{
"op": "set_chooseleaf_tries",
"num": 5
},
{
"op": "set_choose_tries",
"num": 100
},
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "choose_indep",
"num": 0,
"type": "osd"
},
{
"op": "emit"
}
]
}
[ceph: root@serverc /]#
- 编译后的
CRUSH map也包含规则,可能更容易阅读:
[ceph: root@node /]# ceph osd getcrushmap -o . /map.bin
[ceph: root@node /]# crushtool -d . /map.bin -o . /map.txt
[ceph: root@node /]# cat . /map.txt
. . . output omitted ...
rule replicated_rule { AA
id 0 BB
}
type replicated
min_size 1 CC
max_size 10 DD
step take default EE
step chooseleaf firstn 0 type host FF
step emit GG
. . . output omitted ...
AA规则的名称。使用ceph osd pool create命令创建池时,使用此名称来选择规则BB规则ID。有些命令使用规则ID而不是规则名称。例如ceph osd pool set pool-name rush_ruleset ID,为已存在的池设置规则时使用规则IDCC如果一个池的副本数少于这个数字,那么CRUSH不选择此规则DD如果一个存储池的副本数超过这个数字,那么CRUSH不选择此规则EE接受一个桶名,并开始沿着树进行迭代。在本例中,迭代从名为default的桶开始,它是缺省CRUSH层次结构的根。对于由多个数据中心组成的复杂层次结构,可以为数据创建规则,用于强制将特定池中的对象存储在该数据中心的osd中。在这种情况下,这个步骤可以从数据中心桶开始迭代FF选择给定类型(host)的桶集合,并从该集合中每个桶的子树中选择一个叶子(OSD)。本例中,规则从集合中的每个主机桶中选择一个OSD,确保这些OSD来自不同的主机。
支持的类型
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
集合中桶的数量通常与池中的副本数量(池大小)相同:
- 如果firstn后面的数字为0,则根据池中有多少副本选择多少桶
- 如果桶的数量大于零,且小于池中的副本数量,则选择相同数量的桶。在这种情况下,规则需要另一个步骤来为剩余的副本绘制桶。可以使用这种机制强制指定对象副本子集的位置
- 如果这个数字小于零,那么从副本数量中减去它的绝对值,然后选择这个数量的桶
GG 输出规则的结果
例如,可以创建以下规则来在不同的机架上选择尽可能多的osd,但只能从DC1数据中心:
rule myrackruleinDC1 {
id 2
type replicated
min_size 1
max_size 10
step take DC1
step chooseleaf firstn 0 type rack
step emit
}
使用CRUSH可调参数
还可以使用可调参数修改CRUSH算法的行为。可调项可以调整、禁用或启用CRUSH算法的特性。
Ceph在反编译的 CRUSH Map的开始部分定义了可调参数,你可以使用下面的命令获取它们的当前值:
[ceph: root@clienta /]# ceph osd crush show-tunables
{
"choose_local_tries": 0,
"choose_local_fallback_tries": 0,
"choose_total_tries": 50,
"chooseleaf_descend_once": 1,
"chooseleaf_vary_r": 1,
"chooseleaf_stable": 1,
"straw_calc_version": 1,
"allowed_bucket_algs": 54,
"profile": "jewel",
"optimal_tunables": 1,
"legacy_tunables": 0,
"minimum_required_version": "jewel",
"require_feature_tunables": 1,
"require_feature_tunables2": 1,
"has_v2_rules": 0,
"require_feature_tunables3": 1,
"has_v3_rules": 0,
"has_v4_buckets": 1,
"require_feature_tunables5": 1,
"has_v5_rules": 0
}
调整CRUSH可调项可能会改变CRUSH将放置组映射到osd的方式。当这种情况发生时,集群需要将对象移动到集群中的不同osd,以反映重新计算的映射。在此过程中,集群性能可能会下降。
