文章目录
- offset的默认维护位置
- 消费`__consumer_offsets` 案例
- 自动提交offset
- Code
- 手动提交offset
- Code 同步提交
- Code 异步提交
- 指定offset 消费 (auto.offset.reset = earliest | latest | none |)
- 数据漏消费和重复消费分析

offset的默认维护位置
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets。
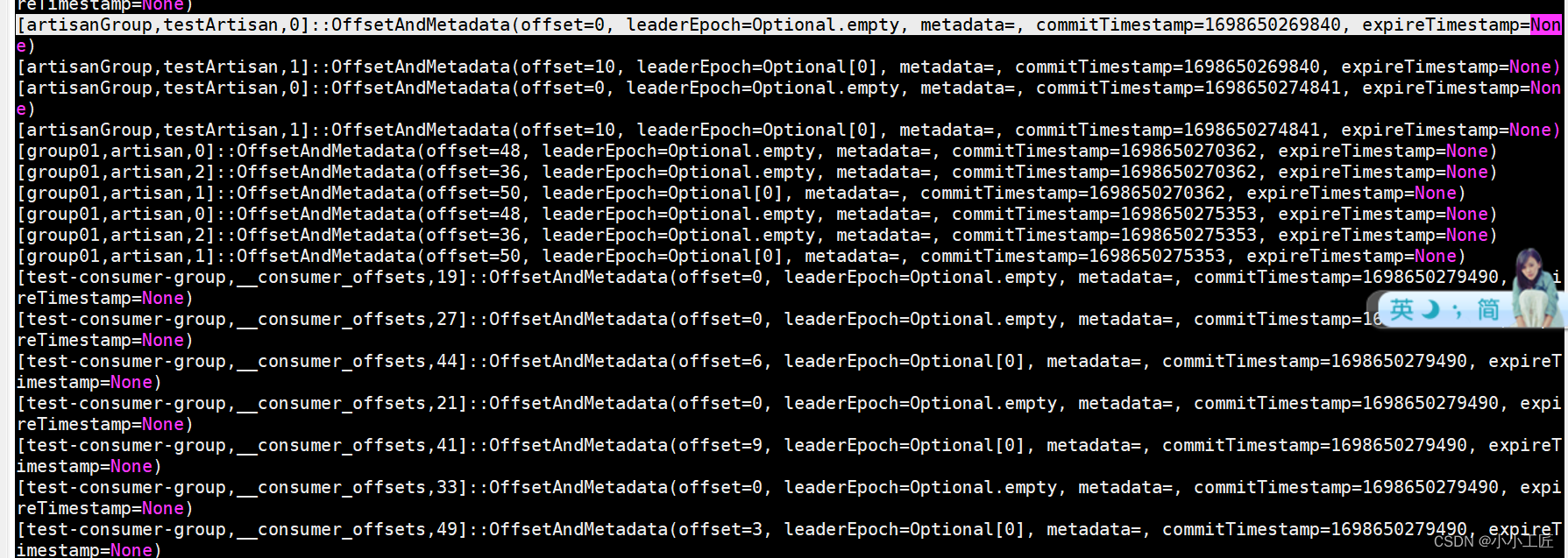
在__consumer_offsets主题里面采用key+value的方式存储数据。
- key是groupId+topic+分区号
- value是当前offset的值。
每个一段时间,kafka内部就会对这个topic进行compact(压实),即每个groupId+topic+分区号就保留最新的数据。

消费__consumer_offsets 案例
-
__consumer_offsets为kafka中的topic, 那就可以通过消费者进行消费 -
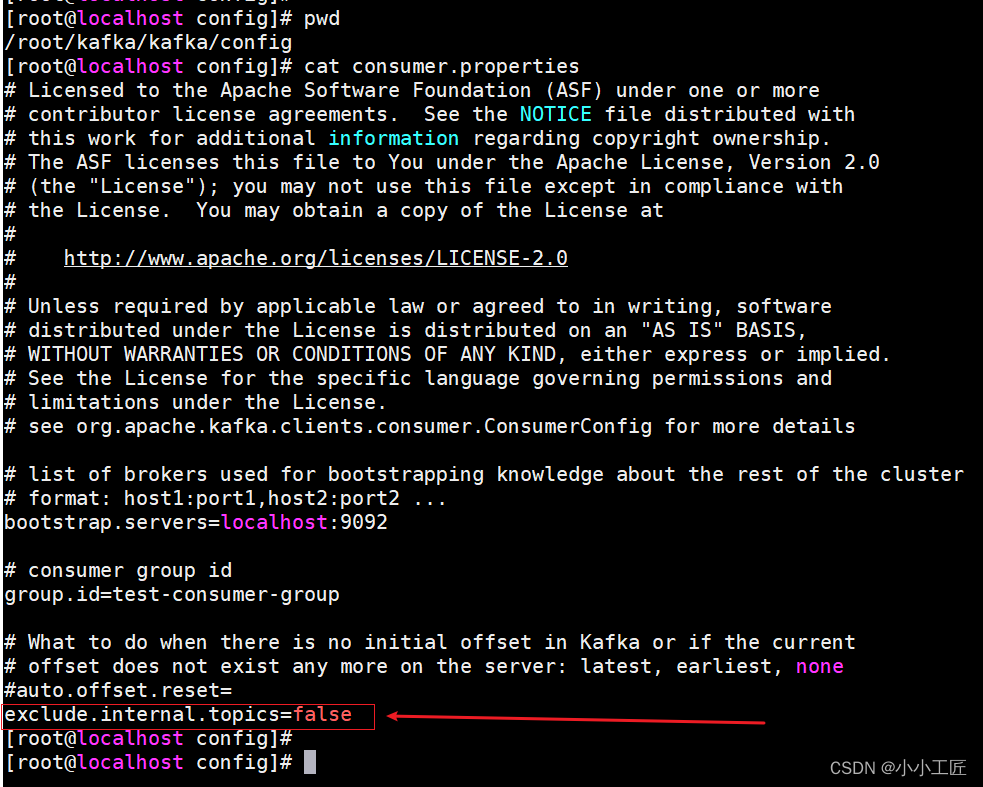
在配置文件
config/consumer.properties中添加配置exclude.internal.topics=false,默认就是true,表示不能消费系统主题。我们为了查看系统主题数据,需要将参数修改为false。
-
在命令行创建一个新的topic
[root@localhost bin]# ./kafka-topics.sh --bootstrap-server 192.168.126.171:9092 --create --topic testArtisan --partitions 2
Created topic testArtisan.
-
启动生产者向主题testArtisan 中生产数据

-
启动消费者消费主题testArtisan 中的数据

注意:指定消费者组的名称,能够更好的观察数据存储位置(key—>groupId+toipc+分区号)。
- 启动消费者消费主题
__consumer_offsets
[root@localhost bin]# ./kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server 192.168.126.171:9092 --consumer.config ../config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
