1、集群管理与配置
1.1、集群搭建
关于Rabbitmq 集群的搭建,详见以下文章。简单说来就是将多个单机rabbitmq服务,通过给到一致的密钥(.erlang.cookie)并且开放rabbitmq服务的 25672 端口,允许多节点间进行互相通讯,就完成了集群的搭建。
- Rabbitmq安装_沿途欣赏i的博客-CSDN博客
- Linux下源码安装RabbitMQ并设置服务开机启动_51CTO博客_linux启动rabbitmq服务命令
当多个单机服务正常部署可运行的时候,则需要进行多节点的配置。假设这里一共有三台物理主机, 均己正确地安装了RabbitMQ ,且主机名分别为myblnp1 , myblnp2和myblnp3 。接下来需要按照以下步骤执行。
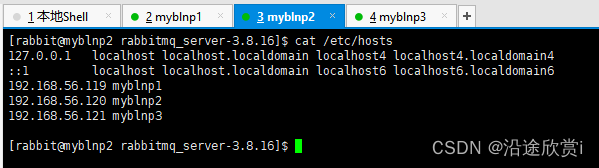
第一步,配置各个节点的hosts 文件,让各个节点都能互相识别对方的存在。比如在LÏnux 系统中可以编辑 /etc/hosts 文件,在其上添加IP地址与节点名称的映射信息:
第二步,编辑RabbitMQ 的cookie 文件,以确保各个节点的cookie 文件使用的是同一个值。可以读取myblnp1 节点的cookie 值, 然后将其复制到myblnp2 和myblnp3 节点中。cookie 文件默认路径为 /var/lib/rabbitmq/.erlang . cookie 或者$HOME/.erlang.cookie。cookie 相当于密钥令牌,集群中的RabbitMQ 节点需要通过交换密钥令牌以获得相互认证。如果节点的密钥令牌不一致,那么在配置节点时就会有如下的报错:
[rabbit@myblnp2 ~]$ rabbitmqctl join_cluster rabbit@myblnp1
Clustering node rabbit@myblnp2 with rabbit@myblnp1
Error: unable to perform an operation on node 'rabbit@myblnp1'. Please see diagnostics information and suggestions below.
Most common reasons for this are:
* Target node is unreachable (e.g. due to hostname resolution, TCP connection or firewall issues)
* CLI tool fails to authenticate with the server (e.g. due to CLI tool's Erlang cookie not matching that of the server)
* Target node is not running
In addition to the diagnostics info below:
* See the CLI, clustering and networking guides on https://rabbitmq.com/documentation.html to learn more
* Consult server logs on node rabbit@myblnp1
* If target node is configured to use long node names, don't forget to use --longnames with CLI tools
DIAGNOSTICS
===========
attempted to contact: [rabbit@myblnp1]
rabbit@myblnp1:
* connected to epmd (port 4369) on myblnp1
* epmd reports node 'rabbit' uses port 25672 for inter-node and CLI tool traffic
* can't establish TCP connection to the target node, reason: ehostunreach (host is unreachable)
* suggestion: check if host 'myblnp1' resolves, is reachable and ports 25672, 4369 are not blocked by firewall
Current node details:
* node name: 'rabbitmqcli-784-rabbit@myblnp2'
* effective user's home directory: /home/rabbit
* Erlang cookie hash: bDQvLYhXS0F44DcLh/J1lg==
[rabbit@myblnp2 ~]$ 第三步, 配置集群。配置集群有三种方式:通过rabbitmqctl 工具配置:通过rabbitmq.config 配置文件配置; 通过rabbitmq-autocluster插件配置。这里主要讲的是通过rabbitmqctl 工具的方式配置集群,这种方式也是最常用的方式。其余两种方式在实际应用中用之甚少, 所以不多做介绍。
首先启动myblnp1, myblnp2 和myblnp3 这3 个节点的RabbitMQ 服务。
[root@myblnp1 ~]# rabbitmq-server -detached
[root@myblnp2 ~]# rabbitmq-server -detached
[root@myblnp3 ~]# rabbitmq-server -detached这样, 这3个节点目前都是以独立节点存在的单个集群。通过rabbitmqctl cluster_status 命令来查看各个节点的状态。
[rabbit@myblnp1 ~]$ rabbitmqctl cluster_status
Cluster status of node rabbit@myblnp1 ...
Basics
Cluster name: rabbit@myblnp1
Disk Nodes
rabbit@myblnp1
Running Nodes
rabbit@myblnp1
Versions
rabbit@myblnp1: RabbitMQ 3.8.16 on Erlang 24.1.4
Maintenance status
Node: rabbit@myblnp1, status: not under maintenance
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@myblnp1, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Feature flags
Flag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: user_limits, state: enabled
Flag: virtual_host_metadata, state: enabled
[rabbit@myblnp1 ~]$ 接下来为了将3 个节点组成一个集群,需要以myblnp1节点为基准,将myblnp2 和myblnp3节点加入myblnp1节点的集群中。这3 个节点是平等的,如果想调换彼此的加入顺序也未尝不可。首
先将myblnp2 节点加入myblnp3 节点的集群中,需要执行如下4 个命令步骤。
[rabbit@myblnp3 ~]$ rabbitmqctl stop_app
Stopping rabbit application on node rabbit@myblnp3 ...
[rabbit@myblnp3 ~]$ rabbitmqctl reset
Resetting node rabbit@myblnp3 ...
[rabbit@myblnp3 ~]$
[rabbit@myblnp3 ~]$ rabbitmqctl join_cluster rabbit@myblnp1
Clustering node rabbit@myblnp3 with rabbit@myblnp1
[rabbit@myblnp3 ~]$
[rabbit@myblnp3 ~]$
[rabbit@myblnp3 ~]$ rabbitmqctl start_app
Starting node rabbit@myblnp3 ...
[rabbit@myblnp3 ~]$
同理在其余节点也执行以上步骤,即可完成集群的构建。此时查看集群状态信息可见如下所示:
[rabbit@myblnp1 rabbitmq_server-3.8.16]$ rabbitmqctl cluster_status
Cluster status of node rabbit@myblnp1 ...
Basics
Cluster name: rabbit@myblnp1
Disk Nodes
rabbit@myblnp1
rabbit@myblnp2
rabbit@myblnp3
Running Nodes
rabbit@myblnp1
rabbit@myblnp2
rabbit@myblnp3
Versions
rabbit@myblnp1: RabbitMQ 3.8.16 on Erlang 24.1.4
rabbit@myblnp2: on Erlang
rabbit@myblnp3: on Erlang
Maintenance status
Node: rabbit@myblnp1, status: not under maintenance
Node: rabbit@myblnp2, status: unknown
Node: rabbit@myblnp3, status: unknown
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@myblnp1, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Feature flags
Flag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: user_limits, state: enabled
Flag: virtual_host_metadata, state: enabled
[rabbit@myblnp1 rabbitmq_server-3.8.16]$
特别说明:这里尤其需要注意三点:
1、必须保证各节点之间,网络可互通。验证方式可以使用 ping 命令,来 ping 对接节点的 hostname 确保通讯正常
2、确保主节点的集群通讯端口(25672)与4369端口是开放的
3、确保各节点的 .erlang.cookie 是一致的
此外,如果使用 自启服务的方式来启动rabbitmq节点时,可能会出现一种情况。就是服务有时启动正常,有时启动失败。并且启动成功的时候,也无法使用 rabbitmq的任何相关命令,执行命令时也会返回 cookie问题。出现这种问题的原因的主要是两方面:
1、当前服务器节点内,存在多个 .erlang.cookie 文件并且不一致。可以通过命令查找所有的 .erlang.cookie 文件
[rabbit@myblnp2 ~]$ sudo find / -name '.erlang.cookie' /home/rabbit/rabbitmq_server-3.8.16/.erlang.cookie /home/rabbit/.erlang.cookie [rabbit@myblnp2 ~]$解决方式:清除多余的 cookie文件,保证cookie文件值的一致性
2、注册的自启服务存在问题,可通过 ‘sudo systemctl status [serviceName]’ 或 'sudo journalctl -xe' 等命令查看服务输出日志,在根据日志进行问题处理。
解决方式:我这里根据日志查看确定问题是因为权限问题,因为自启服务无法在指定目录下读取到 lockFile 文件,导致服务异常。解决方式很简单,首先将服务停止,然后将自启服务创建的整个 var 目录清除,然后进入rabbitmq 的 sbin 目录,使用指令通过前台方式运行服务。当服务运行正常后,停止服务并保留生成的 var 目录配置。此时在开启自启服务运行,则以上问题都解决了。
现在己经完成了集群的搭建。如果集群中某个节点关闭了,那么集群会处于什么样的状态?这里我们在node2 节点上执行rabbitmqctl stop app 命令来主动关闭RabbitMQ 应用。此时node1 上看到的集群状态可以参考下方信息,可以看到在running_nodes 这一选项中已经没有了rabbit@node2 这一节点。
如果关闭了集群中的所有节点,则需要确保在启动的时候最后关闭的那个节点是第一个启动的。如果第一个启动的不是最后关闭的节点,那么这个节点会等待最后关闭的节点启动。这个等待时间是30 秒,如果没有等到,那么这个先启动的节点也会失败。在最新的版本中会有重试机制, 默认重试10 次30 秒以等待最后关闭的节点启动。
在重试失败之后,当前节点也会因失败而关闭自身的应用。比如nodel 节点最后关闭,那么此时先启动node2 节点,在等待若干时间之后发现nod巳l 还是没有启动,则会有如下报错:

如果最后一个关闭的节点最终由于某些异常而无法启动,则可以通过rabbitrnqctl
forget_cluster node 命令来将此节点剔出当前集群,详细内容可以参考后续章节。如果集群中的所有节点由于某些非正常因素,比如断电而关闭,那么集群中的节点都会认为还有其他节点在它后面关闭,此时需要调用rabbitrnqctl force_boot 命令来启动一个节点,之后集群才能正常启动。
1.1.1、集群节点类型
在使用 rabbitrnqctl cluster_status 命令来查看集群状态时会有 Disk Nodes 这一项信息,其中的disk 标注了RabbitMQ 节点的类型。RabbitMQ 中的每一个节点,不管是单一节点系统或者是集群中的一部分,要么是内存节点(ram),要么是磁盘节点(disc)。内存节点将所有的队列、交换器、绑定关系、用户、权限和vhost的元数据定义都存储在内存中,而磁盘节点则将这些信息存储到磁盘中。单节点的集群中必然只有磁盘类型的节点,否则当重启RabbitMQ 之后,所有关于系统的配置信息都会丢失。不过在集群中,可以选择配置部分节点为内存节点,这样可以获得更高的性能。
[rabbit@myblnp3 ~]$ rabbitmqctl cluster_status
Cluster status of node rabbit@myblnp3 ...
Basics
Cluster name: rabbit@myblnp1
Disk Nodes
rabbit@myblnp1
rabbit@myblnp2
rabbit@myblnp3
Running Nodes
rabbit@myblnp1
rabbit@myblnp2
rabbit@myblnp3
Versions
rabbit@myblnp1: RabbitMQ 3.8.16 on Erlang 24.1.4
rabbit@myblnp2: RabbitMQ 3.8.16 on Erlang 24.1.4
rabbit@myblnp3: RabbitMQ 3.8.16 on Erlang 24.1.4
Maintenance status
Node: rabbit@myblnp1, status: not under maintenance
Node: rabbit@myblnp2, status: not under maintenance
Node: rabbit@myblnp3, status: not under maintenance
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@myblnp1, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@myblnp2, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp2, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp2, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@myblnp3, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp3, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp3, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Feature flags
Flag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: user_limits, state: enabled
Flag: virtual_host_metadata, state: enabled
[rabbit@myblnp3 ~]$比如将node2 节点加入node1 节点的时候可以指定node2 节点的类型为内存节点。
[root@node2 ~]# rabbitmqctl join_cluster rabbit@nodel --ram
Clustering node rabbit@node2 with rabbit@nodel 这样在以nodel 和node2 组成的集群中就会有一个磁盘节点和一个内存节点,可以参考下
面的打印信息。默认不展示 "RAM NODES" 选项。如果集群已经搭建好了,那么也可以使用rabbitmqctl change_cluster_node_type {disc , ram) 命令来切换节点的类型,其中disc 表示磁盘节点,而ram 表示内存节点。举例,这里将上面 myblnp3 节点由内存节点转变为磁盘节点。完整执行步骤如下所示:
[rabbit@myblnp3 ~]$ rabbitmqctl cluster_status
Cluster status of node rabbit@myblnp3 ...
Basics
Cluster name: rabbit@myblnp1
Disk Nodes
rabbit@myblnp1
rabbit@myblnp2
rabbit@myblnp3
Running Nodes
rabbit@myblnp1
rabbit@myblnp2
rabbit@myblnp3
Versions
rabbit@myblnp1: RabbitMQ 3.8.16 on Erlang 24.1.4
rabbit@myblnp2: RabbitMQ 3.8.16 on Erlang 24.1.4
rabbit@myblnp3: RabbitMQ 3.8.16 on Erlang 24.1.4
Maintenance status
Node: rabbit@myblnp1, status: not under maintenance
Node: rabbit@myblnp2, status: not under maintenance
Node: rabbit@myblnp3, status: not under maintenance
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@myblnp1, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@myblnp2, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp2, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp2, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@myblnp3, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp3, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp3, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Feature flags
Flag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: user_limits, state: enabled
Flag: virtual_host_metadata, state: enabled
[rabbit@myblnp3 ~]$
[rabbit@myblnp3 ~]$
[rabbit@myblnp3 ~]$
[rabbit@myblnp3 ~]$ rabbitmqctl stop_app
Stopping rabbit application on node rabbit@myblnp3 ...
[rabbit@myblnp3 ~]$ rabbitmqctl change_cluster_node_type disc
Turning rabbit@myblnp3 into a disc node
Node type is already disc
[rabbit@myblnp3 ~]$ rabbitmqctl change_cluster_node_type ram
Turning rabbit@myblnp3 into a ram node
[rabbit@myblnp3 ~]$ rabbitmqctl start_app
Starting node rabbit@myblnp3 ...
[rabbit@myblnp3 ~]$
[rabbit@myblnp3 ~]$ rabbitmqctl cluster_status
Cluster status of node rabbit@myblnp3 ...
Basics
Cluster name: rabbit@myblnp1
Disk Nodes
rabbit@myblnp1
rabbit@myblnp2
RAM Nodes
rabbit@myblnp3
Running Nodes
rabbit@myblnp1
rabbit@myblnp2
rabbit@myblnp3
Versions
rabbit@myblnp1: RabbitMQ 3.8.16 on Erlang 24.1.4
rabbit@myblnp2: RabbitMQ 3.8.16 on Erlang 24.1.4
rabbit@myblnp3: RabbitMQ 3.8.16 on Erlang 24.1.4
Maintenance status
Node: rabbit@myblnp1, status: not under maintenance
Node: rabbit@myblnp2, status: not under maintenance
Node: rabbit@myblnp3, status: not under maintenance
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@myblnp1, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@myblnp2, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp2, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp2, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@myblnp3, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp3, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp3, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Feature flags
Flag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: user_limits, state: enabled
Flag: virtual_host_metadata, state: enabled
[rabbit@myblnp3 ~]$