可以使用ceph osd crush tunables profile 命令选择一个预定义的配置文件,而不是修改单个可调项。
[ceph: root@serverc /]# ceph osd crush tunables profile
Invalid command: profile not in legacy|argonaut|bobtail|firefly|hammer|jewel|optimal|default
osd crush tunables legacy|argonaut|bobtail|firefly|hammer|jewel|optimal|default : set crush tunables values to <profile>
Error EINVAL: invalid command
[ceph: root@serverc /]#
[ceph: root@serverc /]# ceph osd crush tunables optimal
adjusted tunables profile to optimal
将配置文件的值设置为optimal,以启用Red Hat Ceph Storage当前版本的最佳(最优)值。
CRUSH Map 管理
集群保持一个编译后的CRUSH map的二进制表示。你可以通过以下方式修改它:
- 使用
ceph osd crush命令 - 提取二进制 CRUSH Map并将其编译为
纯文本,编辑文本文件,将其重新编译为二进制格式,然后将其导入到集群中
通常使用ceph osd crush命令更新CRUSH Map会更容易。但是,还有一些不太常见的场景只能通过使用第二种方法来实现。
使用Ceph命令定制CRUSH Map
下面的例子创建了一个新的桶:
[ceph: root@node /]# ceph osd crush add-bucket name type
例如,这些命令创建三个新桶,一个是数据中心类型,两个是机架类型:
[ceph: root@node /)# ceph osd crush add-bucket DC1 datacenter
added bucket DCl type datacenter to crush map
[ceph: root@node /)# ceph osd crush add-bucket rackA1 rack
added bucket rackAl type rack to crush map
[ceph: root@node /)# ceph osd crush add-bucket rackB1 rack
added bucket rackBl type rack to crush map
然后,可以使用以下命令以层次结构组织新桶
[ceph: root@node /]# ceph osd crush move name type=parent
还可以使用此命令重新组织树。例如,将上例中的两个机架桶挂载到数据中心桶上,将数据中心桶挂载到默认的根桶上
[ceph: root@node /]# ceph osd crush move rackA1 datacenter=DC1
moved item id -10 name ' rackA1' to location {datacenter=DCl} in crush map
[ceph: root@node /]# ceph osd crush move rackB1 datacenter=DC1
moved item id -11 name ' rackB1' to location {datacenter=DC1} in crush map
[ceph: root@node /)# ceph osd crush move DC1 root=default
moved item id -9 name ' DC1' to location {root=default} in crush map
ID CLASS WEIGHT TYPE NAME
-1 0.09796 root default
-9 0 datacenter DC1
-10 0 rack rackA1
-11 0 rack rackB1
-3 0.03918 host serverc
0 hdd 0.00980 osd.0
1 hdd 0.00980 osd.1
2 hdd 0.00980 osd.2
9 hdd 0.00980 osd.9
-5 0.02939 host serverd
3 hdd 0.00980 osd.3
4 hdd 0.00980 osd.4
5 hdd 0.00980 osd.5
-7 0.02939 host servere
6 hdd 0.00980 osd.6
7 hdd 0.00980 osd.7
8 hdd 0.00980 osd.8
[root@clienta ~]#
设置 osd 位置
在创建了自定义桶层次结构之后,将 osd 作为该树的叶子放置。每个 OSD 都有一个位置,它是一个字符串,定义从树的根到该OSD的完整路径。