自动提交offset
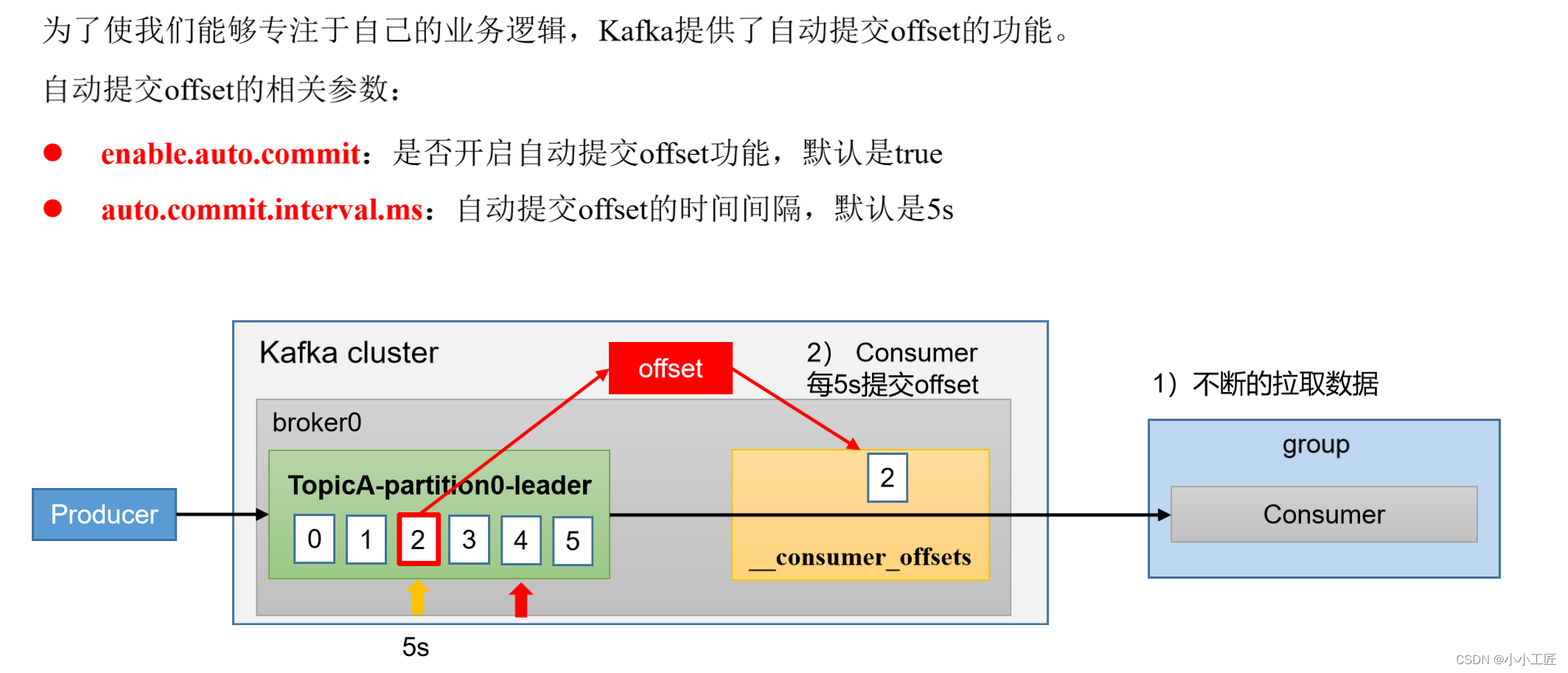
Kafka的自动提交offset机制是一种用于管理消费者在消费消息时的偏移量(offset)的方式。这机制的主要特点是自动地将已成功消费的消息的offset提交给Kafka,而不需要消费者显式地去追踪和提交offset。以下是其工作原理的简要概述:
-
消费者订阅Topic:消费者在启动时订阅一个或多个Kafka Topic,以开始消费消息。
-
消息消费:消费者从订阅的Topic中拉取消息,并进行处理。一旦成功处理一条消息,消费者会自动记录该消息的offset。
-
自动提交offset:根据配置,消费者可以定期自动提交成功消费的消息的offset给Kafka集群。这意味着消费者不需要手动追踪每个分区的offset,Kafka会代替其执行这项任务。
-
配置参数:消费者可以通过配置以下两个参数来控制自动提交offset的方式:
enable.auto.commit:指定是否启用自动提交offset,默认为true。auto.commit.interval.ms:指定自动提交offset的时间间隔,默认为5秒。
-
注意事项:自动提交offset的机制便捷,但也需要注意以下几点:
- 如果开启自动提交,消费者在处理消息时,offset将在后台自动提交。这可能导致消息在失败时被重新处理,因此消费者需要处理消息处理失败的情况。
- 自动提交的时间间隔需要根据具体需求来配置,以兼顾数据处理的实时性和offset提交的频率。
自动提交offset机制简化了消费者代码,降低了维护的复杂性。但在某些情况下,需要注意确保消息处理的幂等性,以防止重复处理已经提交的消息。如果需要更精确的offset控制,或者需要在消息处理失败时执行自定义逻辑,消费者也可以选择禁用自动提交,手动管理offset。
Code
package com.artisan.pc;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Properties;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/
public class CustomConsumer2 {
public static void main(String[] args) {
// 1.创建消费者的配置对象
