文章目录
- 生产经验之Consumer事务
- 生产经验—数据积压(消费者如何提高吞吐量)

生产经验之Consumer事务
Kafka引入了消费者事务(Consumer Transactions)来确保在消息处理期间维护端到端的数据一致性。这使得消费者能够以事务的方式处理消息,包括从Kafka中读取消息、处理消息和提交消息的offset。以下是有关Kafka消费者事务的详细信息:
-
事务的引入:Kafka 0.11.0版本引入了消费者事务的功能。之前,Kafka的消费者通常使用手动提交offset的方式,但这种方式可能导致消息被重复消费或漏消费,特别是在处理消息和提交offset之间发生错误的情况下。
-
Consumer Transactions的目的:消费者事务的主要目的是确保消息被精确一次性地处理。这对于需要强一致性的应用程序非常重要,例如金融或电子商务领域。
-
核心概念:Kafka消费者事务依赖于以下核心概念:
- 事务ID:每个事务都有一个唯一的ID,用于跟踪和标识事务。
- 事务生命周期:一个事务有三个主要阶段:开始事务、处理消息、提交事务。
- 事务性消费:消费者在处理消息时将其包装在一个事务中,然后可以选择性地提交事务,以决定是否将offset提交到Kafka。
-
使用消费者事务:要使用消费者事务,消费者需要执行以下步骤:
- 开始事务:使用
beginTransaction()方法开始一个新的事务。 - 处理消息:在事务内处理Kafka中的消息。
- 提交或中止事务:使用
commitTransaction()提交事务或使用abortTransaction()中止事务。如果事务被提交,那么offset也会被提交;如果事务被中止,offset不会被提交。
- 开始事务:使用
-
事务保证:Kafka消费者事务提供了以下保证:
- Exactly-Once Semantics:确保消息在事务内被处理一次,从而避免了重复消费和漏消费。
- 事务性处理:事务内的消息处理要么全部成功,要么全部失败,从而保持数据的一致性。
-
事务的限制:消费者事务也有一些限制,包括:
- 消费者必须使用新的Kafka协议版本(0.11.0.0及以上)。
- 事务涉及到资源的分配,可能会引入一些开销,因此需要根据具体的用例来评估是否使用。
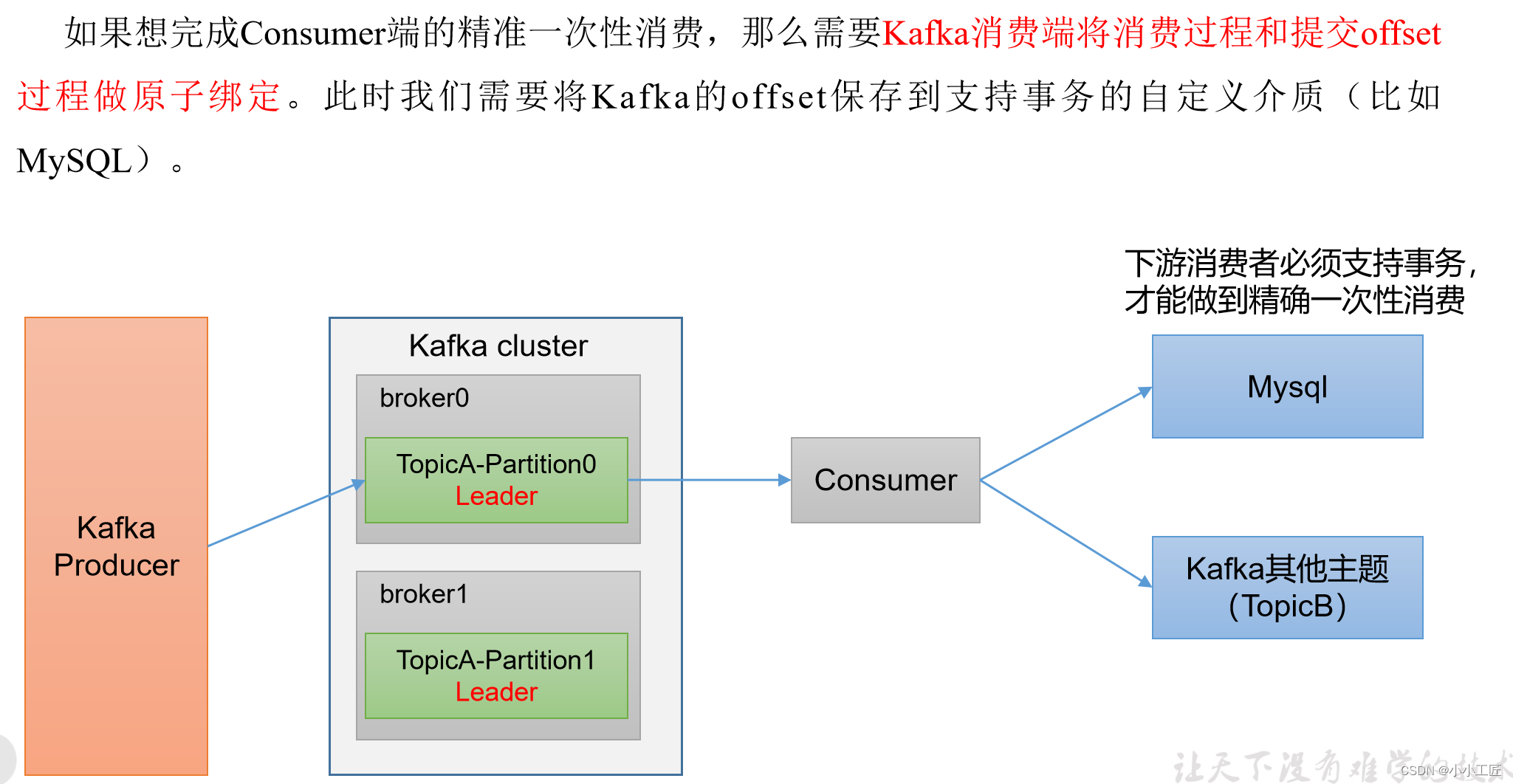
总的来说,Kafka消费者事务提供了可靠的消息处理机制,可以确保消息被精确一次性地处理。这对于需要强一致性的应用程序非常有价值,但也需要在使用时谨慎考虑性能开销和兼容性问题。
生产经验—数据积压(消费者如何提高吞吐量)
提高Kafka消费者的吞吐量是许多应用程序的关键优化目标,特别是在需要处理大量数据的情况下。以下是一些方法,可以帮助你提高Kafka消费者的吞吐量:
-
并行处理:使用多个消费者实例并行处理消息。每个消费者实例可以运行在不同的线程或进程中,从不同的分区中读取消息。这可以有效地利用多核CPU和多台机器的资源。
-
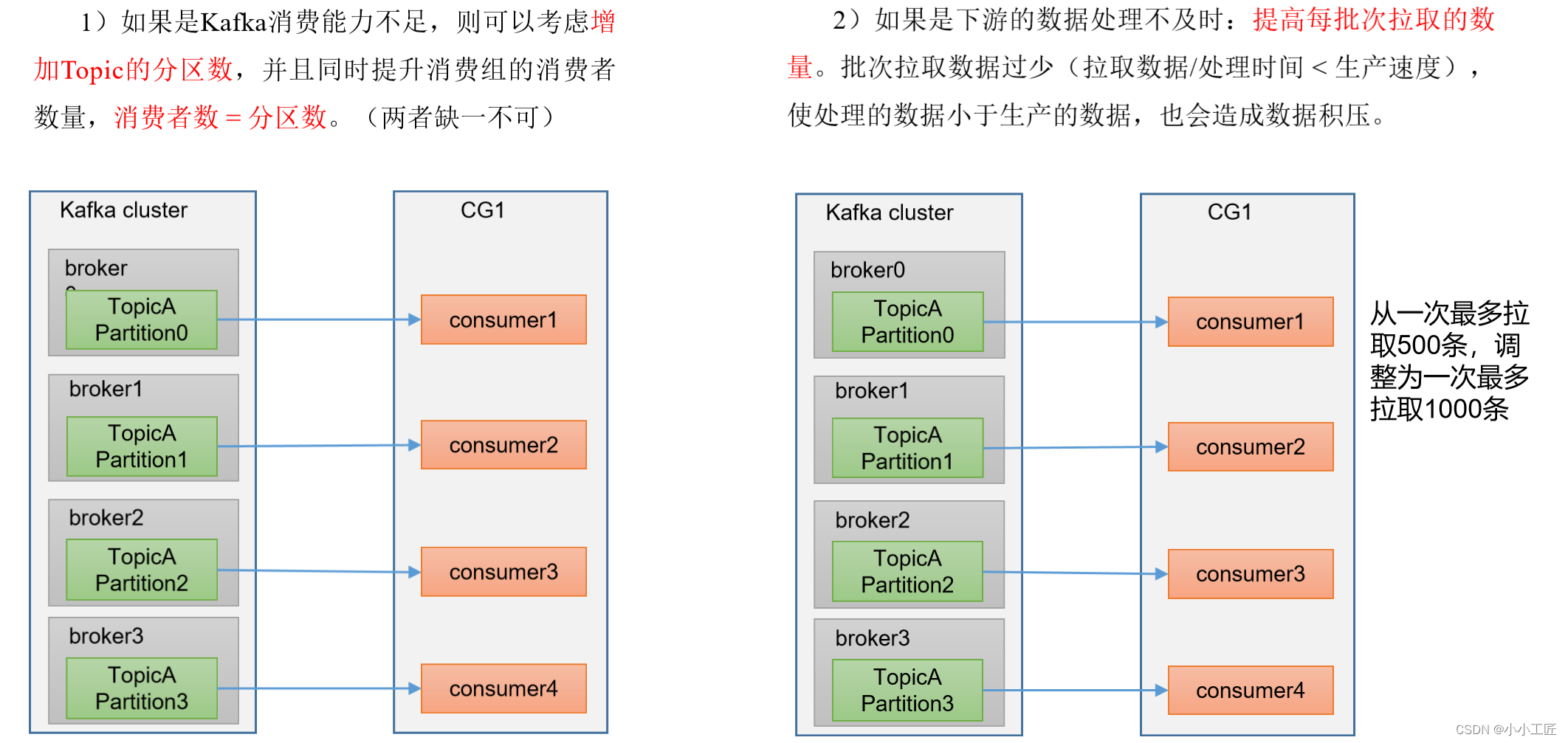
增加分区数:如果Kafka Topic的吞吐量不足,可以考虑增加分区数。更多的分区可以提高并行性,允许更多的消费者同时处理消息。
-
适当调整消费者参数:调整消费者的参数以提高性能。例如,增加
max.poll.records以一次获取更多的消息,或者适当增加fetch.max.bytes以增加每次获取的数据量。 -
使用高性能消费者:一些Kafka客户端库提供了高性能的消费者实现,如Apache Kafka的Java客户端,它具有较低的延迟和更高的吞吐量。选择适当的消费者库对性能至关重要。