例如,挂在 rackA1 桶上的 OSD 的位置为:
root=default datacenter=DC1 rack=rackA1
当Ceph启动时,它使用ceph-crush-location工具来自动验证每个OSD都在正确的CRUSH位置。
如果OSD不在CRUSH Map中预期的位置,它将被自动移动。默认情况下,这是root=default host=hostname。
可以用自己的脚本替换ceph-crush-location实用程序,以更改osd在CRUSH Map中的位置。
为此,在/etc/ceph/ceph.conf中指定crush_ location_hook参数
[osd]
crush_location_hook = /path/to/your/script
Ceph使用以下参数执行该脚本: --cluster cluster-name --id osd-id --type osd。
脚本必须在其标准输出中以一行的形式打印位置。Ceph文档有一个自定义脚本示例,该脚本假设每个系统都有一个名为/etc/rack的包含所在机架名称的机架文件:
#! /bin/sh
echo "root=default rack=$(cat /etc/rack) host=$(hostname -s)"
特定osd的位置定义
可以在/etc/ceph/ceph.conf中设置crush_location参数。重新定义特定osd的位置。
例如,设置osd.0和osd.1,在文件中各自的部分中添加crush_ location参数:
[osd.0]
crush_location = root=default datacenter=DC1 rack=rackA1
[osd.1]
crush_location = root=default datacenter=DC1 rack=rackB1
添加CRUSH Map规则
复制池
创建了一个Ceph可以用于复制池的规则:
[ceph: root@node /]# ceph osd crush rule create-replicated name \
root failure-domain-type [class]
其中:
- Name 为规则的名称
- root 是CRUSH Map层次结构中的起始节点
- failure-domain-type 是用于复制的桶类型
- 类是要使用的设备的类,例如SSD或hdd。可选参数
下面的示例创建新的inDC2规则来在DC2数据中心存储副本,将副本分发到各个机架:
[ceph: root@node /]# ceph osd crush rule create-replicated inDC2 DC2 rack
[ceph: root@node /]# ceph osd crush rule ls
replicated_rule
erasure-code
inDC2
定义规则后,在创建复制池时使用它:
[ceph: root@node /]# ceph osd pool create myfirstpool 50 50 inDC2
pool 'myfirstpool' created
纠删码池
对于erasure code,Ceph自动为您创建的每个erasure code池创建规则。规则的名称为新池的名称。
Ceph使用您在创建池时指定的erasure code配置文件中定义的规则参数
下面的例子首先创建新的myprofile erasure code配置文件,然后基于这个配置文件创建myecpool池:
[ceph: root@node /]# ceph osd erasure-code-profile set myprofile \
k=2 m=1 crush-root=DC2 crush-failture-domain=rack crush-device-class=ssd
[ceph: root@node /)# ceph osd pool create myecpool 50 50 erasure myprofile
[ceph: root@node /]# ceph osd crush rule ls
通过编译二进制版本自定义CRUSH Map
你可以用以下命令来反编译和手动编辑CRUSH Map:
| 命令 | 动作 |
|---|---|
| ceph osd getcrushmap -o binfiIe | 导出当前映射的二进制副本 |
| crushtool -d binfiIe -o textfiIepath | 将一个 CRUSH Map二进制文件反编译成一个文本文件 |
| crushtool -c textfiIepath -o binfiIe | 从文本中编译一个CRUSH Map |
| crushtool -i binfiIe --test | 在二进制CRUSH Map上执行演练,并模拟放置组的创建 |
| ceph osd setcrushmap -i binfiIe | 将二进制 CRUSH Map导入集群 |
ceph osd getcrushmap和ceph osd setcrushmap命令提供了一种备份和恢复集群CRUSH Map的有效方法
