Author: Xinyao Tian
概述
本文档简要梳理了 StarRocks 的基本信息。
简介 Introduction
StarRocks 是面向下个时代的,高性能的数据分析仓库。其提供了实时、多维度、高并发的数据分析能力。
StarRocks is a next-gen, high-performance analytical data warehouse that enables real-time, multi-dimensional, and highly concurrent data analysis.
特性 Features
StarRocks 具有如下功能特性 [1]:
-
基于 MPP 架构 (Massively Parallel Processing architecture)
-
完全向量化处理引擎 (Fully vectorized execution engine)
-
列式存储 (columnar storage)
-
实时更新 (real-time updates)
-
完全可自定义的基于成本的优化器 (Fully-customized cost-based optimizer)
-
智能物化视图 (Intelligent materialized view)
-
丰富数据源的实时数据注入 (real-time data ingestion from a variety data sources)
-
丰富数据源的批量数据注入 (batch data ingestion from a variety data sources)
-
无数据迁移的数据湖分析 (Directly analyze data stored in data lakes with zero data migration)
-
兼容 Mysql 客户端连接协议 (compatible with MySQL protocols)
-
可扩展、高可用、易运维 (highly scalable, available, and easy to maintain)
-
广泛应用于业界 OLAP 分析领域 (widely adopted in the industry with OLAP scenarios)
Fast-speed multi-table joins = MPP + fully vectorized engine + CBO + intelligent materialized view
架构 Architecture [2]
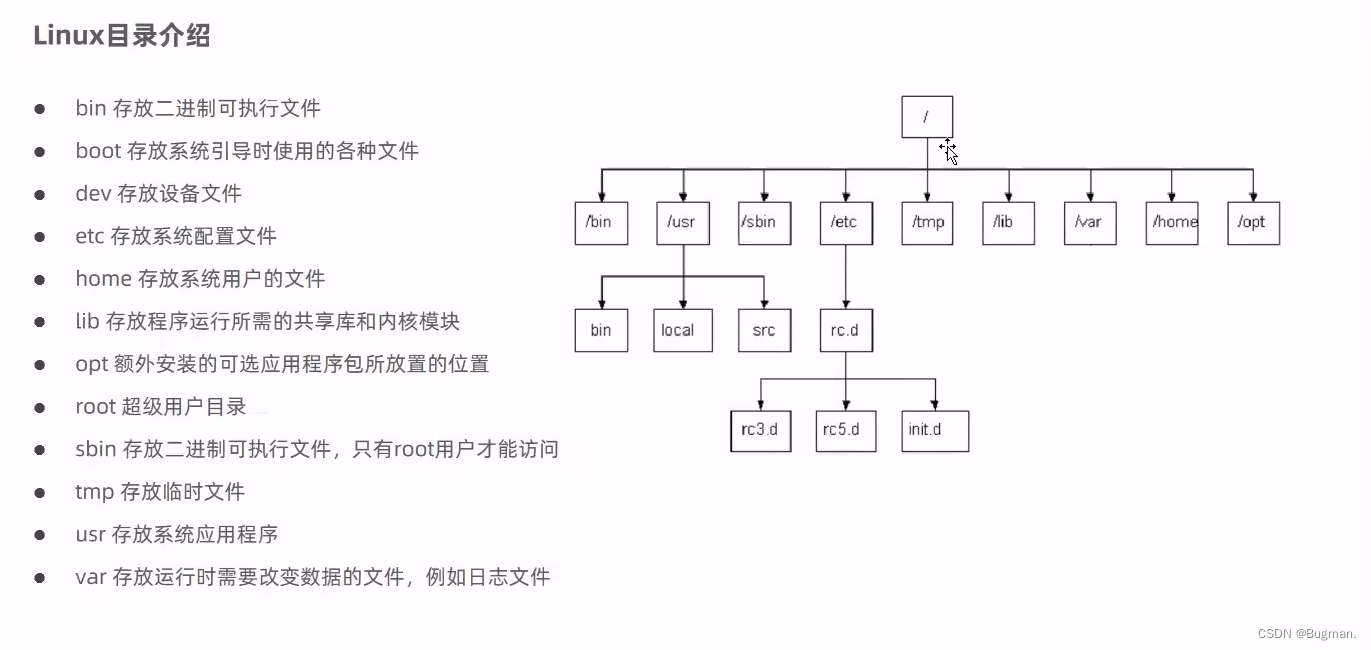
宏观架构
亮点:组件简单、可水平扩展、metadata 也有 replica 提供高可用 (metadata 被完整存储于每台 FE 的内存)
主要分工:
FE (ForntEnd) 负责元数据管理、客户端连接、查询计划、查询调度:
-
Leader:元数据的变更,并通过 BDE JE 协议将 metadata 同步至其他 FEs (Follower 和 Observer)
-
Follower:参与竞选并在内存中同步存储完整的 metadata
-
Observer:不参与选举的 Follower,仅作为性能扩展的 FE
BE (BackEnd) 主要负责数据存储和 SQL 执行和计算:
-
数据存储:BEs 接受从 FEs 分配来的数据,并将数据按照指定格式写入,并生成 Index
-
SQL 执行:BEs 接收从 FEs 处理后的物理执行计划并将目标数据缓存并执行查询