Properties properties = new Properties();
// 2.给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.126.171:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 配置消费者组 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "artisan-group");
// 是否自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 提交offset的时间周期,默认5s,
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 3. 创建消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
// 4. 订阅主题
consumer.subscribe(Arrays.asList("artisan"));
// 5. 拉取数据打印
while (true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 6. 遍历并输出消费到的数据
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord);
}
}
}
}
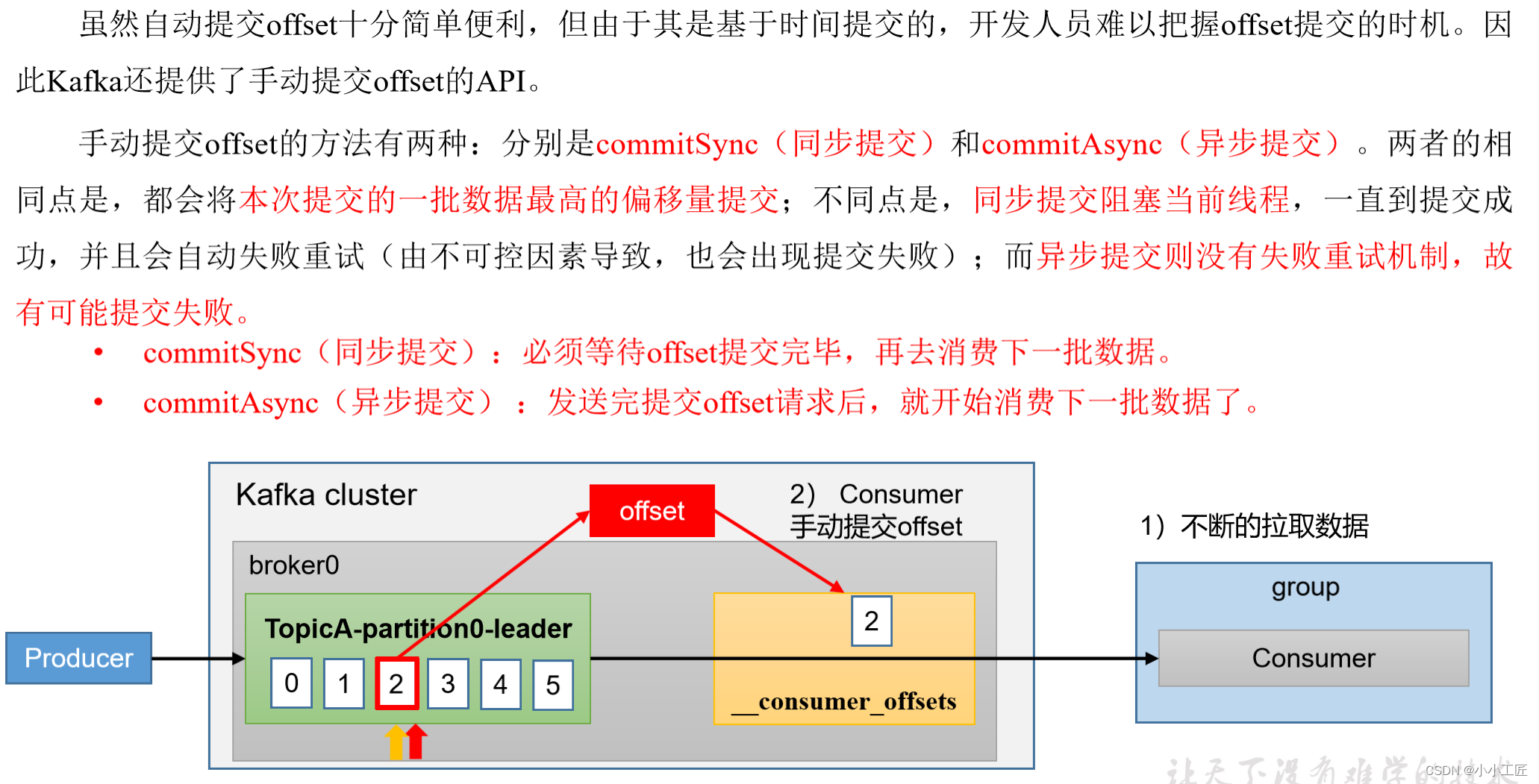
手动提交offset
Kafka允许消费者以两种方式来管理offset,即消费者可以选择自动提交offset或手动提交offset。在手动提交offset的机制中,消费者有更多的控制权和灵活性,可以在确保消息被处理后再提交offset。以下是手动提交offset的简要描述:
-
Offset的概念:在Kafka中,每个消费者都有一个当前的offset,表示它在分区中已经读取到的位置。Offset是一个标识,用来追踪消费者在每个分区中的读取位置。
-
手动提交offset:手动提交offset是指消费者自己负责告知Kafka Broker已经成功处理了一批消息,并提交了offset。这样的机制让消费者能够更细粒度地控制offset的提交时机。
-
何时提交offset:消费者可以在处理消息后手动提交offset,通常在以下情况下提交:
- 在消息成功处理后,即确认消息已被消费。
- 周期性地,以确保即使消费者失败,它不会重新处理相同的消息。