优化放置组PG
放置组(pg)允许集群通过将对象聚合到组中以可伸缩的方式存储数百万个对象。根据对象的ID、池的ID和池中放置组的数量将对象组织成放置组。
在集群生命周期中,pg个数需要根据集群布局的变化进行调整
CRUSH 试图确保对象在池中osd之间的均匀分布,但也存在pg变得不平衡的情况。
放置组自动缩放器可用于优化PG分发,并在默认情况下打开。如果需要,还可以手动设置每个池的pg数量
对象通常是均匀分布的,前提是池中比osd多一个或两个数量级(十个因子)的放置组。
- 如果没有足够的
pg,那么对象的分布可能会不均匀。 - 如果池中存储了少量非常大的对象,那么对象分布可能会变得不平衡
配置pg,以便有足够的对象在集群中均匀分布。如果 pg的数量设置过高,则会显著增加CPU和内存的使用。Red Hat建议每个OSD大约100到200个放置组来平衡这些因素
计算放置组的数量
对于单个池的集群,可以使用以下公式,每个OSD 100个放置组
Total PGs = (OSDs * 100)/Number of replicas
Red Hat推荐使用每个池计算Ceph放置组,https://access.redhat.com/labs/cephpgc/manual/
手动映射PG
使用 ceph osd pg-upmap-iterns 命令手动将pg映射到指定的osd,因为以前的Ceph客户端不支持,所以必须配置ceph osd set-require-min-compat-client启用pg-upmap命令
[ceph: root@node /]# ceph osd set-require-min-compat-client luminous
下面的例子将PG 3.25从ODs 2和0映射到1和0:
[ceph: root@node /]# ceph pg map 3.25
osdmap e384 pg 3.25 (3.25) -> up [2,0) acting [2,0)
[ceph: root@node /]# ceph osd pg-upmap-items 3.25 2 1
set 3.25 pg_ upmap items mapping to [2->1)
[ceph: root@node /]# ceph pg map 3.25
osdmap e387 pg 3.25 (3.25) •> up [1,0) acting [1,0)
以这种方式重新映射数百个pg是不现实的
osdmaptool 命令在这里很有用,它获取一个池的实际 Map,分析它,并生成ceph osd pg-upmap-items命令来运行一个最优分布:
- 将映射导出到一个文件,下面的命令将映射保存到./om文件:
[ceph: root@node /]# ceph osd getmap -o ./om
got osdmap epoch 387
- 使用
osdmaptool命令的--test-map-pgs选项显示pg的实际分布。打印ID为3的池的分布信息:
[ceph: root@node /]# osdmaptool ./om --test-map-pgs --pool 3
osdmaptool: osdmap file './om'
pool 3 pg_num 50
#osd count first primary c wt wt
osd.0 34 19 19 0.0184937 1
osd.1 39 14 14 0.0184937 1
osd.2 27 17 17 0.0184937 1
... output omitted . ..
输出显示了osd.2只有27个PG而osd.1有39 PG
- 生成重新平衡pg的命令。
使用osdmaptool命令的--upmap选项将命令存储在一个文件中:
[ceph: root@node /]# osdmaptool ./om --upmap ./cmds.txt --pool 3
osdmaptool: osdmap file './om'
writing upmap command output to: ./cmds.txt
checking for upmap cleanups
upmap, max-count 100, max deviation 0.01
[ceph: root@node /]# cat ./cmds.txt
ceph osd pg-upmap-items 3.1 0 2
ceph osd pg-upmap-items 3.3 1 2
ceph osd pg-upmap-items 3.6 0 2
... output omitted ...
- 执行命令:
[ceph: root@node /]# bash ./cmds.txt
set 3.1 pg upmap items mapping to [0->2]
set 3.3 pg upmap_items mapping to [1->2]
set 3.6 pg_upmap_items mapping to [0->2]
... output omitted ...
管理OSD Map
