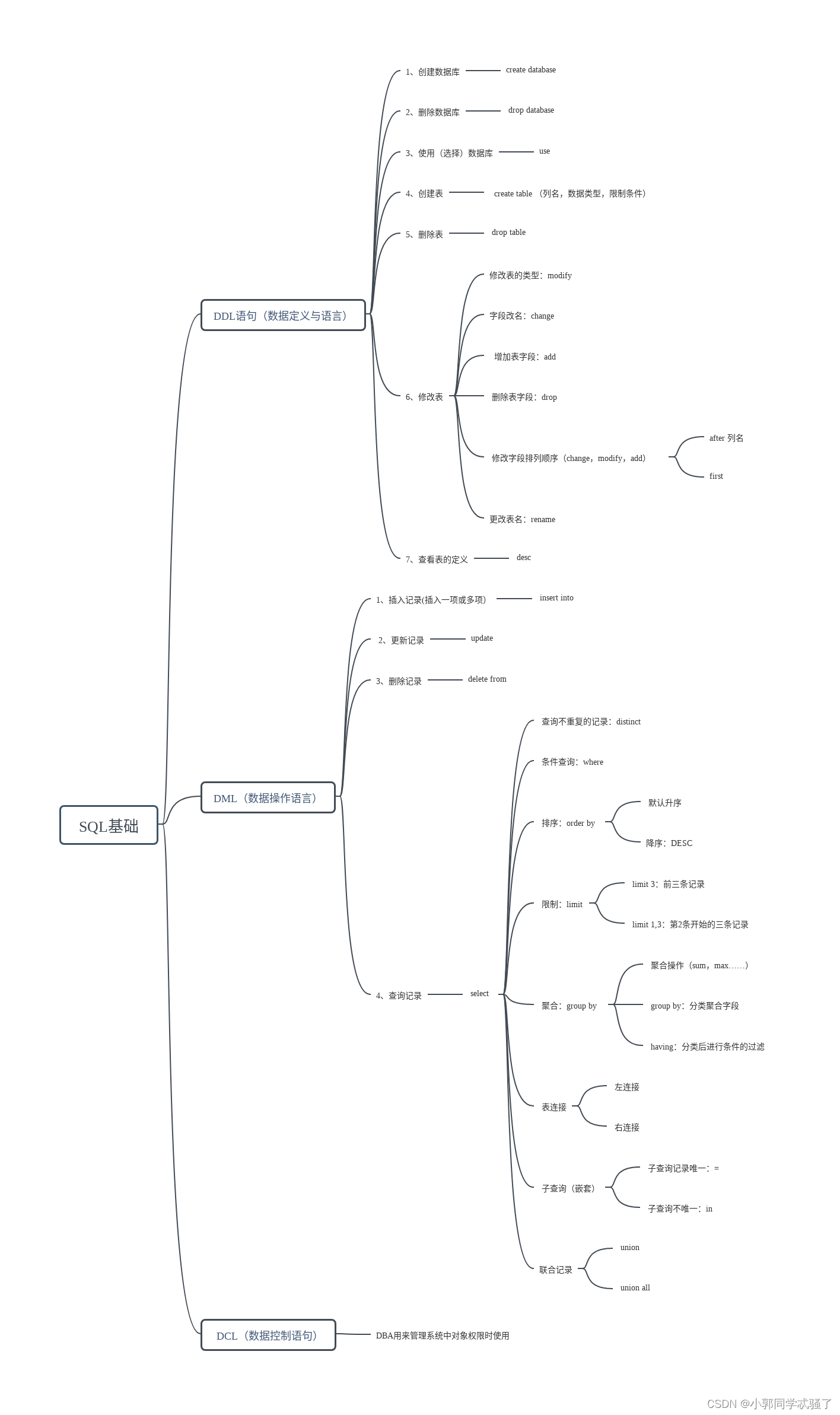
数组
- 前言
- 一、一维数组的创建和初始化
- (一)数组的创建
- 1.数组的概念和创建方式
- 2.变长数组
- (二)数组的初始化
- (三)一维数组的使用
- (四)一维数组在内存中的存储
- 二、二维数组的创建和初始化
- (一)二维数组的创建
- (二)二维数组的初始化
- (三)二维数组的使用
- (四)二维数组在内存中的存储
- 1.存储方式
- 2.小知识
- 三、数组越界
- (一)概念
- (二)拓展知识
- 1.题目描述:
- 2.解释
- (1)代码
- (2)简单解析
- (3)完整解析
- 四、数组作为函数参数
- (一)传参
- (二)数组名
- 五、数组实例
- (一)三子棋
- (二)扫雷
- 总结
前言
数组在C语言中是很重要的,大家需要有前面函数知识的基础才能学好数组,数组分为一维数组、二维数组,在C语言中存储是十分重要的,所以大家需要仔细看看下面的内容,牢牢掌握数组。
一、一维数组的创建和初始化
(一)数组的创建
1.数组的概念和创建方式
概念:数组是一组相同类型元素的集合。

