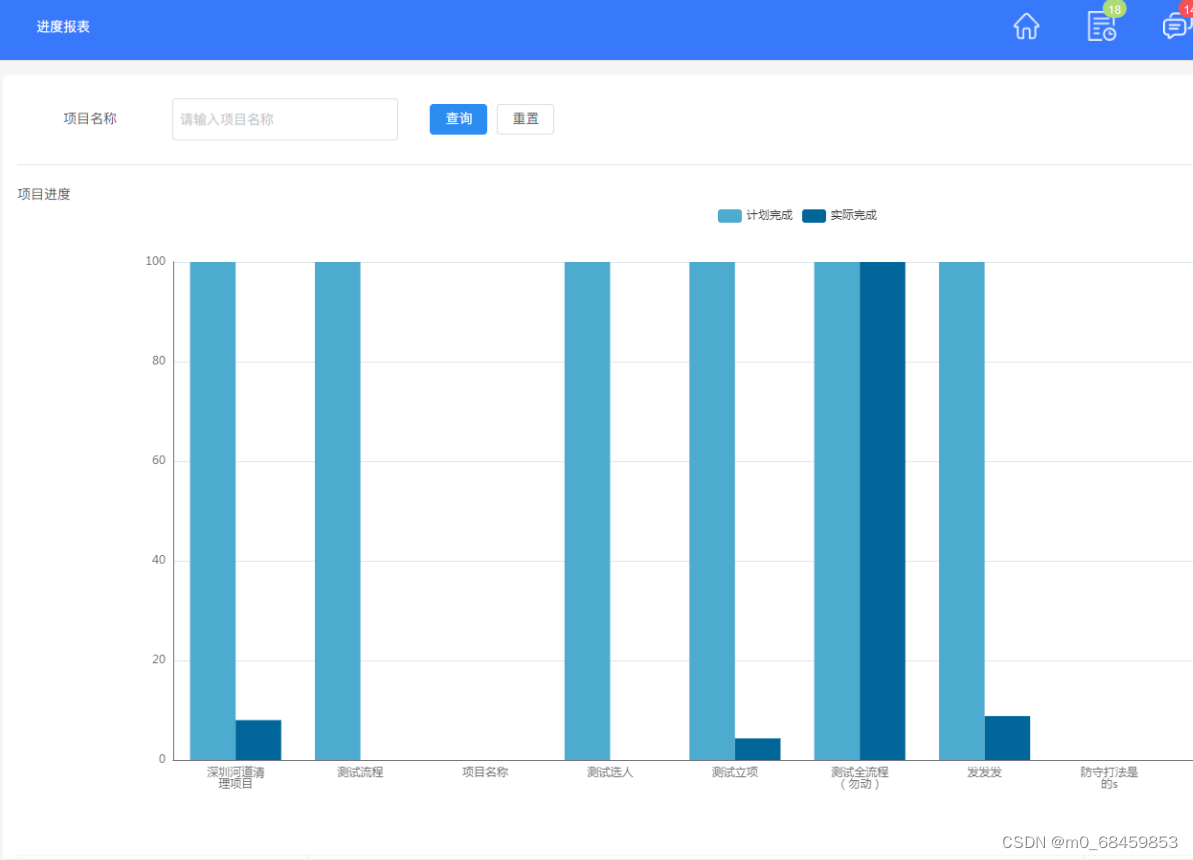
使用colly库的爬虫程序,该程序将使用Go语言爬取内容。
package main
import (
"fmt"
"log"
"github.com/gocolly/colly"
)
func main() {
// 创建一个Colly爬虫实例
c := colly.NewCrawler()
// 设置服务器
c.OnRequest(func(r *colly.Request) {
r.SetProxy()
r.SetHeader("User-Agent", "Mozilla/5.0")
})
// 添加要爬取的URL
c.OnRequest(func(r *colly.Request) {
r/topics = ""
})
// 定义回调函数,用于处理抓取到的网页数据
c.OnPage(func(p *colly.Page) {
// 打印网页标题
fmt.Println(p.Title())
// 打印网页URL
fmt.Println(p.Url())
})
// 开始爬取
c.Crawl()
}
以上代码使用了colly库来创建一个爬虫实例,User-Agent为Mozilla/5.0。然后添加了要爬取的URL,并定义了一个回调函数,用于处理抓取到的网页数据。