-
优化消息处理逻辑:消息处理逻辑应尽量简化和优化,以降低处理每条消息的时间。使用多线程或异步处理可以提高效率,但要注意线程安全和异常处理。
-
合理设置批量处理:在消息处理中,可以考虑批量处理消息,而不是逐条处理。这可以减少网络开销和提高处理效率。
-
使用合适的分区分配策略:选择适当的分区分配策略,以确保分区分配在不同的消费者之间均匀分布,以充分利用多个消费者实例的并行性。
-
使用消息压缩:在网络带宽受限的情况下,启用消息压缩可以减少数据传输的开销,提高吞吐量。
-
使用本地缓存:为消息处理逻辑引入本地缓存,以减少对外部资源(例如数据库)的访问次数。这可以减少延迟并提高吞吐量。
-
合理设置并监控资源:确保消费者实例拥有足够的CPU、内存和网络资源,并监控这些资源的使用情况,以及时发现和解决性能瓶颈。
-
分布式消费者组管理:如果你的应用需要高可用性和横向扩展,可以考虑使用分布式消费者组管理工具,如Apache Kafka Streams或其他流处理框架。
| 参数名称 | 描述 |
|---|---|
| fetch.max.bytes | 消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50MB),仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受message.max.bytes(broker配置)或max.message.bytes(主题配置)的影响。 |
| max.poll.records | 一次poll拉取数据返回消息的最大条数,默认是500条。 |
最终,提高Kafka消费者的吞吐量需要综合考虑多个因素,包括硬件资源、消费者配置、消息处理逻辑等。通过结合上述方法,你可以有效地提高消费者的性能和吞吐量。