2.变长数组

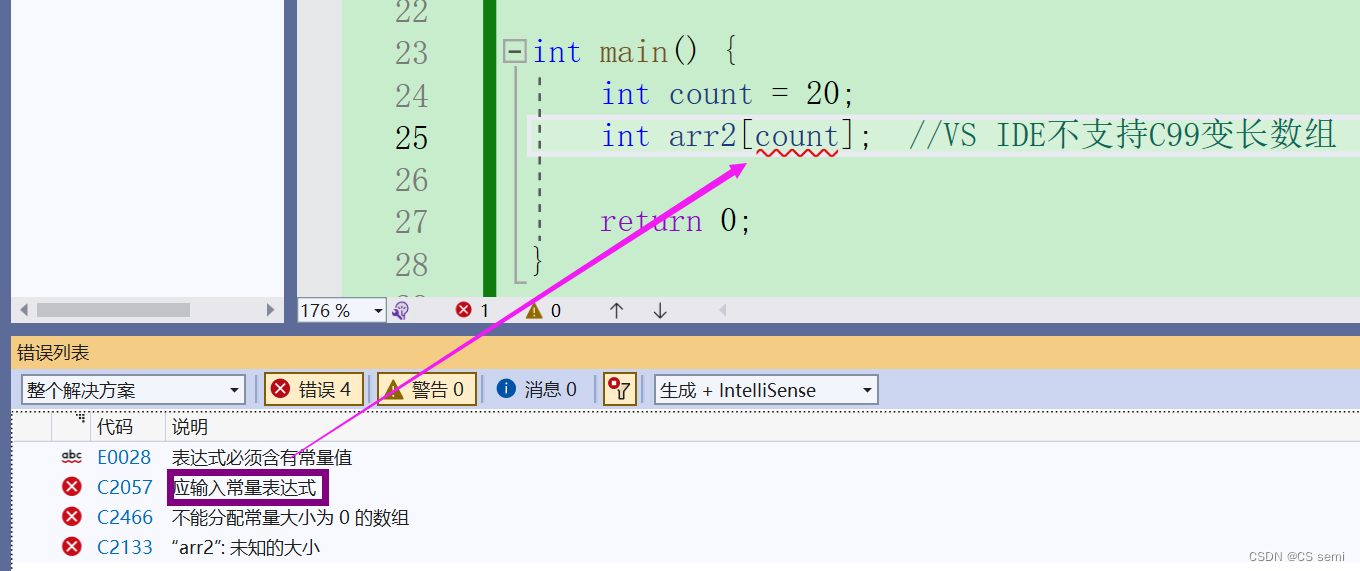
解释:数组创建,在C99标准之前,[]中要给一个常量才可以运行,不能使用变量。在C99标准支持了变长数组的概念,数组的大小可以使用变量指定,但是数组不能初始化(在Linux编译器底下是不能被初始化的,而可以使用变长数组)。而VS IDE不支持C99变长数组,所以报错。
(二)数组的初始化
#include<stdio.h>
int main() {
//创建的同时给数组一些值,这叫做初始化
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };//完全初始化
int arr2[10] = { 1,2,3 }; //不完全初始化,剩余的元素默认初始化为0
int arr3[] = { 1,2,3,4,5 }; //没有指定数组元素个数,编译器会根据初始化的内容来确定数组的元素个数
int arr4[] = { 1,2,3 }; //3个元素
int arr5[10] = { 1,2,3 }; //10个元素
char arr6[3] = { 'a','b','c' };
char arr7[] = { 'a','b','c' };
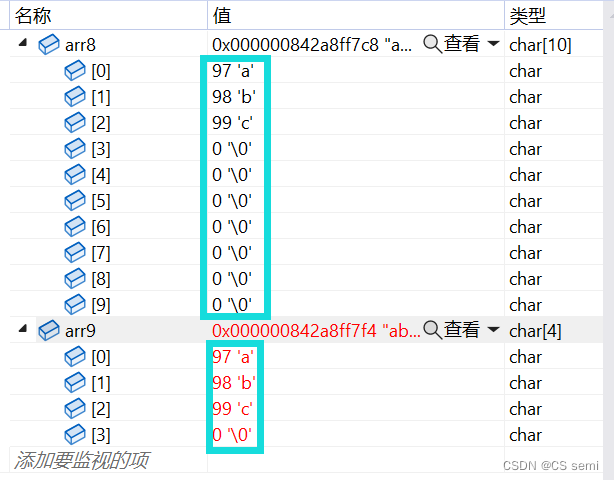
char arr8[10] = "abc"; //'a' 'b' 'c' '\0' 10个元素
char arr9[] = "abc"; //'a' 'b' 'c' '\0' 4个元素
char arr10[] = "abcd"; //5个元素 'a' 'b' 'c' 'd' '\0'
char arr11[] = { 'a','b','c','d' }; //4个元素 'a' 'b' 'c' 'd'
printf("%s\n", arr10);
printf("%s\n", arr11);
int arr12[10]; //不初始化默认放的都是0
return 0;
}
如下图,完全初始化和不完全初始化数组的对比:

如下图,不给元素个数而初始化自动填充元素个数,arr3:

如下图,arr4和arr5初始化的值相同而元素个数的不同:

如下图,arr6和arr7是一样的:

如下图,arr88和arr9初始化的值相同而元素个数的不同:
如下图,arr10与arr11的区别至关重要,这是由于指针从a这个元素往后找一直找到\0才肯罢休,arr10数组后面默认有个\0,这是编译器默认的规矩,所以那个指针找到\0了,统计有五个元素就完了,可是arr11这个数组后面没有\0,编译器找不到啊,那咋办,输出一堆随机值,那这些随机值是什么呢?在函数栈帧的创建于销毁中我们已经看到过了,就是cc cc cc cc这个乱码。
函数栈帧的创建与销毁
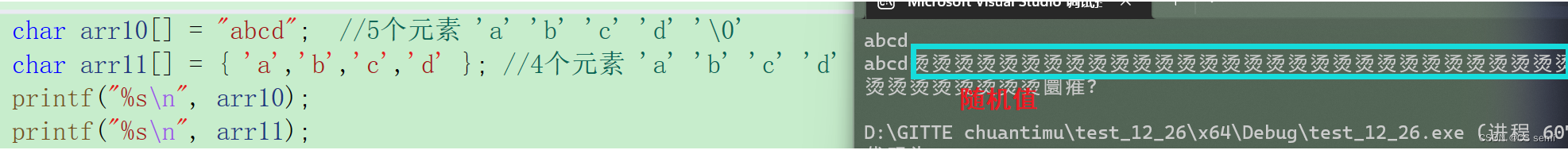
(三)一维数组的使用
对于数组的使用我们之前介绍了一个操作符:[],下标引用操作符。它其实就是数组访问的操作符,如下代码:
//1.数组是有下标的,下标是从0开始的
//2.[]下标访问操作符
//3.数组的大小可以通过计算得到
int main() {
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//按照顺序打印数组
int sz = sizeof(arr) / sizeof(arr[0]); //算总字节长度除以第一个字节的长度就是数组的元素个数
int i = 0;
//正序打印
for (i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
printf("\n");
//倒序打印
for (i = sz - 1; i >= 0; i--) {
printf("%d ", arr[i]);
}
printf("\n");
//奇数打印