描述OSD Map
集群OSD map包含每个OSD的地址、状态、池列表和详细信息,以及OSD的接近容量限制信息等。Ceph使用这些最后的参数来发送警告,并在OSD达到满容量时停止接受写请求
当集群的基础设施发生变化时,比如 osd 加入或离开集群,MONs 会相应地更新相应的映射。Mons保持着map修订的历史。
Ceph使用一组被称为epoch的有序增量整数来标识每个map的每个版本
ceph status -f json-pretty 命令显示每个 map 的 epoch。使用ceph map dump子命令显示每个单独的映射,例如 ceph osd dump
[ceph: root@clienta /]# ceph status -f json-pretty
{
"fsid": "2ae6d05a-229a-11ec-925e-52540000fa0c",
"health": {
"status": "HEALTH_OK",
"checks": {},
"mutes": []
},
"election_epoch": 48,
"quorum": [
0,
1,
2,
3
],
"quorum_names": [
"serverc.lab.example.com",
"clienta",
"serverd",
"servere"
],
"quorum_age": 1961,
"monmap": {
"epoch": 4,
"min_mon_release_name": "pacific",
"num_mons": 4
分析OSD Map更新
每当有 OSD 加入或离开集群时,Ceph 都会更新 OSD 的map。一个OSD可以因为OSD故障或硬件故障而离开 Ceph 集群
虽然整个集群的分布式映射(map)由监控器(MONs)来维护,但是对象存储设备(OSD)并不使用监控器的领导者(leader)来管理存储器的映射。
相反,OSD之间会直接交换它们所持有的映射,并且每次交换都会标记(epoch)出来。当一个 OSD 检测到自己的运行速度落后时,会触发对其对等 OSD 执行映射的更新,以确保所有的 OSD 都具有最新的映射信息。
在大的集群中,OSD map更新频繁,所以总是分发完整的map是不现实的。相反,接收 OSD 的节点执行增量映射更新
Ceph 还将 osd 和客户端之间的消息标记为epoch。每当客户端连接到OSD时,OSD就会检查 epoch。
如果 epoch 不匹配,那么OSD将响应正确的增量,以便客户机可以更新其OSD映射。这就不需要主动传播,因为客户端只有在下一次联系时才会了解更新后的映射
使用Paxos更新集群Map
要访问Ceph集群,客户机首先要从MONs获取集群映射的副本。为了使集群正常运行,所有的MONs必须具有相同的集群映射。
MONs使用Paxos算法作为一种机制来确保它们对集群状态达成一致。Paxos是一种分布式共识算法。
每当MON修改map时,它就通过Paxos将更新发送给其他监视器。Ceph只有在大多数监控器都同意更新后才会提交新版本的map。
MON向Paxos提交map更新,只有在Paxos确认更新后才将新版本写入本地键值存储。读操作直接访问键值存储。
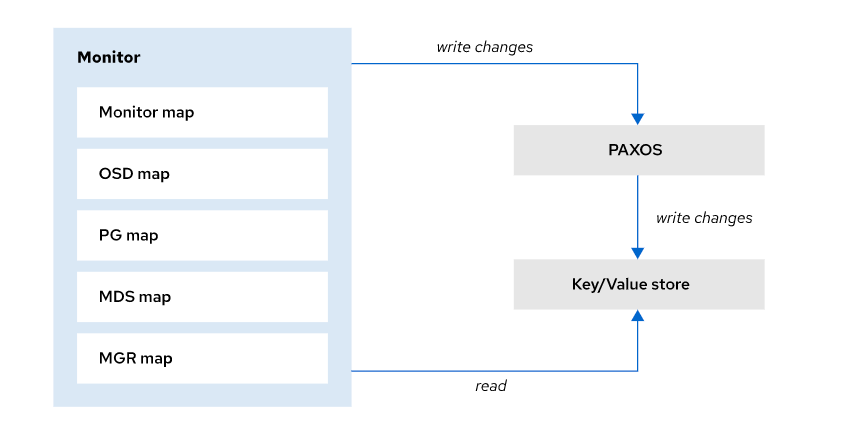
OSD Map 传播
osd 定期向监控器报告其状态。此外,OSD还可以通过交换心跳来检测对等体的故障,并将故障报告给监视器。
当leader监视器得知OSD出现故障时,它会更新Map,增加epoch,并使用 Paxos 更新协议通知其他监视器,同时撤销它们的租约。
在大多数监控器确认更新后,集群有了仲裁,leader 监控器发出新的租约,以便监控器可以分发更新的OSD映射。
OSD Map命令管理员使用以下命令管理 OSD Map:
| 命令 | 动作 |
|---|---|
ceph osd dump | 将OSD映射转储到标准输出 |
ceph osd getmap -o binfile | 导出当前映射的二进制副本 |
osdmaptool --print binfile | 在标准输出中显示人类可读的映射副本 |
osdmaptool --export-crush crushbinfile binfile | 从OSD map 中提取CRUSH map |
osdmaptool --import-crush crushbinfile binfile | 嵌入一个新的CRUSH map |
osdmaptool --test-map-pg pgid binfile | 验证给定PG的映射 |
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知,这是一个开源项目,如果你认可它,不要吝啬星星哦 😃
https://docs.ceph.com/en/pacific/architecture/
https://docs.ceph.com
CL210 授课老师课堂笔记
© 2018-2023 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)