在集群中创建队列、交换器或者绑定关系的时候,这些操作直到所有集群节点都成功提交元数据变更后才会返回。对内存节点来说,这意味着将变更写入内存;而对于磁盘节点来说,这意味着昂贵的磁盘写入操作。内存节点可以提供出色的性能,磁盘节点能够保证集群配置信息的高可靠性,如何在这两者之间进行抉择呢?
RabbitMQ 只要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点。当节点加入或者离开集群时,它们必须将变更通知到至少一个磁盘节点。如果只有一个磁盘节点,而且不凑巧的是它刚好崩溃了,那么集群可以继续发送或者接收消息,但是不能执行创建队列、交换器、绑定关系、用户,以及更改权限、添加或删除集群节点的操作了。也就是说,如果集群中唯一的磁盘节点崩溃,集群仍然可以保持运行, 但是直到将该节点恢复到集群前,你无法更改任何东西。所以在建立集群的时候应该保证有两个或者多个磁盘节点的存在。
在内存节点重启后,它们会连接到预先配置的磁盘节点,下载当前集群元数据的副本。当在集群中添加内存节点时,确保告知其所有的磁盘节点(内存节点唯一存储到磁盘的元数据信息是集群中磁盘节点的地址)。只要内存节点可以找到至少一个磁盘节点,那么它就能在重启后重新加入集群中。
除非使用的是RabbitMQ 的RPC 功能,否则创建队列、交换器及绑定关系的操作确是甚少,大多数的操作就是生产或者消费消息。为了确保集群信息的可靠性,或者在不确定使用磁盘节点或者内存节点的时候,建议全部使用磁盘节点。
1.1.2、剔除单个节点
创建集群的过程可以看作向集群中添加节点的过程。那么如何将一个节点从集群中剔除呢?这样可以让集群规模变小以节省硬件资源,或者替换一个机器性能更好的节点。同样以nodel、node2 和node3 组成的集群为例,这里有两种方式将node2 剥离出当前集群。
第一种,首先在node2 节点上执行rabbitmqctl stop_app 或者rabbitmqctl stop命令来关闭RabbitMQ 服务。之后再在nodel 节点或者node3 节点上执行rabbitmqctl forget_cluster_node rabbit@node2 命令将nodel 节点剔除出去。这种方式适合node2节点不再运行RabbitMQ 的情况。
[rabbit@myblnp1 rabbitmq_server-3.8.16]$ rabbitmqctl forget_cluster_node rabbit@myblnp2
Removing node rabbit@myblnp2 from the cluster
Error:
RabbitMQ on node rabbit@myblnp2 must be stopped with 'rabbitmqctl -n rabbit@myblnp2 stop_app' before it can be removed
[rabbit@myblnp1 rabbitmq_server-3.8.16]$
#待剔除节点尚在运行中,是无法使用该方式进行剔除的
[rabbit@myblnp1 rabbitmq_server-3.8.16]$
[rabbit@myblnp1 rabbitmq_server-3.8.16]$ rabbitmqctl cluster_status
Cluster status of node rabbit@myblnp1 ...
Basics
Cluster name: rabbit@myblnp1
Disk Nodes
rabbit@myblnp1
rabbit@myblnp2
RAM Nodes
rabbit@myblnp3
Running Nodes
rabbit@myblnp1
rabbit@myblnp3
Versions
rabbit@myblnp1: RabbitMQ 3.8.16 on Erlang 24.1.4
rabbit@myblnp3: on Erlang
Maintenance status
Node: rabbit@myblnp1, status: not under maintenance
Node: rabbit@myblnp3, status: unknown
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@myblnp1, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@myblnp1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@myblnp1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Feature flags
Flag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: user_limits, state: enabled
Flag: virtual_host_metadata, state: enabled
[rabbit@myblnp1 rabbitmq_server-3.8.16]$
[rabbit@myblnp1 rabbitmq_server-3.8.16]$
[rabbit@myblnp1 rabbitmq_server-3.8.16]$ rabbitmqctl forget_cluster_node rabbit@myblnp2
Removing node rabbit@myblnp2 from the cluster
[rabbit@myblnp1 rabbitmq_server-3.8.16]$

在上一章节中有提到,在关闭集群中的每个节点之后,如果最后一个关闭的节点最终由于某些异常而无法启动,则可以通过rabbitmqctl forget_cluster_node 命令来将此节点剔除出当前集群。举例,集群中节点按照node3 、node2 、node1 的顺序关闭,此时如果要启动集群, 就要先启动node1节点。
[root@node3 ~]# rabbitmqctl stop
Stopping and halting node rabbit@node3
[root@node2 ~j# rabbitmqctl stop
Stopping and halting node rabbit@node2
[root@nodel ~]# rabbitmqctl stop
Stopping and halting node rabbit@nodel第二种,可以在node2 节点中执行命令将nodel 节点剔除出当前集群。
[root@node2 ~]# rabbitmqctl forget_cluster_node rabbit@nodel -offline
Removing node rabbit@nodel from cluster
* Impersonating node : rabbit@node2 ... done
* Mnesia directory : /opt/rabbitmq/var/lib/rabbitmq/mnesia/rabbit@node2
[root@node2 ~] # rabbitmq-server -detached
Warning: PID file not written ; -detached was passed.
[root@node2 ~]#注意上面在使用 rabbitmqctl forget_cluster_node 命令的时候用到了 " -offline" 参数,如果不添加这个参数,就需要保证node2 节点中的RabbitMQ 服务处于运行状态,而在这种情况下,node2 无法先行启动, 则" -offline" 参数的添加让其可以在非运行状态下将nodel 剥离出当前集群。
第二种方式是在node2 上执行rabbitmqctl reset 命令。如果不是像上面由于启动顺序的缘故而不得不删除一个集群节点,建议采用这种方式。
[root@node2 ~] # rabbitmqctl stop app
Stopping rabbit application on node rabbit@node2
[root@node2 ~]# rabbitmqctl reset
Resetting node rabbit@node2
[root@node2 ~] # rabbitmqctl start app
Starting node rabbit@node2如果从node2 节点上检查集群的状态, 会发现它现在是独立的节点。同样在集群中剩余的节点nodel 和node3 上看到node2 已不再是集群中的一部分了。正如之前所说的, rabbitmqctl reset 命令将清空节点的状态, 并将其恢复到空白状态。当重设的节点是集群中的一部分时, 该命令也会和集群中的磁盘节点进行通信, 告诉它们该节点正在离开集群。不然集群会认为该节点出了故障, 并期望其最终能够恢复过来。
1.1.3、集群节点的升级
如果RabbitMQ 集群由单独的一个节点组成,那么升级版本很容易,只需关闭原来的服务,然后解压新的版本再运行即可。不过要确保原节点的Mnesia 中的数据不被变更,且新节点中的Mnesia 路径的指向要与原节点中的相同。或者说保留原节点Mnesia 数据, 然后解压新版本到相应的目录,再将新版本的Mnesia 路径指向保留的Mnesia 数据的路径(也可以直接复制保留的Mnesia 数据到新版本中相应的目录) ,最后启动新版本的服务即可。如果RabbitMQ 集群由多个节点组成,那么也可以参考单个节点的情形。具体步骤:
- 关闭所有节点的服务, 注意采用rabbitmqctl stop 命令关闭。
- 保存各个节点的Mnesia 数据。
- 解压新版本的RabbitMQ 到指定的目录。
- 指定新版本的Mnesia 路径为步骤2 中保存的Mnesia 数据路径
- 启动新版本的服务,注意先重启原版本中最后关闭的那个节点
其中步骤4 和步骤5 可以一起操作,比如执行RABBITMQ_MNESIA_BASE=/opt/mnesia
rabbitmq-server-detached 命令,其中/opt/mnesia 为原版本保存Mnesia 数据的路径。
RabbitMQ 的版本有很多, 难免会有数据格式不兼容的现象, 这个缺陷在越旧的版本中越发凸显,所以在对不同版本升级的过程中,最好先测试两个版本互通的可能性,然后再在线上环境中实地操作。
如果原集群上的配置和数据都可以舍弃,则可以删除原版本的RabbitMQ ,然后再重新安装
配置即可:如果配置和数据不可丢弃,则先保存元数据,之后再关闭所有生产者并等待消费者消费完队列中的所有数据,紧接着关闭所有消费者,然后重新安装RabbitMQ 并重建元数据等。
1.1.4、单机多节点配置
由于某些因素的限制,有时候不得不在单台物理机器上去创建一个多RabbitMQ 服务节点的集群。或者只想要实验性地验证集群的某些特性,也不需要浪费过多的物理机器去实现。
在一台机器上部署多个RabbitMQ 服务节点,需要确保每个节点都有独立的名称、数据存储位置、端口号(包括插件的端口号)等。我们在主机名称为nodel 的机器上创建一个由rabbitl @nodel 、rabbit2@nodel 和rabbit3 @nodel 这3 个节点组成RabbitMQ 集群。
首先需要确保机器上己经安装了Erlang 和RabbitMQ 的程序。其次,为每个RabbitMQ 服务节点设置不同的端口号和节点名称来启动相应的服务。
[root@nodel ~]# RABBITMQ_NODE_PORT=5672 RABBITMQ_NODENAME=rabbitl
rabbitmq-server -detached
[root@nodel ~]# RABBITMQ_NODE_PORT=5673 RABBITMQ_NODENAME=rabbit2
rabbitmq-server -detached
[root@nodel ~]# RABBITMQ_NODE_PORT=5674 RABBITMQ_NODENAME=rabbit3
rabbitmq-server -detached在启动rabbitl@node1节点的服务之后, 继续启动rabbit2@nodel 和rabbit@nodel 服务节点会遇到启动失败的情况。这种情况大多数是由于配置发生了冲突而造成后面的服务节点启动失败, 需要进一步确认是否开启了某些功能,比如RabbitMQ Management 插件。如果开启了RabbitMQ Management 插件,就需要为每个服务节点配置一个对应插件端口号, 具体内容如下所示。
[root@nodel ~]# RABBITMQ_NODE_PORT=5672 RABBITMQ_NODENAME=rabbitl
RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port , 156721] "
rabbitmq-server -detached
[root@nodel ~]# RABBITMQ_NODE_PORT=5673 RABBITMQ_NODENAME=rabbit2
RABBITMQ_SERVER_START_ARGS= " -rabbitmq_management listener [{port , 1567 3 1] "
rabbitmq-server -detached
[root@nodel ~]# RABBITMQ_NODE_PORT=5674 RABBITMQ_NODENAME=rabbit3
RABBITMQ_SERVER_START_ARGS=" -rabbitmq_management listener [{port , 156741]"
rabbitmq-server -detached启动各节点服务之后, 将rabbit2@nodel 节点加入rabbit l @nodel 的集群之中:
[root@nodel ~]# rabbitmqctl -n rabbit2@nodel stop_app
Stopping rabbit application on node rabbit2@nodel
[root@nodel ~]# rabbitmqctl -n rabbit2@nodel reset
Resetting node rabbit2@nodel
[root@nodel ~]# rabbitmqctl -n rabbit2@nodel join_cluster rabbitl@nodel
Clustering node rabbit2@nodel with rabbitl@nodel
[root@nodel ~]# rabbitmqctl -n rabbit2@nodel start_app
Starting node rabbit2@nodel紧接着可以执行相似的操作将rabbit3@nodel 也加入进来。最后通过rabbitmqctl cluster_status 命令来查看各个服务节点的集群状态。
1.2、查看服务日志
如果在使用RabbitMQ 的过程中出现了异常情况,通过翻阅RabbitMQ 的服务日志可以让你在处理异常的过程中事半功倍。RabbitMQ 日志中包含各种类型的事件,比如连接尝试、服务启动、插件安装及解析请求时的错误等。本节首先举几个例子来展示一下RabbitMQ 服务日志的内容和日志的等级,接着再来阐述如何通过程序化的方式来获得日志及对服务日志的监控。
RabbitMQ 的日志默认存放在$RABBITMQ_HOME/var/log/rabbitmq 文件夹内。在这个文件夹内RabbitMQ 会创建两个日志文件: RABBITMQ_NODENAME-sasl.log 和RABBITMQ_NODENAME.log 。
SASL ( System Application Support Libraries ,系统应用程序支持库)是库的集合,作为Erlang-OTP 发行版的一部分。它们帮助开发者在开发Erlang 应用程序时提供一系列标准,其中之一是日志记录格式。所以当RabbitMQ 记录Erlang 相关信息时,它会将日志写入文件RABBITMQ_NODENAME-sasl . log 中。举例来说,可以在这个文件中找到Erlang 的崩横报告,有助于调试无法启动的RabbitMQ 节点。
如果想查看RabbitMQ 应用服务的日志,则需要查阅RABBITMQ_NODENAME.log 这个文
件,所谓的RabbitMQ 服务日志指的就是这个文件。各位读者实际使用的RabbitMQ 版本各有差异, 这里我们挑选一个稍旧版本(3 .6.2) 来统筹说明。所幸各个版本的日志大致相同,只是有略微变化。读者需要培养一种使用服务日志来解决问题的思路。
1.2.1、启动RabbitMQ服务
启动RabbitMQ 服务可以使用rabbitmq-server-detached 命令, 这个命令会顺带启动Erlang 虚拟机和RabbitMQ 应用服务, 而rabbitmqctl start_app 用来启动RabbitMQ应用服务。注意, RabbitMQ 应用服务启动的前提是Erlang 虚拟机是运转正常的。首先来看一下在执行完rabbitmq-server -detached 命令后其相应的服务日志是什么。
Starting Rabb 工tMQ 3.6.2 on Er1ang 19.1
Copyright (C) 2007-2016 Pivota1 Software , Inc .
Licensed under the MPL . See http : //www . rabbitmq.com/
=INFO REPORT==== 3-0ct-2017 : : 10 : 52:08 ===
node : rabbit@node1
home dir : /root
config fi1e(s) : /opt/rabbitmq/etc/rabbitmq/rabbitmq.config (not found)
cookie hash : VCwbL3S9/ydrGgVsrLjVkA==
10g : /opt/rabbitmq/var/1og/rabbitmq/rabbit@node1 . 1og
sas1 10g : /opt/rabbitmq/var/ 1og/rabbitmq/rabbit@node1-sas1 .1og
database dir : /opt/rabbitmq/var/1ib/rabbitmq/mnesia/rabbit@node1
=INFO REPORT==== 3- Oct -2017::10 : 52 : 09 ===
Memory limit set to 3148MB of 7872MB total .
=INFO REPORT==== 3- Oct - 2017 : : 10 : 52 : 09 ===
Disk free l imit set to 50MB
=INFO REPORT==== 3 - Oct - 2017 : :10 : 52 : 09 ===
Limiting to approx 924 file handles (829 sockets)
=INFO REPORT==== 3 - Oct -2017::10 : 52 : 09 ===
FHC read buffering: OFF
FHC write bufferin g : ON
=INFO REPORT==== 3 - Oct - 2017: : 10:52 : 09 ===
Database d 工rectory at /opt/rabbitmq/var/lib/rabbitmq/mnesia/rabbit@node1 is
empty . Initialising from scratch.. .
=INFO REPORT==== 3 - Oct - 2017: : 10:52 : 10 ===
Pr 工ority queues enabled, real BQ 工s rabb 工t variable queue
=INFO REPORT==== 3- Oct - 2017: : 10 : 52 : 10 ===
Adding vhost ' / '
=INFO REPORT==== 3 - Oct - 2017 : : 10 : 52:10 ===
Creating user ' guest '
=INFO REPORT==== 3 - Oct - 2017 : : 10 : 52:10 ===
Setting user tags for user ' guest ' to [adm工n 工stratorl
=INFO REPORT==== 3 - Oct - 2017 : :10 : 52 : 10 ===
Setting permiss 工ons for ' guest ' in ' / ' to ' .*','. *','. *'
=INFO REPORT==== 3 - Oct - 2017 : :10 : 52 : 10 ===
msg store transient: usi 口9 rabbit msg store ets index to provide index
=INFO REPORT==== 3 - Oct - 2017 : :10 : 52 : 10 ===
msg store pers 工stent : using rabb 工t msg store ets index to provide index
=WARNING REPORT==== 3 - Oct - 2017 : :10 : 52 : 10 ===
msg store pers 工stent : rebuild 工ng 工ndices from scratch
=INFO REPORT==== 3 - Oct - 2017 : :10 : 52 : 10 ===
started TCP Listener on [ : :1 : 5672
=INFO REPORT==== 3 - Oct - 2017 :: 10:52 : 10 ===
Server startup complete ; 0 plugins started .这段日志包含了RabbitMQ 的版本号、Erlang 的版本号、RabbitMQ 服务节点名称、cookie的hash 值、RabbitMQ 配置文件地址、内存限制、磁盘限制、默认账户guest 的创建及权限配置等。
注意到上面日志中有"WARNING REPORT" 和"INFO REPORT" 这些字样, 有过编程经验的读者应该可以猜出这与日志级别有关。在RabbitMQ 中,日志级别有none 、error、waming 、info 、debug 这5 种,下一层级别的日志输出均包含上一层级别的日志输出,比如warning 级别的日志包含warning 和error 级别的日志, none 表示不输出日志。日志级别可以通过rabbitmq.config 配置文件中的log levels 参数来进行设置,默认为[ {connection , info) 。
如果开启了RabbitMQ Management 插件, 则在启动RabbitMQ 的时候会多打印一些日志:
=INFO REPORT==== 3- Oct -2017 : :10 : 57:05 ===
Server startup complete; 6 plugins started.
* rabbitmq management
* rabbitmq_management agent
* rabbitmq_web_dispatch
* webmachine
* mochiweb
* amqp client
#当然还包括一些统计值信息的初始化日志,类似如下:
=INFO REPORT==== 3- Oct -2017 : :10:57:05 ===
Statistics garbage collector started for table {aggr queue stats fine stats ,
5000} .与aggr_queue_stats_fine_stats 日志一起的还有很多项指标,比如aggr_queue_stats_deliver_get 和aggr_queue_stats_queue_msg_counts ,由于篇幅所限,这里不再赘述,有兴趣的读者可以自行查看相关版本的统计指标。不同的版本可能略有差异, 一般情况下对此无须过多探究。
如果使用rabbitmqctl stop_app 命令关闭的RabbitMQ 应用服务, 那么在使用rabbitmqctl start_app 命令开启RabbitMQ 应用服务时的启动日志和rabbitmq-server的启动日志相同。
1.2.2、关闭RabbitMQ服务
如果使用rabbitmqctl stop 命令,会将Erlang 虚拟机一同关闭,而rabbitmqctl stop_app 只关闭RabbitMQ 应用服务,在关闭的时候要多加注意它们的区别。下面先看一下rabbitmqctl stop_app 所对应的服务日志:
=INFO REPORT==== 3- 0ct-2017 : :10:54:01 ===
Stopping RabbitMQ
=INFO REPORT==== 3- Oct -2017: : 10 : 54 : 01 ===
stopped TCP Listener on [ :: ] : 5672
=INFO REPORT==== 3- Oc t -2017: :10:54:01 ===
Stopped RabbitMQ app1ication如果使用rabbitmqctl stop 来进行关闭操作,则会多出下面的日志信息,即关闭Erlang虚拟机。
=INFO REPORT==== 3- Oct -2017: : 10:54: 01 ===
Halting Erlang VM1.2.3、建立集群
建立集群也是一种常用的操作。这里举例将节点rabbit@node2 与rabbit@nodel 组成一个集
群,有关如何建立RabbitMQ 集群的细节可以参考上文。
首先在节点rabbit@node2 中执行rabbitmq-server -detached 开启Erlang 虚拟机和RabbitMQ 应用服务,之后再执行rabbitmqctl stop_app 来关闭RabbitMQ 应用服务,具体的日志可以参考前面的内容。之后需要重置节点rabbit@node2 中的数据rabbitmqctl reset ,相应地在节点rabbit@node2 上输出的日志如下:
=INFO REPORT==== 3- Oct -2017: :11:25:01 ===
Resetting Rabbit在rabbit@node2 节点上执行rabbitmqctl join_clcuster rabbit@nodel ,将其加入rabbit@nodel 中以组成一个集群,相应地在rabbit@node2 节点中会打印日志:
=INFO REPORT==== 3- Oct -2017: : 11:30:46 ===
C1ustering with [rabbit@node1] as disc node与此同时在rabbit@nodel 中会有以下日志:
=INFO REPORT==== 3- Oct -2017: : 11:30 : 56 ===
node rabbit@node2 up如果此时在rabbit@node2 节点上执行rabbitmqctl stop_app 的动作,那么在rabbit@nodel 节点中会有如下信息:
=INFO REPORT==== 3- Oct - 2017: :11 :54 : 01 ===
rabbit on node rabbit@node2 down
=INFO REPORT==== 3- Oct -2017: :11: 54 : 01 ===
Keep rabbit@node2 listeners : the node is already back1.2.4、其他
再比如客户端与RabbitMQ 建立连接:
=INFO REPORT==== 14-0ct- 2017 : :1 6 : 24 : 55 ===
accepting AMQP connection <0 . 5865.0> (192.168.0 . 9:61601 - > 192.168.0.2:5672)当客户端强制中断连接时:
=WARNING REPORT==== 14-Ju1-2017 : : 16 : 36 :57 ===
closing AMQP connection <0 . 5909 . 0> (1 92 . 168 . 0 . 9 : 61629 - > 192 . 168 . 0 . 2:5672 )
connect 工on_closed_abruptly 有时候RabbitMQ 服务持久运行,其对应的日志也越来越多,尤其是在遇到故障的时候会打
印很多信息。有时候也需要对日志按照某种规律进行切分,以便于后期的管理。RabbitMQ 中可
以通过rabbitmqctl rotate_logs {suffix} 命令来轮换日志,比如手工切换当前的日志:
rabbitmqct1 rotate logs .bak之后可以看到在日志目录下会建立新的日志文件,并且将老的日志文件以添加".bak" 后缀的方式进行区分保存:
[root@nodel rabbitmql# ls - a1
-rw-r--r-- 1 root root 0 Ju1 23 00 : 50 rabbit@nodel.1og
-rw-r--r-- 1 root root 22646 Ju1 23 00 : 50 rabbit@nodel.1og.bak
-rw-r--r-- 1 root root o Ju1 23 00:50 rabbit@nodel-sas1.1og
-rw-r--r-- 1 root root o Ju1 23 00 : 50 rabbit@nodel-sas1.log.bak 也可以执行一个定时任务,比如使用Linux crontab ,以当前日期为后缀,每天执行一次切
换日志的任务,这样在后面需要查阅日志的时候可以根据日期快速定位到相应的日志文件。
1.3、单节点故障恢复
在RabbitMQ 使用过程中,或多或少都会遇到一些故障。对于集群层面来说,更多的是单点故障。所谓的单点故障是指集群中单个节点发生了故障,有可能会引起集群服务不可用、数据丢失等异常。配置数据节点冗余(镜像队列)可以有效地防止由于单点故障而降低整个集群的可用性、可靠性。
单节点故障包括:机器硬件故障、机器掉电、网络异常、服务进程异常。单节点机器硬件故障包括机器硬盘、内存、主板等故障造成的死机,无法从软件角度来恢复。此时需要在集群中的其他节点中执行rabbitmqctl forget_cluster_node {nodename} 命令来将故障节点剔除,其中nodename 表示故障机器节点名称。如果之前有客户端连接到此故障节点上,在故障发生时会有异常报出,此时需要将故障节点的 IP 地址从连接列表里删除,并让客户端重新与集群中的节点建立连接,以恢复整个应用。如果此故障机器修复或者原本有备用机器,那么也可以选择性的添加到集群中。
当遇到机器掉电故障,需要等待电源接通之后重启机器。此时这个机器节点上的RabbitMQ
处于stop 状态,但是此时不要盲目重启服务,否则可能会引起网络分区 。此时同样需要在其他节点上执行rabbitmqctl forget_cluster_node {nodename} 命令将此节点从集群中剔除,然后删除当前故障机器的RabbitMQ 中的Mnesia数据(相当于重置),然后再重启RabbitMQ 服务,最后再将此节点作为一个新的节点加入到当前集群中。
网线松动或者网卡损坏都会引起网络故障的发生。对于网线松动,无论是彻底断开,还是"藕断丝连",只要它不降速, RabbitMQ 集群就没有任何影响。但是为了保险起见,建议先关闭故障机器的RabbitMQ 进程,然后对网线进行更换或者修复操作,之后再考虑是否重新开启RabbitMQ 进程。而网卡故障极易引起网络分区的发生,如果监控到网卡故障而网络分区尚未发生时,理应第一时间关闭此机器节点上的RabbitMQ 进程,在网卡修复之前不建议再次开启。如果己经发生了网络分区,可以参考4.5 节进行手动恢复网络分区。对于服务进程异常,如RabbitMQ 进程非预期终止,需要预先思考相关风险是否在可控范围之内。如果风险不可控,可以选择抛弃这个节点。一般情况下,重新启动RabbitMQ 服务进程即可。
1.4、集群迁移
对于RabbitMQ 运维层面来说,扩容和迁移是必不可少的。扩容比较简单,一般向集群中加入新的集群节点即可,不过新的机器节点中是没有队列创建的,只有后面新创建的队列才有可能进入这个新的节点中。或者如果集群配置了镜像队列,可以通过一点"小手术"将原先队列"漂移"到这个新的节点中,具体可以参考第4.5 节。
迁移同样可以解决扩容的问题,将旧的集群中的数据(包括元数据信息和消息〉迁移到新的且容量更大的集群中即可。RabbitMQ 中的集群迁移更多的是用来解决集群故障不可短时间内修复而将所有的数据、客户端连接等迁移到新的集群中,以确保服务的可用性。相比于单点故障而言,集群故障的危害性就大得多,比如IDC 整体停电、网线被挖断等。这时候就需要通过集群迁移重新建立起一个新的集群。RabbitMQ 集群迁移包括元数据重建、数据迁移,以及与客户端连接的切换。
1.4.1、元数据重建
元数据重建是指在新的集群中创建原集群的队列、交换器、绑定关系、vhost、用户、权限和Parameter 等数据信息。元数据重建之后才可将原集群中的消息及客户端连接迁移过来。
有很多种方法可以重建元数据,比如通过手工创建或者使用客户端创建。但是在这之前最耗时耗力的莫过于对元数据的整理,如果事先没有统筹规划, 通过人工的方式来完成这项工作是极其烦琐、低效的,且时效性太差,不到万不得已不建议使用。高效的手段莫过于通过Web管理界面的方式重建,在Web 管理界面的首页最下面有如图所示的内容,这里展示的是 3.8.16 版本的界面,之前的很多版本下面的两项是井排排列的,而非竖着排列,但总体上没有任何影响。