数据管理架构
StarRocks 同时使用分区 (Partitioning) 和分桶 (Bucketing) 机制对数据进行管理,以增强查询的效率和并发度。
如下图所示,一张表被根据时间分为四个分区,同时第一个分区内又被分为了四个数据小块 (Data Tablet) 。每个数据小块又创建了三份备份 (Replica) 并被分别存储在不同的 BE 上。由于一张表被分解成了多个数据小块,因此 StarRocks 可以将一个 SQL 查询语句分派到多个物理节点上并行执行,从而最大化物理主机和处理器的计算能力,同时还可以提升服务的可用性。用户可以轻松地按需扩展物理主机从而获得更高的并发性能。

亮点:No Need for manual data redistribution (StarRocks 会自动根据新加入或删除的物理节点进行数据小块再分配,而不需要手动进行数据均衡。StarRocks 默认的 Replica 数量为 3)
常见应用场景 Scenarios
StarRocks 基于上述的架构和功能特性可以为我们在如下场景中解决诸多问题。
OLAP multi-dimensional analytics
StarRocks 的 MPP 架构配合向量执行引擎可以让用户在不同的 schemas 之间进行选择并开发多维度分析报告。主要的应用场景包括:
-
用户行为分析 (User behavior analysis)
-
用户画像、用户标签、标签分析 (User profiling, user tagging, label analysis)
-
高纬度指标分析报告 (High-dimensional metrics report)
-
自助数据仪表板 (Self-service dashboard)
-
服务异常探测和分析 (Service anomaly probing and analysis)
-
跨场景分析 (Cross-theme analysis)
-
金融数据分析 (Financial Data analysis)
-
系统监测分析 (System monitoring analysis)
Real-time analytics
StarRocks 使用主键表来进行实时更新。在 StarRocks 的 TB 级数据库的数据改变可以被在数秒内得到同步并用于搭建实时数据仓库。主要的应用场景包括:
-
在线促销分析 (Online promotion analysis)
-
物流跟踪和分析 (Logistics tracking and analysis)
-
金融领域的性能分析和指标计算 (Performance analysis and metrics computation for the financial industry)
-
在线直播的质量分析 (Quality analysis for livestreaming)
-
广告放置位置分析 (Ad placement analysis)
-
驾驶舱管理 (Cockpit management)
-
应用性能管理 (Application Performance Management (APM))
High-concurrency analytics
StarRocks 借助高效的数据分布,灵活的 Index 和智能化物化视图来促进面向用户的高并发分析。主要的应用场景包括:
-
广告商报告分析 (Advertiser report analysis)
-
零售业渠道分析 (Channel analysis for the retail industry)
-
Saas 面向用户分析 (User-facing analysis for SaaS)
-
多表仪表板分析 (Multi-tabbed dashboard analysis)
Unified analytics
StarRocks 提供了一致性的数据分析体验。
-
一个系统提供了应对多种分析场景的能力,显著降低系统复杂度和总体采购成本 (TCO)
-
提供了统一的数据湖和数据仓库接口。
核心机制与技术 Core Mechnism and Tech
StarRocks 使用了许多先进的技术为用户在大数据集的场景提供侵略如火般的实时分析体验。其核心技术如下所示,在此处暂不做原理的解释和说明。详情请参考 [3]。
-
MPP 架构 (MPP Framework): StarRocks 并行处理大规模数据的核心理论依据
-
完全向量化的执行引擎 (Fully Vectorized Execution Engine)
-
基于成本的优化器 (Cost-based Optimizer)
-
实时的,可更新的列式存储引擎 (Real-time, updatable columnar storage engine)
-
智能的物化视图 (Intelligent materialized view): 物化视图自动更新 (无需手动操作和人工介入) 且自动进行查询优化
-
数据湖直连分析 (Data lake analytics): 通过 Catalog 达成湖仓直连无需转换或导数
References
-
[1] StarRocks DB 简介: https://docs.starrocks.io/en-us/latest/introduction/StarRocks_intro
-
[2] StarRocks 架构: https://docs.starrocks.io/en-us/latest/introduction/what_is_starrocks
-
[3] StarRocks 特性: https://docs.starrocks.io/en-us/latest/introduction/Features






![致远OA wpsAssistServlet任意文件上传漏洞复现 [附POC]](https://img-blog.csdnimg.cn/f4e5d91968584fd9ac69328e6ee1e388.png)