for (i = 0; i < sz - 1; i += 2) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
(四)一维数组在内存中的存储
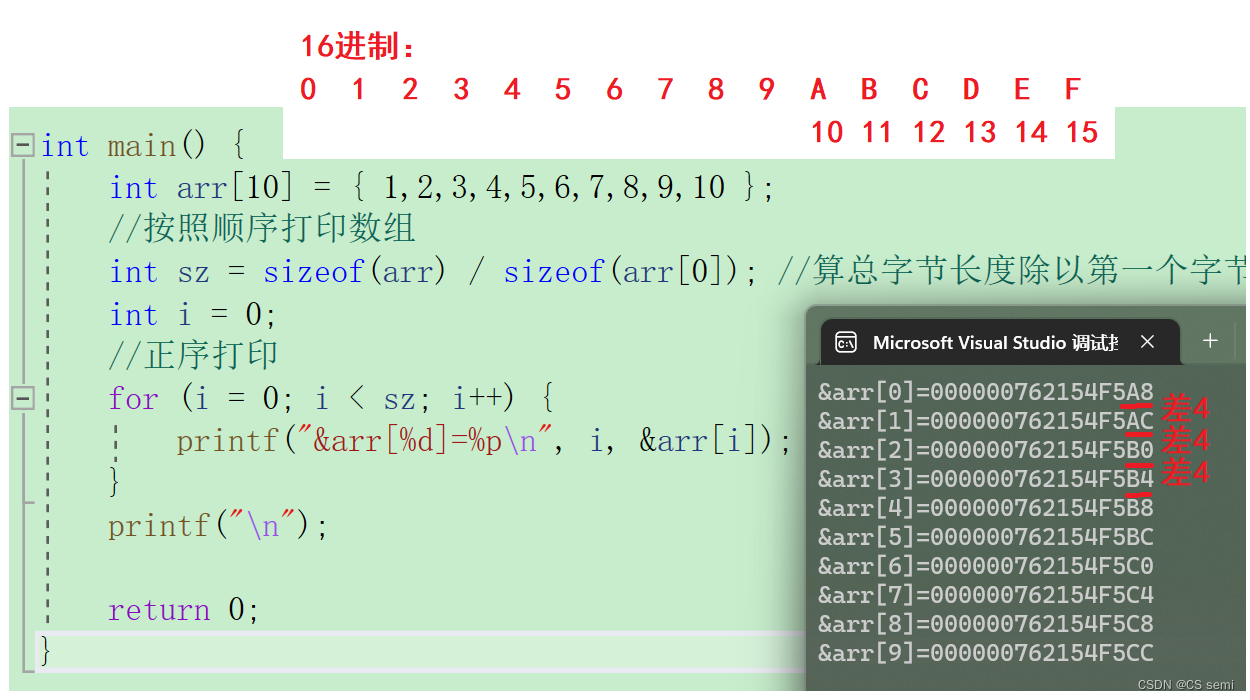
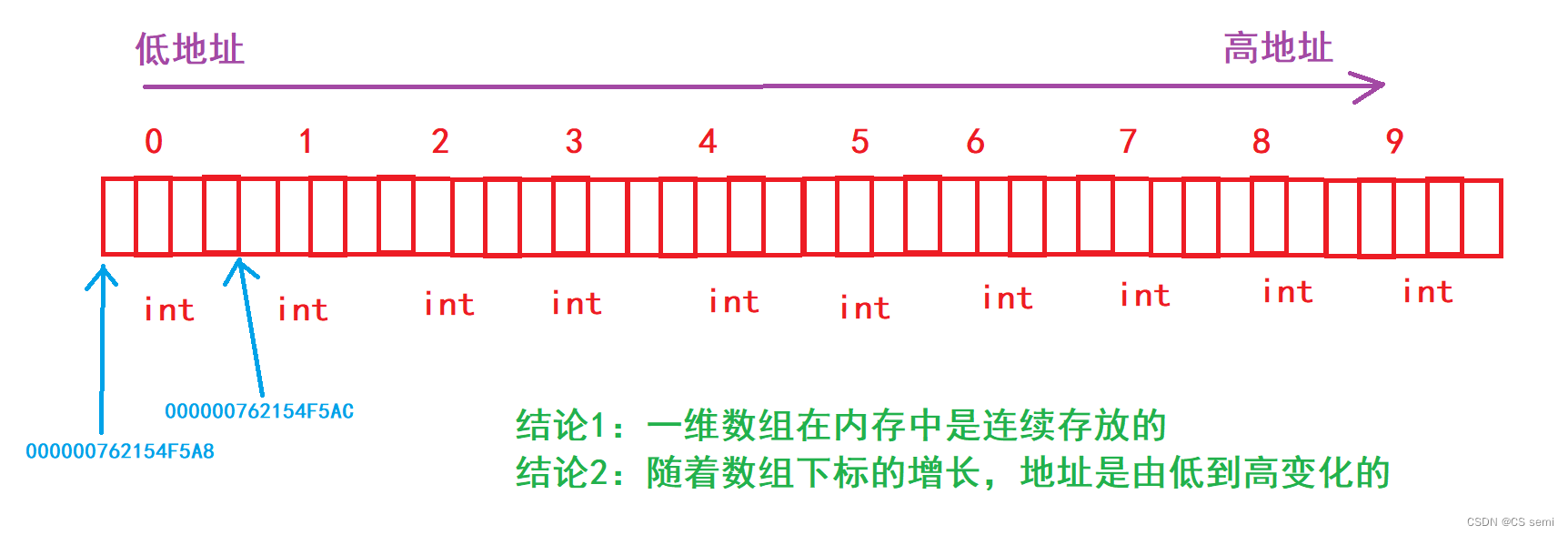
大家看到这个地址是每一个都差4的,不由想到int占4个字节,由此推出两个结论:
结论1:一维数组在内存中是连续存放的
结论2:随着数组下标的增长,地址是由低到高变化的
所以是不是只需要你知道第一个元素的地址,就可以找到之后的所有地址并找到它的值了,这是不是和指针有一定的联系,可以用指针指向第一块的空间并往后查找并打印,上代码试一试:
#include<stdio.h>
int main() {
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//按照顺序打印数组
int sz = sizeof(arr) / sizeof(arr[0]); //算总字节长度除以第一个字节的长度就是数组的元素个数
int i = 0;
/*for (i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}*/
正序打印
//for (i = 0; i < sz; i++) {
// printf("&arr[%d]=%p\n", i, &arr[i]);
//}
//printf("\n");
int* p = &arr[0];
for (i = 0; i < sz; i++) {
printf("%d ", *(p + i));
}
return 0;
}
二、二维数组的创建和初始化
(一)二维数组的创建
与一维数组大致相同,如下图:

(二)二维数组的初始化
先上代码再分析:
#include<stdio.h>
int main() {
int arr[3][4] = { 1,2,3,4,5,6,7,8,9,10,11,12 }; //表示三行四列
int arr1[3][4] = { 1,2,3,4,5 }; //不完全初始化,后面未初始化默认赋0
int arr2[3][4] = { {1,2},{3,4},{5,6} }; //按照自己心意给不同地方赋值
//二维数组的行可以省略,但是列不可以省略
int arr3[][4] = { 1,2,3,4,5,6,7,8,9 };
return 0;
}

这里有个小知识点:
二维数组的行是可以省略的,但是列是千万不能省略的,为什么呢?因为当二维数组是先是横着一个个往后放,到末尾了,列告诉你,到头了,不要再放了,然后就换了个行,继续放,所以列是关键,列告诉你可以放或者放到底了不能再放了,所以行可以省略而列不能省略。
(三)二维数组的使用
只需锁定它的行和列找到并打印出即可:


(四)二维数组在内存中的存储
1.存储方式
二维数组在内存中是连续存放的,我们只需要将一个二维数组转换成n个一维数组即可。

为了更好的理解二维数组是连续存放的,接下来上个指针的代码,指针是加1跳过4个字节(在int 类型当中),供大家思考一下:
#include<stdio.h>
int main() {
int arr[3][4] = { 1,2,3,4,5,6,7,8,9,10,11,12 };
int i = 0;
for (i = 0; i < 3; i++) {
int j = 0;
for (j = 0; j < 4; j++) {
printf("%d ", arr[i][j]);
}
}
printf("\n");
int* p = &arr[0][0];
int k = 0;
for (k = 0; k < 12; k++) {
printf("%d ", *(p + k));
}
return 0;
}
打印结果:

2.小知识