可以在原集群上点击" Download broker defmitions" 按钮下载集群的元数据信息文件,此文件是一个JSON 文件,比如命名为metadata.json . 其内部详细内容可以参考附录A 。之后再在新集群上的Web 管理界面中点击" Upload broker defmitions " 按钮上传metadata.j son 文件,如果导入成功则会跳转到如图7-3 所示的页面,这样就迅速在新集群中创建了元数据信息。注意,如果新集群有数据与metadata.json 中的数据相冲突,对于交换器、队列及绑定关系这类非可变对象而言会报错,而对于其他可变对象如Parameter、用户等则会被覆盖,没有发生冲突的则不受影响。如果过程中发生错误,则导入过程终止,导致metadata扣on 中只有部分数据加载成功。

上面这种方式需要考虑三个问题。
第一,如果原集群突发故障,又或者开启RabbitMQ Management 插件的那个节点机器故障不可修复,就无法获取原集群的元数据metadata.json ,这样元数据重建就无从谈起。这个问题也很好解决, 我们可以采取一个通用的备份任务, 在元数据有变更或者达到某个存储周期时将最新的metadata.json 备份至另一处安全的地方。这样在遇到需要集群迁移时, 可以获取到最新的元数据。
第二, 如果新旧集群的RabbitMQ 版本不一致时会出现异常情况, 比如新建立了一个3.6.10 版本的集群, 旧集群版本为3.5.7 ,这两个版本的元数据就不相同。3.5.7 版本中的user 这一项的内容如下, 与3.6.10 版本的加密算法是不一样的。可以参考附录A 中的相关项以进行对比。
{
"users": [
{
"name": "guest",
"password_hash": "131asf353sd46436ere=",
"tags": "administrator"
},
{
"name": "root",
"password_hash": "sdgsdyer6te34534tsdet3ezxf23=",
"tags": "administrator"
}
]
}再者, 3.6.10 版本中的元数据JSON 文件比3.5.7 版本中多了global_parameters 这一项。一般情况下, RabbitMQ 是能够做到向下兼容的, 在高版本的RabbitMQ 中可以上传低版本的元数据文件。然而如果在低版本中上传高版本的元数据文件就没有那么顺利了, 就以3.6.10版本的元数据加载到3.5.7 版本中就会出现用户登录失败的情况为例, 因为密码加密方式变了,这里可以简单地在Shell 控制台输入变更密码的方式来解决这个问题:
rabbitmqctl change_password {username) {new_password)如果还是不能成功上传元数据,那么就需要进一步采取措施了。在此之前,我们首选需要明确一个概念,就是对于用户、策略、权限这种元数据来说内容相对固定,且内容较少,手工重建的代价较小。而且在一个新集群中要能让Web 管理界面运作起来,本身就需要创建用户、设置角色及添加权限等。相反, 集群中元数据最多且最复杂的要数队列、交换器和绑定这三项的内容,这三项内容还涉及其内容的参数设置,如果采用人工重建的方式代价太大,重建元数据的意义其实就在于重建队列、交换器及绑定这三项的相关信息。
这里有个小窍门,可以将3.6.10 的元数据从queues 这一项前面的内容,包括rabbit_version 、users 、vhosts 、permissions 、parameters 、global_parameters 和 policies这几项内容复制后替换3.5.7 版本中的queues 这一项前面的所有内容, 然后再保存。之后将修改并保存过后的3.5.7 版本的元数据JSON 文件上传到新集群3.6.10 版本的Web 管理界面中,至此就完成了集群的元数据重建(阅读这一段落时可以对照着附录A 的内容来加深理解) 。
第三,就是如果采用上面的方法将元数据在新集群上重建,则所有的队列都只会落到同一个集群节点上,而其他节点处于空置状态,这样所有的压力将会集中到这单台节点之上。举个例子,新集群由nodel 、node2 、node3 节点组成, 其节点的IP 地址分别为192.168.0.2 、192 .1 68.0.3和192.168 . 0 .4 。当访问http://192.168.0.2:15672 页面时,并上传了原集群的元数据metadata.json,
那么原集群的所有队列将只会在nodel 节点上重新建立:

处理这个问题,有两种方式,都是通过程序(或者脚本)的方式在新集群上建立元数据,而非简单地在页面上上传元数据文件而己。第一种方式是通过HTTP API 接口创建相应的数据。第二种则是通过一个相对完整的Java 程序来处理,这里主要是创建队列、交换器和绑定关系, 而其他内容则忽略。
1.4.2、数据迁移 & 客户端连接切换
首先需要将生产者的客户端与原RabbitMQ 集群的连接断开,然后再与新的集群建立新的连接,这样就可以将新的消息流转入到新的集群中。
之后就需要考虑消费者客户端的事情, 一种是等待原集群中的消息全部消费完之后再将连接断开,然后与新集群建立连接进行消费作业。可以通过Web 页面查看消息是否消费完成,可以参考下图 。也可以通过rabbitmqctl list_queues name messages messages_ready messages_unacknowledged 命令来查看是否有未被消费的消息。
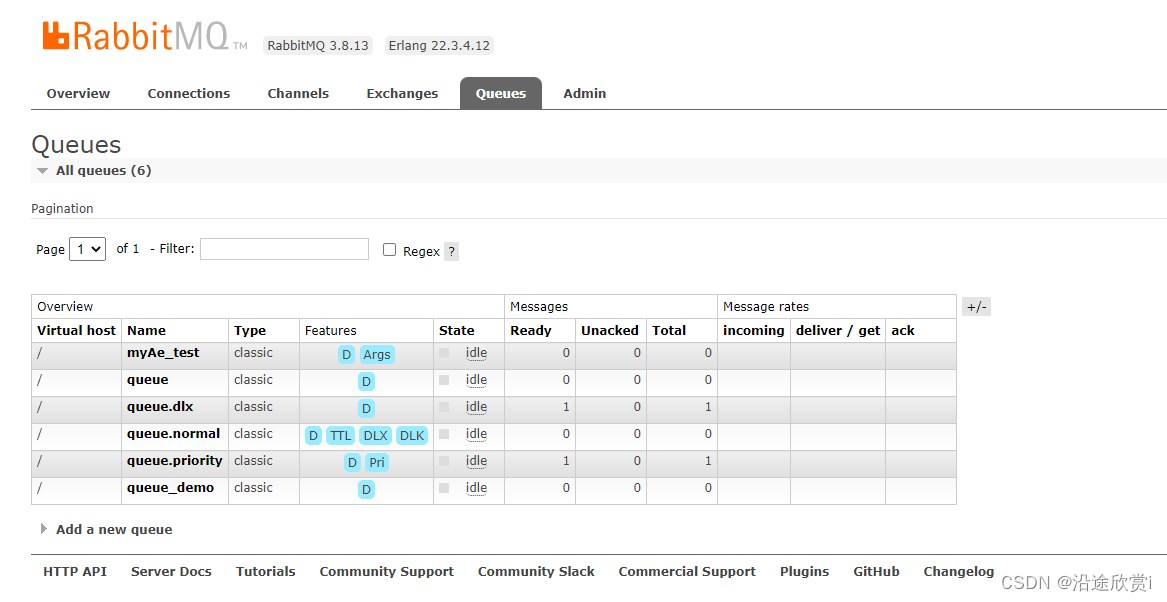
[rabit@myblnp ~]$ sudo rabbitmqctl list_queues name messages messages_ready messages_unacknowledged
Timeout: 60.0 seconds ...
Listing queues for vhost / ...
name messages messages_ready messages_unacknowledged
queue.normal 0 0 0
myAe_test 0 0 0
queue_demo 0 0 0
queue 0 0 0
queue.dlx 1 1 0
queue.priority 1 1 0
[rabit@myblnp ~]$
当原集群服务不可用或者出现故障造成服务质量下降而需要迅速将消息流切换到新的集群中时,此时就不能等待消费完原集群中的消息,这里需要及时将消费者客户端的连接切换到新的集群中,那么在原集群中就会残留部分未被消费的消息,此时需要做进一步的处理。如果原集群损坏,可以等待修复之后将数据迁移到新集群中,否则会丢失数据。
如图所示,数据迁移的主要原理是先从原集群中将数据消费出来,然后存入一个缓存区中,另一个线程读取缓存区中的消息再发布到新的集群中, 如此便完成了数据迁移的动作。作者将此命名为" RabbitMQ ForwardMaker",读者可以自行编写一个小工具来实现这个功能。RabbitMQ 本身提供的Federation 和Shovel 插件都可以实现RabbitMQ ForwardMaker 的功能,确切地说Shovel插件更贴近RabbitMQ ForwardMaker ,详细可以参考后续章节,不过自定义的RabbitMQ ForwardMaker 工具可以让迁移系统更加高效、灵活。

1.4.3、自动化迁移
要实现集群自动化迁移,需要在使用相关资源时就做好一些准备工作,方便在自动化迁移过程中进行无缝切换。与生产者和消费者客户端相关的是交换器、队列及集群的信息,如果这3 种类型的资源发生改变时需要让客户端迅速感知,以便进行相应的处理,则可以通过将相应的资源加载到ZooKeeper 的相应节点中,然后在客户端为对应的资源节点加入watcher 来感知变化,当然这个功能使用 etcd (是一个分布式一致性的 k-v 存储系统,可用于服务注册发现与共享配置)或者集成到公司层面的资源配置中心中会更加标准、高效。如下图所示,将整个RabbitMQ 集群资源的使用分为三个部分:客户端、集群、ZooKeeper配置管理。

在集群中创建元数据资源时都需要在ZooKeeper 中生成相应的配置,比如在cluster1 集群中创建交换器exchange1之后,需要在/rmqNode/exchanges 路径下创建实节点exchange1,并赋予节点的数据内容为:
cluster=cluster1 #表示此交换器所在的集群名称
exchangeType=direct #表示此交换器的类型
vhost=vhost1 #表示此交换器所在的vhost
username=root #表示用户名
password=root123 #表示密码同样,在cluster1集群中创建队列queue1 之后,需要在/rmqNode/queues 路径下创建实节点queuel1,并赋予节点的数据内容为:
cluster=cluster1
bindings=exchange1 #表示此队列所绑定的交换器
#如果有需要,也可以添加一些其他信息,比如路由键等
vhost=vhost1
userni王me=root
password=root123对应集群的数据在/rmqNode/clusters 路径下,比如cluster1 集群,其对应节点的数据内容包含IP 地址列表信息:
ipList=192.168.0.2,192.168.0.3,192.168.0.4 #集群中各个节点的IP 地址信息客户端程序如果与其上的交换器或者队列进行交互,那么需要在相应的ZooKeeper 节点中添加watcher,以便在数据发生变更时进行相应的变更,从而达到自动化迁移的目的。
生产者客户端在发送消息之前需要先连接ZooKeeper ,然后根据指定的交换器名称如exchange1 到相应的路径/rmqNode/exchanges 中寻找exchange1 的节点,之后再读取节点中的数据,井同时对此节点添加watcher。在节点的数据第一条"cluster=cluster1 "中找到交换器所在的集群名称,然后再从路径/rmqNode/clusters 中寻找cluster1节点,然后读取其对应的IP 地址列表信息。这样整个发送端所需要的连接串数据(lp 地址列表、vhost 、usemame 、password 等)都己获取,接下就可以与RabbitMQ 集群clusterl 建立连接然后发送数据了。
对于消费者客户端而言,同样需要连接ZooKeeper,之后根据指定的队列名称(queue1)到相应的路径/rmqNode/queues 中寻找queue1 节点,继而找到相应的连接串,然后与RabbitMQ 集群cluster1建立连接进行消费。当然对/rmqNode/queues/queuel 节点的watcher必不可少。
当cluster1 集群需要迁移到cluster2 集群时,首先需要将cluster1集群中的元数据在cluster2集群中重建。之后通过修改zk 的channel 和queue 的元数据信息,比如原cluster1 集群中有交换器exchange1 、exchange2 和队列queue1 、queue2 ,现在通过脚本或者程序将其中的"cluster=cluster1 " 数据修改为" cluster=cluster2 。客户端会立刻感知节点的变化,然后迅速关闭当前连接之后再与新集群cluster2 建立新的连接后生产和消费消息,在此切换客户端连接的过程中是可以保证数据零丢失的。迁移之后,生产者和消费者都会与cJuster2 集群进行互通,此时原cluster1 集群中可能还有未被消费完的数据,此时需要使用上一节所述的RabbitMQ ForwardMaker 工具将 cluster1 集群中未被消费完的数据同步到cluster2 集群中。
如果没有准备RabbitMQ ForwardMaker 工具,也不想使用Federation 或者Shovel 插件,那么在变更完交换器相关的ZooKeeper 中的节点数据之后,需要等待原集群中的所有队列都消费完全之后,再将队列相关的ZooKeeper 中的节点数据变更,进而使得消费者的连接能够顺利迁移到新的集群之上。可以通过下面的命令来查看是否有队列中的消息未被消费完:
[rabit@myblnp ~]$ sudo rabbitmqctl list_queues -p / -q | awk '{if($2>0) print $0}'
name messages
queue.dlx 1
queue.priority 1
[rabit@myblnp ~]$ 上面的自动化迁移立足于将现有集群迁移到空闲的备份集群,如果由于原集群硬件升级等原因迁移也无可厚非。很多情况下,自动化迁移作为容灾手段中的一种,如果有很多个正在运行的RabbitMQ 集群,为每个集群都配备一个空闲的备份集群无疑是一种资源的浪费。当然可以采取几个集群共用一个备份集群来减少这种浪费,那么有没有更优的解决方案呢?
就以4 个RabbitMQ 集群为例,其被分配4 个独立的业务使用。如图下图所示, cluster1 集群中的元数据备份到cluster2 集群中,而cluster2 集群中的元数据备份到cluster3 集群中,如此可以两两互备。比如在cluster1 集群中创建了一个交换器exchange1,此时需要在cluster2 集群中同样创建一个交换器exchange1 。在正常情况下,使用的是cluster1 集群中的exchange1,而exchange1 在cluster2 集群中只是一份记录,并不消耗cluster2 集群的任何性能。而当需要将cluster1 迁移时,只需要将交换器及队列相对应的ZooKeeper 节点数据项变更即可完成迁移的工作。如此既不用耗费额外的硬件资源,又不用再迁移的时候重新建立元数据信息。

为了更加稳妥起见,也可以准备一个空闲的备份集群以备后用。当cluster1 集群需要迁移到cluster2 集群中时, cluster2 集群己经发生故障被关闭或者被迁移到cluster3 集群中了,那么这个空闲的备份集群可以当作"Plan B" 来增强整体服务的可靠性。如果既想不浪费多余的硬件资源又想具备更加稳妥的措施,可以参考下图 ,将cluster1 中的元数据备份到cluster2 和cluster3 中,这样"以1 备2" 的方式即可解决这个难题。

1.5、集群监控
1.5.1、HTTP API接口监控
假设集群中一共有4 个节点node 1 、node2 、node3 和node4 , 有一个交换器exchange 通过同一个路由键" rk" 绑定了3 个队列queue 1 、queue2 和queue3 。
下面首先收集集群节点的信息, 集群节点的信息可以通过 /api/nodes 接口来获取。有关从 /api/ nodes 接口中获取到数据的结构可以参考附录B ,其中包含了很多的数据统计项,可以挑选感兴趣的内容进行数据收集。
package com.blnp.net.rabbitmq.monitor;
/**
* <p>集群节点信息统计项</p>
*
* @author lyb 2045165565@qq.com
* @createDate 2023/10/30 11:24
*/
public class ClusterNode {
/**
* 磁盘空闲
**/
private long diskFree;
private long diskFreeLimit;
/**
* 句柄使用数
**/
private long fdUsed;
private long fdTotal;
/**
* Socket 使用数
**/
private long socketsUsed;
private long socketsTotal;
/**
* 内存使用值
**/
private long memoryUsed;
private long memoryLimit;
/**
* Erlang 进程使用数
**/
private long procUsed;
private long procTotal ;
@Override
public String toString() {
return " {disk free= " + diskFree + ", " +
"disk free limit=" + diskFreeLimit + ", " +
"fd used=" + fdUsed + ", " +
"fd-total= " + fdTotal + ", " +
"sockets used= " + socketsUsed + ", " +
"sockets total=" + socketsTotal + ", " +
"mem_used=" + memoryUsed + ", " +
"mem_limit= " + memoryLimit + ", " +
"proc used= " + procUsed + ", " +
"proc total=" + procTotal + " } ";
}
public long getDiskFree() {
return diskFree;
}
public void setDiskFree(long diskFree) {
this.diskFree = diskFree;
}
public long getDiskFreeLimit() {
return diskFreeLimit;
}
public void setDiskFreeLimit(long diskFreeLimit) {
this.diskFreeLimit = diskFreeLimit;
}
public long getFdUsed() {
return fdUsed;
}
public void setFdUsed(long fdUsed) {
this.fdUsed = fdUsed;
}
public long getFdTotal() {
return fdTotal;
}
public void setFdTotal(long fdTotal) {
this.fdTotal = fdTotal;
}
public long getSocketsUsed() {
return socketsUsed;
}
public void setSocketsUsed(long socketsUsed) {
this.socketsUsed = socketsUsed;
}
public long getSocketsTotal() {
return socketsTotal;
}
public void setSocketsTotal(long socketsTotal) {
this.socketsTotal = socketsTotal;
}
public long getMemoryUsed() {
return memoryUsed;
}
public void setMemoryUsed(long memoryUsed) {
this.memoryUsed = memoryUsed;
}
public long getMemoryLimit() {
return memoryLimit;
}
public void setMemoryLimit(long memoryLimit) {
this.memoryLimit = memoryLimit;
}
public long getProcUsed() {
return procUsed;
}
public void setProcUsed(long procUsed) {
this.procUsed = procUsed;
}
public long getProcTotal() {
return procTotal;
}
public void setProcTotal(long procTotal) {
this.procTotal = procTotal;
}
}
在真正读取 /api/nodes 接口获取数据之前,我们还需要做一些准备工作,比如使用org.apache.commons.httpclient.HttpClient 对 HTTP GET 方法进行封装,方便后续程序直接调用。
package com.blnp.net.rabbitmq.monitor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.fasterxml.jackson.core.JsonParser;
import org.apache.http.HttpStatus;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import sun.net.www.http.HttpClient;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
/**
* <p></p>
*
* @author lyb 2045165565@qq.com
* @createDate 2023/10/30 11:31
*/
public class HttpUtils {
public static String httpGet(String url, String username, String password) throws Exception {
CredentialsProvider provider = new BasicCredentialsProvider();
provider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
HttpClientBuilder httpClientBuilder = HttpClientBuilder.create();
AuthScope scope = new AuthScope(AuthScope.ANY_HOST, AuthScope.ANY_PORT, AuthScope.ANY_REALM);
UsernamePasswordCredentials credentials = new UsernamePasswordCredentials(username,password);
provider.setCredentials(scope, credentials);
httpClientBuilder.setDefaultCredentialsProvider(provider);
CloseableHttpClient client = httpClientBuilder.build();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse httpResponse = client.execute(httpGet);
int state = httpResponse.getStatusLine().getStatusCode();
String result = "";
//等于200
if (state == HttpStatus.SC_OK) {
InputStream inputStream = httpResponse.getEntity().getContent();
InputStreamReader isr = new InputStreamReader(inputStream);
char[] buffer = new char[1024];
StringBuilder sb = new StringBuilder();
int length = 0;
while ((length = isr.read(buffer)) > 0) {
sb.append(buffer, 0, length);
}
result = sb.toString();
System.out.println("返回的内容:" + result);
JSONArray contentJson = JSONObject.parseArray(result);
System.out.println("contentJson = " + contentJson.toJSONString());
} else {
System.out.println("请求返回的状态值:" + state);
}
return result;
}
public static List<ClusterNode> getClusterData(String ip, int port, String username, String password) {
List<ClusterNode> list = new ArrayList<ClusterNode>();
String url = "http://" + ip + ":" + port + "/api/nodes";
System.out.println(url);
try {
String urlData = HttpUtils.httpGet(url, username, password);
parseClusters(urlData, list) ;
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(list);
return list;
}
private static void parseClusters(String urlData , List<ClusterNode> list) {
JSONArray jsonArray = JSONObject.parseArray(urlData);
for(int i=0; i<jsonArray.size(); i++) {
JSONObject jsonObjectTemp = jsonArray.getJSONObject(i);
ClusterNode cluster = new ClusterNode() ;
cluster.setDiskFree(jsonObjectTemp.getLongValue("disk_free"));
cluster.setDiskFreeLimit(jsonObjectTemp.getLongValue("dlsk_free_limit"));
cluster.setFdUsed(jsonObjectTemp.getLongValue ("fd_used"));
cluster.setFdTotal(jsonObjectTemp.getLongValue("fd_total"));
cluster.setSocketsUsed (jsonObjectTemp.getLongValue("sockets_used"));
cluster.setSocketsTotal(jsonObjectTemp.getLongValue("sockets_total"));
cluster.setMemoryUsed (jsonObjectTemp.getLongValue("mem_used"));
cluster.setMemoryLimit(jsonObjectTemp.getLongValue("mem_limit"));
cluster.setProcUsed(jsonObjectTemp.getLongValue("proc_used"));
cluster.setProcTotal(jsonObjectTemp.getLongValue("proc_total"));
list.add(cluster) ;
}
}
public static void main(String[] args) throws Exception {
System.out.println("请求结果 = " + getClusterData("192.168.56.106",15672,"admin","admin@123"));
}
}
使用的maven依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>elasticsearch-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.bbossgroups.plugins</groupId>
<artifactId>bboss-datatran-jdbc</artifactId>
<version>7.0.8</version>
</dependency>
<dependency>
<groupId>com.bbossgroups.plugins</groupId>
<artifactId>bboss-elasticsearch-spring-boot-starter</artifactId>
<version>7.0.8</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>4.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.79</version>
</dependency>
</dependencies>
</project>
数据来集完之后并没有结束,如下图简单囊括了从数据采集到用户使用的过程。首先采集程序通过定时调用HTTP API 接口获取JSON 数据,然后进行JSON 解析之后再进行持久化处理。对于这种基于时间序列的数据非常适合使用OpenTSDB(基于Hbase 的分布式的,可伸缩的时间序列数据库。主要用途就是做监控系统,比如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储、查询)来进行存储。监控管理系统可以根据用户的检索条件来从OpenTSDB 中获取相应的数据并展示到页面之中。监控管理系统本身还可以具备报表、权限管理等功能,同时也可以实时读取所采集的数据,对其进行分析处理,对于异常的数据需要及时报告给相应的人员。