-
提交offset的方法:Kafka提供了两种主要的手动提交offset的方法:
commitSync():这是同步提交offset的方法,消费者会等待直到offset提交成功后才继续处理消息。commitAsync():这是异步提交offset的方法,消费者会提交offset,但不会等待确认。
-
手动提交的注意事项:
- 手动提交offset需要谨慎,因为如果offset提交不正确,可能会导致消息被重复消费或者丢失。
- 消费者需要确保offset提交的原子性,以避免提交失败的情况。
- 如果消费者处理了消息但在提交offset之前失败,可能需要实施一些恢复机制,以避免数据丢失或重复处理。
手动提交offset的机制使消费者更有控制权,允许它们以适应不同的处理需求。然而,这也增加了一些复杂性,需要谨慎处理offset提交以确保数据的一致性和可靠性。自动提交offset与手动提交offset相比,更容易实施,但可能不适用于需要更细粒度控制的情况。
Code 同步提交
由于同步提交offset有失败重试机制,故更加可靠,以下为同步提交offset的示例。
package com.artisan.pc;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/
public class CustomConsumerByHand {
public static void main(String[] args) {
// 1. 创建kafka消费者配置类
Properties properties = new Properties();
// 2. 添加配置参数
// 添加连接
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.126.171:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 配置消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 是否自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 提交offset的时间周期
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 3. 创建kafka消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 4. 设置消费主题 形参是列表
