随着互联网的流行,网站安全问题就日益突出,但绝大多数的网站开发与建设公司只考虑正常用户的稳定使用,而对于网站安全方面了解甚少,发现网站安全存在问题和漏洞,其修补方式只能停留在页面代码的删除或者是恢复网站备份,很难针对网站具体的漏洞原理对源代码进行修复。但黑客对漏洞具有敏锐的洞察力,网站存在的这些漏洞就会被挖掘出来,成为黑客们直接或间接获取利益的机会。
不过,每一个网站的攻击都离不开网站文件的修改。随时监控网站文件的修改,当网站文件发生修改就进行安全问题的提醒,是这个项目的必要性。
首先,要解决的是如何监控一个网站的修改。
一、监控文件变化的相关信息。
一般服务器采用的都是linux系统,在linux系统中需要安装inotify-tools,这个第三方模块可以不杀死进程的基础上进行文件内容方面的监控。
安装成功后,可以使用命令inotifywait来监控文件内容的修改,inotifywait携带的参数如下。

结合于mqr参数,可以不杀死进程,持续监听文件内容是否发生变化,然后再通过timefmt进行发生时间的格式化,format格式化命令可以指定inotifywait按照指定的格式输出内容。
通过命令inotifywait -mqr --timefmt “%d/%m/%y %H:%M:%S” --format “%T %w %f %e” -e modify,delete,create,attrib /home/data”。

这里可以把timefmt中输入中文“年月日”。

从图中可以看出,当有文件发生修改,就会在控制台产生变化的信息,并且不杀死进程,一直在持续监听文件内容的变化。现在,带来的问题就是如何把这个持续不断的信息使用一种方式收集到某个存储区域,然后通过大数据技术手段进行分析,为了保证信息收集的持续性和不间断性,同时也要保证信息的不丢失。这里使用flume+kafka的大数据技术手段保证信息发送的实时性和准确性。
二、flume+kafka架构收集网站文件监控的内容变化
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理。flume的核心组件包括source、channel和sink。
Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。
flume的sink需要下沉到kafka队列,kafka是一个分布式的基于发布订阅模式的消息队列,主要用于大数据实时处理灵越。
kafka架构由producer、consumer group、broker组成,producer是消息的生产者,consumer是消息的消费者,broker是代理服务器,消息都存放在broker上。producer、consumer要想向kafka发送和消费数据需要先申请一个主题,都是面向主题进行操作,申请创建topic的时候需要指定分区的个数,副本的个数,kafka集群会采用轮询或者range分区的方式将分区分散到不同的broker上。
flume可以理解成一个点对点的模式,从消费者主动拉取数据。消息生产者将消息发送到queue中,然后消费者从queue中取出并消费消息,消息被消费者消费以后,queue中不在存储消息,所以消息消费者不可能重复消费已经被消费过的消息。这个queue就相当于flume的缓存channel。点对点模式可以理解成同步处理模式,类似于填写注册信息,写入数据库,然后调用短信发送接口,进行发送短信的实现。如下图所示的同步模式。

kakfa相当于异步处理模式,相当于填实注册信息,写入数据库,把发送短信的任务写入队列中,在队列中异步处理发送短信的任务。如下图所示。

项目的架构采用flume收集网站攻击的代码修改,当有网站编码上的修改,就会把变化信息收集到flume的source中接收,然后sink到kakfa中进行存储。如下图所示。

从图中看,flume的source接收数据,然后以事件为单位进行处理,通过处理事件,把事件传给拦截器,如果有需要拦截的内容,就需要实现拦截器,并且每个事件都会发给channel选择器,将返回的结果写入事件channel列表,根据channel选择器的选择结果,将事件写入相应的channel,这个channel相当于缓存机制,接上来通过SinkProcessor下沉处理器处理结果,这里通过下沉处理器SinkPrcessor下沉到kafka中进行存储。
搭建flume+kakfa需要zookeeper包,这里使用zookeeper的版本是3.3.3,flume的版本是1.8.0,kafka的版本是2.12,这里需要注意kafka和flume的版本问题,flume的版本1.9需要jdk就会高,当使用的jdk版本大于9时,kafka可以会出现Unrecognized VM option 'PrintGCDateStamps'导致Kafka无法启动,
这里把flume的版本调整为1.8。
启动虚拟机centos之后,在usr目录下新建flume,kafka和zookeeper目录。如下图所示。