对于交换器而言的数据采集可以调用 /api/exchanges/vhost/name 接口, 比如需要调用虚拟主机为默认的 "/" 交换器名称为 exchange 的数据, 只需要使用HTTP GET 方法获取 http://xxx.xxx.xxx. xxx :15672/apνexchanges/%2F/exchange 的数据即可。注意, 这里需要将 "/" 进行HTML 转义成" %2F",否则会出错。对应的数据内容可以参考下方:
//单节点Rabbitmq服务返回:
{
"durable": true,
"incoming": [],
"outgoing": [],
"vhost": "/",
"internal": false,
"auto_delete": false,
"name": "exchange.priority",
"arguments": {},
"type": "fanout",
"user_who_performed_action": "admin"
}
//Rabbitmq集群服务返回:
{
"durable": true,
"incoming": [],
"outgoing": [],
"vhost": "/",
"internal": false,
"auto_delete": false,
"name": "dem_exchange",
"arguments": {},
"message_stats": {
"publish_in_details": {
"rate": 0.0 //数据流入的速率
},
"publish_out_details": {
"rate": 0.0 //数据流出的速率
},
"publish_in": 1, //数据流入的总量(条)
"publish_out": 3 //数据流出的总量(条)
},
"type": "direct",
"user_who_performed_action": "myblnp1"
}对于1 个交换器绑定3 个队列的情况,向交换器发送1 条消息,那么流入就是 1 条,而流出就是3 条。在应用的时候根据实际情况挑选数据流入速率或者数据流出速率作为发送数量,以及挑选数据流入的量还是数据流出的量作为发送量。

1.5.2、客户端监控
除了HTTP API 接口可以提供监控数据, Java 版客户端(3. 6.x 版本开始)中Channel 接口中也提供了两个方法来获取数据。方法定义如下:
long messageCount(String queue) throws IOException;
long consumerCount(String queue) throws IOException;messageCount (String queue) 用来查询队列中的消息个数,可以为监控消息堆积的情况提供数据。consumerCount(String queue) 用来查询队列中的消费者个数, 可以为监控消费者的情况提供数据。
除了这两个方法,也可以通过连接的状态进行监控。Java 客户端中Connection 接口提供了addBlockedListener(BlockedListener listener) 方法(用来监昕连接阻塞信息)和addShutdownListener (ShutdownListener listener) 方法(用来监昕连接关闭信息)。相关示例如以下代码所示:
package com.blnp.net.rabbitmq.monitor;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* <p></p>
*
* @author lyb 2045165565@qq.com
* @createDate 2023/10/30 14:26
*/
public class ConnectionMonitor {
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.56.106");
factory.setPort(5672);
factory.setUsername("admin");
factory.setPassword("admin@123");
//创建mq连接
Connection connection = factory.newConnection();
//创建信道
Channel channel = connection.createChannel();
connection.addShutdownListener(new ShutdownListener() {
@Override
public void shutdownCompleted(ShutdownSignalException cause) {
//处理并记录连接关闭事项
}
}) ;
connection.addBlockedListener(new BlockedListener() {
@Override
public void handleBlocked(String s) throws IOException {
//处理并记录连接阻塞事项
}
@Override
public void handleUnblocked() throws IOException {
//处理并记录连接阻塞取消事项
}
});
long msgCount = channel.messageCount( "queue.dlx");
long consumerCount = channel.consumerCount( "queue.dlx") ;
//记录msgCount 和consumerCount
System.out.println("consumerCount = " + consumerCount);
System.out.println("msgCount = " + msgCount);
}
}
用户客户端还可以自行定义一些数据进行埋点,比如客户端成功发送的消息个数和发送失败的消息个数, 进一步可以计算发送消息的成功率等。
package com.blnp.net.rabbitmq.monitor;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.concurrent.TimeoutException;
/**
* <p>自定义埋点数据</p>
*
* @author lyb 2045165565@qq.com
* @createDate 2023/10/30 14:39
*/
public class CustomBurialPoint {
/**
* 记录发送成功的次数
**/
public static volatile int successCount = 0;
/**
* 记录发送失败的次数
**/
public static volatile int failureCount = 0;
public static void main(String[] args) {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.56.106");
factory.setPort(5672);
factory.setUsername("admin");
factory.setPassword("admin@123");
try {
//创建mq连接
Connection connection = factory.newConnection();
//创建信道
Channel channel = connection.createChannel();
//开启确认发送机制
channel.confirmSelect();
channel.addReturnListener(new ReturnListener() {
@Override
public void handleReturn(int replyCode, String replyText, String exchange, String routingKey,
AMQP.BasicProperties basicProperties, byte[] body) throws IOException {
failureCount++;
}
});
channel.basicPublish("","",MessageProperties.PERSISTENT_TEXT_PLAIN,"msg".getBytes(StandardCharsets.UTF_8));
if (channel.waitForConfirms()) {
successCount++;
}else {
failureCount++;
}
}catch (Exception e) {
failureCount++;
}
}
}
上面的代码中只是简单地对successCount 和failureCount 进行累加操作,这里推荐引入metrics 工具(比如com.codahale.metrics.* ) 来进行埋点,这样既方便又高效。同样的方式也可以统计消费者消费成功的条数和消费失败的条数,还可以统计速率。
1.5.3、检测RabbitMQ服务是否健康
不管是通过HTTP API 接口还是客户端,获取的数据都是以作监控视图之用,不过这一切都基于RabbitMQ 服务运行完好的情况下。虽然可以通过某些其他工具或方法来检测RabbitMQ进程是否在运行(如ps aux I grep rabbitmq) ,或者5672 端口是否开启(如telnet xxx.xxx.xxx.xxx 5672) ,但是这样依旧不能真正地评判RabbitMQ 是否还具备服务外部请求的能力。这里就需要使用AMQP 协议来构建一个类似于TCP 协议中的Ping 的检测程序。当这个测试程序与RabbitMQ 服务无法建立TCP 协议层面的连接,或者无法构建AMQP 协议层面的连接,再或者构建连接超时时,则可判定RabbitMQ 服务处于异常状态而无法正常为外部应用提供相应的服务。示例程序如:
package com.blnp.net.rabbitmq.monitor;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.io.IOException;
import java.io.InputStream;
import java.util.Optional;
import java.util.Properties;
import java.util.concurrent.TimeoutException;
/**
* <p>检测RabbitMQ服务是否健康</p>
*
* @author lyb 2045165565@qq.com
* @createDate 2023/10/30 15:11
*/
public class AmqpPing {
private static String host = "192.168.56.119";
private static int port = 5672;
private static String vhost = "/" ;
private static String username = "admin";
private static String password = "admin@123";
static {
Properties properties = new Properties () ;
try {
InputStream resourceAsStream = AmqpPing.class.getClassLoader().getResourceAsStream("rmq_cfg.properties");
if (Optional.ofNullable(resourceAsStream).isPresent()) {
properties.load(AmqpPing.class.getClassLoader().getResourceAsStream( "rmq_cfg.properties")) ;
if (Optional.ofNullable(properties).isPresent()) {
host = properties.getProperty( "host");
port = Integer.valueOf(properties.getProperty( "port"));
vhost = properties . getProperty("vhost");
username = properties . getProperty("username");
password = properties . getProperty("password");
}
}
}catch (Exception e) {
e.printStackTrace();
}
}
public static PING_STATUS checkAmqpPing() {
PING_STATUS pingStatus = PING_STATUS.OK;
ConnectionFactory connectionFactory = new ConnectionFactory() ;
connectionFactory.setHost (host) ;
connectionFactory.setPort(port) ;
connectionFactory.setVirtualHost(vhost);
connectionFactory.setUsername(username) ;
connectionFactory.setPassword(password);
Connection connection = null;
Channel channel = null ;
try {
connection = connectionFactory.newConnection ();
channel = connection.createChannel();
}catch (IOException | TimeoutException e ) {
e.printStackTrace() ;
pingStatus = PING_STATUS.EXCEPTION;
}finally {
if (connection != null) {
try {
connection.close() ;
}catch (IOException e) {
e.printStackTrace();
}
}
}
return pingStatus;
}
public static void main(String[] args) {
System.out.println("checkAmqpPing() = " + checkAmqpPing());
}
}
enum PING_STATUS {
/**
* 服务正常
**/
OK,
/**
* 服务异常
**/
EXCEPTION;
}
示例中涉及 rmq_cfg.properties 配置文件,这个文件用来灵活地配置与RabbitMQ 服务的连接所需的连接信息,包括IP 地址、端口号、vhost、用户名和密码等。如果没有配置相应的项则可以采用默认的值。
监控应用时,可以定时调用AmqpPing.checkAMQPPing() 方法来获取检测信息,方法返回值是一个枚举类型,示例中只具备两个值: PING_STATUS.OK 和PING_STATUS.EXCEPTION,分别代表RabbitMQ 服务正常和异常的情况,这里可以根据实际应用情况来细分返回值的粒度。
AmqpPing 这个类能够检测RabbitMQ 是否能够接收新的请求和构造AMQP 信道,但是要检测RabbitMQ 服务是否健康还需要进一步的措施。值得庆幸的是RabbitMQ Management 插件提供了/api/aliveness-test/vhost 的 HTTP API 形式的接口,这个接口通过3 个步骤来验证RabbitMQ 服务的健康性:
- 创建一个以 "aliveness-test" 为名称的队列来接收测试消息。
- 用队列名称, 即 "aliveness-test" 作为消息的路由键,将消息发往默认交换器。
- 到达队列时就消费该消息,否则就报错。
这个HTTP API 接口背后的检测程序也称之为 aliveness-test,其运行在Erlang 虚拟机内部,因此它不会受到网络问题的影响。如果在虚拟机外部,则网络问题可能会阻止外部客户端连接到RabbitMQ 的5672 端口。aliveness-test 程序不会删除创建的队列,对于频繁调用这个接口的情况,它可以避免数以千计的队列元数据事务对 Mnesia 数据库造成巨大的压力。如果RabbitMQ服务完好,调用 /api/aliveness-test/vhost 接口会返回{"status": "ok"} , HTTP 状态码为200。
package com.blnp.net.rabbitmq.monitor;
import org.apache.http.HttpStatus;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
/**
* <p></p>
*
* @author lyb 2045165565@qq.com
* @createDate 2023/10/30 15:29
*/
public class AlivenessTest {
public static ALIVE_STATUS checkAliveness(String url,String username,String passwd) throws IOException {
ALIVE_STATUS aliveStatus = ALIVE_STATUS.OK;
CredentialsProvider provider = new BasicCredentialsProvider();
provider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, passwd));
HttpClientBuilder httpClientBuilder = HttpClientBuilder.create();
AuthScope scope = new AuthScope(AuthScope.ANY_HOST, AuthScope.ANY_PORT, AuthScope.ANY_REALM);
UsernamePasswordCredentials credentials = new UsernamePasswordCredentials(username,passwd);
provider.setCredentials(scope, credentials);
httpClientBuilder.setDefaultCredentialsProvider(provider);
CloseableHttpClient client = httpClientBuilder.build();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse httpResponse = client.execute(httpGet);
int state = httpResponse.getStatusLine().getStatusCode();
//等于200
if (state == HttpStatus.SC_OK) {
InputStream inputStream = httpResponse.getEntity().getContent();
InputStreamReader isr = new InputStreamReader(inputStream);
char[] buffer = new char[1024];
StringBuilder sb = new StringBuilder();
int length = 0;
while ((length = isr.read(buffer)) > 0) {
sb.append(buffer, 0, length);
}
System.out.println("sb = " + sb.toString());
if (!"{\"status\":\"ok\"}".equals(sb.toString())) {
aliveStatus = ALIVE_STATUS.EXCEPTION;
}
} else {
aliveStatus = ALIVE_STATUS.EXCEPTION;
}
return aliveStatus;
}
public static void main(String[] args) throws IOException {
System.out.println("checkAliveness() = " + checkAliveness("http://192.168.56.119:15672/api/aliveness-test/%2F","admin","admin@123"));
}
}
enum ALIVE_STATUS {
/**
* 服务正常
**/
OK,
/**
* 服务异常
**/
EXCEPTION;
}
这里的 aliveness-test 程序配合前面的AmqpPing 程序一起使用可以从内部和外部这两个方面来全面地监控 RabbitMQ 服务。此外还有另外两个接口 /api/healthchecks/node和 /api/healthchecks/nodes/node , 这两个HTTP API 接口分别表示对当前节点或指定节点进行基本的健康检查,包括RabbitMQ 应用、信道、队列是否运行正常,是否有告警产生等。使用方式可以参考 /api/aliveness-test/vhost , 在此不再赘述。
2、跨越集群的界限
RabbitMQ 可以通过3 种方式实现分布式部署:集群、Federation 和Shovel。这3 种方式不是互斥的,可以根据需要选择其中的一种或者以几种方式的组合来达到分布式部署的目的。Federation 和Shovel 可以为RabbitMQ 的分布式部署提供更高的灵活性,但同时也提高了部署的复杂性。
2.1、Federation
Federation 插件的设计目标是使RabbitMQ 在不同的Broker 节点之间进行消息传递而无须建立集群,该功能在很多场景下都非常有用:
- Federation 插件能够在不同管理域(可能设置了不同的用户和vhost ,也可能运行在不同版本的RabbitMQ 和Erlang 上〉中的Broker 或者集群之间传递消息。
- Federation 插件基于AMQP 0-9-1 协议在不同的Broker 之间进行通信,并设计成能够容忍不稳定的网络连接情况。
- 一个Broker 节点中可以同时存在联邦交换器(或队列)或者本地交换器(或队列),只需要对特定的交换器(或队列)创建Federation 连接 (Federation link ) 。
- Federation 不需要在N 个Broker 节点之间创建O(N^2)个连接(尽管这是最简单的使用方式) ,这也就意味着Federation 在使用时更容易扩展。
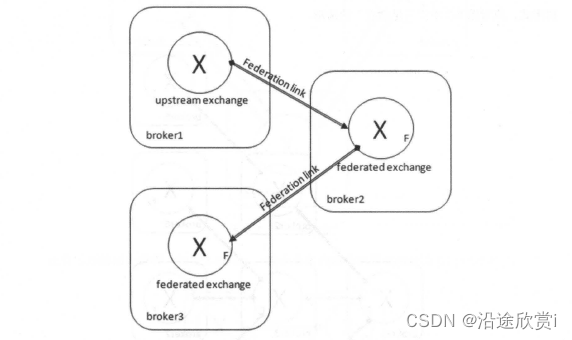
Federation 插件可以让多个交换器或者多个队列进行联邦。一个联邦交换器 (federated exchange) 或者一个联邦队列 (federated queue) 接收上游 (upstream) 的消息,这里的上游是指位于其他Broker 上的交换器或者队列。联邦交换器能够将原本发送给上游交换器 (upstream exchange) 的消息路由到本地的某个队列中;联邦队列则允许一个本地消费者接收到来自上游队列 (upstream queue) 的消息。
2.1.1、联邦交换器
假设图中broker1 部署在北京, broker2 部署在上海,而broker3 部署在广州,彼此之间相距甚远,网络延迟是一个不得不面对的问题。