consumer.subscribe(Arrays.asList("artisan"));
// 5. 消费数据
while (true) {
// 6. 读取消息
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 7. 输出消息
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.value());
}
// 同步提交offset
consumer.commitSync();
}
}
}
Code 异步提交
虽然同步提交offset更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会受到很大的影响。因此更多的情况下,会选用异步提交offset的方式。
package com.artisan.pc;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
/**
* @author 小工匠
* @version 1.0
* @mark: show me the code , change the world
*/
public class CustomConsumerByHandAsync {
public static void main(String[] args) {
// 1. 创建kafka消费者配置类
Properties properties = new Properties();
// 2. 添加配置参数
// 添加连接
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.126.171:9092");
// 配置序列化 必须
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 配置消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 是否自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 提交offset的时间周期
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 3. 创建kafka消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 4. 设置消费主题 形参是列表
consumer.subscribe(Arrays.asList("artisan"));
// 5. 消费数据
while (true) {
// 6. 读取消息
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 7. 输出消息
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.value());
}
// 异步提交offset
consumer.commitAsync(new OffsetCommitCallback() {
/**
* 回调函数输出
* @param offsets offset信息
* @param exception 异常
*/
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
// 如果出现异常打印
if (exception != null) {
System.err.println("Commit failed for " + offsets);
}
}
});
}
}
}
指定offset 消费 (auto.offset.reset = earliest | latest | none |)
auto.offset.reset = earliest | latest | none |
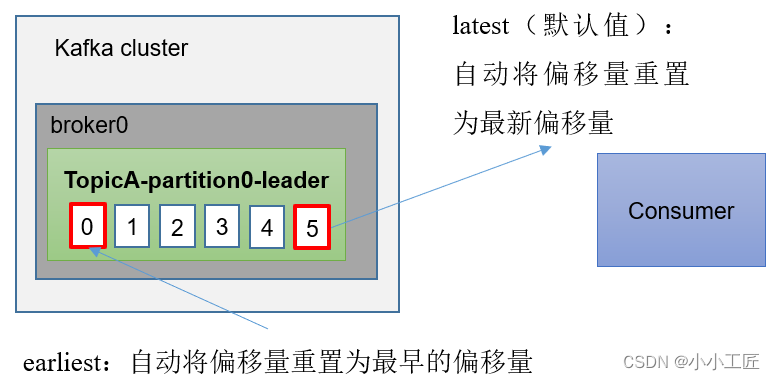
当Kafka中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
(1)earliest:自动将偏移量重置为最早的偏移量
(2)latest(默认值):自动将偏移量重置为最新偏移量
(3)none:如果未找到消费者组的先前偏移量,则向消费者抛出异常
数据漏消费和重复消费分析
- 问题:无论是同步提交还是异步提交offset,都有可能会造成数据的漏消费或者重复消费。
- 漏消费:先提交offset后消费,有可能造成数据的漏消费;
- 重复消费:而先消费后提交offset,有可能会造成数据的重复消费。
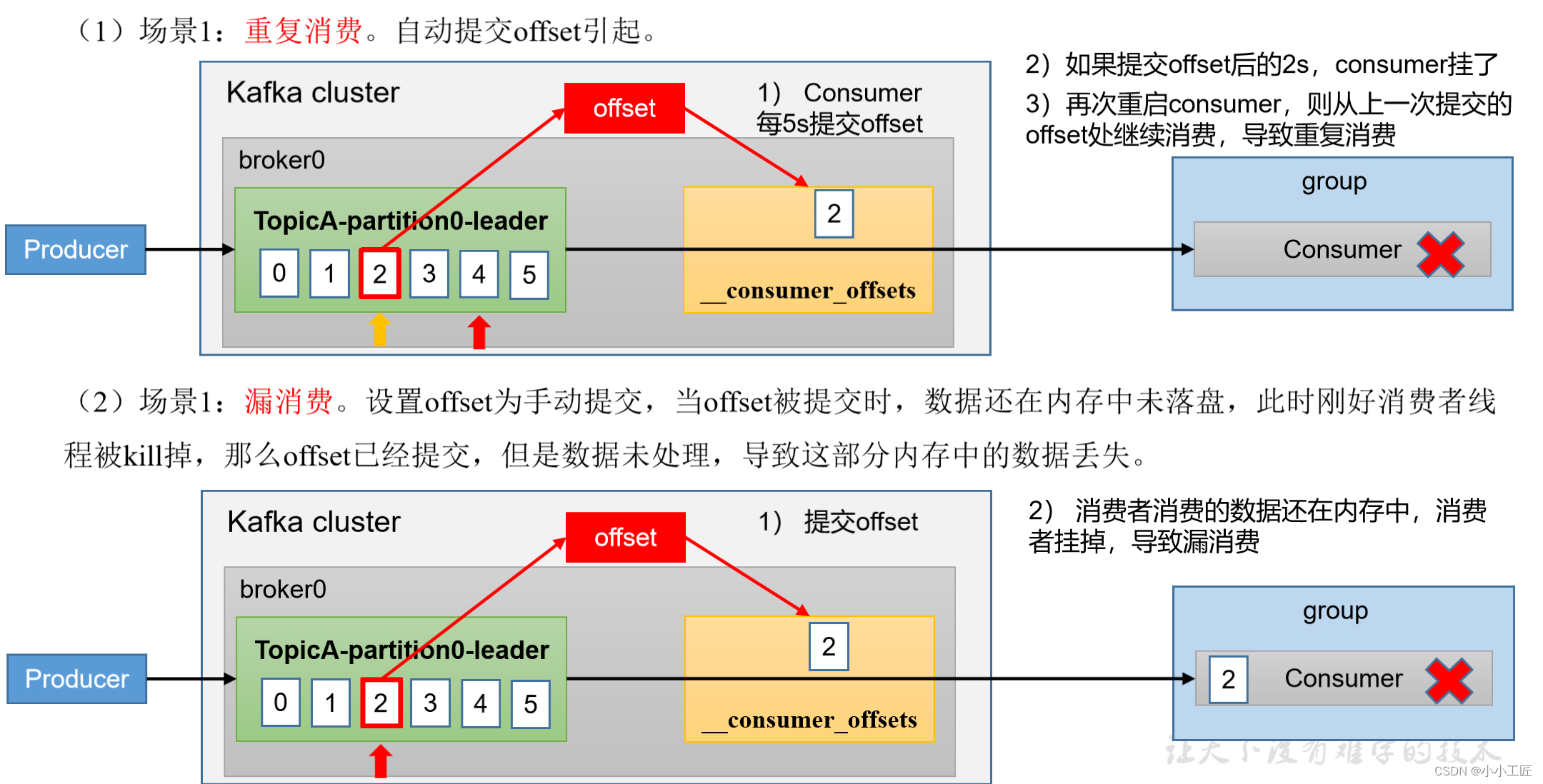
思考:怎么才能做到既不漏消费也不重复消费呢?




![[双指针] (三) LeetCode LCR 179. 查找总价格为目标值的两个商品 和 15. 三数之和](https://img-blog.csdnimg.cn/img_convert/a68be9eda0c5cd735110277576ef3769.png)