其实二维数组是一维数组的数组,是存放n个一维数组的数组。

利用sizeof关键字就能推断出来二维数组的大小(总共有多少个元素):
int row = sizeof(arr) / sizeof(arr[0]); //算行有多少
int col = sizeof(arr[0]) / sizeof(arr[0][0]); //算列有多少
int sum = row * col; //算总共多少个元素

三、数组越界
(一)概念
数组的下标是有范围限制的。
数组的下标是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。所以数组的下标如果小于1,或者大于n-1,就是数组的越界访问了,超出了合法空间的访问。而C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就是正确的,所以我们在进行编译的时候,要检查一下有没有越界。

(二)拓展知识
在大厂面试的时候,有道题目看起来很简单,但是解释起来很复杂,其实不需要那么难的解释,接下来,让我细细来讲一下:
1.题目描述:

2.解释
(1)代码
代码如下:
#include<stdio.h>
int main() {
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int i = 0;
for (i = 0; i <= 12; i++) {
printf("Hello World\n");
arr[i] = 0;
}
return 0;
}
(2)简单解析
在新版2022的VS IDE下运行结果是没问题,调试的过程中也不会像老版2013VS IDE一样会死循环i在运行到12的时候i的值会变成0重新进入循环,此时取地址i与取地址arr[12]是一样的,而新版VS IDE只会出现异常提醒,i的值不会从12变成0。
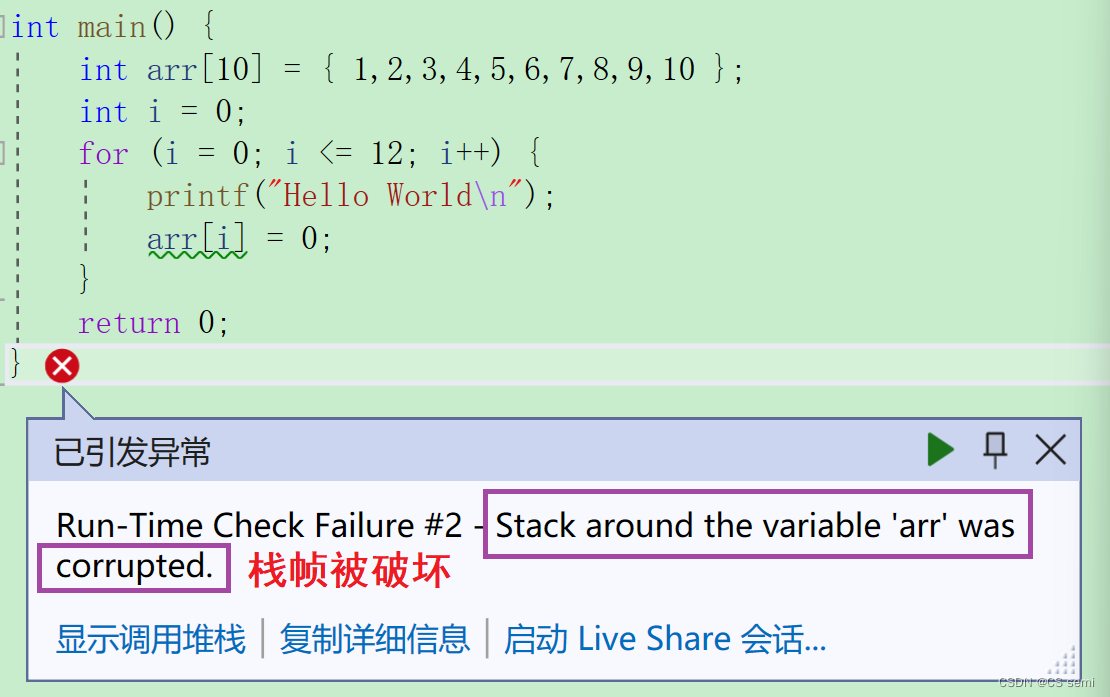
局部变量是放在内存中的栈区的,栈区的使用习惯是先使用高地址处的空间,再使用低地址处的空间。