有一个在广州的业务ClientA需要连接broker3 ,并向其中的交换器exchangeA 发送消息,此时的网络延迟很小, ClientA可以迅速将消息发送至exchangeA 中,就算在开启了publisher confirrn 机制或者事务机制的情况下,也可以迅速收到确认信息。此时又有一个在北京的业务ClientB 需要向exchangeA 发送消息,那么ClientB 与broker3 之间有很大的网络延迟, ClientB将发送消息至exchangeA 会经历一定的延迟,尤其是在开启了publisher confrrrn 机制或者事务机制的情况下, ClientB 会等待很长的延迟时间来接收broker3 的确认信息,进而必然造成这条发送线程的性能降低,甚至造成一定程度上的阻塞。
那么要怎么优化业务ClientB呢?将业务ClientB 部署到广州的机房中可以解决这个问题,但是如果ClientB调用的另一些服务都部署在北京,那么又会引发新的时延问题,总不见得将所有业务全部部署在一个机房,那么容灾又何以实现?这里使用 Federation 插件就可以很好地解决这个问题。
如图下图所示,在broker3 中为交换器exchangeA (broker3 中的队列queueA 通过"rkA"与exchangeA 进行了绑定)与广州的broker1 之间建立一条单向的Federation link。此时Federation插件会在broker1 上会建立一个同名的交换器exchangeA (这个名称可以配置,默认同名),同时建立一个内部的交换器"exchangeA→ broker3 B ",并通过路由键"rkA"将这两个交换器绑定起来。这个交换器 " exchangeA• broker3 B" 名字中的" broker3 "是集群名,可以通过rabbitmqctl set_cluster_name {new name} 命令进行修改。与此同时Federation 插件还会在brokerl 上建立一个队列"federation: exchangeA• broker3 B 飞井与交换器 "exchangeA• broker3 B" 进行绑定。Federation 插件会在队列"federation: exchangeA• broker3 B" 与broker3中的交换器exchangeA 之间建立一条AMQP 连接来实时地消费队列"federation: exchangeA•broker3 B" 中的数据。这些操作都是内部的,对外部业务客户端来说这条Federation link 建立在broker1 的exchangeA 和broker3 的exchangeA 之间。

回到前面的问题,部署在北京的业务ClientB 可以连接broker1 并向exchangeA 发送消息,这样ClientB可以迅速发送完消息并收到确认信息, 而之后消息会通过Federation link 转发到broker3 的交换器exchangeA 中。最终消息会存入与exchangeA 绑定的队列queueA 中,消费者最终可以消费队列queueA 中的消息。经过Federation link 转发的消息会带有特殊的headers 属性标记。例如向broker1 中的交换器exchangeA 发送一条内容为"federation test payload. "的持久化消息,之后可以在broker3 中的队列queueA 中消费到这条消息,详细如下图所示。

Federation 不仅便利于消息生产方,同样也便利于消息消费方。假设某生产者将消息存入broker1 中的某个队列queueB , 在广州的业务ClientC 想要消费queueB 的消息,消息的流转及确认必然要忍受较大的网络延迟,内部编码逻辑也会因这一因素变得更加复杂,这样不利于ClientC 的发展。不如将这个消息转发的过程以及内部复杂的编程逻辑交给Federation 去完成,而业务方在编码时不必再考虑网络延迟的问题。Federation 使得生产者和消费者可以异地部署而又让这两方感受不到过多的差异。
图中broker1 的队列 "federation: exchangeA -> broker3 B " 是一个相对普通的队列,可以直接通过客户端进行消费。假设此时还有一个客户端ClientD 通过 Basic.Consume 来消费队列"federation: exchangeA• broker3 B" 的消息,那么发往broker1 中exchangeA 的消息会有一部分(一半〉被ClientD消费掉,而另一半会发往broker3 的exchangeA。所以如果业务应用有要求所有发往broker1 中exchangeA 的消息都要转发至broker3 的exchangeA 中,此时就要注意队列" federation : exchangeA• broker3 B" 不能有其他的消费者;而对于"异地均摊消费"这种特殊需求,队列"federation: exchangeA• broker3 B" 这种天生特性提供了支持。对于broker1的交换器exchangeA 而言,它是一个普通的交换器,可以创建一个新的队列绑定它,对它的用法没有什么特殊之处。
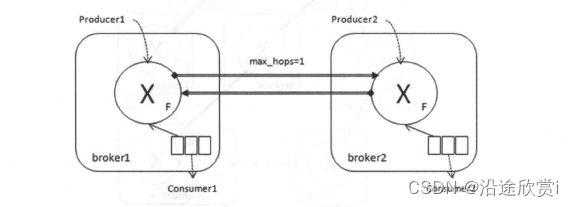
如图8-4 所示, 一个federated exchange 同样可以成为另一个交换器的upstream exchange。同样如图8-5 所示,两方的交换器可以互为federated exchange 和upstream exchange 。其中参数"max_hops=l" 表示一条消息最多被转发的次数为1。
需要特别注意的是,对于默认的交换器(每个vhost 下都会默认创建一个名为""的交换器)和内部交换器而言,不能对其使用 Federation 的功能。对于联邦交换器而言,还有更复杂的拓扑逻辑部署方式。比如图8-6 中"fan-out " 的多叉树形式,或者图8-7 中"三足鼎立"的情形。



2.1.2、联邦队列
除了联邦交换器, RabbitMQ 还可以支持联邦队列(federated queue) 。联邦队列可以在多个Broker 节点(或者集群〉之间为单个队列提供均衡负载的功能。一个联邦队列可以连接一个或者多个上游队列(upstream queue) ,并从这些上游队列中获取消息以满足本地消费者消费消息的需求。
图8-9 演示了位于两个Broker 中的几个联邦队列(灰色〉和非联邦队列(白色) 。队列queue1和queue2 原本在broker2 中,由于某种需求将其配置为federated queue 并将broker1作为upsteam。
Federation 插件会在broker1 上创建同名的队列queue1 和queue2,与broker2 中的队列queue1 和
queue2 分别建立两条单向独立的Federation link 。当有消费者ClinetA连接broker2 并通过Basic.Consume 消费队列queue1 (或queue2) 中的消息时,如果队列queue1 (或queue2) 中本身有若干消息堆积,那么ClientA直接消费这些消息,此时broker2 中的queue1 (或queue2 )并不会拉取broker1中的queue1 (或queue2 ) 的消息:如果队列queue1 (或queue2 ) 中没有消息堆积或者消息被消费完了,那么它会通过Federation link 拉取在broker1 中的上游队列queue1 (或queue2) 中的消息(如果有消息),然后存储到本地,之后再被消费者ClientA进行消费。

消费者既可以消费broker2 中的队列,又可以消费broker1中的队列, Federation 的这种分布式队列的部署可以提升单个队列的容量。如果在broker1 一端部署的消费者来不及消费队列queue1 中的消息,那么broker2 一端部署的消费者可以为其分担消费,也可以达到某种意义上的负载均衡。
和federated exchange 不同, 一条消息可以在联邦队列间转发无限次。如图8-10 中两个队列queue 互为联邦队列。
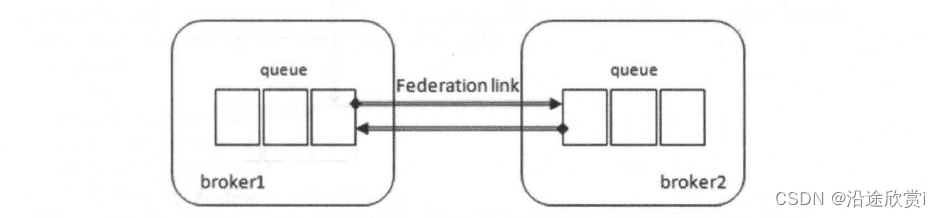
队列中的消息除了被消费,还会转向有多余消费能力的一方,如果这种"多余的消费能力"在broker1 和broker2 中来回切换,那么消费也会在broker1 和broker2 中的队列queue 中来回转发。
可以在其中一个队列上发送一条消息 "msg" , 然后再分别创建两个消费者ClientB 和ClientC分别连接broker1 和broker2 , 并消费队列queue 中的消息,但是并不需要确认消息(消费完消息不需要调用Basic. Ack) 。来回开启/关闭ClientB 和ClientC 可以发现消息" msg"会在broker1和broker2 之间串来串去。
图8 -11 中的broker2 的队列queue 没有消息堆积或者消息被消费完之后并不能通过Basic.Get 来获取broker1 中队列queue 的消息。因为Basic.Get 是一个异步的方法,如果要从broker1 中队列queue 拉取消息,必须要阻塞等待通过Federation link 拉取消息存入broker2 中的队列queue 之后再消费消息,所以对于federated queue 而言只能使用Basic.Consume 进行消费。
federated queue 并不具备传递性。考虑图8 -11 的情形,队列queue2 作为federated queue 与队列queue1 进行联邦,而队列queue2 又作为队列queue3 的upstramqueue ,但是这样队列queue1与queue3 之间并没有产生任何联邦的关系。如果队列queue1 中有消息堆积, 消费者连接broker3消费queue3 中的消息,无论queue3 处于何种状态,这些消费者都消费不到queue1 中的消息,除非queue2 有消费者。

注意要点:理论上可以将一个federated queue 与一个federated exchange 绑定起来,不过这样会导致一些不可预测的结果,如果对结果评估不足,建议慎用这种搭配方式.
2.1.3、Federation 的使用
为了能够使用Federation 功能, 需要配置以下2 个内容:
- 需要配置一个或多个 upstream ,每个upstream 均定义了到其他节点的Federation link。这个配置可以通过设置运行时的参数( Runtime Parameter ) 来完成,也可以通过federation management 插件来完成。
- 需要定义匹配交换器或者队列的一种/多种策略( Policy ) 。
Federation 插件默认在RabbitMQ 发布包中,执行rabbitmq-plugins enable rabbitmq_federation 命令可以开启Federation 功能,示例如下:
[rabbit@myblnp1 ~]$ rabbitmq-plugins enable rabbitmq_federation
Enabling plugins on node rabbit@myblnp1:
rabbitmq_federation
The following plugins have been configured:
rabbitmq_federation
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@myblnp1...
The following plugins have been enabled:
rabbitmq_federation
started 1 plugins.
[rabbit@myblnp1 ~]$
特别说明:当需要在集群中使用Federation 功能的时候,集群中所有的节点都应该开启Federation 插件
根据前面的讲解可知, Federation 内部基于AMQP 协议拉取数据,所以在开启rabbitmq_federation 插件的时候,默认会开启 amqp_client 插件。同时,如果要开启Federation 的管理插件,需要执行rabbitmq-plugins enable rabbitmq_federation_management 命令, 示例如下:
[rabbit@myblnp1 ~]$ rabbitmq-plugins enable rabbitmq_federation_management
Enabling plugins on node rabbit@myblnp1:
rabbitmq_federation_management
The following plugins have been configured:
rabbitmq_federation
rabbitmq_federation_management
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@myblnp1...
The following plugins have been enabled:
rabbitmq_federation_management
started 1 plugins.
[rabbit@myblnp1 ~]$
开启 rabbitmq_federation_management 插件之后,在RabbitMQ 的管理界面中 "Admin" 的右侧会多出"Federation Status" 和"Federation Upstreams" 两个Tab 页,如图:

rabbitmq_federation_management 插件依附于rabbitmq_management 插件,所以开启rabbitmq_federation_management 插件的同时默认也会开启rabbitmq_management 插件。
有关Federation upstream 的信息全部都保存在RabbitMQ 的Mnesia 数据库中,包括用户信息、权限信息、队列信息等。在Federation 中存在3 种级别的配置。
- Upstreams: 每个upstream 用于定义与其他Broker 建立连接的信息。
- Upstream sets: 每个upstream set 用于对一系列使用Federation 功能的upstream 进行分组。
- Policies: 每一个Policy 会选定出一组交换器,或者队列,亦或者两者皆有而进行限定,进而作用于一个单独的 upsteam 或者upstream set 之上。
实际上,在简单使用场景下,基本上可以忽略 upstream set 的存在,因为存在一种名为" all"并且隐式定义的 upstream set ,所有的 upstream 都会添加到这个set 之中。Upstreams 和Upstream sets 都属于运行时参数,就像交换器和队列一样,每个vhost 都持有不同的参数和策略的集合。
Federation 相关的运行时参数和策略都可以通过下面3 种方式进行设置:
- 通过rabbitmqctl 工具。
- 通过RabbitMQ Management 插件提供的HTTP API 接口
- 通过 rabbitmq_federation_management 插件提供的Web 管理界面的方式(最方便且通用)。不过基于Web 管理界面的方式不能提供全部功能,比如无法针对 upstream set 进行管理。
下面就详细讲解如何正确地使用 Federation 插件,首先以 broker1 ( IP 地址:192.168.56.119)和broker2 (IP 地址: 192 .1 68.56.120)的关系来讲述如何建立federated exchange 。
第一步:
需要在broker1 和broker2 中开启rabbitmq_federation 插件,最好同时开启rabbitmq_federation_management 插件。