通过vftp软件把zookeeper、 flume和kafka软件上传到linux服务器中,如下图所示。

上传软件后,把上传到/home/soft中的软件解压到usr目录下相应的目录中,这里可以解压zookeeper解压包,命令如下 。

继续解压flume压缩包,解压命令如下。

最后将kafka压缩包解压,解压命令如下。

这里首先进入zookeeper的config目录下,设置config的文件zoo.cfg,但是在config目录下,没有zoo.cfg文件,原来只有zoosample.cfg,需要把zoosample.cfg复制成zoo.cfg,拷贝命令如下。

文件拷贝成功后,通过vi指令进行编辑zoo.cfg的配置文件。

在zoo.cfg的文件末尾加上一句服务器的指示语句,这里只有一个zookeeper服务器,所以只配置一台服务器的配置Ip即可,配置代码如下。

这里配置的ip是192.168,214.128,配置的端口号是3666。完成配置后,可以在zookeeper的bin目录下,执行zkServer.sh文件,后面带上一个参数start来启动zookeeper服务器,如下图所示。

zookeeper启动后,配置kafka,首先进入到usr目录下的kafka目录,然后在kafka的目标目录下的config目录中有配置文件server.properties。这里需要通过vi编辑server.properties文件,如下图所示。
在文件的末尾处找到zookeeper的连接配置,后面配置上zookeeper的连接ip地址和默认端口号2181。配置如下。

这里配置的zookeeper地址是192.168.214,128,具体内容根据虚拟机的具体IP决定,2181是zookeeper的默认地址。
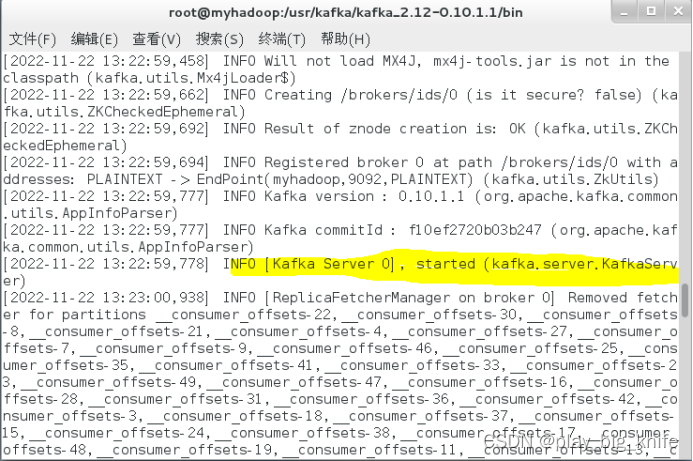
配置结束后,需要启动kafka服务,通过kafka目录中bin目录下的kafka-server-start.sh文件,后面需要跟上server.properties的路径文件。

启动后,当看到“kafka started”信息后,表示kafka服务已成功启动。 如下图。
kafka服务启动后,不会退出进程,这里需要在虚拟机中再启动一个终端,继续启动kafka消费者,当flume的source源接收到网站被改变的数据后,就会在消费者终端中输出,启动消费者终端需要用到kafka的bin目录中的kafka-console-consumer.sh文件。启动指令时文件后面需要指定zookeeper的地址以及当前需要消费的topic,为了保证这个topic的存在,需要kafka先创建一个topic主题,然后再启动kakfa消费者。创建kafka的topic指令如下。
./kafka-topics.sh --create --zookeeper 192.168.110.140:2181 --topic myhello --partitions 1 --replication-factor 1
这里使用kafka目录中bin目录中的kafka-topic.sh文件,后面跟上zookeeper的地址,并且指明--topic主题名,当前指明的是myhello主题,还需要指明partitions的分区及replication-factor的复制份数。这里由于是1台服务器,分区数和备份数都为1。
把kafka的topic创建结束后,需要启动kafka消费者。命令如下图。