(3)完整解析
在老版2013的VS IDE中如果越界超过2个元素,那么&i与&arr[12]两者地址是一样的,所以当循环到12时,i自动变为0,从头开始循环了,而最新版的VS IDE中解决了这个问题,只是报出警告。
同样,这个小问题在其他编译器上也会出现,但是看溢出的元素的个数而定的,就比如Linux编译器上是不能溢出的,是只要你有一个元素溢出都会产生死循环。

四、数组作为函数参数
(一)传参
先来一个冒泡排序,进行理解一下:

//选择排序,冒泡排序,插入排序
//冒泡排序思想
//两两相邻元素进行比较
#include<stdio.h>
//Void Sort(int* arr, int sz) //本质
void Sort(int arr[], int sz) {
//int n = sizeof(arr)/sizeof(arr[0]); //n的值为1
int i = 0;
//趟数
for (i = 0; i < sz - 1; i++) {
//一趟冒泡排序,决定了进行多少对比较
int j = 0;
for (j = 0; j < sz - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main() {
int arr[] = { 3,1,4,2,9,8,6,7,0,5 };
int sz = sizeof(arr) / sizeof(arr[0]);//sz的值为10
//写一个函数对数组进行排序
Sort(arr, sz);
//打印
int i = 0;
for (i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
return 0;
}
(二)数组名
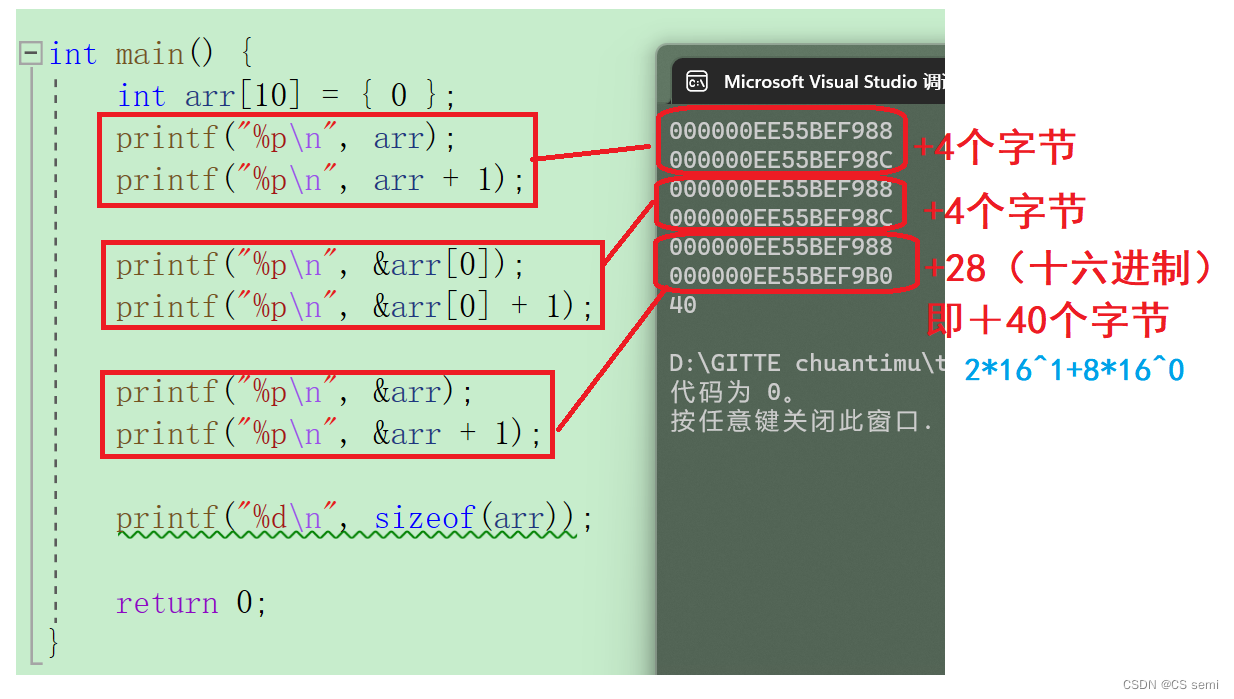
大家需要先知道的是数组名是一个地址,但到底是谁的地址呢?数组名是首元素的地址。