第二步:
在broker2 中定义一个upstream。
##第一种方式:通过rabbitmqctl 工具的方式,详细如下:
[rabbit@myblnp2 ~]$ rabbitmqctl set_parameter federation-upstream f1 '{"uri":"amqp://root:root123@192.168.56.119:5672","ack-mode":"on-confirm"}'
Setting runtime parameter "f1" for component "federation-upstream" to "{"uri":"amqp://root:root123@192.168.56.119:5672","ack-mode":"on-confirm"}" in vhost "/" ...
[rabbit@myblnp2 ~]$
##第二种方式:通过调用HTTP API 接口的方式,详细如下:
[rabbit@myblnp2 ~]$ curl -i -u root:root123 -XPUT -d '{"value":{"uri":"amqp://root:root123@192.168.56.119:5672","ack-mode":"on-confirm"}}' http://192.168.56.120:15672/api/parameters/federation-upstream/%2F/f2
HTTP/1.1 201 Created
content-length: 0
content-security-policy: script-src 'self' 'unsafe-eval' 'unsafe-inline'; object-src 'self'
date: Tue, 31 Oct 2023 06:38:37 GMT
server: Cowboy
vary: accept, accept-encoding, origin
[rabbit@myblnp2 ~]$
##第三种方式:通过在Web 管理界面中添加的方式,在"Admin" → "Pederation Upstreams" -> "Add a new upstream" 中创建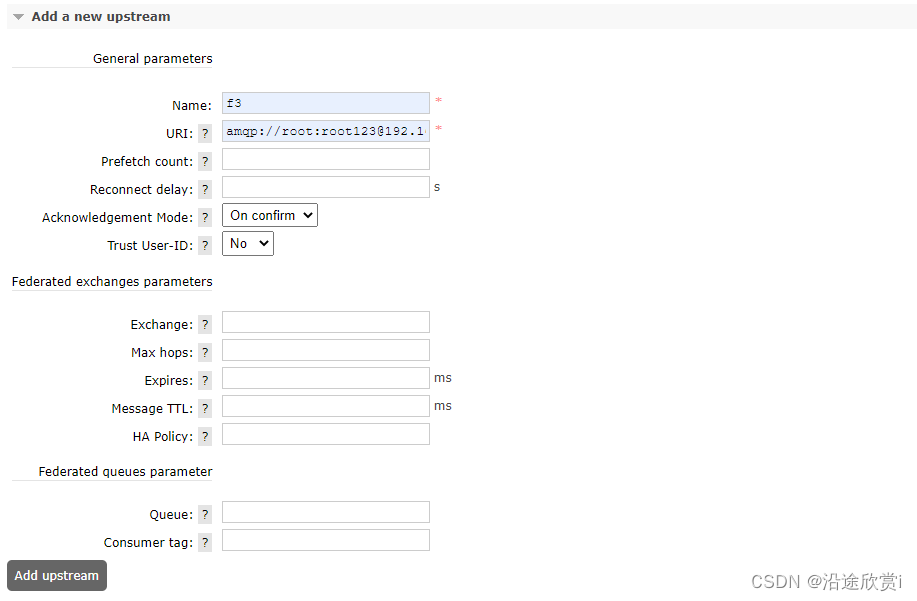

通用的参数如下所示:
- Name: 定义这个upstream 的名称。必填项。
- URI (uri): 定义upstream 的AMQP 连接。必填项。本示例中可以填写为:amqp://root:root123@192.168.56.119:5672
- Prefetch count (prefetch_count): 定义Federation 内部缓存的消息条数,即在收到上游消息之后且在发送到下游之前缓存的消息条数。
- Reconnect delay (reconnect-delay): Federation link 由于某种原因断开之后,需要等待多少秒开始重新建立连接。
- Acknowledgement Mode (ack-mode): 定义Federation link 的消息确认方式。其有3 种: on-confirm 、on-publish 、no-acko 默认为on-confirm ,表示在接收到下游的确认消息(等待下游的Basic.Ack) 之后再向上游发送消息确认,这个选项可以确保网络失败或者Broker 宕机时不会丢失消息,但也是处理速度最慢的选项。如果设置为on-publish ,则表示消息发送到下游后(并需要等待下游的Basic.Ack)再向上游发送消息确认,这个选项可以确保在网络失败的情况下不会丢失消息,但不能
- 确保Broker 岩机时不会丢失消息。no - ack 表示无须进行消息确认,这个选项处理速度最快,但也最容易丢失消息。
- Trust User-ID (trust-user-id): 设定Federation 是否使用"Validated User-ID" 这个功能。如果设置为false 或者没有设置,那么Federation 会忽略消息的user_id 这个属性;如果设置为true ,则Federation 只会转发user_id 为上游任意有效的用户的消息。
所谓的 "Validated User-ID" 功能是指发送消息时验证消息的user_id 的属性,在前面章节中讲到channel.basicPublish 方法中有个参数是BasicProperties ,这个BasicProperties 类中有个属性为userld。可以通过如下的方法设置消息的user_id 属性为 "root":
AMQP.BasicProperties properties = new AMQP.BasicProperties();
properties.setUserId("root");
channel.basicPublish("amq.fanout", "", properties, "test user id".getBytes());如果在连接Broker 时所用的用户名为"root",当发送"test user id"这条消息时设置的user_id的属性为"guest",那么这条消息会发送失败, 具体报错为406 PRECONDITION FAILED - user id property set to 'guest' but authenticated user was 'root' ,只有当user_id 设置为"root" 时这条消息才会发送成功。
只适合Federation Exchange的参数:
- Exchange (exchange): 指定upstream exchange 的名称,默认情况下和federated exchange 同名,即图8-2 中的exchangeA 。
- Max hops (max-hops): 指定消息被丢弃前在Federation link 中最大的跳转次数。默认为1 。注意即使设置max-hops 参数为大于1 的值,同一条消息也不会在同一个Broker中出现2 次,但是有可能会在多个节点中被复制。
- Expires (expires): 指定Federation link 断开之后, federated queue 所对应的upstream queue( 即图8-2 中的队列"federation: exchangeA• broker3 B") 的超时时间,默认为"none" ,表示为不删除,单位为ms 。这个参数相当于设置普通队列的x-expires 参数。设置这个值可以避免Federation link 断开之后,生产者一直在向broker1中的exchangeA 发送消息,这些消息又不能被转发到broker3 中而被消费掉,进而造成broker1中有大量的消息堆积。
- Message TTL (message-ttl): 为federated queue 所对应的 upstream queue (即图8-2 中的队列 "federation: exchangeA• broked B ")设置,相当于普通队列的 x-message-ttl 参数。默认为"none" 表示消息没有超时时间。
- HA policy (ha-policy): 为federated queue 所对应的upstream queue (即图8-2 中的队列 "federation: exchangeA• broker3 B" ) 设置,相当于普通队列的x-ha-policy参数,默认为"none飞表示队列没有任何HA 。
只适合Federation Queue的参数:
- Queue (queue) :执行upstream queue 的名称,默认情况下和federated queue 同名,可以参考图8-10 中的queue 。
- Consurm tag(consurm-tag):从上游消费时使用的消费者标签。可选的。
第三步:
定义一个Policy 用于匹配交换器exchangeA,并使用第二步中所创建的upstream 。
##第一种方式:通过rabbitmqctl 工具的方式,如下(定义所有以"exchange" 开头的交换器作为federated exchange):
[rabbit@myblnp2 ~]$ rabbitmqctl set_policy --apply-to exchanges p1 "^exchange" '{"federation-upstream":"f1"}'
Setting policy "p1" for pattern "^exchange" to "{"federation-upstream":"f1"}" with priority "0" for vhost "/" ...
[rabbit@myblnp2 ~]$
##第二种方式:是通过HTTP API 接口的方式
[rabbit@myblnp2 ~]$ curl -i -u root:root123 -XPUT -d '{"pattern":"^f2_","definition":{"federation-upstream":"f2"},"apply-to":"exchanges"}' http://192.168.56.120:15672/api/policies/%2F/p2
HTTP/1.1 201 Created
content-length: 0
content-security-policy: script-src 'self' 'unsafe-eval' 'unsafe-inline'; object-src 'self'
date: Tue, 31 Oct 2023 07:11:16 GMT
server: Cowboy
vary: accept, accept-encoding, origin
[rabbit@myblnp2 ~]$
##第三种方式:在Web 管理界面中添加的方式,在"Admin " → "Policies" → "Add/update a policy" 中创建

Federation Upstream:

Policies:

Federation Status:

这样就创建了一个Federation link ,可以在Web 管理界面中" Admin" → "Federation Status" -> "Running Links" 查看到相应的链接。还可以通过rabbitmqctl eval 'rabbit_federation_status:status().' 命令来查看相应的Federation link。示例如下:
[rabbit@myblnp1 ~]$ rabbitmqctl eval 'rabbit_federation_status:status().'
[[{exchange,<<"exchange_de">>},
{upstream_exchange,<<"exchange_de">>},
{type,exchange},
{vhost,<<"/">>},
{upstream,<<"f1">>},
{id,<<"b3047226">>},
{status,running},
{local_connection,<<"<rabbit@myblnp1.1698731305.5662.0>">>},
{uri,<<"amqp://192.168.56.119:5672">>},
{timestamp,{{2023,10,31},{15,7,37}}}]]
[rabbit@myblnp1 ~]$
特别说明:Federation Link 当匹配有对应策略后,在 Federation status 里才会有具体数据
对于federated queue 的建立,首先同样也是定义一个upstream。之后定义Policy 的时候略微有变化,比如使用rabbitmqctl 工具的情况(定义所有以"queue" 开头的队列作为federated queue ) :
rabbitmqctl set_policy --apply-to queues p2 "^queue" '{"federation-upstream":"f1"}'通常情况下,针对每个upstream 都会有一条Federation link , 该Federation link 对应到一个交换器上。例如, 3 个交换器与2 个upstream 分别建立Federation link 的情况下,会有6条连接。
2.2、Shovel
与Federation 具备的数据转发功能类似,Shovel 能够可靠、持续地从一个Broker 中的队列(作为源端,即source )拉取数据并转发至另一个Broker 中的交换器(作为目的端,即destination )。作为源端的队列和作为目的端的交换器可以同时位于同一个Broker 上,也可以位于不同的Broker 上。Shovel 可以翻译为"铲子",是一种比较形象的比喻,这个" 铲子"可以将消息从一方"挖到"另一方。Shovel 的行为就像优秀的客户端应用程序能够负责连接源和目的地、负责消息的读写及负责连接失败问题的处理。Shovel 的主要优势在于:
- 松耦合:Shovel 可以移动位于不同管理域中的Broker (或者集群)上的消息,这些Broker (或者集群〉可以包含不同的用户和 vhost ,也可以使用不同的RabbitMQ 和Erlang 版本。
- 支持广域网:Shovel 插件同样基于AMQP 协议在Broker 之间进行通信, 被设计成可以容忍时断时续的连通情形, 并且能够保证消息的可靠性。
- 高度定制:当Shovel 成功连接后,可以对其进行配置以执行相关的AMQP 命令。
2.2.1、Shovel 的原理
图8-15 展示的是Shovel 的结构示意图。这里一共有两个Broker:broker1(IP 地址:192.168.56.119) 和broker2 (lp 地址: 192.168.56.120)。 broker1 中有交换器 dexchange1 和队列queue1 ,且这两者通过路由键"rk1 "进行绑定; broker2 中有交换器 dexchange2 和队列queue2 ,且这两者通过路由键"rk2 "进行绑定。在队列 queue1 和交换器exchange2 之间配置一个Shovel link , 当一条内容为 "shovel test payload" 的消息从客户端发送至交换器exchange1 的时候,这条消息会经过图8-15中的数据流转最后存储在队列queue2 中。如果在配置Shovel link 时设置了
add-forward-headers 参数为true ,则在消费到队列queue2 中这条消息的时候会有特殊的 headers 属性标记,详细内容可参考图8-16。


通常情况下,使用Shovel 时配置队列作为源端,交换器作为目的端,就如图8-15 一样。同样可以将队列配置为目的端,如图8-17 所示。虽然看起来队列queue1 是通过Shovel link 直接将消息转发至queue2 的, 其实中间也是经由broker2 的交换器转发, 只不过这个交换器是默认的交换器而己。
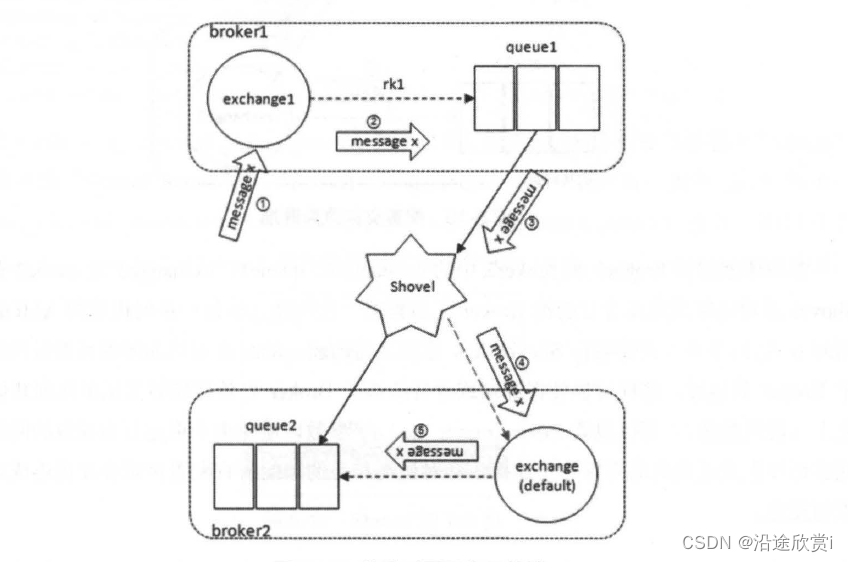
如图8-18 所示,配置交换器为源端也是可行的。虽然看起来交换器 exchange1 是通过Shovel link 直接将消息转发至exchange2 上的,实际上在broker1 中会新建一个队列(名称由RabbitMQ自定义,比如图8-18 中的"amq.gen-ZwolUsoUchY6a7xaPyrZZH") 并绑定exchange1,消息从交换器exchange1 过来先存储在这个队列中,然后Shovel 再从这个队列中拉取消息进而转发至交换器exchange2 。

