文章目录
- 1. 简介
- 2. 多头注意力
- 3. 有掩码的多头注意力
- 4. 基于位置的前馈网络
- 5. 层归一化
- 6. 信息传递
- 7. 预测
1. 简介
- 基于编码器-解码器架构来处理序列对
- 跟使用注意力的seq2seq不同,Transformer是纯基于注意力

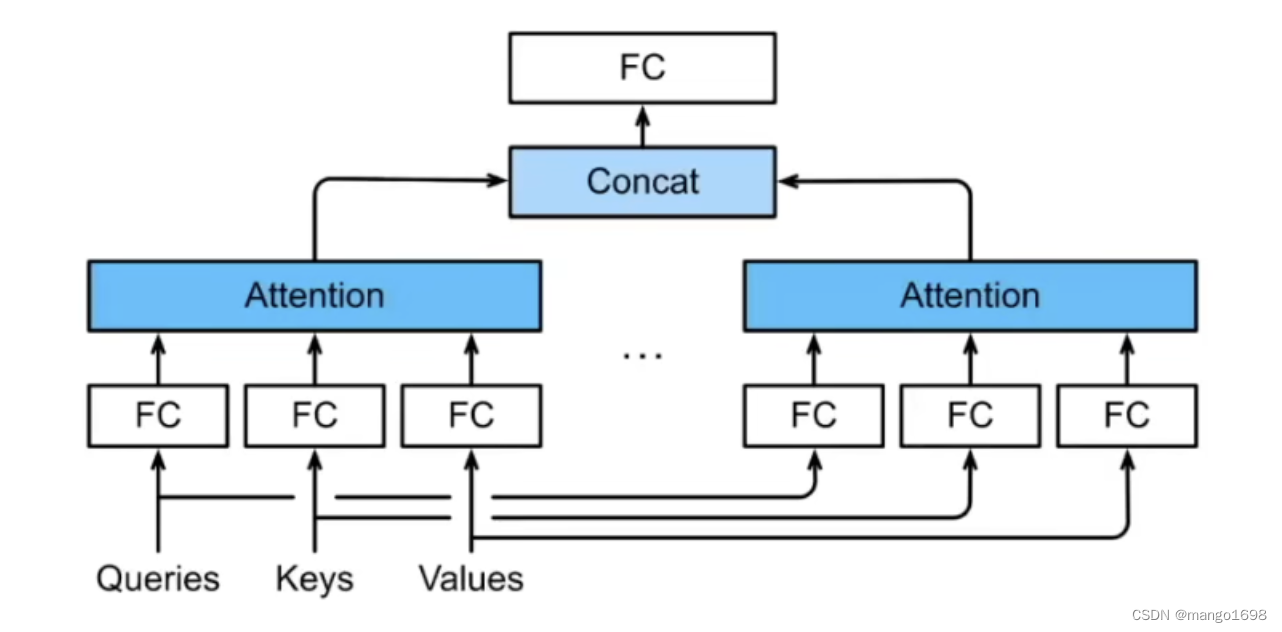
2. 多头注意力
- 对同一key,value,query,希望抽取不同的信息
- 例如短距离关系和长距离关系
- 多头注意力使用
h
h
h个独立的注意力池化
- 合并各个头(head)输出得到最终输出
3. 有掩码的多头注意力
- 解码器对序列中一个元素输出时,不应该考虑该元素之后的元素
- 可以通过掩码来实现
- 也就是计算 x i x_i xi输出时,假装当前序列长度为 i i i
4. 基于位置的前馈网络
- 将输入形状由 ( b , n , d ) (b,n,d) (b,n,d)变成 ( b n , d ) (bn,d) (bn,d)
- 作用两个全连接层
- 输出形状由 ( b n , d ) (bn,d) (bn,d)变化回 ( b , n , d ) (b,n,d) (b,n,d)
- 等价于两层核窗口为1的一维卷积层
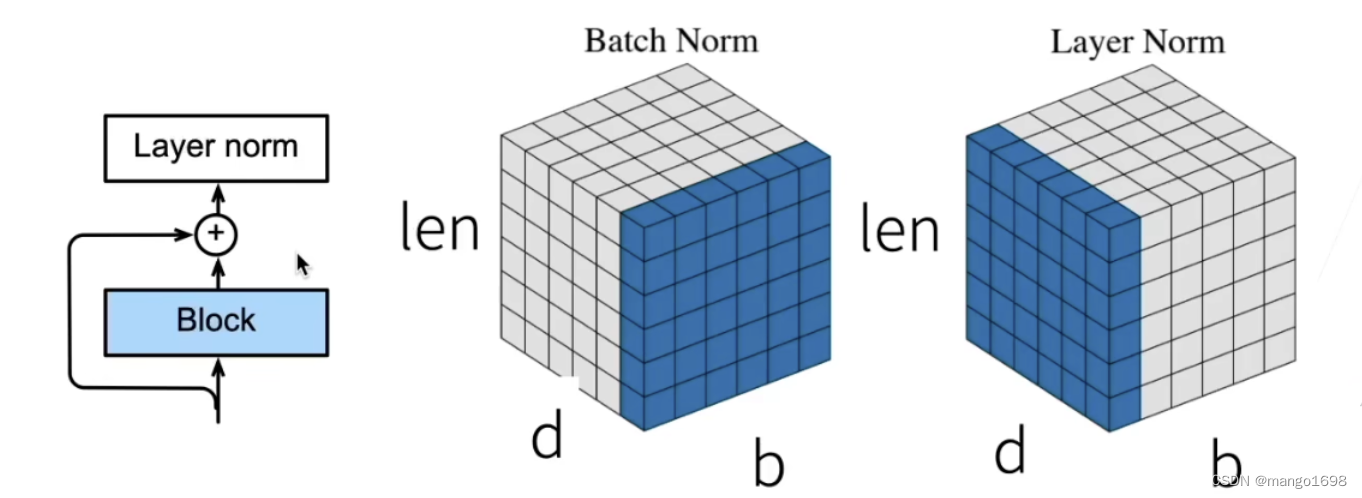
5. 层归一化
- 批量归一化对每个特征/通道里元素进行归一化
- 不适合序列长度会变的NLP应用
- 层归一化对每个样本里的元素进行归一化
6. 信息传递
- 编码器中的输出 y 1 , . . . , y n y_1,...,y_n y1,...,yn
- 将其作为解码中第
i
i
i个Transformer块中多头注意力的key核value
- 它的query来自目标序列
- 意味着编码器和解码器中块的个数和输出维度都是一样的
7. 预测
- 预测第 t + 1 t+1 t+1个输出时
- 解码器中输入前
t
t
t个预测值
- 在自注意力中,前t个预测值作为key和value,第t个预测值还作为query

总结:
- Transformer是一个纯使用注意力的编码-解码器
- 编码器和解码器都有n个transformer块
- 每个块里使用多头(自)注意力,基于位置的前馈网络,和层归一化。



![[论文笔记]BGE](https://img-blog.csdnimg.cn/img_convert/b1719d974e103a39ca7e66ff844f21f4.png)