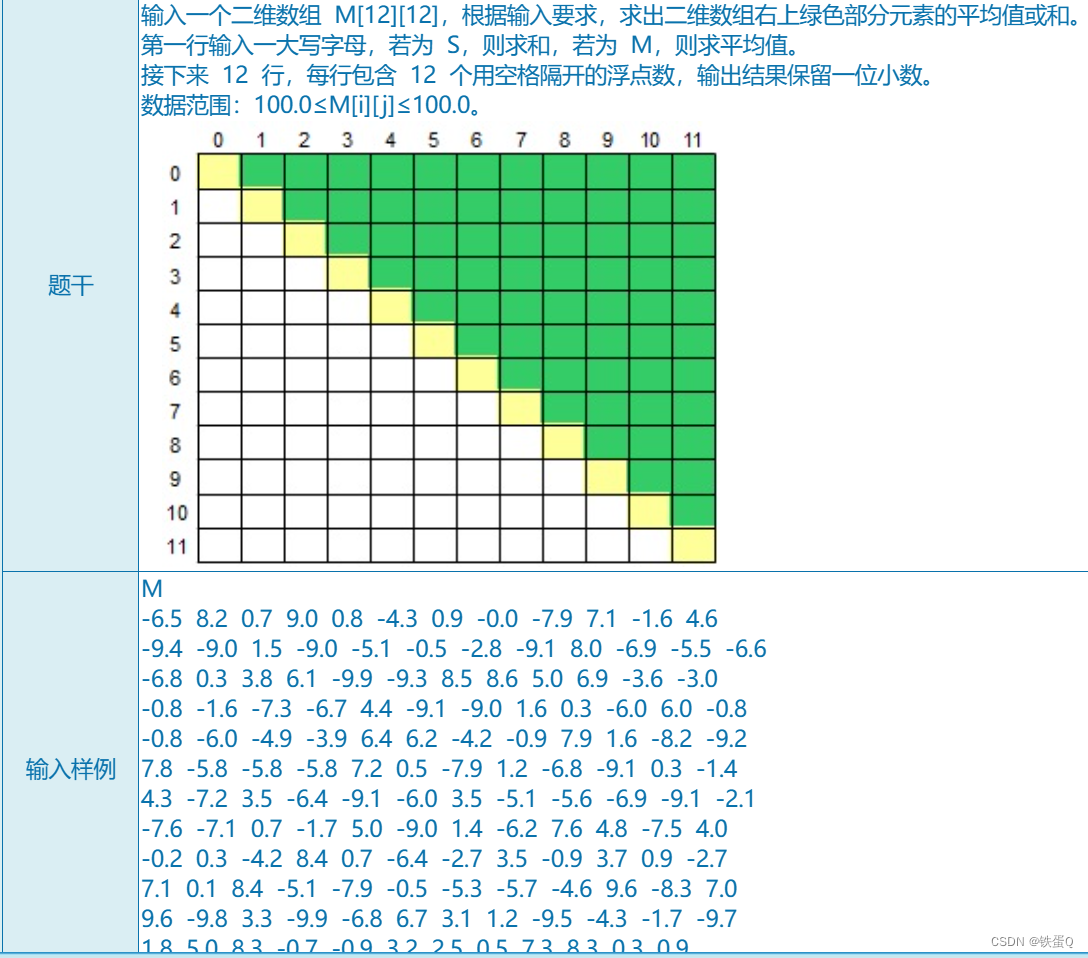
前言
如此前这篇文章《学术论文GPT的源码解读与微调:从chatpaper、gpt_academic到七月论文审稿GPT》中的第三部分所述,对于论文的摘要/总结、对话、翻译、语法检查而言,市面上的学术论文GPT的效果虽暂未有多好,可至少还过得去,而如果涉及到论文的修订/审稿,则市面上已有的学术论文GPT的效果则大打折扣。
原因在哪呢?本质原因在于无论什么功能,它们基本都是基于OpenAI的API实现的,而关键是API毕竟不是万能的,API做翻译/总结/对话还行,但如果要对论文提出审稿意见,则API就捉襟见肘了,故为实现更好的review效果,需要使用特定的对齐数据集进行微调来获得具备优秀review能力的模型
继而,我们在第一版中,做了以下三件事
- 爬取了3万多篇paper、十几万的review数据,并对3万多篇PDF形式的paper做解析
当然,paper中有被接收的、也有被拒绝的 - 为提高数据质量,针对paper和review做了一系列数据处理
- 基于RWKV进行微调,然因其遗忘机制比较严重,故最终效果不达预期
所以,进入Q4后,我司项目团队开始做第二版(我司目前总共在不断迭代三大LLM项目,除了论文审稿GPT之外,还有:AIGC模特生成系统、企业知识库问答),并着重做以下三大方面的优化
- 数据的解析与处理的优化,meta的一个ocr 能提出LaTeX
- 借鉴GPT4做审稿人那篇论文,让ChatGPT API帮爬到的review语料,梳理出来 以下4个方面的内容
1 重要性和新颖性,2 论文被接受的原因,3 论文被拒绝的原因,4 改进建议 - 模型本身的优化,llama longlora或者mistral
第一部分 多种PDF数据的解析
1.1 Meta nougat
nougat是Meta推出的学术PDF解析工具,其主页和代码仓库分别为
- nougat主页
https://facebookresearch.github.io/nougat/ - nougat仓库
https://github.com/facebookresearch/nougat
对比下
- nougat比较好的地方在于可以把公式拆解成latex,很多模型底模会学习到latex的规则,会较之直接地希腊符号好些,另外就是识别出来的内容可以通过“#”符号来拆解文本段
缺陷就是效率很低、非常慢,拿共约80页的3篇pdf来解析的话,大概需要2分钟,且占用20G显存,到时候如果要应用化,要让用户传pdf解析的话,部署可能也会有点难度 - sciencebeam的话就是快不少,同样量级的3篇大约一分钟内都可以完成,和第一版用的SciPDF差不多,只需要cpu就可以驱动起来了
当然,还要考虑的是解析器格式化的粒度,比如正文拆成了什么样子的部分,后续我们需不需要对正文的特定部分专门取出来做处理,如果格式化粒度不好的话,可能会比较难取出来
// 待更
第二部分 第二版数据处理的优化:借鉴GPT4审稿的思路
2.1 斯坦福:让GPT4首次当论文的审稿人
近日,来自斯坦福大学等机构的研究者把数千篇来自Nature、ICLR等的顶会文章丢给了GPT-4,让它生成评审意见、修改建议,然后和人类审稿人给出的意见相比较