前面所阐述的broker1 和broker2 中的exchange1、queue1、exchange2 及queue2 都可以在
Shovel 成功连接源端或者目的端Broker 之后再第一次创建(执行一系列相应的AMQP 配置声明时),它们并不一定需要在Shovel link 建立之前创建。Shovel 可以为源端或者目的端配置多个Broker 的地址,这样可以使得源端或者目的端的Broker 失效后能够尝试重连到其他Broker之上(随机挑选) 。可以设置reconnect delay 参数以避免由于重连行为导致的网络泛洪,或者可以在重连失败后直接停止连接。针对源端和目的端的所有配置声明会在重连成功之后被重新发迭。
2.2.2、Shovel 的使用
Shovel 插件默认也在RabbitMQ 的发布包中,执行rabbitmq-plugins enable rabbitmq_shovel 命令可以开启Shovel 功能, 示例如下:
[rabbit@myblnp1 ~]$ rabbitmq-plugins enable rabbitmq_shovel
Enabling plugins on node rabbit@myblnp1:
rabbitmq_shovel
The following plugins have been configured:
rabbitmq_federation
rabbitmq_federation_management
rabbitmq_management
rabbitmq_management_agent
rabbitmq_shovel
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@myblnp1...
The following plugins have been enabled:
rabbitmq_shovel
started 1 plugins.
[rabbit@myblnp1 ~]$
由前面的讲解可知, Shovel 内部也是基于AMQP 协议转发数据的, 所以在开启rabbitmq_shovel 插件的时候, 默认也会开启amqp_client 插件。同时,如果要开启Shovel的管理插件, 需要执行rabbitmq-plugins enable rabbitmq_shovel_management 命令, 示例如下:
[rabbit@myblnp1 ~]$ rabbitmq-plugins enable rabbitmq_shovel_management
Enabling plugins on node rabbit@myblnp1:
rabbitmq_shovel_management
The following plugins have been configured:
rabbitmq_federation
rabbitmq_federation_management
rabbitmq_management
rabbitmq_management_agent
rabbitmq_shovel
rabbitmq_shovel_management
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@myblnp1...
The following plugins have been enabled:
rabbitmq_shovel_management
started 1 plugins.
[rabbit@myblnp1 ~]$ 
开启 rabbitmq_shovel_management 插件之后, 在RabbitMQ 的管理界面中" Admin "的右侧会多出"Shovel Status" 和" Shovel Management " 两个Tab 页,如上图所示。rabbitmq_shovel_management 插件依附于rabbitmq management 插件, 所以开启rabbitmq_shovel_management 插件的同时默认也会开启rabbitmq_management 插件。
Shovel 既可以部署在源端,也可以部署在目的端。有两种方式可以部署Shovel: 静态方式(static)和动态方式(dynamic)。静态方式是指在rabbitmq.config(3.8.16版本是在:advanced.config.example) 配置文件中设置,而动态方式是指通过Runtime Parameter 设置。
静态方式:
在rabbitmq.config 配置文件中针对Shove1 插件的配置信息是一种Erlang 项式,由单条Shove1 条目构成 (shovels 部分的下一层) :
{rabbitmq_shovel , [ {shovels , [ {shovel_name, [ . .. ]} , ... ]} ]}每一条Shove1 条目定义了源端与目的端的转发关系,其名称 (shove1 name ) 必须是独一无二的。每一条Shove1 的定义都像下面这样:
{defaults, [{prefetch_count, 0},
{ack_mode, on_confirm},
{publish_fields, []},
{publish_properties, [{delivery_mode, 2}]},
…………
{reconnect_delay, 2.5}]}完整配置示例如下所示:
{rabbitmq_shovel,
[{shovels,
[%% A named shovel worker.
%% {my_first_shovel,
%% [
%% List the source broker(s) from which to consume.
%%
%% {sources,
%% [%% URI(s) and pre-declarations for all source broker(s).
%% {brokers, ["amqp://user:password@host.domain/my_vhost"]},
%% {declarations, []}
%% ]},
%% List the destination broker(s) to publish to.
%% {destinations,
%% [%% A singular version of the 'brokers' element.
%% {broker, "amqp://"},
%% {declarations, []}
%% ]},
%% Name of the queue to shovel messages from.
%%
%% {queue, <<"your-queue-name-goes-here">>},
%% Optional prefetch count.
%%
%% {prefetch_count, 10},
%% when to acknowledge messages:
%% - no_ack: never (auto)
%% - on_publish: after each message is republished
%% - on_confirm: when the destination broker confirms receipt
%%
%% {ack_mode, on_confirm},
%% Overwrite fields of the outbound basic.publish.
%%
%% {publish_fields, [{exchange, <<"my_exchange">>},
%% {routing_key, <<"from_shovel">>}]},
%% Static list of basic.properties to set on re-publication.
%%
%% {publish_properties, [{delivery_mode, 2}]},
%% The number of seconds to wait before attempting to
%% reconnect in the event of a connection failure.
%%
%% {reconnect_delay, 2.5}
%% ]} %% End of my_first_shovel
]}
%% Rather than specifying some values per-shovel, you can specify
%% them for all shovels here.
%%
%% {defaults, [{prefetch_count, 0},
%% {ack_mode, on_confirm},
%% {publish_fields, []},
%% {publish_properties, [{delivery_mode, 2}]},
%% {reconnect_delay, 2.5}]}
]},其中broker 项配置的是URI , 定义了用于连接Shovel 两端的服务器地址、用户名、密码、vhost 和端口号等。如果sources 或者destinations 是RabbitMQ 集群,那么就使用brokers ,并在其后用多个URI 字符串以" []"的形式包裹起来,比如 {brokers, ["amqp://root:root123@192.168.56.119:5672", "amqp://root:root123@192.168.56.120:5672" ]} ,这样的定义能够使得Shovel 在主节点故障时转移到另一个集群节点上。
declarations 这一项是可选的, declaration list 指定了可以使用的AMQP 命令的列表,声明了队列、交换器和绑定关系。比如代码示例中sources 的declarations 这一项声明了队列queue1 ('queue.declare')、 交换器 exchange1 ('exchange. declare' )及其之间的绑定关系( 'queue.bind' )。注意其中所有的字符串井不是简单地用引号标注,而是同时用双尖括号包裹,比如<<"queue1">> 。这里的双尖括号是要让ErLang 程序不要将其视为简单的字符串,而是binary 类型的字符串。如果没有双尖括号包裹,那么Shovel 在启动的时候就会出错。与queue1 一起的还有一个durable 参数,它不需要像其他参数一样需要包裹在大括号内,这是因为像durable 这种类型的参数不需要赋值,它要么存在,要么不存在,只有在参数需要赋值的时候才需要加上大括号。
与sources 和destinations 同级的queue 表示源端服务器上的队列名称。可以将queue 设置为"<<>>",表示匿名队列(队列名称由RabbitMQ 自动生成, 参考图8-18 中broker1的队列) 。
prefetch_count 参数表示Shovel 内部缓存的消息条数,可以参考Federation 的相关参数。ShoveL 的内部缓存是源端服务器和目的端服务器之间的中间缓存部分。
ack_mode 表示在完成转发消息时的确认模式,和Federation 的ack mode 一样也有三种取值:
- no ack 表示无须任何消息确认行为;
- on publish 表示Shovel 会把每一条消息发送到目的端之后再向源端发送消息确认;
- on confirm 表示Shovel 会使用publisher confmn 机制,在收到目的端的消息确认之后再向源端发送消息确认。
ShoveL 的ack mode 默认也是on confirm ,并且官方强烈建议使用该值。如果选择使用其他值,整体性能虽然会有略微提升,但是发生各种失效问题的情况时,消息的可靠性得不到保障。
publish_properties 是指消息发往目的端时需要特别设置的属性列表。默认情况下,被转发的消息的各个属性是被保留的,但是如果在publish_properties 中对属性进行了设置则可以覆盖原先的属性值。publish properties 的属性列表包括content_type 、content_encoding 、headers 、delivery_mode 、priority 、correlation_id 、reply_to 、expiration 、message_id 、timestamp 、type 、user id 、app_id 和 cluster_id 。
add_forward_headers 如果设置为true ,则会在转发的消息内添加x-shovelled 的header 属性
publish_fields 定义了消息需要发往目的端服务器上的交换器以及标记在消息上的路由键。如果交换器和路由键没有定义,则Shovel 会从原始消息上复制这些被忽略的设置。
reconnect_delay 指定在Shovel link 失效的情况下,重新建立连接前需要等待的时间,单位为秒。如果设置为0 ,则不会进行重连动作,即Shovel 会在首次连接失效时停止工作。reconnect_delay 默认为5 秒。
动态方式:
与Federation upstream 类似, Shovel 动态部署方式的配置信息会被保存到RabbitMQ 的Mnesia 数据库中,包括权限信息、用户信息和队列信息等内容。每一个Shovel link 都由一个相应的Parameter 定义,这个Parameter 同样可以通过rabbitmqctl 工具、RabbitMQ Management 插件的HTTP API 接口或者rabbitmq_shovel_management 提供的Web 管理界面的方式设置。
##第一种方式:通过rabbitmqctl 工具的方式
[rabbit@myblnp2 ~]$ rabbitmqctl set_parameter shovel hidden_shovel \
> '{"src-uri":"amqp://root:root123@192.168.56.119:5672","src-queue":"queue1","dest-uri":"amqp://root:root123@192.168.56.121:5672","src-exchange-key":"rk1","prefetch-count":64,"reconnect-delay":5,"publish-properties":[],"add-forward-headers":true,"ack-mode":"on-confirm"}'
Setting runtime parameter "hidden_shovel" for component "shovel" to "{"src-uri":"amqp://root:root123@192.168.56.119:5672","src-queue":"queue1","dest-uri":"amqp://root:root123@192.168.56.121:5672","src-exchange-key":"rk1","prefetch-count":64,"reconnect-delay":5,"publish-properties":[],"add-forward-headers":true,"ack-mode":"on-confirm"}" in vhost "/" ...
[rabbit@myblnp2 ~]$
##第二种方式:通过HTTP API方式
[rabbit@myblnp2 ~]$ curl -i -u root:root123 -XPUT -d '{"value":{"src-uri":"amqp://root:root123@192.168.56.119:5672","src-queue":"queue1","dest-uri":"amqp://root:root123@192.168.56.121:5672","src-exchange-key":"rk1","prefetch-count":64,"reconnect-delay":5,"publish-properties":[],"add-forward-headers":true,"ack-mode":"on-confirm"}}' http://192.168.56.120:15672/api/parameters/shovel/%2F/hidden_shovel
HTTP/1.1 204 No Content
content-security-policy: script-src 'self' 'unsafe-eval' 'unsafe-inline'; object-src 'self'
date: Tue, 31 Oct 2023 09:38:02 GMT
server: Cowboy
vary: accept, accept-encoding, origin
[rabbit@myblnp2 ~]$
第三种是通过Web 管理界面中添加的方式,在"Admin" → "Shovel Management" --> "Add
a new shovel" 中创建:

在创建了一个Shovel link 之后, 可以在Web 管理界面中"Admin " → "Shovel Status" 中查看到相应的信息, 也可以通过rabbitmqctl eval 'rabbit_shovel_status:status().' 命令直接查询Shovel 的状态信息, 该命令会调用rabbitmq shovel 插件模块中的status 方法,该方法将返回一个Erlang 列表, 其中每一个元素对应一个己配直好的Shovel。示例如下:
[rabbit@myblnp2 ~]$ rabbitmqctl eval 'rabbit_shovel_status:status().'
[{{<<"/">>,<<"hidden_shovel">>},
dynamic,
{running,[{src_uri,<<"amqp://192.168.56.119:5672">>},
{src_protocol,<<"amqp091">>},
{dest_protocol,<<"amqp091">>},
{dest_uri,<<"amqp://192.168.56.121:5672">>},
{src_queue,<<"queue1">>}]},
{{2023,10,31},{17,27,21}}}]
[rabbit@myblnp2 ~]$
列表中的每一个元素都以一个四元组的形式构成: {Name , Type , Status , Timestamp} 。具体含义如下:
- Name 表示Shovel 的名称。
- Type 表示类型,有2 种取值一-static 和dynamic 。
- Status 表示目前Shovel 的状态。当Shovel 处于启动、连接和创建资源时状态为 starting; 当Shovel 正常运行时是 running;当Shovel 终止时是terminated 。
- Timestamp 表示该Shovel 进入当前状态的时间戳,具体格式是{{YYYY,MM,DD } I {HH,MM,SS}}。
2.2.3、案例:消息堆积的治理
消息堆积是在使用消息中间件过程中遇到的最正常不过的事情。消息堆积是一把双刃剑,适量的堆积可以有削峰、缓存之用,但是如果堆积过于严重,那么就可能影响到其他队列的使用,导致整体服务质量的下降。对于一台普通的服务器来说,在一个队列中堆积1 万至10 万条消息,丝毫不会影响什么。但是如果这个队列中堆积超过1 千万乃至一亿条消息时,可能会引起一些严重的问题,比如引起内存或者磁盘告警而造成所有Connection 阻塞。
消息堆积严重时,可以选择清空队列,或者采用空消费程序丢弃掉部分消息。不过对于重要的数据而言,丢弃消息的方案并无用武之地。另一种方案是增加下游消费者的消费能力,这个思路可以通过后期优化代码逻辑或者增加消费者的实例数来实现。但是后期的代码优化在面临紧急情况时总归是"远水解不了近渴",并且有些业务场景也井非可以简单地通过增加消费实例而得以增强消费能力。
在一筹莫展之时,不如试一下Shovel 。当某个队列中的消息堆积严重时,比如超过某个设定的阑值,就可以通过Shovel 将队列中的消息移交给另一个集群。
如图8-21 所示,这里有如下几种情形。
情形1 :当检测到当前运行集群cluster1 中的队列queue1 中有严重消息堆积,比如通过 /api/queues/vhost/name 接口获取到队列的消息个数(messages) 超过2 千万或者消息占用大小(messages bytes) 超过10GB 时,就启用shovel1 将队列queue1中的消息转发至备份集群cluster2 中的队列queue2 。
情形2: 紧随情形1,当检测到队列queue1 中的消息个数低于 1 百万或者消息占用大小低于1GB 时就停止shovel1 ,然后让原本队列queue1 中的消费者慢慢处理剩余的堆积。
情形3: 当检测到队列queue1 中的消息个数低于10 万或者消息占用大小低于100 MB时,就开启shove12 将队列queue2 中暂存的消息返还给队列queue1 。
情形4: 紧随情形3 ,当检测到队列queue1 中的消息个数超过 1 百万或者消息占用大小高于1GB 时就将shove12 停掉。
2.3、小结
上一章节一直在讲述的一种部署方式,也是最为通用的一种方式。集群将多个Broker 节点连接起来组成逻辑上独立的单个Broker。集群内部借助Erlang 进行消息传输,所以集群中的每个节点的Erlang cookie 务必要保持一致。同时,集群内部的网络必须是可靠的,RabbitMQ 和Erlang 的版本也必须一致。虚拟主机、交换器、用户、权限等都会自动备份到集群中的各个节点。队列可能部署单个节点或被镜像到多个节点中。连接到任意节点的客户端能够看到集群中所有的队列,即使该队列不在所连接的节点之上。通常使用集群的部署方式来提高可靠性和吞吐量,不过集群只能部署在局域网内。
Federation ,可以翻译为"联邦"。 Federation 可以通过AMQP 协议(可配置SSL)让原本发送到某个Broker (或集群〉中的交换器(或队列)上的消息能够转发到另一个Broker (或集群)中的交换器(或队列)上,两方的交换器(或队列〉看起来是以一种"联邦"的形式在运作。当然必须要确保这些"联邦"的交换器或者队列都具备合适的用户和权限。
联邦交换器(federated exchange) 通过单向点对点的连接(Federation link) 形式进行通信。默认情况下,消息只会由Federation 连接转发一次,可以允许有复杂的路由拓扑来提高转发次数。在Federation 连接上,消息可能不会被转发,如果消息到达了联邦交换器之后路由不到合适的队列,那么它也不会被再次转发到原来的地方(这里指上游交换器,即(upstream exchange) 。可以通过Federation 连接广域网中的各个RabbitMQ 服务器来生产和消费消息。联邦队列(federated queue) 也是通过单向点对点连接进行通信的,消息可以根据具体的配置消费者的状态在联邦队列中游离任意次数。
通过Shovel 来连接各个RabbitMQ Broker ,概念上与Federation 的情形类似,不过Shovel工作在更低一层。鉴于Federation 从一个交换器中转发消息到另一个交换器(如果必要可以确认消息是否被转发), Shovel 只是简单地从某个Broker 上的队列中消费消息,然后转发消息到另一个Broker 上的交换器而已。Shovel 也可以在单独的一台服务器上去转发消息,比如将一个队列中的数据移动到另一个队列中。如果想获得比Federation 更多的控制,可以在广域网中使用Shovel 连接各个RabbitMQ Broker 来生产或消费消息。
| Federation / Shovel | 集群 |
|---|---|
| 各个Broker 节点之间逻缉分离 | 逻辑上是个Broker 节点 |
| 各个Broker 节点之间可以运行不同版本的Erlang 和RabbitMQ | 各个Broker 节点之间必须运行相同版本的Erlang 和RabbitMQ |
| 各个Broker 节点之间可以在广域网中相连,当然必须要授予适当的用户和权限 | 各个Broker 节点之间必须在可信赖的局域网中相连, 通过 Erlang 内部节点传输消息,但节点间需要有相同的Erlang cookie |
| 各个Broker 节点之间能以任何拓扑逻辑部署,连接可以是单向的或者双向的 | 所有Broker 节点都双向连续所有其他节点 |
| 从CAP 理论中选择可用性和分区耐受性,即AP | 从CAP 理论中选择一致性和可用性, CA |
| 一个Broker 中的交换器可以是Federation 生成的或者是本地的 | 集群中所有Broker 节点中的交换器都是一样的,要么全有要么全无 |
| 客户端所能看到它所连接的Broker 节点上的队列 | 客户端连接到集群中的任何Broker 节点都可以看到所有的队列 |