但是有两个例外:
1.sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节。
2.&数组名,这里的数组名表示整个数组,&数组名取出的是数组的地址。但是取地址和首元素取地址是一样的。而往后+1就差别巨大,&arr+1是跳过整个数组,&arr+1是跳过一个int型的字节。
&arr地址输出的是首元素地址,arr地址输出的是首元素地址,&arr[0]地址输出的是首元素地址,而进行加1,往后找元素的时候大不相同,&arr是取的一整个数组,加1是代表整个数组跳过了,而&arr[0]与arr取的是数组的首元素,往后加一是跳过一个元素,也就是int类型的四个字节。
所以大家可以想到为什么前面所讲的冒泡排序中的n为1,而不是我们想要的数组元素,因为在X86(32位)机器下,int* 是占4个字节的,而底下Sort把arr传参传的是指针,是arr数组的首元素的地址,所以在Sort函数内部的n是1。
指针的字节长度是取决于编译器是几位的,具体可以看一下下面的博客:【C函数】初识函数

当进行传参的时候,只把数组首元素地址传参上去,上面的数组知道了这个首元素地址以后可以往后找原数组中的其他元素,这对于节省空间和时间层面都是十分重要的。
五、数组实例
(一)三子棋
三子棋的创建,让大家能够很轻松就了解数组之间的关系,如下博客:
三子棋
(二)扫雷
了解了扫雷,对于数组的理解会有质的飞跃,大家可以看下面博客:
初阶扫雷
总结
这篇分享,我们学习到了关于数组的知识,知道了数组的底层逻辑,学习到了很多不一样的小知识,这在以后的学习当中是受益匪浅的,在学习数组的过程中我们详细知道了一维数组和二维数组的知识,也同样经过一个大厂面试题使大家了解到了数组越界的危险,最重要的是大家了解到了数组作为函数进行传参,这个是十分关键的,对于后续指针的学习是很有利的,以及对于理解内存是很关键的。
客官,码字不易,来个三连支持一下吧~~~