这里消费的主题--topic指明的是前面建立的主题myhello。启动后,消费者不会退出进程,需要再次另外启动一个终端。
kafka中消费者由于是flume下沉过来的,因此这里需要设置flume,进入到flume的配置目录,设置flume的配置文件,这个文件名需要自己去命名,如下图所示。

flume的配置文件有3个说明,说明source、 channel和sink,这里的source需要监控网站文件被攻击的记录,这个记录一般放在文件中,linux显示问题文件的记录可以使用tail来显示出来。channel默认可以使用Momery内存做为缓存方式,最后sink需要一个固定的kafka配置,配置kafka的类文件,然后指明kafka的消费主题及相关配置。

从图中可以看出,当前flume设置的source名称为r1,channel名称为c1,sinks的名称为k1。 r1的类型是exec类型,这个类型可以执行tail指令来查看网站攻击的日志文件web.log。接下来设置c1的type类型为momery,其大小设置为1000。再设置了k1的下沉类型,指出其type类型为KafkaSink,bootstrap的地址指定为192.168.214.128,bootstrap服务器的端口号默认为9092,topic指示主题为myhello。最后指示r1的channels为c1,这里可以有多个缓冲channel,所以是复数,指示下沉k1的channel为c1,注意这里的 channel为单数形式。
编辑完这个配置文件后,通过flume目录下bin目录中的flume-ng去启动一个agent。指令如下。

注意,指令中指定的--name是a1,这个a1与配置文件中指定的flume的agent名称一致。后面的-f参数,指定conf文件的位置和名称,-D参数指定输出信息的等级和输出位置在控制台上。
启动成功后,这个进程也不会被杀死,如下图所示。
在启动信息中,可以看到k1 started,表示从r1到k1都已经启动了。
这里的进程不会被杀死,需要另起一个终端,继续执行网站的监控并输出到文件中。
inotifywait -mqr --timefmt “%d/%m/%y %H:%M:%S” --format “%T %w %f %e” -e modify,delete,create,attrib /home/data”-o /home/mykafka/web.log /home/web
注意,命令中的输出日志必须与flume中tail后指示的日志名称是一致的。
命令中监控的网站是home目录下的web目录。
web目录可以有若干web文件,也可以进行嵌套,这里的web目录下有3个web文件,a.html,b.html与c.html,其具体内容如下。

现在,另外开启一个终端,对/home中的web目录进行修改,修改内容如下。

这时,相当于网站内容受到攻击,inofitywait会接收到修改的内容并通过flume下沉到kafka的消费者中,最终, kakfa消费者的输出结果如下。
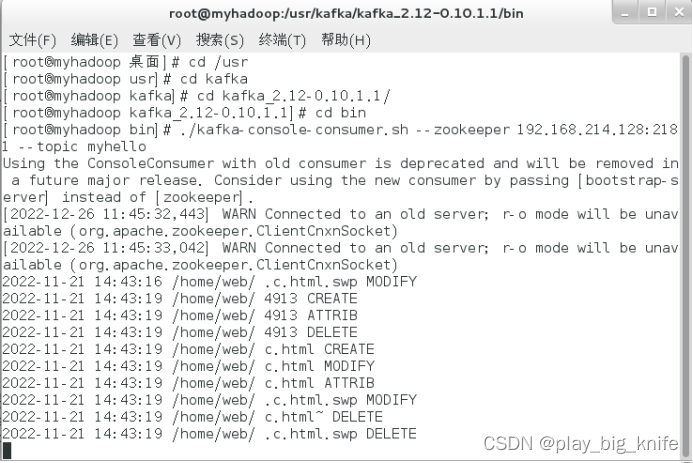
这样,网站攻击的数据就会实时地存储到了kafka中,随时关注博客,后期更新会说明后续如何分析kakfa中的消费信息。
哔哩哔哩官网视频地址:
https://www.bilibili.com/video/BV1sd4y1t7iG/