- 在GPT4给出的意见中,超50%和至少一名人类审稿人一致,并且超过82.4%的作者表示,GPT-4给出的意见相当有帮助
- 这个工作总结在这篇论文中《Can large language models provide useful feedback on research papers? A large-scale empirical analysis》,这是其对应的代码仓库
所以,怎样让LLM给你审稿呢?具体来说,如下图所示

- 爬取PDF语料
- 接着,解析PDF论文的标题、摘要、图形、表格标题、主要文本
- 然后告诉GPT-4,你需要遵循业内顶尖的期刊会议的审稿反馈形式,包括四个部分
成果是否重要、是否新颖(signifcance andnovelty)
论文被接受的理由(potential reasons for acceptance)
论文被拒的理由(potential reasons for rejection)
改进建议(suggestions for improvement) - 最终,GPT-4针对上图中的这篇论文一针见血地指出:虽然论文提及了模态差距现象,但并没有提出缩小差距的方法,也没有证明这样做的好处
2.2 为了让模型对review的学习更有迹可循:规划Review的格式很重要(需要做选取和清洗)
上一节介绍的斯坦福这个让GPT4挡审稿人的工作,对我司做论文审稿GPT还挺有启发的
- 正向看,说明我司这个方向是对的,至少GPT4的有效意见超过50%
- 反向看,说明即便强如GPT4,其API的效果还是有限:近一半意见没被采纳,证明我司做审稿微调的必要性、价值性所在
- 审稿语料的组织 也还挺关键的,好让模型学习起来有条条框框 有条理 分个 1 2 3 4 不混乱
比如要是我们爬取到的审稿语料 也能组织成如下这4块,我觉得 就很强了,模型学习起来 会很快
成果是否重要、是否新颖
论文被接受的理由
论文被拒的理由
改进建议
对于第三点,我们(特别是阿荀)创造性的想出来一个思路,即让通过提示模板让ChatGPT来帮忙梳理咱们爬的审稿语料,好把审稿语料 梳理出来上面所说的4个方面的常见review意见
那怎么设计这个提示模板呢?借鉴上节中斯坦福的工作,提示模板可以如下设计
// 待更
第三部分 mistral到llama longlora
【mistral】
mistral仓库
https://github.com/mistralai/mistral-src
mistral-7B中文资料
https://zhuanlan.zhihu.com/p/658911982
【longlora】
longlora仓库
https://github.com/dvlab-research/LongLoRA
longlora中文资料
https://zhuanlan.zhihu.com/p/659226557
// 待更
参考文献与推荐阅读
- GPT4当审稿人那篇论文的全文翻译:【斯坦福大学最新研究】使用大语言模型生成审稿意见
- GPT-4竟成Nature审稿人?斯坦福清华校友近5000篇论文实测,超50%结果和人类评审一致